【无标题】
IceBerg+Minio+Hms+K8s环境下,使用Java API插入数据pom.xml数据写入非分区表写入结果数据写入分区表网上搜了不少文章,但是都是只包含了写入非分区表的用法,基本上没有看到分区表的写入案例。下面代码包含了分区表和非分区表的用法。都是在生产中使用的pom.xml<dependencies><dependency><groupId>org.
·
网上搜了不少文章,但是都是只包含了写入非分区表的用法,基本上没有看到分区表的写入案例。下面代码包含了分区表和非分区表的用法。都是在生产中使用的
pom.xml
<dependencies>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-core</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-hive-metastore</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.iceberg</groupId>
<artifactId>iceberg-hive-runtime</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
<exclusions>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>pentaho-aggdesigner-algorithm</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-aws</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.4</version>
<executions>
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/main/java</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
<encoding>utf8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.demo.WriteDataWithPartition</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
数据写入非分区表
WriteDataWithPartition.java
import org.apache.hadoop.conf.Configuration;
import org.apache.iceberg.*;
import org.apache.iceberg.catalog.Namespace;
import org.apache.iceberg.catalog.TableIdentifier;
import org.apache.iceberg.data.GenericRecord;
import org.apache.iceberg.data.IcebergGenerics;
import org.apache.iceberg.data.Record;
import org.apache.iceberg.data.parquet.GenericParquetWriter;
import org.apache.iceberg.hive.HiveCatalog;
import org.apache.iceberg.io.*;
import org.apache.iceberg.parquet.Parquet;
import org.apache.iceberg.relocated.com.google.common.collect.ImmutableList;
import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
import org.apache.iceberg.types.Types;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
public class WriteDataWithPartition {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hive.metastore.uris", "thrift://127.0.0.1:9083");
conf.set("fs.s3a.endpoint", "http://127.0.0.1:9000");
conf.set("fs.s3a.access.key", "admin");
conf.set("fs.s3a.path.style.access", "true");
conf.set("fs.s3a.secret.key", "******");
HiveCatalog catalog = new HiveCatalog();
catalog.setConf(conf);
Map<String, String> properties = new HashMap<>();
// 登录Mysql元数据库,select properties from catalog_manager where catalog_name = '?';
// 获取catalog.location,hive.metastore.uris
properties.put(CatalogProperties.WAREHOUSE_LOCATION, "s3a://bucket_name/object_name");
properties.put(CatalogProperties.CATALOG_IMPL, "org.apache.iceberg.hive.HiveCatalog");
catalog.initialize("hive", properties);
Table table = createNamespaceAndTable("db_name", "tb_name", catalog);
hiveCatalogAppend(table);
scanTable(table);
}
/**
* 定义表字段信息
*
* @return
*/
public static Schema definitionTableSchema() {
Schema schema = new Schema(
Types.NestedField.required(1, "id", Types.StringType.get()),
Types.NestedField.required(2, "name", Types.StringType.get()),
Types.NestedField.required(3, "age", Types.StringType.get()),
Types.NestedField.required(4, "date_time", Types.StringType.get()),
Types.NestedField.required(5, "dt", Types.StringType.get())
);
return schema;
}
/**
* 查询库表是否存在,如果不存在就创建
*
* @param ns 命名空间
* @param tn 表名
* @param catalog
* @return 表信息
*/
public static Table createNamespaceAndTable(String ns, String tn, HiveCatalog catalog) {
Table table;
TableIdentifier name = TableIdentifier.of(ns, tn);
Map<String, String> prop = new HashMap<>(2);
prop.put(TableProperties.ENGINE_HIVE_ENABLED, "true");
prop.put(TableProperties.FORMAT_VERSION, "2");
prop.put(TableProperties.UPSERT_ENABLED, "true");
Schema schema = definitionTableSchema();
PartitionSpec spec = PartitionSpec.builderFor(schema).identity("dt").build();
if (!catalog.namespaceExists(Namespace.of(ns))) {
catalog.createNamespace(Namespace.of(ns));
}
// 判断表是否存在,不存在则创建,存在则直接加载
if (!catalog.tableExists(name)) {
table = catalog.createTable(name, schema, spec, prop);
} else {
table = catalog.loadTable(name);
}
return table;
}
/**
* 扫描全表
*
* @param table
*/
public static void scanTable(Table table) {
IcebergGenerics.ScanBuilder scanBuilder = IcebergGenerics.read(table);
CloseableIterable<Record> records = scanBuilder.build();
for (Record record : records) {
System.out.print(record.getField("id"));
System.out.print("|");
System.out.print(record.getField("name"));
System.out.print("|");
System.out.print(record.getField("age"));
System.out.print("|");
System.out.print(record.getField("date_time"));
System.out.print("|");
System.out.print(record.getField("dt"));
System.out.println();
}
}
public static void hiveCatalogAppend(Table table) throws IOException {
Schema schema = definitionTableSchema();
GenericRecord record = GenericRecord.create(schema);
ImmutableList.Builder<GenericRecord> builder = ImmutableList.builder();
PartitionSpec spec = PartitionSpec.builderFor(schema)
.identity("dt")
.build();
for (Integer i = 0; i < 1000; i++) {
builder.add(record.copy(ImmutableMap.of("id", i.toString(),
"name", "张三",
"age", "18",
"date_time", "2023-01-01 00:00:00",
"dt", "20240521")));
}
ImmutableList<GenericRecord> records = builder.build();
// 将记录写入parquet文件
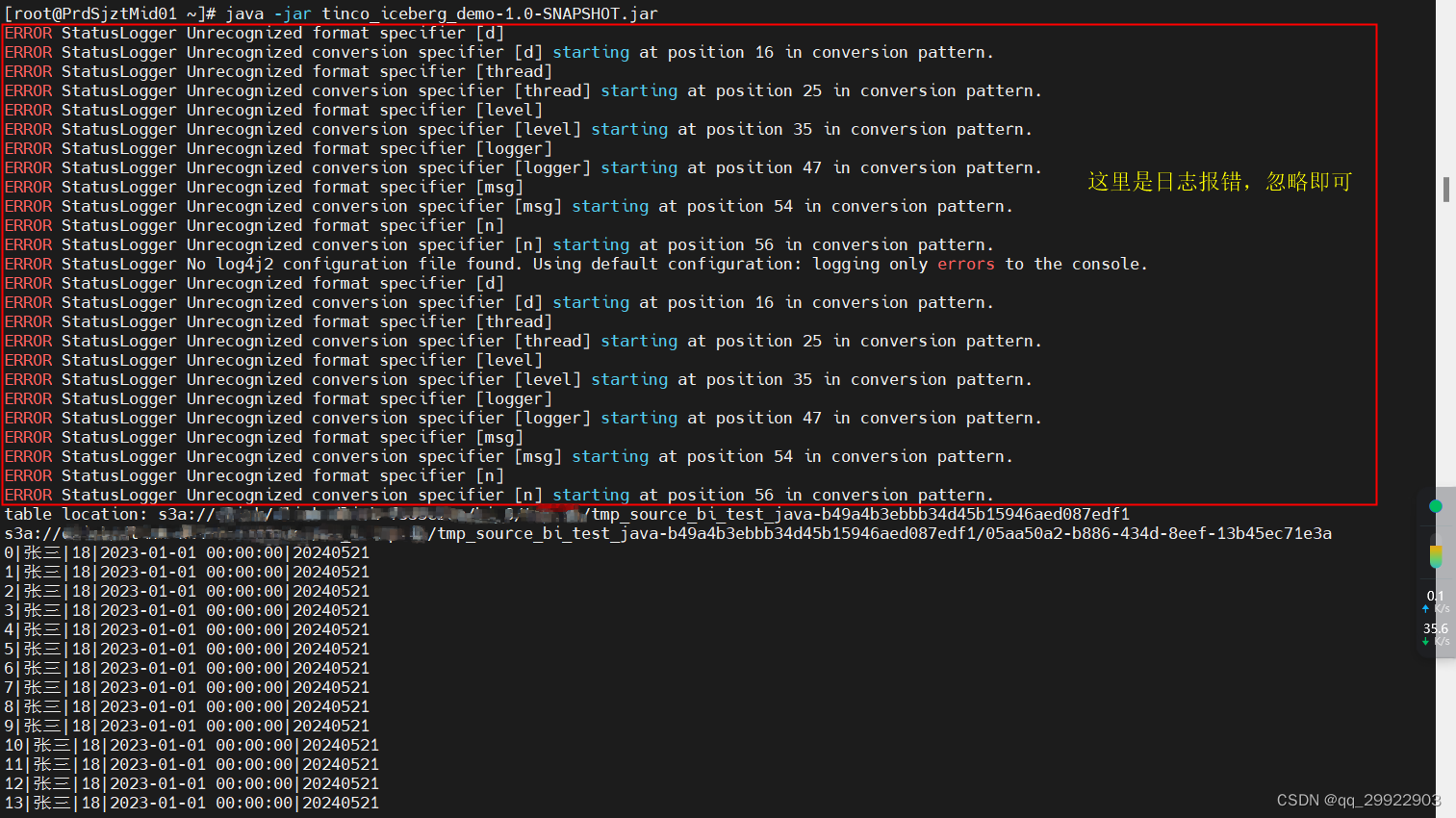
System.out.println("table location: " + table.location());
String filePath = table.location() + "/" + UUID.randomUUID().toString();
OutputFile file = table.io().newOutputFile(filePath);
DataWriter<GenericRecord> dataWriter = Parquet.writeData(file).schema(schema)
.createWriterFunc(GenericParquetWriter::buildWriter)
.overwrite()
.withSpec(PartitionSpec.unpartitioned())
.build();
try {
dataWriter.write(records);
} finally {
dataWriter.close();
}
DataFile df = dataWriter.toDataFile();
DataFile dataFile = DataFiles.builder(spec)
.withPath(df.path().toString())
.withFormat(FileFormat.PARQUET)
.withRecordCount(df.recordCount())
.withFileSizeInBytes(df.fileSizeInBytes())
.withPartitionPath("dt=20240521")
.build();
table.newAppend()
.appendFile(dataFile)
.commit();
}
}
写入结果

数据写入分区表
WriteDataWithoutPartition.java
import org.apache.hadoop.conf.Configuration;
import org.apache.iceberg.*;
import org.apache.iceberg.catalog.Namespace;
import org.apache.iceberg.catalog.TableIdentifier;
import org.apache.iceberg.data.GenericRecord;
import org.apache.iceberg.data.IcebergGenerics;
import org.apache.iceberg.data.Record;
import org.apache.iceberg.data.parquet.GenericParquetWriter;
import org.apache.iceberg.hive.HiveCatalog;
import org.apache.iceberg.io.CloseableIterable;
import org.apache.iceberg.io.DataWriter;
import org.apache.iceberg.io.OutputFile;
import org.apache.iceberg.parquet.Parquet;
import org.apache.iceberg.relocated.com.google.common.collect.ImmutableList;
import org.apache.iceberg.relocated.com.google.common.collect.ImmutableMap;
import org.apache.iceberg.types.Types;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
public class WriteDataWithoutPartition {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("hive.metastore.uris", "thrift://127.0.0.1:9083");
conf.set("fs.s3a.endpoint", "http://127.0.0.1:9000");
conf.set("fs.s3a.access.key", "admin");
conf.set("fs.s3a.path.style.access", "true");
conf.set("fs.s3a.secret.key", "******");
HiveCatalog catalog = new HiveCatalog();
catalog.setConf(conf);
Map<String, String> properties = new HashMap<>();
properties.put(CatalogProperties.WAREHOUSE_LOCATION, "s3a://bucket_name/object_name");
properties.put(CatalogProperties.CATALOG_IMPL, "org.apache.iceberg.hive.HiveCatalog");
catalog.initialize("hive", properties);
Table table = createNamespaceAndTable("db_name", "tb_name", catalog);
hiveCatalogAppend(table);
scanTable(table);
}
/**
* 定义表字段信息
*
* @return
*/
public static Schema definitionTableSchema() {
Schema schema = new Schema(
Types.NestedField.required(1, "id", Types.StringType.get()),
Types.NestedField.required(2, "name", Types.StringType.get()),
Types.NestedField.required(3, "age", Types.StringType.get()),
Types.NestedField.required(4, "date_time", Types.StringType.get()),
Types.NestedField.required(5, "dt", Types.StringType.get())
);
return schema;
}
/**
* 查询库表是否存在,如果不存在就创建
*
* @param ns 命名空间
* @param tn 表名
* @param catalog
* @return 表信息
*/
public static Table createNamespaceAndTable(String ns, String tn, HiveCatalog catalog) {
Table table;
TableIdentifier name = TableIdentifier.of(ns, tn);
Map<String, String> prop = new HashMap<>(2);
prop.put(TableProperties.ENGINE_HIVE_ENABLED, "true");
prop.put(TableProperties.FORMAT_VERSION, "2");
prop.put(TableProperties.UPSERT_ENABLED, "true");
Schema schema = definitionTableSchema();
if (!catalog.namespaceExists(Namespace.of(ns))) {
catalog.createNamespace(Namespace.of(ns));
}
// 判断表是否存在,不存在则创建,存在则直接加载
if (!catalog.tableExists(name)) {
table = catalog.createTable(name, schema, null, prop);
} else {
table = catalog.loadTable(name);
}
return table;
}
/**
* 扫描全表
*
* @param table
*/
public static void scanTable(Table table) {
IcebergGenerics.ScanBuilder scanBuilder = IcebergGenerics.read(table);
CloseableIterable<Record> records = scanBuilder.build();
for (Record record : records) {
System.out.print(record.getField("id"));
System.out.print("|");
System.out.print(record.getField("name"));
System.out.print("|");
System.out.print(record.getField("age"));
System.out.print("|");
System.out.print(record.getField("date_time"));
System.out.print("|");
System.out.print(record.getField("dt"));
System.out.println();
}
}
public static void hiveCatalogAppend(Table table) throws IOException {
Schema schema = definitionTableSchema();
GenericRecord record = GenericRecord.create(schema);
ImmutableList.Builder<GenericRecord> builder = ImmutableList.builder();
for (Integer i = 0; i < 1000; i++) {
builder.add(record.copy(ImmutableMap.of("id", i.toString(),
"name", "张三",
"age", "18",
"date_time", "2023-01-01 00:00:00",
"dt", "20240521")));
}
ImmutableList<GenericRecord> records = builder.build();
// 将记录写入parquet文件
String filePath = table.location() + "/" + UUID.randomUUID().toString();
OutputFile file = table.io().newOutputFile(filePath);
DataWriter<GenericRecord> dataWriter = Parquet.writeData(file).schema(schema)
.createWriterFunc(GenericParquetWriter::buildWriter)
.overwrite()
.withSpec(PartitionSpec.unpartitioned())
.build();
try {
dataWriter.write(records);
} finally {
dataWriter.close();
}
System.out.println(dataWriter.toDataFile().path());
// 将文件写入table
DataFile dataFile = dataWriter.toDataFile();
table.newAppend().appendFile(dataFile).commit();
}
}

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 50
50 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)