
生成式人工智能集成模式(二)
让我们考虑一个场景,我们正在与一家处理大量法律合同、监管文件、产品披露、内部政策和程序的大型金融机构合作。这些文件单独可能长达数十页甚至数百页,使得员工、客户和其他利益相关者在需要时难以快速找到相关信息。这些文件在信息报告的方式上也没有一致的格式,这使得像正则表达式语句或普通业务规则这样的非 AI 驱动的文本提取解决方案无效。该机构希望实施一个聊天机器人系统,可以为用户提供友好的界面,让他们提出自
原文:
zh.annas-archive.org/md5/81a893dea72f891dc95a3737db4644e8译者:飞龙
第八章:集成模式:实时检索增强生成
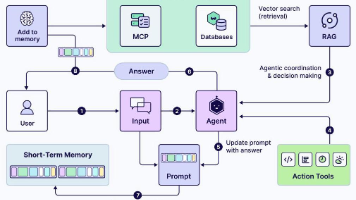
在本章中,我们将探讨另一种集成模式,该模式结合了检索增强生成(RAG)和生成式 AI 模型的力量,以构建一个能够根据 PDF 文件内容回答问题的聊天机器人。这种方法结合了检索系统和生成模型的优势,使我们能够利用现有的知识源,同时生成相关和上下文化的响应。
RAG 方法的一个关键优势是其防止幻觉并提高生成响应上下文的能力。基于广泛数据训练的生成式 AI 模型有时可能会产生事实错误或过时的响应,因为它们的训练数据仅限于某个时间点或它们在推理时可能缺乏适当的上下文。通过将模型的生成过程建立在从文档语料库检索到的相关信息之上,RAG 方法减轻了幻觉的风险,并确保响应准确且上下文相关。
例如,术语退款在不同的上下文中可能有不同的含义和影响。在零售银行业的上下文中,退款可能指客户请求退还费用或收费,而在税收的上下文中,退款可能指政府提供的税收退款。通过从文档语料库中检索相关上下文,RAG 驱动的聊天机器人可以生成准确反映退款意图含义的响应,基于用户查询的具体上下文。
下图展示了简单的 RAG 流程:
https://github.com/OpenDocCN/freelearn-dl-zh/raw/master/docs/genai-app-intg-ptn/img/B22175_08_01.png
图 8.1:简单的 RAG 流程
继续我们关于金融服务公司的例子,这些公司经常处理大量的文件,包括法律合同、监管文件、产品披露以及内部政策和程序。这些文档存储库可能包含数万甚至数十万页,这使得员工和客户在需要时难以快速找到相关信息。
通过实施基于 RAG 的聊天机器人系统,金融服务公司可以为员工、客户和其他利益相关者提供一个用户友好的界面,让他们能够提出自然语言问题并接收来自大量文档的简洁、相关的答案。RAG 方法允许系统从文档语料库中高效地检索相关信息,然后使用强大的生成式 AI 模型生成上下文化的响应。
例如,客户服务代表可以向聊天机器人询问关于贷款协议中特定条款的问题,系统将检索文档语料库中的相关部分,并生成针对用户查询的简洁解释。同样,投资顾问可以询问与金融产品相关的特定法规或指南,聊天机器人将提供相关文档中的必要信息。
通过利用 RAG 方法,金融服务公司可以极大地提高其文档存储库的可访问性和可用性,实现更快、更准确的信息检索,并减少手动搜索数千页文档所需的时间和精力。
在本章中,我们将介绍以下内容:
-
用例定义(针对金融服务公司)
-
架构(基于 RAG 的聊天机器人系统概述):
-
数据摄取层
-
文档语料库管理
-
AI 处理层
-
监控和日志记录
-
-
入口点(处理各种输入模式的设计)
-
提示预处理和向量数据库集成
-
使用 Vertex AI 的 Gemini 1.5 Flash 模型进行推理过程
-
使用 Markdown 进行结果后处理和展示
-
演示实现(使用 Gradio)
-
RAG 流程的完整代码示例
用例定义
让我们考虑一个场景,我们正在与一家处理大量法律合同、监管文件、产品披露、内部政策和程序的大型金融机构合作。这些文件单独可能长达数十页甚至数百页,使得员工、客户和其他利益相关者在需要时难以快速找到相关信息。这些文件在信息报告的方式上也没有一致的格式,这使得像正则表达式语句或普通业务规则这样的非 AI 驱动的文本提取解决方案无效。
该机构希望实施一个聊天机器人系统,可以为用户提供友好的界面,让他们提出自然语言问题,并接收来自组织文档语料库的简洁、相关答案。该系统应利用 RAG 的力量,确保生成的回答准确、上下文相关,并基于文档语料库中的相关信息。
建筑学
为了构建我们的基于 RAG 的聊天机器人系统,我们将利用建立在 Google Cloud 之上的无服务器、事件驱动的架构。这种方法与我们之前示例中使用的云原生原则相一致,并允许与其他云服务无缝集成。您可以在以下示例架构中深入了解 Google Cloud 的示例:cloud.google.com/architecture/rag-capable-gen-ai-app-using-vertex-ai。
在本例中,架构包括以下关键组件:
-
摄取层:这一层负责接受来自各种渠道的用户查询,例如网页表单、聊天界面或 API 端点。我们将使用 Google Cloud Functions 作为我们系统的入口点,它可以由云存储、Pub/Sub 或 Cloud Run 等服务的事件触发。
-
文档语料库管理:在这一层,我们将存储代表文档内容的嵌入表示。在这种情况下,我们可以使用从专门构建的向量数据库(如 Chroma DB、Pinecone 或 Weaviate)到知名行业标准(如 Elastic、MongoDB、Redis)的各种解决方案,甚至包括以其他能力著称的数据库,如 PostgreSQL、SingleStore、Google AlloyDB 或 Google BigQuery。
-
AI 处理层:在这一层,我们将通过 Vertex AI 集成 Google Gemini。一旦从向量数据库检索到结果,它们将作为上下文与提示一起暴露给 Google Gemini。这个过程可以通过云函数处理。
-
监控和日志记录:为确保系统的可靠性和性能,您应实施强大的监控和日志记录机制。我们将利用云日志、云监控和云操作等服务来了解系统行为,并快速识别和解决任何问题。
入口点
对于基于 RAG 的聊天机器人系统,入口点被设计成用户友好,允许用户通过各种接口提交他们的自然语言查询,例如网页表单、聊天应用或 API 端点。然而,入口点不应仅限于接受基于文本的输入;它还应处理不同的模态,如音频文件或图像,具体取决于底层语言模型的能力。
对于像 Google Gemini(支持多模态输入)这样的模型,入口点可以直接接受和处理文本、音频、图像,甚至视频。这种多功能性使用户能够以更自然和直观的方式与聊天机器人系统交互,与人类在现实世界场景中的沟通方式相一致。
在语言模型不原生支持多模态输入的情况下,入口点仍然可以通过预处理数据和提取文本内容来适应各种输入模态。这种方法确保了聊天机器人系统易于访问和用户友好,同时利用底层语言模型的能力,满足多样化的输入格式。
对于文本输入,入口点可以直接将查询传递给 RAG 管道的后续阶段。然而,当处理音频或图像输入时,入口点需要执行额外的处理来从这些模态中提取文本内容。
对于音频输入,入口点可以利用语音识别技术,如 Google Chirp、Amazon Transcribe、OpenAI Whisper 或 CMU Sphinx 等开源库,将音频数据转录成文本格式。这个过程涉及将音频信号转换为语言模型可以理解的单词或短语序列。
同样,对于图像输入,入口点可以采用光学字符识别(OCR)技术从提供的图像中提取文本。这可以通过集成 Google Cloud Vision API、Amazon Textract 或 Tesseract OCR 等开源工具来实现。这些技术利用计算机视觉和机器学习算法来准确识别和从图像中提取文本内容,使聊天机器人系统能够理解和处理以视觉形式呈现的信息。
在这个例子中,我们将利用文本;Python 代码将如下所示:
#In this case we will simulate the input from a chat interface
question = "What is this call about?"
无论输入类型如何,入口点都应该设计成能够处理各种场景和输入格式。它可能需要执行额外的预处理步骤,例如噪声去除、格式转换或数据清理,以确保输入数据适合 RAG 管道后续阶段的格式。此外,运行原始请求通过严格的安全监控管道也是最佳实践,以防止数据泄露或模型中毒,如提示摄入。
以下网站提出了关于多模态场景中提示注入带来的挑战的非常有趣的观点:protectai.com/blog/hiding-in-plain-sight-prompt。
提示预处理
对于我们的例子,我们需要实时构建提示及其必要的上下文和指令。在我们 RAG 管道的这个步骤中,我们将利用向量数据库进行高效的向量相似度搜索。向量数据库是专门的数据存储,用于存储和检索高维向量,能够实现快速和准确的相似度搜索。尽管有众多向量数据库提供商,但我们将在这个特定例子中使用 Chroma DB。
在 RAG 管道中的检索过程相对简单。首先,我们使用预训练的语言模型或嵌入技术从用户的查询中生成嵌入。这些嵌入是查询的数值表示,能够捕捉其语义意义。接下来,我们使用生成的查询嵌入在向量数据库上执行相似度搜索。向量数据库将返回与查询嵌入最相似的向量,以及它们对应的文本信息或上下文。这些向量与之前摄取的文本段落相关联。
可以应用不同的过滤策略来进一步细化搜索结果。具体参数和技术可能因所使用的向量数据库提供商而异。例如,一些向量数据库提供相似度分数,该分数衡量查询嵌入与检索向量之间的接近程度。可以利用此分数来识别和过滤掉低于一定相似度阈值的向量。
另一种常见的过滤策略是限制从向量数据库中获取的结果数量。这种方法在存在对可以传递给语言模型的标记最大数量的限制时特别有用,无论是由于模型施加的标记限制还是为了成本优化目的。通过限制结果数量,我们可以控制提供给语言模型的上下文信息量,确保高效处理和成本效益的运行。
一旦结果被过滤,并获取到相关的文本信息,它就被用来构建将传递给语言模型的提示。在这个例子中,我们使用以下提示模板:
prompt_template = """
You are a helpful assistant for an online financial services company that allows users to check their balances, invest in certificates of deposit (CDs), and perform other financial transactions.
Your task is to answer questions from your customers, in order to do so follow these rules:
1\. Carefully analyze the question you received.
2\. Carefully analyze the context provided.
3\. Answer the question using ONLY the information provided in the context, NEVER make up information
4\. Always think step by step.
{context}
User question: {query}
Answer:
"""
在我们的示例中,我们提交给 LLM 的提示将如下所示:
You are a helpful assistant for an online financial services company that allows users to check their balances, invest in certificates of deposit (CDs), and perform other financial transactions.
Your task is to answer questions from your customers, in order to do so follow these rules:
1\. Carefully analyze the question you received.
2\. Carefully analyze the context provided.
3\. Answer the question using ONLY the information provided in the context, NEVER make up information
4\. Always think step by step.
<context>
---This information is contained in a document called coca_cola_earnings_call_2023.pdf
1-877-FACTSET www.callstreet.com
18 Copyright © 2001-2024 FactSet CallStreet, LLC
The Coca-Cola Co. (KO) Q1 2024 Earnings Call
Corrected Transcript 30-Apr-2024
Operator: Ladies and gentlemen, this concludes today's conference call. Thank you for participating. You may now disconnect.
Disclaimer The information herein is based on sources we believe to be reliable but is not guaranteed by us and does not purport to be a complete or error-free statement or summary of the available data. As such, we do not warrant, endorse or guarantee the completeness, accuracy, integrity, or timeliness of the information. You must evaluate, and bear all risks associated with, the use of any information provided hereunder, including any reliance on the accuracy, completeness, safety or usefulness of such information. This information is not intended to be used as the prim ary basis of investment decisions. It should not be construed as advice designed to meet the particular investment needs of any investor. This report is published solely for information purposes, and is not to be construed as financial or other advice or as an offer to sell or the solicitation of an offer to buy any security in any state where such an offer or solicitation would be illegal. Any information expressed herein on this date is subject to change without notice. Any opinions or assertions contained in this information do not represent the opinions or beliefs of FactSet CallStreet, LLC. FactSet CallStreet, LLC, or one or more of its employees, including the writer of this report, may have a position in any of the securities discussed herein.
---
---This information is contained in a document called coca_cola_earnings_call_2023.pdf
All participants will be on listen-only mode until the formal question-and-answer portion of the call. I would like to remind everyone that the purpose of this conference is to talk with investors and, therefore, questions from the media will not be addressed. Media participants should contact Coca-Cola's Media Relations department if they have any questions.
. . .
---
</context>
User question: What is this call about?
Answer:
推理
generate() function is responsible for sending the prompt to the Gemini 1.5 Flash model and obtaining the generated response:
#This is the section where we submit the full prompt and
#context to the LLM
result = generate(prompt)
generate()函数封装了生成过程所需的配置和设置。它包括两个主要组件:generation_config和safety_settings。
generation_config字典指定了在生成过程中控制语言模型行为的参数。在这个例子中,提供了以下设置:
generation_config = {
"max_output_tokens": 8192,
"temperature": 0,
"top_p": 0.95,
}
来自 Google Gemini 的文档:
-
max_output_tokens: 响应中可以生成的最大标记数。一个标记大约是四个字符。100 个标记相当于大约 60-80 个单词。 -
temperature: 温度用于在响应生成过程中进行采样,这发生在应用top_p和top_k时。temperature控制了标记选择的随机程度。较低的温度值适用于需要较少开放或创造性的响应的提示,而较高的温度值可能导致更多样化或创造性的结果。温度为 0 表示始终选择概率最高的标记。在这种情况下,对于给定的提示,响应大多是确定性的,但仍可能存在少量变化。
温度为 0 表示模型将根据其训练数据选择最可能的标记,而较高的值会在输出中引入更多的随机性和多样性。
top_p: 此参数改变模型选择输出标记的方式。标记从最有可能到最不可能依次选择,直到这些标记的概率总和等于 top-p 值。例如,如果标记 A、B 和 C 分别具有 0.3、0.2 和 0.1 的概率,且 top-p 值为 0.5,那么模型将通过温度选择 A 或 B 作为下一个标记,并将 C 排除作为候选。
在这种情况下,它被设置为 0.95,这意味着在生成过程中只考虑概率最高的前 95%的标记。
除了上述内容之外,safety_settings字典指定了危害类别及其对应的阈值,用于从生成的输出中过滤可能有害或不适当的内容。在此示例中,提供了以下设置:
safety_settings = {
generative_models.HarmCategory.HARM_CATEGORY_HATE_SPEECH: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
generative_models.HarmCategory.HARM_CATEGORY_HARASSMENT: generative_models.HarmBlockThreshold.BLOCK_ONLY_HIGH,
}
这些设置指示 Gemini 1.5 Flash 模型仅阻止与仇恨言论、危险内容、色情内容和骚扰高度相关的有害内容。任何低于这些类别“高”危害阈值的任何内容都将允许在生成的输出中出现。
generate()函数创建了一个GenerativeModel类的实例,传递了MODEL参数;在此示例中,为 Gemini 1.5 Flash。然后它调用模型实例上的generate_content()方法,提供提示、生成配置和安全设置。stream=False参数表示生成应在非流模式下进行,这意味着整个响应将一次性生成并返回:
def generate(prompt):
model = GenerativeModel(MODEL)
responses = model.generate_content(
[prompt],
generation_config=generation_config,
safety_settings=safety_settings,
stream=False,
)
return(responses)
生成的响应存储在responses变量中,然后通过generate()函数返回。
通过将格式化的提示提交给 Vertex AI 的 Gemini 1.5 Flash API 端点,利用提供的生成配置和安全设置,此 RAG 管道可以获取一个针对用户查询的上下文化和相关响应,同时遵守指定的参数和内容过滤规则。
结果后处理
在收到语言模型的响应后,通常希望以更结构化和视觉上吸引人的格式展示输出。Markdown 是一种轻量级标记语言,允许你添加格式化元素,如标题、列表、代码块等。在此示例中,我们使用 Markdown 格式化来增强问题、答案和上下文的展示:
#In this section you can format the answer for example with markdown
formatted_result = f"###Question:\n{question}\n\n###Answer:\n{result.text}\n\n<details><summary>Context</summary>{context}</details>"
此格式化组件的分解如下:
"###问题:\n{question}"
此部分为问题部分添加了一个 3 级 Markdown 标题(###),随后是新的一行上用户的原始查询(({question})。
"\n\n###答案:\n{result.text}"
在该部分开头添加一个空行(\n\n)之后,此部分为答案部分创建了一个新的 3 级 Markdown 标题,随后是新的一行上语言模型生成的响应({result.text})。
"\n\n<details><summary>上下文</summary>{context}</details>"
此部分利用 Markdown <details> 和 <summary> 标签创建一个可折叠的显示从向量数据库检索到的上下文信息的部分。<summary>上下文</summary> 文本作为可折叠部分的标签,实际上下文文本({context})被包含在 <details> 标签内。
结果展示
IPython.display模块中的Markdown类是一个实用工具,允许你在 Colab 笔记本或其他 IPython 环境中显示格式化的 Markdown 内容。通过将formatted_result字符串传递给 Markdown 构造函数,你创建了一个 Markdown 对象,该对象可以通过display函数进行渲染:
display(Markdown(formatted_result))
当你调用display()时,笔记本将渲染formatted_result字符串中包含的 Markdown 格式化内容。这允许你在笔记本环境中利用 Markdown 的丰富格式化功能。
以下是我们演示的 Markdown 格式化输出示例:
https://github.com/OpenDocCN/freelearn-dl-zh/raw/master/docs/genai-app-intg-ptn/img/B22175_08_02.png
图 8.2:Google Colab 笔记本中格式化结果截图
通过使用Markdown类和display函数,你可以在 Google Colab 笔记本环境中利用 Markdown 的格式化功能。这包括标题、粗体和斜体文本、列表、代码块、链接等功能。
渲染的输出将在笔记本单元格中显示,提供对问题、答案和上下文信息的视觉吸引力和良好结构化的表示。这可以极大地提高聊天机器人响应的可读性和可用性,使用户或开发者更容易理解和解释结果。
此外,在context部分使用的 <details> 和 <summary> 标签创建了一个可折叠部分,允许用户切换上下文信息的可见性。这在处理大量上下文数据时尤其有用,因为它可以防止主输出混乱,同时仍然提供轻松访问相关信息。
在下一节中,我们将通过用例演示深入探讨所有这些组件是如何协同工作的。
用例演示
以下是用 Gradio 构建演示的代码;在这种情况下,我们将使用一个额外的函数来执行 RAG 管道。当你运行此代码时,默认网络浏览器中会打开一个 Gradio 界面,显示三个主要部分:
-
金融科技助手标题
-
聊天机器人区域
-
文本输入框
用户可以在输入框中输入问题并提交。聊天功能将被调用,它将使用answer_question函数从向量数据库中检索相关上下文,使用 RAG 管道生成答案,并更新聊天机器人界面,显示用户的问题和生成的响应。
Gradio 接口为用户提供了一种用户友好的方式来与 RAG 管道系统交互,使其更容易测试和展示其功能。此外,Gradio 还提供了各种自定义选项和功能,例如支持不同的输入和输出组件、样式和部署选项。我们首先安装 Gradio:
#In this case we will use a Gradio interface to interact
#with the system
#Install Gradio
!pip install --upgrade gradio
接下来,我们定义两个辅助函数,这些函数基于之前解释的 generate() 函数:
import gradio as gr
def answer_question(query, db, number_of_results):
context = get_context(query, db, number_of_results)
answer = generate(prompt_template.format(query=query, context=context))
return(answer.text)
def chat(message, history):
response = answer_question(message,db, MAX_RESULTS)
history.append((message, response))
return "", history
answer_question(...) 函数接受三个参数:
-
query: 用户的提问 -
db: 向量数据库 -
number_of_results: 从数据库中检索的最大上下文结果数量
然后调用 get_context 函数(在提供的代码中未显示)以检索相关的上下文信息——基于用户的查询和指定的结果数量,从向量数据库中获取。检索到的上下文随后在 prompt_template 字符串中格式化,并传递给 generate 函数——如前几节所述——以获取答案。
函数执行结束时,生成的答案作为字符串返回。
chat(...) 函数接受两个参数:
-
message: 用户的提问 -
history: 表示对话历史的一个列表
然后调用 answer_question() 函数,传入用户的问题、向量数据库(db)和最大结果数量(MAX_RESULTS)。
生成的响应附加到历史列表中,包括用户的问题。函数返回一个空字符串和更新后的历史列表,该列表将用于更新聊天机器人界面。
Gradio 应用程序
定义了辅助函数后,我们现在可以创建 Gradio 接口:
with gr.Blocks() as demo:
gr.Markdown("Fintech Assistant")
chatbot = gr.Chatbot(show_label=False)
message = gr.Textbox(placeholder="Enter your question")
message.submit(chat, [message, chatbot],[message, chatbot] )
demo.launch(debug=True)
这段代码中发生的事情如下:
-
with gr.Blocks() as demo创建一个名为demo的 Gradio 接口块。 -
gr.Markdown(...)在聊天机器人界面中显示一个 Markdown 格式的标题。 -
gr.Chatbot(...)创建一个 Gradio 聊天机器人组件,该组件将显示对话历史。 -
gr.Textbox(...)创建一个文本输入框,用户可以在其中输入问题。 -
message.submit(...)设置一个事件处理器,当用户提交问题时会触发。它调用 chat 函数,传入用户输入(消息)和聊天机器人实例,并使用返回的值更新消息和聊天机器人组件。 -
demo.launch(...)以调试模式启动 Gradio 接口,允许您与聊天机器人交互。
请参阅本章的 GitHub 目录,以获取演示上述所有部分如何组合在一起的完整代码。
摘要
在本章中,你探索了一种集成模式,它结合了 RAG 和生成 AI 模型,以构建一个能够根据文档语料库回答问题的聊天机器人。你已经了解到 RAG 利用了检索系统和生成模型的优势,使系统能够从现有的知识源中检索相关上下文并生成上下文响应,防止幻觉并确保准确性。
我们提出了一种基于谷歌云的无服务器、事件驱动的架构。它包括一个用于接受用户查询的摄取层,一个用于存储嵌入的文档语料库管理层,一个与 Vertex AI 上的谷歌 Gemini 集成的 AI 处理层,以及监控和日志组件。入口点处理各种输入模式,如文本、音频和图像,并根据需要预处理它们。
你已经了解到 RAG 管道的核心涉及从用户查询生成嵌入,在向量数据库上执行向量相似性搜索(在这个例子中,我们使用了 Chroma DB),检索相关上下文,将其格式化为带有指令的提示,并将其提交给 Vertex AI 上的 Gemini 模型。生成的响应可以后处理,用 Markdown 格式化,并使用 Gradio 等工具在用户友好的界面中展示。
现在,你已经获得了关于实现强大的基于 RAG 的聊天机器人系统的宝贵见解。你已经学会了如何结合检索和生成技术,以提供上下文丰富、无幻觉的响应,利用向量数据库通过内容嵌入进行语义搜索。本章为你提供了改进检索结果和通过提示调整定制用户体验的策略。这些技能将使你能够增强你组织提供准确和上下文化响应的能力,有效地利用现有的文档存储库和生成 AI 的力量。
加入我们的 Discord 社区
加入我们社区的 Discord 空间,与作者和其他读者进行讨论:
packt.link/genpat
第九章:操作化生成式 AI 集成模式
在前面的章节中,我们探讨了各种利用生成式 AI(GenAI)模型(如 Vertex AI 上的 Google Gemini)的集成模式。我们讨论了根据目标业务用例开发生产级企业架构。在本章中,我们将深入讨论在将您的生成式 AI 集成作为生产级应用操作时需要考虑的最佳实践。随着我们从概念设计过渡到实际应用,可扩展性、可靠性和可维护性等操作挑战将浮出水面。简而言之,在本章中,我们将涵盖以下主题:
-
操作化生成式 AI 集成模式的介绍
-
适用于生成式 AI 操作的四层框架
-
数据层:
-
数据质量和预处理
-
数据安全和加密
-
数据治理和版本控制
-
监管合规性(例如,GDPR 或 HIPAA)
-
伦理考量与偏差缓解
-
-
训练层:
-
模型适应策略(少样本学习、微调和完整训练)
-
模型治理和政策制定
-
性能指标和监控
-
偏差检测和缓解
-
可解释人工智能(XAI)技术
-
-
推理层:
-
可扩展性和性能优化
-
安全性和访问控制
-
模型部署策略(例如,金丝雀和蓝绿部署)
-
边缘和分布式推理
-
-
运营层:
-
持续集成和持续部署(CI/CD)用于生成式 AI
-
MLOps 最佳实践
-
监控和可观察性:
-
使用“黄金提示”进行评估和监控
-
警报系统
-
分布式跟踪
-
完整的日志记录实践
-
成本优化策略
-
-
-
真实世界的例子:AI 驱动的语言翻译服务
-
在所有四层中实施
-
在示例背景下每个层的具体考量
操作化框架
在生成式 AI 快速发展的领域中,拥有一个结构化的方法来操作您新创建的应用至关重要。我们将探讨的操作框架由四个相互关联的层组成:数据、训练、推理和运营。这些层共同为在应用中有效利用生成式 AI 模型潜力提供了一个全面的蓝图。在以下列表中,我们将简要介绍这四个相互关联的层:
- 数据层:任何成功的生成式 AI 应用的基础在于数据的质量和数量。这一层包括数据速度、整理、提示和训练数据预处理以及整体数据管理。
从训练的角度来看,确保数据的相关性、多样性和对目标领域的代表性至关重要。蒸馏和过滤等技术对于提高训练数据质量起着至关重要的作用。从推理的角度来看,正如前几章所述,了解你的数据速度将帮助你定义最适合你的数据的应用模式:批量处理还是实时处理。
-
训练层:一旦数据准备就绪,训练层就专注于模型训练或微调的复杂过程。这一层包括选择合适的训练架构、超参数调整,并利用迁移学习、少样本学习或自监督学习等前沿训练技术。有效管理资源,包括利用分布式训练和硬件加速,对于优化训练或微调过程至关重要。
-
推理层:在模型训练或微调完成后,推理层开始发挥作用。这一层包括在生产环境中部署和提供 GenAI 模型。可扩展性、延迟和资源优化是关键考虑因素。可以采用高级技术,如模型量化、剪枝和蒸馏,以优化模型性能和内存占用,确保大规模高效推理。
-
操作层:操作层专注于对部署的通用人工智能(GenAI)应用的持续监控、维护和改进。这一层包括模型监控、性能跟踪和模型重新训练流程等任务。强大的日志记录和事件管理流程对于确保应用程序的可靠性和弹性至关重要。此外,这一层还处理诸如模型治理、伦理考虑和法规遵从等关键方面。
通过理解和有效实施这个操作化框架的每一层,组织可以释放通用人工智能应用的全部潜力,推动创新并交付卓越的用户体验。在这些层次之间实现无缝集成和协作是实现成功和可扩展的通用人工智能应用的关键。
这四个层次相互依存。要对模型进行推理,你必须使用精心挑选的数据对其进行训练或微调。下方的图 9.1突出了这些层次之间的关系。
注意,操作层跨越所有层次,为你提供了一个强大的框架来部署企业级应用:
https://github.com/OpenDocCN/freelearn-dl-zh/raw/master/docs/genai-app-intg-ptn/img/B22175_09_01.png
图 9.1:四个生产化层次之间的相互依赖关系
在以下章节中,我们将深入探讨这个生产化框架的四个层次中的每一个。让我们从数据层开始。
数据层
数据层是构建您的通用人工智能系统的基石。这不仅仅是拥有数据;这是关于有效管理数据,以确保信息的质量、安全和道德使用。强大的数据管理流程是不可或缺的。您的通用人工智能系统的好坏取决于它们所交互的数据。例如,如果没有足够的信息背景,大型语言模型(LLMs)可能会产生幻觉,过多的噪声可能导致模型在中间丢失信息,正如文档《迷失在中间:语言模型如何使用长上下文》中所述(arxiv.org/abs/2307.03172)。因此,您需要做出有意识的努力来构建和扩展您的数据管道(RAG 和微调),以提供正确级别的细节和内容,以增强您的通用人工智能模型的能力。
我们将概述在准备您的数据时需要考虑的高级组件:
-
数据质量:实施严格的程序来清理、验证和预处理您的数据。这包括处理缺失值、异常值、不一致性和潜在的偏见。
-
数据安全:保护您的数据免受未经授权的访问和滥用。加密(静态和传输中)、访问控制和定期安全审计是至关重要的。请记住,您的训练数据通常包含需要最高级别保护的秘密信息。
-
数据治理:跟踪您的数据集、模型以及用于生成的提示的变化。版本控制让您能够重现过去的结果,追踪系统的发展,并更有效地解决问题。在处理合规性和审计时,这一点尤为重要。
-
合规性:了解与您的行业和您处理的数据类型相关的法律环境。例如,在通用数据保护条例(GDPR)的情况下,如果您处理的是欧盟公民的数据,您必须遵守关于数据收集、处理和存储的严格规则;或者在医疗保健领域的健康保险可携带性和问责法案(HIPAA),患者数据保护至关重要。
-
道德考量:超越法律条文和不断演变的法规。解决算法偏见、确保公平性以及透明地说明您的通用人工智能系统如何使用数据,对于建立用户信任和避免意外的负面后果至关重要。
-
云数据丢失预防(DLP):这项服务帮助您在 Google Cloud 资源中发现、分类和保护敏感数据。它可以自动删除个人身份信息(PII)或提醒您潜在的数据泄露。
-
云身份和访问管理(IAM):对谁可以访问什么数据进行细粒度控制是必不可少的。IAM 让您可以非常精确地定义角色和权限。
真实世界的例子:第一部分
让我们通过一个例子来探讨一下。想象一下,你正在构建一个用于辅助医生进行诊断的 GenAI 应用程序。你的数据层需要你考虑以下因素:
- 数据质量:仔细清理和去标识患者记录,以移除个人信息同时保留数据的医学相关性。这个过程通常包括消除直接标识符(如姓名和地址)、泛化某些信息(例如将确切年龄转换为年龄范围),并仔细审查自由文本字段中可能存在的识别细节。
目标是在保持数据完整性和有用性的同时,最大限度地降低重新识别的风险。一个例子是将包含姓名、确切年龄和具体位置的详细患者记录转换为去标识化的版本,带有编码的 ID、年龄范围和泛化的地区。
-
数据安全:始终加密患者数据,实施严格的访问控制,并可能使用 Google Cloud 的 DLP 来检测和保护敏感的健康信息。
-
数据治理:遵守 HIPAA 法规,记录所有数据处理活动,并积极解决推理上下文数据中可能存在的偏见,这些偏见可能导致错误的诊断。
训练层
训练层是 GenAI 模型学习如何在客户面前表现的地方,从精选的数据中学习,获取生成有意义输出的所需技能。但这不仅仅是训练;它还涉及到治理、监控、理解和持续改进这些模型。模型治理对于构建可信赖的 AI 是必要的。以下是一些需要考虑的关键策略:
-
明确的政策和指南:建立一个框架,定义模型如何开发、部署、监控和更新。解决公平性、透明度和问责制等伦理问题。记录你的模型选择、超参数调整和数据处理的决策过程。
-
负责任的 AI 实践:实施检测和减轻训练数据和模型输出中潜在偏见的技术的措施。定期评估你的模型对不同用户群体和利益相关者的影响。考虑使用多元化的团队来评估和审计你的模型。
-
人工审核:设计工作流程,允许人工审核人员对模型输出提供反馈和纠正错误,尤其是在医疗或金融等高风险应用中。这有助于你建立一个安全网,并持续改进模型性能。
此外,我们需要将模型视为不是静态的代码片段;它们需要持续的关怀和关注。随着时间的推移,您将看到模型性能的漂移,这是正常的,因为模型在训练时没有看到的新数据现在可用。与传统的机器学习模型相比,LLMs 现在的重大优势是它们在推理时能够非常高效地处理大量信息。这开辟了我们可以用来增强模型性能的新机制,而无需完全重新训练模型:
-
少量样本学习解决了训练每个任务类别仅使用少量示例的 AI 模型的挑战。模型不是记住特定的数据点,而是专注于学习如何识别示例之间的相似性和差异性。这使得它能够根据其从少量信息中“学习学习”的能力,泛化到新的、未见过的类别。这在获取大量标记数据困难或昂贵的情况下特别有用。这种“学习”是在推理时进行的,这意味着您将这些示例添加到提示本身中。
-
微调解决了将预训练语言模型适应特定任务或领域挑战的问题。与在推理时发生的少量样本学习不同,微调涉及在目标数据集上的额外训练。这个过程允许模型调整其参数,并在特定领域专业化,同时不失其广泛的语料库理解。通过教授模型相关的词汇、上下文和细微差别,微调可以显著提高在特定领域任务上的性能,例如医学文本分析或法律文件处理。当您拥有一定数量的特定任务数据,并希望创建一个比通用提示技术表现更佳的更专业化的模型时,这种方法尤其有价值。最近的发展引入了高效的微调方法,如低秩适应(LoRA),通过在每个层中添加小的、可训练的秩分解矩阵来减少可训练参数的数量。其他技术,如前缀调整(在输入前添加可训练参数)、提示调整(优化一组连续的任务特定向量)和 AdapterHub(在现有层之间引入小的、可训练的模块),提供了以最小计算开销适应模型的替代方法。这些方法使 LLMs 的更有效和灵活的适应成为可能,使微调更加易于访问和资源友好。特别是使用这些高效技术,微调在从头开始训练模型这一资源密集型过程和使用通用模型进行专用应用的限制之间找到了平衡。
-
完全训练 LLMs 涉及从头开始训练语言模型或显著修改现有模型的所有层参数的综合过程。这种方法需要大量多样化的文本数据和大量的计算资源,包括高性能的 GPU 或 TPUs。与微调不同,微调是为特定任务调整预训练模型,而完全重新训练旨在创建具有广泛语言理解和生成能力的模型。这种方法允许将新知识、语言或结构变化纳入模型架构。
当开发针对现有大型语言模型(LLMs)中未得到良好代表的语言或领域模型时,或者当旨在减少预训练模型中存在的偏差时,这尤其有用。完全重新训练还允许将新颖的训练技术,如宪法 AI 或高级提示工程方法,纳入训练过程。然而,巨大的计算成本、时间要求以及引入新偏差或错误的可能性使得完全重新训练成为一项具有挑战性的任务,通常由大型科技公司或资源丰富的研究机构承担。
在确定了可用于特定任务训练 LLMs 的选项之后,我们的重点现在转向确保这些模型表现最优并满足我们的期望。这包括:
-
性能指标,对于衡量模型的质量、准确性和效率至关重要。定义和跟踪相关指标,监控模型漂移和意外行为的迹象是至关重要的。为了解决这个问题,考虑实施自动监控系统,这些系统随着时间的推移跟踪关键性能指标,使用 A/B 测试比较模型版本,采用交叉验证和自助法技术评估模型稳定性,对基准数据集进行定期重新评估以检测漂移,以及使用置信度评分来识别模型对其预测不确定的情况。
-
偏差检测,另一个关键方面,可以通过利用公平性指标(如人口统计学对等性和平等机会)来实现,这些指标在训练期间实施对抗性去偏技术,使用后处理方法调整模型输出以实现公平性,使用多样化的测试集进行定期审计,以及采用如反事实公平性等技术来评估和减轻隐藏的偏差。
-
幻觉检测,它解决了 LLMs 产生看似合理但实际上错误的内容的挑战。为了应对这一挑战,考虑实施事实核查算法,这些算法将模型输出与受信任的知识库进行交叉引用,使用集成方法比较多个模型的输出,采用不确定性量化技术,实施人机交互系统用于关键应用,以及使用困惑度分数或其他统计指标来检测异常或可能幻觉的内容。
-
可解释人工智能(XAI)技术,这对于理解模型为何做出特定预测、建立信任和识别潜在问题至关重要。该领域的选项包括实施局部可解释模型无关解释(LIME),它为输入空间中的局部区域创建可解释模型,或者SHapley 加性解释(SHAP),它使用博弈论为特征分配重要性值以进行特征重要性分析,采用注意力可视化技术,使用反事实解释,实施概念激活向量以理解模型学习的高级概念,以及使用层级相关性传播来追踪每个输入对最终预测的贡献。
真实世界的例子:第二部分
为了说明我们讨论的概念的实际应用,让我们考虑一个旨在处理客户咨询的 GenAI 聊天机器人。这个例子展示了模型训练、治理、监控和改进的各个方面如何在现实世界的应用中结合起来:
-
模型适应策略:为了使我们的客户服务聊天机器人保持有效并保持相关性,考虑将模型适应于新信息或变化的需求至关重要。为此,我们需要根据企业特定的需求和预期变化性质选择最合适的方法。在这里,我们探讨了三种主要策略——少样本学习、微调和全面训练——每种策略都适用于不同的模型适应场景:
-
少样本学习:这种方法非常适合快速适应新的客户咨询类型或产品更新。例如,如果你的公司推出了一款新产品,你可以在提示中为聊天机器人提供一些与产品相关的问题和答案的示例。然后,聊天机器人可以从这些示例中推广,以处理关于新产品的更广泛范围的查询。这种方法快速,不需要任何模型重新训练,因此适合快速响应不断变化的企业需求。然而,对于更复杂或细微的变化,其有效性可能有限。具体的局限性包括难以处理需要深层上下文的问题,不同类型问题的表现不一致,随着主题的增加存在可扩展性问题,可能过度拟合提供的示例,以及无法保留先前交互中的信息。
-
微调:当您有大量新数据或需要将聊天机器人适应到客户服务模式的重要转变时,微调成为一种有价值的选项。例如,如果您的公司进入了一个具有不同文化规范和客户期望的新市场,您可以在特定于该市场的交互数据集上微调聊天机器人。这允许模型调整其语言使用和响应风格,同时保留其一般知识。考虑使用高效的微调方法,如 LoRA,以减少计算需求。
-
全面训练:对于预存聊天机器人来说,全面训练可能不太常见,但如果公司对客户服务的方法有根本性的转变,或者原始模型被发现存在重大限制或偏见,则可能考虑全面训练。例如,如果公司决定完全改造其产品线并改变客户互动方式,或者如果它希望从头开始构建一个与独特品牌声音和价值观深度一致的聊天机器人,全面训练可能是最佳方法。这种方法允许从底层整合公司特定的知识和互动风格,但需要大量的计算资源和高质量的大型数据集。
-
在实践中,这些方法的组合通常会产生最佳结果。您可能使用少量样本学习进行日常适应,安排定期的微调会议(例如,每月或每季度一次)以整合积累的新数据,并保留全面训练用于重大改造。通过战略性地运用这些不同的适应方法,您可以确保您的客户服务聊天机器人保持最新、有效,并与您的业务目标保持一致,同时高效地管理计算资源。
一旦我们选择了并实施了最合适的适应策略,我们将确保这些变化有效地整合到聊天机器人的持续运营中,如下所述:
-
模型治理:为聊天机器人的运营建立一个全面的框架。这包括定义语气指南,确保其与品牌身份和客户期望保持一致。制定一套明确的可接受响应,并为需要人工干预的复杂查询创建升级程序。定期审查对话记录,以确保遵守道德标准并保持高客户满意度。记录模型选择、超参数调整和数据处理的决策过程。在聊天机器人的交互中解决公平性、透明度和问责制等道德问题。考虑使用多元化的团队来评估和审计模型,确保在治理过程中考虑广泛的视角。
-
模型监控:实施一个强大的系统来跟踪关键性能指标。这包括响应准确性(聊天机器人提供正确和有用信息的频率)、解决时间(客户查询解决的快速程度)和客户情绪(通过后交互调查或客户响应的情感分析来衡量)。利用像 Vertex AI 模型监控这样的工具来检测用户行为或数据模式的变化,这些变化可能会影响聊天机器人的性能。实施自动监控系统以跟踪这些关键性能指标随时间的变化。使用 A/B 测试比较聊天机器人的不同版本并检测性能变化。采用交叉验证和自助抽样技术来评估模型稳定性。在基准数据集上实施定期再评估,以检测性能或意外行为的漂移。
-
偏差检测与缓解:定期评估聊天机器人针对不同用户群体的性能,以确保公平和均衡的服务。利用公平性指标,如人口统计学上的平等和均等机会。在训练期间实施对抗性去偏技术以减少固有偏差。使用后处理方法调整模型输出以实现公平。使用多样化的测试集进行定期审计,以识别响应或处理不同客户群体中可能存在的偏差。
-
幻觉检测:实施交叉验证聊天机器人响应与公司政策及产品信息可信知识库的事实核查算法。使用集成方法比较多个模型版本的输出。采用不确定性量化技术标记模型可能不太自信的响应。在关键查询或检测到潜在幻觉时实施人机交互系统。使用困惑度分数或其他统计指标来识别聊天机器人响应中的异常或不正确内容。
-
可解释人工智能(XAI):实施理解并解释聊天机器人决策过程的技术。使用 LIME 或 SHAP 进行特征重要性分析,以了解哪些客户查询的部分对生成响应最有影响力。采用注意力可视化技术来查看模型关注的单词或短语。使用反事实解释来了解不同输入如何改变聊天机器人的响应。这不仅有助于调试,还有助于培训客户服务代表与 AI 系统协同工作。
-
模型更新与持续学习:为聊天机器人对新客户交互和反馈进行训练建立定期计划。这使它的知识库保持最新,并提高其处理多样化查询的能力。
利用少量学习技术快速适应新的客户查询类型或产品更新,而无需全面重新训练。考虑定期对最近的高质量交互进行微调,以保持最佳性能。实施一个反馈循环,让客户服务代表可以标记不正确或次优的响应,为未来的改进提供宝贵的数据。
通过投资模型管理、监控和持续改进的这些方面,你将构建一个不仅强大而且负责任、可靠,并能适应客户和业务不断变化需求的 GenAI 聊天机器人。这种全面的方法确保你的 AI 驱动的客户服务解决方案始终是你客户参与策略中宝贵、值得信赖和有效的工具。
推理层
推理层是 GenAI 模型变得生动的地方,它将输入数据实时转换为有意义的输出。这一层对于向最终用户提供价值并将 AI 能力集成到你的应用程序和业务流程中至关重要。然而,大规模部署和管理 GenAI 模型带来了独特的挑战,需要仔细考虑和规划:
-
可扩展性和性能优化:在设计你的 GenAI 系统时,要考虑到可扩展性,利用云提供商提供的无服务器和自动扩展功能。这确保了你的基础设施可以动态调整以适应不同的工作负载,在优化成本的同时保持性能。实施负载测试和容量规划流程,以确保你的系统可以处理预期的流量模式和需求激增。这种主动方法有助于防止中断并保持无缝的用户体验。为了进一步优化资源利用并有效管理成本,探索请求批处理、缓存和负载削减等技术。请求批处理可以通过一起处理多个请求来显著提高吞吐量,而缓存频繁访问的结果可以减少不必要的模型调用。负载削减机制可以在极端流量激增期间优雅地降低服务级别,确保关键功能保持运行。考虑实施排队和缓冲机制来处理流量激增,防止你的 GenAI 模型或下游组件过载。这种方法有助于平滑不规则的流量模式并确保一致的性能。此外,采用模型量化精简等技术来降低模型的计算需求,同时不会显著影响其准确性。
-
安全与访问控制:实施强大的安全措施以保护您的生成人工智能系统免受未经授权的访问、数据泄露和其他安全威胁。鉴于人工智能模型处理数据的敏感性,这一点尤为重要。利用云平台提供的身份和访问管理(IAM)功能来控制对您的生成人工智能资源的访问并强制执行最小权限原则。这确保用户和系统只有执行其所需任务所需的权限。实施安全的通信渠道和加密机制以保护数据在传输和静止状态下的安全。这包括对所有 API 端点使用 HTTPS、加密存储在数据库或文件系统中的数据,以及实施适当的关键管理实践。定期审查和更新您的安全政策和程序以应对新兴的威胁和漏洞。这可能涉及定期进行安全审计、执行渗透测试,并了解人工智能领域的最新安全最佳实践。
-
监控和可观察性:实施全面的监控和可观察性解决方案,以获得对您的生成人工智能系统性能、健康和用法模式的实时洞察。这包括跟踪关键指标,如推理延迟、吞吐量、错误率和资源利用率。使用分布式跟踪来了解请求通过您系统的流程,并识别瓶颈或不效率。设置警报机制,以便及时通知您的团队任何异常或性能问题。这允许在潜在问题影响最终用户之前快速响应和缓解。考虑在您的推理层中实施 A/B 测试功能,以比较不同模型版本或配置在实际场景中的性能。
-
合规与治理:确保您的推理层遵守相关的监管要求和行业标准。这可能包括实施数据保留政策、维护模型预测的审计日志,以及提供人工智能决策过程中的可解释性和透明度机制。制定清晰的模型部署、版本控制和回滚的政策和程序。这有助于保持您人工智能服务的连贯性和可靠性,同时允许快速迭代和改进。实施强大的持续集成/持续部署(CI/CD)管道,包括自动化测试、安全扫描和性能基准测试,以确保只有高质量的、安全的模型版本被部署到生产环境中。
-
边缘和分布式推理:考虑在低延迟或离线操作至关重要的场景中实施边缘推理能力。这可能涉及将您的模型优化版本部署到边缘设备或实施混合云-边缘架构。探索联邦学习和分割推理等技术,以在分布式人工智能系统中平衡隐私、性能和资源限制。
通过在您的推理层全面解决这些方面,您将构建出不仅强大且高效,而且安全、可扩展和可靠的生成人工智能系统。这种全面的方法确保了您的 AI 解决方案能够为用户提供持续的价值,同时适应 AI 动态领域不断变化的需求和新兴挑战。
真实世界的例子:第三部分
让我们来看一个例子,您的公司部署了一个先进的 AI 驱动的语言翻译服务,该服务旨在提供跨多种语言的实时、高质量翻译,适用于文本、语音和视频内容。这项基于云的服务面向多样化的用户群体,包括企业、政府机构和全球个人,其使用模式在一天中以及不同地区之间差异很大。
该服务部署在具有自动扩展能力的无服务器架构的云平台上,以确保可扩展性和优化性能。这种基础设施允许系统在需求高峰期自动扩展,例如重大国际事件期间,通过按需启动额外的推理实例。对于文本翻译,实现了请求批处理,通过单个模型推理处理多个短翻译以提高吞吐量。频繁请求的翻译被缓存以减少模型调用。对于视频翻译,一个排队系统管理大型翻译作业,确保公平的资源分配并防止系统过载。在需要超低延迟的场景中,可以直接将优化模型部署到边缘设备,实现离线翻译功能。
安全性和访问控制是该服务设计的基本要素。所有 API 请求都需要强大的身份验证,不同用户层级有不同的访问级别。通过加密确保数据保护,无论是在传输中还是在静止状态下。基于角色的访问控制(RBAC)允许企业客户精细管理用户权限。一个专门的安全运营中心监控异常模式或潜在的入侵尝试,使用 AI 驱动的异常检测系统来维护强大的安全性。
已实施全面的监控和可观察性系统,以维护服务的性能和可靠性。运维团队使用定制的仪表板显示关键指标,如翻译延迟、准确度评分以及不同语言对和内容类型中的资源利用率。分布式跟踪允许对每个翻译请求进行端到端跟踪,从而快速识别瓶颈或错误。通过 A/B 测试,新模型版本逐步推出,性能始终与当前生产模型进行比较。为各种阈值设置了自动警报,以确保对任何问题都能及时关注。
合规性和治理是该服务运营的核心。实施了严格的数据保留政策,以符合隐私法规,翻译后的用户内容在未明确要求保留的情况下将自动删除。为了合规和计费目的,维护了详细的翻译日志(仅包含元数据,不包含内容)。一个严格的审批流程管理着新模型版本的部署,包括对准确性、偏差和性能的自动化测试。一个可解释性功能可用,突出显示哪些输入部分对翻译输出影响最大,增强了透明度和信任。
该服务的架构集成了边缘和分布式推理能力。为满足对数据主权要求严格的客户,提供本地化解决方案。轻量级版本作为 SDK 提供给移动应用开发者,即使在离线状态下也能提供基本的翻译功能。为了提高罕见语言或特定领域的翻译质量,实施了一个联邦学习系统,允许模型从用户更正中学习,而无需集中收集敏感数据。
该服务保持了一个持续改进的周期。每日自动脚本来分析性能指标和用户反馈。每周对汇总的性能数据进行审查,优先改进最常用的语言对和内容类型。每月进行 A/B 测试以更新模型,成功的改进逐步推出。每季度进行全面的网络安全审计和渗透测试,确保系统对不断发展的威胁保持稳健。
这种多方面的推理层方法确保了 AI 翻译服务始终保持高度可用性和性能,能够处理全球规模,并实现一致的低延迟翻译。该服务安全合规,满足企业客户和监管机构的高要求。它还具有可观察性和适应性,能够快速识别和解决问题,以及持续改进。凭借其边缘能力和分布式学习,该服务能够适应不断变化的市场需求和科技进步,使其成为自然语言处理动态领域中的一个灵活且未来证明的解决方案。
运营层
运营层构成了一个强大且高效的通用人工智能(GenAI)系统的骨架,确保其平稳运行、可靠性和成本效益。这一层包括使 AI 模型在生产环境中持续改进、监控和优化的关键流程和工具。
通过关注 CI/CD 和 MLOps、监控和可观察性以及成本优化,操作层弥合了开发和生产之间的差距,使组织能够在适应不断变化的需求的同时,有效地管理资源并保持高性能 AI 系统。精心设计的操作层对于扩展 AI 解决方案、确保其可靠性和最大化 GenAI 技术的投资回报至关重要。该层的核心是 CI/CD 管道,它简化了集成新代码和无缝部署更新模型的过程。让我们更详细地看看这一点。
CI/CD 和 MLOps
采用 DevOps 原则和实施 CI/CD 管道对于简化 GenAI 系统的开发、测试和部署至关重要。这种方法确保了对 AI 模型、支持基础设施和应用代码的更改得到有效且可靠的集成、测试和部署。通过利用 Cloud Build、Artifact Registry 和 Cloud Deploy 等工具,组织可以自动化构建、测试和部署过程,显著减少人为错误并加速新功能和改进的交付。为了最大限度地提高 GenAI 系统的效率和可靠性,应在 CI/CD 和 MLOps 中实施几个关键实践:
-
健壮的 CI/CD 管道:GenAI 系统应包括涵盖单元测试、集成测试和端到端测试的自动化测试框架。单元测试关注系统的单个组件,如特定函数或模块。集成测试验证系统的不同部分是否正确协同工作,而端到端测试模拟实际使用场景,以确保整个系统按预期运行。这些全面的测试策略对于维护 GenAI 系统的可靠性和正确性至关重要,尤其是在 AI 模型行为复杂且往往不可预测的情况下。
-
模型部署:为了最小化停机时间并降低引入破坏性变更的风险,组织应考虑实施高级部署策略,例如金丝雀部署和蓝绿部署。金丝雀部署涉及在向整个系统推出之前,先将新版本发布给一小部分用户或服务器,以便进行实际测试,并在发现问题后轻松回滚。蓝绿部署维护两个相同的生产环境,在它们之间切换以发布,这可以实现即时回滚和零停机时间更新。组织还应考虑实施功能标志,以便对新功能或模型版本的推出进行精细控制。
-
版本控制:公司应实施通用人工智能系统所有方面的版本控制,包括模型版本、训练数据、超参数和应用代码。这使可追溯性和可重复性成为调试、审计和合规性的基本要求。
-
模型监控和重新训练管道:这些管道应自动跟踪模型性能指标,检测数据分布或模型准确性的漂移,并在必要时触发重新训练过程。这确保了人工智能模型随着时间的推移保持准确性和相关性,适应不断变化的数据模式和用户行为。
-
数据版本控制和血缘追踪:通过维护每个模型版本所使用数据的清晰记录,组织可以确保可重复性和便于调试模型行为。这在模型决策可能需要审计或解释的监管行业中尤为重要。
最后,组织应专注于在数据科学家、机器学习工程师和运维团队之间营造一种协作文化。这包括建立清晰的沟通渠道、对整个机器学习生命周期的共同责任,以及持续的知识共享。对事故和成功部署的定期事后分析可以帮助团队识别改进领域,并随着时间的推移完善他们的 MLOps 实践。
通过实施这些全面的 CI/CD 和 MLOps 实践,组织可以显著提高其通用人工智能系统的可靠性、效率和有效性。这种方法不仅加快了开发和部署周期,还确保了在数据和使用需求不断变化的情况下,人工智能模型保持准确性、安全性和与业务目标的一致性。
监控和可观测性
在通用人工智能系统快速发展的领域中,保持对模型性能和行为的清晰视图至关重要。监控和可观测性为您提供了对 AI 运营的视角,提供了关于系统健康、性能指标和潜在问题的关键见解。本节深入探讨了确保您的通用人工智能模型以最高效率运行的关键组件,同时允许快速识别和解决问题。我们将探讨评估和监控技术以跟踪模型性能,警报系统以及时通知异常,分布式跟踪以理解复杂的系统交互,以及全面的日志记录实践以维护系统行为的详细记录。这些元素共同构成了一个强大的框架,用于维护对通用人工智能系统的监督,使主动管理和持续改进成为可能。
评估和监控
确保与生成式人工智能能力集成的应用程序可靠且高效地运行至关重要。全面的监控和可观察性解决方案在实现这一目标中发挥着关键作用,为这些系统的性能、健康和可靠性提供宝贵的见解。通过利用 Google Cloud 强大的监控和可观察性工具,如 Cloud Monitoring、Cloud Logging 和 Cloud Operations,组织可以实时了解其生成式人工智能系统的内部运作。
下面是关于建立监控结果和检测模型更新引入的变化的机制的扩展叙述,包括仪表化、自动批量处理以及利用大型语言模型或其他技术的细节。
监控生成式人工智能系统的一个基本方面是建立一种稳健的机制来监控结果并检测模型更新引入的变化。这种积极主动的方法可以帮助组织提前发现潜在问题,并确保其生成式人工智能系统的持续可靠性和准确性。
这一监控机制的核心是“黄金提示”的概念——精心设计的提示,代表生成式人工智能系统的典型用例或场景。这些提示应与主题专家和利益相关者合作设计,确保它们涵盖多样化的背景、复杂性和预期行为。
为了使这一监控过程得以实施,组织可以利用自动批量处理技术。通过设置计划任务或工作流程,这些黄金提示可以定期和系统地提交给生成式人工智能模型,并将产生的输出捕获和分析,以检测任何偏差或异常。
通过利用评分者大型语言模型或其他自动评估和评分技术,这种分析可以进一步得到增强。评分者大型语言模型可以被微调以评估生成式人工智能模型生成的响应的质量、连贯性和正确性,从而提供性能的定量衡量,并标记任何与预期输出显著偏离的情况。
或者,组织可以采用其他评估技术,例如利用人工评分者或众包平台手动评估生成式人工智能模型输出的质量。虽然这种方法资源消耗更大,但它可以提供宝贵的见解,并从人类视角了解模型的表现。
一个有趣的方法是由Chatbot Arena平台(见论文arxiv.org/html/2403.04132v1)实施的,该方法引入了一种基于人类偏好的评估 LLM 的新方法。与依赖于静态数据集和事实评估的传统基准不同,Chatbot Arena 利用了众包的成对比较方法。这种方法旨在通过直接将用户偏好纳入现实世界的开放性任务中,捕捉 LLM 的细微和多样化的方面。
Chatbot Arena 的核心是一个交互式网站,用户可以在该网站上提交问题并从两个匿名的 LLM(大型语言模型)那里获得回应。在审查回应后,用户会对提供最佳答案的模型进行投票。这一投票过程是匿名的且随机的,确保了无偏见的评估环境。通过收集来自不同用户群体的成对比较,Chatbot Arena 可以收集丰富的用户提示和人类偏好的数据集,准确反映现实世界 LLM 的应用。
为了根据众包数据可靠地排名 LLM,Chatbot Arena 采用了一套强大的统计技术。这包括 Bradley-Terry 模型和 Vovk 和 Wang 提出的 E-values,使平台能够尽可能可靠和高效地估计模型排名。此外,该平台还结合了专门设计的有效采样算法,以加速排名的收敛同时保持统计有效性。
监控机制还应包含全面的日志记录和审计功能,不仅记录提示、回应和评估分数,还包括元数据,如模型版本、输入数据源以及其他任何相关的上下文信息。这些数据对于根本原因分析、调试以及维护 GenAI 系统性能的全面审计记录至关重要。
此外,组织可以将此监控机制与其现有的警报和通知系统集成,确保任何重大的偏差或异常都能及时标记并传达给适当的团队进行调查和补救。
通过建立一个利用黄金提示、自动化批量处理和高级评估技术(如评分 LLM 或人类评分员)的强大监控机制,组织可以领先于由模型更新引入的潜在问题。这种主动方法不仅增强了 GenAI 系统的可靠性和准确性,而且增强了利益相关者和最终用户的信心,因为他们可以确信系统的性能是持续监控的,任何偏差都会得到及时解决。
警报
在此背景下,警报机制是必不可少的,它可以使相关团队在出现任何问题或异常时得到通知。这些警报可以根据预定义的阈值或条件进行配置,例如错误率、延迟或资源利用率的突然激增。通知可以通过各种渠道发送,包括电子邮件、消息平台或专门的故障管理工具,确保适当的团队能够及时得到通知并采取措施减轻问题。
分布式追踪
分布式追踪是另一种强大的技术,可以帮助监控和调试生成式人工智能(GenAI)系统。通过在应用程序中应用遥测数据,组织可以追踪请求在系统不同组件中流动的路径。这种端到端的可见性在诊断性能问题、识别瓶颈或调试复杂、分布式系统中的错误时非常有价值。在生成式人工智能(GenAI)的背景下,分布式追踪变得尤为重要,因为 AI 管道通常具有复杂和相互关联的特性。它允许团队:
-
可视化请求流程:追踪提供了请求如何通过各种服务、API 和参与 AI 推理或训练过程的微服务传播的清晰图景。
-
识别延迟问题:通过分解每个组件花费的时间,追踪有助于确定延迟发生的位置,无论是在数据预处理、模型推理还是后处理步骤中。
-
检测异常:在追踪数据中的异常模式可以突出显示潜在问题,在它们升级为重大问题之前,从而实现主动的系统管理。
-
优化资源分配:了解不同组件的资源消耗有助于微调资源分配并提高整体系统效率。
-
调试复杂场景:在涉及多个 AI 模型或复杂决策树的场景中,追踪有助于了解请求的精确路径以及每一步所做的决策。
-
确保数据可追溯性:追踪可以追踪数据在系统中的流动,确保符合数据治理政策,并有助于审计。
通过利用分布式追踪,组织可以更深入地了解其生成式人工智能(GenAI)系统的行为,从而实现更稳健、高效和可靠的 AI 应用程序。
记录日志
应用程序性能管理(APM)工具,如云操作和云追踪,可以提供有关应用程序指标的具体见解。它们还可以请求追踪和日志记录,从而快速识别和解决性能问题、优化资源利用并确保无缝的用户体验。
完善的日志记录实践对于从 GenAI 系统中捕获和分析相关信息也是必不可少的。通过配置应用程序记录重要事件、错误和诊断信息,并利用云日志等日志管理工具,组织可以集中和分析这些日志,识别模式,追踪问题,并深入了解其 GenAI 系统的行为。
定期审查和分析从 GenAI 系统收集的监控数据可以揭示趋势、模式和潜在的优化或改进领域。通过利用这些信息,组织可以微调其系统,提高性能,并提升用户体验。
实施异常检测机制也有助于自动识别和标记 GenAI 系统中的意外或异常行为。这些机制可以利用机器学习技术分析历史数据,建立基线,并检测与正常模式偏差,使组织能够采取适当的行动。
最后,建立稳健的事件管理和响应流程对于确保任何问题或事件都能得到及时有效的处理至关重要。明确角色和责任、沟通渠道以及升级程序可以促进对可能发生的任何事件的协调和高效响应。
成本优化
在通用人工智能(GenAI)系统的领域,平衡性能与成本效益对于可持续运营至关重要。在谷歌云等云平台上运行这些复杂的 AI 系统时,实施稳健的成本优化策略对于管理运营费用至关重要。
组织应利用云提供商提供的各种成本节约机制。承诺使用折扣可以通过承诺在指定期限内使用一定数量的资源来显著降低可预测工作负载的成本。这些承诺可以在基础设施层或通过管理服务批量折扣进行。此外,探索像预占虚拟机(preemptible VMs)这样的选项,用于容错工作负载,或探索像按需虚拟机(spot VMs)这样的选项,用于灵活且可中断的任务,可以带来实质性的节省。
实施全面的成本监控和归因机制对于了解云支出至关重要。这些工具允许组织跟踪不同项目、团队和服务的费用,帮助识别高支出领域和优化机会。云成本管理平台可以提供详细的支出细分、预测能力和对使用或成本异常波动的警报。通过将成本归因于特定功能或模型,团队可以做出关于资源分配的明智决策,并优先考虑在最能产生影响的领域进行优化。
自动扩展和自动关闭机制在优化资源利用和降低低流量期间的成本方面发挥着至关重要的作用。通过根据需求自动调整计算实例的数量,自动扩展确保系统在较安静时期不会过度配置的情况下能够处理峰值负载。在非工作时间实施开发测试环境的自动关闭可以带来显著节省,而不会影响生产力。
优化数据存储和传输成本是管理生成式人工智能系统费用的另一个关键方面。这可能涉及实施分层存储解决方案,有效使用缓存,以及优化数据传输模式以最小化出口费用。对于大规模人工智能训练任务,考虑使用自动优化成本效益的托管服务,例如谷歌云的 Vertex AI,它可以根据工作要求动态调整资源分配。
最后,考虑架构决策的长期成本影响。虽然无服务器架构在每请求的基础上可能看起来更昂贵,但它们通常可以通过消除对持续基础设施管理的需求并允许真正的按使用付费定价来降低总成本。同样,投资于模型优化技术,如量化或蒸馏,虽然可能需要前期开发努力,但可以从长远降低推理成本。
通过解决这些关键考虑因素,并在所有这些层(数据、训练、推理和操作)中实施最佳实践,您可以成功实施您的生成式人工智能集成模式,确保在生产环境中具有可靠性、可扩展性和可维护性。此外,建立稳健的数据管理、模型治理和安全实践将帮助您建立信任并遵守相关法规和行业标准。
摘要
在本章中,您已经探索了一个全面框架,用于实施生成式人工智能集成模式。您了解了一个四层方法,该方法解决了部署和维护生产级生成式人工智能应用程序的复杂性,包括数据、训练、推理和操作层。
我们提出了一种全面战略,强调数据质量、安全和治理在数据层的重要性,同时解决法规遵从性和伦理考量。训练层向您介绍了各种模型适应技术,包括少样本学习、微调和全训练,以及模型治理、性能监控和可解释人工智能的关键方面。
你已经了解到推理层专注于可扩展性、性能优化和安全的部署策略,包括边缘和分布式推理能力。关于操作层的章节强调了实施稳健的持续集成/持续部署(CI/CD)管道、MLOps 最佳实践以及全面监控和可观察性系统对于通用人工智能应用程序的重要性。
到本章结束时,你已经对操作通用人工智能系统的复杂性有了宝贵的见解。你学习了如何在确保可扩展性和可靠性的同时,平衡性能、成本效益和伦理考量。本章为你提供了实施黄金提示评估、分布式跟踪和成本优化技术的策略。这些技能将使你能够提高组织部署和维护复杂通用人工智能应用程序的能力,有效地利用云基础设施和人工智能操作的最佳实践。
在下一章中,我们将讨论负责任的 AI 及其在将通用人工智能(GenAI)集成到您的应用程序时的影响。
加入我们的 Discord 社区
加入我们社区的 Discord 空间,与作者和其他读者进行讨论:
packt.link/genpat
第十章:将负责任的人工智能嵌入您的生成式人工智能应用
在前面的章节中,我们探讨了在 Vertex AI 上利用像谷歌 Gemini 这样的生成式人工智能(GenAI)模型的各种集成模式和操作考虑因素。随着我们实施这些强大的技术,解决与构建和部署将被添加到您的应用程序中的 AI 模型相关的伦理影响和责任至关重要。本章将重点介绍负责任人工智能的最佳实践,确保我们的生成式人工智能应用是公平的、可解释的、私密的和安全的。
在本章中,我们将涵盖:
-
负责任的人工智能简介
-
生成式人工智能应用中的公平性
-
可解释性和可解释性
-
隐私和数据保护
-
生成式人工智能系统中的安全和安保
-
谷歌对负责任人工智能的方法
-
Anthropic 对负责任人工智能的方法
负责任的人工智能简介
负责任的人工智能是一种开发和应用人工智能系统的方法,它优先考虑伦理考量、透明度和问责制。
随着生成式人工智能模型以及像谷歌的 Gemini、OpenAI 的 GPT 和 Anthropic 的 Claude 这样的应用变得越来越强大和广泛使用,确保这些系统以造福社会并最大限度地减少潜在危害的方式进行设计和实施变得至关重要。让我们从高层次上探讨在您的系统中实施负责任人工智能的关键方面。我们还将讨论过度关注以下主题可能对创新产生的负面影响:
-
公平性:在人工智能系统中实现公平是一个至关重要的目标,它需要在人工智能生命周期的整个过程中进行深思熟虑的设计和实施。几个关键因素有助于使人工智能系统公平。首先和最重要的是训练数据的质量和多样性。确保数据集代表广泛的群体、经验和观点有助于最小化偏见并促进公平的结果。这不仅仅涉及收集多样化的数据,还包括精心策划和平衡数据,以避免某些群体的过度或不足代表,确保人工智能系统不会持续或放大偏见。虽然追求公平至关重要,但实施起来很复杂。不同的公平定义可能相互冲突。例如,实现人口统计学上的平等可能并不总是与平等机会相一致。过度补偿历史偏见可能会产生新的歧视形式。例如,一个人工智能招聘系统可能会过于关注人口统计学上的平等,以至于忽视了真正的资格,这可能导致更有能力的候选人被忽视。
-
可解释性:这是关于理解人工智能系统如何做出决策。高度可解释的模型可能会为了可解释性而牺牲性能。这种权衡在医疗诊断或金融预测等需要复杂模式进行准确预测的领域可能特别有问题。
-
隐私:这涉及到保护用户数据和尊重隐私权利。严格的隐私措施可能会阻碍有益的数据共享和协作研究。它们也可能增加企业的成本,可能抑制无法承担强大隐私保护措施的小公司的创新。例如,过于严格的数据保护可能会阻止创建用于开发罕见病治疗所需的大型、多样化的数据集。
-
安全性:这是确保人工智能系统按预期行为并不会造成伤害的地方。严格的安全测试可能会显著减缓人工智能系统的发展和部署。这可能会延迟具有潜在救命技术的引入。此外,过于谨慎的方法可能会导致错过从受控的、现实世界的测试中学习的机会。
-
问责制:这是关于对人工智能系统结果承担责任。清晰的问责制界限是必要的;过于严厉的措施可能会阻碍创新。它还可能导致当问题出现时,形成一种归咎于而不是学习和改进的文化。
没有获得所有这些方面正确的秘密配方。公司需要找到平衡,并在实践中解决这些关注。让我们考虑以下方法来最小化对僵化方法过度依赖的担忧:
-
情境应用:认识到每个方面的重要性可能因具体的人工智能应用及其潜在影响而异。例如,可解释性在医疗诊断人工智能中可能比在电影推荐系统中更为关键。
-
利益相关者参与:在开发和部署过程中涉及多样化的利益相关者。这有助于早期识别潜在的问题和权衡。采用基于风险的策略,其中审查和保障措施的水平与人工智能系统的潜在危害或影响成比例。
-
透明度和监控:公开你的人工智能系统的局限性和权衡。这有助于管理期望并建立信任。定期评估人工智能系统在实际应用中的性能和影响,并准备好进行调整。逐步实施这些原则,从最低可行标准开始,并根据现实世界的反馈和结果逐步改进。
-
监管合作:与政策制定者合作,制定鼓励负责任创新而不是抑制创新的法规。投资于教育开发者和用户了解这些原则及其影响。
通过采取细致入微、具体情境的方法,并持续重新评估这些原则之间的平衡,我们可以努力最大化人工智能的益处,同时最小化潜在的危害。
通用人工智能应用中的公平性
随着这些技术越来越多地融入社会各个领域的决策过程,人工智能系统中的公平性是一个关键问题。确保人工智能系统不会持续或放大现有偏差对于建立信任、促进平等和最大化人工智能对所有人的利益至关重要。然而,实现人工智能的公平性是一个复杂且多方面的挑战,需要持续的努力和警惕。
这涉及到人工智能生命周期的每个阶段,从数据收集和模型开发到部署和监控。以下要点概述了促进人工智能系统公平性的关键策略和考虑因素,重点关注实际方法和现实世界案例。通过实施这些做法,组织可以朝着创建更公平、更透明且对整个社会有益的人工智能系统迈进。
-
多样性和代表性数据:确保多样性和代表性数据对于创建公平的人工智能系统至关重要。这不仅包括包括来自各个人口群体的数据,还要考虑交叉性和不太明显的多样性形式。例如,在开发语音识别系统时,确保训练数据包括来自不同年龄组和性别的各种口音和方言的说话者。例如,当苹果公司的早期版本 Siri 在处理苏格兰口音时遇到困难时,受到了批评,这突显了在训练数据中语言多样性的重要性。
-
偏差检测和缓解:这包括主动和被动措施。主动地,使用统计技术来识别数据和中模型输出中的潜在偏差。被动地,实施反馈机制来捕捉和纠正现实世界使用中出现的偏差。例如,考虑一个在技术行业中针对特定人口或性别表现出偏差的人工智能招聘工具。这可能是因为系统在历史招聘数据上进行了训练,这些数据反映了技术行业过去在性别或人口结构上的偏差。这个案例突显了仔细审查训练数据和模型输出以发现不公平模式的重要性。
-
定期审计:公平性审计应该是全面的,不仅要检查模型的输出,还要检查其在现实世界中的影响。这可能涉及定量指标和定性评估。例如,信用评分人工智能可能通过初步的公平性测试,但定期的审计可能会揭示,由于经济条件的变化,它无意中在一段时间内对某些群体造成了不利影响。定期的审计将捕捉到这种漂移,并允许及时纠正。
-
包容性设计:包容性设计不仅限于咨询多样化的利益相关者。它涉及赋予他们积极塑造发展过程的能力,并在决策中给予他们的意见实际权重。例如,当微软为有限活动能力的游戏玩家开发 Xbox 自适应控制器时,他们让有残疾的游戏玩家参与了整个设计过程。这种包容性方法导致了可能被没有残疾生活经验的开发者忽视的创新。
-
情境公平性:在不同的情境中,公平可能意味着不同的事情。在一个情况下公平的事情可能在另一个情况下就不公平。人工智能系统需要足够灵活,以适应这些细微差别。例如,用于大学录取的人工智能系统可能需要平衡多个公平标准——平等机会、人口比例和个体优势。适当的平衡可能在有多样化代表性使命的公立大学和专门的技术学院之间有所不同。
-
透明度和可说明性:为了使人工智能系统真正公平,用户应该了解决策是如何做出的。这既涉及技术可说明性,也涉及与非技术利益相关者的清晰沟通。在医疗保健领域,做出治疗建议的人工智能系统应该能够用医生和患者都能理解的方式解释其推理。这允许知情同意,并为患者提供机会,让他们提供人工智能可能错过的额外背景信息。
-
持续监控和调整:公平不是一次性的成就,而是一个持续的过程。社会规范和对公平的理解不断发展,人工智能系统需要相应地进行调整。例如,用于社交媒体平台的内容审核的人工智能系统可能需要持续更新其对仇恨言论和歧视性语言的理解,因为社会规范在演变,新的编码语言形式出现。
-
法律和伦理合规性:确保公平措施符合相关法律(如反歧视立法)并符合伦理标准。这可能因司法管辖区和应用领域而异。在欧盟,GDPR 和拟议中的 AI 法案对人工智能系统中的公平性和非歧视性设定了具体要求。在欧盟市场运营或向欧盟市场销售的公司需要确保其人工智能系统符合这些规定。
这些扩展点突出了确保人工智能系统公平性所涉及的复杂性和细微差别。这是一个持续性的挑战,需要警觉性、适应性和对伦理原则的承诺。
可解释性和可说明性
在人工智能系统中,尤其是在大型语言模型(LLMs)和 GenAI 中,可解释性和可解释性对于建立信任、实现有效监督和确保负责任部署至关重要。随着这些系统变得更加复杂,其决策过程更加不透明,理解和解释其输出的方法的需求日益增长。可解释性允许利益相关者窥视人工智能的“黑箱”,而可解释性则侧重于以人类可以理解的方式传达决策是如何做出的。
以下要点概述了增强人工智能系统中可解释性和可解释性的关键策略,重点关注实用方法和现实世界案例。通过实施这些实践,组织可以创建更透明的 AI 系统,促进更好的决策、合规性和用户信任。
-
模型卡:模型卡提供了一种标准化的方式来记录人工智能模型,包括其性能特征、预期用途和限制。它们是透明度和负责任人工智能部署的关键工具。例如,谷歌的 BERT 语言模型附带了一份详细的模型卡,概述了其训练数据、不同任务和人口统计学的评估结果,以及伦理考量。这使用户能够做出是否 BERT 适合其特定用例的知情决策,并帮助他们了解潜在的偏见或限制。
-
可解释人工智能(XAI)技术:XAI 技术旨在使人工智能模型的决策过程更易于人类理解。这些方法可以提供关于哪些特征对特定决策或预测最重要的见解。例如,在医疗诊断人工智能系统中,SHapley Additive exPlanations(SHAP)值可以用来显示哪些症状或测试结果对特定诊断的贡献最大。这允许医生理解人工智能的推理,并将其与自己的临床判断进行比较。
-
用户友好的解释:人工智能决策的技术性解释通常对最终用户来说并不有用。开发清晰、非技术性的解释,针对用户的技能水平进行定制,对于实现实用性解释至关重要。信用评分人工智能可能不仅仅用数值分数来解释拒绝贷款的决定,而是用一个简单的解释,例如“你的申请主要由于高债务收入比和信用卡近期逾期还款而被拒绝。”这为用户提供可操作的信息,而无需他们理解底层人工智能模型。
-
可追溯性:维护人工智能系统输入、输出和关键决策点的详细日志,可以用于审计并有助于理解系统随时间的行为。这对于法规遵从和调试尤其重要。在一个自动驾驶车辆系统中,维护详细的传感器输入、决策点和采取的行动的日志至关重要。如果发生事故,此日志可以用于分析 AI 为何做出某些决策,以及如何在未来防止类似事件的发生。
-
可解释的模型架构:虽然不使用本质上更可解释的模型架构可能是一种强大的方法,但这可能涉及尽可能使用更简单的模型,或者开发旨在提高可解释性的新架构。
在金融欺诈检测系统中,对于某些组件,可能会使用决策树模型而不是更复杂的神经网络。决策树的逻辑可以轻松可视化并理解,从而可以清楚地解释为什么一笔交易被标记为可能存在欺诈。
- 交互式解释:向用户提供交互式工具以探索模型行为可以极大地增强理解。这使用户能够提出“如果…会怎样”的问题,并看到输入的变化如何影响输出。例如,一个电子商务平台的推荐系统可以包括一个交互式功能,允许用户调整不同因素(例如,价格、品牌、评分)的重要性,并实时看到这如何影响产品推荐。这有助于用户理解系统的逻辑,并根据他们的偏好进行调整。
通过实施这些策略,组织可以显著提高其人工智能系统的可解释性和可解释性,从而实现更透明、更值得信赖和更有效的人工智能应用。
隐私和数据保护
在人工智能系统中,尤其是在强大的通用人工智能模型背景下,隐私和数据保护是一个关键问题,它影响着用户的信任、法律合规性和技术的道德使用。随着人工智能系统处理越来越多的个人和可能敏感的数据,确保强大的隐私保障成为组织成败的关键点。有效的隐私保护不仅涉及技术措施,还包括组织政策和用户赋权。以下要点概述了增强人工智能系统中隐私和数据保护的关键策略,重点关注实际方法和现实世界案例。通过实施这些实践,组织可以创建尊重用户隐私、遵守法规并维护用户和利益相关者信任的人工智能系统:
-
数据最小化:这涉及仅收集和使用 AI 系统预期功能绝对必要的数据。这一原则降低了隐私风险,并与许多数据保护法规相一致。例如,一个智能家居 AI 助手可以设计为在设备上尽可能本地处理语音命令,而不是将所有音频数据发送到云端服务器。这减少了可能敏感数据离开用户控制的情况,并增加了用户对其数据不会泄露或用于进一步改进模型的信任。
-
匿名化和加密:这些技术通过在用于训练和推理的数据集中移除或模糊个人可识别信息来帮助保护个人隐私。如果正确实施,它们可以在保护隐私的同时允许有用的数据分析。在开发用于分析医院患者结果的 AI 系统时,研究人员可以使用差分隐私技术。例如,差分隐私会在数据或模型输出中添加精心校准的噪声,允许进行准确的整体分析,同时从数学上使其不可能识别个别患者。
-
用户控制:赋予用户对其数据的控制权不仅是许多司法管辖区的一项法律要求,而且有助于建立信任。这包括提供清晰、易于访问的数据管理选项。例如,一个使用 AI 进行内容推荐的社交媒体平台可以提供一个详细的隐私仪表板,用户可以在其中查看正在收集哪些数据,如何使用这些数据,以及轻松地退出特定的数据收集或处理活动。
-
合规性:遵守相关的数据保护法规至关重要。这通常涉及实施隐私设计原则、进行影响评估以及维护数据处理活动的详细记录。一家开发 AI 人力资源工具的跨国公司需要确保遵守 GDPR 以符合欧盟员工的要求,CCPA 以符合加州居民的要求,以及其他适用的当地法规。这可能包括创建特定区域的数据处理流程,并根据用户位置提供不同的隐私通知和控制措施。
-
避免记录 PII 和其他敏感信息:日志经常被忽视作为潜在的隐私泄露来源。在日志中避免捕获个人可识别信息是维护隐私的关键。即使日志不包含 PII,它们也可能包含有关系统操作的敏感信息。对日志数据进行强大的安全措施是至关重要的。一家使用 AI 进行欺诈检测的金融机构可以实施一个安全、加密的日志存储系统,并具有严格的访问控制。只有授权人员才能访问日志,所有访问都会被记录以供审计目的。
-
保留政策:建立和执行数据保留政策有助于随着时间的推移降低隐私风险,并且通常符合数据最小化方面的法律要求。一个由人工智能(AI)驱动的健身应用可以实施一项政策,在用户明确选择保留更长时间之前,自动删除用户活动数据(例如,6 个月)。这降低了旧数据被泄露的风险,同时仍然允许用户在需要时保持长期记录。
-
隐私保护的人工智能技术:如联邦学习和同态加密等新兴技术允许人工智能(AI)模型在不直接访问数据的情况下从数据中学习,为隐私保护提供了强大的新工具。智能手机上的键盘预测人工智能(AI)可以使用联邦学习来改进其模型。模型将使用本地数据在单个设备上更新,并且只有模型更新(而不是原始数据)会被发送回中央服务器,从而保护用户隐私。
通过实施这些策略,组织可以显著提高其人工智能(AI)系统的隐私和数据保护方面,从而产生更值得信赖且符合法律规定的、尊重用户隐私的人工智能(AI)应用。
通用人工智能(GenAI)系统中的安全性和安全性
确保通用人工智能(GenAI)系统安全、安全地按预期运行对于保护用户和防止信息生成和训练中的潜在滥用以及意外后果至关重要。这需要一种多方面的方法,包括主动措施和反应能力。以下要点概述了增强通用人工智能(GenAI)系统安全性和安全性的关键策略,重点关注实际方法和现实世界案例:
-
内容过滤:实施过滤器以防止生成有害或不适当的内容是一项至关重要的安全措施。例如,为儿童教育平台提供的由通用人工智能(GenAI)驱动的聊天机器人可以使用高级内容过滤算法来检测和阻止生成任何不适宜年龄的内容尝试,确保一个安全的学习环境。这可能涉及维护和定期更新一个全面的禁止词汇和主题列表,以及使用更复杂的自然语言处理技术来识别即使以新颖方式表达的可能有害内容。
-
速率限制:对 API 调用应用合理的限制对于防止滥用和确保公平使用至关重要。一个提供图像生成能力的通用人工智能(GenAI)服务可以实施分层速率限制,其中免费用户每天的限制数量有限,而付费用户有更高的限制。这不仅防止了潜在的拒绝服务攻击,还有助于有效管理计算资源。系统还可以根据请求的复杂性实施更细致的速率限制,允许更频繁的简单生成,同时限制资源密集型生成。
-
对抗性测试:定期使用对抗性输入测试系统对于识别和解决漏洞至关重要。这些测试需要添加到开发周期以及系统的持续监控中。
对于旨在协助医疗诊断的通用人工智能(GenAI)系统,研究人员可以创建一系列对抗性测试案例,旨在欺骗系统做出错误的诊断。这可能包括对医学图像进行细微的修改或精心制作的症状文本描述。通过持续运行和扩展这些测试,开发者可以识别系统决策过程中的弱点,并实施有针对性的改进以增强鲁棒性。
-
监控和警报:建立系统以检测和响应异常行为对于维持持续的安全和保障至关重要。使用通用人工智能(GenAI)进行欺诈检测的金融机构可以实施实时监控系统,以跟踪 AI 行为中的异常模式。例如,如果系统突然开始将异常高数量的交易标记为欺诈,或者其置信度分数显示出意外的波动,则可以自动触发警报供人工审查。这允许在系统出现潜在故障或遭受针对性攻击时进行快速干预。
-
增强的鲁棒性:如 Gemini 1.5 等模型所展示的输出稳定性和一致性对于安全性至关重要。用于自动化客户服务的通用人工智能(GenAI)系统可以利用这些改进,在广泛的客户咨询中提供更可靠和一致的反应。这降低了系统提供矛盾或无意义信息的风险,这可能导致客户困惑或不满。定期评估系统随时间和不同输入的输出,可以帮助验证和维护这种鲁棒性。
-
内容安全:内置机制以避免生成有害或露骨的内容是基本的安全保障。由通用人工智能(GenAI)驱动的创意写作助手可以整合多层内容安全检查。这可能包括分析生成的文本中可能冒犯性的语言,根据用户的个人资料检查适合年龄的内容,并在系统检测到可能进入敏感领域时提供警告或替代方案。这些机制应定期更新,以反映不断变化的社会规范和新的识别风险。
-
多模态安全: 随着 GenAI 系统变得更加多功能,将安全考虑扩展到文本、图像和其他模态变得越来越重要。一个用于社交媒体内容审查的多模态 GenAI 系统可以在文本、图像和视频上同时进行安全检查。例如,它可以分析帖子的文本和任何伴随的图像,以检测潜在的政策违规行为,确保有害内容不会通过利用不同模态之间的差距而溜走。这需要开发和维护能够理解不同类型数据上下文的全面安全模型。
通过实施这些策略,组织可以显著提高其 GenAI 系统的安全性和安全性,创造更可靠、值得信赖和有益的 AI 应用。定期审查和更新这些措施对于跟上 GenAI 技术的快速发展和潜在风险至关重要。
谷歌对负责任的 AI 的方法
谷歌对负责任的 AI 的方法是一个全面的框架,为实施 GenAI 系统的组织提供了一个模型。其核心,该方法优先考虑:
-
以人为本的设计 强调了在 AI 开发中用户需求和 societal impact 的重要性。这确保了 AI 系统是在对其现实世界影响和为不同背景的用户带来的潜在益处的深刻理解下创建的。
-
公平性 是谷歌框架的另一个关键方面。公司开发了复杂的工具和实践来检测和减轻 AI 系统中的不公平偏见。对公平性的承诺包括严格的测试、创建多样化的数据集以及持续的监控,以确保 AI 应用在演变和部署到各种环境中时保持公平。
-
可解释性 是一个关键焦点,谷歌致力于创建可解释的 AI 系统,以促进透明度。这涉及到开发方法,使 AI 决策过程对开发者和最终用户都更加可理解,从而在 AI 应用中培养信任和问责制。
-
隐私 是一个基本关注点,通过诸如联邦学习和差分隐私等高级技术得到解决。这些方法允许开发强大的 AI 模型,同时保护个人用户数据,在创新和隐私保护之间取得平衡。
-
安全和安全 在谷歌负责任的 AI 方法中至关重要。公司进行严格的测试,并专注于开发能够抵御潜在滥用或操纵的强大 AI 系统。这种主动的安全立场有助于确保 AI 技术不仅强大,而且值得信赖和有弹性。
谷歌的方法强调跨职能协作的重要性,将来自不同领域的专家聚集在一起,以应对人工智能发展的多方面挑战。这得到了对持续研究的坚定承诺的补充,推动人工智能能力的边界,同时探索其伦理影响。
谷歌的安全人工智能框架(SAIF)
这是一个概念框架,旨在管理与快速发展的人工智能技术相关的风险。它包括六个核心要素:
-
扩展强大的安全基础:调整现有的网络安全措施以保护人工智能系统,并培养与人工智能进步同步的专业知识。
-
扩展检测和响应:将人工智能相关威胁纳入现有的网络安全实践,包括监控人工智能系统输入和输出中的异常。
-
自动化防御:利用人工智能创新来提高对安全事件的响应规模和速度,对抗潜在的增强人工智能威胁。
-
协调平台级控制:确保组织内不同人工智能平台和工具之间的安全一致性,利用默认保护措施。
-
调整控制:通过强化学习、定期红队演习等技术持续测试和改进检测和保护机制。
-
情境化人工智能系统风险:对人工智能部署进行全面风险评估,考虑端到端业务风险,并实施自动化检查以验证人工智能性能。
该框架旨在帮助组织随着人工智能的进步而发展其风险管理策略,确保更安全、更负责任的人工智能实施。
在谷歌安全人工智能框架(SAIF)的核心要素基础上,实施方法(services.google.com/fh/files/blogs/google_secure_ai_framework_approach.pdf)为希望将人工智能安全地整合到其运营中的组织提供了一个实用的指南。该方法将过程分解为四个关键步骤,并详细阐述了如何有效地应用 SAIF 的六个核心要素:
-
理解用途:明确定义特定的 AI 用例及其在组织中的上下文。
-
组建团队:创建一个跨职能团队,包括来自安全、法律、数据科学和伦理等各个部门的利益相关者。
-
通过人工智能入门课程进行水平设定:确保所有团队成员对人工智能概念和术语有基本了解。
-
应用 SAIF 的六个核心要素:
-
扩展强大的安全基础:
-
审查现有的安全控制措施及其对人工智能系统的适用性。
-
评估传统控制措施对人工智能特定威胁的适用性。
-
准备供应链管理和数据治理。
-
-
扩展检测和响应:
-
理解人工智能特定威胁。
-
准备应对针对人工智能的攻击和人工智能输出提出的问题。
-
调整针对人工智能特定事件的滥用政策和事件响应流程。
-
-
自动化防御措施:
-
识别用于保护系统和数据管道的人工智能安全能力。
-
在保持人工参与的同时,使用人工智能防御措施来对抗人工智能威胁。
-
利用人工智能自动化耗时任务并加快防御机制。
-
-
协调平台级控制措施:
-
审查人工智能的使用和基于人工智能的应用程序的生命周期。
-
标准化工具和框架以防止控制碎片化。
-
-
适应控制措施:
-
对人工智能驱动的产品进行红队演习。
-
了解新型人工智能攻击。
-
应用机器学习来提高检测准确性和速度。
-
创建反馈循环以实现持续改进。
-
-
语境化人工智能系统风险:
-
建立模型风险管理框架。
-
建立人工智能模型及其风险概况的清单。
-
在机器学习模型的生命周期中实施政策和控制措施。
-
对人工智能的使用进行全面的风险评估。
-
考虑人工智能安全中的共同责任。
-
将人工智能用例与组织风险承受能力相匹配。
-
-
这种方法为组织提供了一个结构化的方式来实施 SAIF,确保人工智能的集成是安全的、负责任的,并与业务目标保持一致。
谷歌的“红队”方法
这种人工智能系统的方法是一种全面的策略,旨在识别和减轻人工智能部署中潜在的安全风险。公司已成立一个专门的 AI 红队,该队结合了传统的红队专业知识和专门的人工智能专业知识。该团队模拟针对人工智能部署的威胁行为者,目的是评估模拟攻击对用户和产品的影响,分析新的人工智能检测和预防能力的弹性,提高早期攻击识别的检测能力,并提高利益相关者对关键风险和必要安全控制的意识。欲了解更多信息,请参阅services.google.com/fh/files/blogs/google_ai_red_team_digital_final.pdf。
人工智能红队与谷歌的威胁情报团队(如 Mandiant 和威胁分析小组(TAG))紧密合作,确保他们的模拟反映现实世界的对手活动。这种合作使团队能够优先考虑不同的练习,并形成与真实世界威胁非常相似的互动。
谷歌对人工智能系统进行红队攻击的方法侧重于几种常见的攻击类型:
-
提示攻击是一个重大问题,特别是对于为生成人工智能产品提供动力的 LLMs。这些攻击涉及构建输入,以未预期的方式操纵模型的行为。例如,攻击者可能会在电子邮件中注入隐藏指令,以绕过基于人工智能的钓鱼检测系统。
-
训练数据提取攻击旨在重建字面训练示例,可能暴露敏感信息,如个人身份信息(PII)或密码。这些攻击对个性化模型或训练在包含 PII 的数据上的模型尤其危险。
-
模型后门攻击是另一种关键威胁,攻击者试图秘密改变模型的行为,以产生带有特定“触发”词或特征的错误输出。这可以通过直接操纵模型的权重、针对对抗目的的微调或修改模型的文件表示来实现。
-
对抗性示例涉及导致模型产生意外输出的输入。例如,人类看起来像狗的图像,但模型将其分类为猫。这些攻击的影响可能因人工智能系统的用例而异。
-
数据中毒攻击涉及操纵训练数据,以根据攻击者的偏好影响模型的输出。这突出了在人工智能开发中确保数据供应链安全的重要性。
-
数据泄露攻击专注于窃取模型本身,这通常包括敏感的知识产权。这些攻击可能从简单的文件复制到更复杂的攻击,涉及重复查询模型以确定其功能并重新创建它。
Google 强调,虽然这些针对人工智能的特定攻击至关重要,但它们应被视为传统安全威胁的补充,而不是替代。公司主张采用综合方法,结合人工智能特定的红队测试和传统的安全实践,如渗透测试、漏洞管理和安全开发生命周期。
通过分享他们的方法和经验教训,Google 旨在建立人工智能的明确行业安全标准,并帮助推进人工智能安全领域。他们的经验强调了跨职能协作、持续学习和将人工智能安全与更广泛的网络安全努力相结合以创建更强大和安全的 AI 部署的重要性。
Anthropic 对负责任的人工智能开发的方法
Anthropic 对负责任的人工智能开发的方法是全面且多方面的,将伦理考量、安全措施和实证研究贯穿于他们的工作之中。他们方法的关键方面包括:
-
优先考虑安全研究:Anthropic 将人工智能安全研究视为迫切重要且值得广泛支持。他们采用投资组合方法,为从乐观到悲观的各种场景做准备,以应对创建安全人工智能系统的难度。
-
实证重点:公司强调以实证为基础的安全研究,认为与前沿人工智能系统的密切接触对于在风险成为关键问题之前识别和解决潜在风险至关重要。
-
平衡进步与谨慎:Anthropic 在推进必要的安全研究和可能加速危险技术部署之间谨慎权衡。他们旨在快速将安全研究整合到实际系统中,同时保持负责任的发展实践。
-
透明度和合作:尽管不发布能力研究,Anthropic 仍分享以安全为导向的研究,以贡献于更广泛的 AI 社区对这些问题的理解。
-
负责任的部署:公司在展示前沿能力时持谨慎态度,在适当的情况下优先考虑安全研究而非公共部署。
-
对安全标准的承诺:Anthropic 计划对外做出可验证的承诺,只有在满足特定安全标准的情况下才会开发高级模型,允许对他们的模型能力和安全性进行独立评估。
-
社会影响评估:他们进行研究以评估其 AI 系统可能产生的潜在社会影响,既为内部政策提供信息,也参与更广泛的 AI 治理讨论。
-
负责任的扩展:Anthropic 认识到快速扩展 AI 能力的风险,并旨在开发可扩展监督等技术,以确保强大的系统与人类价值观保持一致。
-
跨学科方法:他们的策略涵盖了技术研究、政策考虑和伦理审议,反映了 AI 安全挑战的复杂性质。
-
适应性:Anthropic 在其方法上保持灵活性,随时准备根据对 AI 发展和相关风险的了解调整策略。
通过整合这些原则,Anthropic 旨在为开发既强大又安全、符合伦理且对人类有益的 AI 系统做出贡献。他们的方法反映了面对可能变革性的 AI 技术时对负责任创新的深厚承诺。Anthropic 的研究领域多样且全面,专注于 AI 安全和负责任发展的各个方面。他们的方法从即时的实际关注到长期的、推测性的风险,展示了应对 AI 发展多方面挑战的承诺。
Anthropic 研究的核心是机制可解释性,旨在“逆向工程”神经网络成为人类可理解算法。这个雄心勃勃的项目旨在使 AI 模型能够进行类似“代码审查”的操作,可能允许进行彻底的审计以识别不安全方面或提供强大的安全保证。该团队在将这种方法从视觉模型扩展到小型语言模型方面取得了进展,并发现了驱动情境学习的机制。
可扩展的监督是 Anthropic 关注的另一个关键领域。这项研究旨在开发使人工智能系统部分自我监督或协助人类进行监督的方法。这是对提供足够高质量反馈以引导人工智能行为的挑战的回应,随着系统变得越来越复杂,这一挑战变得更加严峻。
团队探索了各种方法,包括宪法人工智能的扩展、人类辅助监督的变体、人工智能-人工智能辩论和多智能体强化学习中的红队攻击。
以过程为导向的学习代表了一种新颖的人工智能训练方法。这种方法不是通过奖励人工智能系统实现特定结果来训练系统,而是专注于训练系统遵循安全的过程。目标是确保系统遵循可理解的、经过批准的过程,而不是通过可能有害或难以理解的手段追求目标,从而解决关于人工智能安全性的担忧。
测试危险故障模式是识别人工智能系统中潜在风险的一种主动方法。这涉及到故意将问题属性训练到小型模型中,以便在它们成为更强大系统中的直接威胁之前进行隔离和研究。一个特别感兴趣的研究领域是研究人工智能系统在“情境感知”时的行为以及这如何影响它们在训练过程中的行为。
最后,Anthropic 高度重视研究社会影响和评估。这涉及到构建工具和测量方法来评估人工智能系统的能力、局限性和潜在的社会影响。该领域的研究包括对 LLMs 中可预测性和意外的研究、针对语言模型的红队攻击方法,以及减少人工智能输出中的偏见和刻板印象的研究。这项研究不仅为 Anthropic 的内部实践提供了信息,也为更广泛的人工智能治理和政策讨论做出了贡献。
这些相互关联的研究领域共同旨在解决人工智能安全和伦理的各个方面。Anthropic 的方法因其广度和深度而引人注目,反映了人工智能发展挑战的复杂性质。该公司在其研究重点上保持灵活性,随时准备适应人工智能快速发展的领域中出现的新信息和挑战,展示了面对可能具有变革性的人工智能技术时的负责任创新承诺。
Anthropic,一家领先的 AI 研究公司,已经开发了一套全面的方法来应对 AI 安全和伦理方面的挑战。他们的方法被称为宪法 AI,在创建既强大又符合人类价值观的 AI 系统方面取得了重大进步,同时减少了在训练过程中对大量人类监督的需求。他们的方法在论文《宪法 AI:来自 AI 反馈的无害性》中被突出展示,(arxiv.org/pdf/2212.08073),该论文介绍了 Anthropic 开发安全且负责任的 AI 系统的方法,而不依赖于人类反馈来评估无害性。研究引入了一种称为宪法 AI(CAI)的方法,旨在创建既有帮助又无害的 AI 助手,同时避免规避回答。
Anthropic 的方法核心包括两个主要阶段:监督学习阶段和强化学习阶段。在监督阶段,AI 模型被训练根据一套原则或“宪法”来批评和修改自己的响应。这个过程有助于减少 AI 输出中的有害内容。随后,强化学习阶段通过使用 AI 生成的反馈而不是人类标签来评估无害性,进一步细化模型的行为。
Anthropic 开发这种技术的动机源于几个因素。他们旨在通过利用 AI 来帮助监督其他 AI 系统,减少 AI 助手中帮助性和无害性之间的紧张关系,提高 AI 决策的透明度,并减少对大量人类反馈的依赖。研究人员强调,实证、数据驱动的方法对 AI 安全的重要性,以及应对从乐观到悲观的各种潜在场景时所需的灵活性,这些场景涉及创建安全 AI 系统的难度。
论文展示了实验结果,表明宪法 AI 方法可以产生比使用传统从人类反馈中强化学习(RLHF)训练的模型更少有害且更有帮助的模型。值得注意的是,CAI 模型展示了以深思熟虑、非规避的方式处理敏感话题的能力,同时仍保持安全性。
Anthropic 的方法还结合了诸如思维链推理等技术,以提高 AI 决策的透明度和可解释性。这有助于更好地理解 AI 系统如何得出结论和采取行为。研究人员强调,随着 AI 能力的提升,他们对其安全技术的持续适应和改进的重要性。
论文最后讨论了该研究的潜在未来方向,包括将宪法方法应用于以各种方式引导人工智能行为,提高对对抗性攻击的鲁棒性,以及进一步细化有益性和无害性之间的平衡。Anthropic 承认这些技术的双重用途潜力,并强调人工智能系统负责任开发和部署的必要性。
总体而言,这项研究代表了朝着创建既强大又符合人类价值观的人工智能系统迈出的重要一步,同时减少了在训练过程中对大量人工监督的需求。
摘要
当设计人工智能应用时,开发者可以结合谷歌和 Anthropic 的方法,创建更负责任、更安全的系统。这种综合策略涉及几个关键关注领域:
全面的安全和影响评估对于负责任的人工智能开发至关重要。这个过程应包括对乐观和悲观结果的情景规划,使开发者能够为各种可能性做好准备。在小型系统上对安全措施进行实证测试是必不可少的,因为它提供了宝贵的见解,而没有大规模部署的风险。让多元化的利益相关者参与有助于在开发早期识别潜在问题,确保对人工智能系统潜在影响有广泛的视角。在扩展或部署更高级功能之前建立明确的安全阈值,有助于保持对人工智能发展的控制,并确保在整个过程中安全始终是首要任务。
透明和适应性强的开发过程对于建立信任并保持人工智能系统的安全性至关重要。实施可解释的人工智能技术使系统的决策过程更具可解释性,使开发者和用户都能理解人工智能如何得出结论。定期对系统的性能、公平性和安全性进行外部审计提供客观评估,并有助于确定改进领域。对模型的性能、局限性和预期用例进行清晰的文档记录有助于管理期望并防止滥用。开发一个快速整合新的安全研究成果的过程确保人工智能系统始终与人工智能安全领域的最新进展保持同步。
公平性和偏见缓解是负责任的人工智能开发的关键方面。确保人工智能系统不会持续或放大偏见,需要使用多样化和代表性的训练数据,实施主动和反应性的偏见检测和缓解措施,并在不同的背景和用户群体中进行定期的公平性审计。应用适合特定应用的情境公平性有助于确保人工智能系统在各种场景中的决策是公平的。
隐私和数据保护 对于安全的 AI 开发至关重要。实施强大的用户隐私保护措施包括应用数据最小化原则,使用匿名化、加密和隐私保护 AI 技术,为用户提供对其数据的明确控制权,并建立和执行数据保留政策。这些措施有助于建立用户信任并确保符合数据保护法规。
安全和安全措施 对于确保 AI 系统按预期行为并抵抗潜在攻击至关重要。这包括实施内容过滤和速率限制以防止滥用,定期进行对抗性测试以识别漏洞,建立监控和警报系统以检测异常行为,以及为多模态 AI 系统应用多模式安全考虑。这些措施有助于保护 AI 系统免受外部威胁并防止意外有害行为。
负责任的 AI 不仅是一个道德上的要求,而且是构建可持续、值得信赖和有效的通用人工智能应用的关键组成部分。通过在整个开发周期中整合公平性、可解释性、隐私和安全考虑因素,我们可以利用像 Google Gemini 这样的模型的力量,同时减轻潜在的风险和负面影响。
正如我们在本章中探讨的那样,实施负责任的 AI 实践需要多方面的方法。这包括多样化的代表性数据、偏见检测和缓解、可解释 AI 技术、强大的隐私保护和全面的安全措施。通过学习像 Google 和 Anthropic 这样的行业领导者,并将他们的框架适应到我们的特定用例中,我们可以创建通用人工智能应用,不仅推动可能性的边界,而且以造福整个社会的方式进行。
记住,负责任的 AI 是一个持续的过程,而不是一次性的勾选框。随着通用人工智能技术持续快速地发展,了解 AI 伦理的最新进展至关重要,定期重新评估我们的应用,并准备好相应地调整我们的实践。
在本书中,我们开始了一段穿越通用人工智能世界的全面旅程,重点关注利用像 Vertex AI 上的 Google Gemini 这样的强大模型。我们首先探索了用例构思和选择的过程,学习如何识别通用人工智能可以提供重大价值并转型业务流程的机会。
从那里,我们深入到至关重要的概念验证(POC)开发阶段,通过四个实际示例,将其置于一个框架中以简化规模并细化我们的方法。然后,我们探讨了关键的仪器化方面,学习如何有效地将通用人工智能模型集成到我们的应用和系统中,以及如何监控和优化其性能。
最后,我们讨论了至关重要的负责任 AI 主题,确保我们在推动生成式 AI 可能性的边界时,以符合道德、公平且对社会有益的方式进行。
从构思到负责任实施的过程代表了在现实世界中成功利用生成式 AI 的蓝图。随着这些技术以快速的速度发展,我们讨论的原则和实践将变得越来越重要。
人工智能的未来不仅仅是构建更强大的模型;它关于构建更智能、更负责任的系统,这些系统能够增强人类能力,并为我们的世界做出积极贡献。通过遵循本书中概述的方法——从谨慎选择用例到严格的 POC 开发、深思熟虑的仪表化和对负责任 AI 的坚定不移的承诺——您将充分准备好在这个激动人心且变革性的领域中引领潮流。
在您推进自己的生成式 AI 项目时,请记住,成功不仅在于技术实现,还在于深思熟虑地考虑如何使用这些强大的工具在创造真正价值的同时,维护最高的道德和责任标准。AI 发展的旅程是持续的,您在塑造其未来的角色现在就开始了。
加入我们的 Discord 社区
加入我们的社区 Discord 空间,与作者和其他读者进行讨论:
packt.link/genpat
订阅我们的在线数字图书馆,全面访问超过 7,000 本书籍和视频,以及行业领先的工具,帮助您规划个人发展并推进您的职业生涯。更多信息,请访问我们的网站。
为什么订阅?
-
使用来自超过 4,000 位行业专业人士的实用电子书和视频,花更少的时间学习,更多的时间编码
-
通过为您量身定制的技能计划提高您的学习效果
-
每月免费获得一本电子书或视频
-
完全可搜索,便于轻松访问关键信息
-
复制粘贴、打印和收藏内容
在www.packt.com,您还可以阅读一系列免费的技术文章,订阅各种免费通讯,并享受 Packt 书籍和电子书的独家折扣和优惠。
您可能还会喜欢的其他书籍
如果您喜欢这本书,您可能对 Packt 出版的以下其他书籍也感兴趣:
https://github.com/OpenDocCN/freelearn-dl-zh/raw/master/docs/genai-app-intg-ptn/img/9781835083468.png(https://www.packtpub.com/en-in/product/generative-ai-with-langchain-9781835083468)
使用 LangChain 的生成式 AI
本·奥法特
ISBN: 978-1-83508-346-8
-
理解 LLM,它们的优点和局限性
-
掌握生成式 AI 基础和行业趋势
-
使用 LangChain 创建类似问答系统和聊天机器人的 LLM 应用
-
理解 Transformer 模型和注意力机制
-
使用 pandas 和 Python 自动化数据分析可视化
-
掌握提示工程以提高性能
-
微调 LLMs 并了解释放其力量的工具
-
使用 LangChain 将 LLMs 作为服务部署并应用评估策略
-
使用开源 LLMs 私下与文档互动,以防止数据泄露
https://www.packtpub.com/en-in/product/building-llm-powered-applications-9781835462317
构建由 LLM 驱动的应用程序
Valentina Alto
ISBN: 978-1-83546-231-7
-
探索 LLM 架构的核心组件,包括编码器-解码器块和嵌入
-
理解 LLMs(如 GPT-3.5/4、Llama 2 和 Falcon LLM)的独特功能
-
使用 LangChain 等 AI 编排器,配合 Streamlit 进行前端开发
-
熟悉 LLM 组件,如内存、提示和工具
-
学习如何使用非参数知识和向量数据库
-
理解 LFMs 对人工智能研究和行业应用的影响
-
使用微调自定义你的 LLMs
-
了解由 LLM 驱动的应用程序的伦理影响
Packt 正在寻找像你这样的作者
如果你有兴趣成为 Packt 的作者,请访问authors.packtpub.com并今天申请。我们已与成千上万的开发者和科技专业人士合作,就像你一样,帮助他们将见解分享给全球科技社区。你可以提交一般申请,申请我们正在招募作者的特定热门话题,或者提交你自己的想法。
分享你的想法
现在你已经完成了《生成式 AI 应用集成模式》,我们非常想听听你的想法!如果你在亚马逊购买了这本书,请点击此处直接转到该书的亚马逊评论页面并分享你的反馈或在该购买网站上留下评论。
你的评论对我们和科技社区非常重要,并将帮助我们确保我们提供高质量的内容。
更多推荐
 29
29 0
0- 0



 已为社区贡献170条内容
已为社区贡献170条内容

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
所有评论(0)