
一文通透多模态LLaVA系列——Visual Instruction Tuning:组合CLIP ViT和Vicuna
前言
本文一开始的标题是《多模态LLaVA系列与Eagle 2——从组合CLIP ViT和Vicuna的LLaVA,到英伟达开源的VLM Eagle 2(用于人形VLA GR00T N1中)》
但考虑到:1 Eagle 2.5也出来了,2 LLaVA的重要性,故把这两部分分开独立,各自成文比较好
故也有了本文
第一部分 LLaVA
1.1 LLaVA
1.1.1 引言与提出背景
基于最近的LLM LLaMA,OpenFlamingo [5]和LLaMA-Adapter [59]使得LLaMA能够接收图像输入,为构建开源多模态LLM铺平了道路
虽然这些模型表现出有前途的任务迁移泛化能力,但它们并未明确使用视觉-语言指令数据进行微调,因此在多模态任务中的表现通常不及仅语言任务
23年12月,来自Wisconsin–Madison大学、微软研究院、哥伦比亚大学的研究者提出了LLaVA
- 其对应的paper为:Visual Instruction Tuning
- 其将CLIP [40]的开放集视觉编码器与语言解码器Vicuna [9]连接起来,并在生成的指令视觉-语言数据上进行端到端微调
1.1.2 GPT辅助的视觉指令数据生成
受到最近GPT模型在文本注释任务中成功的启发[17],作者提出利用ChatGPT/GPT-4进行多模态指令跟随数据收集——基于广泛存在的图像对数据
- 对于一张图像
及其相关的描述
,自然的做法是创建一组问题
,以引导助手描述图像内容。作者提示GPT-4来策划这样一组问题(详见附录)
因此,将图像-文本对扩展为遵循指令的版本的一种简单方法是
说白了,就是让GPT4 给一张张图像打字幕,以拿到图像-字幕对数据..
虽然构造成本低,但这种简单的扩展版本在指令和响应中都缺乏多样性和深入推理 - 为了解决这个问题,作者利用仅支持文本的 GPT-4 或 ChatGPT 作为强大的教师(两者都仅接受文本作为输入),以创建涉及视觉内容的指令跟随数据
具体来说,为了将图像编码为视觉特征,以提示仅支持文本的 GPT,使用两种符号表示:
- 字幕通常从不同的角度描述视觉场景
- 边界框通常定位场景中的对象,每个框都编码对象的概念及其空间位置
通过这种符号表示法使得能够将图像编码为LLM可识别的序列,一个示例如表 14 顶部模块所示,作者使用COCO图像[31]并生成三种类型的指令遵循数据「对于每种类型,首先手动设计一些示例。这些是作者在数据收集中拥有的唯一人工注释,并用作上下文学习中的种子示例以查询GPT-4」

- 对话
作者设计了一段助理与一个人就这张照片进行问答的对话。回答的语气好像助理正在观察图像并回答问题
关于图像的视觉内容,提出了多样化的问题,包括对象类型、对象数量、对象动作、对象位置、对象之间的相对位置。仅考虑有明确答案的问题。详细提示请参见附录 - 详细描述
为了为图像提供丰富而全面的描述,作者创建了一个包含此意图的问题列表。提示GPT-4,然后整理此列表
对于每张图像,从列表中随机抽取一个问题,要求GPT-4生成详细描述 - 复杂推理
这两种类型主要关注于视觉内容本身,在此基础上,进一步创建深入的推理问题。答案通常需要遵循严格的逻辑进行逐步推理
最终,作者总共收集了158K个独特的语言-图像指令跟随样本,包括58K个对话样本,23K个详细描述样本,以及77K个复杂推理样本。在早期实验中,作者对ChatGPT和GPT-4的使用进行了消融实验,发现GPT-4始终提供更高质量的指令跟随数据,例如空间推理
1.2 可视化指令调整
1.2.1 架构
主要目标是有效利用预训练的大语言模型(LLM)和视觉模型的能力。网络架构如下图图1所示
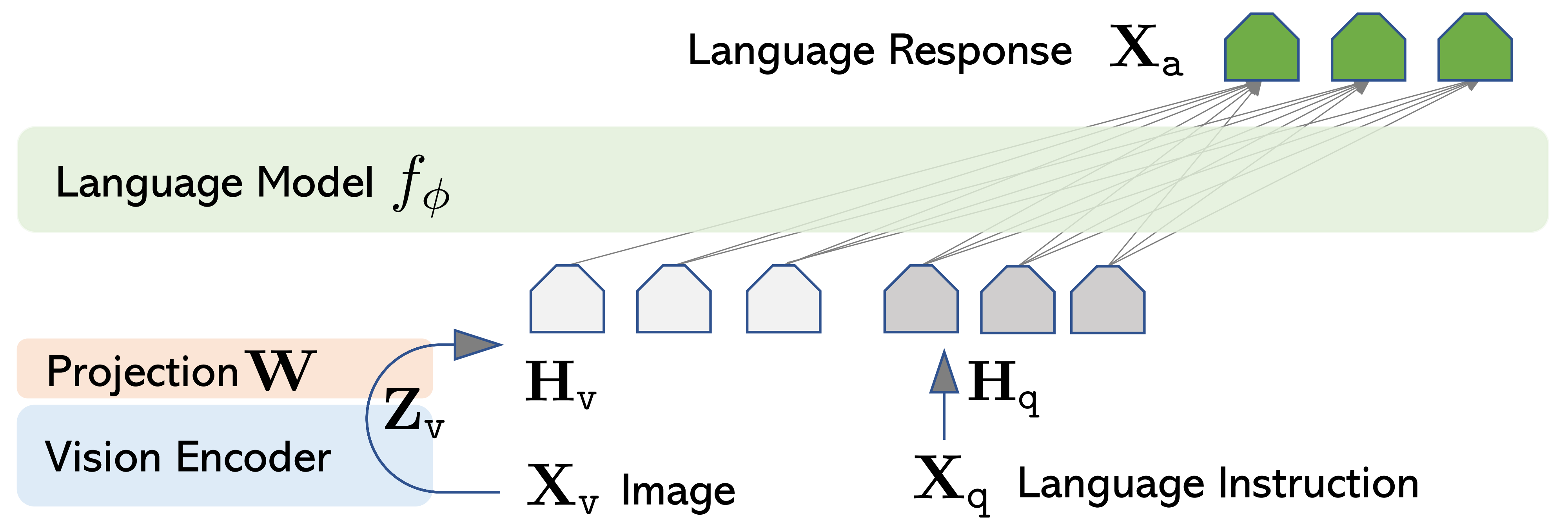
- 作者选择了Vicuna 『9,详见此文《LLaMA的解读与其微调(含LLaMA 2):Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙》的「2.3.1 UC Berkeley的Vicuna/FastChat:通过ShareGPT.com的7万条对话数据微调LLaMA」』 作为
,由
参数化
- 因为它在公开可用的检查点中具有语言任务中最佳的指令跟随能力[48,9,38]——注意 此点限定在24年之前
对于输入图像,考虑预训练的CLIP 视觉编码器ViT-L/14 [40],其提供视觉特征
- 在实验中,考虑了最后一个Transformer 层之前和之后的网格特征,以及使用一个简单的线性层将图像特征连接到词嵌入空间
- 具体来说,应用一个可训练的投影矩阵
将
转换为语言嵌入token
,其具有与语言模型中词嵌入空间相同的维度
当然,也可以考虑更复杂的图像和语言表示连接方案,例如Flamingo [2]中的门控交叉注意力和BLIP-2 [28]中的Q-former
1.2.2 训练
// 待更
更多推荐


 32
32 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)