
SoFTA——如何让人形在餐厅给顾客上一杯啤酒:快-慢双智能体框架,上半身高频执行精细操作,下半身低频稳步行走
前言
25年9.20/9.21,我司在长沙举办了人形二次开发线下营(由于我司侧重具身开发了,故具身开发外,差不多一年一个具身大课),其中一位老师姚老师在讲行走操作时,提到了SoFTA这篇论文
我一细看,SoFTA论文说,尽管人形机器人在各种炫目的演示中频频亮相——如跳舞、递送包裹、穿越崎岖地形——但在行走过程中实现精细化控制仍是一大挑战
这话说得 可是深得我个人之意啊
总之,行走中干活不容易,尤其是在行走时稳定携带装满液体的末端执行器EE,由于任务特性存在根本性差异,这一问题远未解决:下半身行走需要慢时域的鲁棒控制,而上半身EE的稳定则要求快速且高精度的修正
而让机器人干活,是我司作为具身开发公司的第一目标,无论是坐着干活,还是行走中干活,故对此类问题高度关注
- 为了解决这一问题,来自的研究者提出了SoFTA(Slow-Fast Two-Agent),一种慢-快双智能体框架,将上半身与下半身的控制解耦,分别由不同频率、不同奖励机制的智能体独立控制
- 即SoFTA以上半身100 Hz的频率执行动作,实现高精度的EE控制;下半身以50 Hz的频率执行动作,确保步态的鲁棒性
PS,该工作与《FALCON——力自适应RL框架:上下双智能体(上肢操作策略、下肢行走策略)共享本体感觉和命令,然后联合训练》有类似之处
第一部分 SoFTA:学习温和的人形机器人行走与末端执行器稳定控制
1.1 引言与相关工作
1.1.1 引言
近年来,运动能力[1–11]和操作能力[12–16]的进步推动了人形机器人性能接近人类水平[17]。然而,有一项关键能力仍然研究不足:在行走过程中对末端执行器EE的精细稳定控制。这一能力对于与物体进行安全且精确的物理交互至关重要,例如递送一杯水或录制稳定的视频,但当前的人形机器人在这方面表现不佳
例如,Unitree G1 默认控制器在原地敲击时,其末端执行器的平均加速度约为 5m/s²——数值越高代表稳定性越低,超过人类水平的 10 倍,导致过度抖动,使精细任务变得不可行
这一根本性的性能差距源自于末端执行器EE稳定与行走任务在任务特性方面的差异,无论是在任务目标还是动态特性层面
- 在任务目标层面
行走需要具备可通过性,这自然引入了非准静态动态特性
相比之下,EE 稳定则要求底座运动最小,以维持精确性 - 在动态层面
下肢行走属于“慢”动态,只能通过相对较大时间尺度上的离散足部接触来控制。地面接触的特性使其更容易受到仿真到现实sim-to-real差距的影响,因此对噪声和扰动的鲁棒性要求更高
而 EE 控制则涉及“快”动态,手臂为全驱动且更易于控制,能够产生连续的力矩,实现快速且精确的修正
为弥合这一差距,来自CMU的研究者提出了SoFTA——一种慢-快双智能体强化学习(RL)框架,该框架将上半身和下半身的动作与价值空间解耦
- 其paper地址为:Hold My Beer: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control
其对应的作者包括
Yitang Li1, Yuanhang Zhang, Wenli Xiao, Chaoyi Pan,Haoyang Weng1
Guanqi He, Tairan He, Guanya Shi - 其项目地址为:lecar-lab.github.io/SoFTA
其GitHub地址为:github.com/LeCAR-Lab/SoFTA
截止到25年9.25日,其training code、evaluation code已发布,而其deploy code待发布
具体而言,此设计允许不同的执行频率和奖励结构:
- 上半身智能体以高频率动作,实现精确的末端执行器EE控制及补偿行为
- 而下半身智能体则以较低频率优先实现稳健的行走
通过这种解耦,SoFTA促进了稳定的训练与全身协调,从而实现了快速且精确的末端执行器控制,同时保证了稳健的运动能力
如图1所示

他们的系统在末端执行器加速度方面相较于基线方法实现了50–80%的降低
SoFTA能够在多样化运动中将末端执行器加速度控制在2m/s²以下,这一表现更接近于人类水平的稳定性,使得如端咖啡或稳定视频录制等任务成为可能
1.1.2 相关工作
// 待更
1.2 SoFTA:用于学习稳定末端执行器控制和鲁棒行走的算法
1.2.1 问题描述
首先,对于观测与动作,作者的目标是控制一个人形机器人,使其末端执行器稳定在目标位置,同时还能够遵循行走指令
作者将该问题表述为一个目标条件强化学习任务,其中
- 策略
被训练以输出动作
,表示目标关节位置
- 本体感输入
包括
关节位置
关节速度
躯干角速度
投影重力向量
和过去的动作的5 步历史
- 目标状态
包含
目标躯干线速度
目标偏航角速度
期望的基座朝向,
(包括一个二元站立/行走指令和步态频率)
- 以及
编码了末端执行器指令
其中,表示潜在末端执行器的数量,每个末端执行器有一个5 维指令,分别指定其是否被激活用于稳定、本地坐标系下的x 和y 坐标、全局坐标系下的z 坐标,以及跟踪容差σ
其次,对于用于稳定末端执行器控制的奖励设计,作者使用PPO [57] 来最大化累计折扣奖励
定义了若干奖励 以实现稳定的末端执行器控制:
- 惩罚较大的线性/角加速度
- 鼓励接近零的线性/角加速度
- 惩罚末端执行器坐标系下的重力倾斜
.
表示线加速度
表示角加速度
为指数型奖励缩放因子
表示旋转矩阵,g表示重力向量,
表示投影到xy 平面
最后,对于任务特征
稳定末端执行器控制与鲁棒行走在任务目标和动力学方面本质上是不同的任务
- 在任务目标层面
末端执行器的控制需要极高的稳定性,因此要求基座尽可能保持静止
而移动则需要适应不同的步态和动量变化
精确的末端执行器控制受益于细致、连续的高分辨率奖励
而移动则更适合长期、注重鲁棒性的奖励
鉴于这些差异,使用单一的评价器来汇总所有奖励信号可能并不是最有效的方法 - 在动力学层面,运动由离散的地面接触力控制,并由于其较长的时间尺度而表现出“较慢”的动力学特性
相比之下,上半身具有“较快”的动力学反应并且通常通过全驱动机械臂更易于控制,从而能够实现更激进和更快速的控制策略
鉴于更高的控制频率往往会提高系统的灵敏度,并加剧仿真到现实的差距[58–60,19],而较低的频率虽然精度较低,但更易于部署且更具鲁棒性,因此根据实际情况调节控制速率是有利的
1.2.2 SoFTA:慢-快双智能体框架
首先,是慢-快双智能体框架设计。鉴于这些不同的任务特性,作者提出了SoFTA,这是一种双智能体框架,每个智能体以不同的控制频率独立控制机器人自由度的非重叠子集(见图2)
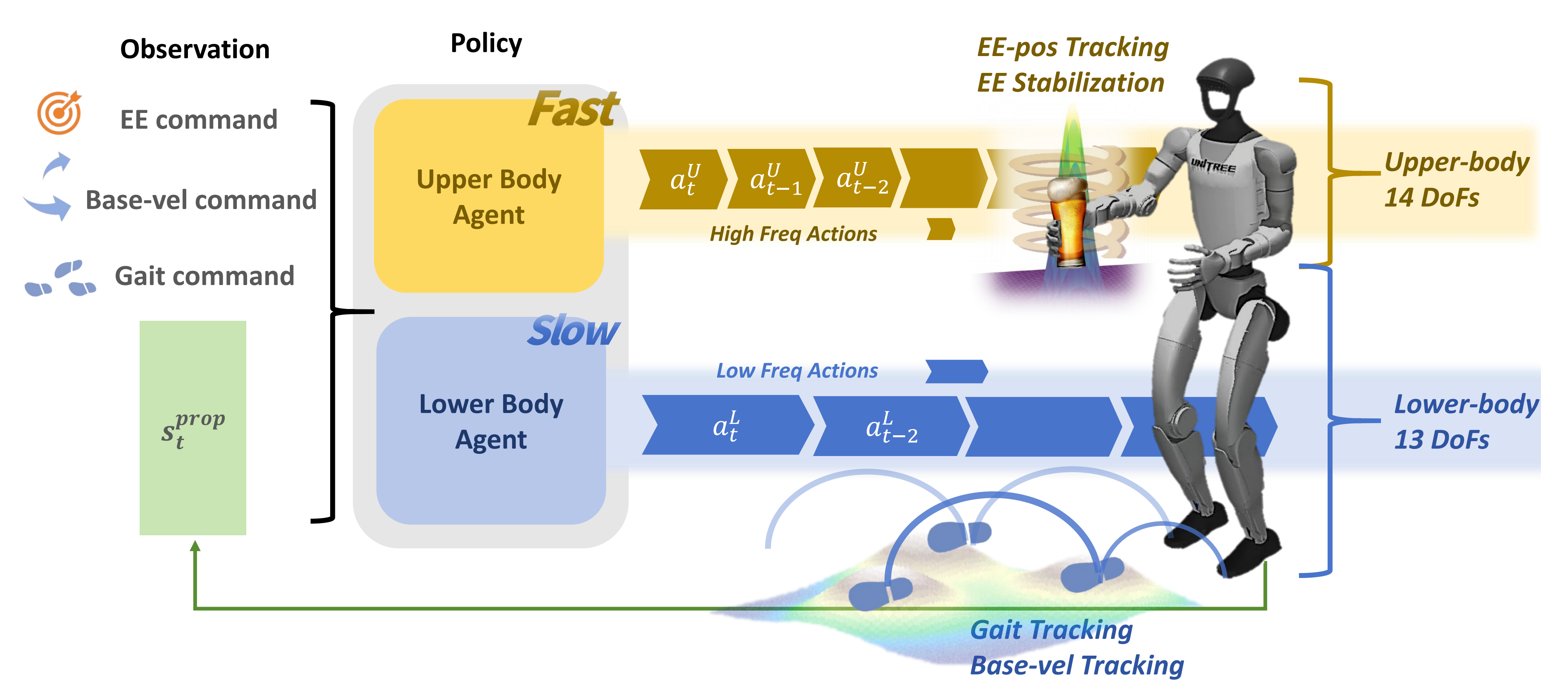
SoFTA中的两个智能体共享全身观测信息,以促进协调行为,同时允许各自专精
- 具体而言,上半身智能体以高频率运行,控制14个手臂关节,从而实现末端执行器的精确和快速调整以保持稳定
- 而下半身智能体以较低的频率运行,管理腿部和腰部,以确保行走和保持平衡的稳定性
这种不对称的控制频率与步态周期较长的特征时间尺度相匹配,同时满足稳定任务所需的快速、精确运动
其次,使用独立奖励组训练SoFTA。由于上半身与下半身任务的控制动态和时间尺度不同,其奖励信号本质上是异质的,这可能导致相互干扰并造成次优学习
- 为改善奖励归因[61–64],作者将整体奖励分解为两个语义对齐的组成部分,分别针对各自的PPO智能体进行定制
此分解为每个智能体提供了更有针对性的反馈,避免了任何智能体的过载,并促进了公平协作 - 且为了进一步鼓励协作行为和持续任务执行,作者在两个奖励流中都包含了终止奖励
尽管两个智能体共享同一观测空间,但它们分别使用独立的actor和critic网络,且参数不共享。更多细节见附录A.1
如原论文附录A.1 训练细节
- 对于观测
采用非对称观测结构,以便在仿真中实现高效的策略学习,同时确保在现实世界中具备部分可观测条件下的鲁棒部署
智能体仅依赖于可通过车载系统获取的输入——本体感知、指令信号以及最近的动作——不包含全局位置信息,从而消除了对里程计或外部跟踪的依赖
观测数据在五个时间步内进行堆叠,以提供短期的时序上下文
在训练过程中,评论器被赋予了特权,可以访问额外的信息,包括基线速度、末端执行器的相对位置以及末端执行器的重力,这有助于机器人更准确地理解其当前状态和任务完成情况
为了提升鲁棒性,会在部分观测数据中注入噪声
观测量的缩放比例和噪声缩放比例汇总见表4该设置提升了价值估算和训练的稳定性,同时确保可部署的策略基于真实的传感器输入,从而支持运动和末端执行器任务的强健仿真到现实迁移
- 对于任务定义
作者将任务定义为在一般身体构型下,结合稳健运动和末端执行器(EE)稳定的任务
末端执行器稳定命令,记作,用于编码特定任务需求
第一个维度是一个二值标志,指示是否启用EE稳定。如果该值为零,则与该EE相关的所有稳定奖励都会被禁用
接下来的两个值指定了EE在本体局部坐标系中的期望位置
第四个值定义了相对于期望基座z位置的全局z轴EE目标高度偏移量
cEE的最后一个元素是容差参数,用于控制EE跟踪的精度。较高的容差会带来更平滑的运动和更低的加速度,这对于如瓶子搬运等对EE精确定位要求不高的任务是有益的
相反,较低的容差则优先保证跟踪的精确性,这对于如相机稳定等必须严格保持EE姿态的任务至关重要
——————————
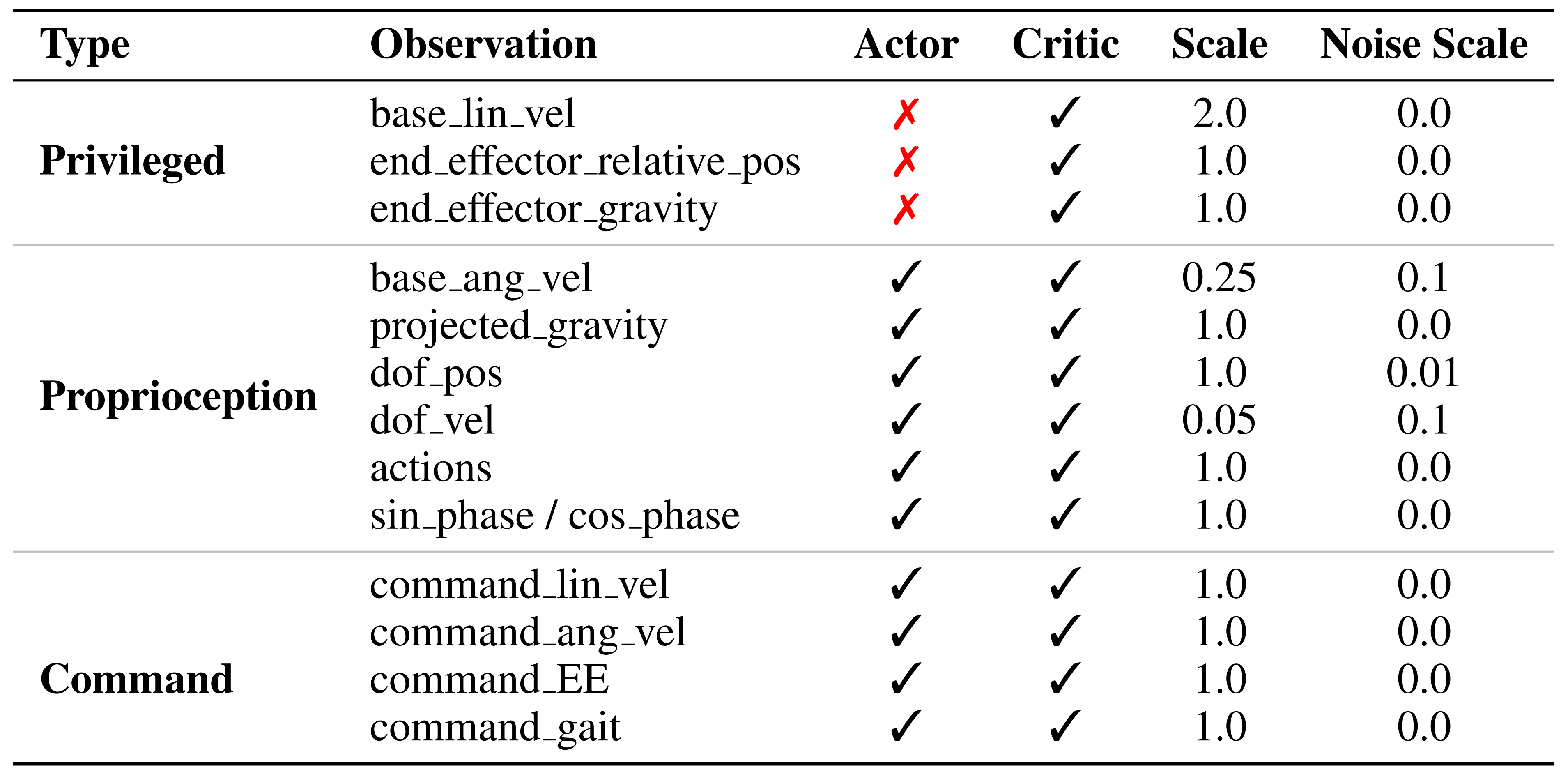
对于运动控制,控制指令包括目标底座速度和步态信息。速度指令包括期望的线速度和角速度
,所有这些都在底座坐标系中定义。系统应在指定的容差
,
,
内跟踪这些速度。步态控制由一个二维向量表示
第一个值是一个二进制指示器,用于表示期望步态是否为双支撑(双脚均接触地面)。如果不是(即处于动态步态模式)
进行表示,其中
表示相位。这使得可以推导出每只脚的目标接触时序
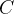
随后引入了一种基于相位的奖励,以引导智能体遵循期望的接触序列
作者在表5 中列出了所有指令范围,其中,
,
分别表示
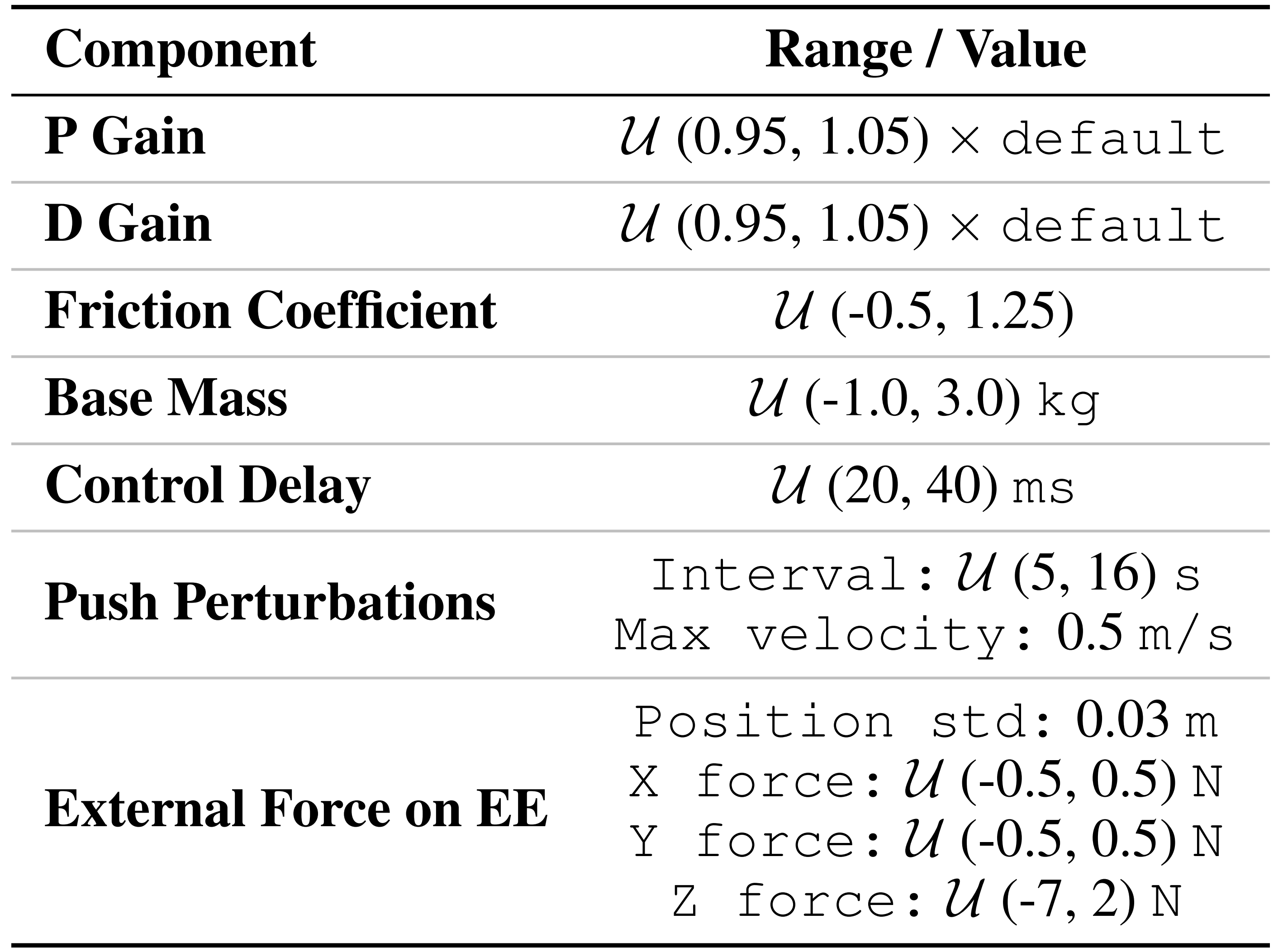
- 对于域随机化
为了增强SoFTA的鲁棒性和泛化能力,作者采用了域随机化技术,具体如表6所示首先在所有列出的域随机化策略下训练SoFTA,但不包括推挤扰动。在获得稳定的策略后,作者再引入推挤扰动,以进一步提升系统在外部干扰下的鲁棒性
- 对于奖励设计
作者在表8 中展示了分组的SoFTA 任务奖励组件。需要注意的是,终止是一个共享的奖励组件此外,作者引入了若干惩罚项和能量正则化,以实现稳健的仿真到现实性能,例如自由度限制、站立对称性、接触力、脚在空中的高度、动作速率等。按照[21] 的方法,他们在累计折扣奖励公式中调整缩放因子st,i,以根据奖励的符号区别对待小奖励:
其中,当
时,若
则为1。因子
初始值为0.5,并根据动态调整——当回合长度小于0.4 秒时乘以0.9999,大于2.1 秒时乘以1.0001,最大上限为1
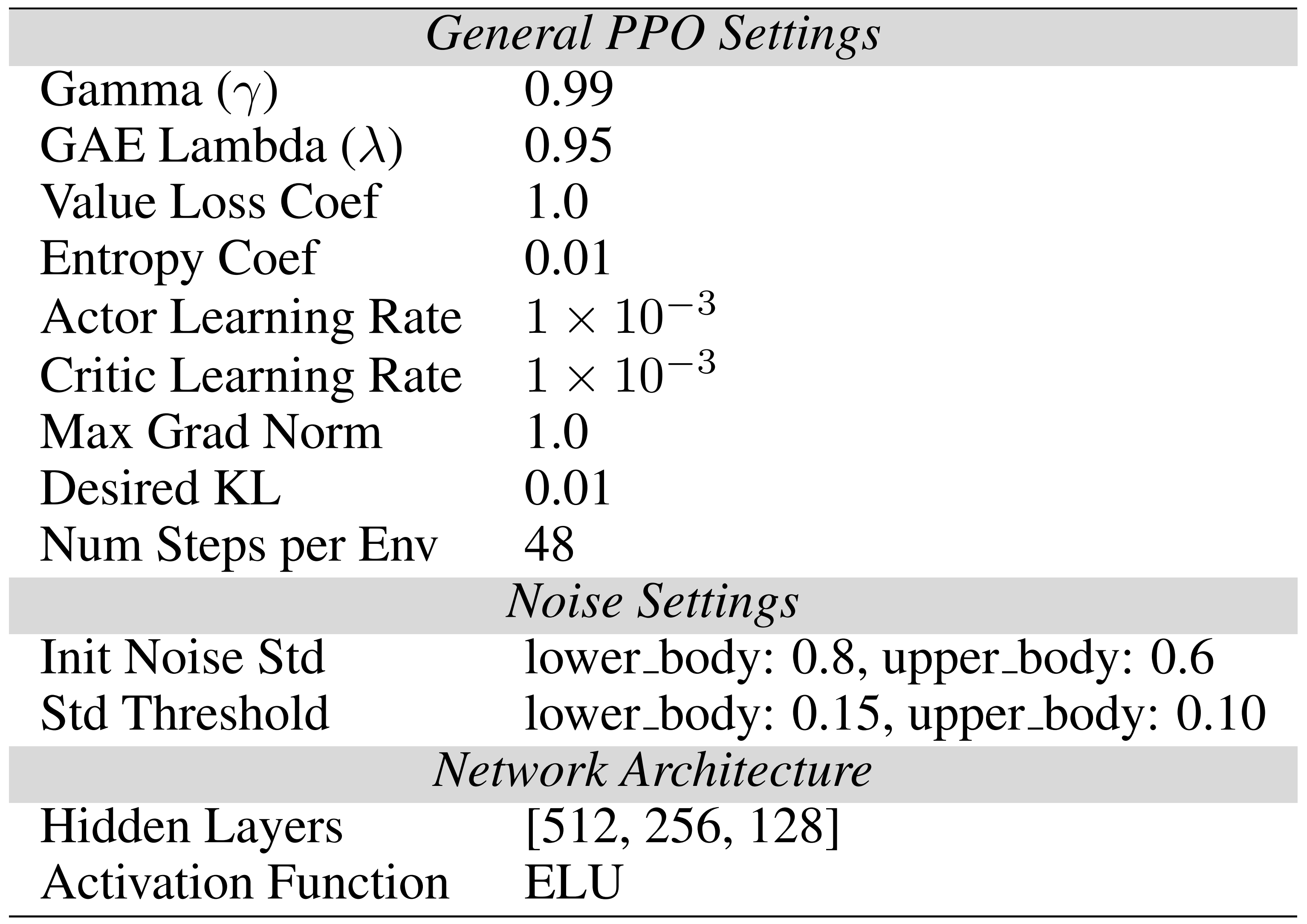
这使得他们的策略能够首先关注任务项,然后对行为进行正则化,使其在仿真到现实中表现得平滑且合理- 对于训练超参
作者在表8中总结了PPO多智能体-评论家训练设置中使用的主要超参数。这些包括通用的PPO设置、不同身体模块的动作标准差,以及策略网络与价值网络共用的网络结构
1.3 实验
本节中,作者将在仿真环境和真实环境中评估 SoFTA 的性能。他们的实验旨在回答以下关键问题:
- Q1 第4.1节:SoFTA 的双智能体设计在仿真中能否表现得更好?
- Q2 第4.2节:SoFTA在现实世界中能够实现哪些功能?
- Q3 第4.3节:Slow-Fast频率设计对SoFTA性能有多重要?
首先,对于基线方法
作者将SoFTA 与以下基线方法进行比较
- 机器人默认控制器1 [65]:采用Unitree 默认行走控制,提供稳定且低冲击的步态。该方法作为EE 稳定性的朴素基线
- 下肢RL + IK [31]:使用学习得到的下肢策略进行行走,然后通过逆运动学来稳定EE
- 全身RL:训练单一的RL 智能体,联合控制全身,实现鲁棒的行走和稳定的EE 控制
其次,对于SoFTA消融实验
作者评估了SoFTA的不同变体,采用33.3 Hz、50 Hz和100 Hz的上半身与下半身频率组合
- 实验设置。作者在 Isaac Gym 中以 200 Hz 的仿真频率训练他们的策略。在训练过程中,奖励函数、终止条件和课程设计在所有对比实验中均保持一致且与频率无关
- 对于实际环境评估,作者按照 HumanoidVerse [66] 的仿真到现实流程,将 SoFTA 部署在 Unitree G1 机器人上
为了验证泛化能力,作者将他们的框架以相同的频率配置迁移到 Booster T1 机器人上(可视化结果见附录 4.4)
最后,对于指标
作者使用以下指标评估EE稳定性:线性加速度模(Acc)、角加速度模(AngAcc)以及EE坐标系下XY平面上的投影重力(Grav-XY)
- 具体而言,在运动过程中,由于接触原因,z方向可能会出现突发的速度变化,因此他们额外报告z方向加速度(Acc-Z),以进行更全面的评估
这些指标均以平均值和最大绝对值的形式报告 - 每项指标在3次实验中评估,并报告均值和标准差
对于真实世界的加速度,作者使用动作捕捉系统以200 Hz的频率采集位姿数据进行评估
数据首先进行插值,去除异常点,然后通过二阶差分和滤波计算加速度
1.3.1 仿真结果
为了解答Q1(SoFTA的双代理设计在仿真中能否表现更优?),作者在三种行走场景下评估末端执行器(EE)的稳定性:
- 原地踏步:机器人原地踏步,以测试在持续且可预测的接触事件下的稳定性
- 随机指令(RandCommand):每10秒发出一次随机指令,以评估系统在多样化运动下的鲁棒性
- 推扰(Push):每秒以0.5m/s的速度向随机方向扰动底座,以模拟不可预测的外部干扰。结果汇总见表1
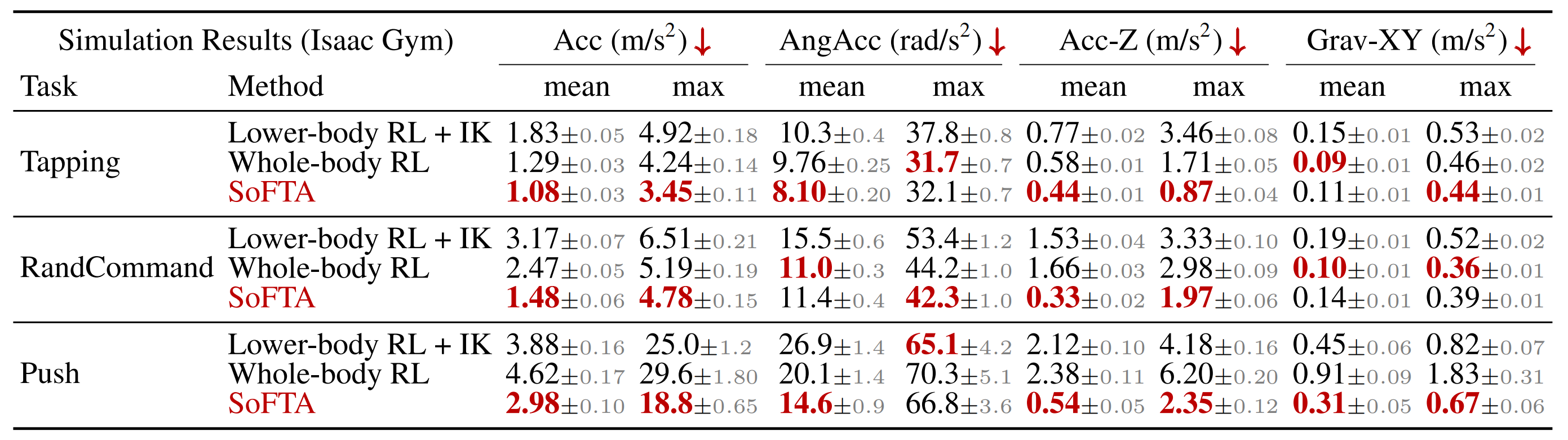
作者观察到,下肢RL + IK由于缺乏对动力学的感知,表现最差;而全身RL有所提升,但在诸如Push等高要求场景下,难以稳定末端执行器(EE),因为外部扰动会加剧不稳定性
相比之下,SoFTA表现最佳,显著降低了EE的加速度,尤其是在垂直方向上,突显了他们基于频率调度的解耦设计的优势
首先,受益于双智能体奖励组分离配给
图8显示了奖励冲突,EE-AngAcc-Penalty(用于能耗稳定性)与Angular-Vel-Tracking-Reward(用于行走)的冲突
- 对于全身强化学习,同时优化两者非常困难:如果优先考虑行走,会导致能耗惩罚增加;而过高的能耗惩罚则会导致强化学习无法持续站立,从而牺牲了行走质量(见蓝线后半部分)
- 相比之下,SoFTA通过将任务目标解耦为两个独立的智能体,解决了这一问题
即使在有显著能耗惩罚的情况下,下肢依然能够持续提升行走能力,随后实现协调,从而带来更稳定的学习过程和更优的性能
其次,新出现的补偿行为
- 图4(a)展示了底座和末端执行器(EE)的加速度曲线
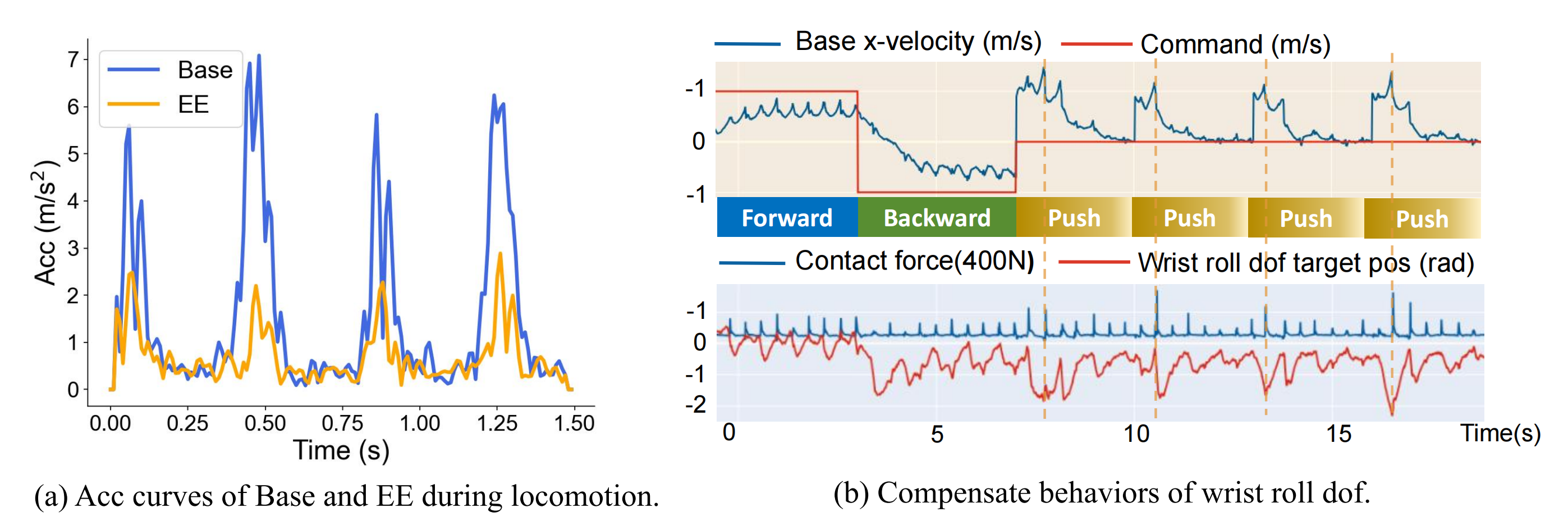
他们的策略减少了由于地面接触引起的底座剧烈加速度,表明通过有效补偿实现了稳定性,而不仅仅是减少底座运动
为说明这一点,他们可视化了机械臂自由度(DoF)目标位置和接触力模式 - 如图4(b)所示
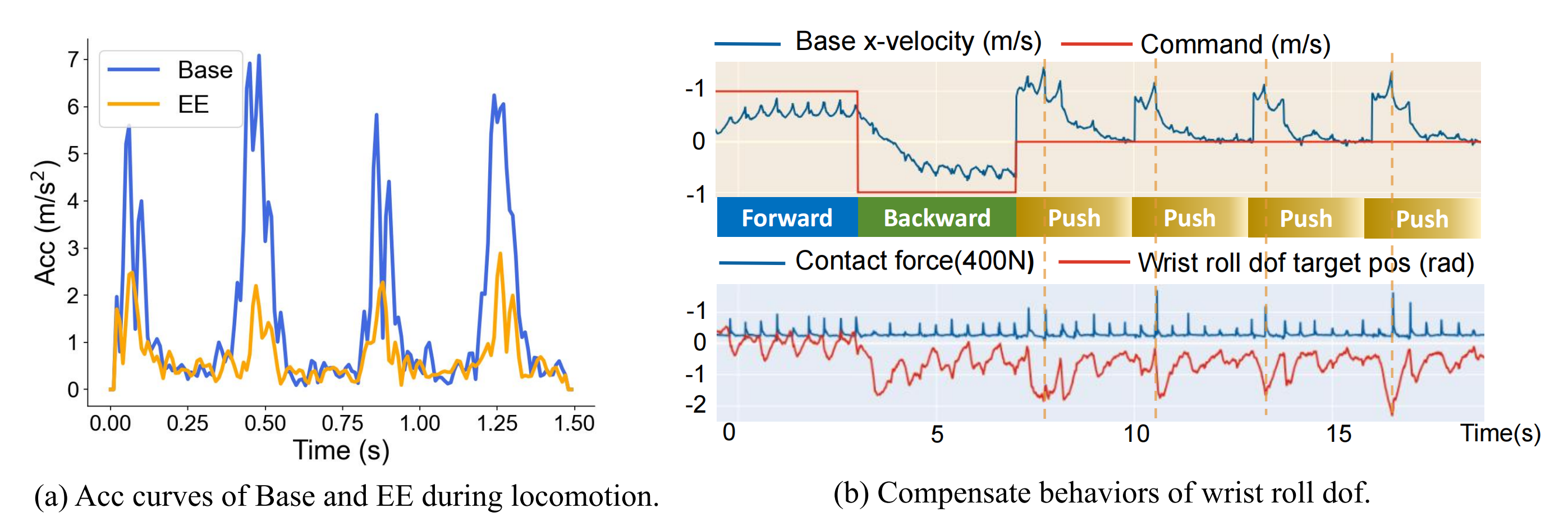
自由度激活与行走节奏及接触事件保持一致,补偿在外部推力和地面冲击时达到峰值,突显了上半身在稳定末端执行器中的作用
1.3.2 真实世界结果
为回答Q2(SoFTA在现实世界中具备哪些能力?),作者在三种真实世界的运动场景中评估了末端执行器(EE)的稳定性:
- 敲击
- TrajTrack,用于沿直线路径周期性移动
- 转向,实现原地旋转
需要注意的是,基于逆运动学(IK)的方法极度依赖于动作捕捉系统。即使在仿真中拥有完美的状态信息,该方法也难以取得理想效果,因此作者未在现实世界实验中纳入该方法
表2中的结果显示
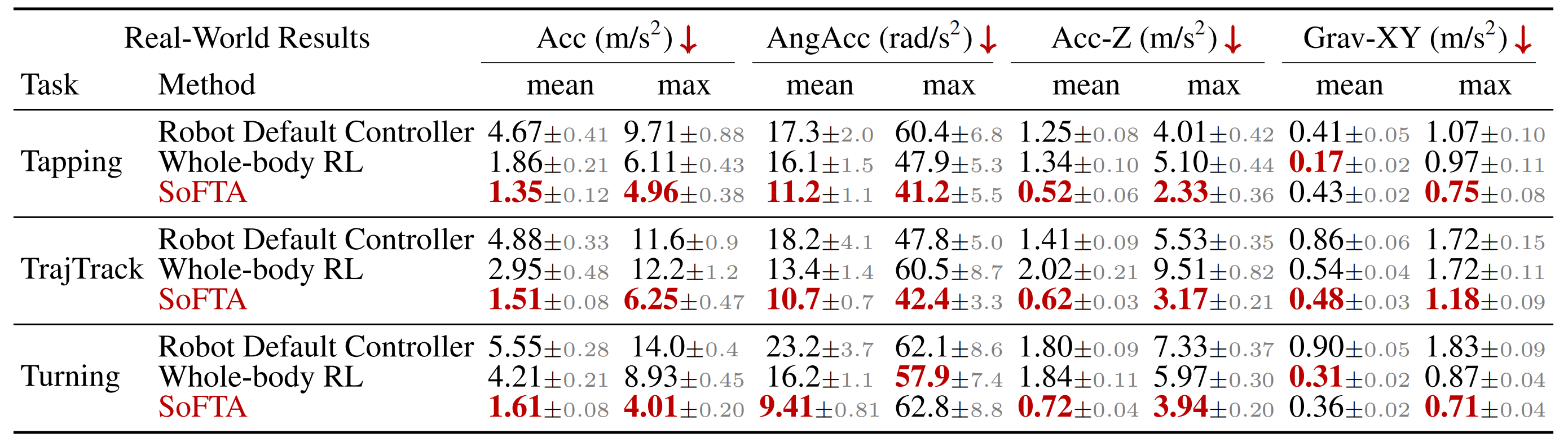
- Robot Default Controller在几乎所有指标上都表现出最高的加速度,这突显出即使是经过精心设计、步态平稳的运动控制器——现有方法在需要精确末端执行器(EE)稳定性的任务中表现不足
尽管全身强化学习(Whole-body RL)带来了一定程度的改进,但在如TrajTrack等大幅运动情形下仍然表现不佳 - 相比之下,SoFTA即便在多样化的移动过程中也能保持稳定且强健的性能。与仿真结果相比,现实世界测试显示,尽管采用了相同的领域随机化、观测噪声和奖励函数,SoFTA依然展现出更强的仿真到现实迁移能力
相比之下,全身强化学习表现出明显的动作迟缓和犹豫,尤其在脚步敲击时出现位移,这很可能是由于上半身影响过大所致
凭借末端执行器的稳定性和强健的行走能力,SoFTA 使机器人能够在移动过程中执行以下精确且稳定的上半身任务
案例1:仿人机器人携带水瓶且无液体溢出。图5展示了仿人机器人在行走过程中携带水瓶的情景

- 即使在轻敲的情况下,如果没有稳定机制(黄色,无补偿行为),接触冲击会导致液体明显晃动。相比之下,SoFTA(红色)极大地抑制了液体的晃动,使机器人能够在行走时平稳地携带几乎装满水的杯子
- 除了周期性行走外,他们的策略还展现出强大的抗干扰能力
如上图图5所示,当机器人遭受突然且强烈的推力时,其强健的行走能力能够迅速适应以避免跌倒,同时上半身主动补偿以尽可能保持末端执行器的稳定,有效防止液体溢出
案例2:类人机器人作为摄像机稳定器。图6展示了机器人在持续转动过程中录制的视频片段,比较了有无稳定化的效果
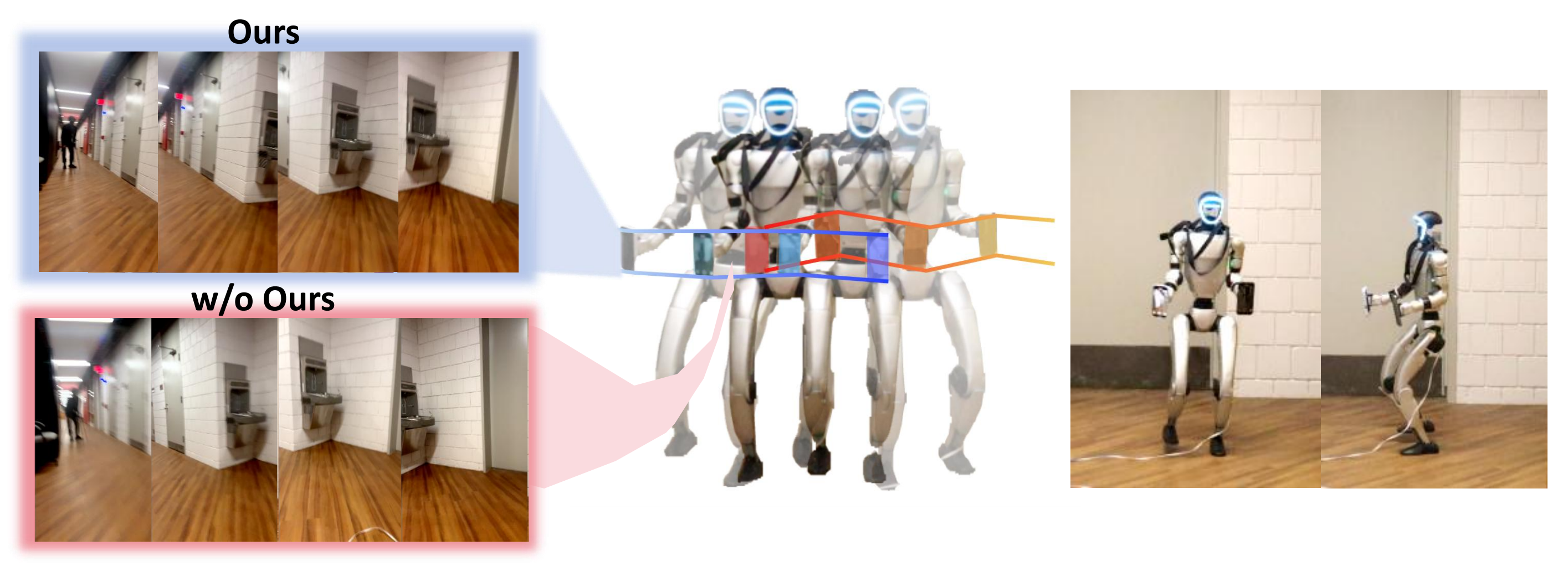
SoFTA保证了摄像机运动的平稳与一致,即使在非龙门架级别的强健行走下,也能避免明显的抖动。因此,机器人能够实现长时间、不中断的视频录制
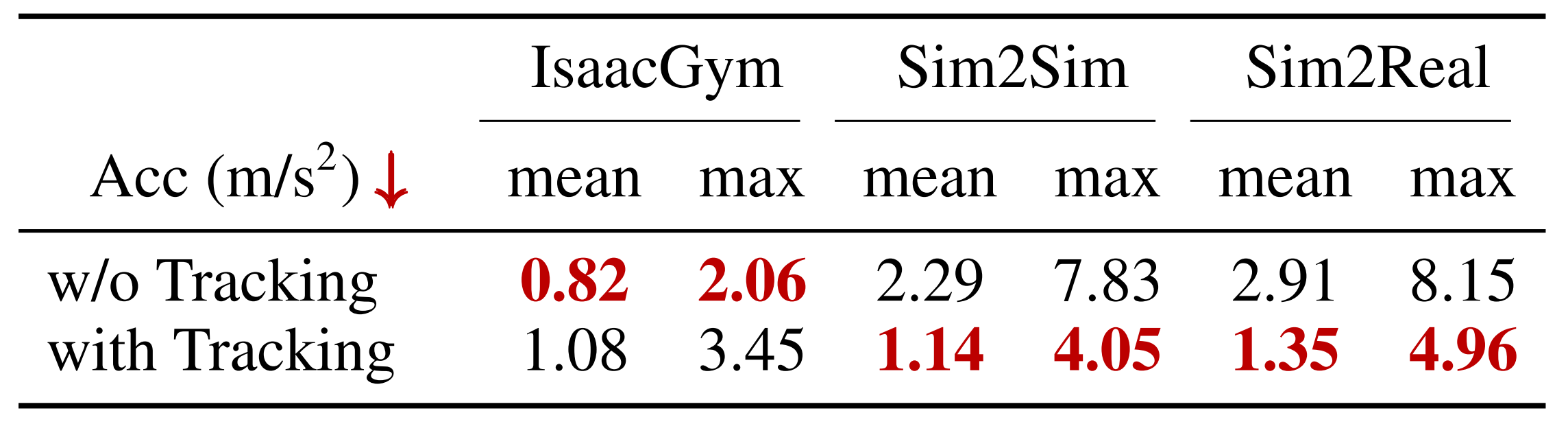
随机末端执行器位置指令对仿真到现实的益处。尽管全身强化学习和SoFTA都包含了末端执行器跟踪,但作者发现,通过强制进行跟踪,尤其是末端执行器(EE)在特定位置保持稳定,对于泛化能力起着至关重要的作用。在训练过程中固定EE的位置,往往会导致行为过拟合于特定的姿态和仿真器动力学,从而使迁移能力较差
相比之下,采用随机EE位置指令进行训练,可以促进更加灵活和适应性的运动,进而形成更具迁移性的补偿模式(见下表表3)
1.3.3 频率设计的深入分析
为回答Q3(慢-快频率设计对SoFTA性能有多重要?),作者在仿真和现实环境中,分别在两种场景下对不同频率设置下的峰值EE加速度进行了对比,这两种场景为:Tapping(可预测接触)和Stop(从行走到站立的突然切换)
如下图图7所示「仿真与现实世界中不同控制频率下的最大加速度:数值越高代表稳定性越低。N/A 表示在现实世界测试中出现不稳定或试验失败」,他们的慢-快设计——下肢50 Hz,上肢100 Hz——在各项任务和不同环境下均能持续实现更低的加速度(相当于4个任务区间中,你看最上面最中间的那一个数值即可:3.5 5.0 5.8 8.5)
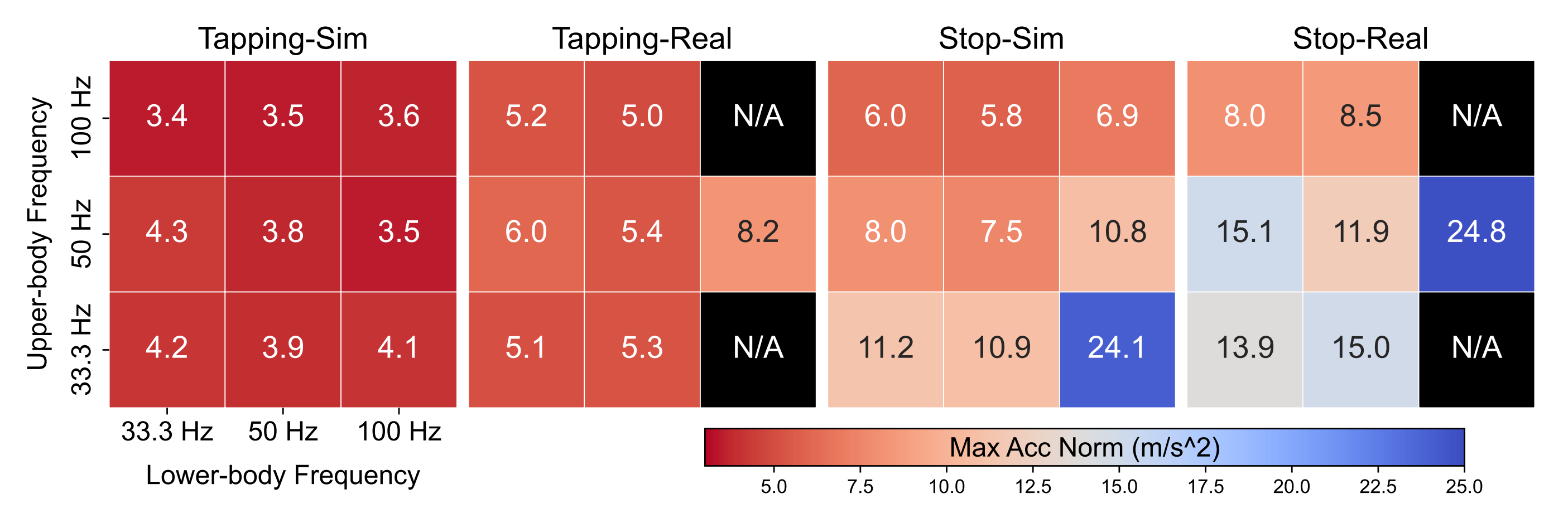
总之,作者观察到,在仿真中,50 Hz 的下肢策略足以在不可预测的环境下维持稳定的步态运动。相比之下,更高频率的上肢策略在突然停止时有助于实现快速恢复
- 从仿真到现实的角度来看,结果表明部署高频下肢策略可能会带来更严格的部署约束。在他们的真实停止实验中,100 Hz 下肢策略导致了更多的振荡,并降低了能效性能(EE),部分情况下甚至导致失败——比如上面三个任务区间中,最下面最右边的数值,可以看到第2个任务 tapping-real sotp-sim stop0-real分别出现了:N/A、24.1、N/A
这种性能下降可能是由于对观测噪声和控制延迟的敏感性增加所致 - 另一方面,将上肢智能体以 100 Hz 运行时,并未出现上述问题,且始终提升了整体性能。鉴于 50 Hz步态控制已被广泛采用,并且推理时延约束(0.01 秒)也已设定,作者认为 他们的“慢-快频率”配置似乎接近最优。关于高频上肢行为的进一步分析可参见附录A.2
如原论文「A.2 关于频率消融的更多分析」所说
- 无论是在模拟环境还是真实环境中,他们的实验表明,50 赫兹的下肢控制频率始终能实现稳定的行走,而不论上肢控制频率如何;但其他下肢控制频率在某些上肢控制频率下可能会导致性能下降
- 且作者进一步研究了在具有挑战性的情境下(如突发外部推力)更高的上半身控制频率如何增强末端执行器(EE)的稳定性
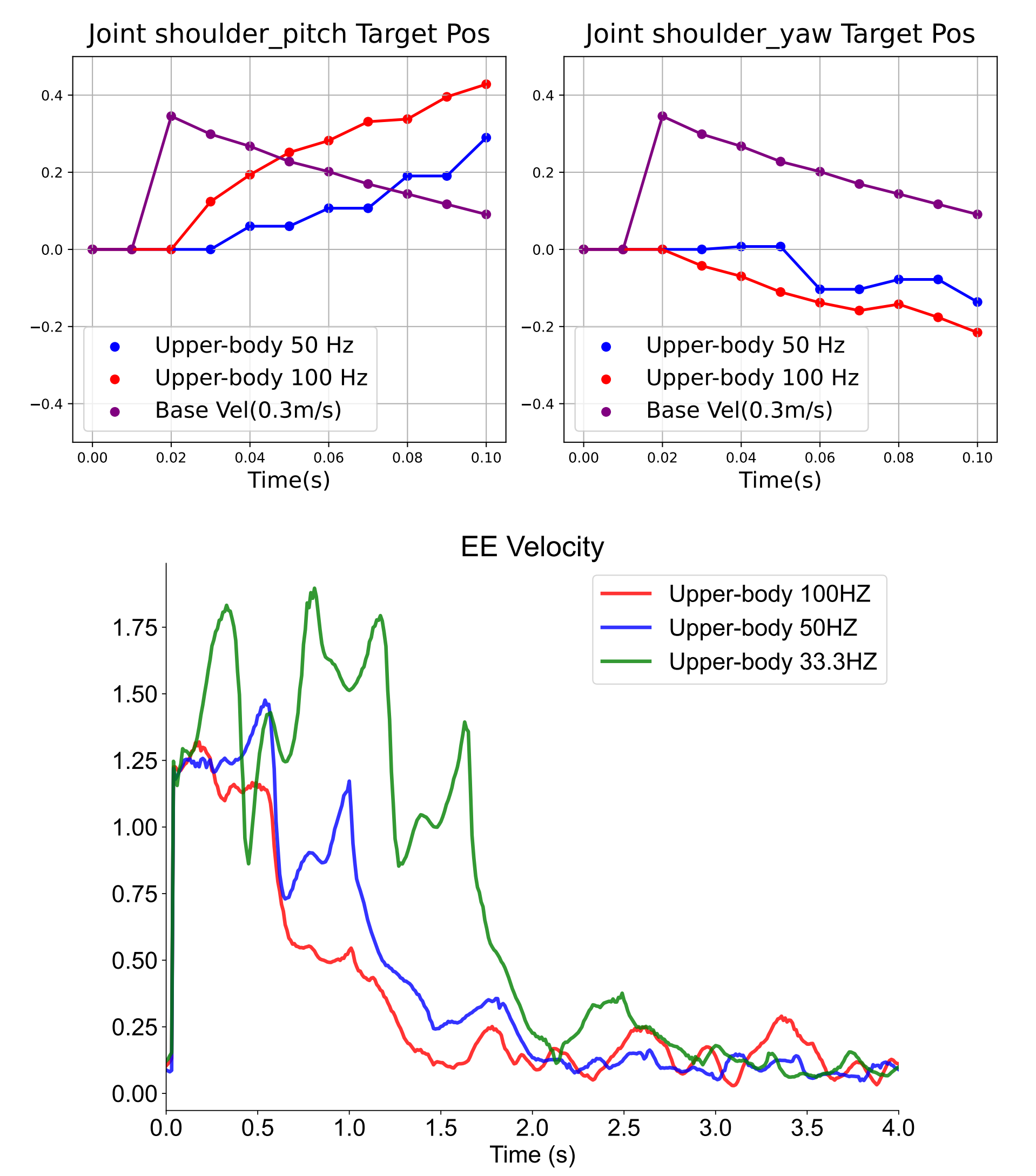
对于下图图9——上半身控制频率对末端执行器(EE)稳定性的影响。上图:不同上半身频率下末端执行器速度(m/s)的恢复情况。下图:100 Hz与50 Hz响应的对比如图9(上)所示,高频策略(100 Hz)对底座运动变化的反应更快,能够更快地恢复平衡
在图9(下)中,作者观察到更高的频率带来了更快的末端执行器速度恢复
表9给出了定量结果
可以发现,提升上半身控制频率能够缩短恢复时间(定义为误差首次低于1的时间)其结束最大值),以及峰值加速度和速度误差
这表明扰动补偿能力增强,恢复动态响应更快
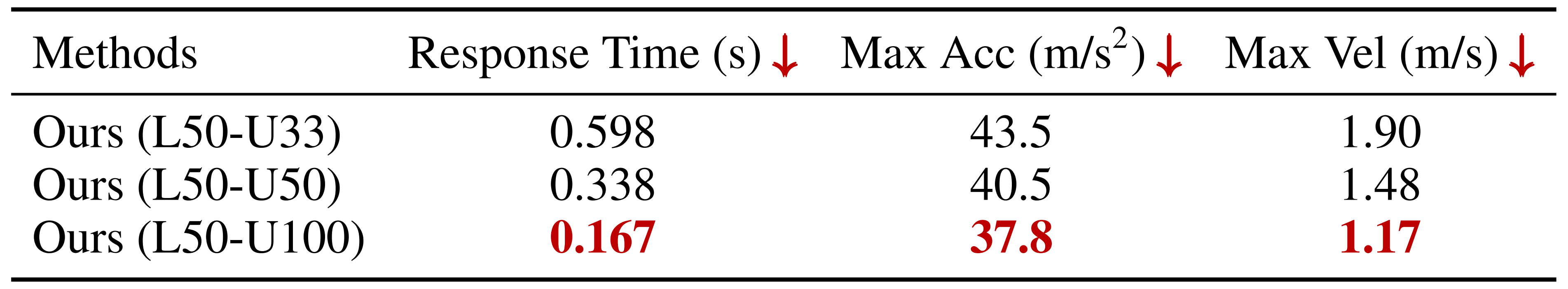
1.3.4 跨形体验证
为评估他们的策略训练方法和控制设计的泛化能力,作者通过将相同的训练流程应用于另一种不同的机器人形体——Booster T1 [67],进行跨形体验证
- 该机器人在关节配置和身体比例上与基础人形机器人存在差异。本次评估主要关注这些设计原则(如慢-快频率策略)在应用于新形态时,是否能够持续产生有效的行为
- 尽管具体实现存在差异,采用相同设计框架训练的T1策略在稳定性和协调性方面表现优于其默认控制器,尤其是在涉及突然停止和精确末端执行器控制的任务中
作者认为 这些结果表明,他们的训练方法能够捕捉可迁移的结构先验,从而在不同的人形机器人平台上实现鲁棒的行为,无需针对具体形体进行额外调优
1.4 结论与局限性
1.4.1 结论
在本文中,作者提出了SoFTA,一种慢-假两智能体强化学习框架,通过频率分离和任务特定的奖励设计,实现了稳健的运动能力以及精确、稳定的末端执行器(EE)控制
大量实验表明,SoFTA能够使末端执行器加速度降低50-80%,从而显著提升至接近人类水平的稳定性。这一方法使得在Unitree G1人形机器人上成功部署如携带液体行走或录制稳定视频等任务成为可能,并推动人形机器人以高精度和高可靠性完成复杂任务
1.4.2 局限性
尽管SoFTA表现出色,但仍存在若干局限性
- 首先,虽然它显著降低了末端执行器(EE)的加速度,但其实现的稳定性仍未达到人类水平。比如,人在行走时端水杯可以轻松做到几乎不洒水,而SoFTA尚未能匹配人类控制的细腻性和适应性
- 其次,运动与末端执行器控制的解耦带来了固定的任务边界。虽然这种分离对于许多运动-操作任务是有效的,但当两个模块需要高度协同(如动态抓取或复杂交互)时,这种方式就变得不够理想
- 第三,尽管SoFTA为多种场景提供了灵活的框架,并在频率分配方面带来了有价值的见解,但其性能可能会因具体任务或机器人配置而异。例如,任务复杂性、机器人形态结构,或对更细致协同的需求,可能都需要进一步调整设计
未来的工作可以着重于提升SoFTA在更多样化任务和机器人配置中的适应性,尤其关注动态协调与复杂交互
此外,解决与人类水平稳定性之间的差距将尤为关键,特别是在需要高精度和精细运动控制的任务中
探索更先进的学习策略和架构,例如注意力机制,有助于在不同平台和任务间实现更好的泛化能力
更多推荐

 23
23 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)