
【MLLM】Qwen-Omni系列全模态模型架构和训练
note
- Qwen3-Omni系列模型,模型输入可以是文本、图片、语音、视频;输出可以是流式的文本/语音:
- Thinker(思考者):基于混合专家(MoE)架构,负责文本语义的理解与生成,是模型处理逻辑、知识和推理的“大脑”。它确保了在处理音视频任务时,核心的文本与图像能力不受干扰,真正实现“全模态不降智”。
- Talker(表达者):同样基于 MoE 架构,专注于流式语音 Token 的生成。它直接接收来自 Thinker 的高层语义表征,确保语音输出与文本意图高度一致,避免了传统端到端模型在语音生成过程中对语义理解的损耗。
- Qwen3-omni模型训练:
- 预训练:编码器对齐阶段(S1)即先训练adapter再训练编码器、通用阶段 (S2)即全参训练、长上下文阶段 (S3)即逐渐增加长视频、长音频数据的比例训练。
- Thinker的后训练:轻量级SFT、强弱模型蒸馏即离策略蒸馏(Off-policy Distillation)+在线策略蒸馏(On-policy Distillation)、GSPO强化学习训练(基于规则的奖励、基于模型评估的奖励)
- Talker的后训练:多模态到语音的映射、持续预训练 (CPT)、直接偏好优化 (DPO)、说话人微调即学习特定音色
- 在Qwen3-Omni-30B-A3B的基础上微调得到了 Qwen3-Omni-30B-A3B-Captioner。该模型能为任意音频输入生成详细、低幻觉的字幕
- Qwen3-omni的后续工作:通义团队将沿多个技术方向持续推进模型升级,包括多说话人ASR、视频OCR、音视频主动学习等核心能力建设,并强化基于智能体的工作流与函数调用支持。
- Qwen3-Omni模型代码源码解读:Qwen3-Omni全模态模型源码解读
- 使用:打开千问 https://chat.qwen.ai/,支持语音通话和视频通话
- Qwen 2.5 Omni 的实时交互能力:视频聊天:支持实时视频交互。多模态理解:可以同时处理视频画面和声音。即时响应:支持流式输出,反应快速自然
一、Qwen3-Omni系列模型
1、模型架构
一个真正的性能无损的多模态系统应具备两大特性:
- 1能力对等:在各个单模态任务上,其性能与专门的单模态模型相当。
- 2协同增益:能促进新颖的、单模态模型不具备的跨模态推理和交互能力。
五大关键升级:
- Thinker和Talker均升级为混合专家(MoE)架构。
- 用自研的、在2000万小时有监督音频上训练的AuT音频编码器取代了Whisper,提供了更强的通用音频表示。
- 语音生成端采用多codebook(multi-codebook)表示,增强了对多样化声音和声学现象的建模能力。
- Talker从单轨解码转向多轨编解码器(codec)建模,并用轻量级的卷积网络(ConvNet)取代了计算密集的扩散模型(DiT)。
- 输入输出音频码率降至12.5Hz,实现了单帧即时语音合成。
阿里此次开源了三种 Qwen3-Omni 模型变体,均基于 30B 参数,采用 Apache 2.0 许可:
- Qwen3-Omni-30B-A3B-Instruct:优化指令跟随,适合交互式任务。
- Qwen3-Omni-30B-A3B-Thinking:增强复杂推理,适合逻辑分析。
- Qwen3-Omni-30B-A3B-Captioner:低幻觉音频字幕生成,适合媒体应用。
组成模块:
- Thinker(思考者):基于混合专家(MoE)架构,负责文本语义的理解与生成,是模型处理逻辑、知识和推理的“大脑”。它确保了在处理音视频任务时,核心的文本与图像能力不受干扰,真正实现“全模态不降智”。
- Talker(表达者):同样基于 MoE 架构,专注于流式语音 Token 的生成。它直接接收来自 Thinker 的高层语义表征,确保语音输出与文本意图高度一致,避免了传统端到端模型在语音生成过程中对语义理解的损耗。
(1)概述
模型架构:
- 音频编码:模型的音频编码器采用基于 2000 万小时数据训练的 AuT 模型,为音视频理解提供了强大的通用表征基础。
- 推理加速:为实现毫秒级实时交互,Talker 采用了创新的多codebook自回归方案,在每一步解码中,MTP(Multi-Token Prediction)模块会预测当前音频帧的残差codebook。随后,Code2Wav 模块将这些codebook即时合成为波形,实现逐帧流式音频生成。

Qwen3-Omni 通过 Vision Encoder 和 AuT 音频编码器将图文音视频输入编码为隐藏状态,由 MoE Thinker 负责文本生成与语义理解,再由 MoE Talker 结合 MTP 模块,实现超低延迟的流式语音生成。
推理效果:得益于这一协同设计,Qwen3-Omni 纯模型端到端的音频对话延迟可低至 211ms,视频对话延迟可低至 507ms,交互体验如真人对话般自然流畅。
(2)音频转换器 (Audio Transformer, AuT)

AuT是一个基于Attention的编码器-解码器模型,它在2000万小时的有监督音频数据上从零开始训练。其训练数据包含80%的中英文ASR(自动语音识别)伪标签数据、10%的其他语言ASR数据和10%的音频理解数据。AuT采用了动态大小的注意力窗口,以平衡实时预填充缓存的效率和离线音频任务的性能。在Qwen3-Omni中,作者们使用了约6亿参数的AuT编码器作为音频编码器。
(3)多模态输入
多模态输入处理:
- 文本:使用Qwen的分词器。
- 音频:重采样至16kHz,转换为128通道的mel谱图,再由AuT编码器处理。
- 图像/视频:采用Qwen3-VL的视觉编码器,该编码器从SigLIP2-So400m初始化,约5.4亿参数。
注意:时间对齐的多模态旋转位置嵌入 (TM-RoPE):
受Qwen2.5-Omni启发,作者们采用了TM-RoPE,它将传统RoPE分解为时间、高度、宽度三个维度。
(4)语音生成
Qwen3-Omni的Talker模块直接在RVQ(残差矢量量化)token上操作。它采用一种层级预测方案:主干网络接收当前帧的聚合codebook特征,并用一个线性头预测第0个codebook;然后,一个多令牌预测(MTP) 模块生成所有剩余的残差codebook。这一策略使模型能够学习声学细节的完整表示,增强了声音的表现力。因此,波形重建被简化为一个轻量级的因果ConvNet(Code2Wav),这在降低推理延迟和计算成本的同时,实现了比复杂的DiT-based声码器更高的音频保真度。
(5)为流式和并发所做的设计
- 分块预填充 (Chunked Prefilling) 和 MoE 架构:保留了Qwen2.5-Omni中的分块预填充机制,音频和视觉编码器能沿时间维度输出块。Thinker和Talker异步预填充,显著减少了首个token的响应时间(TTFT)。同时,MoE架构通过减少长序列处理中的KV Cache I/O消耗,有效提升了服务吞吐量和并发能力。
- 流式多码本编解码器生成:为最小化首包延迟,作者们提出了一个仅依赖左侧上下文的多码本生成机制。一旦Talker生成第一个token,MTP模块就会预测当前帧的剩余token,然后这些token被一个流式的、仅关注左侧上下文的解码器解码成波形。这与Qwen2.5-Omni需要等待足够上下文才能合成的机制形成鲜明对比,极大地降低了首包延迟。
- 轻量级MTP模块和ConvNet:MTP模块是一个超轻量级的定步自回归Transformer,而基于ConvNet的解码器也能高效地进行批处理推理。两者都具有低计算开销和高吞吐量的特点。
表1: Qwen3-Omni-30B-A3B的架构设计和端到端首包延迟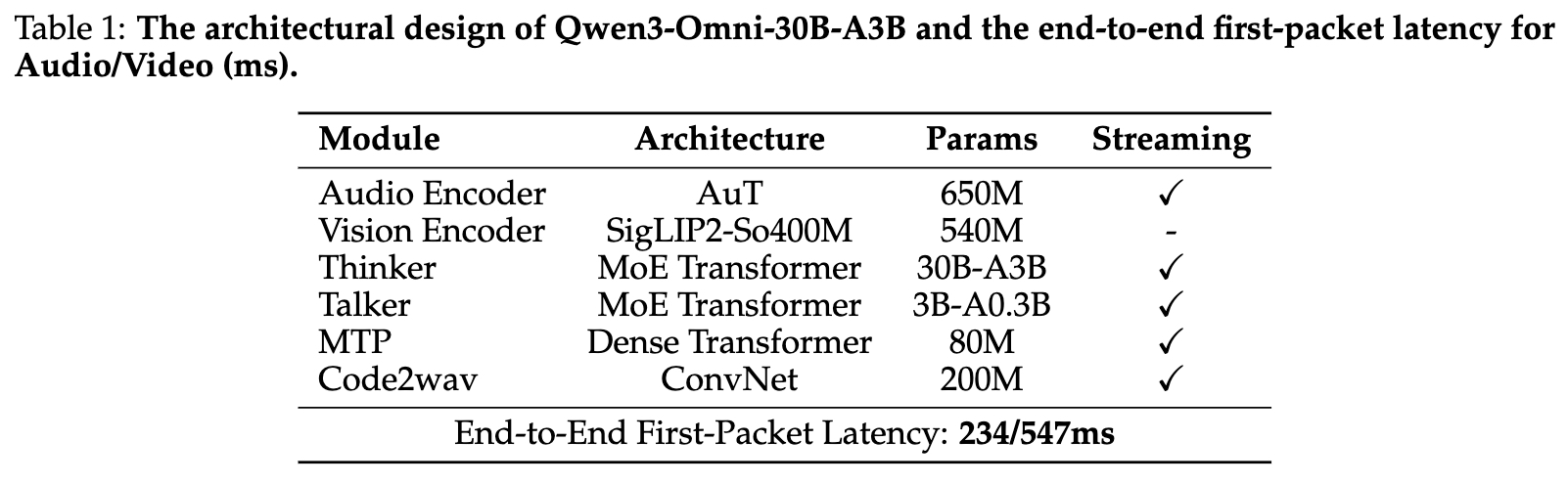
表2: Qwen3-Omni在不同并发下的理论首包延迟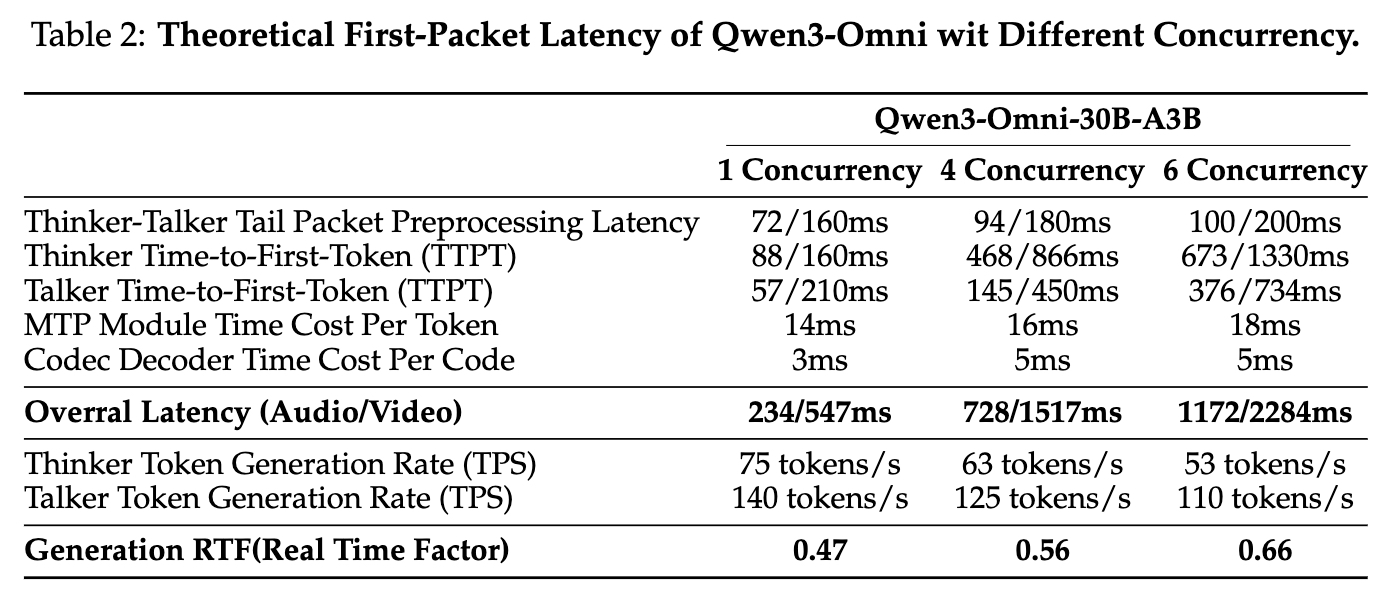
如上表所示,在单并发的冷启动设置下,Qwen3-Omni的端到端首包延迟理论上可低至234毫秒(音频)/ 547毫秒(视频)。得益于MoE架构和轻量化设计,即使在多并发场景下,其延迟和实时率(RTF)也保持在可接受的范围内,确保了流畅的流式音频响应体验。
2、模型训练
(1)预训练
Qwen3-Omni在一个包含多种语言和模态(图文、视频文、音文、音视频、音视频文、纯文本)的多样化数据集上进行预训练。其预训练分为三个阶段:
- 编码器对齐阶段(S1):在初始预训练阶段,Qwen3-Omni的LLM组件使用Qwen3的参数进行初始化,视觉编码器采用自 Qwen3-VL,音频编码器使用 AuT 初始化。两个编码器在固定的 LLM 上分别进行训练,最初都专注于训练各自的适配器(adapters),然后再训练编码器本身。
- 我们摒弃了 Bai et al. (2025) 和 Xu et al. (2025) 中使用的在LLM冻结时联合训练编码器和适配器的阶段,因为这种方法可能导致编码器去补偿冻结 LLM 的局限性,从而导致感知能力下降。
- 通用阶段 (S2):解冻所有参数,在一个约2万亿token的大规模多模态数据集上进行训练,以增强模型的综合理解和交互能力。
- 长上下文阶段 (S3):将最大token长度从8192增加到32768,并增加长音频和长视频在训练数据中的比例,显著提升了模型对长序列数据的理解能力。
(2)后训练
1)Thinker模块
Thinker的后训练同样分为三阶段:
- 轻量级SFT:通过有针对性的指令微调,弥合预训练表示与下游任务之间的差距。
- 强弱模型蒸馏:
- 离策略蒸馏(Off-policy Distillation):首先进行离策略蒸馏,让学生模型学习教师模型(如Qwen3-32B或Qwen3-235B)的响应,以获得基础推理能力;
- 在线策略蒸馏(On-policy Distillation):然后进行在策略蒸馏,让学生模型自己生成响应,再通过最小化与教师模型logits的KL散度进行微调。
- GSPO:利用GSPO(Group Sequence Policy Optimization)全面增强模型在文本、图像、视频和音频等所有模态上的能力和稳定性。反馈信号来自两种奖励:
- 基于规则的奖励:用于数学、代码等可验证的多模态任务。
- 基于模型的奖励:对于缺乏客观评价指标的任务,采用“LLM即评委”的协议,使用Qwen3和Qwen2.5-VL作为自动评估器。
2)Talker
Talker的后训练分为四阶段,以实现与文本同步的语音响应生成。所有训练数据均采用 ChatML 格式,以确保与思考者(Thinker)的一致性。
- 多模态到语音的映射:利用数亿条带多模态上下文的语音数据进行训练,建立从多模态表示到语音的映射。
- 持续预训练 (CPT):用高质量数据进行CPT,以减轻第一阶段噪声数据带来的幻觉,并提升长上下文处理能力。
- 直接偏好优化 (DPO):构建多语言语音样本的偏好对,使用DPO优化模型,以提高多语言语音生成的稳定性和泛化能力。
- 说话人微调:在基础模型上进行特定说话人的微调,以实现特定音色的采纳,并提升语音的自然度、表现力和可控性。
3)字幕生成器 (Captioner)
为了弥补当前多模态研究中对音频字幕生成的忽视,作者们在Qwen3-Omni-30B-A3B的基础上微调得到了 Qwen3-Omni-30B-A3B-Captioner。该模型能为任意音频输入生成详细、低幻觉的字幕,为多模态感知研究提供了重要的基础工具。
3、模型评估
音视频能力强劲:在 36 项音视频基准测试中,32 项取得开源模型最佳效果,22项达到 SOTA 水平。性能表现超越 Seed-ASR、GPT-4o-Transcribe 等闭源模型。
文本能力稳定:在 MMLU-Redux、AIME25 等文本评测中,Qwen3-Omni-30B-A3B 得分分别为 85.9 和 64.0,与参数量更大的单模态模型 Qwen3-235B-A22B(89.2, 24.7)表现接近。
图像能力扎实:在 MMMU 和 CountBench 图像理解评测中得分 69.1 和 90.0,与专用视觉模型 Qwen2.5-VL-72B 表现相当。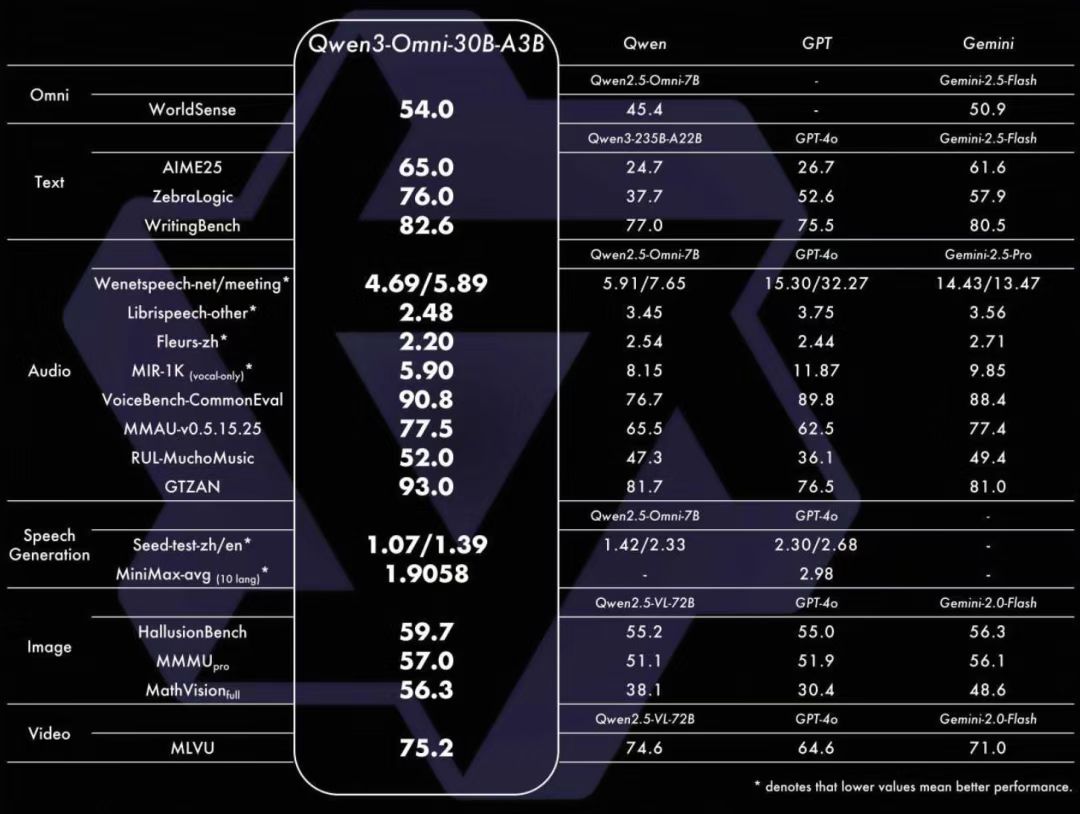
(1)X→文本 评估
文本→文本:在通用任务、推理、代码、对齐、智能体和多语言等六大类任务上进行评估。如表4和表5所示,Qwen3-Omni-30B-A3B-Instruct在GPQA、AIME25等多个基准上超越了更大规模的开源模型和强大的闭源模型GPT-4o。其Thinking版本也表现出与Gemini-2.5-Flash-Thinking相当的性能。
[表4: Qwen3-Omni-Instruct与其他非推理基线的文本→文本性能]
[表5: Qwen3-Omni-Thinking与其他推理基线的文本→文本性能]
音频→文本:在ASR、S2TT、语音聊天、音频推理和音乐理解等任务上进行评估。如表6、7、8所示,Qwen3-OmnOmni在这些任务上取得了惊人的成绩,在多个基准上刷新了SOTA记录,超越了包括Gemini-2.5-Pro、GPT-4o-Audio在内的众多专业或通用模型。这充分展示了其在通用音频理解和推理方面的强大能力。
[表6: 音频→文本任务的转录性能对比]
[表7: 音频→文本任务的语音交互和音频推理性能对比]
[表8: 音频→文本任务的音乐理解性能对比]
视觉→文本:在通用视觉问答、数学/STEM、文档理解、计数和视频理解等任务上进行评估。如表9和表10所示,Qwen3-Omni-Instruct表现出与更大规模的Qwen2.5-VL-72B相当的性能,并在数学/STEM相关任务上优于GPT-4o等模型。其Thinking版本在多个基准上也取得了显著进步。
[表9: Qwen3-Omni-Instruct与其他非推理基线的视觉→文本性能]
音视频→文本:在WorldSense、DailyOmni和VideoHolmes等基准上进行评估。如表11和表12所示,Qwen3-Omni在这些需要整合音视频信息的任务上取得了SOTA性能,展示了其在基础多模态整合和复杂推理方面的巨大潜力。
[表11: Qwen3-Omni-Instruct的音视频→文本性能]
(2)X→语音 评估
作者们在零样本语音生成、多语言语音生成和跨语言语音生成三个方面评估了Qwen3-Omni的语音生成能力。
零样本语音生成:如表13所示,Qwen3-Omni表现出极具竞争力的性能,在经过RL优化后,其生成稳定性和内容一致性达到了最佳水平。
[表13: Seed-TTS测试集上的零样本语音生成]
多语言语音生成:如表14所示,Qwen3-Omni在中文、英文、法文等语言上显著超越了MiniMax和ElevenLabs,并在其他语言上表现相当。
[表14: MiniMax多语言测试集上的多语言语音生成]
跨语言语音生成:如表15所示,Qwen3-Omni在任意语言到英语/韩语的音色克隆上优于CosyVoice3,展示了其在不同语言环境下的强大适应性。
[表15: CosyVoice3跨语言测试集上的跨语言语音生成]
(3)跨模态无损性能评估
为了严格验证“性能无损”这一核心论点,作者们设计了一个受控对比实验。他们训练了三个参数量匹配的模型:纯文本模型、纯视觉模型和多模态的Omni模型。Omni模型在与单模态模型完全相同的文本和视觉语料上训练,唯一的区别是额外加入了音频和音视频数据。
[表16: Qwen系列30B-A3B模型的同尺寸同期性能对比]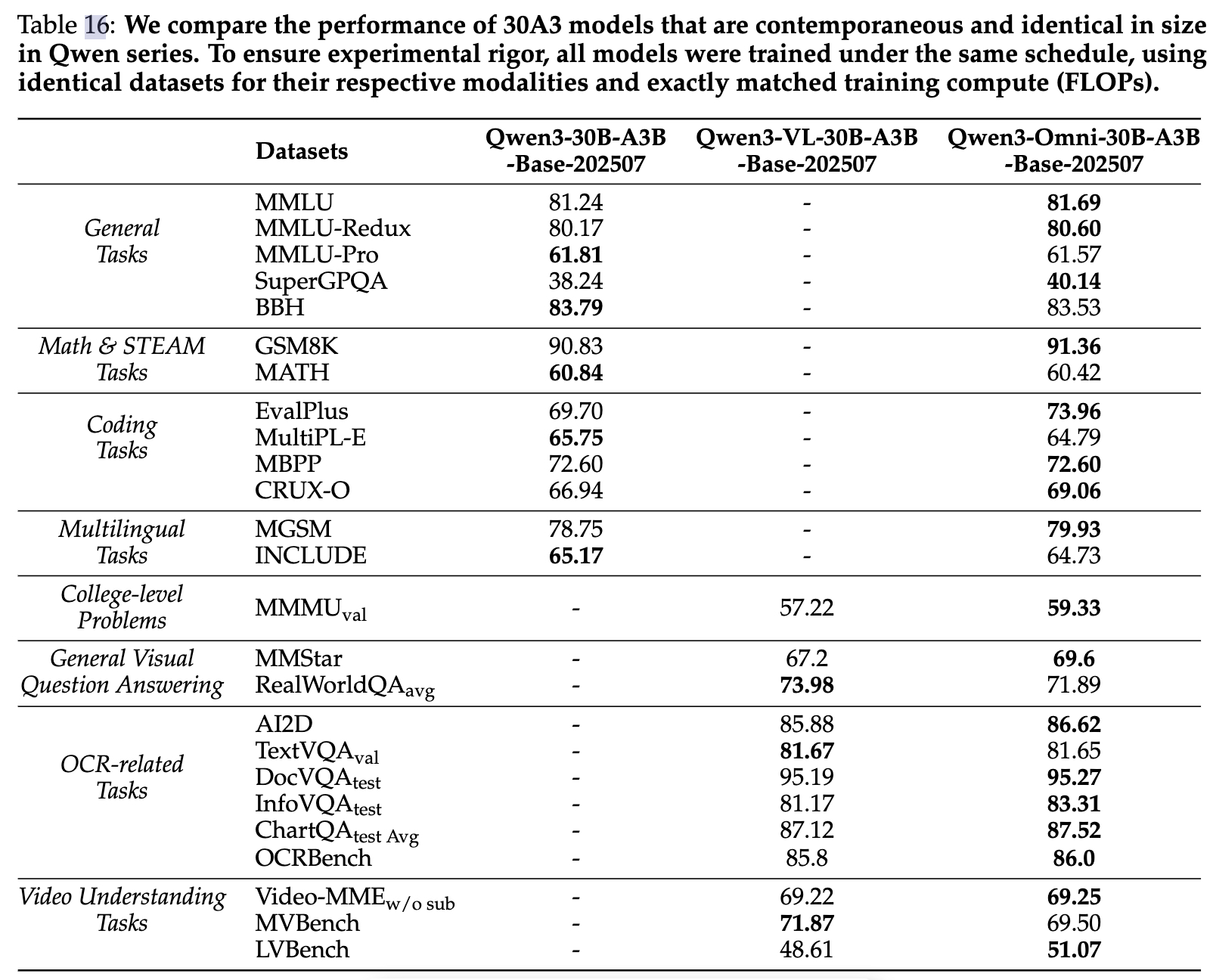
如上表所示,实验结果有力地证明了:
1、在预训练早期就整合多模态数据,可以在不牺牲语言能力的情况下,将语言模型与视觉或音频共同训练。
2、文本模态的加入,显著提升了视觉和音频的性能。
3、音频数据的加入,也能提升模型在MMMU和OCR相关任务上的视觉性能。
这表明,联合多模态训练不仅能实现性能对等,甚至还能在不同模态间产生相互促进的增益效应。
4、相关实践
(1)模型微调训练
ms-swift main分支已支持Qwen/Qwen3-Omni-30B-A3B-Instruct系列,Qwen/Qwen3-VL-235B-A22B-Instruct系列模型的Transformers & Megatron后端的训练。
Qwen3-Omni:
- 最佳实践:https://github.com/modelscope/ms-swift/pull/5900
- 训练脚本:https://github.com/modelscope/ms-swift/blob/main/examples/megatron/multimodal/omni/moe.sh
Qwen3-VL:
- 最佳实践:https://github.com/modelscope/ms-swift/pull/5805
- 训练脚本:https://github.com/modelscope/ms-swift/tree/main/examples/models/qwen3_vl
(2)模型推理
进行模型推理:
import soundfile as sf
from transformers import Qwen3OmniMoeForConditionalGeneration, Qwen3OmniMoeProcessor
from qwen_omni_utils import process_mm_info
MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Instruct"
# MODEL_PATH = "Qwen/Qwen3-Omni-30B-A3B-Thinking"
# MODEL_PATH = "/root/paddlejob/workspace/env_run/model/Qwen_moe/Qwen3-Omni-30B-A3B-Instruct"
model = Qwen3OmniMoeForConditionalGeneration.from_pretrained(
MODEL_PATH,
dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
)
processor = Qwen3OmniMoeProcessor.from_pretrained(MODEL_PATH)
conversation = [
{
"role": "user",
"content": [
{"type": "image", "image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cars.jpg"},
{"type": "audio", "audio": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen3-Omni/demo/cough.wav"},
{"type": "text", "text": "What can you see and hear? Answer in one short sentence."}
],
},
]
# Set whether to use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text,
audio=audios,
images=images,
videos=videos,
return_tensors="pt",
padding=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs,
speaker="Ethan",
thinker_return_dict_in_generate=True,
use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids.sequences[:, inputs["input_ids"].shape[1] :],
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
print(text)
if audio is not None:
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
二、Qwen2.5-Omni系列模型
Qwen2.5-Omni-7B/3B全模态模型:
- 全模态LLM,Qwen2.5-Omni-7B/3B全模态模型:
- 输入可以是文本、图片、语音、视频
- 输出可以是流式的文本/语音
- 提出了一种名为 TMRoPE(时间对齐多模态 RoPE)的新颖位置嵌入,用于同步视频输入和音频的时间戳
- 实时语音和视频聊天:专为完全实时交互而设计的架构,支持分块输入和即时输出
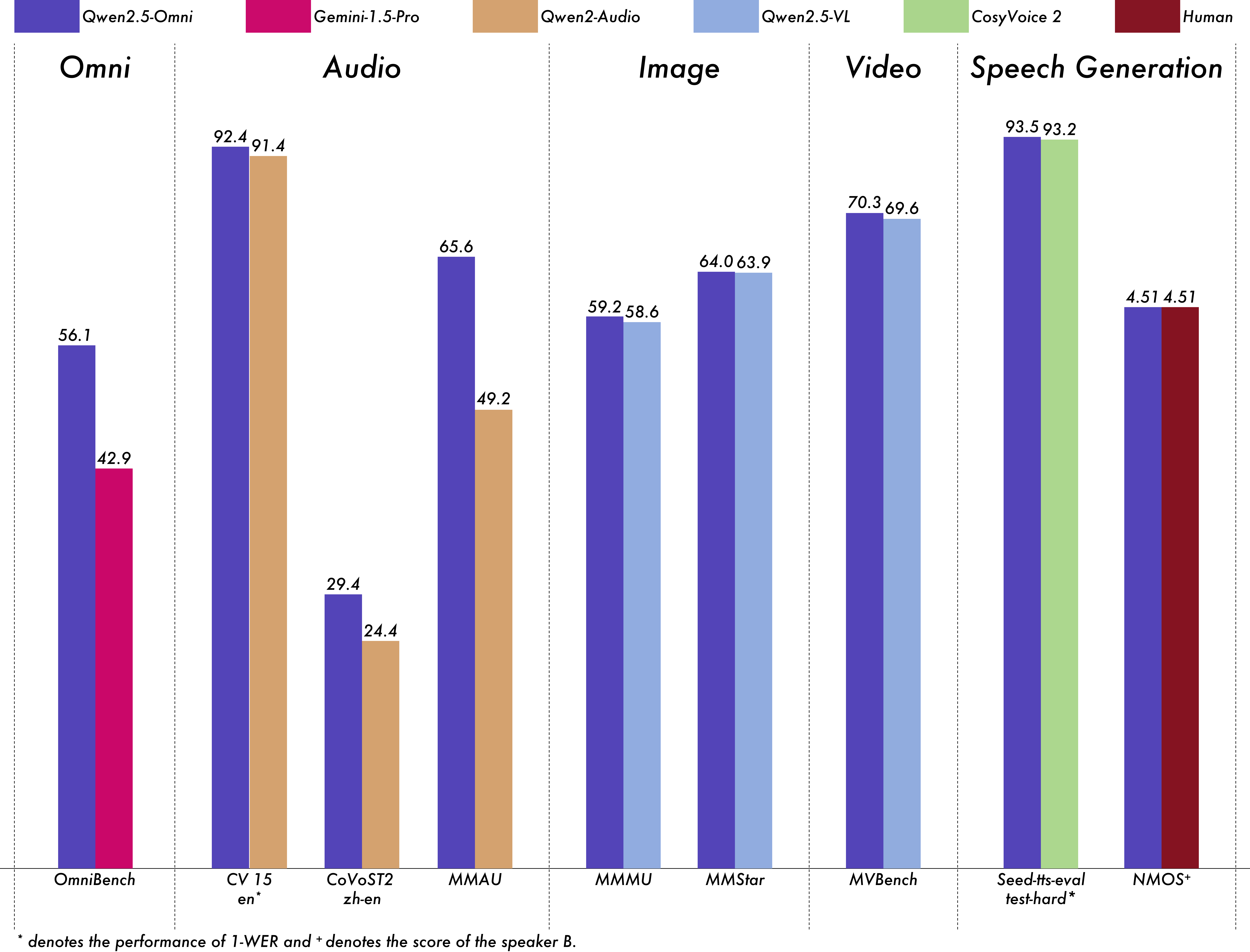
- 和单模态模型作对比,更强:Qwen2.5-Omni 在音频功能方面优于类似大小的 Qwen2-Audio,并达到了与 Qwen2.5-VL-7B 相当的性能
- Qwen 2.5 Omni 的实时交互能力:
- 语音对话:像打电话一样自然流畅
- 视频聊天:支持实时视频交互
- 多模态理解:可以同时处理视频画面和声音
- 即时响应:支持流式输出,反应快速自然
1、Qwen2.5-Omni-7B模型
- 是全模态LLM:输入可以是文本、图片、语音、视频,输出可以是流式的文本/语音
- 提出Thinker-Talker模型架构
- 提出了一种名为 TMRoPE(时间对齐多模态 RoPE)的新颖位置嵌入,用于同步视频输入和音频的时间戳
- 实时语音和视频聊天:专为完全实时交互而设计的架构,支持分块输入和即时输出
- 和单模态模型作对比,更强:Qwen2.5-Omni 在音频功能方面优于类似大小的 Qwen2-Audio,并达到了与 Qwen2.5-VL-7B 相当的性能
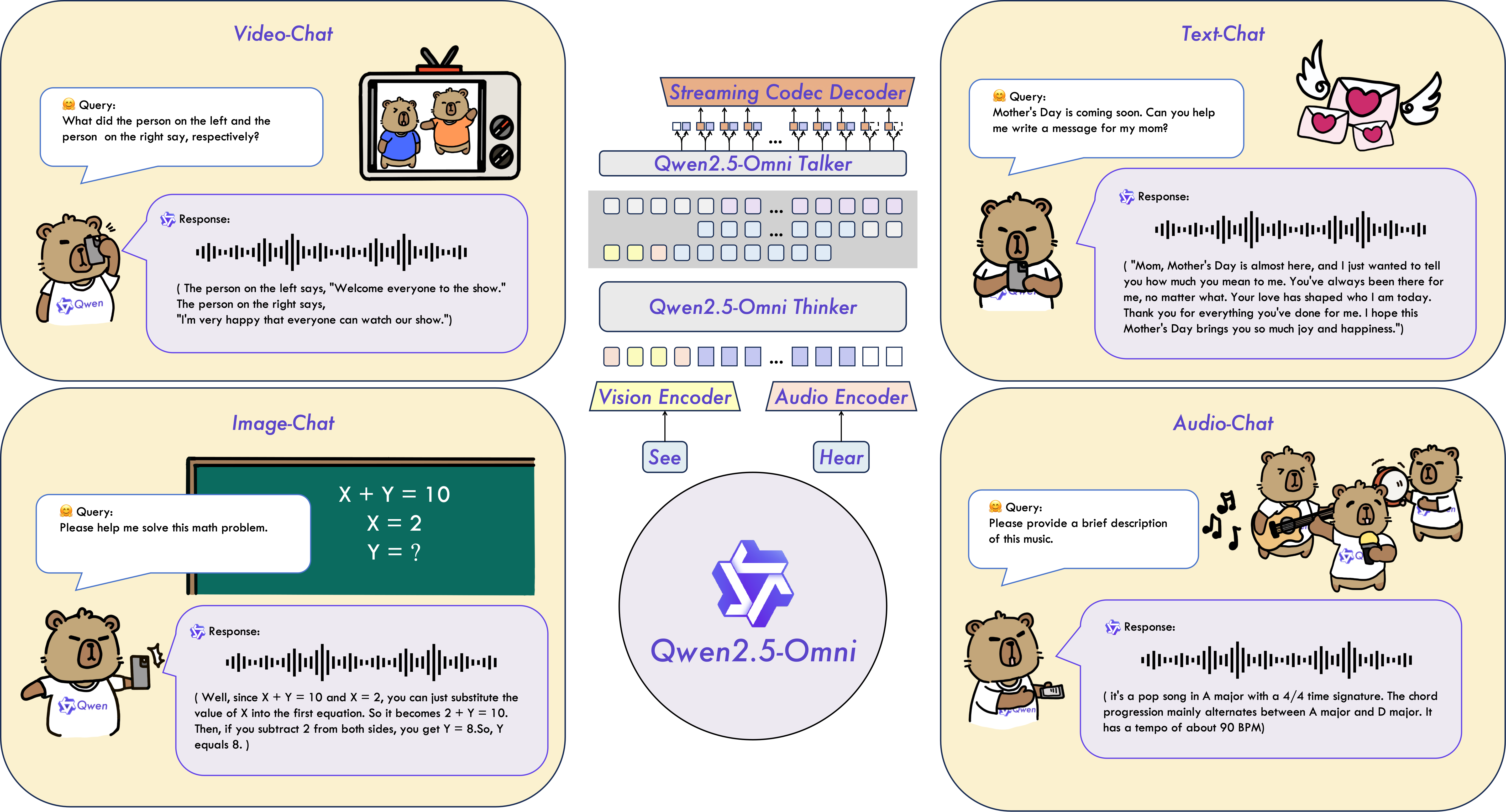
Qwen2.5-Omni-7B是一个端到端的多模态模型,可以接收文本、图像、音频和视频的输入,以文本或语音作为输出,参数模型结构见图2-3。
HF link:
https://huggingface.co/Qwen/Qwen2.5-Omni-7B
Paper:
https://github.com/QwenLM/Qwen2.5-Omni/blob/main/assets/Qwen2.5_Omni.pdf
Qwen2.5-Omni提出了Thinker-Talker架构,同时提出了TMRoPE(时间对齐多模态 RoPE)的新型位置编码,用于同步视频输入的时戳与音频,支持全实时交互,支持分块输入和即时输出。
Qwen2.5-Omni,文本部分初始化采用Qwen2.5模型,Vision编码器初始化采用Qwen2.5-VL部分,Audio编码器初始化使用Whisper-large-v3。
Qwen2.5-Omni效果很强,在音频能力上优于同等规模的Qwen2-Audio,在视觉能力上与Qwen2.5-VL-7B相当。
注意:如果需要音频输出,系统提示词必须为“You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.”
2、Qwen2.5-Omni-3B模型
HF link: https://huggingface.co/Qwen/Qwen2.5-Omni-3B
Paper: https://huggingface.co/papers/2503.20215
3、模型架构
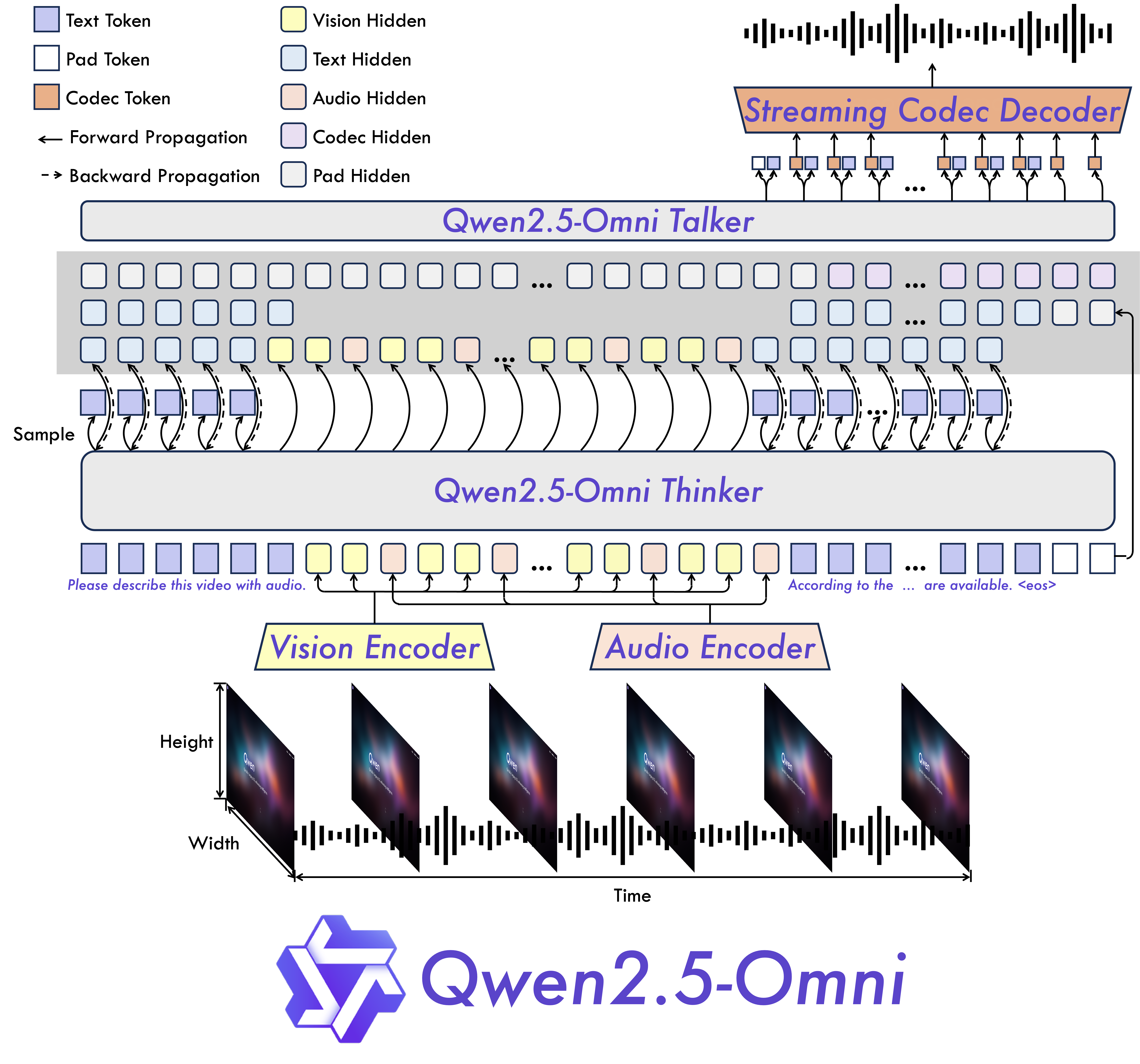
一、架构设计:
- Thinker-Talker架构: Thinker负责处理和理解来自文本、音频和视频模态的输入,生成高层次的表示和相应的文本。Talker则负责接收Thinker的高层次表示,并以流式方式生成语音令牌。
- TMRoPE: 提出了一种新的位置嵌入方法TMRoPE,显式地结合时间信息以同步音频和视频。通过对原始旋转嵌入进行分解,分别处理时间、高度和宽度信息。
- 流式处理: 采用块状流处理方法,支持多模态信息的实时处理。音频和视频编码器分别采用块状注意力和闪存注意力机制,以提高处理效率。
二、生成过程:
- 文本生成: 由Thinker直接生成文本,采用自回归采样方法,基于词汇表上的概率分布生成文本。
- 语音生成: Talker接收Thinker的高层次表示和文本令牌的嵌入,自回归地生成音频令牌。引入滑动窗口块注意力机制,限制当前令牌的上下文访问范围,增强流式输出的质量。
三、训练过程:
- 预训练: 分为三个阶段,第一阶段锁定LLM参数,训练视觉和音频编码器;第二阶段解冻所有参数,进行更广泛的多模态数据训练;第三阶段使用长序列数据进行训练,增强模型对复杂长序列数据的理解能力。
- 后训练: 包括指令跟随数据训练、DPO优化和多说话人指令微调,提升语音生成的稳定性和自然性。
4、模型效果
Reference
[1] https://github.com/QwenLM/Qwen2.5-Omni
[2] 性能无损,全能合一!Qwen3-Omni技术报告深度解读
[3] https://github.com/Dao-AILab/flash-attention
[4] ImportError: /lib/x86_64-linux-gnu/libc.so.6: version GLIBC_2.32‘ not found
[5] https://stackoverflow.com/questions/71940179/error-lib-x86-64-linux-gnu-libc-so-6-version-glibc-2-34-not-found
[6] https://github.com/modular/modular/issues/3684#issuecomment-2480409734
[7] https://github.com/Dao-AILab/flash-attention/releases
[8] https://modelscope.cn/models/Qwen/Qwen3-Omni-30B-A3B-Instruct
[9] Qwen3-Omni-30B-A3B-Captioner:https://github.com/QwenLM/Qwen3-Omni/blob/main/cookbooks/omni_captioner.ipynb
[10] moe训练脚本:https://github.com/modelscope/ms-swift/blob/main/examples/megatron/moe/qwen3_moe.sh
[11] Qwen Team,Qwen3-Omni Technical,Report.https://arxiv.org/pdf/2509.17765
[12] 通义千问,https://modelscope.cn/models/Qwen/Qwen3-Omni-30B-A3B-Instruct
[13] Qwen,https://qwen.ai/blog?id=fdfbaf2907a36b7659a470c77fb135e381302028&from=research.research-list
更多推荐


 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)