
强化学习一文通俗详解
【摘要】强化学习通过用户反馈优化AI模型表现。当用户对AI回答点赞或点踩时,这些行为成为"奖励信号":点赞促使模型重复优质回答,点踩帮助避免错误响应。强化学习系统包含智能体(模型)、环境(用户问题)、状态(具体问题)、动作(生成答案)和奖励(用户反馈)五个要素。完整的训练流程分为三个阶段:1)监督微调使模型掌握基础应答能力;2)训练奖励模型模拟人类偏好;3)通过强化学习算法(如
一、用户视角引入:您的“点赞”与“点踩”就是最强信号
想象一下这个场景:
-
您向一个大模型提问:“如何用Python计算斐波那契数列?”
-
模型给出了两个答案:
答案A:一段清晰、高效、带有注释的代码。答案B:一段冗长、晦涩、甚至有错误的代码。 -
您会如何反应?
对于答案A,您会满意地点赞👍。 对于答案B,您会失望地点踩👎。
这个简单的“点赞”和“点踩”动作,在强化学习的世界里,被称为 “奖励信号”。
-
点赞(正向奖励):告诉模型——“刚才这个动作(生成答案A)非常棒,以后遇到类似问题要多这么做!”
-
点踩(负向奖励):告诉模型——“刚才这个动作(生成答案B)很糟糕,以后要避免再犯!”
模型的目标,就是通过无数次这样的互动,学习如何最大化它从您那里获得的“总点赞数”(累积奖励)。它不再仅仅是模仿数据,而是学习在复杂环境中通过“试错”来做出最优决策。这就是强化学习的核心思想。
二、强化学习核心概念解析
将上面的例子抽象化,我们就得到了强化学习的五个核心要素:
-
智能体:即学习者和决策者。在上例中,就是大模型本身。
-
环境:智能体所处的外部世界。对模型而言,环境就是用户的提问+整个互联网的知识背景。
-
状态:环境在某个时刻的具体情况。即 “用户当前提出的具体问题”。
-
动作:智能体可以做出的行为。即 “模型生成一段答案”。
-
奖励:环境对智能体动作的反馈。即 用户给出的“点赞”或“点踩”。
三、系统的强化学习流程框架图
你的一次点击并不会立刻改变你眼前这个模型。它的影响是宏观和深远的。整个过程可以分为三个核心阶段,其完整流程与循环如下所示:
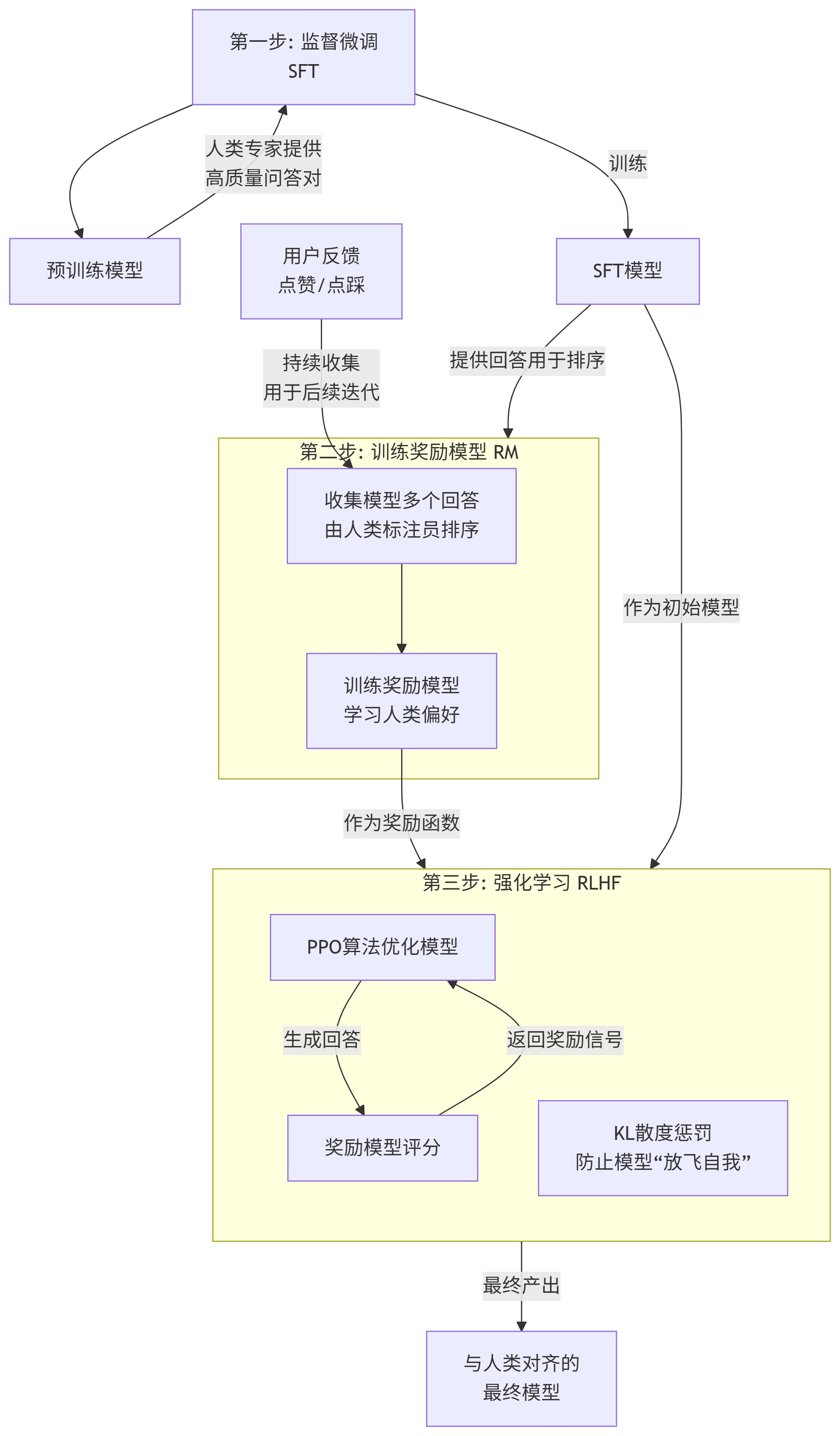
第一步:基础教学 - 监督微调 (Supervised Fine-Tuning, SFT)
-
目标:让模型学会“如何好好说话”,理解指令并给出符合格式的有用回答。
-
过程:聘请大量人类专家,编写大量高质量的“指令-回答”对(例如:“写一首关于春天的诗”、“用Python计算斐波那契数列”并给出正确答案)。
-
你的视角:你看不到这一步。这是在模型发布之前完成的。它奠定了模型能力和行为的基础。
第二步:学会评判 - 训练奖励模型 (Reward Model, RM)
-
目标:创建一个能够模拟人类喜好的“裁判员”。
-
过程:
-
让基础模型(第一步产出的SFT模型)对同一个问题生成多个不同的回答(A, B, C, D)。
-
聘请人类标注员对这些回答进行排序(例如:D > A > C > B)。注意:这里只需要比较排序,不需要直接打分,这比直接评分要容易且一致得多。
-
利用这些排序数据,训练一个单独的“奖励模型”。这个模型学会预测:给定任何一个回答,它会得到人类多大程度的喜欢(一个分数)。
-
-
你的视角:你的“点赞”和“点踩”行为,本质上就是在做微型的排序工作。当你点击时,你就在帮助优化这个“裁判员”(奖励模型)。
第三步:自我优化 - 强化学习优化 (RL, 通常是PPO)
-
目标:让模型学会生成能获得“裁判员”高分的回答。
-
过程:
-
将初始模型(第一步的SFT模型)和奖励模型(第二步的RM模型)接入强化学习框架。
-
模型针对一个新问题生成一个回答。
-
奖励模型对这个回答进行打分(这就是强化学习中的奖励信号)。
-
强化学习算法(如PPO[近端策略优化])根据这个奖励信号,反向更新模型的参数,使得模型以后更倾向于生成能获得高分的回答。
-
同时,为了防止模型为了高分而“钻牛角尖”(比如生成全是“好好好”的垃圾回答),还会加入一个正则化约束,确保模型的输出不会偏离初始模型太远。
-
所以,您每一次的点赞和点踩,都是在为AI世界的进化投票,是在帮助塑造未来的AI。 这就是强化学习的力量,它架起了一座从人类意图到机器智能的桥梁。
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)