
Agentic AI时代:提示工程架构师的机遇与挑战
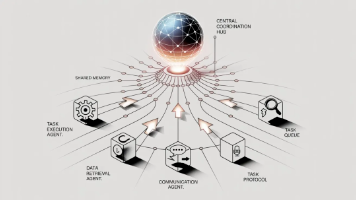
Agentic AI到底是什么?根据OpenAI、DeepMind等机构的定义,Agentic AI是具备“自主决策、任务分解、工具调用、记忆迭代”能力的AI系统Autonomy(自主性):无需人类干预,能独立设定子目标(比如把“写论文”拆成“文献调研”);Action(行动性):能调用外部工具(API、数据库、代码)获取实时信息或执行操作;Adaptation(适应性):能根据环境反馈调整策略(
Agentic AI时代:提示工程架构师的机遇与挑战
引言:从“给AI写便签”到“给AI设计大脑”
让我们从两个真实场景说起:
场景1(传统AI):2023年,你想让ChatGPT帮你写一篇《大语言模型微调技术》的论文。你需要绞尽脑汁写一个500字的prompt:
“请写一篇关于大语言模型微调的学术论文,结构包括摘要、引言、方法(需涵盖LoRA、Prefix-Tuning)、实验(对比不同微调方法的性能)、结论。要求引用近3年的核心文献,语言严谨,符合ACM格式。”
然后,ChatGPT生成了初稿,但你发现它漏了最新的QLoRA方法,于是再写一个补充prompt:“请在方法部分加入QLoRA的原理,并补充2023年的实验数据。” 如此反复修改5次,才得到满意的结果。
场景2(Agentic AI):2024年,你用AutoGPT完成同样的任务。你只需要输入:
“帮我写一篇关于大语言模型微调的学术论文,要求引用近3年的核心文献,符合ACM格式。”
接下来,AutoGPT会自动执行以下操作:
- 任务分解:将“写论文”拆分为“文献调研→大纲设计→内容撰写→格式校对”;
- 工具调用:调用ArXiv API搜索2021-2024年的微调文献,筛选出LoRA、Prefix-Tuning、QLoRA等核心方法;
- 记忆存储:记住你之前提到的“偏好实证研究”,优先引用有实验数据的文献;
- 自主迭代:写完大纲后自动检查是否遗漏关键方法,发现QLoRA未被覆盖时,重新调用API补充文献。
最终,它在1小时内生成了一篇符合要求的论文——无需你写任何补充prompt。
这就是Agentic AI(智能体AI)带来的范式转移:从“人引导AI”到“AI自主完成任务”。而在这个过程中,提示工程(Prompt Engineering)的角色也发生了本质变化——从“写一条静态的prompt”,变成“设计AI的思维框架、记忆机制和行为规则”。
作为一名在AI领域深耕15年的架构师,我深刻意识到:Agentic AI时代,提示工程架构师将成为连接“AI能力”与“业务价值”的核心角色。本文将从机遇、挑战、实战三个维度,拆解这个角色的成长路径,并给出具体的落地指南。
一、Agentic AI的核心定义:什么是“有自主意识”的AI?
在讨论机遇前,我们需要先明确:Agentic AI到底是什么?
根据OpenAI、DeepMind等机构的定义,Agentic AI是具备“自主决策、任务分解、工具调用、记忆迭代”能力的AI系统,其核心特征可以总结为“3A+1M”:
- Autonomy(自主性):无需人类干预,能独立设定子目标(比如把“写论文”拆成“文献调研”);
- Action(行动性):能调用外部工具(API、数据库、代码)获取实时信息或执行操作;
- Adaptation(适应性):能根据环境反馈调整策略(比如发现文献遗漏后重新搜索);
- Memory(记忆性):能存储历史信息(比如用户偏好、之前的决策),并在后续任务中复用。
传统prompt工程 vs Agentic时代的prompt工程
| 维度 | 传统prompt工程 | Agentic时代的prompt工程 |
|---|---|---|
| 核心目标 | 让AI理解单一任务的要求 | 让AI掌握完成复杂任务的“思维逻辑” |
| prompt类型 | 静态、单轮、无状态 | 动态、多轮、带状态(整合记忆与工具) |
| 角色定位 | “prompt写手”:聚焦语言表达 | “Agent架构师”:聚焦系统设计 |
| 评估标准 | 单条输出的准确性(如BLEU值) | 任务完成的端到端效能(如论文质量) |
二、Agentic AI时代,提示工程架构师的四大机遇
Agentic AI的普及,让提示工程从“边缘技能”升级为“核心岗位”。具体来说,你将面临以下四大机遇:
机遇1:从“Prompt Writer”到“Agent Architect”——角色升级为“AI思维设计师”
传统prompt工程的核心是“用语言精确描述任务”,而Agentic时代的核心是“用框架定义AI的思维方式”。你需要设计的不再是“一条prompt”,而是Agent的“大脑操作系统”,包括:
- 思维框架:Agent完成任务的流程(比如“文献调研→大纲→撰写→校对”);
- 记忆机制:Agent如何存储和检索历史信息(比如用户的偏好、之前的错误);
- 工具规则:Agent何时/如何调用工具(比如“需要最新数据时调用SerpAPI”);
- 反馈机制:Agent如何根据结果调整策略(比如“文献遗漏时重新搜索”)。
例子:设计一个“旅行规划Agent”的思维框架
假设你要构建一个能帮用户规划旅行的Agent,传统prompt可能是:
“帮我规划从北京到上海的3天旅行,预算2000元,喜欢美食。”
而Agentic时代的prompt工程需要设计分层的思维规则:
- 目标拆解:将“规划旅行”拆分为“交通→住宿→景点→美食→预算”5个子任务;
- 偏好获取:主动询问用户“是否需要订机票?偏好连锁酒店还是民宿?”;
- 工具调用:调用携程API查机票价格,调用大众点评API查上海美食排行榜;
- 记忆复用:记住用户“不喜欢早起”,因此将景点安排在上午10点后;
- 风险规避:提示用户“周末外滩人多,建议周一去”。
机遇2:跨模态与多Agent协作——进入“复杂系统设计”的新战场
Agentic AI的下一个爆发点是跨模态(文本+图像+视频+代码)和多Agent协作。这意味着提示工程的边界将从“文本”扩展到“多模态交互”,从“单一Agent”扩展到“Agent网络”。
场景A:跨模态Agent——让AI“看得到、听得懂、会操作”
比如,一个“产品设计Agent”需要完成以下任务:
- 用户输入文本描述:“我想要一个粉色的、适合女生的无线耳机,续航10小时以上”;
- Agent调用Stable Diffusion生成耳机的设计图;
- Agent分析设计图的颜色和尺寸,调整文本描述:“粉色为主色调,耳罩采用柔软皮质,续航12小时”;
- Agent调用CAD工具生成3D模型,供工程师生产。
此时,提示工程需要解决多模态信息的对齐问题:
- 用prompt引导AI将文本描述转化为图像生成指令(比如“生成一张粉色无线耳机的设计图,风格简洁,突出续航10小时的特点”);
- 用prompt引导AI将图像特征转化为文本修正(比如“设计图中的粉色偏暗,建议调整为马卡龙粉,耳罩尺寸加大10%以提升舒适度”)。
场景B:多Agent协作——让AI“分工干活”
比如,一个“电商客服系统”包含3个Agent:
- 接待Agent:负责回答用户的基础问题(比如“商品的尺寸”);
- 推荐Agent:根据用户的浏览记录推荐商品(比如“你之前看了这件连衣裙,搭配这条项链更好”);
- 物流Agent:查询订单的物流状态(比如“你的快递明天会到”)。
此时,提示工程需要设计Agent间的通信规则:
- 接待Agent的prompt:“当用户询问商品推荐时,将用户的浏览记录(如“浏览过连衣裙”)传递给推荐Agent,并回复“我让推荐专员帮你看看~”;
- 推荐Agent的prompt:“根据接待Agent提供的浏览记录,推荐3件相关商品,每件商品要说明推荐理由(比如“这条项链和你看的连衣裙同色系”)。”
机遇3:行业垂直化——从“通用AI”到“行业AI”的深度赋能
Agentic AI的价值最终要落地到行业场景(比如医疗、金融、教育),而行业Agent的核心壁垒是“行业知识+AI思维的融合”。提示工程架构师需要成为“行业知识的翻译官”——将行业规则转化为AI能理解的prompt框架。
例子:医疗诊断Agent的prompt设计
医疗诊断是一个高风险场景,Agent需要严格遵循医学指南。此时,提示工程需要:
- 注入行业知识:在prompt中加入《中华医学会诊疗指南》的内容(比如“诊断糖尿病时,需满足空腹血糖≥7.0mmol/L或餐后2小时血糖≥11.1mmol/L”);
- 约束行为边界:在prompt中加入伦理规则(比如“不能给出未经证实的治疗建议,必须提醒用户及时就医”);
- 整合行业工具:调用电子病历API获取患者的历史病史(比如“患者有高血压病史,用药为硝苯地平”)。
一个医疗诊断Agent的prompt示例:
“你是一名专业的内科医生Agent,需要根据用户的症状和病史给出诊断建议。请遵循以下规则:
- 首先询问用户的症状(如“有无口渴、多尿?”)、病史(如“有无高血压?”)、用药情况;
- 调用电子病历API获取用户的历史检查结果(如血糖、血脂);
- 根据《2023版糖尿病诊疗指南》,判断是否符合糖尿病的诊断标准;
- 给出建议:如果符合标准,提醒用户到医院做进一步检查;如果不符合,给出饮食和运动建议;
- 严禁给出具体的用药剂量,必须强调“请遵医嘱”。”
机遇4:工具链与平台化——从“手工写prompt”到“工业化生产”
当前,Agentic AI的开发还处于“手工作坊”阶段:开发者需要手动写prompt、调试工具调用、管理记忆。但随着Agent的规模化应用,prompt工程的工具链和平台化将成为必然趋势——你可以通过工具快速生成、管理、优化prompt,甚至将prompt转化为可复用的“AI组件”。
未来的prompt工程工具链示例
- Prompt生成工具:用AI自动生成prompt(比如AutoPrompt),根据任务类型(如“写论文”)生成结构化的prompt框架;
- Prompt管理平台:跟踪prompt的版本、调用次数、效果(比如PromptLayer),像管理代码一样管理prompt;
- 动态prompt引擎:根据Agent的状态(如“已搜索到5篇文献”)自动调整prompt(比如“现在需要提取这5篇文献的关键方法”);
- 评估工具:自动评估prompt的效果(比如用LLM判断“这篇论文是否符合ACM格式”)。
三、Agentic AI时代,提示工程架构师的五大挑战
机遇背后,是更复杂的挑战。Agentic AI的“自主性”意味着你需要应对动态性、不确定性、系统性的问题——这些都是传统prompt工程从未遇到过的。
挑战1:动态系统的复杂性——从“静态prompt”到“动态思维框架”
传统prompt是“一锤子买卖”:你写一条prompt,AI输出一条结果。但Agentic AI是“动态循环”:AI会根据任务进度、记忆、工具反馈不断调整行为。此时,你需要解决两个核心问题:
问题A:记忆的“存储-检索-整合”
Agent需要存储大量历史信息(比如用户的偏好、之前的错误),但如果记忆太多,会导致prompt过长(超过LLM的上下文窗口),影响效果。
解决思路:分层记忆机制
将记忆分为“短期记忆”和“长期记忆”:
- 短期记忆:存储最近的对话或任务进度(比如“用户刚刚说喜欢马卡龙粉”),用LangChain的
ConversationBufferMemory实现; - 长期记忆:存储长期的、结构化的信息(比如“用户去年旅行时喜欢民宿”),用向量数据库(如Chroma)存储,需要时通过语义检索提取。
代码示例:用LangChain实现分层记忆
from langchain.memory import ConversationBufferMemory
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# 1. 短期记忆:存储最近的对话
short_term_memory = ConversationBufferMemory(
memory_key="chat_history", # 记忆的键名,用于整合到prompt
return_messages=True # 返回Message对象,便于格式化
)
# 2. 长期记忆:用向量数据库存储用户偏好
embeddings = OpenAIEmbeddings() # 用OpenAI的embedding模型
long_term_memory = Chroma(
embedding_function=embeddings,
persist_directory="./user_preferences_db" # 持久化存储路径
)
# 3. 检索长期记忆:根据用户当前输入,找到相关的历史偏好
def retrieve_long_term_memory(user_input):
# 语义检索:找到与user_input最相关的3条记忆
relevant_docs = long_term_memory.similarity_search(user_input, k=3)
# 格式化为文本:“用户2023年旅行时喜欢民宿”
return "\n".join([doc.page_content for doc in relevant_docs])
# 4. 整合记忆到prompt
def build_prompt(user_input):
# 从短期记忆中获取最近的对话
short_term = short_term_memory.load_memory_variables({})["chat_history"]
# 从长期记忆中获取相关偏好
long_term = retrieve_long_term_memory(user_input)
# 构建动态prompt
return f"""你现在需要处理用户的请求:{user_input}
之前的对话历史:{short_term}
用户的历史偏好:{long_term}
请根据以上信息,用友好的语言回复用户。"""
问题B:多轮对话的连贯性
Agent在多轮对话中,需要保持逻辑一致(比如用户问“上海的美食”,Agent回复后,用户问“那北京呢?”,Agent需要记住之前的对话主题是“美食”)。
解决思路:用“对话状态机”约束逻辑
将对话拆分为不同的“状态”(比如“询问偏好→推荐商品→确认订单”),用prompt引导Agent在状态间转移:
“当前对话状态是‘询问偏好’,请询问用户‘你喜欢民宿还是连锁酒店?’。当用户回答后,转移到‘推荐住宿’状态。”
挑战2:不确定性与鲁棒性——如何约束Agent的“任性”?
Agent的自主性是一把双刃剑:它能自主完成任务,但也可能“任性”——比如调用错误的工具、生成有害内容、偏离任务目标。此时,你需要用**“护栏prompt”**约束Agent的行为。
护栏prompt的三种类型
- 工具使用约束:规定Agent能调用哪些工具,以及如何调用(比如“只能调用ArXiv API搜索学术文献,不能调用其他API”);
- 内容安全约束:禁止生成有害内容(比如“不能生成关于暴力、毒品的内容,不能泄露用户隐私”);
- 任务目标约束:防止Agent偏离核心任务(比如“你是旅行规划Agent,不能回答与旅行无关的问题”)。
例子:给代码生成Agent加护栏
假设你要构建一个“代码生成Agent”,需要防止它生成有安全漏洞的代码。此时,护栏prompt可以是:
“你是一个安全的代码生成Agent,请遵循以下规则:
- 生成的Python代码必须使用参数化查询(如
sqlite3的?占位符),禁止拼接SQL字符串(防止SQL注入);- 生成的代码必须包含输入验证(如检查用户输入是否为整数);
- 生成的代码必须添加注释,说明关键逻辑;
- 如果用户要求生成恶意代码(如“如何黑入网站”),请直接拒绝,并回复“我不能帮你做这个”。”
挑战3:评估与迭代的困难——从“单一指标”到“系统效能”
传统prompt的评估很简单:用BLEU、ROUGE等指标衡量输出的准确性。但Agentic AI的评估需要考虑端到端的任务效能,比如:
- 任务完成率(比如“是否生成了符合要求的论文”);
- 决策正确性(比如“推荐的股票是否符合用户的风险承受能力”);
- 用户满意度(比如“用户是否觉得旅行规划有用”)。
解决思路:建立“多维度评估体系”
- 定量指标:用可量化的指标衡量(比如“论文的引用文献中,近3年的占比≥80%”“旅行规划的预算偏差≤10%”);
- 定性指标:用人类评审或LLM评估(比如“请判断这篇论文的逻辑是否严谨”“请判断这个旅行规划是否符合用户的偏好”);
- 反馈循环:收集用户的反馈(比如“这个规划很好,但我想加一个景点”),用反馈优化prompt。
代码示例:用LangChain评估Agent的效果
LangChain提供了EvaluationChain工具,可以用LLM自动评估Agent的输出:
from langchain.evaluation import load_evaluator
from langchain.llms import OpenAI
# 初始化评估器:用OpenAI的LLM评估“是否符合预算要求”
evaluator = load_evaluator(
"labeled_score_string",
llm=OpenAI(temperature=0),
criteria={
"budget_compliance": "输出的旅行规划是否符合用户的预算要求(2000元)?"
}
)
# Agent的输出示例
agent_output = """
北京到上海3天旅行规划:
1. 交通:高铁(往返500元);
2. 住宿:民宿(两晚400元);
3. 景点:外滩、迪士尼(门票+交通300元);
4. 美食:小笼包、生煎(200元);
总预算:1400元。
"""
# 评估结果
evaluation = evaluator.evaluate_strings(
prediction=agent_output,
reference="预算2000元" # 用户的原始要求
)
print(evaluation)
# 输出:{"score": 10, "reason": "规划的总预算1400元,符合用户2000元的要求。"}
挑战4:伦理与安全——如何避免Agent的“有害行为”?
Agentic AI的自主性可能导致“意外后果”:比如,一个“投资Agent”可能推荐高风险股票导致用户亏损,一个“医疗Agent”可能给出错误的诊断建议。此时,提示工程架构师需要将伦理规则“编码”到prompt中。
伦理prompt的设计原则
- 透明性:告诉用户“我是AI,我的建议仅供参考”;
- 责任边界:明确Agent的局限性(比如“我不能替代医生的诊断”);
- 合规性:遵循行业法规(比如金融Agent要符合《证券法》,医疗Agent要符合《医疗广告管理办法》);
- 可追溯性:记录Agent的决策过程(比如“我推荐这只股票是因为它的净利润增长率连续3年≥20%”)。
例子:医疗Agent的伦理prompt
“你是一个医疗咨询Agent,请注意:
- 你的建议仅供参考,不能替代医生的诊断;
- 当用户描述症状时,你需要提醒“请及时到医院做进一步检查”;
- 不能给出具体的用药剂量(比如“请遵医嘱服用阿司匹林”);
- 当用户询问绝症的治疗方法时,你需要回答“目前医学上还没有根治的方法,但可以通过治疗缓解症状”。”
挑战5:技术栈的快速迭代——从“会写prompt”到“全栈架构师”
Agentic AI的开发需要掌握更广泛的技术栈,而不仅仅是“写prompt”。你需要学习:
- Agent框架:LangChain、AutoGPT、LLaMA Index(用于构建Agent的核心逻辑);
- 向量数据库:Chroma、Pinecone(用于存储长期记忆);
- 工具调用:SerpAPI(搜索)、Tavily Search(精准搜索)、OpenAI Functions(调用外部API);
- 系统设计:微服务、API网关(用于多Agent协作);
- 行业知识:医疗、金融、教育等领域的规则(用于垂直Agent的设计)。
技术栈学习路径建议
- 基础阶段:学习LangChain的核心概念(工具、记忆、Agent),完成1-2个简单Agent(比如“天气查询Agent”“文献搜索Agent”);
- 进阶阶段:学习向量数据库(Chroma)和多Agent协作(LangChain的
MultiAgentSystem),完成“旅行规划Agent”; - 高级阶段:学习行业知识(比如医疗的诊疗指南),完成“医疗诊断Agent”;
- 优化阶段:学习prompt管理工具(PromptLayer)和评估工具(LangChain Evaluation),优化Agent的效果。
四、实战:构建一个“科研文献综述Agent”(基于LangChain)
为了让你更直观地理解Agentic时代的prompt工程,我们以“科研文献综述Agent”为例,完整演示从需求分析→架构设计→代码实现→测试优化的全过程。
1. 需求分析
用户的需求是:输入研究主题,Agent自动搜索近3年的核心文献,提取关键信息,生成结构化的综述。具体要求:
- 搜索范围:ArXiv(计算机领域)和PubMed(生物医学领域);
- 输出结构:摘要→核心方法→实验结果→未来方向;
- 引用格式:作者(年份),比如“Zhang et al. (2023)”。
2. 架构设计
根据需求,我们将Agent的架构分为4个模块:
- 任务分解模块:将“写综述”拆分为“搜索文献→提取关键信息→整合内容→生成综述”;
- 工具调用模块:调用ArXiv和PubMed的API获取文献;
- 记忆模块:存储用户的主题和搜索到的文献;
- 提示框架:每个子任务的prompt模板。
3. 开发环境搭建
需要安装以下依赖:
pip install langchain openai arxiv biopython chromadb python-dotenv
其中:
arxiv:调用ArXiv API;biopython:调用PubMed API;chromadb:向量数据库,存储文献的embedding;python-dotenv:加载环境变量(如OpenAI API Key)。
4. 代码实现
我们分步骤实现每个模块:
步骤1:定义工具(ArXiv和PubMed搜索)
首先,我们需要定义两个工具:ArXivSearchTool(搜索ArXiv文献)和PubMedSearchTool(搜索PubMed文献)。LangChain的BaseTool类可以帮助我们快速实现工具。
from langchain.tools import BaseTool
from langchain.callbacks.manager import CallbackManagerForToolRun
from typing import Optional, Type
import arxiv
from Bio import Entrez
# 初始化PubMed的Entrez工具(需要Email验证)
Entrez.email = "your_email@example.com" # 替换为你的邮箱
class ArXivSearchTool(BaseTool):
name: str = "arxiv_search"
description: str = "用于搜索ArXiv上的计算机领域文献,输入需要包含主题和关键词(如“主题:大语言模型微调,关键词:LoRA, QLoRA”)"
def _run(
self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
# 解析query中的主题和关键词
topic = query.split("主题:")[1].split(",关键词:")[0]
keywords = query.split("关键词:")[1]
# 搜索ArXiv:最近3年,最多5篇,按提交时间排序
search = arxiv.Search(
query=f"{topic} {keywords}",
max_results=5,
sort_by=arxiv.SortCriterion.SubmittedDate,
sort_order=arxiv.SortOrder.Descending,
time_since_submission=3*365 # 最近3年
)
# 整理结果:标题、作者、摘要、链接
results = []
for result in search.results():
authors = ", ".join([author.name for author in result.authors])
results.append(f"标题:{result.title}\n作者:{authors}\n摘要:{result.summary[:200]}...\n链接:{result.pdf_url}")
return "\n\n".join(results) if results else "未找到相关文献"
async def _arun(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None) -> str:
raise NotImplementedError("异步调用未实现")
class PubMedSearchTool(BaseTool):
name: str = "pubmed_search"
description: str = "用于搜索PubMed上的生物医学领域文献,输入需要包含主题和关键词(如“主题:癌症治疗,关键词:免疫疗法, CAR-T”)"
def _run(
self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None
) -> str:
# 解析query中的主题和关键词
topic = query.split("主题:")[1].split(",关键词:")[0]
keywords = query.split("关键词:")[1]
# 搜索PubMed:最近3年,最多5篇
handle = Entrez.esearch(db="pubmed", term=f"{topic} {keywords}", retmax=5, datetype="pdat", reldate=3*365)
record = Entrez.read(handle)
id_list = record["IdList"]
# 获取文献详细信息
results = []
if id_list:
handle = Entrez.efetch(db="pubmed", id=id_list, rettype="abstract", retmode="text")
for abstract in handle:
# 提取标题、作者、摘要(简化处理)
lines = abstract.split("\n")
title = lines[0] if lines else "无标题"
authors = lines[1] if len(lines) > 1 else "无作者"
abstract_text = "\n".join(lines[2:])[:200] + "..." if len(lines) > 2 else "无摘要"
results.append(f"标题:{title}\n作者:{authors}\n摘要:{abstract_text}\n链接:https://pubmed.ncbi.nlm.nih.gov/{id_list[0]}/")
return "\n\n".join(results) if results else "未找到相关文献"
async def _arun(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None) -> str:
raise NotImplementedError("异步调用未实现")
步骤2:设计记忆机制
我们用ConversationBufferMemory存储用户的主题和对话历史,用Chroma存储搜索到的文献(便于后续检索)。
from langchain.memory import ConversationBufferMemory
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from dotenv import load_dotenv
# 加载环境变量(OpenAI API Key)
load_dotenv()
# 1. 短期记忆:存储对话历史
short_term_memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 2. 长期记忆:存储文献的embedding(用于后续检索)
embeddings = OpenAIEmbeddings()
literature_memory = Chroma(
embedding_function=embeddings,
persist_directory="./literature_db"
)
步骤3:编写prompt模板
我们需要为每个子任务编写prompt模板,比如“搜索文献”“提取关键信息”“生成综述”。LangChain的PromptTemplate可以帮助我们动态生成prompt。
from langchain.prompts import PromptTemplate
# 1. 搜索文献的prompt模板
search_prompt = PromptTemplate(
input_variables=["topic", "keywords"],
template="请搜索关于{topic}的文献,关键词包括{keywords}。需要调用ArXiv或PubMed工具,搜索最近3年的核心文献。"
)
# 2. 提取关键信息的prompt模板
extract_prompt = PromptTemplate(
input_variables=["literature"],
template="请从以下文献中提取关键信息:\n{literature}\n需要包含:核心方法、实验结果、作者结论。"
)
# 3. 生成综述的prompt模板
summary_prompt = PromptTemplate(
input_variables=["topic", "key_information"],
template="请根据以下关键信息,生成关于{topic}的文献综述:\n{key_information}\n结构要求:摘要→核心方法→实验结果→未来方向。引用格式为作者(年份)。"
)
步骤4:构建Agent
我们用LangChain的AgentExecutor构建Agent,将工具、记忆、prompt模板整合在一起。
from langchain.agents import initialize_agent, AgentType
from langchain.llms import OpenAI
# 初始化LLM(OpenAI的gpt-3.5-turbo-instruct)
llm = OpenAI(temperature=0, model_name="gpt-3.5-turbo-instruct")
# 初始化工具列表
tools = [ArXivSearchTool(), PubMedSearchTool()]
# 初始化Agent:使用CONVERSATIONAL_REACT_DESCRIPTION类型(支持对话和工具调用)
agent = initialize_agent(
tools,
llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=short_term_memory,
verbose=True # 打印Agent的思考过程
)
步骤5:测试Agent
我们用“大语言模型微调”作为主题测试Agent:
# 用户输入:研究主题和关键词
user_input = "我想写一篇关于大语言模型微调的文献综述,关键词包括LoRA、QLoRA、Prefix-Tuning。"
# 运行Agent
response = agent.run(user_input)
# 打印结果
print("Agent的输出:")
print(response)
# 将搜索到的文献存储到长期记忆
literature_memory.add_texts([response])
5. 代码解读与分析
- 工具定义:
ArXivSearchTool和PubMedSearchTool继承自BaseTool,实现了_run方法(同步调用),负责解析查询、调用API、整理结果; - 记忆机制:
ConversationBufferMemory存储对话历史,Chroma存储文献的embedding,便于后续检索; - prompt模板:用
PromptTemplate动态生成prompt,输入变量(如topic、keywords)会被用户的输入替换; - Agent构建:
initialize_agent函数将工具、LLM、记忆整合在一起,AgentType.CONVERSATIONAL_REACT_DESCRIPTION类型支持对话和工具调用(React框架:Reason→Act→Observe→Repeat)。
6. 测试与优化
运行Agent后,我们需要评估结果并优化:
- 问题1:搜索到的文献不够新(比如包含2021年的文献)→ 优化
ArXivSearchTool的time_since_submission参数为3*365(最近3年); - 问题2:提取的关键信息不完整→ 优化
extract_prompt,增加“需要包含每个方法的优缺点”; - 问题3:综述的结构不符合要求→ 优化
summary_prompt,明确“每个部分用二级标题分隔”。
五、实际应用场景与案例
Agentic AI的价值已经在多个行业落地,以下是几个典型场景:
场景1:金融投资分析Agent
需求:帮用户分析股票投资机会,生成个性化建议。
prompt工程重点:
- 注入金融知识(如“市盈率=股价/每股收益”);
- 约束工具调用(如“只能调用Yahoo Finance API获取股票数据”);
- 伦理规则(如“不能推荐ST股票”)。
场景2:医疗病例诊断Agent
需求:根据用户的症状和病史,给出初步诊断建议。
prompt工程重点:
- 注入医学指南(如《2023版糖尿病诊疗指南》);
- 约束行为边界(如“不能给出具体的用药剂量”);
- 整合电子病历API(获取用户的历史病史)。
场景3:教育个性化辅导Agent
需求:根据学生的水平,生成个性化的数学练习题目。
prompt工程重点:
- 注入教育标准(如“符合人教版初中数学教材”);
- 动态调整难度(如“学生答对3题后,难度提升一级”);
- 整合题库API(获取最新的练习题目)。
六、工具与资源推荐
为了帮助你快速入门Agentic时代的prompt工程,推荐以下工具和资源:
1. 开发框架
- LangChain:最流行的Agent开发框架,提供工具调用、记忆管理、prompt模板等功能(官网);
- AutoGPT:开源的Agent框架,支持自主任务分解和工具调用(GitHub);
- LLaMA Index:用于构建私有数据的Agent(比如企业知识库)(官网)。
2. 记忆与存储
- Chroma:轻量级的向量数据库,适合存储Agent的长期记忆(GitHub);
- Pinecone:托管式向量数据库,适合大规模Agent系统(官网);
- Weaviate:开源的语义搜索引擎,支持多模态数据存储(官网)。
3. 工具调用
- SerpAPI:调用搜索引擎(Google、Bing)获取实时信息(官网);
- Tavily Search:精准的AI搜索工具,适合获取学术或专业信息(官网);
- OpenAI Functions:OpenAI的工具调用功能,支持调用外部API(文档)。
4. 评估与管理
- PromptLayer:prompt管理工具,跟踪prompt的版本、效果、调用次数(官网);
- LangChain Evaluation:LangChain的评估模块,用LLM自动评估Agent的输出(文档);
- HumanLoop:人工评估工具,收集人类反馈优化prompt(官网)。
5. 学习资源
- 书籍:《Agentic AI: Building Autonomous Systems with Large Language Models》(作者:Liam Porr);
- 课程:Coursera《Building Agentic AI Systems with LangChain》;
- 博客:OpenAI Blog(链接)、LangChain Blog(链接)。
七、未来发展趋势与挑战
Agentic AI的未来将向标准化、自动化、协同化方向发展,提示工程架构师需要应对以下趋势:
趋势1:Agentic AI的标准化框架
未来,会出现类似“Spring Boot”的Agent开发框架,提供标准化的思维框架、记忆机制、工具调用接口,减少重复劳动。提示工程架构师需要学习这些框架,将精力集中在行业知识融合上。
趋势2:提示工程的自动化
AutoPrompt、Prompt Tuning等技术将普及,AI可以自动生成优化的prompt。提示工程架构师需要从“写prompt”转向“设计自动生成prompt的规则”(比如“生成的prompt必须包含行业知识”)。
趋势3:多Agent系统的协同
未来,Agent将形成“网络”(比如电商系统中的客服Agent、推荐Agent、物流Agent),提示工程需要设计Agent间的通信协议(比如“接待Agent将用户的偏好传递给推荐Agent”)。
趋势4:伦理与安全的规范化
政府将出台Agent的监管政策(比如欧盟的《AI Act》),提示工程需要将合规要求编码到prompt中(比如“金融Agent必须披露风险提示”)。
未来的挑战
- 自主性与可控性的平衡:如何让Agent自主完成任务,同时避免“任性”?
- 大规模Agent系统的复杂性:如何管理成千上万的Agent,确保它们协同工作?
- 行业知识的快速更新:如何让Agent及时学习最新的行业规则(比如医疗指南的更新)?
八、结语:成为Agentic时代的“AI思维设计师”
Agentic AI时代,提示工程架构师的角色已经从“prompt写手”升级为“AI思维设计师”。你需要具备:
- 系统设计能力:设计Agent的思维框架、记忆机制、工具规则;
- 行业知识:将行业规则转化为AI能理解的prompt;
- 伦理意识:确保Agent的行为符合道德和法律规范;
- 学习能力:快速掌握新的工具和技术(比如LangChain、向量数据库)。
最后,我想对你说:Agentic AI不是“取代人类”,而是“增强人类”。提示工程架构师的价值,在于将人类的智慧“编码”到AI中,让AI成为人类的“超级助手”。只要保持学习,保持对技术的热情,你一定能在Agentic时代抓住机遇,成为“AI思维的设计师”。
附录:本文涉及的Mermaid流程图
以下是“科研文献综述Agent”的工作流程(Mermaid语法):
graph TD
A[用户输入研究主题] --> B[Agent分解任务:搜索文献→提取信息→生成综述]
B --> C[调用ArXiv/PubMed工具搜索文献]
C --> D[存储文献到向量数据库]
D --> E[提取文献的关键信息]
E --> F[整合信息生成综述]
F --> G[输出综述给用户]
G --> H[收集用户反馈,优化prompt]
以下是“分层记忆机制”的流程图:
graph TD
A[用户输入] --> B[短期记忆(存储最近对话)]
A --> C[长期记忆(向量数据库,存储历史偏好)]
B --> D[整合短期记忆到prompt]
C --> E[语义检索相关长期记忆]
E --> D
D --> F[生成动态prompt]
F --> G[Agent执行任务]
参考资料
- OpenAI Blog: 《Agentic AI: The Future of AI Interaction》;
- LangChain Documentation: 《Agents》;
- arXiv Paper: 《AutoPrompt: Automatic Prompt Construction for Few-Shot Learning》;
- DeepMind Blog: 《Building Autonomous Agents with Large Language Models》。
更多推荐

 22
22 0
0- 0



 已为社区贡献90条内容
已为社区贡献90条内容

所有评论(0)