可控图像生成模型综述(简短)
最近一段时间看了好多论文和优秀的帖子,自己做一个简单的总结。1、绪论1.1引言近年来,由深度学习驱动的图像生成模型迅速发展,从生成对抗网络(Generative Adversarial Networks, GAN)和变分自编码器(Variational Autoencoders, VAE)等基础模型,到后来基于Transformer的图像生成模型、扩散模型等,模型生成图像的质量和多样性都有了显著提
最近一段时间看了好多论文和优秀的帖子,非常感谢各位大佬的文章,深入浅出,使我受益匪浅,借着最近完成课程作业的机会,自己也做一个简单的总结。
这里是一些参考文章:
轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型
VQGAN 论文与源码解读:前Diffusion时代的高清图像生成模型
近年来,由深度学习驱动的图像生成模型迅速发展,从生成对抗网络(Generative Adversarial Networks, GAN)和变分自编码器(Variational Autoencoders, VAE)等基础模型,到后来基于Transformer的图像生成模型、扩散模型等,模型生成图像的质量和多样性都有了显著提升。然而,虽然模型能够生成视觉上合理的图像,但在精细控制生成内容方面仍有不足,图像生成模型的可控性需求愈发明显。用户们不仅期望生成高质量的图像,还希望能够灵活地控制生成图像的内容,以满足个性化、多样化的需求。为此,研究人员提出了多种可控图像生成方法,通过输入额外条件信息、生成提示引导等方式,使得生成过程可以根据用户指定的条件进行调整,从而生成符合要求的图像。这种可控性大大扩展了生成模型的应用场景。
深度学习(Deep Learning)是机器学习(Machine Learning)中的一个重要分支,深度学习通过构建多层神经网络,从数据中自动学习复杂的特征,其“深度”的含义就是指网络的层数很多。自从2012年AlexNet[1]在ImageNet大规模视觉识别竞赛中取得了优异的成绩,把深度学习模型在比赛中的正确率提升到一个前所未有的高度后,以卷积神经网络(Convolutional Neural Networks, CNN)为代表的深度学习技术迅速成为人工智能领域的核心技术之一。深度学习的关键优势在于其能够处理大规模数据,并通过多层网络结构自动提取数据中的高层次特征,这使得它在计算机视觉、自然语言处理等领域取得了巨大的成果,同时在语音识别领域取得了更优的结果。图2-1是AlexNet网络架构的示意图。
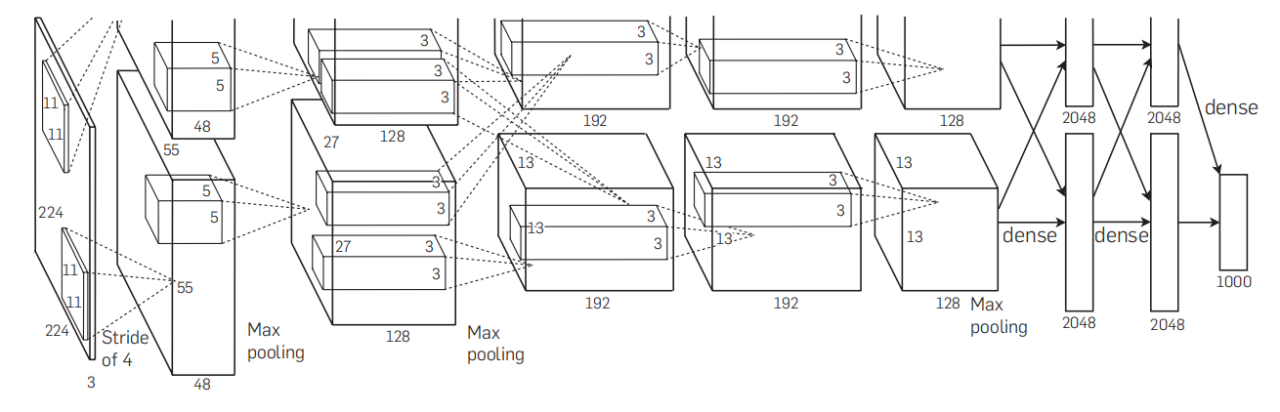
图 2-1 AlexNet网络架构的示意图[1]
Figure 2-1 Diagram of AlexNet Network Architecture[1]
1.2.1 计算机视觉
计算机视觉(Computer Vision, CV)是人工智能(Artificial Intelligence, AI)的其中一个领域,它使用机器学习和神经网络来训练计算机和系统,以便从数字图像、视频和其他视觉输入中获取有意义的信息。机器学习使用算法模型,让计算机能够自行学习视觉数据的上下文;当给模型输入足够多的数据时,由于神经网络的反向传播机制赋予了计算机的自学能力,无需人类实时编程就能使计算机逐渐准确识别图像。
深度学习在计算机视觉中的应用,特别是卷积神经网络CNN,已经成为解决图像分类、目标检测、图像分割等问题的核心技术。卷积神经网络通过模拟生物视觉系统的结构,利用卷积层、池化层和全连接层对图像进行处理,有效地提取图像的空间特征。在深度学习兴起之前,图像处理任务通常依赖于手工设计的特征提取算法。然而,深度学习的引入使得模型能够自动从原始图像中学习到丰富的特征表示,无需人工干预。深度学习技术的发展极大促进了计算机视觉领域的进步。
1.2.2 图像生成
图像生成是利用算法模型构建全新图像数据的一项重要研究方向,不仅包括图像的生成,还涵盖图像修复以及风格转换等相关任务。图像生成技术的历史可以追溯到1950年代,当时的研究者开始研究如何让计算机生成图像,随着计算机图形学和深度学习技术的发展,图像生成技术逐渐成熟,并在许多应用中得到广泛使用,如游戏、电影、设计等。如今的图像生成技术已经可以很方便地根据用户的需求和指示生成期望的图像,甚至可以对视频数据进行内容或风格的修改。
2、可控图像生成模型发展历史
本章节将回顾可控图像生成模型的主要发展历程,从生成对抗网络(GAN)到基于变分自编码器(VAE)和Transformer架构的生成模型,再到近两年来广受关注的扩散模型。本文将重点讨论这些模型的原理和优势。
生成式对抗网络GAN自Ian Goodfellow[2]等人提出后,就受到极大的重视。而随着GAN在理论与算法模型上的高速发展,它在计算机视觉、自然语言处理、人机交互等领域有着越来越深入的应用,并不断向着其它领域继续延伸。
2.2.1 原理概述
GAN的工作原理可以简单描述为一个生成器和判别器博弈的过程,在该过程中,生成器和判别器相互竞争和学习。通过持续的竞争和学习,生成器和判别器逐渐提高其性能,直到达到一个动态平衡状态,其中生成器生成的假数据与真实数据难以区分。图2-2展示了GAN网络的大致工作过程。
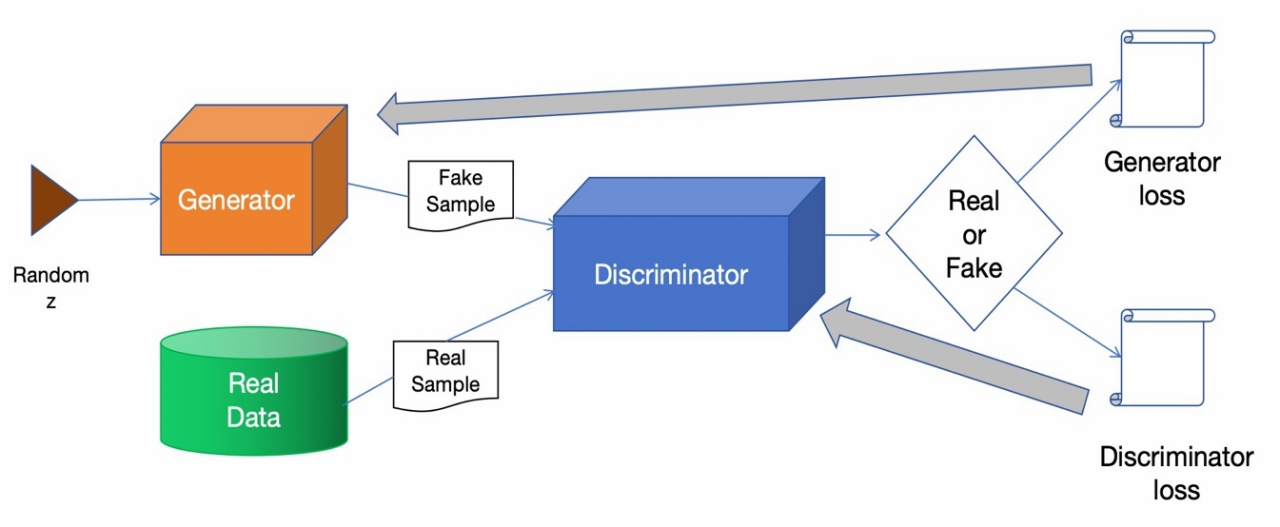
图 2-2 GAN网络架构的工作示意图
Figure 2-2 Working Diagram of GAN Network Architecture
2.2.2 生成对抗网络的发展
在可控图像生成领域,生成对抗网络GAN经历了几个重要的发展阶段,分别是CGAN[3]、CycleGAN[4]和StyleGAN[5]。
2.2.2.1 CGAN
原始的GAN模型没有任何条件限制,生成图像是随机的,因此CGAN的作者考虑加入一些条件信息,比如类别标签或者是其他类型的数据,使得网络生成的图像能够朝规定的方向进行。CGAN的原论文比较短,主要是想法的阐述,其思想也比较简单,就是在原本GAN的基础上增加了一些条件信息输入,在生成网络和判别网络中分别加入一个条件输入,与原始的输入结合在一起作为一个新的输入。CGAN虽然思想很简单,但对于后续延伸出的许多新可控图像生成模型提供了很好的思路。
2.2.2.2 CycleGAN
在图像生成领域中,其中一项任务叫做风格迁移,是指两种不同风格的图像之间进行转换,也称为域迁移。2017年,Zhu et al.[4]提出了CycleGAN网络框架,在原始GAN网络的损失函数中加入循环一致性的约束,使用两套生成器和编码器进行对抗学习,可以很好地完成源图像域和目标图像域中图像的转换任务,同时创新性地克服了训练中缺乏成对数据集的困难。其实在CycleGAN之前,就已经有了域迁移模型,比如Pix2Pix[6],但是Pix2Pix要求训练数据必须是成对的,而现实生活中成对图像的获取是相当困难的,因此CycleGAN的出现对于两种特定风格转换的图像生成任务来说是一次很大的突破,它只需要两种域的数据,而不需要他们有严格对应关系。其整体框架示意图如图2-3所示。
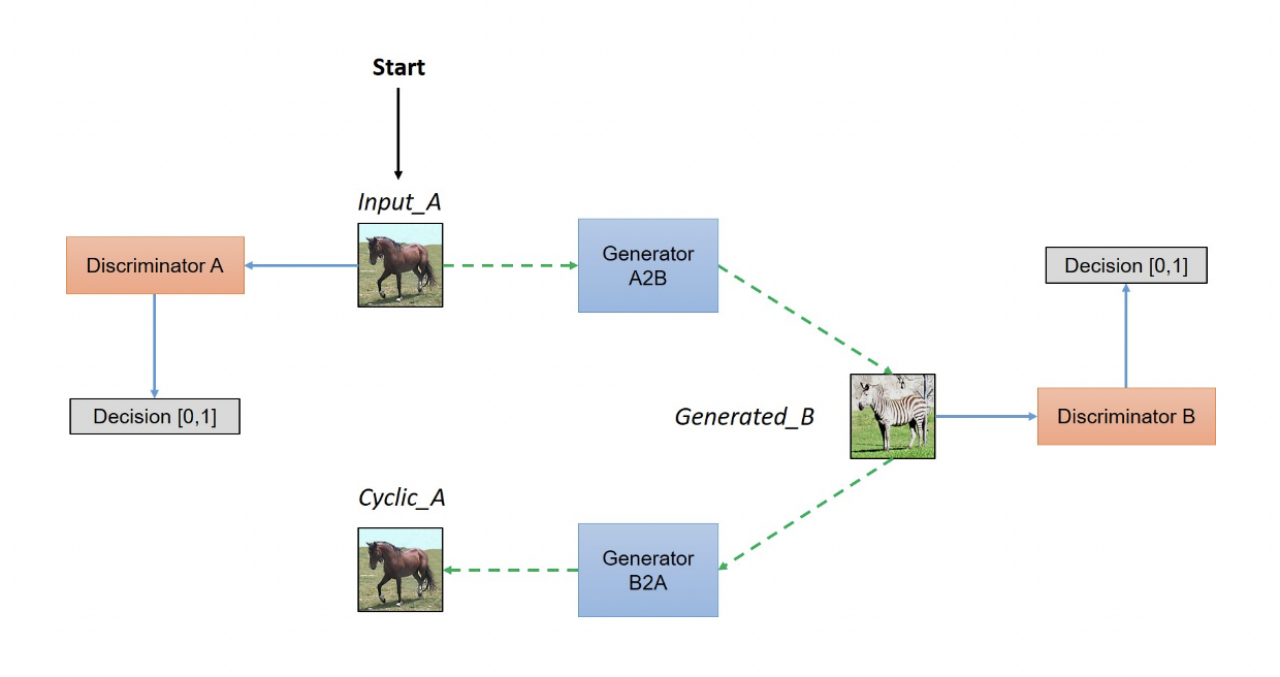
图 2-3 CycleGAN整体框架示意图
Figure 2-3 Framework Diagram of CycleGAN
2.2.2.3 StyleGAN
StyleGAN[5]是继CycleGAN之后再次做出巨大进步的一种可控GAN网络,其是NVIDIA在原有ProGAN[7]的基础上改进而来,StyleGAN比起CycleGAN能够更灵活地调整生成图像的内容和风格。StyleGAN主要通过分别修改每一层级的输入,在不影响其他层级的情况下,来控制该层级所表示的视觉特征,从而生成多样的结果。从结构上来说,StyleGAN的网络结构包含两个部分,即Mapping network和Synthesis network。其中Mapping network实现了对潜在空间的解耦,潜在空间与生成图片的属性之间有更好的线性关系,这有利于对生成图片的属性控制。而Synthesis network的作用是生成图像,其创新之处每一层子网络都可以获取中间潜在空间变量的信息,这样做可以使生成的图像具备更好的风格特征;而且Synthesis network中还输入了转换后的随机噪声,进一步丰富了生成图像的细节。其结构如图2-4所示。
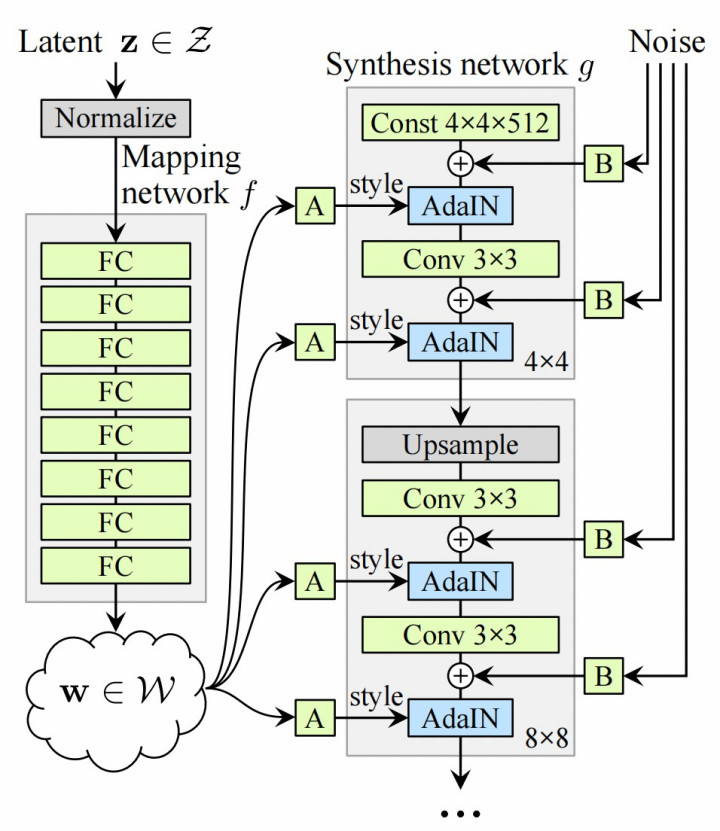
图 2-4 StyleGAN的结构[5]
Figure 2-4 Network Structure of StyleGAN[5]
变分自编码器(Variational Autoencoder,VAE)[8]也是生成模型中广泛应用的一种深度学习方法。与1986年Rumelhart[9]提出的传统自动编码器(Autoencoder,AE)的概念不同,VAE通过引入变分推断的技术,使得网络构建的潜在空间表示能够更好地捕捉数据的统计特性,从而生成更为多样且逼真的图像数据,在数据生成方面表现出了巨大的应用价值。VAE一经提出就迅速获得了深度生成模型领域广泛的关注,并和生成对抗网络GAN被视为无监督式学习领域最具研究价值的方法之一,在深度生成模型领域得到越来越多的应用。
2.3.1 原理概述
VAE的核心思想是通过将输入数据映射到潜在空间,并对其进行概率建模,生成与输入数据分布相似的新样本。原始的自编码器(autoencoder,AE)是一类能够把图片压缩成较短的向量的神经网络模型,其包含一个编码器和一个解码器。在训练时,输入图像会被编码成一个较短的向量,再被解码回另一幅与输入相似的图像。网络的学习目标是让重建出来的图像和原图像尽可能相似。而VAE在AE的基础上通过最大化变分下界(Variational Lower Bound)来优化模型,从而学习数据的潜在分布。具体而言,VAE由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器将输入数据压缩成一个潜在空间的分布,而解码器则从潜在空间采样点出发重建出输入数据的近似值。通过优化变分下界,VAE不仅能够重构输入数据,还能够生成全新的样本;此外,VAE的优势还在于其生成过程的稳定性,能够避免如GAN中常见的训练不稳定和模式崩溃问题。
2.3.2 基于变分自编码的图像生成网络发展
在可控图像生成领域,基于变分自编码的网络经历了几个重要的发展阶段,分别是CVAE[10]和VQVAE[11]。
2.3.2.1 CVAE
条件变分自编码器(Conditional Variational Autoencoder,CVAE)[10]结合了变分自编码器VAE和条件控制生成的概念,CVAE的基本结构也是包括编码器和解码器两部分,编码器将输入数据压缩成低维的隐变量,而解码器则根据这些隐变量和条件输入来重构或生成数据。与原本的VAE不同,CVAE在生成数据时,不仅依赖于潜在空间中的采样点,其在解码过程中考虑了额外的条件信息输入,比如图像类别标签等信息。除此之外,CVAE在损失函数的设计中也加入了条件损失,从而能够生成更符合特定条件的图像。
2.3.2.2 VQVAE
在AE基础上改进的VAE可以生成更加多样的图像,但VAE输出的图像质量不是很理想。VQVAE[11]的作者认为,VAE生成的图像质量不高的原因在于在编码器阶段,输入图像被编码为连续向量。VQVAE从这点切入,将输入图像编码为离散向量,能够更好地表示图像的特征;同时为了方便解码器输出结果,VQVAE又新设计了一个嵌入空间(Embedding Space),将表示原输入图像的连续向量与嵌入空间中使用离散值表示的连续向量建立联系。具体是通过先计算输入向量与嵌入空间中每个向量的距离,选择与各输入向量距离最近的向量,记录其离散值下标,在嵌入空间中取出该下标指示的向量作为解码器的输入。这种机制也被称为“codebook”,VQVAE利用codebook机制把图像编码成离散向量,为图像生成类任务提供了一种新的思路。VQVAE的这种建模方法启发了无数的后续工作,包括后来著名的Stable Diffusion[20]。图2-5是VQVAE网络的框架示意图。
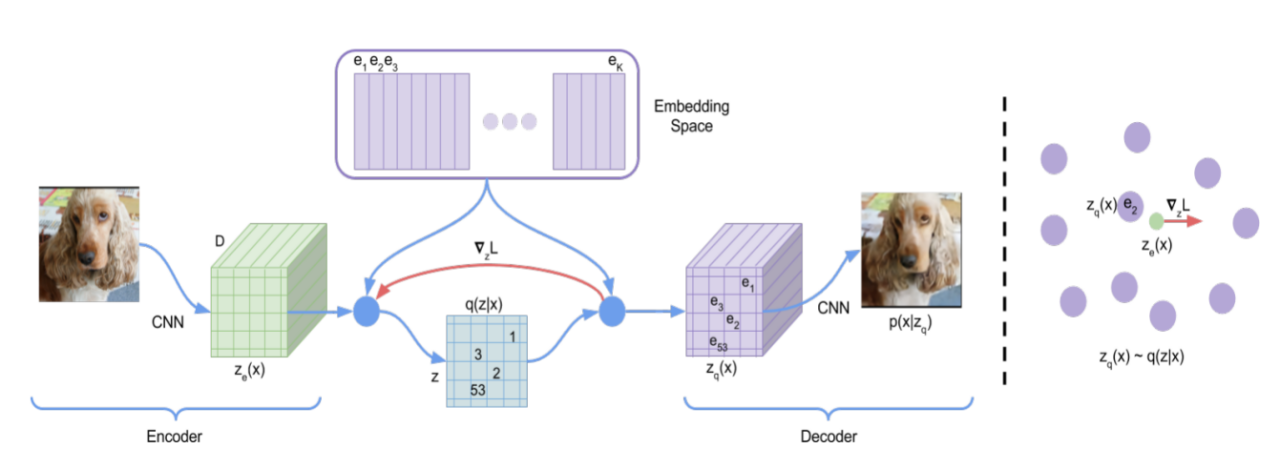
图 2-5 VQVAE框架示意图[11]
Figure 2-5 Framework Diagram of VQVAE[11]
Transformer是一种用于自然语言处理(Natural Language Processing,NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构,它在2017年由Vaswani等人[12]首次提出。Transformer架构引入了自注意力机制(self-attention mechanism),这是一个关键的创新,使其在处理序列数据时表现出色。近年来,Transformer架构在自然语言处理领域的成功促使研究者将其应用于图像生成任务。与卷积神经网络CNN不同,Transformer通过自注意力机制(Self-Attention)捕获数据之间的全局依赖关系,从而在长序列建模中展现了出色的表现。这种特性使得Transformer在图像生成中具有巨大的潜力,尤其在需要处理复杂依赖关系和实现多样化生成的任务中表现突出。
2.4.1 原理概述
在图像生成任务中,基于Transformer的模型通常将图像分割为一系列小块(如图像块或像素),并将每个小块视作一个序列元素。通过自注意力机制,模型可以在生成过程中根据已有的图像信息逐步生成新图像,使得生成结果更加符合全局一致性。
2.4.2 基于Transformer的图像生成网络发展
在可控图像生成领域,基于Transformer的网络经历了几个重要的发展阶段,分别是Vision Transformer(ViT)[13]和VQGAN[14]。
2.4.2.1 Vision Transformer(ViT)
ViT是谷歌发表在ICLR2021的一篇很经典的工作,也是在那一年最有影响力的工作。它挑战了卷积神经网络在计算机视觉领域里的绝对统治地位,其结论就是Transformer不仅在自然语言处理领域使用,只要在足够多的数据上进行预训练,那么在计算机视觉领域的效果也非常好。可以说ViT打破了计算机视觉和自然语言处理在模型上的壁垒,后续基于它的工作更是层出不穷。图2-6展示了ViT的网络结构。
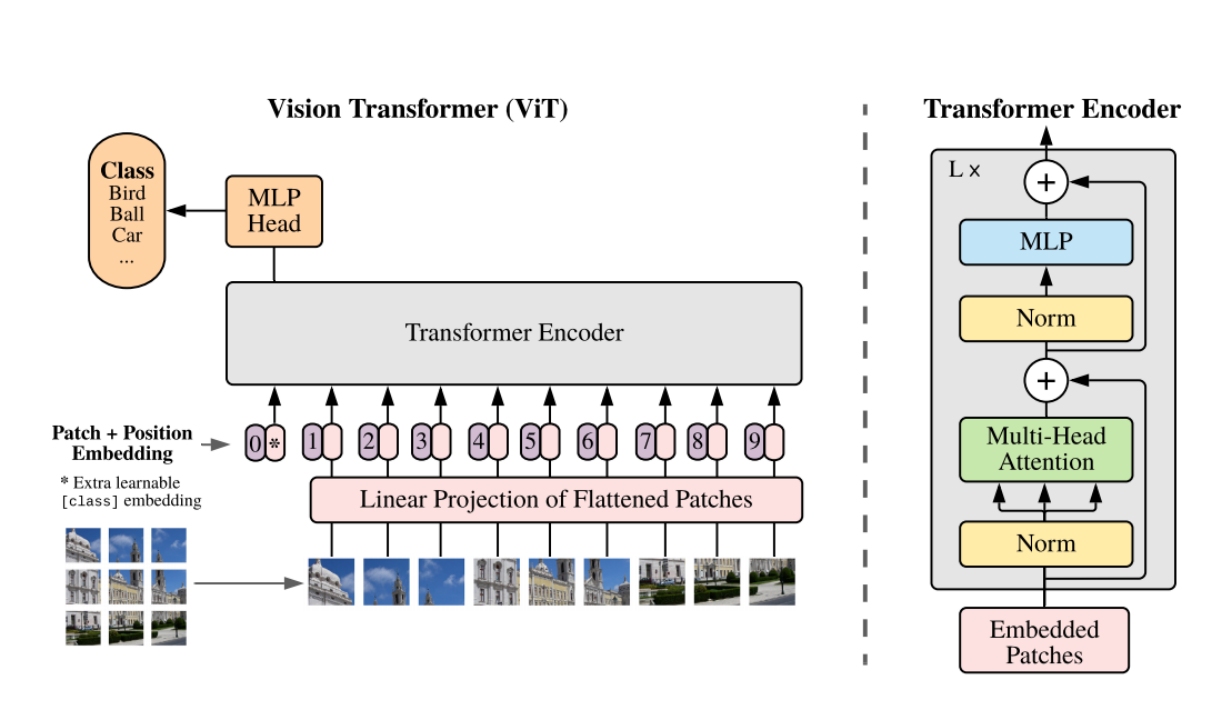
图 2-6 Vision Transformer的结构[13]
Figure 2-6 Network Structure of Vision Transformer[13]
观察ViT网络的结构图,可以发现ViT模型先把输入图像分解成许多patch,之后变成一个序列,每个patch会通过一个线性投射层,得到一个特征(patch embedding)。由于原始自注意力机制是两两交互的,本身不考虑顺序问题,但是图像是一个整体,由图像分成的patch是有固定顺序的,需要给每个patch embedding加上表示位置的position embedding,之后这个整体的token就既包含了图片块原本的图像信息,又包含了图像块所在的位置信息。按照这种方式得到的许多token后续直接输入进Transformer Encoder,得到很多输出。在处理这些输出时,ViT借鉴了BERT[15],在BERT中使用了extra learnable embedding特殊字符CLS分类字符,同样的,ViT中的cls用*代替,也是包含位置信息的,且永远是0。由于所有的token都会两两交互,所以作者相信这个cls embedding能从其它embedding中学到有用的信息,从而只需要根据它的输出做判断。将得到的输出经过通用的分类器MLP Head即可得到最后的结果。
2022年中旬,以扩散模型为核心的图像生成模型将AI绘画带入了大众的视野。实际上,在更早的一年之前,就有了一个能根据文字生成高清图片的模型—VQGAN[14]。VQGAN不仅本身具有强大的图像生成能力,更是继承了前作VQVAE把图像压缩成离散编码的思想,而且推广了「先压缩,再生成」的两阶段图像生成思路,启发了无数后续工作。图2-7是VQGAN网络的架构示意图。
相对于普通的图像生成模型,VQGAN的突出点在于其使用codebook来离散编码模型中间特征,并且使用Transformer作为编码生成工具。codebook的思想在VQVAE中已经提出,而VQGAN的整体架构大致是将VQVAE的编码生成器从pixelCNN[16]换成了Transformer,并且在训练过程中使用PatchGAN[6]的判别器加入对抗损失。相比纯种的GAN(如StyleGAN),VQGAN的强大之处在于它支持带约束的高清图像生成。VQGAN借助NLP中"decoder-only"策略实现了带约束图像生成,并使用滑动窗口机制实现了高清图像生成。虽然在某些特定任务上VQGAN还是落后于其他GAN,但VQGAN的泛化性和灵活性都要比纯种GAN要强。它的这些潜力直接促成了Stable Diffusion[19]的诞生。
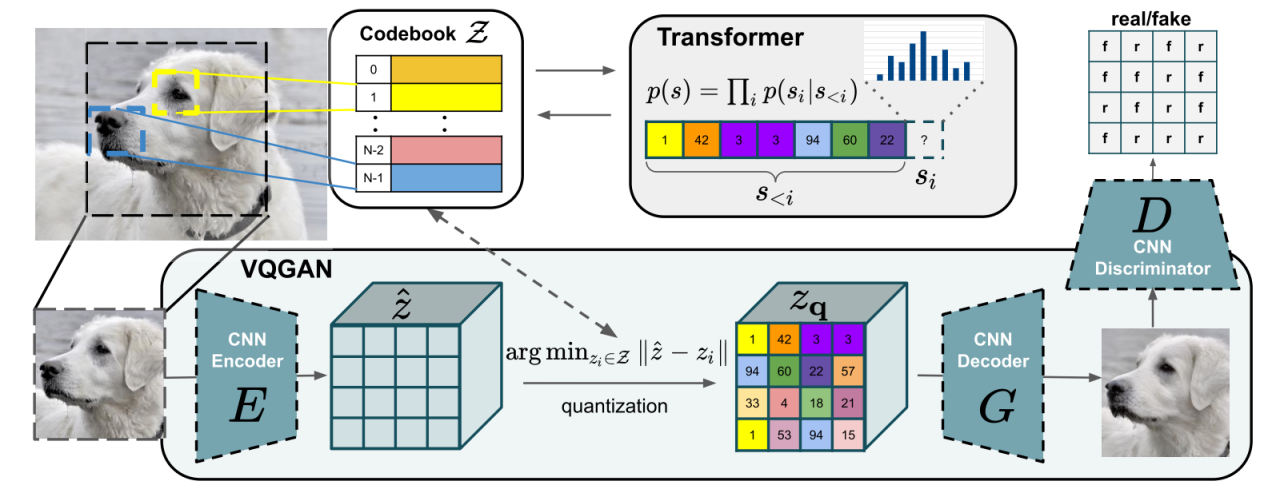
图 2-7 VQGAN的网络结构[14]
Figure 2-7 Network Structure of VQGAN[14]
近两年来,扩散模型(Diffusion Model)在生成模型领域崭露头角,成为继生成对抗网络(GAN)和变分自编码器(VAE)之后的重要图像生成技术。扩散模型以其生成图像的高质量、稳定性和多样性引起了研究者的广泛关注。特别是在复杂场景生成和高分辨率生成任务中,扩散模型展现了极大的潜力。
2.5.1 原理概述
去噪扩散概率模型(Denoising Diffusion Probabilistic Model,DDPM)[17]是当今扩散模型的开山鼻祖,DDPM主要基于马尔可夫链的思想,包含两个核心过程:正向扩散过程和反向生成过程。在正向扩散过程中,逐步向输入图像添加高斯噪声,最终退化为标准正态分布的随机噪声;在反向过程中,模型通过学习添加噪声的逆过程,从随机噪声逐步还原生成逼真的图像。反向生成过程依赖于神经网络来估计每一步的噪声分布,通过最大化似然函数或最小化噪声预测误差的训练后,扩散模型能够逐步去噪并生成高质量的图像。图2-8是DDPM模型的描绘图。

图 2-8 DDPM模型描绘图[17]
Figure 2-8 Graphical Model of DDPM[17]
2.5.2 基于扩散模型的图像生成网络发展
在DDPM问世后,许多性能优异的变种模型如雨后春笋般出现,其中具有代表性的扩散模型有DDIM[18]、Stable Diffusion[19]和ControlNet[20]。
2.5.2.1 DDIM
在DDPM中,生成过程被定义为马尔可夫扩散过程的反向过程,模型在逆向采样过程的每一步中预测噪声。而DDIM的作者发现,扩散过程并不是必须遵循马尔科夫链。基于此,DDIM的作者重新定义了扩散过程的逆过程,并提出了一种新的采样技巧,可以大幅减少采样的步骤,虽然代价是牺牲了一定的多样性,图像质量略微下降,但依然在可接受的范围内,极大提高了图像生成的效率。图2-9是DDIM模型的描绘图。与图2-8展示的DDPM模型描绘图对比,可以发现DDPM是遵循马尔科夫过程,而DDIM却不是。
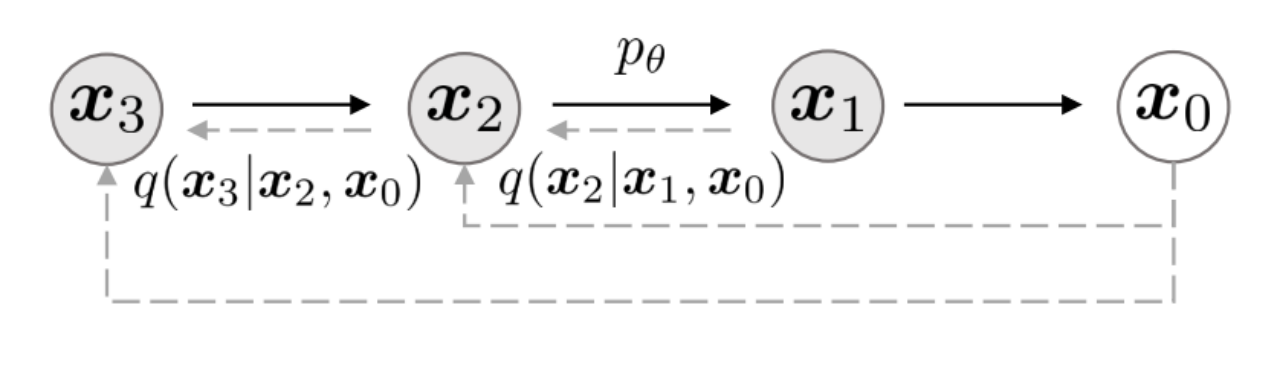
图 2-9 DDIM模型描绘图[18]
Figure 2-9 Graphical Model of DDIM[18]
2.5.2.2 Stable Diffusion
在2022年的AI绘画浪潮中,Stable Diffusion无疑是最受欢迎的图像生成模型。Stable Diffusion由两类AE的变种发展而来,一类是有强大生成能力却需要耗费大量运算资源的DDPM,一类是能够以较高保真度压缩图像的VQVAE。Stable Diffusion是一个两阶段的图像生成模型,它先用一个使用KL正则化或VQ正则化的VQGAN来实现图像压缩,再用DDPM等扩散模型生成压缩图像。可以把额外的约束(如文字)输入进DDPM等扩散模型以实现带约束图像生成。图2-10展示了Stable Diffusion网络的架构图。
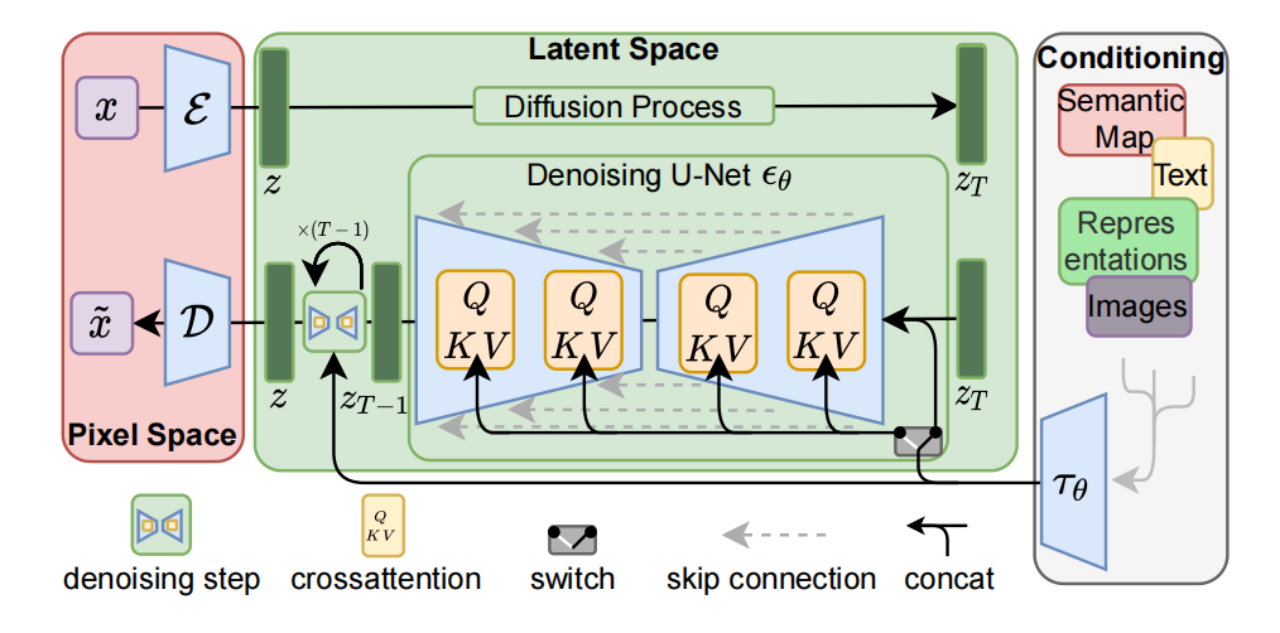
图 2-10 Stable Diffusion的结构[19]
Figure 2-10 Network structure of Vision Stable Diffusion[19]
2.5.2.3 ControlNet
随着Stable Diffusion等大型文本到图像生成模型的出现,只需要用户输入一个简短的描述性提示就可以生成质量相当好的图像。但在输入一些文本并获得图像后,我们可能会自然地提出问题:这种基于提示的控制是否满足我们的需求?例如,在图像处理中,我们可能着重于某些具体的任务,比如低光照图像增强任务,这些大型模型能否应用于促进这些特定任务?ControlNet的出现更好地解决了以上问题。图2-10展示了ControlNet的网络架构图。
ControlNet中使用的主体架构依然是Stable Diffusion的U-Net[21],ControlNet主要将Stable Diffusion U-Net的编码器Encoder部分和中间层Middle部分进行复制训练,在Stable Diffusion U-Net的解码器Decoder模块中通过跳跃连接skip connection加入了零卷积模块zero convolution模块处理后的特征,以实现对最终模型与训练数据的一致性。且由于零卷积不会向深层特征添加新的噪声,因此与从头开始训练新层相比,训练速度与微调扩散模型一样快。
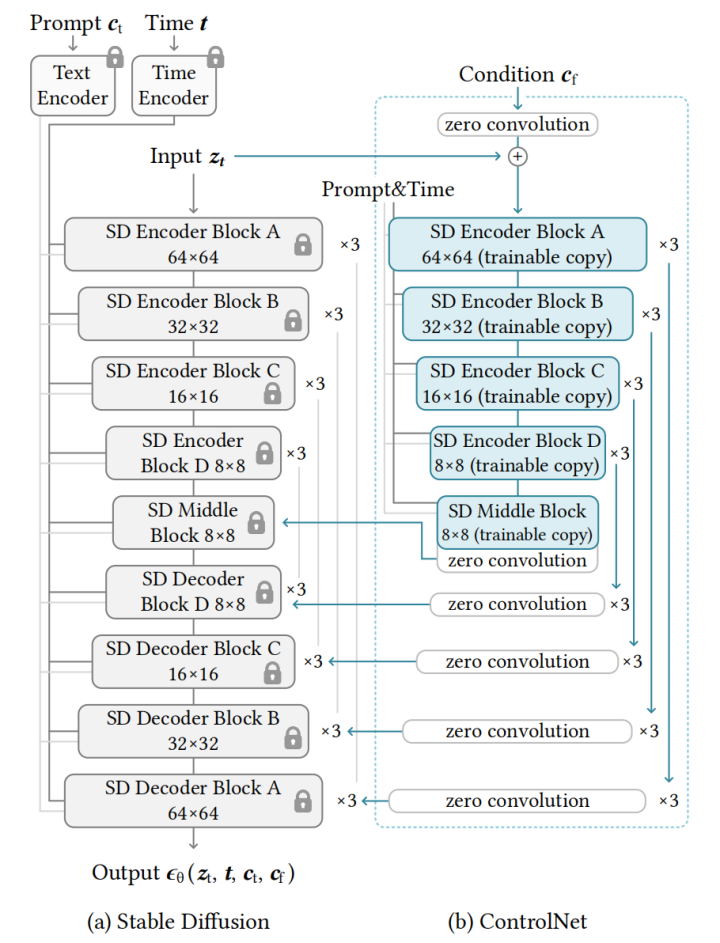
图 2-11 ControlNet的结构[20]
Figure 2-11 Network Structure of ControlNet[20]
3、总结和展望
可控图像生成模型作为生成模型领域的重要分支,近年来取得了显著进展。从最早的生成对抗网络(GAN)到变分自编码器(VAE),再到基于Transformer和扩散模型的最新方法,这些模型在生成质量、稳定性和可控性方面不断提升。具体而言,GAN通过对抗机制生成高质量图像,但训练不稳定性和模式崩溃问题限制了其应用范围;VAE则以稳定训练和潜在空间建模为特点,但生成图像的精细程度稍显不足。基于Transformer的模型通过自注意力机制捕获全局上下文信息,展现了优越的生成能力和条件控制灵活性。而扩散模型以其逐步去噪生成方法,兼顾高质量和稳定性,成为近期的研究热点。
可控性是图像生成模型的关键特性之一,通过引入条件变量(如文本、标签或图像提示),模型能够生成符合预期的特定图像,极大地拓展了生成模型的应用场景。从人脸生成、艺术创作到医学影像分析,可控图像生成模型的实际应用不断扩展,显示了其巨大的潜力。
尽管当前的可控图像生成模型取得了显著进展,但仍然存在许多挑战和改进方向,如生成效率的提升和多模态条件控制的改进。
当前部分模型(如扩散模型)在高分辨率图像生成任务中计算效率较低,未来研究可以集中于开发更高效的生成方法,例如通过引入更快的采样技术或混合模型架构(如结合扩散模型和GAN)来加速生成过程。另一方面,随着多模态学习的深入发展,未来的图像生成模型需要更好地融合文本、图像、语音等多模态信息,实现跨模态的高效生成与控制。这将极大地推动“文本到图像”等任务的发展,并在人机交互、虚拟现实等领域发挥重要作用。
展望未来,可控图像生成模型将继续发挥其独特优势,推动图像生成技术的发展。在技术不断迭代和算力持续提升的背景下,我们有理由相信,可控图像生成模型将进一步突破当前的技术瓶颈,为科学研究、艺术创作和工业应用带来更广阔的可能性。
- Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25.
- Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[J]. Advances in neural information processing systems, 2014, 27.
- Mirza M. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
- Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
- Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 4401-4410.
- Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
- Karras T. Progressive Growing of GANs for Improved Quality, Stability, and Variation[J]. arXiv preprint arXiv:1710.10196, 2017.
- Kingma D P. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013.
- Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. nature, 1986, 323(6088): 533-536.
- Sohn K, Lee H, Yan X. Learning structured output representation using deep conditional generative models[J]. Advances in neural information processing systems, 2015, 28.
- Van Den Oord A, Vinyals O. Neural discrete representation learning[J]. Advances in neural information processing systems, 2017, 30.
- Vaswani A. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017.
- Dosovitskiy A. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
- Esser P, Rombach R, Ommer B. Taming transformers for high-resolution image synthesis[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 12873-12883.
- Devlin J. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
- Van den Oord A, Kalchbrenner N, Espeholt L, et al. Conditional image generation with pixelcnn decoders[J]. Advances in neural information processing systems, 2016, 29.
- Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models[J]. Advances in neural information processing systems, 2020, 33: 6840-6851.
- Song J, Meng C, Ermon S. Denoising diffusion implicit models[J]. arXiv preprint arXiv:2010.02502, 2020.
- Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 10684-10695.
- Zhang L, Rao A, Agrawala M. Adding conditional control to text-to-image diffusion models[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 3836-3847.
- Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer International Publishing, 2015: 234-241.

助力合肥开发者学习交流的技术社区,不定期举办线上线下活动,欢迎大家的加入
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)