
AIGC笔记
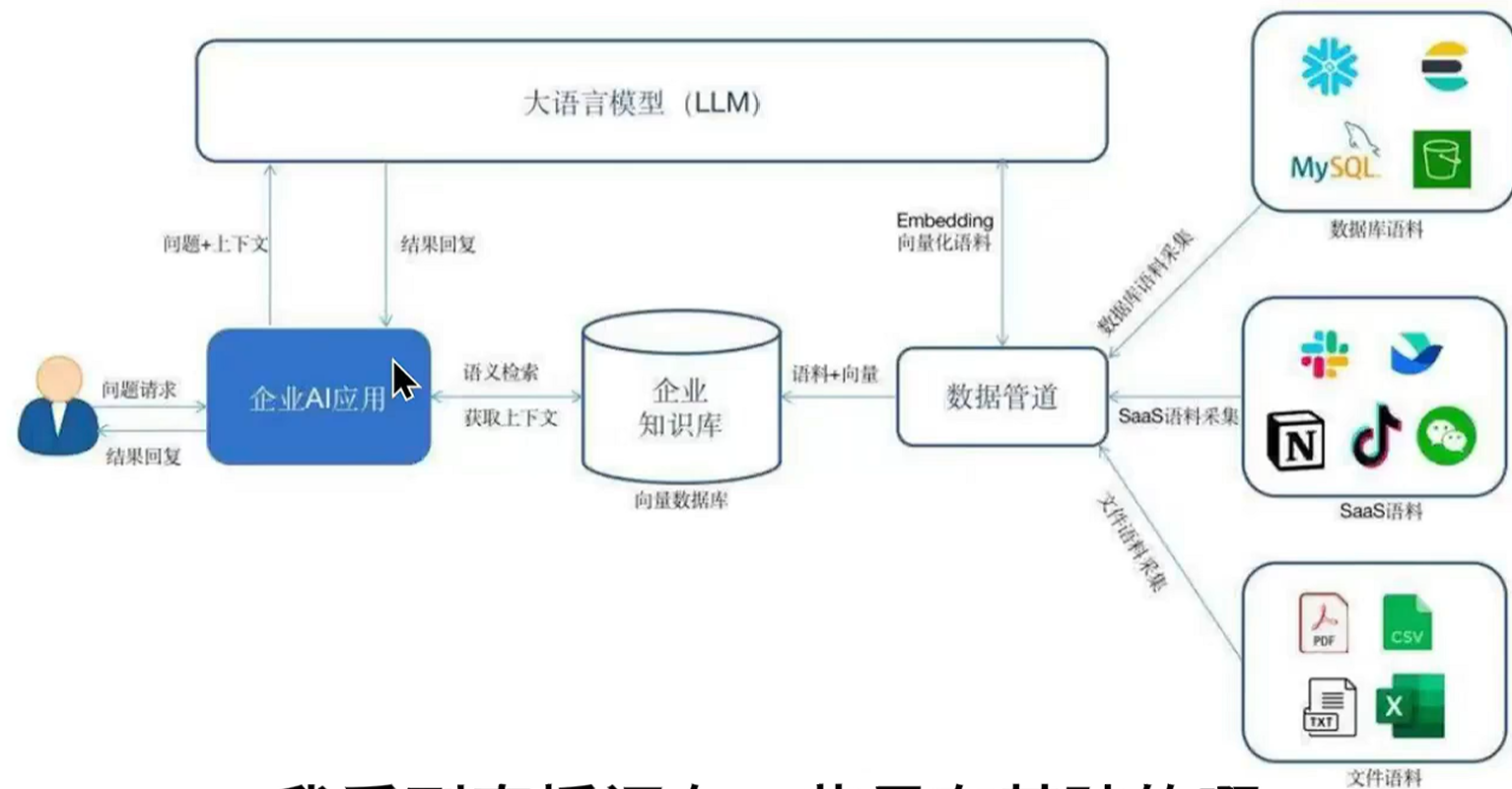
LLM大语言模型提示工程,使提问更加清晰RAG(Retrival-Augmented Generation检索增强生成),结合信息检索和生成式AI的技术架构,RAG 通过从外部知识库(如文档、数据库)中检索相关信息,并将其作为上下文输入给 LLM(大型语言模型),从而提高回答的准确性,减少幻觉问题微调,可以增强模型能力LangChain开源框架,允许开发人员将LLM与外部的计算和数据源结合起来对比
一、概念
LLM大语言模型
- BERT:Bidirectional Encoder Representations from Transformers
- GPT3:Generative Pre-trained Transformer 3
- T5:Text-to-Text Transfer Transformer,基于Transformer架构的文本生成模型
提示工程,使提问更加清晰
RAG(Retrival-Augmented Generation检索增强生成),结合信息检索和生成式AI的技术架构,RAG 通过从外部知识库(如文档、数据库)中检索相关信息,并将其作为上下文输入给 LLM(大型语言模型),从而提高回答的准确性,减少幻觉问题
微调,可以增强模型能力
LangChain开源框架,允许开发人员将LLM与外部的计算和数据源结合起来
|
对比维度 |
通用大模型 |
推理大模型 |
|
实现 |
模式识别、统计关联 |
在通用大模型基础上使用强化学习、神经符号推理、元学习等,强化推理、分析、决策能力 |
|
计算效率 |
计算量小,响应速度快,适合高并发场景 |
计算量大,推理过程复杂,单次响应时间长 |
|
适用场景 |
适用于常规文本生成、创意写作、多轮对话、开放性问答等场景 |
适合多步逻辑推理任务,如数学推理、代码分析、复杂决策 |
|
提示词策略 |
需显式引导推理步骤,依赖提示语补偿短板 |
提示语更简洁,只需明确任务目标和需求 |
prompt
组成:目标(核心指令)、上下文(背景信息)、输入(具体数据)、输出(期望结果)、条件限制(注意事项)
原则:明确、简洁、具体、迭代
|
要素 |
描述 |
示例 |
|
目标 |
这一项是prompt的核心:明确告诉AI你希望它执行什么任务 |
|
|
上下文 |
业务背景、技术栈等,提供更多的背景信息,帮助模型更好的理解任务 |
|
|
输入要求 |
需要给模型提供的信息,比如参数信息、数据结构等 |
|
|
输出要求 |
期望AI生成的内容形式,如文本、代码、图像等 |
|
|
条件限制 |
对输出结果额外要求,比如字数、语气、风格、技术约束、性能要求等 |
|
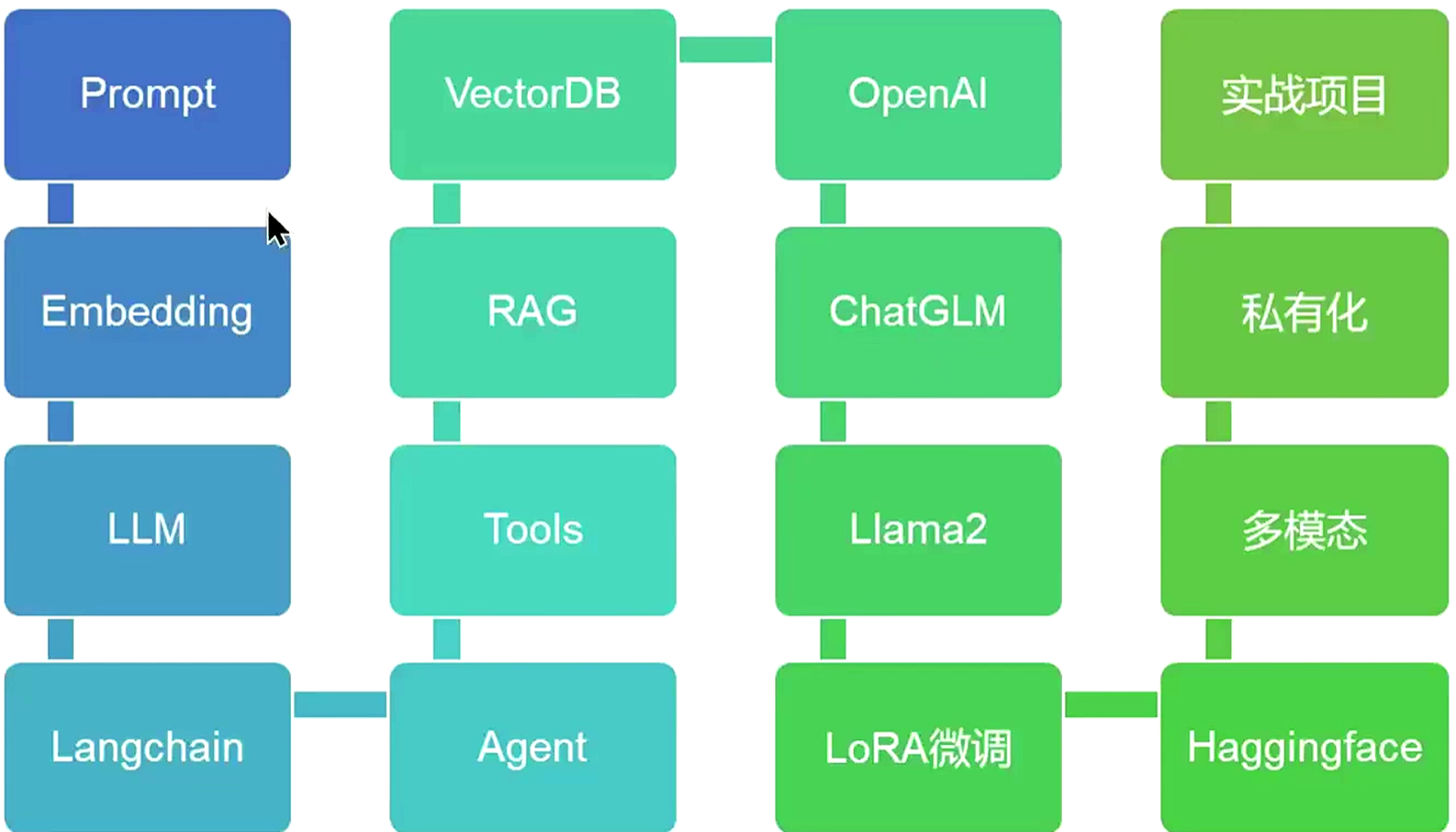
二、学习路线
三、DeepSeek
# 安装
pip install OpenAI
# 使用
from openai import OpenAI
client = OpenAI(api_key="<token>", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)四、LangChain
https://python.langchain.com/docs/introduction/
等价于数据库领域的JDBC,作为连接和集成不同系统的桥梁,使LLMs不仅能处理文本,还能做私有数据连接、行动执行,扩展了应用范围和有效性
1、组件
- Models模型:包装器允许连接到不同的LLM,如GPT-4、HuggingFace
- Prompt Templates提示模板:避免硬编码输入,可以动态地将用户输入插入到模板中并发送给LLMs
- Components组件:驱动,为LLMs提供接口封装、模板提示和信息检索索引
- Chains链:将不同的组件组合起来解决特定的任务,比如在大量文本查找信息
- Agents代理:使LLMs能与外部环境交互,比如通过API请求执行操作
- Embedding嵌入:与VectorStores向量数据库结合使用,是数据表示和检索的手段,为模型提供必要的语言理解基础
- Indexes索引:建立索引后帮助提取相关信息
2、原理
- 从用户提出的Question出发,通过Similarity Search(向量的余弦夹角)在一个大型数据库或向量空间找到相关的信息
- 得到的信息与原始Question结合后,由一个LLM分析产生一个Answer
- 这个Answer被用来指导一个Agent采取Action,调用API或与外部系统交互来完成任务
3、应用场景
- 个人助手
- 学习辅助
- 数据分析和数据科学
4、安装
https://blog.csdn.net/qq_41969287/article/details/145620258
pip install langchain-core
pip install langchain-deepseek
pip install langchain-community #支持ChatHistory允许记住过去的互动,在回应后续问题时考虑
pip install langchain-chroma # langchain提供的内置向量数据库5、langSmith
trace
# langsmith trace
os.environ["LANGSMITH_TRACING"]="true"
os.environ["LANGSMITH_ENDPOINT"]="https://api.smith.langchain.com"
os.environ["LANGSMITH_API_KEY"]="xx"
os.environ["LANGSMITH_PROJECT"]="langchainDeepseek"6、langchain-deepseek使用
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
# other params...
)
messages = [
(
"system",
"You are a helpful assistant that translates English to Chinese. Translate the user sentence.",
),
("human", "I love programming."),
]
ai_msg = llm.invoke(messages)
ai_msg.content7、聊天机器人
使用langchain_community保存聊天历史记录,定义config保存session_id,在模板中通过MessagesPlaceholder定义聊天内容的key
# 定义提示模板
prompt_template = ChatPromptTemplate.from_messages([
('system','你是一个乐于助人的助手,用{language}尽你所能回答所有问题。'),
MessagesPlaceholder(variable_name="my_msg")
])
# 保存聊天历史记录
from langchain_community.chat_message_histories import ChatMessageHistory
store = {} # 所有用户的聊天记录都保存到store,key:sessionId,value:历史聊天记录
def get_session_history(session_id: str):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
do_message = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key='my_msg' # 每次聊天时发送msg的key
)
# 当前会话定义一个session_id
config = {'configurable':{'session_id':'sent by Yubin'}}
resp = do_message.invoke(
input = {
'my_msg':[HumanMessage(content = "你好,我是李宇彬,喜欢研究AI")],
'language':'中文'
},
config = config)8、向量数据库用于RAG
deepseek不提供embedding模型。。
五、python环境
先安装python3.11.1,安装uv python包管理工具
brew install pyenv
pyenv install 3.11.1
pyenv global 3.11.1
pyenv versions
pip3 install uv
pyenv init >> .zprofile
# 可选安装
uv pip install ipython
uv pip install jupyter
#jupyter notebook
uv run --with jupyter jupyter lab #更好
brew install npm六、RAG
Retrival-Augmented-Generation,检索增强生成
提问前:分片 -> 索引(embedding把文本转换成向量;调用api存到向量数据库)
提问后:召回 -> 重排 -> 生成
uv init
uv add sentence_transformers #加载embedding、cross-encoder模型
uv add chromadb # 一个非常流行的向量数据库
uv add google-genai #google的ai sdk,调用Gemini-2.5-flash必备
uv add python-dotenv #把Gemini API key映射到环境变量七、MCP
与外部工具交互
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)