
【论文阅读】联邦学习开山之作《Communication-Efficient Learning of Deep Networks from Decentralized Data》
相比于FedSGD,FedAvg能够在非独立同分布数据上更快收敛,在相同通信轮次下,测试集精度更高。在IID(独立同分布)和non-IID(非独立同分布)两种数据分布下进行实验,评估模型在不同数据分布条件下的收敛性和通信效率。文章提出的方法(FedAvg)经过了四个数据集,五个模型的实验,对于不平衡和non-IID的数据集表现良好,具有鲁棒性。探索异步联邦学习方法,减少同步通信的延迟问题,尤其在网
一、研究背景
背景:
- 数据产生和隐私问题:随着移动设备的普及,模型的训练通常需要
海量数据,这些数据通常是隐私敏感信息,如医疗数据、图像照片等。将这些数据集中上传到云端服务器,存在极高的隐私泄露风险。 - 通信成本问题:在集中式深度学习模式下,设备需要
频繁上传大量数据进行训练,这使得通信成本称为一个关键瓶颈。
现有挑战:
- 隐私保护:传统的集中式学习要求将数据集中化存储,这增加了隐私风险,尤其是对于敏感数据而言,
用户通常不愿意共享数据。 - 高通信成本:随着设备数量的增长,通信的频繁性导致的
通信成本变得不可忽视,设备上传数据的频次直接影响网络负载。
重要性:
- 联邦学习(Federated Learning, FL)提出了一种有效的解决方案: 将
数据保留在本地设备上进行模型训练,而不是传输数据。只需将模型更新发送到中央服务器进行聚合,从而减少了隐私泄露的风险,这显著降低了通信开销。 - FedAvg作为论文提出的联邦学习优化算法,能够在保证模型性能的前提下,极大地减少通信成本,并且应对异质性(non-IID)数据的挑战。
研究动机:
- 从SGD到FedSGD:
在深度学习中,随机梯度下降(SGD)是一种经典的优化算法,现在很多深度学习的成功,都是在优化了SGD以及 变体上进行的,所以自然想到从SGD开始构建联邦学习方法。
采用传统的SGD,通过将所有数据集中在一个服务器上进行模型训练,依然存在隐私泄漏风险和通信成本过高。
因此,联邦学习提出了FedSGD方法,允许客户端设备在本地运行SGD来更新数据,而不需要传输到服务器。客户端只需要将其本地计算出的梯度上传给服务器,服务器将这些梯度进行聚合,更新全局模型。 - FedSGD的局限性:
通信成本高,每一轮训练都要求所有客户端上传其本地梯度。
处理非独立同分布(non-IID)数据时,性能下降,数据分布导致FedSGD的模型收敛速度变慢。 - 从FedSGD到FedAvg的优化:
核心思想:客户端设备可以在本地进行多轮训练,然后再将更新后的模型参数而不是梯度发送给服务器。这使得在处理non-IID数据时表现出更好的鲁棒性,因为客户端在本地多轮训练后,模型能够更好地适应本地数据的分布。 - 核心动机:
FedAvg的提出动机在于通过减少通信频次和增强非独立同分布数据的适应性,来优化联邦学习的通信效率和模型性能。

二、解决方法
FedAvg算法核心思想:
流程:
- 初始化:服务器发送初始模型参数w0给客户端;
- 本地训练:每个客户端在本地数据集上进行E轮小批量梯度下降,更新模型wk;
- 上传更新:每个客户端将其更新后的参数发送给服务器;
- 全局聚合:服务器对所有客户端更新的模型参数进行加权平均,更新全局模型wt+1;
- 迭代:重复上述步骤,直至模型收敛。
公式:

- 服务器端聚合公式:
w t + 1 = ∑ k = 1 K n k n w k w_{t+1} = \sum_{k = 1}^{K} \frac{n_{k}}{n}w_{k} wt+1=k=1∑Knnkwk
其中nk表示第k个客户端的数据量,wk是客户端的本地模型参数。
三、实验分析
文章提出的方法(FedAvg)经过了四个数据集,五个模型的实验,对于不平衡和non-IID的数据集表现良好,具有鲁棒性。
实验数据集:
- MNIST:手写数字识别任务,数据相对简单且均衡
- CIFAR-10:图像分类任务,包含10个类,数据较为复杂且分布不均衡
- Shakespeare:语言建模任务,模拟真实世界中的non-IID数据,数据集基于角色的对话分布,反映了联邦学习在文本任务中的表现
- Next Word Prediction LSTM:来自这叫网络的大规模词预测任务,模拟用户设备端的non-IID文本数据分布,具有高度异质性,是对模型在复杂场景下性能的进一步验证。
实验设置:
- 多层感知机(MLP):用于MNIST数据集,测试模型在简单任务中的基础表现。
- 卷积神经网络(CNN):用于MNIST和CIFAR-10,适用于图像分类任务,测试模型在中等复杂任务中的表现。
- 两层字符级LSTM:用于Shakespeare数据集,适用于字符级语言建模任务,模拟不同客户端间异质数据的影响。
- 词级LSTM:用于大规模词预测任务,测试模型在复杂文本任务中的表现。
实验场景:
在IID(独立同分布)和non-IID(非独立同分布)两种数据分布下进行实验,评估模型在不同数据分布条件下的收敛性和通信效率。

|
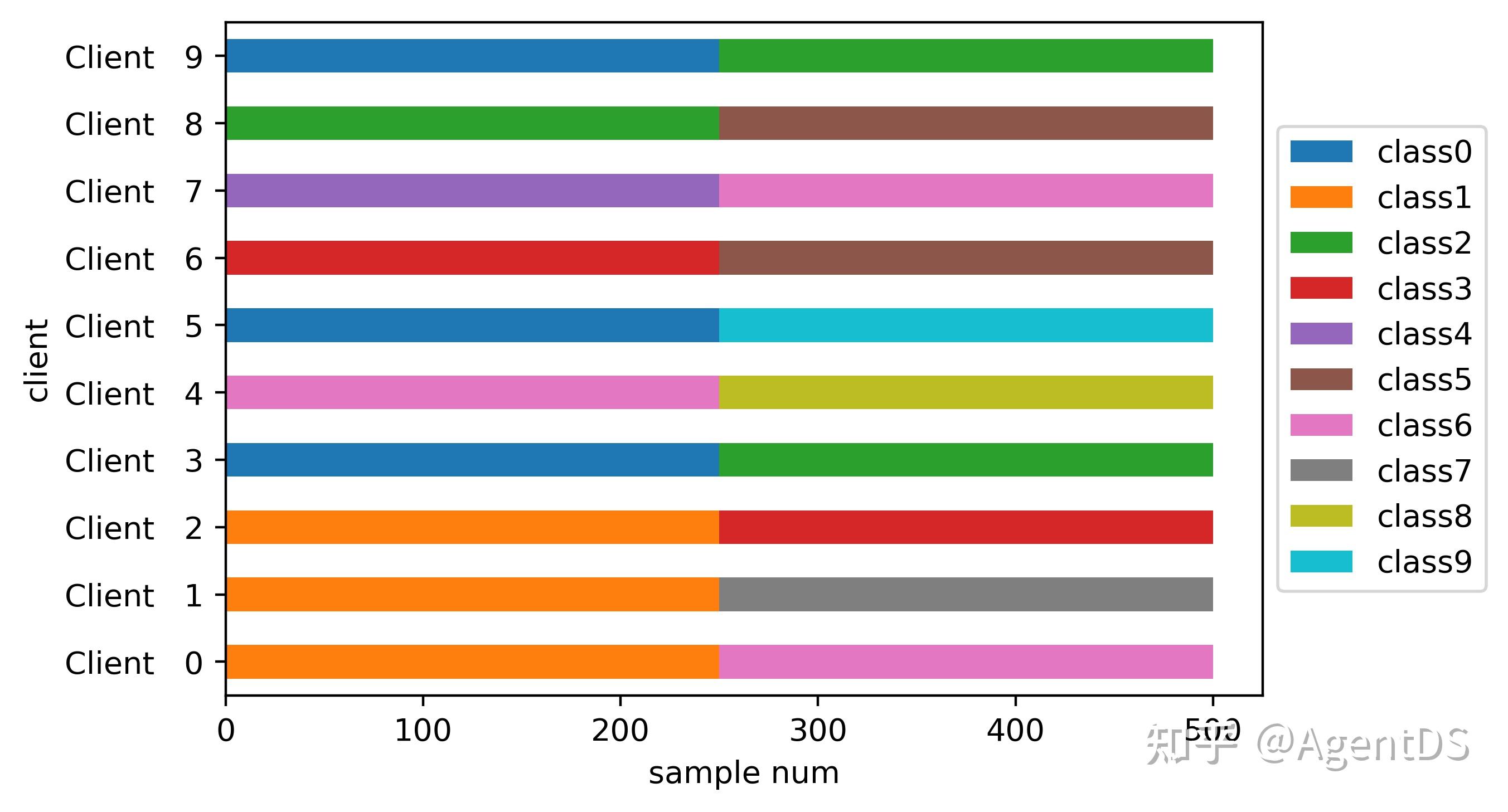
|
评价指标:
1、测试集精度:模型在测试集上的表现,衡量模型的泛化能力。
2、通信轮次:客户端与服务器通信的次数,评估联邦学习的通信效率。
实验结果:
- MNIST数据集:
在IID场景下,FedAvg在仅使用50轮通信时即可达到99%的测试集精度,而FedSGD需要超过600轮通信。
在non-IID场景下,FedAvg仍然能够通过较少的通信轮次达到高精度,表现出对异质性数据的鲁棒性。
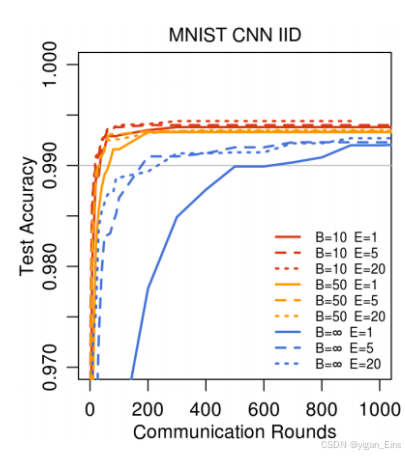
|
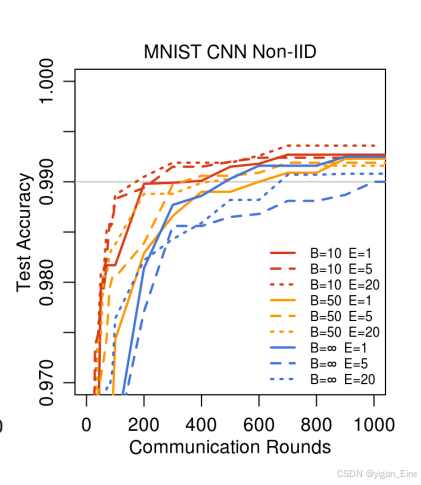
|
-
CIFAR-10数据集:
FedAvg显示了在复杂图像任务上的优势。相比于FedSGD,FedAvg能够在非独立同分布数据上更快收敛,在相同通信轮次下,测试集精度更高。
通信轮次减少了大约50倍,同时保持了85%以上的精度。


可以发现,FedAvg的曲线明显优于FedSGD,FedAvg收敛的更快且更加的稳定。 -
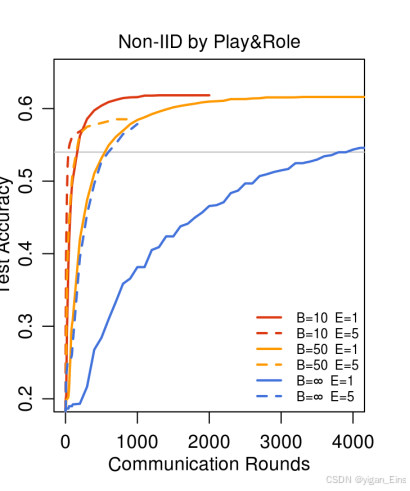
Shakespeare数据集:
在字符级LSTM的语言建模任务中,FedAvg比FedSGD更快收敛,特别时non-IID数据场景下,FedAvg的通信轮次显著减少。
实验显示FedAvg能够通过300轮通信达到相同的语言建模准确率,而FedSGD需要2000轮。
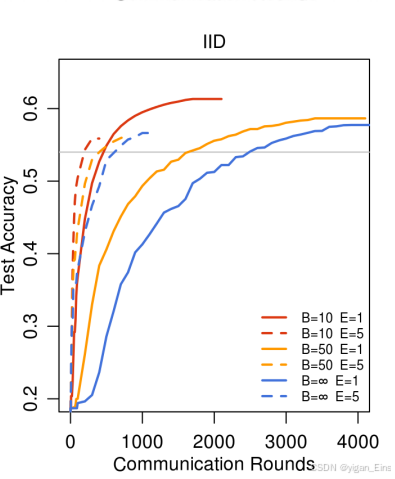
|
|
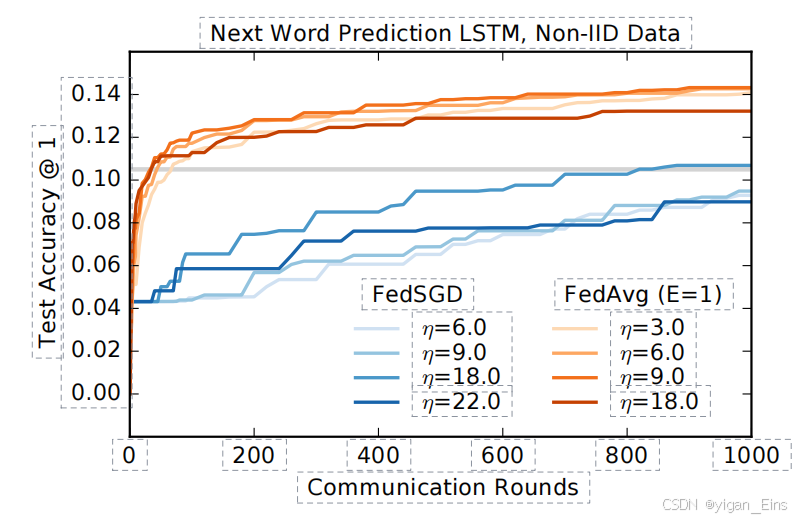
- 大规模词预测LSTM:
FedAvg在处理大规模词级别的文本任务时表现出了巨大的通信效率优势。通过本地多轮训练,FedAvg能够在1000轮通信内达到接近0.12的测试集精度。而FedSGD则需要超过3000轮通信才能达到类似的精度。
四、优缺点分析
优点:
- 通信效率显著提高:通过本地多轮训练减少了全局通信频次。
- 更适应异质数据分布:FedAvg在处理非IID数据时的性能提升明显,特别适合现实世界中的场景。
缺点: - 同步通信要求高:FedAvg是同步算法,要求每轮所有客户端同时进行通信和更新,可能在不稳定的网络环境中遇到延迟问题。
- 数据质量影响:客户端本地数据质量不均衡可能影响全局模型收敛速度和精度。
五、未来工作
隐私保护增强:
- 结合差分隐私来进一步保护用户数据不被推测。
- 通过安全多方计算(MPC)来确保通信过程中的数据安全。
异步更新方法:
探索异步联邦学习方法,减少同步通信的延迟问题,尤其在网络不稳定时保持模型的有效性。
模型扩展:
将FedAvg应用于更复杂的深度学习任务,如大型自然语言处理或超大规模神经网络的训练中,进一步验证其可扩展性和鲁棒性。
六、附图
|
|

欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容























所有评论(0)