
端到端 RAG 解决方案 RAGFlow 正式开源
继 AI 原生数据库 Infinity 于去年底正式开源之后,我们的端到端 RAG 解决方案 RAGFlow 也于今日正式开源。项目地址: https://github.com/infiniflow/ragflow
继 AI 原生数据库 Infinity 于去年底正式开源之后,我们的端到端 RAG 解决方案 RAGFlow 也于今日正式开源。在回答 RAGFlow 是一款怎样的产品之前,我们先来谈谈为何要做这样一款产品。
RAG 发展到今日,已经成为 LLM 面向 B 端服务的共识,然而时至今日,针对它的疑问却从来没有停止过。我们的公号从开通至今,大部分内容输出,都是针对这一点来回答,包括最近一篇针对今年以来长上下文 LLM 不断引爆市场从而产生对 RAG 的广泛质疑,作出了深入解读。
简单地讲:以个人和中小企业简易场景为代表的许多问答系统,确实没有用 RAG 的必要。然而,这些长上下文 LLM ,已经或者正在解决 RAG 发展过程中面临的两个大的问题之一,因此,它们跟 RAG 之间是合作,而远非相互取代的关系。这两大问题即为:
-
LLM 自身的问题
-
RAG 的问题
对于 RAG 来说,LLM 最基础的能力包括:
-
摘要能力
-
翻译能力
-
可控性(是否听话)
是的,你没看错, 这3个看起来很不性感的地方,恰恰是目前许多 LLM 没有做好的。这些能力没有解锁,那么所谓的逻辑推理,所谓各类 Agent 的决策系统,也是空中楼阁。所以,随着长上下文 LLM 的升级,特别是针对长上下文“大海捞针”能力地提升,极大缓解了 RAG 实施中的问题之一 —— 来自 LLM 自身的问题。而另一大问题就是来自 RAG 系统本身,这包含:
-
数据库的问题。我们在过去的公号中,多次强调了多路召回对于 RAG 的重要性。 哪怕最简易的知识库,没有多路召回,也很难表现好。因此,RAG 系统的数据库,需要具备多路召回能力,而非简易的向量数据库。
-
数据的问题。这一点,对于许多初期做 RAG 的朋友感受并不明显,因为拿现有的开源软件栈,包括各种向量数据库 ,RAG 编排工具例如 LangChain, LlamaIndex 等,再搭配一个漂亮的 UI,就可以很容易的让一套 RAG 系统运行起来。类似的编排工具,在 Github 上已经有数万的 star, 然而,所有这些工具,都没有很好地解决数据本身的问题,这导致复杂格式的文档是以混乱的方式进入到数据库中,必然导致 Garbage In Garbage Out。
以上这2点,是导致当前的 RAG 仍然停留在浅层,尤其没有解锁出更多企业端场景的重要原因。因此,我们很欣喜地看到 LLM 自身能力在不断演进之外,我们也有必要去专门解决 RAG 本身的挑战: 我们既提供了 RAG 专用的数据库Infinity 来缓解上边第一点, 也针对上述第二点提供一款专用的 RAG 工具,让 RAG 逐渐为更多企业和个人用起来,逐渐解锁更多的场景。这就是 RAGFlow 推出的来龙去脉。
下边我们来看看 RAGFlow 这款产品,相比目前市面上已有的各类开源方案,都有哪些特点。
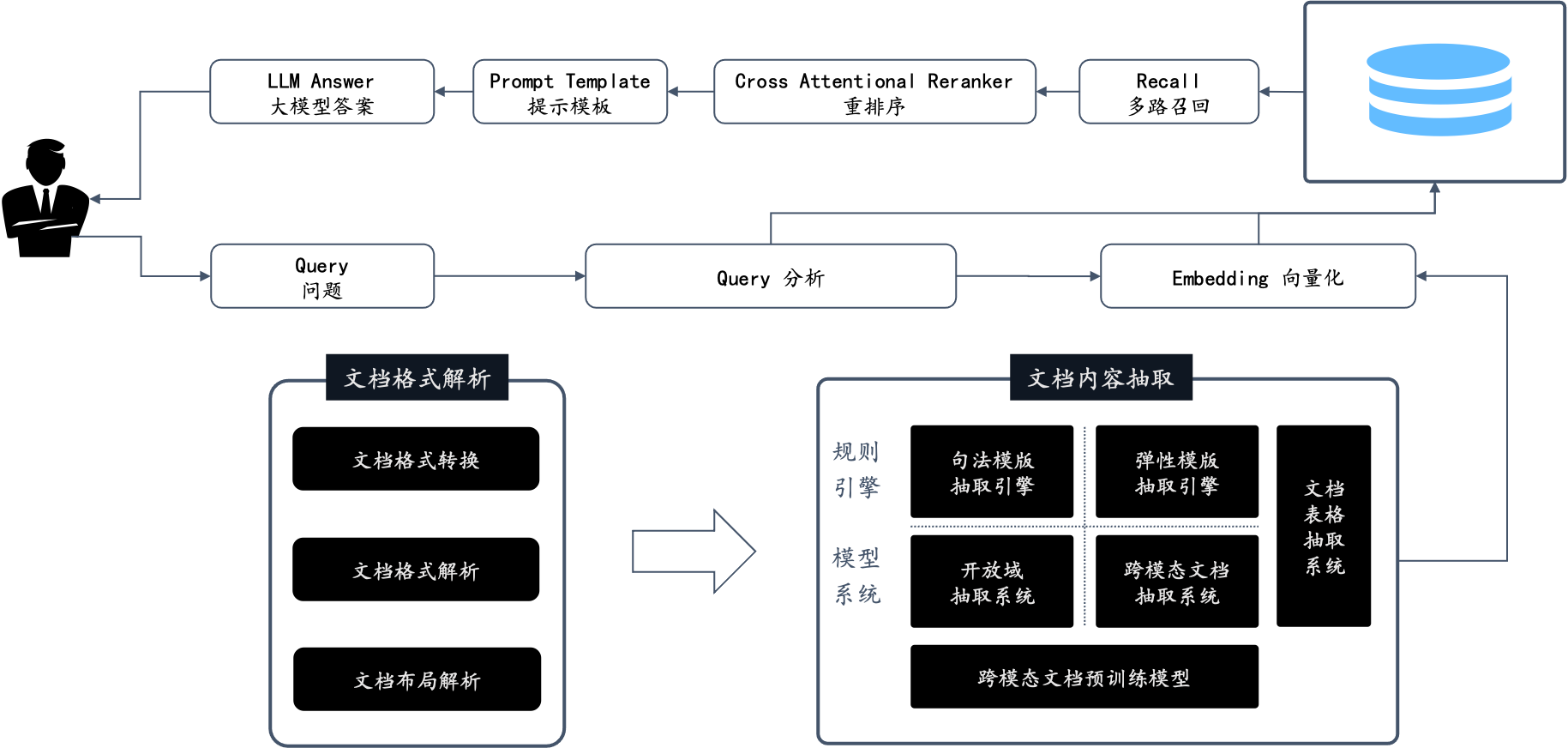
首先, RAGFlow 是一款完整的 RAG 解决方案,它允许用户上传并管理自己的文档,文档类型可以是任意类型,例如 PDF、Word、PPT、Excel、当然也包含 TXT,在完成智能解析之后,让数据以正确地格式进入到数据库,然后用户可以采用任意大模型对自己上传的文档进行提问。 也就是说,包含了如下完整的端到端流程。
其次,RAGFlow 的最大特色,就是多样化的文档智能处理,保证用户的数据从 Garbage In Garbage Out 变为 Quality In Quality Out。为了做到这一点, RAGFlow 没有采用任何开源的 RAG 中间件包括 LangChain、LlamaIndex 等,而是完全重新研发了一套智能文档理解系统,并以此为依托构建 RAG 任务编排体系。 这个系统的特点包含:
-
它是一套基于 AI 模型的智能文档处理系统:对于用户上传的文档,它需要自动识别文档的布局,包括标题,段落,换行等等,还包含难度很大的图片和表格。对于表格来说,不仅仅要识别出文档中存在表格,还会针对表格的布局做进一步识别,包括内部每一个单元格,多行文字是否需要合并成一个单元格,等等,并且表格的内容还会结合表头信息处理,确保以合适的形式送到数据库,从而完成 RAG 针对这些细节数字的“大海捞针”。
-
它是一套包含各种不同模板的智能文档处理系统:不同行业不同岗位所用到的文档不同,行文格式不同,对文档查阅的需求也不同。比如:
-
会计一般最常接触到的凭证,发票,Excel报表;查询的一般都是数字,如:看一下上月十五号发生哪些凭证,总额多少?上季度资产负债表里面净资产总额多少?合同台账中下个月有哪些应付应收?
-
作为一个HR平时接触最庞杂的便是候选人简历,且查询最多的是列表查询,如:人才库中985/211的3到5年的算法工程师有哪些?985 硕士以上学历的人员有哪些?赵玉田的微信号多少?香秀哪个学校的来着?
-
作为科研工作者接触到最多的可能是就是论文了,快速阅读和理解论文,梳理论文和引文之间的关系成了他们的痛点。
-
这样看来凭证/报表、简历、论文的文档结构是不一样的,查询需求也是不一样的,那处理方式肯定是不一样。因此RAGFlow 在处理文档时,给了不少的选择:Q&A,Resume,Paper,Manual,Table,Book,Law,通用... 。
当然,这些分类还在不断继续扩展中,处理过程还有待完善。我们也会抽象出更多共通的东西,使各种定制化的处理更加容易。


-
智能文档处理的可视化和可解释性:用户上传的文档到底被处理成啥样了,如:分割了多少片,各种图表处理成啥样了,毕竟任何基于 AI 的系统只能保证大概率正确,作为系统有必要给出这样的空间让用户进行适当的干预,作为用户也有把控的需求,黑箱不敌白箱。特别是对于 PDF,行文多种多样,变化多端,而且广泛流行于各行各业,对于它的把控尤为重要,我们不仅给出了处理结果,而且可以让用户查看文档解析结果并一次点击定位到原文,对比和原文的差异,可增可减可改可查,如下图所示:



最后, RAGFlow 是一个完整的 RAG 系统,而目前开源的 RAG,大都忽视了 RAG 本身的最大优势之一: 可以让 LLM 以可控的方式回答问题,或者换种说法: 有理有据、消除幻觉。我们都知道,随着模型能力的不同,LLM 多少都会有概率会出现幻觉,在这种情况下, 一款 RAG 产品应该随时随地给用户以参考,让用户随时查看 LLM 是基于哪些原文来生成答案的,这需要同时生成原文的引用链接,并允许用户的鼠标 hover 上去即可调出原文的内容,甚至包含图表。如果还不能确定,再点一下便能定位到原文,如下图所示:



RAGFlow 于 2024 年 4 月 1 日正式开源,它已经在若干家企业中得到使用。我们在持续不断完善它,近期目标包含:完善文件管理功能,使之可以像文档管理器那样工作,这样个人和企业的数据,可以被更加有效地管理并跟企业级知识库结合。RAGFlow 未来将进一步向企业级低代码工具演进,不断解锁 RAG B 端场景, 让 AI 普适化,我们一直在路上。欢迎 Star 和关注 RAGFlow!
项目地址:
https://github.com/infiniflow/ragflow
项目官网:
https://ragflow.io
在线Demo:https://demo.ragflow.io
开源说明:RAGFlow 采用 Apache 2.0 License,我们欢迎任何企业和个人免费使用和二次开发。在使用中遇到的问题,欢迎给我们提 Issue,点击下方二维码加小助手好友加入 RAGFlow 交流群 。目前开源的版本,仅提供较为基础的智能处理模型。如果需要更加智能的文档处理模型,欢迎与我们取得联系。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)