《概率论与数理统计》学渣笔记
文章目录
1 随机事件和概率
1.1 古典概型求概率
在古典概型中,样本空间中的每个基本事件发生的概率是相同的。如果样本空间中有 n n n 个可能的基本事件,而感兴趣的事件 A A A 包含其中的 m m m 个基本事件,则事件 A A A 发生的概率 P ( A ) P(A) P(A) 可以表示为:
P ( A ) = 事件 A 包含的基本事件数 样本空间Ω中的基本事件总数 = m n \boldsymbol{P(A) = \frac{\text{事件 } A \text{ 包含的基本事件数}}{\text{样本空间Ω中的基本事件总数}} = \frac{m}{n}} P(A)=样本空间Ω中的基本事件总数事件 A 包含的基本事件数=nm
随机分配问题
将 n 个球随机分配到 N 个盒子中 \boldsymbol{将n个球随机分配到N个盒子中} 将n个球随机分配到N个盒子中
| 分配方式 | 不同分法的总数 |
|---|---|
| 每个盒子能装任意多个球 | N n N^n Nn |
| 每个盒子最多只能容纳一个球 | A N n = N ! ( N − n ) ! A_N^n = \frac{N!}{(N-n)!} ANn=(N−n)!N! |
“某指定n个”:只有1种情况
“恰有n个”:有 C N n C_N^n CNn种情况
简单随机抽样问题
从含有 N 个球的盒子中 n 次简单随机抽样 \boldsymbol{从含有N个球的盒子中n次简单随机抽样} 从含有N个球的盒子中n次简单随机抽样
| 抽样方式 | 抽样法总数 |
|---|---|
| 先后有放回取n次 | N n N^n Nn |
| 先后无放回取n次 | A N n = N ! ( N − n ) ! A_N^n = \frac{N!}{(N-n)!} ANn=(N−n)!N! |
| 任取n个 | C N n C_N^n CNn |
抓阄模型:“先后无放回取 k k k个球”与“任取 k k k个球”的概率相同。
1.2 几何概型求概率
P ( A ) = A (子区域:长度,面积) Ω (几何区域:长度,面积) \boldsymbol{P(A)=\frac{A(子区域:长度,面积)}{Ω(几何区域:长度,面积)}} P(A)=Ω(几何区域:长度,面积)A(子区域:长度,面积)
1.3 重要公式求概率











2 一维随机变量及其分布
2.1 随机变量及其分布函数的定义

离散型随机变量及其概率分布(概率分布)


连续型随机变量及其概率分布(分布函数)



2.2 离散型分布
0-1分布 X ∼ B ( 1 , p ) X \sim B(1,p) X∼B(1,p)



二项分布 X ∼ B ( n , p ) X\sim B(n,p) X∼B(n,p)




负二项分布(帕斯卡分布) X ∼ N b ( r , p ) X\sim Nb(r,p) X∼Nb(r,p)
在伯努利试验中,每次试验中事件 A A A发生的概率为 p p p,若 X X X表示事件 A A A在第 r r r次发生时的试验次数,则
P { X = k } = C k − 1 r − 1 p r ( 1 − p ) k − r , k = r , r + 1 , . . . P\{X = k\} =C^{r - 1}_{k - 1} p^r (1-p)^{k-r} ,k=r,r+1,... P{X=k}=Ck−1r−1pr(1−p)k−r,k=r,r+1,...
E X = r p , D X = r ( 1 − p ) p 2 EX=\frac{r}{p},DX=\frac{r(1-p)}{p^2} EX=pr,DX=p2r(1−p)
帕斯卡分布与几何分布有关, r = 1 r = 1 r=1时为几何分布。表首 r r r次即停止。

Y ∼ N b ( 2 , p ) Y\sim Nb(2,p) Y∼Nb(2,p)得 E Y = 2 p EY=\frac{2}{p} EY=p2
几何分布 X ∼ G ( p ) X\sim G(p) X∼G(p)
首中即停止(等待型分布),具有无记忆性 首中即停止(等待型分布),具有无记忆性 首中即停止(等待型分布),具有无记忆性

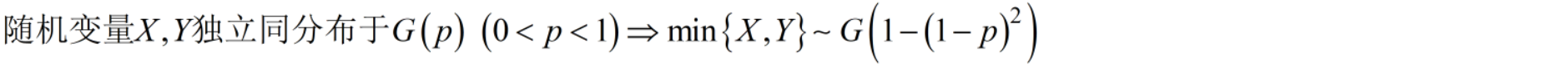


超几何分布 X ∼ H ( n , M , N ) X\sim H(n,M,N) X∼H(n,M,N)

泊松分布 X ∼ P ( λ ) X\sim P(λ) X∼P(λ)
用于描述稀有事件的概率 用于描述稀有事件的概率 用于描述稀有事件的概率


离散型→离散型

2.3 连续型分布


均匀分布 X ∼ U ( a , b ) X\sim U(a,b) X∼U(a,b)




指数分布 X ∼ E ( λ ) X\sim E(λ) X∼E(λ)


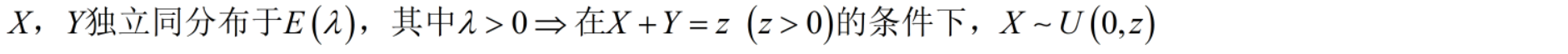

正态分布 X ∼ N ( μ , σ 2 ) X\sim N(μ,σ^2) X∼N(μ,σ2)











正态分布,也叫高斯分布,是一种特定的概率分布。其曲线呈钟形,对称于均值。
正态分布的重要性源于以下几个原因:
-
自然现象的普遍性:很多自然和社会现象的测量结果近似服从正态分布,比如人的身高、考试成绩、误差分布等。原因是这些现象往往受到多种独立因素的共同影响,而根据中心极限定理,当这些影响因素足够多且相互独立时,其结果往往接近正态分布。
-
统计推断的基础:在统计学中,许多推断方法(如 t t t 检验、 z z z 检验、线性回归等)都基于数据服从正态分布的假设。正态分布的数学特性使得这些方法可以更有效地估计参数、检验假设。
-
中心极限定理的支持:无论数据原本的分布是什么样的,只要样本量足够大,样本均值的分布就会趋向于正态分布。这一理论使得我们可以在处理大样本时,使用正态分布来简化问题。
-
易于计算和理解:正态分布有简洁的数学表达式,且它的标准化(即转化为标准正态分布)使得很多复杂的计算变得简单、直观。
连续型→离散型

2.4 混合型分布



连续型→连续型(或混合型)





3 多维随机变量及其分布
3.1 定义






3.2 求联合分布

二维均匀分布与二维正态分布






3.3 求边缘分布

3.4 求条件分布

3.5 判独立


3.6 用分布


3.7(离散型,离散型)→离散型

3.8(连续型,连续型)→连续型
分布函数法


卷积公式法(建议用这个)

最值函数的分布


3.10(离散型,连续型)→连续型【全集分解】

3.11 离散型→(离散型,离散型)

3.12 连续型→(离散型,离散型)

3.13 (离散型,离散型)→(离散型,离散型)

3.14 (连续型,连续型)→(离散型,离散型)

3.15 (离散型,连续型)→(离散型,离散型)

4 数字特征
4.1 数学期望







4.2 方差



4.3 亚当-夏娃公式(全期望定理,全方差定理)



4.4 常用分布的期望和方差
| 分布 | 期望 E ( X ) E(X) E(X) | 方差 D ( X ) D(X) D(X) |
|---|---|---|
| 0 − 1 0-1 0−1分布 X ∼ B ( p ) X \sim B(p) X∼B(p) | p p p | p ( 1 − p ) p(1-p) p(1−p) |
| 二项分布 X ∼ B ( n , p ) X\sim B(n,p) X∼B(n,p) | n p np np | n p ( 1 − p ) np(1-p) np(1−p) |
| 负二项分布(帕斯卡分布) X ∼ N b ( r , p ) X\sim Nb(r,p) X∼Nb(r,p) | r p \frac{r}{p} pr | r ( 1 − p ) p 2 \frac{r(1-p)}{p^2} p2r(1−p) |
| 几何分布 X ∼ G ( p ) X\sim G(p) X∼G(p) | 1 p \frac{1}{p} p1 | 1 − p p 2 \frac{1-p}{p^2} p21−p |
| 泊松分布 X ∼ p ( λ ) X\sim p(λ) X∼p(λ) | λ λ λ | λ λ λ |
| 均匀分布 X ∼ U ( a , b ) X\sim U(a,b) X∼U(a,b) | E ( X ) = a + b 2 E(X)=\frac{a+b}{2} E(X)=2a+b E ( X 2 ) = a 2 + a b + b 2 3 E(X^2) = \frac{a^2 + ab + b^2}{3} E(X2)=3a2+ab+b2 | D ( X ) = ( b − a ) 2 12 D(X)=\frac{(b-a)^2}{12} D(X)=12(b−a)2 求 a , b 的矩估计量: 1 n ∑ i = 1 n ( X i − X ‾ ) 2 = ( b − a ) 2 12 求a,b的矩估计量:\frac{1}{n}\sum_{i=1}^n(X_i-\overline{X})^2=\frac{(b-a)^2}{12} 求a,b的矩估计量:n1i=1∑n(Xi−X)2=12(b−a)2 D ( X 2 ) = ( b − a ) 4 80 D(X^2) = \frac{(b - a)^4}{80} D(X2)=80(b−a)4 |
| 指数分布 X ∼ E ( λ ) X\sim E(λ) X∼E(λ) | E ( X ) = 1 λ E(X)=\frac{1}{λ} E(X)=λ1 E ( X 4 ) = 24 λ 4 E(X^4) = \frac{24}{\lambda^4} E(X4)=λ424 | D ( X ) = 1 λ 2 D(X)=\frac{1}{λ^2} D(X)=λ21 D ( X 2 ) = 20 λ 4 D(X^2) = \frac{20}{\lambda^4} D(X2)=λ420 |
| 正态分布 X ∼ N ( μ , σ 2 ) X\sim N(μ,σ^2) X∼N(μ,σ2) X − X ‾ ∼ N ( 0 , n − 1 n σ 2 ) X-\overline{X}\sim N\left(0,\frac{n-1}{n}σ^2\right) X−X∼N(0,nn−1σ2) | E ( X ) = μ E(X)=μ E(X)=μ E [ ( X − μ ) 4 ] = 3 σ 4 E[(X - \mu)^4] = 3\sigma^4 E[(X−μ)4]=3σ4 E [ ( X − X ‾ ) 4 ] = 3 ( n − 1 ) 2 σ 4 n 2 E[(X - \overline{X})^4] = \frac{3(n-1)^2\sigma^4}{n^2} E[(X−X)4]=n23(n−1)2σ4 | D ( X ) = σ 2 D(X)=σ^2 D(X)=σ2 D ( X 2 ) = 2 σ 4 + 4 μ 2 σ 2 D(X^2) = 2\sigma^4 + 4\mu^2\sigma^2 D(X2)=2σ4+4μ2σ2 D ( S 2 ) = 2 σ 4 n − 1 D(S^2)=\frac{2σ^4}{n-1} D(S2)=n−12σ4 |
| 标准正态分布 X ∼ N ( 0 , 1 ) X\sim N(0,1) X∼N(0,1) | E ( X ) = 0 E(X)=0 E(X)=0 E ( X 4 ) = 3 E(X^4)=3 E(X4)=3 | D ( X ) = 1 D(X)=1 D(X)=1 D ( X 2 ) = 2 D(X^2)=2 D(X2)=2 |
| 卡方分布 X ∼ χ 2 ( n ) X\sim \chi^2(n) X∼χ2(n) | E ( X ) = n E(X)=n E(X)=n E ( X 4 ) = n ( n + 2 ) ( n + 4 ) E(X^4) = n(n + 2)(n + 4) E(X4)=n(n+2)(n+4) | D ( X ) = 2 n D(X)=2n D(X)=2n D ( X 2 ) = 4 n D(X^2)=4n D(X2)=4n |
| t t t分布 t ∼ t ( n ) t\sim t(n) t∼t(n) | 0 0 0 | n n − 2 \frac{n}{n-2} n−2n |
| 超几何分布(了解) X ∼ H ( n , M , N ) X\sim H(n,M,N) X∼H(n,M,N) | n M N \frac{nM}{N} NnM | n ⋅ M N ⋅ ( 1 − M N ) ⋅ N − n N − 1 n \cdot \frac{M}{N} \cdot \left(1 - \frac{M}{N}\right) \cdot \frac{N-n}{N-1} n⋅NM⋅(1−NM)⋅N−1N−n |
| 瑞利分布(了解) X ∼ R ( σ ) X \sim \text{R}(\sigma) X∼R(σ) | π 2 σ \sqrt{\frac{π}{2}}σ 2πσ | ( 2 − π 2 ) σ 2 (2-\frac{π}{2})σ^2 (2−2π)σ2 |
4.5 协方差




4.6 相关系数


对于随机变量 X X X 和 Y Y Y,若它们满足线性关系 Y = a X + b Y = aX + b Y=aX+b:
-
当 a > 0 a > 0 a>0 时, Y Y Y 随 X X X 同方向变化(即 X X X 增加, Y Y Y 也增加),所以它们呈完全正相关,此时相关系数 ρ X Y = 1 \rho_{XY} = 1 ρXY=1。
-
当 a < 0 a < 0 a<0 时, Y Y Y 随 X X X 反方向变化(即 X X X 增加, Y Y Y 减少),因此它们呈完全负相关,此时相关系数 ρ X Y = − 1 \rho_{XY} = -1 ρXY=−1。如 X + Y = 1 X+Y=1 X+Y=1可以直接推出 ρ X Y = − 1 \rho_{XY} = -1 ρXY=−1
4.7 独立性与不相关性的判定


4.8 切比雪夫不等式


5 大数定律与中心极限定理



5.1 切比雪夫大数定律(均值依概率收敛到期望)


5.2 伯努利大数定律(频率依概率收敛到概率)

5.3 辛钦大数定律(均值依概率收敛到期望)



5.4 中心极限定理(n足够大时,均收敛于正态分布)


6 统计量及其分布
6.1 统计量
统计量是不含未知参数的随机变量的函数 统计量是不含未知参数的随机变量的函数 统计量是不含未知参数的随机变量的函数


6.2 标准正态分布分布的上α分位数



6.3 卡方分布 X ∼ χ 2 ( n ) X\sim \chi^2(n) X∼χ2(n)
标准正态分布的平方 标准正态分布的平方 标准正态分布的平方






6.4 t分布 t ∼ t ( n ) t\sim t(n) t∼t(n)
标准正态分布的单打独斗 标准正态分布的单打独斗 标准正态分布的单打独斗
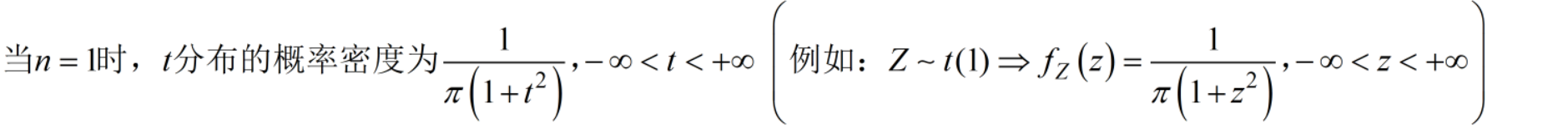




6.5 F分布 F ∼ F ( n 1 , n 2 ) F\sim F(n_1,n_2) F∼F(n1,n2)
卡方分布的单打独斗 卡方分布的单打独斗 卡方分布的单打独斗



6.6 正态总体下的常用结论

7 参数估计与假设检验
7.1 矩估计


矩估计法的核心思想是使得样本的样本矩等于总体的理论矩,从而通过这个等式来解出模型的参数。所谓“矩”就是随机变量的不同阶的期望,比如一阶矩是期望值,二阶矩是方差等。
参数估计能揭示数据规律,指导实际应用。描述数据、预测未来、优化决策和风险评估是参数估计的主要用途。
-
描述数据特性:估计参数帮助我们理解数据的分布特性,比如正态分布的均值(数据中心)和方差(数据分散程度)。
-
预测与推断:通过估计参数,可以进行未来预测或假设检验。例如,使用时间序列模型的参数预测市场趋势。
-
建模与优化:许多模型依赖参数估计来优化决策,如线性回归中的回归系数,用于预测或分类。
-
风险管理与模拟:估计参数后可以进行数据模拟,帮助评估金融风险或仿真系统性能。
-
理论验证与模型选择:通过实际数据检验理论模型,参数估计帮助选择更适合的模型。
7.2 最大似然估计(MLE)



MLE的应用
在 概率模型 中,最大似然估计 (MLE) 通过学习模型的参数,优化模型,使得在给定这些参数的情况下,训练数据的观测结果发生的概率最大。简言之,最大似然估计的目标是选择一组参数,使得模型最能够生成或解释现有数据。在深度学习中,这种优化过程通常通过最小化负对数似然损失来实现。
- 似然函数 是给定数据和模型的情况下,模型参数的联合概率。它评估在不同的参数值下,观测数据出现的可能性。
- 对数似然函数 是似然函数的对数,它常用于优化,因为对数的运算简化了计算,尤其是在处理大规模数据时。
- 负对数似然函数 是对数似然函数的负数,因为在优化问题中我们通常通过最小化损失来优化模型,而不是最大化似然。
因此,最大似然估计的目标 可以转化为 最小化负对数似然损失(NLL),这就是损失函数。在 机器学习和深度学习 中,我们通常用损失函数来度量模型的预测与真实数据之间的差距。
7.3 常见分布的矩估计量和最大似然估计量
| X服从的分布 | 矩估计量 | 似然估计量 |
|---|---|---|
| 0 − 1 分布 0-1分布 0−1分布 | p ^ = X ‾ \hat{p}=\overline{X} p^=X | p ^ = X ‾ \hat{p}=\overline{X} p^=X |
| B ( n , p ) B(n,p) B(n,p) | p ^ = X ‾ n \hat{p}=\frac{\overline{X}}{n} p^=nX | p ^ = X ‾ n \hat{p}=\frac{\overline{X}}{n} p^=nX |
| G ( p ) G(p) G(p) | p ^ = 1 X ‾ \hat{p}=\frac{1}{\overline{X}} p^=X1 | p ^ = 1 X ‾ \hat{p}=\frac{1}{\overline{X}} p^=X1 |
| P ( λ ) P(λ) P(λ) | λ ^ = X ‾ \hat{λ}=\overline{X} λ^=X | λ ^ = X ‾ \hat{λ}=\overline{X} λ^=X |
| U ( a , b ) U(a,b) U(a,b) | a ^ = X ‾ − 3 n ∑ i = 1 n ( X i − X ‾ ) \hat{a}=\overline{X}-\sqrt{\frac{3}{n}\sum_{i=1}^n(X_i-\overline{X})} a^=X−n3i=1∑n(Xi−X) b ^ = X ‾ + 3 n ∑ i = 1 n ( X i − X ‾ ) \hat{b}=\overline{X}+\sqrt{\frac{3}{n}\sum_{i=1}^n(X_i-\overline{X})} b^=X+n3i=1∑n(Xi−X) | a ^ = m i n { X 1 , X 2 , . . . , X n } \hat{a}=min\{X_1,X_2,...,X_n\} a^=min{X1,X2,...,Xn} b ^ = m a x { X 1 , X 2 , . . . , X n } \hat{b}=max\{X_1,X_2,...,X_n\} b^=max{X1,X2,...,Xn} |
| E ( λ ) E(λ) E(λ) | λ ^ = 1 X ‾ \hat{λ}=\frac{1}{\overline{X}} λ^=X1 | λ ^ = 1 X ‾ \hat{λ}=\frac{1}{\overline{X}} λ^=X1 |
| N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2) | μ ^ = X ‾ \hat{μ}=\overline{X} μ^=X σ 2 ^ = 1 n ∑ i = 1 n ( X i − X ‾ ) 2 \hat{σ^2}=\frac{1}{n}\sum_{i=1}^n(X_i-\overline{X})^2 σ2^=n1i=1∑n(Xi−X)2 | μ ^ = X ‾ \hat{μ}=\overline{X} μ^=X σ 2 ^ = 1 n ∑ i = 1 n ( X i − X ‾ ) 2 \hat{σ^2}=\frac{1}{n}\sum_{i=1}^n(X_i-\overline{X})^2 σ2^=n1i=1∑n(Xi−X)2 |
7.4 无偏性:求期望

7.5 有效性:比方差,方差越小越有效

7.6 一致性(相合性):大数定律
常用切比雪夫不等式、辛钦大数定律判一致性 常用切比雪夫不等式、辛钦大数定律判一致性 常用切比雪夫不等式、辛钦大数定律判一致性

7.7 区间估计










7.8 假设检验



选择检验统计量




7.9 两类错误
需要注意的几点:
- 通常用检验的显著性水平 α α α来表示在检验中允许犯第一类错误的概率。
- 两类错误之和可以大于1。
- 增大样本容量不一定能降低同时犯两类错误的概率。
第一类错误:弃真(直接算落入拒绝域的概率)

第二类错误:取伪(直接算落入收敛域的概率)





欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐



 155
155 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)