【智能体记忆】记忆管理系统:mem0介绍
本文介绍了mem0这款开源的“记忆层”框架,它能为 AI 系统提供跨会话的持久化记忆,用于存储、管理和检索用户及智能体的长期与短期上下文信息,从而实现更情境化和个性化的交互。借助案例来辅助理解men0的应用实现机制,希望对你理解智能体记忆有所启发和帮助。
目录

1.mem0 是什么?
mem0 是一个开源的 “Memory Layer(记忆层)” 库/服务,旨在为人工智能系统实现持久上下文记忆。 他能够使你构建的智能体跨会话记住用户或系统提供的信息,并在将来使用时自动检索和调用它。
换句话说,如果你用 OpenAI/Claude 等 API 做了一个 AI 助手,默认它的“记忆”只在当前上下文(prompt)窗口里,结束对话就忘了。但 mem0 能帮你把重要信息保存下来,下次会话也能回忆起来。
智能体(Agent)需要强大的记忆机制来实现以下关键功能:
-
在多个交互序列和会话中保持对话上下文
-
从历史互动中学习并为未来互动创造背景
-
实施与时俱进的自适应个性化系统
如果没有完善的记忆架构,智能体(Agent)将以无状态运行,将每次交互都视为一个孤立事件。这种架构限制会导致上下文信息丢失,并阻碍复杂的情境化和个性化交互的实现,导致差的用户体验。
mem0代码仓库:https://github.com/mem0ai/mem0
2.搭建 mem0 开源版环境
使用 Python 包存储库安装
pip install mem0ai
为 chromadb 安装额外的依赖项
pip install chromadb
mem0 组件
mem0的主要代码可以在GitHub repo中找到https://github.com/mem0ai/mem0/
mem0内存管理
信息提取(Information Extraction)
- 事实提取(Fact Extraction):系统使用大型语言模型(LLM)分析对话数据,从中提取离散的记忆单元,并在对话上下文中识别各个实体之间的关系。
- 记忆处理(Memory Processing):系统使用大型语言模型(LLM)基于新提取信息与当前已有记忆单元之间的语义相关性分析,决定是否执行添加、删除或更新等合适的记忆操作。
内存架构
实现双数据库方法,向量存储支持语义检索,图数据库维护关系拓扑。检索机制利用语义相似度评分和图遍历算法,并根据相关性指标和时间近因进行优先排序。
3.技术实现
3.1 使用的组件
ChromaDB:具有高效语义搜索功能的嵌入式矢量数据库
GPT-4o:OpenAI 用于高级 NLP 处理的 LLM
对于 LLM 接口,mem0 利用 litegpt 库,通过统一的 API 提供对众多 LLM 提供程序和模型的抽访问。此架构支持灵活的模型选择,同时无论底层模型实现如何,都能保持一致的内存操作。
3.2 记忆创建过程
mem0 利用底层 LLM 和精心构建的提示来协调记忆操作。该框架从对话中提取语义事实,根据现有记忆进行处理,并选择性地存储相关信息。
在下面的实现中,我们演示了如何通过实现custom_prompt配置参数中定义的定制提示来覆盖默认的事实提取行为。
import chromadb
from neo4j import GraphDatabase
from mem0 import MemoryClient
from mem0 import Memory
#mem0 configuration
config = {
"vector_store": {
"provider": "chroma",
"config": {
"collection_name": "test",
"path": "/Users/pi/LL/src/mem0/db",
}
},
"llm": {
"provider": "openai",
"config": {
"api_key": openai_api_key,
"model": "gpt-4o-mini",
"temperature": 0.1,
"max_tokens": 2048,
"top_p": 1.0,
"top_k":10,
}
},
"embedder": {
"provider": "openai",
"config": {
"api_key": openai_api_key,
"model": "text-embedding-3-small"
}
},
"history_db_path": "/Users/pi/LL/src/mem0/history.db",
"version": "v1.1",
"user_email" : "AA",
"custom_fact_extraction_prompt": custom_prompt
}
# Initialize mem0 client
client = Memory.from_config(config)
app_id="test_application"3.3 通过对话创造回忆
本节演示如何创建和存储用户与助手之间对话的记忆。示例展示了如何处理两轮对话,并将其与相应的用户标识一起添加到记忆系统中。
m=[]
# 第一轮:关于印度名人的初步对话
m=[{ "role" : "user" , "content" : "用户想知道印度名人的情况" }]
m.append({ "role" : "assistant" , "content" : "印度在各个领域都涌现出许多名人。以下是一些著名人物:\
圣雄甘地——因其在印度独立运动中通过非暴力不合作所发挥的作用而闻名。\
BR 安贝德卡尔博士——一位颇具影响力的社会改革家和印度宪法的主要制定者。\
拉宾德拉纳特·泰戈尔——一位诗人、作家,第一位获得诺贝尔文学奖的非欧洲人。\
特蕾莎修女——因其人道主义工作和帮助穷人和病人的奉献精神而闻名。APJ 阿卜杜勒·卡拉姆——一位科学家和印度第 11 任总统,因其在航空航天工程领域的工作和鼓舞人心的领导而闻名。\
这些人为社会做出了重大贡献,并在印度和世界各地留下了持久的影响。 " })
result=client.add(
m,
metadata={ "app_id" : app_id},
user_id= "user1"
)
print ( "第一轮记忆结果:" , result)
# 第二轮:用户询问印度菜
m2=[{ "role" : "user" , "content" : "我应该尝试哪些著名的印度菜?" }]
m2.append({ "role" : "assistant" , "content" : "印度提供丰富多样的美味佳肴。以下是您绝对应该尝试的一些菜肴:\
\n\n1. 黄油鸡 - 一种以奶油番茄为基底的咖喱,配以鲜嫩的鸡块\
\n2. 马萨拉多萨 - 一种酥脆的米饼,内馅是香料土豆\
\n3. 印度香饭 - 一种香喷喷的米饭,配有肉类或蔬菜和香料\
\n4. 萨莫萨三角饺 - 一种三角形的糕点,内馅是香料土豆和豌豆\
\n5. 恰特 - 一种以酥脆元素、酸奶和浓郁酸辣酱为特色的咸味小吃\
\n6. 菠菜奶酪 - 菠菜酱汁中的奶酪块\
\n\n这些菜肴代表了印度的不同地区,展示了印度菜的多元风味。" })
result2=client.添加(
m2,
元数据={ “app_id”:app_id},
user_id= “user1”
)
print(“第二轮记忆结果:”,result2)3.4 记忆存储和检索
embedding_metadata在检查底层存储系统时,我们可以观察到 mem0 的向量数据库操作将数据持久存储在指定的数据库文件夹中。为了更好地理解内存的结构和访问方式,让我们检查一下文件中表的内容chroma.sqlite3。
下表显示了存储有用户身份信息的记忆示例:
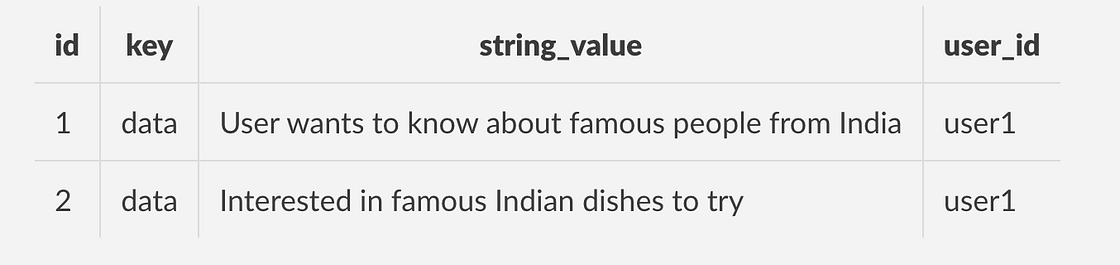
请注意,当我们user_id在记忆创建请求中仅提供参数时,系统会专门捕获用户的查询并创建记忆,而不是完整的对话内容。
3.5 智能体(Agent)的记忆存储
该agent_id参数启用了一种从AI助手视角存储记忆的机制。代理记忆专门捕捉助手产生的洞察或明确提供给助手的信息。
# 第三轮:助手识别用户的食物偏好
m3=[{"role": "assistant", "content": "听说你喜欢吃辣真是太好了,
尤其是咖喱!Vindaloo确实以其辛辣和复杂的口味而闻名,最初来自果阿,但在印度
和国外都很受欢迎。你去年出差时在孟买尝过的那道菜一定是正宗的。孟买有一些很棒
的餐厅,供应来自印度各地的地方美食。你在旅行期间还尝过其他地方特产吗?许多旅
行者发现印度的食物因地区而异。"}]
result3=client.add(
m3,
metadata={"app_id": app_id},
agent_id="agent1"
)
print("Turn 3 Memory Result:", result3)在检查底层存储系统时,我们可以观察到智能体(Agent)记忆的结构与用户记忆的不同:

这种差异化使得AI应用系统能够维护基于独特视角的记忆,从而随着时间的推移,对交互产生更复杂、更细致的理解。代理记忆作为系统自身学习到的关于用户的观察结果,能够在未来的交互中提供更个性化的响应,而无需用户明确重复输入。
3.5 利用短期记忆处理临时上下文
mem0 通过会话作用域存储(session-scoped storage)支持短期记忆管理。
借助 run_id 参数,开发者可以创建仅在特定交互会话中持久存在的上下文记忆。
result3 = client.add(
m3,
metadata={"app_id": app_id},
run_id="trip-planning-2024"
)
当会话结束时,与之相关的记忆run_id可以被删除
3.6 召回之前的记忆
检索用户特定记忆
搜索功能提供了语义检索功能,可以访问与特定用户相关的记忆。这使我们能够获取按用户身份筛选并按与查询的相关性排序的记忆
retrieved_memories = client.search(
"What do we know about this user?",
user_id="user1",
limit=10
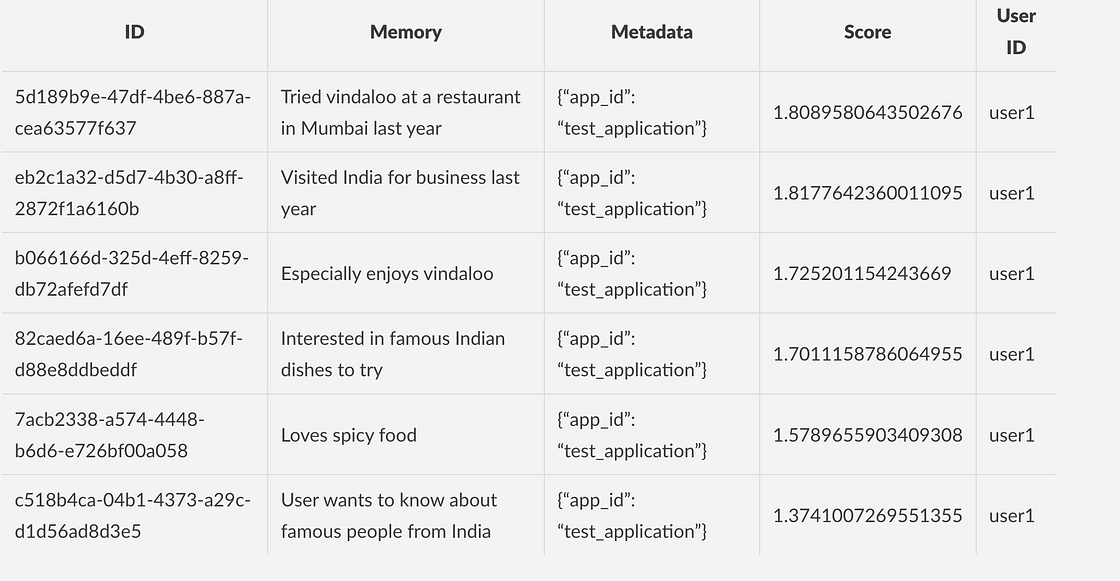
)搜索功能根据查询文本进行语义匹配,并返回具有相似度分数的相关记忆,从而实现符合情境的记忆检索。
检查结果时,我们可以看到相关记忆按其与查询的语义相似度排序
检索特定于智能体(Agent)的记忆
用户记忆记录的是用户请求的信息,而智能体记忆则追踪的是 AI智能体生成的洞察。为了检索这些特定于智能体的记忆,我们可以利用带有代理标识符的搜索功能:
retrieved_memories = client.search(
"What does the agent know about this user?",
agent_id="agent1",
limit=10
)当我们检查返回的数据时,可以看到系统是如何捕捉并对智能体(Agent)的观点进行排序的:

这些记忆代表了智能体在对话过程中了解到的有关用户的事实。
3.7 批量记忆检索
为了进行全面的内存分析或系统调试,mem0 提供了使用函数检索与特定标识符关联的所有记忆的功能get_all。以下示例演示了如何批量检索会话特定的记忆:
# 从特定会话中检索所有记忆
retrieved_memories = client.get_all(
run_id="trip-planning-2024",
limit=10
)结果提供了在指定会话上下文中创建的记忆的完整视图:

我们也可以通过将 user_id 和 agent_id 作为输入参数传递给 get_all 函数(而不是使用 run_id),来检索与它们关联的所有记忆。
3.8 删除个人记忆
mem0 框架通过delete对特定记忆标识符进行操作的方法,对记忆删除提供精确的控制:
# 使用唯一ID删除特定记忆
client.delete(memory_id="d978d2a8-2fa4-402d-90e2-722f357fedc3")这种细粒度的方法可以实现选择性内存管理,允许系统删除过时或不正确的信息,同时保留上下文的完整性。
3.9 批量删除记忆
为了进行更全面的清理操作,该delete_all方法可以根据关联的标识符有效地删除多个记忆:
# 删除与特定会话相关的所有记忆
client.delete_all(
run_id="trip-planning-2024",
limit=10
)此功能支持各种过滤参数,包括user_id和agent_id,从而实现跨不同内存类别的有针对性的记忆管理。
3.10 完成系统重置
在实现开发迭代或与隐私相关的数据清除时,该reset函数提供了完整的记忆系统初始化:
# 彻底清除 系统客户端的所有记忆
client.reset()此操作可有效地将记忆存储重置为其初始状态,删除所有存储的记忆,无论其关联的标识符或元数据是什么。
4.总结
本文介绍了mem0这款开源的“记忆层”框架,它能为 AI 系统提供跨会话的持久化记忆,用于存储、管理和检索用户及智能体的长期与短期上下文信息,从而实现更情境化和个性化的交互。借助案例来辅助理解men0的应用实现机制,希望对你理解智能体记忆有所启发和帮助。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)