
RAG(Retrieve-and-Generate)实现流程详解
RAG(Retrieve-and-Generate)实现流程详解
·
RAG(Retrieve-and-Generate)实现流程详解
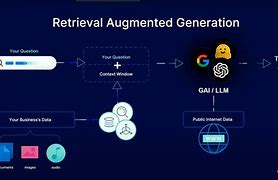
根据提供的上下文信息,以下是 RAG(检索增强生成) 实现流程的详细解析:


1. 整体流程概述
RAG 流程主要分为 6 个步骤,形成一个完整的问答闭环。具体如下:
2. 详细步骤解析
Step 1: 用户提出查询(Query)
- 定义:用户向系统提出一个具体问题或请求。
- 示例:用户输入“去年公司的营收是多少?”。
Step 2: Agent 搜索相关信息
- 定义:Agent 根据用户的查询,在指定数据源(如互联网、数据库、企业内部文档)中搜索相关信息。
- 方法:
- 互联网搜索:使用搜索引擎 API 获取相关网页内容。
- 数据库查询:直接访问结构化数据库,提取相关记录。
- 文档检索:通过向量数据库(如 Milvus、Pinecone)检索相似文档片段。
- 示例:对于上述查询,Agent 可能在公司财务报告文档中搜索相关数据。
Step 3: 检索(Retrieval)信息
- 定义:从搜索结果中提取具体、相关的上下文信息,用于后续生成回答。
- 技术:
- 向量检索:将查询和文档片段转化为向量,计算相似度并筛选高分项。
- 关键词匹配:基于关键词在文档中定位相关段落。
- 示例:找到包含“2022年”和“营收”关键词的具体句子或段落。
Step 4: 相关信息传给大模型
-
定义:将检索到的信息与用户的原始查询组合,作为输入传递给大模型。
-
格式:
Query: 去年公司的营收是多少? Context: 2022年,公司总营收为10亿元人民币。 -
目的:提供丰富背景,帮助模型生成准确答案。
Step 5: 大模型生成(Generate)响应
- 定义:大模型基于输入信息生成最终回答。
- 技术:
- 文本生成模型(如 GPT、Qwen):理解查询和上下文,输出自然语言答案。
- 条件生成:根据输入动态调整生成策略(如摘要、解释、对比等)。
- 示例:生成回答“去年(2022年)公司的营收为10亿元人民币。”
Step 6: 回答用户的请求(Response)
- 定义:将大模型生成的答案返回给用户,完成一次交互。
- 优化:
- 格式化输出:确保答案清晰、易读(如添加标题、列表等)。
- 多轮交互:根据用户反馈调整后续回答(如追问细节、修正错误)。
- 示例:展示回答并允许用户进一步提问(如“能否提供详细财务报表?”)。
3. 循环迭代机制
- 定义:每次用户查询不仅产生回答,还用于改进后续交互。
- 场景:
- 需要更多信息:系统提示用户补充细节(如“请问是哪个部门的营收?”)。
- 用户有额外问题:利用前次回答中的信息丰富新查询(如“那利润呢?”)。
- 优势:
- 动态交互:提供更自然、灵活的对话体验。
- 精准理解:逐步澄清用户意图,提高回答准确性。
4. 使用 LlamaIndex 实现 RAG
-
简易性:LlamaIndex 提供高级 API,简化 RAG 流程构建。
-
5 行代码示例:
from llama_index import SimpleDirectoryReader, GPTListIndex documents = SimpleDirectoryReader('data').load_data() index = GPTListIndex(documents) response = index.query("去年公司的营收是多少?") print(response) -
功能:自动处理文档加载、向量化、检索和生成。
-
-
灵活性:底层 API 支持自定义模块,满足复杂需求。
- 示例:自定义检索策略、集成外部数据源、优化生成逻辑。
5. 总结表格
| 步骤 | 定义 | 关键技术 | 示例 |
|---|---|---|---|
| 1. 用户提出查询 | 用户输入具体问题或请求。 | 自然语言输入 | “去年公司的营收是多少?” |
| 2. Agent 搜索信息 | 根据查询在指定数据源中搜索相关信息。 | 互联网搜索、数据库查询、文档检索 | 搜索公司财务报告文档 |
| 3. 检索信息 | 从搜索结果中提取具体、相关的上下文信息。 | 向量检索、关键词匹配 | 找到包含“2022年”和“营收”的句子 |
| 4. 传给大模型 | 将检索信息和原始查询组合,作为输入传递给大模型。 | 结构化输入格式 | Query + Context |
| 5. 大模型生成响应 | 大模型基于输入信息生成最终回答。 | 文本生成模型(GPT、Qwen) | “去年(2022年)公司营收为10亿元。” |
| 6. 回答用户请求 | 将生成的回答返回给用户,完成一次交互。 | 格式化输出、多轮交互 | 展示回答并允许进一步提问 |
6. 实际应用案例
企业知识库问答
- 场景:员工查询公司政策、项目文档等。
- 流程:
- 员工提问(如“休假申请流程?”)。
- Agent 搜索公司内部文档。
- 检索相关段落(如 HR 手册中的休假章节)。
- 传给大模型(结合问题和文档内容)。
- 生成详细回答(如“请登录OA系统提交申请…”)。
- 返回给员工并支持追问(如“如何登录OA?”)。
客服机器人
- 场景:客户咨询产品信息、售后服务等。
- 流程:
- 客户提问(如“这款手机有哪些功能?”)。
- Agent 搜索产品手册和FAQ。
- 检索相关描述和参数。
- 传给大模型(结合问题和产品信息)。
- 生成专业回答(如“支持5G网络、AI摄影…”)。
- 返回给客户并支持多轮对话(如“价格是多少?”)。
7. 技术选型建议
- 框架:
- LangChain:灵活构建 RAG 流程,支持多模型和工具链。
- LlamaIndex:简化文档处理和检索,适合快速原型开发。
- 模型:
- Qwen:阿里云提供的高性能大模型,支持多种任务。
- GPT:OpenAI 的经典模型,广泛应用于文本生成。
- 向量数据库:
- Milvus:开源高性能向量数据库,支持大规模检索。
- Pinecone:云原生服务,提供租户隔离和自动扩展。
如果需要更具体的代码示例或应用场景分析,请进一步说明!
更多推荐


 15
15 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)