
【学习笔记】从零构建大模型
【学习笔记】从零构建大模型
代码清单3-5 多头注意力
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
# 减少投影维度以匹配所需的输出维度
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# 使用一个线性层来组合头的输出
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape # (2, 6, 3)
# shape: (b, num_tokens, d_out)
keys = self.W_key(x) # (2, 6, 3) @ (3, 2) => (2, 6, 2)
queries = self.W_query(x)
values = self.W_value(x)
# 通过添加一个 num_heads 维 度来隐式地分隔矩阵。然后 展开最后一个维度:
# (b, num _tokens, d_ out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) # (2, 6, 2) => (2, 6, 2, 1)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
)
# 从形状(b, num_tokens, num_heads, head_dim) 转换到(b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2) # (2, 6, 2, 1) => (2, 2, 6, 1)
values = values.transpose(1, 2)
queries = queries.transpose(1, 2)
# 计算每个头的点积
attn_scores = queries @ keys.transpose(2, 3) # (2, 2, 6, 1) @ (2, 2, 1, 6) => (2, 2, 6, 6)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# 张量形状: (b, num_tokens, n_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2) # (2, 2, 6, 6) @ (2, 2, 6, 1) => (2, 2, 6, 1) => (2, 6, 2, 1)
# 组合头,其中 self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(
b, num_tokens, self.d_out
) # (2, 6, 2, 1) => (2, 6, 2)
# 添加一个可选 的线性投影
context_vec = self.out_proj(context_vec)
return context_vec
inputs = torch.tensor(
[[0.43, 0.15, 0.89], # Your (x^1)
[0.55, 0.87, 0.66], # journey (x^2)
[0.57, 0.85, 0.64], # starts
[0.22, 0.58, 0.33], # with
[0.77, 0.25, 0.10], # one
[0.05, 0.80, 0.55]] # step
)
batch = torch.stack((inputs, inputs), dim=0)
torch.manual_seed(123)
batch_size, context_length, d_in = batch.shape # (2, 6, 3)
d_out = 2
mha = MultiHeadAttention(d_in, d_out, context_length, 0, num_heads=2)
context_vecs = mha(batch)
print(context_vecs.shape, context_vecs)
代码清单4-2 层归一化类
层归一化:减去均值,并将结果除以方差的平方根(也就是标准差)。归一化后的层输出也包含负值,其均值为 0,方差为 1
层归一化,提高神经网络训练的稳定性和效率。层归一化的主要思想是调整神经网络层的激活(输出),使其均值为 0 且方差(单位方差)为 1。这种调整有助于加速权重的有效收敛,并确保训练过程的一致性和可靠性。
import torch
import torch.nn as nn
torch.manual_seed(123)
batch_example = torch.randn(2, 5)
layer = nn.Sequential(nn.Linear(5, 6), nn.ReLU())
out = layer(batch_example)
print(out)
"""
tensor([[0.2260, 0.3470, 0.0000, 0.2216, 0.0000, 0.0000],
[0.2133, 0.2394, 0.0000, 0.5198, 0.3297, 0.0000]],
grad_fn=<ReluBackward0>)
"""
# 均值
mean = out.mean(dim=-1, keepdim=True)
# 方差
var = out.var(dim=-1, keepdim=True)
print("Mean:", mean)
print("Variance:", var)
"""
Mean: tensor([[0.1324],
[0.2170]], grad_fn=<MeanBackward1>)
Variance: tensor([[0.0231],
[0.0398]], grad_fn=<VarBackward0>)
"""
# 归一化
out_norm = (out - mean) / torch.sqrt(var)
mean = out_norm.mean(dim=-1, keepdim=True)
var = out_norm.var(dim=-1, keepdim=True)
print("out_norm:", out_norm)
"""
out_norm: tensor([[ 0.6159, 1.4126, -0.8719, 0.5872, -0.8719, -0.8719],
[-0.0189, 0.1121, -1.0876, 1.5173, 0.5647, -1.0876]],
grad_fn=<DivBackward0>)
"""
torch.set_printoptions(sci_mode=False)
print("mean:", mean)
print("variance:", var)
"""
mean: tensor([[ 0.0000],
[ 0.0000]], grad_fn=<MeanBackward1>)
variance: tensor([[1.0000],
[1.0000]], grad_fn=<VarBackward0>)
"""import torch
import torch.nn as nn
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
torch.manual_seed(123)
batch_example = torch.randn(2, 5)
ln = LayerNorm(emb_dim=5)
out_ln = ln(batch_example)
mean = out_ln.mean(dim=-1, keepdim=True)
var = out_ln.var(dim=-1, unbiased=False, keepdim=True)
torch.set_printoptions(sci_mode=False)
print("Mean:", mean)
print("Variance:", var)
"""
Mean: tensor([[ 0.0000],
[ -0.0000]], grad_fn=<MeanBackward1>)
Variance: tensor([[1.0000],
[1.0000]], grad_fn=<VarBackward0>)
"""代码清单4-3 GELU激活函数

import torch
import torch.nn as nn
import matplotlib.pyplot as plt
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
gelu, relu = GELU(), nn.ReLU()
x = torch.linspace(-3, 3, 100) # 在-3 和 3 之间创建 100 个样本数据点
y_gelu, y_relu = gelu(x), relu(x)
plt.figure(figsize=(8,3))
for i, (y, label) in enumerate(zip([y_gelu, y_relu], ["GELU", "ReLU"]), 1):
plt.subplot(1, 2, i)
plt.plot(x, y)
plt.title(f"{label} activation function") # 图标标题
plt.xlabel("x") # X轴标签
plt.ylabel(f"{label}(x)")
plt.grid(True) # 显示网格
plt.tight_layout() # 自动调整图表布局,防止标签重叠
plt.savefig('gelu_relu')
plt.show()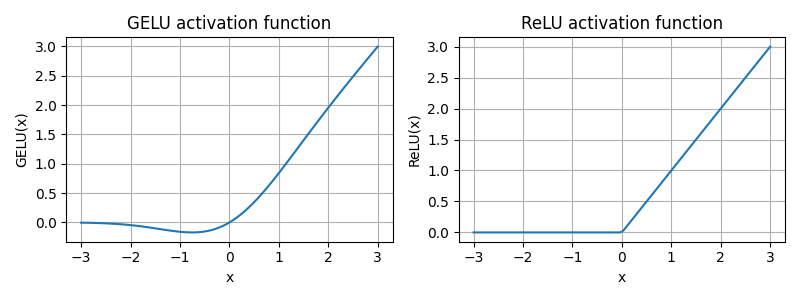
代码清单4-5 梯度消失&快捷连接(跳跃连接或残差连接)
梯度消失:指的是在训练过程中,梯度在反向传播时逐渐变小,导致早期网络层难以有效训练。
快捷连接:最初用 于计算机视觉中的深度网络(特别是残差网络),目的是缓解梯度消失问题。通过跳过一个或多个层,为梯度在网络中的流动提供了一条可替代且更短的路径。这是通过将一层的输出添加到后续层的输出中实现的。
import torch
import torch.nn as nn
class ExampleDeepNeuralNetwork(nn.Module):
def __init__(self, layer_sizes, use_shortcut):
super().__init__()
self.use_shortcut = use_shortcut
self.layers = nn.ModuleList([
nn.Sequential(nn.Linear(layer_sizes[0], layer_sizes[1]),
GELU()),
nn.Sequential(nn.Linear(layer_sizes[1], layer_sizes[2]),
GELU()),
nn.Sequential(nn.Linear(layer_sizes[2], layer_sizes[3]),
GELU()),
nn.Sequential(nn.Linear(layer_sizes[3], layer_sizes[4]),
GELU()),
nn.Sequential(nn.Linear(layer_sizes[4], layer_sizes[5]),
GELU()),
])
def forward(self, x):
for layer in self.layers:
layer_output = layer(x) # 计算当前层的输出
if self.use_shortcut and x.shape == layer_output.shape: # 检查是否可以使用快捷连接
x = x + layer_output
else:
x = layer_output
return x
def print_gradients(model, x):
output = model(x) # 前向传播
target = torch.tensor([[0.]]) # 为简化处理,这里设为 0
loss = nn.MSELoss()
loss = loss(output, target) # 基于目标和输出之间的差距来计算损失
loss.backward() # 反向传播来计算梯度
for name, param in model.named_parameters():
if 'weight' in name:
print(f"{name} has gradient mean of {param.grad.abs().mean().item()}")
layer_sizes = [3, 3, 3, 3, 3, 1]
sample_input = torch.tensor([[1., 0., -1.]])
torch.manual_seed(123) # 指定随机种子,用于初始化权重,以确保结果可复现
model_without_shortcut = ExampleDeepNeuralNetwork(
layer_sizes, use_shortcut=True
)
print(model_without_shortcut)
print_gradients(model_without_shortcut, sample_input)
"""
ExampleDeepNeuralNetwork(
(layers): ModuleList(
(0-3): 4 x Sequential(
(0): Linear(in_features=3, out_features=3, bias=True)
(1): GELU()
)
(4): Sequential(
(0): Linear(in_features=3, out_features=1, bias=True)
(1): GELU()
)
)
)
use_shortcut=False
layers.0.0.weight has gradient mean of 0.00020173584925942123
layers.1.0.weight has gradient mean of 0.00012011159560643137
layers.2.0.weight has gradient mean of 0.0007152040489017963
layers.3.0.weight has gradient mean of 0.0013988736318424344
layers.4.0.weight has gradient mean of 0.005049645435065031
梯度在从最后一层(layers.4)到第 1 层(layers.0) 的过程中逐渐变小,这种现象称为梯度消失问题。
use_shortcut=True
layers.0.0.weight has gradient mean of 0.22169792652130127
layers.1.0.weight has gradient mean of 0.20694108307361603
layers.2.0.weight has gradient mean of 0.3289699852466583
layers.3.0.weight has gradient mean of 0.2665732204914093
layers.4.0.weight has gradient mean of 1.3258541822433472
最后一层(layers.4)的梯度仍然大于其他层。然而,梯度值在逐渐接近第 1 层(layers.0) 时趋于稳定,并且没有缩小到几乎消失的程度。
"""代码清单4-6 Transformer block
Transformer 块的核心思想是,自注意力机制在多头注意力块中用于识别和分析输入序列中元素之间的关系。前馈神经网络则在每个位置上对数据进行单独的修改。
输出是一个包含整个输入序列信息的上下 文向量。这意味着,虽然序列的物理维度(长度和特征尺寸)在通过 Transformer 块时保持不变, 但每个输出向量的内容都要重新编码,以整合来自整个输入序列的上下文信息。
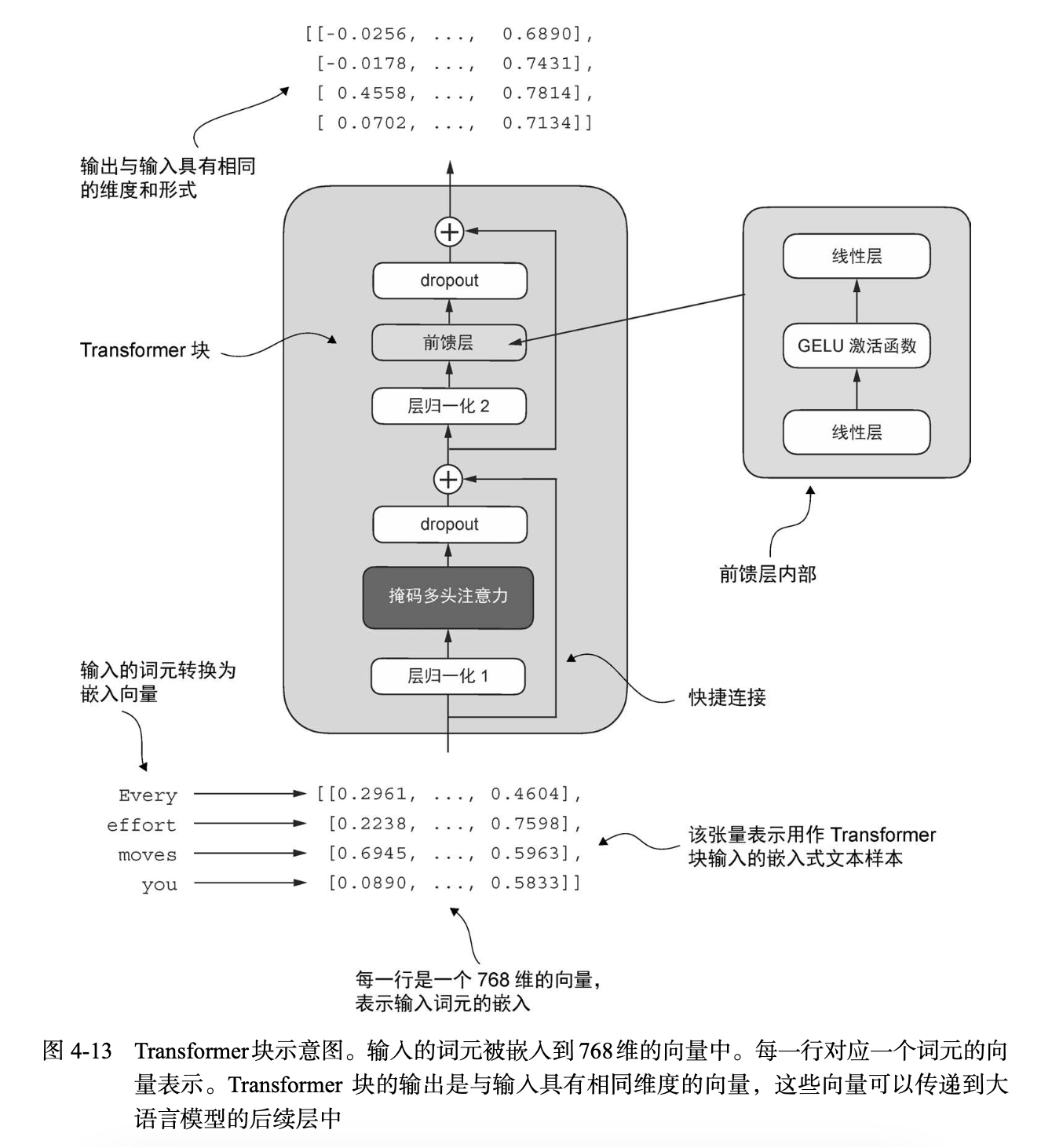
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
# 减少投影维度以匹配所需的输出维度
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# 使用一个线性层来组合头的输出
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape # (2, 6, 3)
# shape: (b, num_tokens, d_out)
keys = self.W_key(x) # (2, 6, 3) @ (3, 2) => (2, 6, 2)
queries = self.W_query(x)
values = self.W_value(x)
# 通过添加一个 num_heads 维 度来隐式地分隔矩阵。然后 展开最后一个维度:
# (b, num _tokens, d_ out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) # (2, 6, 2) => (2, 6, 2, 1)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
)
# 从形状(b, num_tokens, num_heads, head_dim) 转换到(b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2) # (2, 6, 2, 1) => (2, 2, 6, 1)
values = values.transpose(1, 2)
queries = queries.transpose(1, 2)
# 计算每个头的点积
attn_scores = queries @ keys.transpose(2, 3) # (2, 2, 6, 1) @ (2, 2, 1, 6) => (2, 2, 6, 6)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# 张量形状: (b, num_tokens, n_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2) # (2, 2, 6, 6) @ (2, 2, 6, 1) => (2, 2, 6, 1) => (2, 6, 2, 1)
# 组合头,其中 self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(
b, num_tokens, self.d_out
) # (2, 6, 2, 1) => (2, 6, 2)
# 添加一个可选 的线性投影
context_vec = self.out_proj(context_vec)
return context_vec
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
shortcut = x # 在注意力块中添加快捷连接
"""
层归一化(LayerNorm)应用于这两个组件之前,而 dropout 应用于这两个组件之后,
以便对模型进行正则化并防止过拟合。这种方法也被称为前层归一化(Pre-LayerNorm)。
"""
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
"""
每个组件后面都跟着一个快捷连接,将块 的输入加到其输出上。
这个关键特性有助于在训练过程中使梯度在网络中流动,并改善深度模型的学习效果
"""
x = x + shortcut # 将原始输入添加回来
shortcut = x # 在前馈层中添加快捷链接
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # 将原始输入添加回来
return x
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 1024,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}
torch.manual_seed(123)
x = torch.rand(2, 4, 768)
block = TransformerBlock(GPT_CONFIG_124M)
output = block(x)
print("Input:", x.shape)
print("Output:", output.shape)
"""
Input: torch.Size([2, 4, 768])
Output: torch.Size([2, 4, 768])
"""代码清单4-7 实现GPT模型
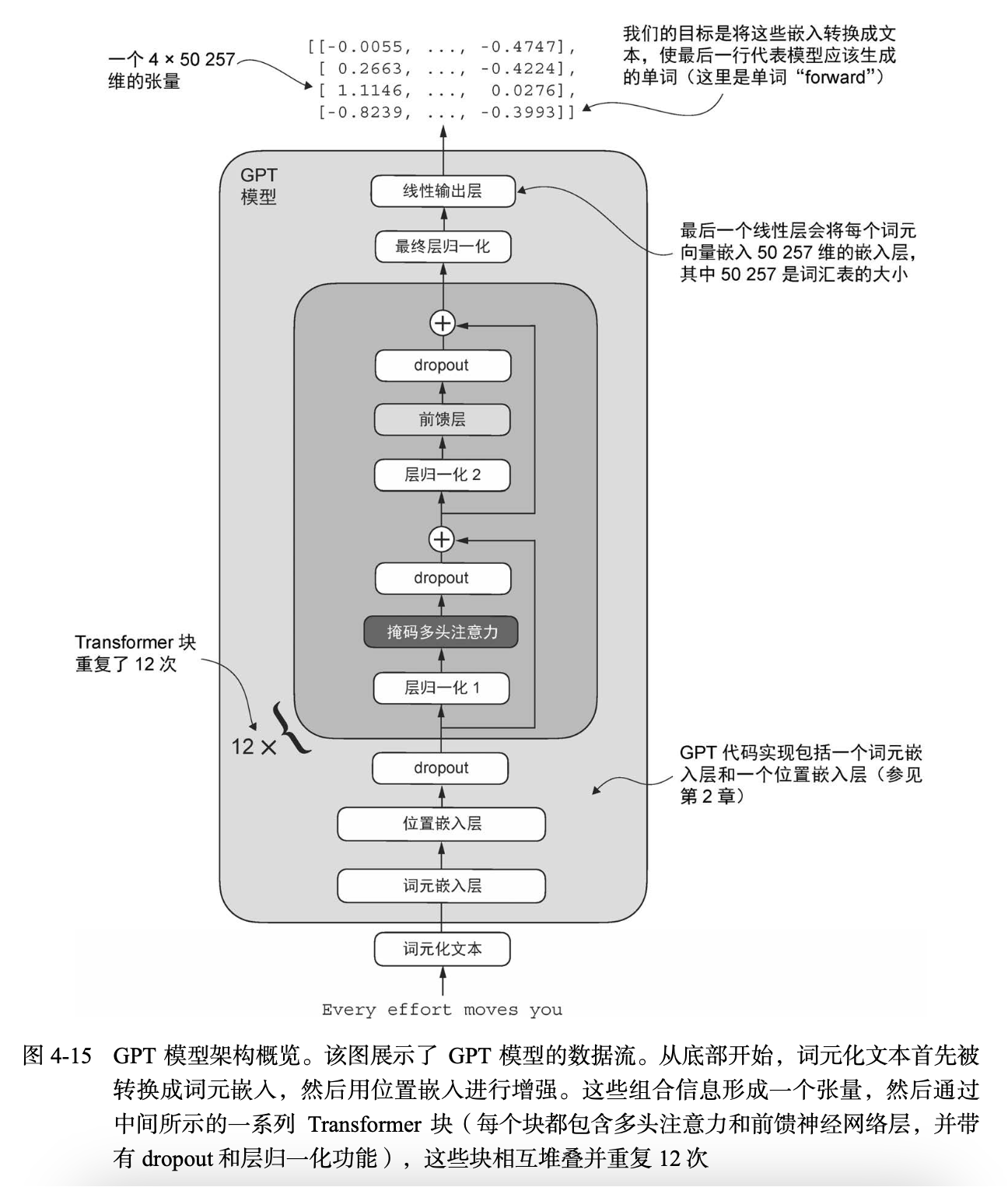
import torch
import torch.nn as nn
import tiktoken
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
# 减少投影维度以匹配所需的输出维度
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# 使用一个线性层来组合头的输出
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape # (2, 6, 3)
# shape: (b, num_tokens, d_out)
keys = self.W_key(x) # (2, 6, 3) @ (3, 2) => (2, 6, 2)
queries = self.W_query(x)
values = self.W_value(x)
# 通过添加一个 num_heads 维 度来隐式地分隔矩阵。然后 展开最后一个维度:
# (b, num _tokens, d_ out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) # (2, 6, 2) => (2, 6, 2, 1)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
)
# 从形状(b, num_tokens, num_heads, head_dim) 转换到(b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2) # (2, 6, 2, 1) => (2, 2, 6, 1)
values = values.transpose(1, 2)
queries = queries.transpose(1, 2)
# 计算每个头的点积
attn_scores = queries @ keys.transpose(2, 3) # (2, 2, 6, 1) @ (2, 2, 1, 6) => (2, 2, 6, 6)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# 张量形状: (b, num_tokens, n_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2) # (2, 2, 6, 6) @ (2, 2, 6, 1) => (2, 2, 6, 1) => (2, 6, 2, 1)
# 组合头,其中 self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(
b, num_tokens, self.d_out
) # (2, 6, 2, 1) => (2, 6, 2)
# 添加一个可选 的线性投影
context_vec = self.out_proj(context_vec)
return context_vec
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
shortcut = x # 在注意力块中添加快捷连接
"""
层归一化(LayerNorm)应用于这两个组件之前,而 dropout 应用于这两个组件之后,
以便对模型进行正则化并防止过拟合。这种方法也被称为前层归一化(Pre-LayerNorm)。
"""
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
"""
每个组件后面都跟着一个快捷连接,将块 的输入加到其输出上。
这个关键特性有助于在训练过程中使梯度在网络中流动,并改善深度模型的学习效果
"""
x = x + shortcut # 将原始输入添加回来
shortcut = x # 在前馈层中添加快捷链接
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # 将原始输入添加回来
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
# 词元嵌入层和位置嵌入层负责将输入的词元索引转换为稠密向量,并添加位置信息
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
# LayerNorm层将Transformer块的输出标准化,以稳定学习过程
self.final_norm = LayerNorm(cfg["emb_dim"])
# 无偏置的线性输出头,将Transformer的输出投影到分词器的词汇空间,为词汇中的每个词元生成分数logits
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx) # 词元嵌入层
pos_embeds = self.pos_emb(
torch.arange(seq_len, device=in_idx.device)
) # 位置嵌入层
x = tok_embeds + pos_embeds
x = self.drop_emb(x) # dropout
x = self.trf_blocks(x) # transformer blocks
x = self.final_norm(x) # 最终层归一化
# 计算logits,这些logits代表下一个词元的非归一化概率
# 最后一个线性层会将每个词元向量嵌入 50257 维的嵌入层,其中 50257 是词汇表的大小
# 这个线性输出层将 Transformer 的输出映射到一个高维空间,以预测序列中的下一个词元
logits = self.out_head(x) # 线性输出层
return logits
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 1024,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}
tokenizer = tiktoken.get_encoding("gpt2")
batch = []
txt1 = "Every effort moves you"
txt2 = "Every day holds a"
batch.append(torch.tensor(tokenizer.encode(txt1)))
batch.append(torch.tensor(tokenizer.encode(txt2)))
batch = torch.stack(batch, dim=0)
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
out = model(batch)
print("Input:", batch)
print("Output:", out.shape, out)
# print(model)
# 模型参数张量的总参数量
total_params = sum(p.numel() for p in model.parameters())
print(f"Total number of parameters: {total_params:,}")
# 权重共享(weight tying)
print("Token embedding layer shape:", model.tok_emb.weight.shape)
print("Output layer shape:", model.out_head.weight.shape)
total_params_gpt2 = (
total_params - sum(p.numel()
for p in model.out_head.parameters())
)
print(f"Number of trainable parameters "
f"considering weight tying: {total_params_gpt2:,}")
# 计算模型参数的内存需求
total_size_bytes = total_params * 4 # 假设每个参数是4字节的32位浮点数
total_size_mb = total_size_bytes / 1024 / 1024
print(f"Total size of the model: {total_size_mb:.2f} MB")
"""
Input: tensor([[6109, 3626, 6100, 345],
[6109, 1110, 6622, 257]])
Output: torch.Size([2, 4, 50257]) tensor([[[ 0.3613, 0.4222, -0.0711, ..., 0.3483, 0.4661, -0.2838],
[-0.1792, -0.5660, -0.9485, ..., 0.0477, 0.5181, -0.3168],
[ 0.7120, 0.0332, 0.1085, ..., 0.1018, -0.4327, -0.2553],
[-1.0076, 0.3418, -0.1190, ..., 0.7195, 0.4023, 0.0532]],
[[-0.2564, 0.0900, 0.0335, ..., 0.2659, 0.4454, -0.6806],
[ 0.1230, 0.3653, -0.2074, ..., 0.7705, 0.2710, 0.2246],
[ 1.0558, 1.0318, -0.2800, ..., 0.6936, 0.3205, -0.3178],
[-0.1565, 0.3926, 0.3288, ..., 1.2630, -0.1858, 0.0388]]],
grad_fn=<UnsafeViewBackward0>)
Total number of parameters: 163,009,536
Token embedding layer shape: torch.Size([50257, 768])
Output layer shape: torch.Size([50257, 768])
Number of trainable parameters considering weight tying: 124,412,160
Total size of the model: 621.83 MB
"""
代码清单4-8 生成文本
- 层归一化:可以确保每个层的输出具有一致的均值和方差,从而稳定训练过程。
- 减去均值,再除以方差的平方根(也就是标准差);
- 归一化后的层输出包含负值,其均值为 0,方差为 1
- 快捷连接(跳跃连接/残差连接):是通过将一层的输出直接传递到更深层来跳过一个或多个层的连接,它能帮助缓解在训练深度神经网络(如大语言模型)时遇到的梯度消失问题。
- Transformer块:融合了掩码多头注意力模块和使用GELU激活函数的全连接前馈神经网络。
- GPT模型:是具有许多重复Transformer块的大语言模型,这些Transformer块有数百万到数十亿个参数。
import torch
import torch.nn as nn
import tiktoken
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
# 减少投影维度以匹配所需的输出维度
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# 使用一个线性层来组合头的输出
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape # (2, 6, 3)
# shape: (b, num_tokens, d_out)
keys = self.W_key(x) # (2, 6, 3) @ (3, 2) => (2, 6, 2)
queries = self.W_query(x)
values = self.W_value(x)
# 通过添加一个 num_heads 维 度来隐式地分隔矩阵。然后 展开最后一个维度:
# (b, num _tokens, d_ out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) # (2, 6, 2) => (2, 6, 2, 1)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
)
# 从形状(b, num_tokens, num_heads, head_dim) 转换到(b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2) # (2, 6, 2, 1) => (2, 2, 6, 1)
values = values.transpose(1, 2)
queries = queries.transpose(1, 2)
# 计算每个头的点积
attn_scores = queries @ keys.transpose(2, 3) # (2, 2, 6, 1) @ (2, 2, 1, 6) => (2, 2, 6, 6)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# 张量形状: (b, num_tokens, n_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2) # (2, 2, 6, 6) @ (2, 2, 6, 1) => (2, 2, 6, 1) => (2, 6, 2, 1)
# 组合头,其中 self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(
b, num_tokens, self.d_out
) # (2, 6, 2, 1) => (2, 6, 2)
# 添加一个可选 的线性投影
context_vec = self.out_proj(context_vec)
return context_vec
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
shortcut = x # 在注意力块中添加快捷连接
"""
层归一化(LayerNorm)应用于这两个组件之前,而 dropout 应用于这两个组件之后,
以便对模型进行正则化并防止过拟合。这种方法也被称为前层归一化(Pre-LayerNorm)。
"""
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
"""
每个组件后面都跟着一个快捷连接,将块 的输入加到其输出上。
这个关键特性有助于在训练过程中使梯度在网络中流动,并改善深度模型的学习效果
"""
x = x + shortcut # 将原始输入添加回来
shortcut = x # 在前馈层中添加快捷链接
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # 将原始输入添加回来
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
# 词元嵌入层和位置嵌入层负责将输入的词元索引转换为稠密向量,并添加位置信息
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
# LayerNorm层将Transformer块的输出标准化,以稳定学习过程
self.final_norm = LayerNorm(cfg["emb_dim"])
# 无偏置的线性输出头,将Transformer的输出投影到分词器的词汇空间,为词汇中的每个词元生成分数logits
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx) # 词元嵌入层
pos_embeds = self.pos_emb(
torch.arange(seq_len, device=in_idx.device)
) # 位置嵌入层
x = tok_embeds + pos_embeds
x = self.drop_emb(x) # dropout
x = self.trf_blocks(x) # transformer blocks
x = self.final_norm(x) # 最终层归一化
# 计算logits,这些logits代表下一个词元的非归一化概率
# 最后一个线性层会将每个词元向量嵌入 50257 维的嵌入层,其中 50257 是词汇表的大小
# 这个线性输出层将 Transformer 的输出映射到一个高维空间,以预测序列中的下一个词元
logits = self.out_head(x) # 线性输出层
return logits
# 入参 idx 是当前文本的索引数组,其形状为(batch, n_tokens)
def generate_text_simple(model, idx,
max_new_tokens, context_size):
for _ in range(max_new_tokens):
# 将当前文本截断至支持的长度。如果大语言 模型仅支持 5 个词元,
# 但此时文本长度为 10, 则只有最后 5 个词元会被用作输入文本
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
# 只关注最后一个输出的内容,因此形状会从(batch, n_token, vocab_size) 变为(batch, vocab_size)
logits = logits[:, -1, :]
probas = torch.softmax(logits, dim=-1) # probas 的形状为(batch, vocab_size)
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # idx_next 的形状为(batch, 1)
idx = torch.cat((idx, idx_next), dim=1) # 将计算出的下一个字符的索引添加 到索引数组中,此时 idx 的形状会变为(batch, n_tokens+1)
return idx
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 1024,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}
start_context = "Hello, I am"
tokenizer = tiktoken.get_encoding("gpt2")
encoded = tokenizer.encode(start_context)
print("encoded:", encoded)
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # 添加 batch 维度
print("encoded_tensor:", encoded_tensor.shape, encoded_tensor)
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval() # 将模型设置为.eval()模式,禁用诸如 dropout 等只在训练期间使用的随机组件
out = generate_text_simple(
model=model,
idx=encoded_tensor,
max_new_tokens=6,
context_size=GPT_CONFIG_124M["context_length"]
)
print("Output:", len(out[0]), out)
decoded_text = tokenizer.decode(out.squeeze(0).tolist())
print(decoded_text)
"""
encoded: [15496, 11, 314, 716]
encoded_tensor: torch.Size([1, 4]) tensor([[15496, 11, 314, 716]])
Output: 10 tensor([[15496, 11, 314, 716, 27018, 24086, 47843, 30961, 42348, 7267]])
Hello, I am Featureiman Byeswickattribute argue
"""
章节5.1.2 负平均对数概率&交叉损失熵
训练大语言模型的目标是最大化正确词元的可能性,这涉及增大其相对于其他词元的概率。通过 这种方式,可以确保大语言模型始终选择目标词元(实质上是句子中的下一个单词)作为它生成 的下一个词元。
|
反向传播 |
|
如何最大化与目标词元对应的 softmax 概率值呢?大致思路是,更新模型权重,以便模型为我们想要生成的相应词元 ID 输出更高的值。权重更新是通过一种称为反向传播的过程完成的,这是训练深度神经网络的标准技术。 反向传播需要一个损失函数,它会计算模型的预测输出(在这里是与目标词元 ID 对应的 概率)与实际期望输出之间的差异。这个损失函数衡量的是模型的预测与目标值之间的偏差。 |

|
交叉熵损失 |
|
在机器学习和深度学习中,交叉熵损失是一种常用的度量方式,用于衡量两个概率分布 之间的差异——通常是标签(在这里是数据集中的词元)的真实分布和模型生成的预测分布(例如,由大语言模型生成的词元概率)之间的差异。 在机器学习的背景下,特别是在像 PyTorch 这样的框架中,交叉熵函数可以对离散的结 果进行度量,类似于给定模型生成的词元概率时目标词元的负平均对数概率。因此,在实践 中,“交叉熵”和“负平均对数概率”这两个术语是相关的,且经常可以互换使用。 |
|
困惑度 |
|
困惑度通常与交叉熵损失一起用来评估模型在诸如语言建模等任务中的性能。它可以提 供一种更易解释的方式来理解模型在预测序列中的下一个词元时的不确定性。 困惑度可以衡量模型预测的概率分布与数据集中实际词汇分布的匹配程度。与损失类 似,较低的困惑度表明模型的预测更接近实际分布。 困惑度可以通过 perplexity = torch.exp(loss)计算得出,在先前计算的损失上应 用该公式会得到 tensor(48725.8203)。 困惑度通常被认为比原始损失值更易于解释,因为它表示模型在每一步中对于有效词汇 量的不确定性。在给定的示例中,这意味着模型不确定在词汇表的 48 725 个词元中应该生成 哪个来作为下一个词元。 |
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval() # 将模型设置为.eval()模式,禁用诸如 dropout 等只在训练期间使用的随机组件
tokenizer = tiktoken.get_encoding("gpt2")
inputs = torch.tensor([[16833, 3626, 6100], # ["every effort moves",
[40, 1107, 588]]) # "I really like"]
targets = torch.tensor([[3626, 6100, 345 ], # [" effort moves you",
[1107, 588, 11311]]) # " really like chocolate"])
# 1. logits
with torch.no_grad():
logits = model(inputs)
# 2. 概率
probas = torch.softmax(logits, dim=-1)
print(probas.shape)
token_ids = torch.argmax(probas, dim=-1, keepdim=True)
#print("Token IDs:", token_ids)
print(f"Targets batch 1: {token_ids_to_text(targets[0], tokenizer)}")
print(f"Outputs batch 1: {token_ids_to_text(token_ids[0].flatten(), tokenizer)}")
# 3. 目标概率
text_idx = 0
target_probas_1 = probas[text_idx, [0,1,2], targets[text_idx]]
print("Text 1:", target_probas_1)
text_idx = 1
target_probas_2 = probas[text_idx, [0,1,2], targets[text_idx]]
print("Text 2:", target_probas_2)
# 4. 对数概率
log_probas = torch.log(torch.cat((target_probas_1, target_probas_2)))
print(log_probas)
# 5. 平均对数概率
avg_log_probas = torch.mean(log_probas)
print(avg_log_probas)
# 6. 负平均对数概率
"""
负平均对数概率就是需要计算的损失。
目标是通过在训练过程中更新模型的权重,使平均对数概率尽可能接近 0。
然而,在深度 学习中,通常的做法不是将平均对数概率升至 0,而是将负平均对数概率降至 0。
"""
net_avg_log_probas = avg_log_probas * -1
print(net_avg_log_probas)
# 交叉熵损失
logits_flat = logits.flatten(0, 1)
targets_flat = targets.flatten()
print("Flattened logits:", logits_flat.shape)
print("Flattened targets:", targets_flat.shape)
loss = torch.nn.functional.cross_entropy(logits_flat, targets_flat)
print(loss)
"""
tensor([[16833, 3626, 6100, 345]])
tensor([[ 40, 1107, 588, 11311]])
torch.Size([2, 3, 50257])
Targets batch 1: effort moves you
Outputs batch 1: Armed heNetflix
Text 1: tensor([7.4540e-05, 3.1061e-05, 1.1563e-05])
Text 2: tensor([1.0337e-05, 5.6776e-05, 4.7559e-06])
tensor([ -9.5042, -10.3796, -11.3677, -11.4798, -9.7764, -12.2561])
tensor(-10.7940)
tensor(10.7940)
Flattened logits: torch.Size([6, 50257])
Flattened targets: torch.Size([6])
tensor(10.7940)
"""代码清单5-2 计算训练集和验证集的损失
import torch
import torch.nn as nn
import tiktoken
from torch.utils.data import Dataset, DataLoader
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
# 减少投影维度以匹配所需的输出维度
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# 使用一个线性层来组合头的输出
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape # (2, 6, 3)
# shape: (b, num_tokens, d_out)
keys = self.W_key(x) # (2, 6, 3) @ (3, 2) => (2, 6, 2)
queries = self.W_query(x)
values = self.W_value(x)
# 通过添加一个 num_heads 维 度来隐式地分隔矩阵。然后 展开最后一个维度:
# (b, num _tokens, d_ out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) # (2, 6, 2) => (2, 6, 2, 1)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
)
# 从形状(b, num_tokens, num_heads, head_dim) 转换到(b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2) # (2, 6, 2, 1) => (2, 2, 6, 1)
values = values.transpose(1, 2)
queries = queries.transpose(1, 2)
# 计算每个头的点积
attn_scores = queries @ keys.transpose(2, 3) # (2, 2, 6, 1) @ (2, 2, 1, 6) => (2, 2, 6, 6)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# 张量形状: (b, num_tokens, n_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2) # (2, 2, 6, 6) @ (2, 2, 6, 1) => (2, 2, 6, 1) => (2, 6, 2, 1)
# 组合头,其中 self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(
b, num_tokens, self.d_out
) # (2, 6, 2, 1) => (2, 6, 2)
# 添加一个可选 的线性投影
context_vec = self.out_proj(context_vec)
return context_vec
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
shortcut = x # 在注意力块中添加快捷连接
"""
层归一化(LayerNorm)应用于这两个组件之前,而 dropout 应用于这两个组件之后,
以便对模型进行正则化并防止过拟合。这种方法也被称为前层归一化(Pre-LayerNorm)。
"""
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
"""
每个组件后面都跟着一个快捷连接,将块 的输入加到其输出上。
这个关键特性有助于在训练过程中使梯度在网络中流动,并改善深度模型的学习效果
"""
x = x + shortcut # 将原始输入添加回来
shortcut = x # 在前馈层中添加快捷链接
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # 将原始输入添加回来
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
# 词元嵌入层和位置嵌入层负责将输入的词元索引转换为稠密向量,并添加位置信息
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
# LayerNorm层将Transformer块的输出标准化,以稳定学习过程
self.final_norm = LayerNorm(cfg["emb_dim"])
# 无偏置的线性输出头,将Transformer的输出投影到分词器的词汇空间,为词汇中的每个词元生成分数logits
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx) # 词元嵌入层
pos_embeds = self.pos_emb(
torch.arange(seq_len, device=in_idx.device)
) # 位置嵌入层
x = tok_embeds + pos_embeds
x = self.drop_emb(x) # dropout
x = self.trf_blocks(x) # transformer blocks
x = self.final_norm(x) # 最终层归一化
# 计算logits,这些logits代表下一个词元的非归一化概率
# 最后一个线性层会将每个词元向量嵌入 50257 维的嵌入层,其中 50257 是词汇表的大小
# 这个线性输出层将 Transformer 的输出映射到一个高维空间,以预测序列中的下一个词元
logits = self.out_head(x) # 线性输出层
return logits
# 入参 idx 是当前文本的索引数组,其形状为(batch, n_tokens)
def generate_text_simple(model, idx,
max_new_tokens, context_size):
for _ in range(max_new_tokens):
# 将当前文本截断至支持的长度。如果大语言 模型仅支持 5 个词元,
# 但此时文本长度为 10, 则只有最后 5 个词元会被用作输入文本
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
# 只关注最后一个输出的内容,因此形状会从(batch, n_token, vocab_size) 变为(batch, vocab_size)
logits = logits[:, -1, :]
probas = torch.softmax(logits, dim=-1) # probas 的形状为(batch, vocab_size)
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # idx_next 的形状为(batch, 1)
idx = torch.cat((idx, idx_next), dim=1) # 将计算出的下一个字符的索引添加 到索引数组中,此时 idx 的形状会变为(batch, n_tokens+1)
return idx
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # 使用 .unsqueeze(0) 添加batch维度
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0) # 移除batch维度
return tokenizer.decode(flat.tolist())
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt)
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=256, stride=128, shuffle=True, drop_last=True,
num_workers=0):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
# 交叉熵损失
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(
logits.flatten(0, 1), target_batch.flatten()
)
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
total_loss += loss.item()
else:
break
return total_loss / num_batches
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 256,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.eval() # 将模型设置为.eval()模式,禁用诸如 dropout 等只在训练期间使用的随机组件
tokenizer = tiktoken.get_encoding("gpt2")
file_path = "the-verdict.txt"
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
total_characters = len(text_data)
total_tokens = len(tokenizer.encode(text_data))
print("Characters:", total_characters)
print("Tokens:", total_tokens)
train_ratio = 0.9
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=False,
shuffle=False,
num_workers=0
)
print("Train loader:")
for x, y in train_loader:
print(x.shape, y.shape)
print("\nValidation loader:")
for x, y in val_loader:
print(x.shape, y.shape)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
"""
Characters: 20479
Tokens: 5145
Train loader:
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
torch.Size([2, 256]) torch.Size([2, 256])
Validation loader:
torch.Size([2, 256]) torch.Size([2, 256])
Training loss: 10.987581782870823
Validation loss: 10.981117248535156
"""
代码清单5-3 预训练
步骤:从遍历每个训练轮次开始,处理批次,重置梯度,计算损失和新梯度,更新权重,最后以监控步骤(包括打印损失、生成文本样本等操作)结束。
在每次循环中,计算每个训练集批次的损失以确定损失梯度,然后使用这些梯度来更新模型权重,以使训练集损失最小化。
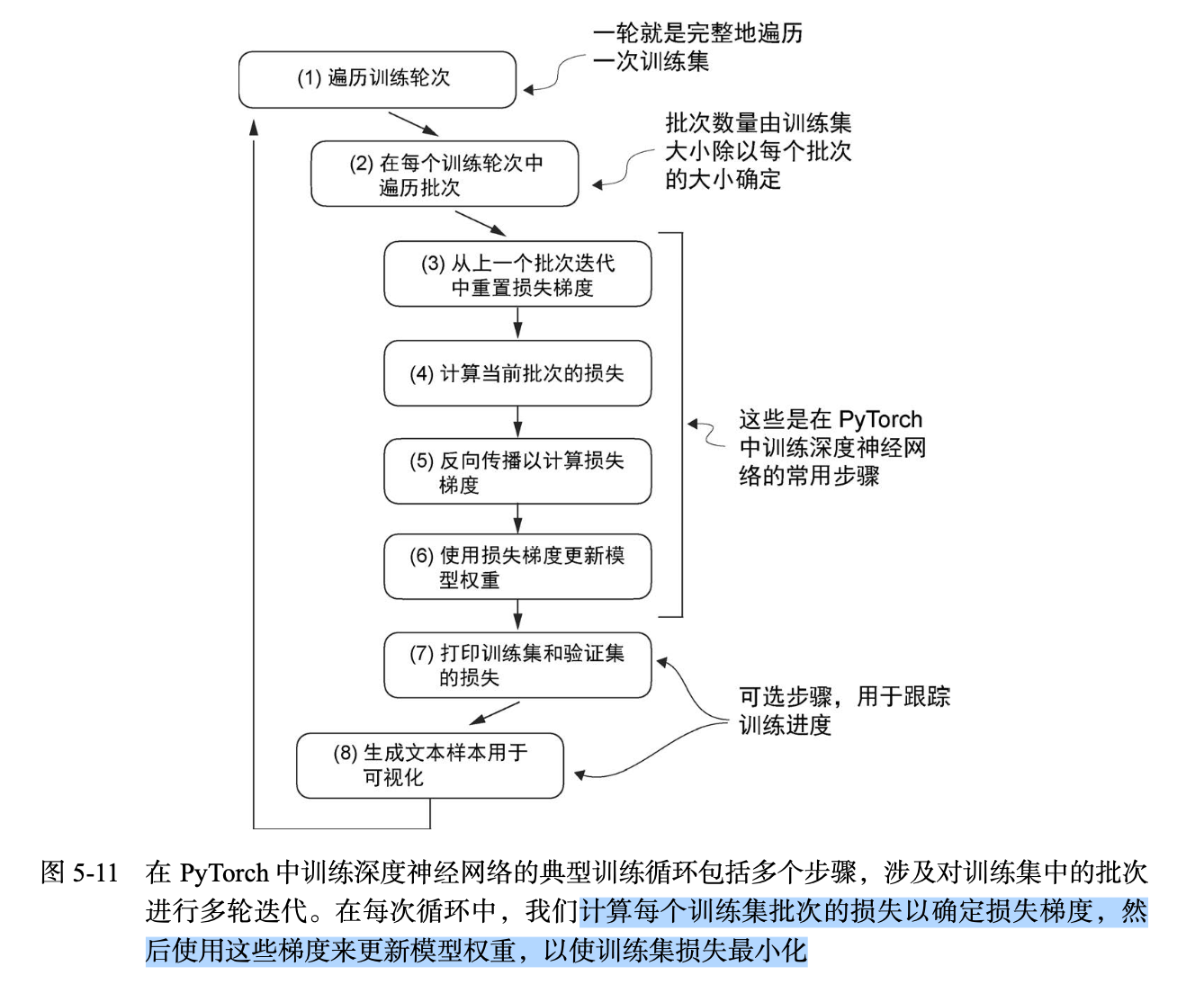
import torch
import torch.nn as nn
import tiktoken
from torch.utils.data import Dataset, DataLoader
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
# 减少投影维度以匹配所需的输出维度
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# 使用一个线性层来组合头的输出
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape # (2, 6, 3)
# shape: (b, num_tokens, d_out)
keys = self.W_key(x) # (2, 6, 3) @ (3, 2) => (2, 6, 2)
queries = self.W_query(x)
values = self.W_value(x)
# 通过添加一个 num_heads 维 度来隐式地分隔矩阵。然后 展开最后一个维度:
# (b, num _tokens, d_ out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) # (2, 6, 2) => (2, 6, 2, 1)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
)
# 从形状(b, num_tokens, num_heads, head_dim) 转换到(b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2) # (2, 6, 2, 1) => (2, 2, 6, 1)
values = values.transpose(1, 2)
queries = queries.transpose(1, 2)
# 计算每个头的点积
attn_scores = queries @ keys.transpose(2, 3) # (2, 2, 6, 1) @ (2, 2, 1, 6) => (2, 2, 6, 6)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# 张量形状: (b, num_tokens, n_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2) # (2, 2, 6, 6) @ (2, 2, 6, 1) => (2, 2, 6, 1) => (2, 6, 2, 1)
# 组合头,其中 self.d_out = self.num_heads * self.head_dim
context_vec = context_vec.contiguous().view(
b, num_tokens, self.d_out
) # (2, 6, 2, 1) => (2, 6, 2)
# 添加一个可选 的线性投影
context_vec = self.out_proj(context_vec)
return context_vec
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
shortcut = x # 在注意力块中添加快捷连接
"""
层归一化(LayerNorm)应用于这两个组件之前,而 dropout 应用于这两个组件之后,
以便对模型进行正则化并防止过拟合。这种方法也被称为前层归一化(Pre-LayerNorm)。
"""
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
"""
每个组件后面都跟着一个快捷连接,将块 的输入加到其输出上。
这个关键特性有助于在训练过程中使梯度在网络中流动,并改善深度模型的学习效果
"""
x = x + shortcut # 将原始输入添加回来
shortcut = x # 在前馈层中添加快捷链接
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # 将原始输入添加回来
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
# 词元嵌入层和位置嵌入层负责将输入的词元索引转换为稠密向量,并添加位置信息
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
# LayerNorm层将Transformer块的输出标准化,以稳定学习过程
self.final_norm = LayerNorm(cfg["emb_dim"])
# 无偏置的线性输出头,将Transformer的输出投影到分词器的词汇空间,为词汇中的每个词元生成分数logits
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx) # 词元嵌入层
pos_embeds = self.pos_emb(
torch.arange(seq_len, device=in_idx.device)
) # 位置嵌入层
x = tok_embeds + pos_embeds
x = self.drop_emb(x) # dropout
x = self.trf_blocks(x) # transformer blocks
x = self.final_norm(x) # 最终层归一化
# 计算logits,这些logits代表下一个词元的非归一化概率
# 最后一个线性层会将每个词元向量嵌入 50257 维的嵌入层,其中 50257 是词汇表的大小
# 这个线性输出层将 Transformer 的输出映射到一个高维空间,以预测序列中的下一个词元
logits = self.out_head(x) # 线性输出层
return logits
# 入参 idx 是当前文本的索引数组,其形状为(batch, n_tokens)
def generate_text_simple(model, idx,
max_new_tokens, context_size):
for _ in range(max_new_tokens):
# 将当前文本截断至支持的长度。如果大语言 模型仅支持 5 个词元,
# 但此时文本长度为 10, 则只有最后 5 个词元会被用作输入文本
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
# 只关注最后一个输出的内容,因此形状会从(batch, n_token, vocab_size) 变为(batch, vocab_size)
logits = logits[:, -1, :]
probas = torch.softmax(logits, dim=-1) # probas 的形状为(batch, vocab_size)
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # idx_next 的形状为(batch, 1)
idx = torch.cat((idx, idx_next), dim=1) # 将计算出的下一个字符的索引添加 到索引数组中,此时 idx 的形状会变为(batch, n_tokens+1)
return idx
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # 使用 .unsqueeze(0) 添加batch维度
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0) # 移除batch维度
return tokenizer.decode(flat.tolist())
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt)
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=256, stride=128, shuffle=True, drop_last=True,
num_workers=0):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
# 交叉熵损失
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch = input_batch.to(device)
target_batch = target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(
logits.flatten(0, 1), target_batch.flatten()
)
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
total_loss += loss.item()
else:
break
return total_loss / num_batches
def train_model_simple(model, train_loader, val_loader,
optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
for epoch in range(num_epochs):
# 模型切换到训练模式
model.train()
for input_batch, target_batch in train_loader:
# 1. 从上一个批次迭代中重置损失梯度
optimizer.zero_grad() # 重置上一个批次迭代中的损失梯度
# 2. 计算当前批次的损失
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
# 3. 反向传播以计算损失梯度
loss.backward()
# 4. 使用损失梯度更新模型权重
optimizer.step()
tokens_seen += input_batch.numel()
global_step += 1
if global_step % eval_freq == 0: # 可选的评估步骤,用于跟踪训练进度
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, "
f"Val loss {val_loss:.3f}"
)
generate_and_print_sample( # 可选的步骤,生成文本样本用于可视化
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
# 模型切换到评估模式
model.eval() # 在评估阶段禁用 dropout, 以产出稳定且可复现的结果
with torch.no_grad(): # 评估阶段也会禁用梯度跟踪,因为这是不需要的,而且这样可以减少计算开销
train_loss = calc_loss_loader(
train_loader, model, device, num_batches=eval_iter
)
val_loss = calc_loss_loader(
val_loader, model, device, num_batches=eval_iter
)
model.train() # 恢复训练模式,开启 dropout
return train_loss, val_loss
def generate_and_print_sample(model, tokenizer, device, start_context):
model.eval()
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device)
with torch.no_grad():
token_ids = generate_text_simple(
model=model, idx=encoded,
max_new_tokens=50, context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer)
print(decoded_text.replace("\n", " "))
model.train()
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(epochs_seen, val_losses, linestyle="-.", label="Validation loss")
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True))
ax1.legend()
ax2 = ax1.twiny() # 创建共享同一个y轴的第二个x轴
ax2.plot(tokens_seen, train_losses, alpha=0) # 对齐刻度线的隐藏图标
ax2.set_xlabel("Tokens seen")
fig.tight_layout()
plt.savefig("pretrain")
plt.show()
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 256,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}
file_path = "the-verdict.txt"
with open(file_path, "r", encoding="utf-8") as file:
text_data = file.read()
train_ratio = 0.9
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
train_loader = create_dataloader_v1(
train_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=True,
shuffle=True,
num_workers=0
)
val_loader = create_dataloader_v1(
val_data,
batch_size=2,
max_length=GPT_CONFIG_124M["context_length"],
stride=GPT_CONFIG_124M["context_length"],
drop_last=False,
shuffle=False,
num_workers=0
)
torch.manual_seed(123)
tokenizer = tiktoken.get_encoding("gpt2")
model = GPTModel(GPT_CONFIG_124M)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
"""
Adam 优化器是训练深度神经网络的一种常见选择。
AdamW 是 Adam 的一个变体,它改进了权重衰减方法,旨在通过对较大的
权重进行惩罚来最小化模型复杂性并防止过拟合。
这种调整使得 AdamW 能够实现更有效的正则化和更好的泛化能力。
"""
optimizer = torch.optim.AdamW(
model.parameters(), # .parameters()方法返回模型的所有可训练权重参数
lr=0.0004,
weight_decay=0.1
)
num_epochs = 10
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context="Every effort moves you", tokenizer=tokenizer
)
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
"""
Ep 1 (Step 000000): Train loss 9.818, Val loss 9.929
Ep 1 (Step 000005): Train loss 8.065, Val loss 8.336
Every effort moves you,,,,,,,,,,,,.
Ep 2 (Step 000010): Train loss 6.622, Val loss 7.052
Ep 2 (Step 000015): Train loss 6.047, Val loss 6.600
Every effort moves you, and,, and,,,,,,, and,.
Ep 3 (Step 000020): Train loss 5.590, Val loss 6.476
Ep 3 (Step 000025): Train loss 5.539, Val loss 6.403
Every effort moves you, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and, and
Ep 4 (Step 000030): Train loss 5.168, Val loss 6.384
Ep 4 (Step 000035): Train loss 4.980, Val loss 6.377
Every effort moves you a a so a a a of the picture. Gisburn. Gisburn, and a, and a. "I the picture of the of the picture.
Ep 5 (Step 000040): Train loss 4.349, Val loss 6.256
Every effort moves you, I had been a--as of the--as of the of the of the, I had been--and it's had been, in the of the of the picture, in the picture. "I had been the picture of the of
Ep 6 (Step 000045): Train loss 4.027, Val loss 6.212
Ep 6 (Step 000050): Train loss 3.534, Val loss 6.149
Every effort moves you know the
Ep 7 (Step 000055): Train loss 3.549, Val loss 6.167
Ep 7 (Step 000060): Train loss 2.736, Val loss 6.133
Every effort moves you know the fact, and I felt of the picture, and I felt. "I he was his pictures-c.
Ep 8 (Step 000065): Train loss 2.292, Val loss 6.147
Ep 8 (Step 000070): Train loss 1.953, Val loss 6.210
Every effort moves you know," was not that the picture. "I had the last word. Gisburn's an! "Oh, I was _rose at my elbow and I had the donkey. "There were days when I
Ep 9 (Step 000075): Train loss 1.576, Val loss 6.218
Ep 9 (Step 000080): Train loss 1.239, Val loss 6.236
Every effort moves you know," was not that my hostess was "interesting": on that Mrs. "Yes--and by me to me to have to see a smile behind his pictures--as he had been his painting, a _j--because he had been his
Ep 10 (Step 000085): Train loss 0.953, Val loss 6.301
Every effort moves you?" "Yes--quite insensible to the irony. She wanted him vindicated--and by me!" "I didn't face that he had married her--the quality of the a fashionable painter--and by holding
"""
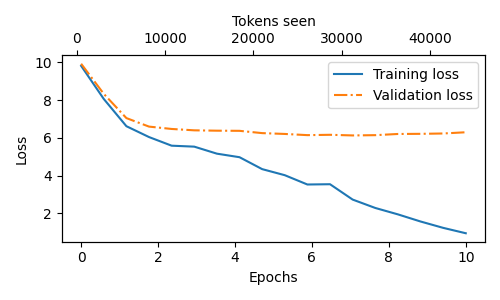
- 在训练开始阶段,训练集损失和验证集损失急剧下降,这表明模型正在学习。
- 然而,在第二轮之后,训练集损失继续下降,验证集损失则停滞不前。这表明模型仍在学习,但在第二轮之后开始对训练集过拟合,经常逐字记忆训练集中的段落。(验证集损失远大于训练集损失,表明模型对训练数据过拟合。)
章节5.3.1 温度缩放
温度缩放指的是将 logits 5 除以一个大于 0 的数
next_token_logits = torch.tensor(
[4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]
)
probas = torch.softmax(next_token_logits, dim=0)
next_token_id = torch.argmax(probas).item()
print(next_token_id)
torch.manual_seed(123)
next_token_id = torch.multinomial(probas, num_samples=1).item()
print(next_token_id)
def print_sampled_tokens(probas):
torch.manual_seed(123)
sample = [torch.multinomial(probas, num_samples=1).item()
for i in range(1_000)]
sampled_ids = torch.bincount(torch.tensor(sample))
print("sampled_ids:", sampled_ids)
for i, freq in enumerate(sampled_ids):
print(f"{freq} x {i}")
print_sampled_tokens(probas)
def softmax_with_temperature(logits, temperature):
# 温度缩放指的是将 logits 除以一个大于 0 的数
scaled_logits = logits / temperature
return torch.softmax(scaled_logits, dim=0)
vocab = {
"closer": 0,
"every": 1,
"effort": 2,
"forward": 3,
"inches": 4,
"moves": 5,
"pizza": 6,
"toward": 7,
"you": 8,
}
inverse_vocab = {v: k for k, v in vocab.items()}
temperatures = [1, 0.1, 5]
scaled_probas = [softmax_with_temperature(next_token_logits, T) for T in temperatures]
x = torch.arange(len(vocab))
bar_width = 0.15
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(5,3))
for i, T in enumerate(temperatures):
rects = ax.bar(x + i * bar_width, scaled_probas[i],
bar_width, label=f'Temperature = {T}')
ax.set_ylabel('Probability')
ax.set_xticks(x)
ax.set_xticklabels(vocab.keys(), rotation=90)
ax.legend()
plt.tight_layout()
plt.savefig("argmax_multinomial")
plt.show()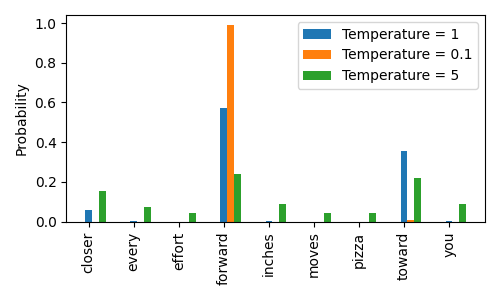
- 温度为 1 表示词汇表中每个词元的未缩放概率分数。
- 将温度降低到 0.1 会使分布更加集中,因此最可能的词元(这里是 forward)将具有更高的概率分数,接近于 argmax 函数的行为。
- 同样,将温度提高到 5 会使分布更加均匀,使得其他词元更容易被选中。这可以为生成的文本增加更多变化, 但也更容易生成无意义的文本。
章节5.3.2 Top-k采样
通过与概率采样和温度缩放相结合,Top-k 采样可以改善文本生成结果。在 Top-k 采样中, 可以将采样的词元限制在前 k 个最可能的词元上,并通过掩码概率分数的方式来排除其他词元。
Top-k 方法用负无穷值(-inf)替换所有未选择的 logits,因此在计算 softmax 值时,非前 k 词元的概率分数为 0,剩余的概率总和为 1。(在实现因果注意力模块中使用过这种掩码技巧。)

import torch
next_token_logits = torch.tensor(
[4.51, 0.89, -1.90, 6.75, 1.63, -1.62, -1.89, 6.28, 1.79]
)
top_k = 3
top_logits, top_pos = torch.topk(next_token_logits, top_k)
print("Top logits: ", top_logits)
print("Top positions: ", top_pos)
new_logits = torch.where(
condition=next_token_logits < top_logits[-1], # 识别出比前3个logits值中最低的logits值还低的logits值
input=torch.tensor(float('-inf')), # 给这些更低的logits值赋值-inf
other=next_token_logits # 保留所有其他词元的原始logits值
)
print(new_logits)
topk_probas = torch.softmax(new_logits, dim=0)
print(topk_probas)
"""
Top logits: tensor([6.7500, 6.2800, 4.5100])
Top positions: tensor([3, 7, 0])
tensor([4.5100, -inf, -inf, 6.7500, -inf, -inf, -inf, 6.2800, -inf])
tensor([0.0615, 0.0000, 0.0000, 0.5775, 0.0000, 0.0000, 0.0000, 0.3610, 0.0000])
"""代码清单5-4 结合温度缩放和top-k采样的文本生成
def generate(model, idx, max_new_tokens, context_size,
temperature=0.0, top_k=None, eos_id=None):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :] # 只关注最后一个时间步
# 使用top-k采样筛选logits
if top_k is not None:
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(
condition=logits < min_val,
input=torch.tensor(float('-inf')).to(logits.device),
other=logits
)
# 使用温度缩放
if temperature > 0.0:
logits = logits / temperature
# New (not in book): numerical stability tip to get equivalent results on mps device
# subtract rowwise max before softmax
logits = logits - logits.max(dim=-1, keepdim=True).values
probas = torch.softmax(logits, dim=-1)
idx_next = torch.multinomial(probas, num_samples=1)
else:
# 当禁用温度缩放时,执行贪心解码,选取下一个词元
idx_next = torch.argmax(logits, dim=-1, keepdim=True)
# 如果遇到序列结束词元,则提前停止生成
if idx_next == eos_id:
break
idx = torch.cat((idx, idx_next), dim=1)
return idx
model.eval()
token_ids = generate(
model=model,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=15,
context_size=GPT_CONFIG_124M["context_length"],
top_k=25,
temperature=1.4
)章节5.5 从OpenAI加载GPT-2模型权重
import torch
import torch.nn as nn
import tiktoken
from torch.utils.data import Dataset, DataLoader
import numpy as np
import json
import os
import tensorflow as tf
def download_and_load_gpt2(model_size, models_dir):
# Validate model size
allowed_sizes = ("124M", "355M", "774M", "1558M")
if model_size not in allowed_sizes:
raise ValueError(f"Model size not in {allowed_sizes}")
# Define paths
model_dir = os.path.join(models_dir, model_size)
base_url = "https://openaipublic.blob.core.windows.net/gpt-2/models"
filenames = [
"checkpoint", "encoder.json", "hparams.json",
"model.ckpt.data-00000-of-00001", "model.ckpt.index",
"model.ckpt.meta", "vocab.bpe"
]
# Download files
# os.makedirs(model_dir, exist_ok=True)
# for filename in filenames:
# file_url = os.path.join(base_url, model_size, filename)
# file_path = os.path.join(model_dir, filename)
# download_file(file_url, file_path)
# Load settings and params
tf_ckpt_path = tf.train.latest_checkpoint(model_dir)
settings = json.load(open(os.path.join(model_dir, "hparams.json")))
params = load_gpt2_params_from_tf_ckpt(tf_ckpt_path, settings)
return settings, params
def load_gpt2_params_from_tf_ckpt(ckpt_path, settings):
# Initialize parameters dictionary with empty blocks for each layer
params = {"blocks": [{} for _ in range(settings["n_layer"])]}
# Iterate over each variable in the checkpoint
for name, _ in tf.train.list_variables(ckpt_path):
# Load the variable and remove singleton dimensions
variable_array = np.squeeze(tf.train.load_variable(ckpt_path, name))
# Process the variable name to extract relevant parts
variable_name_parts = name.split("/")[1:] # Skip the 'model/' prefix
# Identify the target dictionary for the variable
target_dict = params
if variable_name_parts[0].startswith("h"):
layer_number = int(variable_name_parts[0][1:])
target_dict = params["blocks"][layer_number]
# Recursively access or create nested dictionaries
for key in variable_name_parts[1:-1]:
target_dict = target_dict.setdefault(key, {})
# Assign the variable array to the last key
last_key = variable_name_parts[-1]
target_dict[last_key] = variable_array
return params
class MultiHeadAttention(nn.Module):
def __init__(self, d_in, d_out,
context_length, dropout, num_heads, qkv_bias=False):
super().__init__()
assert (d_out % num_heads == 0), \
"d_out must be divisible by num_heads"
self.d_out = d_out
self.num_heads = num_heads
# 减少投影维度以匹配所需的输出维度
self.head_dim = d_out // num_heads
self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
# 使用一个线性层来组合头的输出
self.out_proj = nn.Linear(d_out, d_out)
self.dropout = nn.Dropout(dropout)
self.register_buffer(
"mask",
torch.triu(torch.ones(context_length, context_length),
diagonal=1)
)
def forward(self, x):
b, num_tokens, d_in = x.shape # (2, 6, 3)
# shape: (b, num_tokens, d_out)
keys = self.W_key(x) # (2, 6, 3) @ (3, 2) => (2, 6, 2)
queries = self.W_query(x)
values = self.W_value(x)
# 通过添加一个 num_heads 维 度来隐式地分隔矩阵。然后 展开最后一个维度:
# (b, num _tokens, d_ out) -> (b, num_tokens, num_heads, head_dim)
keys = keys.view(b, num_tokens, self.num_heads, self.head_dim) # (2, 6, 2) => (2, 6, 2, 1)
values = values.view(b, num_tokens, self.num_heads, self.head_dim)
queries = queries.view(
b, num_tokens, self.num_heads, self.head_dim
)
# 从形状(b, num_tokens, num_heads, head_dim) 转换到(b, num_heads, num_tokens, head_dim)
keys = keys.transpose(1, 2) # (2, 6, 2, 1) => (2, 2, 6, 1)
values = values.transpose(1, 2)
queries = queries.transpose(1, 2)
# 计算每个头的点积
attn_scores = queries @ keys.transpose(2, 3) # (2, 2, 6, 1) @ (2, 2, 1, 6) => (2, 2, 6, 6)
mask_bool = self.mask.bool()[:num_tokens, :num_tokens]
attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax(
attn_scores / keys.shape[-1]**0.5, dim=-1)
attn_weights = self.dropout(attn_weights)
# 张量形状: (b, num_tokens, n_heads, head_dim)
context_vec = (attn_weights @ values).transpose(1, 2) # (2, 2, 6, 6) @ (2, 2, 6, 1) => (2, 2, 6, 1) => (2, 6, 2, 1)
# 组合头,其中 self.d_out = self.num_heads * self.head_dim
#context_vec = context_vec.contiguous().view(
# b, num_tokens, self.d_out
#) # (2, 6, 2, 1) => (2, 6, 2)
context_vec = context_vec.reshape(b, num_tokens, self.d_out)
# 添加一个可选 的线性投影
context_vec = self.out_proj(context_vec)
return context_vec
class GELU(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return 0.5 * x * (1 + torch.tanh(
torch.sqrt(torch.tensor(2.0 / torch.pi)) *
(x + 0.044715 * torch.pow(x, 3))
))
class FeedForward(nn.Module):
def __init__(self, cfg):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(cfg["emb_dim"], 4 * cfg["emb_dim"]),
GELU(),
nn.Linear(4 * cfg["emb_dim"], cfg["emb_dim"]),
)
def forward(self, x):
return self.layers(x)
class LayerNorm(nn.Module):
def __init__(self, emb_dim):
super().__init__()
self.eps = 1e-5
self.scale = nn.Parameter(torch.ones(emb_dim))
self.shift = nn.Parameter(torch.zeros(emb_dim))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = x.var(dim=-1, keepdim=True, unbiased=False)
norm_x = (x - mean) / torch.sqrt(var + self.eps)
return self.scale * norm_x + self.shift
class TransformerBlock(nn.Module):
def __init__(self, cfg):
super().__init__()
self.att = MultiHeadAttention(
d_in=cfg["emb_dim"],
d_out=cfg["emb_dim"],
context_length=cfg["context_length"],
num_heads=cfg["n_heads"],
dropout=cfg["drop_rate"],
qkv_bias=cfg["qkv_bias"])
self.ff = FeedForward(cfg)
self.norm1 = LayerNorm(cfg["emb_dim"])
self.norm2 = LayerNorm(cfg["emb_dim"])
self.drop_shortcut = nn.Dropout(cfg["drop_rate"])
def forward(self, x):
# Shortcut connection for attention block
shortcut = x # 在注意力块中添加快捷连接
"""
层归一化(LayerNorm)应用于这两个组件之前,而 dropout 应用于这两个组件之后,
以便对模型进行正则化并防止过拟合。这种方法也被称为前层归一化(Pre-LayerNorm)。
"""
x = self.norm1(x)
x = self.att(x)
x = self.drop_shortcut(x)
"""
每个组件后面都跟着一个快捷连接,将块 的输入加到其输出上。
这个关键特性有助于在训练过程中使梯度在网络中流动,并改善深度模型的学习效果
"""
x = x + shortcut # 将原始输入添加回来
shortcut = x # 在前馈层中添加快捷链接
x = self.norm2(x)
x = self.ff(x)
x = self.drop_shortcut(x)
x = x + shortcut # 将原始输入添加回来
return x
class GPTModel(nn.Module):
def __init__(self, cfg):
super().__init__()
# 词元嵌入层和位置嵌入层负责将输入的词元索引转换为稠密向量,并添加位置信息
self.tok_emb = nn.Embedding(cfg["vocab_size"], cfg["emb_dim"])
self.pos_emb = nn.Embedding(cfg["context_length"], cfg["emb_dim"])
self.drop_emb = nn.Dropout(cfg["drop_rate"])
self.trf_blocks = nn.Sequential(
*[TransformerBlock(cfg) for _ in range(cfg["n_layers"])])
# LayerNorm层将Transformer块的输出标准化,以稳定学习过程
self.final_norm = LayerNorm(cfg["emb_dim"])
# 无偏置的线性输出头,将Transformer的输出投影到分词器的词汇空间,为词汇中的每个词元生成分数logits
self.out_head = nn.Linear(
cfg["emb_dim"], cfg["vocab_size"], bias=False
)
def forward(self, in_idx):
batch_size, seq_len = in_idx.shape
tok_embeds = self.tok_emb(in_idx) # 词元嵌入层
pos_embeds = self.pos_emb(
torch.arange(seq_len, device=in_idx.device)
) # 位置嵌入层
x = tok_embeds + pos_embeds
x = self.drop_emb(x) # dropout
x = self.trf_blocks(x) # transformer blocks
x = self.final_norm(x) # 最终层归一化
# 计算logits,这些logits代表下一个词元的非归一化概率
# 最后一个线性层会将每个词元向量嵌入 50257 维的嵌入层,其中 50257 是词汇表的大小
# 这个线性输出层将 Transformer 的输出映射到一个高维空间,以预测序列中的下一个词元
logits = self.out_head(x) # 线性输出层
return logits
# 入参 idx 是当前文本的索引数组,其形状为(batch, n_tokens)
def generate_text_simple(model, idx,
max_new_tokens, context_size):
for _ in range(max_new_tokens):
# 将当前文本截断至支持的长度。如果大语言 模型仅支持 5 个词元,
# 但此时文本长度为 10, 则只有最后 5 个词元会被用作输入文本
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
# 只关注最后一个输出的内容,因此形状会从(batch, n_token, vocab_size) 变为(batch, vocab_size)
logits = logits[:, -1, :]
probas = torch.softmax(logits, dim=-1) # probas 的形状为(batch, vocab_size)
idx_next = torch.argmax(probas, dim=-1, keepdim=True) # idx_next 的形状为(batch, 1)
idx = torch.cat((idx, idx_next), dim=1) # 将计算出的下一个字符的索引添加 到索引数组中,此时 idx 的形状会变为(batch, n_tokens+1)
return idx
def generate(model, idx, max_new_tokens, context_size,
temperature=0.0, top_k=None, eos_id=None):
for _ in range(max_new_tokens):
idx_cond = idx[:, -context_size:]
with torch.no_grad():
logits = model(idx_cond)
logits = logits[:, -1, :] # 只关注最后一个时间步
# 使用top-k采样筛选logits
if top_k is not None:
top_logits, _ = torch.topk(logits, top_k)
min_val = top_logits[:, -1]
logits = torch.where(
condition=logits < min_val,
input=torch.tensor(float('-inf')).to(logits.device),
other=logits
)
# 使用温度缩放
if temperature > 0.0:
logits = logits / temperature
# New (not in book): numerical stability tip to get equivalent results on mps device
# subtract rowwise max before softmax
logits = logits - logits.max(dim=-1, keepdim=True).values
probas = torch.softmax(logits, dim=-1)
idx_next = torch.multinomial(probas, num_samples=1)
else:
# 当禁用温度缩放时,执行贪心解码,选取下一个词元
idx_next = torch.argmax(logits, dim=-1, keepdim=True)
# 如果遇到序列结束词元,则提前停止生成
if idx_next == eos_id:
break
idx = torch.cat((idx, idx_next), dim=1)
return idx
def text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # 使用 .unsqueeze(0) 添加batch维度
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0) # 移除batch维度
return tokenizer.decode(flat.tolist())
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
def create_dataloader_v1(txt, batch_size=4, max_length=256, stride=128, shuffle=True, drop_last=True,
num_workers=0):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
# 交叉熵损失
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch)
loss = torch.nn.functional.cross_entropy(
logits.flatten(0, 1), target_batch.flatten()
)
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
total_loss += loss.item()
else:
break
return total_loss / num_batches
def train_model_simple(model, train_loader, val_loader,
optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
for epoch in range(num_epochs):
# 模型切换到训练模式
model.train()
for input_batch, target_batch in train_loader:
# 1. 从上一个批次迭代中重置损失梯度
optimizer.zero_grad() # 重置上一个批次迭代中的损失梯度
# 2. 计算当前批次的损失
loss = calc_loss_batch(
input_batch, target_batch, model, device
)
# 3. 反向传播以计算损失梯度
loss.backward()
# 4. 使用损失梯度更新模型权重
optimizer.step()
tokens_seen += input_batch.numel()
global_step += 1
if global_step % eval_freq == 0: # 可选的评估步骤,用于跟踪训练进度
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, "
f"Val loss {val_loss:.3f}"
)
generate_and_print_sample( # 可选的步骤,生成文本样本用于可视化
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
# 模型切换到评估模式
model.eval() # 在评估阶段禁用 dropout, 以产出稳定且可复现的结果
with torch.no_grad(): # 评估阶段也会禁用梯度跟踪,因为这是不需要的,而且这样可以减少计算开销
train_loss = calc_loss_loader(
train_loader, model, device, num_batches=eval_iter
)
val_loss = calc_loss_loader(
val_loader, model, device, num_batches=eval_iter
)
model.train() # 恢复训练模式,开启 dropout
return train_loss, val_loss
def generate_and_print_sample(model, tokenizer, device, start_context):
model.eval() # 模型切换到评估模式,关闭 dropout 之类的随机组件
context_size = model.pos_emb.weight.shape[0]
encoded = text_to_token_ids(start_context, tokenizer).to(device)
with torch.no_grad():
token_ids = generate_text_simple(
model=model, idx=encoded,
max_new_tokens=50, context_size=context_size
)
decoded_text = token_ids_to_text(token_ids, tokenizer)
print(decoded_text.replace("\n", " ")) # Compact print format
model.train()
import matplotlib.pyplot as plt
from matplotlib.ticker import MaxNLocator
def plot_losses(epochs_seen, tokens_seen, train_losses, val_losses):
fig, ax1 = plt.subplots(figsize=(5, 3))
ax1.plot(epochs_seen, train_losses, label="Training loss")
ax1.plot(epochs_seen, val_losses, linestyle="-.", label="Validation loss")
ax1.set_xlabel("Epochs")
ax1.set_ylabel("Loss")
ax1.xaxis.set_major_locator(MaxNLocator(integer=True))
ax1.legend(loc="upper right")
ax2 = ax1.twiny() # 创建共享同一个y轴的第二个x轴
ax2.plot(tokens_seen, train_losses, alpha=0) # 对齐刻度线的隐藏图标
ax2.set_xlabel("Tokens seen")
fig.tight_layout()
plt.savefig("pretrain")
#plt.show()
def assign(left, right):
if left.shape != right.shape:
raise ValueError(f"Shape mismatch. Left: {left.shape}, "
"Right: {right.shape}"
)
# 返回可训练的PyTorch参数
return torch.nn.Parameter(torch.tensor(right))
# 将模型的位置信息和词元嵌入权重设置为 params 中指定的值
def load_weights_into_gpt(gpt, params):
# pos_emb = nn.Embedding(...)
gpt.pos_emb.weight = assign(gpt.pos_emb.weight, params['wpe'])
# tok_emb = nn.Embedding(...)
gpt.tok_emb.weight = assign(gpt.tok_emb.weight, params['wte'])
for b in range(len(params["blocks"])): # 遍历模型中的每一个 Transformer 块
# np.split 将注意力和偏置权重 平均分为3个部分,分别用于查询组件、健组件和值组件
q_w, k_w, v_w = np.split(
(params["blocks"][b]["attn"]["c_attn"])["w"], 3, axis=-1)
# Attention().W_query = nn.Linear(...)
gpt.trf_blocks[b].att.W_query.weight = assign(
gpt.trf_blocks[b].att.W_query.weight, q_w.T)
gpt.trf_blocks[b].att.W_key.weight = assign(
gpt.trf_blocks[b].att.W_key.weight, k_w.T)
gpt.trf_blocks[b].att.W_value.weight = assign(
gpt.trf_blocks[b].att.W_value.weight, v_w.T)
q_b, k_b, v_b = np.split(
(params["blocks"][b]["attn"]["c_attn"])["b"], 3, axis=-1)
gpt.trf_blocks[b].att.W_query.bias = assign(
gpt.trf_blocks[b].att.W_query.bias, q_b)
gpt.trf_blocks[b].att.W_key.bias = assign(
gpt.trf_blocks[b].att.W_key.bias, k_b)
gpt.trf_blocks[b].att.W_value.bias = assign(
gpt.trf_blocks[b].att.W_value.bias, v_b)
# Attention().out_proj = nn.Linear(...)
gpt.trf_blocks[b].att.out_proj.weight = assign(
gpt.trf_blocks[b].att.out_proj.weight,
params["blocks"][b]["attn"]["c_proj"]["w"].T)
gpt.trf_blocks[b].att.out_proj.bias = assign(
gpt.trf_blocks[b].att.out_proj.bias,
params["blocks"][b]["attn"]["c_proj"]["b"])
# FeedForward().layers = nn.Sequential(nn.Linear(...), GELU(), nn.Linear(...))
gpt.trf_blocks[b].ff.layers[0].weight = assign(
gpt.trf_blocks[b].ff.layers[0].weight,
params["blocks"][b]["mlp"]["c_fc"]["w"].T)
gpt.trf_blocks[b].ff.layers[0].bias = assign(
gpt.trf_blocks[b].ff.layers[0].bias,
params["blocks"][b]["mlp"]["c_fc"]["b"])
gpt.trf_blocks[b].ff.layers[2].weight = assign(
gpt.trf_blocks[b].ff.layers[2].weight,
params["blocks"][b]["mlp"]["c_proj"]["w"].T)
gpt.trf_blocks[b].ff.layers[2].bias = assign(
gpt.trf_blocks[b].ff.layers[2].bias,
params["blocks"][b]["mlp"]["c_proj"]["b"])
# norm1 = LayerNorm(...)
# LayerNorm().scale = nn.Parameter(...)
# LayerNorm().shift = nn.Parameter(...)
gpt.trf_blocks[b].norm1.scale = assign(
gpt.trf_blocks[b].norm1.scale,
params["blocks"][b]["ln_1"]["g"])
gpt.trf_blocks[b].norm1.shift = assign(
gpt.trf_blocks[b].norm1.shift,
params["blocks"][b]["ln_1"]["b"])
# norm2 = LayerNorm(...)
gpt.trf_blocks[b].norm2.scale = assign(
gpt.trf_blocks[b].norm2.scale,
params["blocks"][b]["ln_2"]["g"])
gpt.trf_blocks[b].norm2.shift = assign(
gpt.trf_blocks[b].norm2.shift,
params["blocks"][b]["ln_2"]["b"])
# final_norm = LayerNorm(...)
gpt.final_norm.scale = assign(gpt.final_norm.scale, params["g"])
gpt.final_norm.shift = assign(gpt.final_norm.shift, params["b"])
# out_head = nn.Linear(...)
gpt.out_head.weight = assign(gpt.out_head.weight, params["wte"])
GPT_CONFIG_124M = {
"vocab_size": 50257,
"context_length": 256,
"emb_dim": 768,
"n_heads": 12,
"n_layers": 12,
"drop_rate": 0.1,
"qkv_bias": False
}
model_configs = {
"gpt2-small-124M": {"emb_dim":768, "n_layers":12, "n_heads":12},
"gpt2-medium-355M": {"emb_dim":1024, "n_layers":24, "n_heads":16},
"gpt2-large-774M": {"emb_dim":1280, "n_layers":36, "n_heads":20},
"gpt2-xl-1558M": {"emb_dim":1600, "n_layers":48, "n_heads":25},
}
model_name = "gpt2-small-124M"
NEW_CONFIG = GPT_CONFIG_124M.copy()
NEW_CONFIG.update(model_configs[model_name])
NEW_CONFIG.update({"context_length": 1024})
NEW_CONFIG.update({"qkv_bias": True})
# from gpt_download import download_and_load_gpt2
settings, params = download_and_load_gpt2(
model_size="124M", models_dir="gpt2"
)
gpt = GPTModel(NEW_CONFIG)
load_weights_into_gpt(gpt, params)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
gpt.to(device)
gpt.eval()
tokenizer = tiktoken.get_encoding("gpt2")
torch.manual_seed(123)
token_ids = generate(
model=gpt,
idx=text_to_token_ids("Every effort moves you", tokenizer).to(device),
max_new_tokens=25,
context_size=NEW_CONFIG["context_length"],
top_k=50,
temperature=1.0
)
print("Output:\n", token_ids_to_text(token_ids, tokenizer))
"""
"""更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)