
AI原生应用架构设计指南:从技术原理到企业级落地
在2025年云栖大会上,阿里云正式发布的《AI原生应用架构白皮书》,为正处于探索阶段的AI规模化落地提供了关键性的架构指引与工程范式。该白皮书基于40余位一线技术专家的实战积累,体系化地梳理了AI原生应用的11大核心架构要素,内容逾20万字。其核心贡献在于,不仅首次明确定义了AI原生应用的整体架构标准,还针对当前企业落地过程中的共性挑战——如大模型“黑盒”引发的输出不确定性、生产级场景下的响应延迟
在2025年云栖大会上,阿里云正式发布的《AI原生应用架构白皮书》,为正处于探索阶段的AI规模化落地提供了关键性的架构指引与工程范式。该白皮书基于40余位一线技术专家的实战积累,体系化地梳理了AI原生应用的11大核心架构要素,内容逾20万字。
其核心贡献在于,不仅首次明确定义了AI原生应用的整体架构标准,还针对当前企业落地过程中的共性挑战——如大模型“黑盒”引发的输出不确定性、生产级场景下的响应延迟、安全隐患以及资源成本管控等——提出了系统性的设计原则与可实施的工程方案。
本文将基于该白皮书,从架构设计的本质出发,深入解析其技术理念与实践路径,帮助企业构建可控、高效、可持续的AI应用能力,实现从概念验证到生产部署的平稳过渡。

一、AI 原生应用到底是什么?和传统应用差在哪?
很多人误以为,在传统App里加个聊天机器人入口就是“AI原生”了。这其实是“AI外挂”,本质没变。
真正的AI原生应用,是从架构设计的第一天起,就把大模型作为整个应用的“大脑”和“核心控制器”。业务逻辑不再由成千上万行固定代码定义,而是由“大脑”通过理解、推理、决策来动态生成。
简单来说,差别就在于:
-
传统应用 + AI接口:给一辆马车装上电动机,还是马车的底子。
-
AI原生应用:从一开始就设计成一辆特斯拉,电力驱动和智能驾驶是其与生俱来的核心。
二、AI 原生应用的 11 大要素
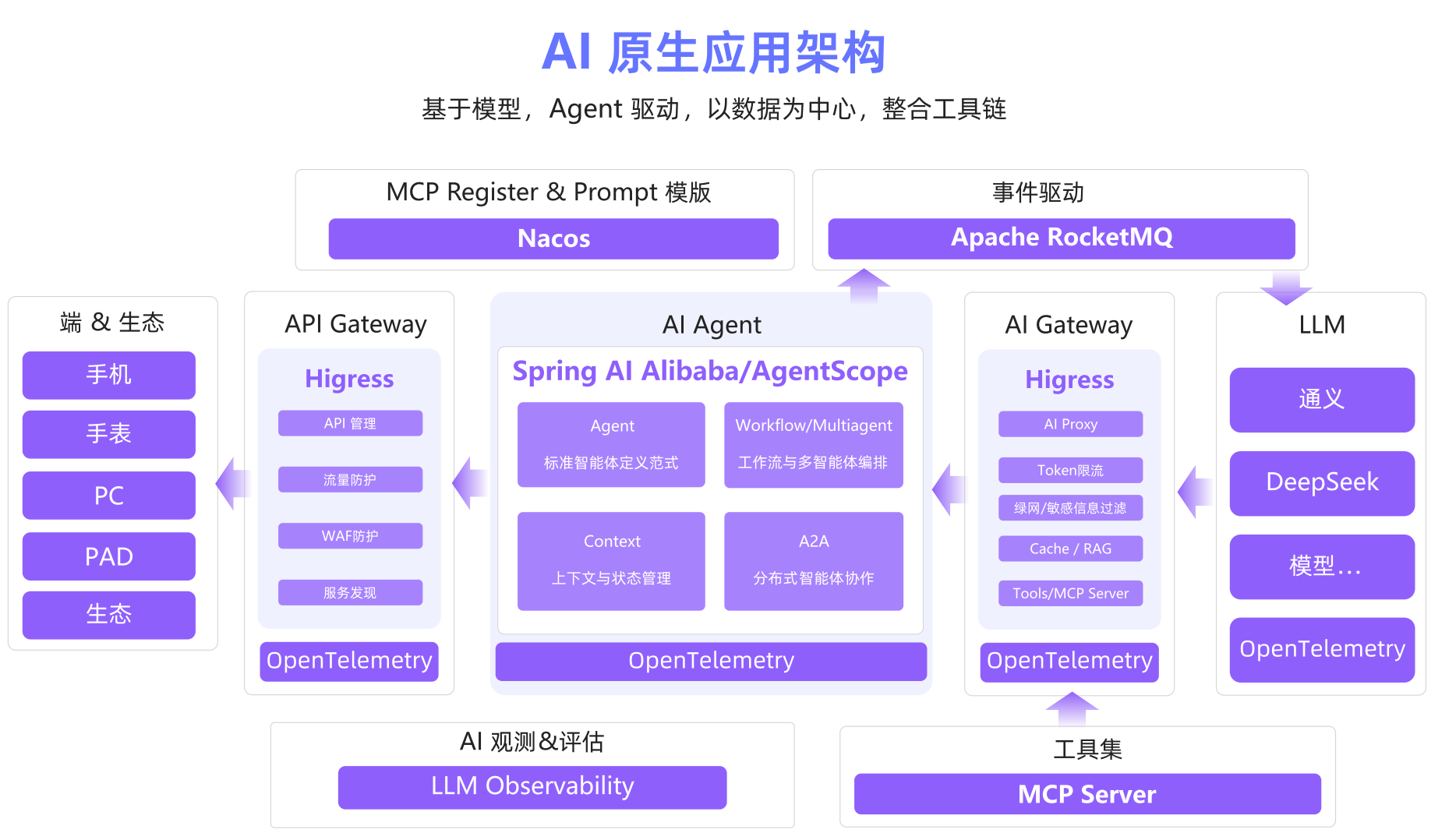
很多企业开发 AI 应用时,会陷入 “把大模型当插件” 的误区,结果导致系统碎片化、维护成本高。白皮书里的典型架构图,清晰展现了 AI 原生应用是一套 “环环相扣的系统”,从下到上分为 6 层,每一层都有不可替代的作用(模型层→工具层→运行时层→网关层→开发框架层→端生态层)。
我们重点拆解 5 个对企业落地最关键的核心组件:
-
大模型:AI 原生应用的 “大脑”,但不能单打独斗大模型负责理解需求、推理决策、生成内容,但单独用很容易出问题,比如:知识陈旧(不知道最新政策)、容易 “幻觉”(编造不存在的信息)。白皮书建议,大模型必须和 RAG(外部知识库)、记忆系统、工具库配合:用 RAG 实时拉取行业数据,用记忆系统记住用户偏好,用工具库获取真实业务数据,这样才能避免 “空谈”。
-
Agent:复杂任务的 “总调度”,解决 “谁来干活、怎么干” 的问题企业落地 AI 时,最头疼的就是 “多任务协同”,比如 “做一份竞品分析报告”,需要查行业数据、爬竞品官网、整理产品功能、生成可视化图表,这些步骤怎么串起来?白皮书里提到的 Agent 就是解决方案,比如阿里云 Spring AI 中的 FlowAgent 能按业务流程编排多个子 Agent(数据采集 Agent、分析 Agent、可视化 Agent),LlmRoutingAgent 能让大模型自主判断 “下一步该调用哪个工具”,不用工程师写死调度逻辑。
-
MCP:工具连接的 “通用语言”,告别 “重复适配” 的噩梦很多企业有几十上百个业务工具(ERP、CRM、物流系统等),如果每个工具都要针对不同大模型(GPT-4、通义千问、文心一言)做适配,工程师会 “忙到飞起”。MCP(Model Context Protocol)就是为解决这个问题而生,它相当于工具和模型之间的 “翻译官”,只要把工具接口转成 MCP 格式,所有大模型都能调用,不用重复开发,比如:企业的 ERP 系统,适配一次 MCP,通义千问能查库存,GPT-4 能做销量预测,大幅降低连接成本。
-
AI 网关:企业级落地的 “安全阀”,解决延迟、成本、安全问题很多 AI 应用在测试环境跑得很好,一到生产环境就出问题:模型突然挂了导致服务中断、用户频繁重复提问导致 Token 成本飙升、出现恶意提示攻击系统……AI 网关就是应对这些问题的 “中间件”。白皮书提到,阿里云的 AI 网关能实现 “模型自动切换(主模型挂了切备用)、语义缓存(重复请求走缓存,不用再调用模型)、Token 限流(控制单用户用量)、内容安全过滤(拦截恶意提示)”,相当于给 AI 应用加了一层 “防护网”。
-
上下文工程:提升模型输出质量的 “秘密武器”大模型的输出质量,很大程度取决于 “给它的上下文够不够好”。白皮书里的上下文工程,由 RAG(外部知识库)、记忆系统(短期对话记忆 + 长期用户偏好记忆)、运行时管理(上下文压缩 / 重排)三部分组成。比如企业做 AI 销售助手时,用 RAG 加载最新产品手册,用记忆系统记住客户 “关注性价比”,用运行时管理把长对话压缩成关键信息,避免超出模型上下文窗口,这样助手给出的推荐才精准。
三、企业开发 AI 原生应用的 3 个痛点怎么解?
白皮书最有价值的部分,不是讲概念,而是直面行业痛点,给出具体可操作的方案。我们挑 3 个企业最常遇到的问题拆解:
痛点 1:MCP 工具太多,模型 “选不过来” 还浪费 Token?
很多企业接入 MCP 工具后,会发现工具数量越来越多(几十个甚至上百个),模型每次处理需求时,都要先读全量工具的描述,不仅容易超出上下文窗口,还会浪费大量 Token(按 Token 计费的模型,成本会飙升)。白皮书给出的解决方案:
-
用 Nacos 做 MCP 注册中心,按任务语义自动筛选工具:比如用户要 “做财务报表”,注册中心会自动过滤掉物流、CRM 等无关工具,只给模型推送 Excel 工具、数据查询工具;
-
AI 网关 “工具精选” 功能:把匹配到的工具再压缩到 10 个以内,并用简洁语言描述核心能力,减少 Token 消耗;
-
搭建 “All-in-One” MCP Server:把多个同类工具聚合到一个服务里,支持语义搜索,比如 “数据统计” 类工具,模型只要搜 “统计” 就能找到,不用逐个看。
痛点 2:Token 成本不可控,AI 应用成 “烧钱机器”?
大模型按 Token 计费,多轮对话、重复请求、工具描述过长,都会导致成本失控,有企业反馈,测试阶段每月成本几千元,到生产环境直接涨到几万甚至几十万。白皮书的成本优化方案:
-
语义缓存:用 Redis 缓存相同或相似的请求结果,比如用户问 “公司年假政策”,第一次调用模型生成答案后,后续相同提问直接走缓存,不用再调用模型;
-
Token 限流:AI 网关设置单用户 / 总服务的 Token 用量上限,比如普通员工每天最多用 10 万 Token,避免恶意刷量;
-
Serverless 运行时:CPU/GPU 资源按需伸缩,没请求时缩到 0,有请求再扩容,比如夜间用户少,资源就减少,不用一直占着资源浪费钱。
痛点 3:AI 输出 “不靠谱”,还有安全风险?
企业落地 AI 应用时,最担心两个问题:一是模型输出 “不靠谱”(比如给客户推荐不存在的产品),二是安全风险(比如泄露客户隐私、被恶意攻击)。白皮书的风险控制方案:
-
建立 “LLM-as-a-Judge” 自动评估体系:用一个更权威的大模型(比如通义千问企业版),对 AI 应用的输出打分,低于阈值就重新生成,确保结果准确;
-
全栈安全防护:从应用层(WAF 防护,拦截恶意请求)、模型层(提示词攻击拦截,比如防止 “绕过安全规则” 的提示)、数据层(敏感信息过滤,比如手机号、身份证号打码)、身份层(非人类身份管控,防止机器人滥用)四层防护;
-
端到端可观测:追踪每一次模型调用、工具调用的 Token 数、延迟、错误率,一旦出问题,能快速定位是模型问题、工具问题还是网关问题,比如 “输出错误”,能查是模型理解错了,还是工具返回的数据有误。
四、未来趋势预判
除了落地指导,白皮书还预判了 AI 原生应用的 3 个发展趋势,帮企业提前布局:
- 模型从 “语言理解” 到 “世界模型”
未来的大模型不仅能处理文本,还能通过强化学习感知物理世界,比如工业场景的 AI 质检,能结合传感器数据判断设备故障,甚至模拟故障扩散路径,给出预防方案;
- 多 Agent 协同成主流
复杂业务会由 “主 Agent 统筹 + 子 Agent 执行”,比如企业做 AI 供应链优化,主 Agent 负责拆解任务(查库存、找供应商、算成本),子 Agent 分别执行,AI 中台沉淀通用能力(比如供应商评估、成本计算),避免每个业务线重复造轮子;
- 数据从 “静态积累” 到 “动态进化”
上下文工程会更智能,比如实时抓取行业数据更新 RAG,用合成数据(不涉及真实隐私)训练模型,解决数据不足问题,让 AI 应用的决策越来越精准。
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)