
大模型微调的数据准备
大模型微调数据准备
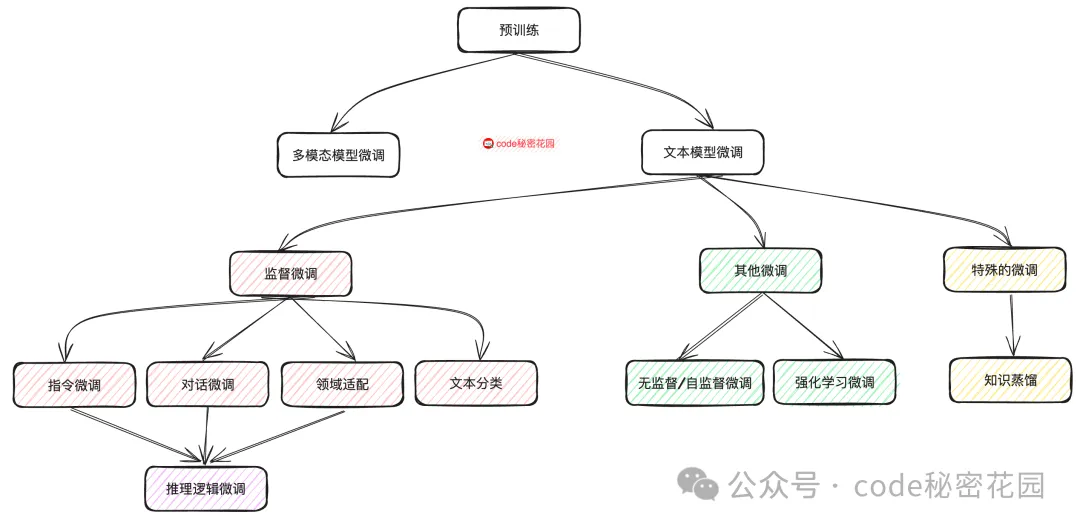
微调的类型
给模型喂的数据需要什么样的格式,要根据微调任务类型决定。不同的业务场景下解决不同的问题,采取的微调任务类型是不一样的,所用的数据集格式也有所差别。
预训练
从零开始训练一个模型,这个流程叫做预训练,这个过程的目的就是让模型掌握语言的通用规律,以及基本的语言理解能力。目前主流的大模型,比如 ChatGPT、DeepDeek 等都属于 “自回归模型”,而 “自回归模型” 的本质就是:用过去的自己来预测未来的自己。
Token 简单理解就是把句子拆成最小语义单元(如中文拆字 / 词,英文拆词或子词)。给定模型一个问题时,模型先会预测出第一个 Token,然后根据问题和第一个 Token 再去预测第二个 Token。在预训练的过程中,一般用海量非结构化文本(比如书籍、网页、对话),通过「预测下一个词」来训练模型,这也就意味着预训练的数据集格式是没有明确要求的。
微调
有监督
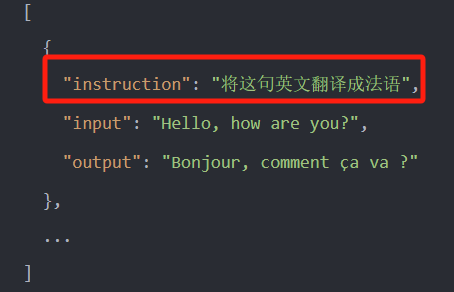
指令微调
如在翻译任务中,Input 与output 可能是不一样的,此时需要一个指令告诉模型。
指令微调常见的业务场景:
-
智能教育:实现作业辅导、规划个性化学习路径、辅助语言学习。
-
智能办公:可处理文档、邮件,进行日程管理。
-
智能翻译:应用于专业领域翻译、特定场景翻译及多语言交互。
-
数据分析:让模型根据分析需求指令,对数据进行准确解读和洞察。
指令微调的数据集制作相对简单,要执行的任务一般很明确,有比较明确的答案了,比如想要微调模型在翻译方面的能力,那就用现成的翻译 API 来构造数据集;想要微调模型在数学解题方面的能力,其实也有现成的题目 + 答案可以用来构造。所以指令微调场景的数据集一般不太难做,主要进行一些格式转换的工作即可。
对话微调
通过多轮对话数据训练模型生成连贯、符合语境的回复,强调对话历史的上下文理解和回复的自然流畅性。其核心在于教会模型处理对话中的逻辑关系、情感表达和角色身份,对话微调的数据集通常包含对话的上下文以及对应的回复。

对话微调数据集的核心特点:包含多轮对话上下文、标注角色身份,注重回复连贯性与逻辑性。通过这样的数据,模型可以学习到在不同对话场景下如何生成合适的回复,从而提高对话的连贯性和相关性。
对话微调常见的业务场景:
-
智能客服系统:提升客服机器人在处理用户咨询时的对话能力,能够更准确地理解用户意图并提供解决方案。
-
聊天机器人:让聊天机器人更自然地与用户进行多轮对话,提高用户体验。
-
语音助手:优化语音助手在语音交互中的对话表现,使其更符合用户的期望。
领域适配
在特定领域的数据集上对模型进行训练,通常包含该领域的专业术语、特定格式和相关任务的标注。例如,在医疗领域,数据集可能包含病历文本、医学术语以及对应的诊断结果等信息。

领域适配典型的业务场景:
-
医疗领域适配:用于病历分析、疾病诊断辅助、医疗文献检索等。
-
法律领域适配:辅助法律文件分析、案例检索、合同审查等。
-
金融领域适配:用于风险评估、市场分析报告生成、金融产品推荐等。
文本分类

文本分类微调的典型业务场景:
-
情感分析:商品评论情感极性识别(正面/负面/中性)
-
内容审核:检测违规内容(涉政/暴力/广告)
-
新闻分类:自动归类至财经/科技/体育等栏目
-
意图识别:用户query分类(咨询/投诉/比价)
模型推理
监督微调的一种特殊形式,通过在数据集中显式标注思维链(Chain of Thought, COT),训练模型不仅给出最终答案,还能生成逻辑推导过程。其核心在于让模型学会「分步思考」,适用于需要复杂逻辑推理的场景(如数学证明、代码调试)。
在推理模型(比如 DeepSeek-R1)的回答中,<think></think> 中包含的这部分其实就是模型的推理过程,它其实是根后面的答案一起作为一个回答输出的,只不过在大部分的 C 端应用中对这部分提取出来做了特殊展示。

不是所有任务都适合用推理模型,推理模型的幻觉比较大,有些情况选择推理模型反而会起到相反的效果,在处理简单明确的任务时,推理模型可能会把问题复杂化,导致思考过度、响应较慢,甚至增加幻觉的风险。比如如果你让推理模型去完成检索、解释类的任务时,当它找不到可以参考的信息就会按照自己的思考过程进行输出,结果并不一定准确。
适合用于推理模型微调的场景:
-
代码生成与调试:推理模型能够理解复杂的编程问题,生成高效的代码解决方案,并辅助开发人员进行代码调试。
-
数学问题求解:在数学建模、复杂计算和逻辑推理任务中,推理模型表现出色,能够提供详细的解题步骤和准确的答案。
-
复杂数据分析:推理模型擅长处理需要多步骤推理和策略规划的复杂数据分析任务,帮助科学家和研究人员进行更深入的数据挖掘。
-
法律与金融分析:在处理法律合同、金融协议等复杂文档时,推理模型能够提取关键条款,理解模糊信息,辅助决策。
知识蒸馏
蒸馏技术并不属于微调的范畴,但可以通过微调达到蒸馏的效果,可当作特殊的微调。
知识蒸馏(Knowledge Distillation)是将复杂模型(教师模型)的知识迁移到轻量级模型(学生模型)的技术,通过优化学生模型使其输出接近教师模型的“软标签”,从而在保持性能的同时降低推理成本。
如果大模型可以满足特定任务上的诉求,但部署成本太高,可以选择一个小模型,从大模型里把任务里需要用到的领域知识提取出来,构造成数据集,再去微调小模型,从而让这个小模型也能在你的特定领域完成任务,这就可以理解为一个模型蒸馏的过程。
模型蒸馏的数据集构造应该是最简单的,完全信任大模型输出的条件下,直接将大模型产出的问答对作为数据集,最后在进行人工的质量评估和验证即可。
其他
强化学习
强化学习微调(Reinforcement Learning from Human Feedback,RLHF)是在监督微调的基础上,通过人类来主动反馈优化模型生成质量的方法。核心在于引入奖励模型(Reward Model)评估生成结果的合理性,通过强化学习策略(如 PPO 算法)调整模型参数,使生成内容更符合人类偏好。

强化学习微调的典型业务场景:
-
对话系统优化:提升回复的相关性,对齐人类价值观(安全、无害、有用性)。
-
内容生成:控制输出风格(如幽默、正式)或避免敏感信息。
-
代码生成:优化代码的可读性和正确性。
特殊
多模态
多模态微调(Multimodal Fine-Tuning)指通过文本、图像、语音等多模态数据训练模型,使其具备跨模态理解与生成能力。它和文本类模型的微调可以说是并列的两个范畴,也包括监督/非监督微调、强化学习微调等范畴。
需要注意的是,想要做一个多模态的微调任务,前提是选择的预训练模型一定也要具备基础的多模态理解能力,多模态微调任务涉及多种模态的数据(如文本、图像、音频等),模型需要能够理解和处理这些不同模态的信息,并有效地进行融合和交互。如果预训练模型本身不具备多模态能力,那么在微调阶段将面临很大的挑战,难度不亚于从零训练一个多模态模型。

多模态微调的典型业务场景:
-
图文问答:输入图片和问题,生成答案。
-
视频内容理解:分析视频帧和字幕,生成摘要。
-
跨模态检索:根据文本描述搜索相关图像/视频。
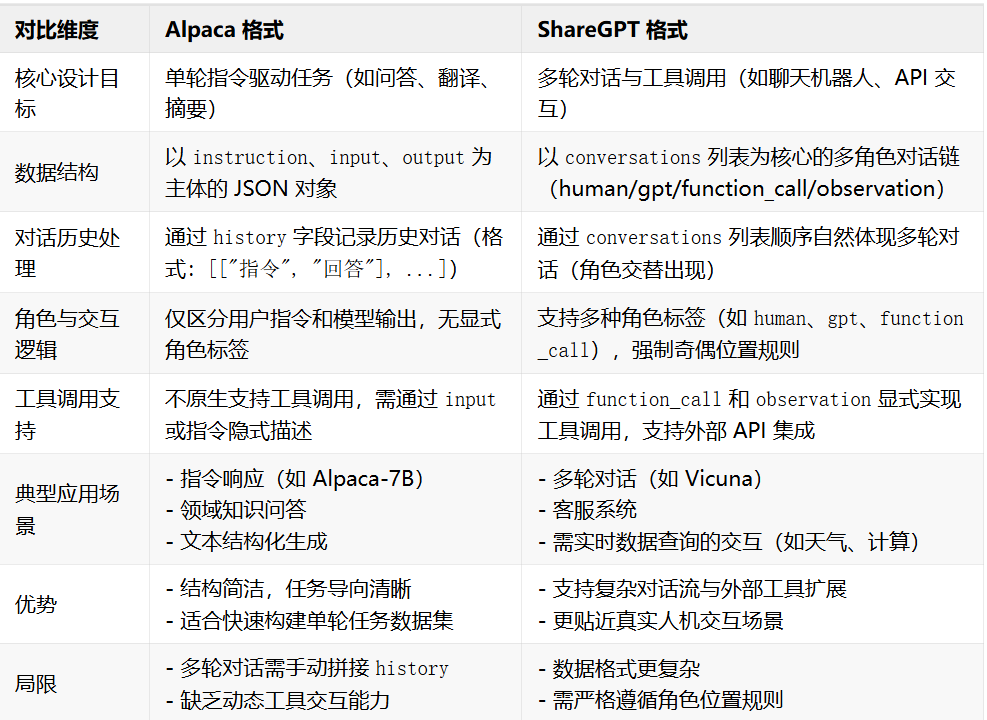
两种常用的数据格式
Alpaca

ShareGPT
一种数据格式标准,由社区设计用于规范多轮对话和工具调用场景的模型训练数据存储方式。核心目标是通过结构化字段(如 conversations 列表、tools 工具描述)支持复杂交互(如用户提问 → 工具调用 → 结果整合)。
核心特征:
-
角色标签包括
human(用户)、gpt(模型)、function_call(工具调用指令)、observation(工具返回结果)等,覆盖完整工具调用流程。 -
消息顺序规则:
human或observation必须出现在奇数位置,gpt或function_call在偶数位置,确保逻辑连贯性。 -
通过
tools字段定义外部工具(如天气查询 API、计算函数),使模型能动态调用外部资源生成响应。 -
通过
conversations列表完整记录对话历史,适用于需上下文理解的场景(如医疗问诊中的连续追问)。

Chat格式和Instruction格式
主要区别在于训练数据和优化目标不同,导致模型能力侧重不同。
训练数据差异
Chat模型采用多轮对话数据进行监督微调,并通过强化学习(如人类反馈优化)提升对话能力。
Instruction模型侧重指令数据微调,通过标注的指令-响应对训练模型理解并执行具体任务。
能力侧重不同
Chat模型更擅长上下文对话生成和多轮交互,能生成连贯回复并维持对话历史。
Instruction模型优势在于精确执行特定指令(如代码生成、设备控制等),但对话生成能力可能稍弱于Chat模型。
适用场景
Chat模型适用于聊天机器人、客服系统等需要维持对话连贯性的场景。
Instruction模型更适合需要精确指令执行的任务(如自动化工具调用、内容创作指导等)。
微调效果
Chat模型因经过多任务微调,对新指令的适应性可能略逊于Instruction模型,但长期效果更稳定。
Instruction模型对单一指令优化更好,但多任务性能依赖指令覆盖度。
参考:
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)