

OpenAI被打脸?地表最强开源大模型:Grok,拥有3140亿参数
一周前,马斯克就在X上发布了一则消息,表示这周xAI会发布开源版本的Grok,然后今天就如期的实现了他的承诺。314B参数的开源大模型!
前言:
今天凌晨,马斯克xAI的大模型Grok-1的开源版本发布,其拥有314B的参数,以及8个混合专家模型(Mixture-of-Experts,MoE)。遵循Apache 2.0协议开放模型权重和架构,是迄今为止训练参数量最大的开源大语言模型。
我们先来看一个我觉得非常搞笑的事情
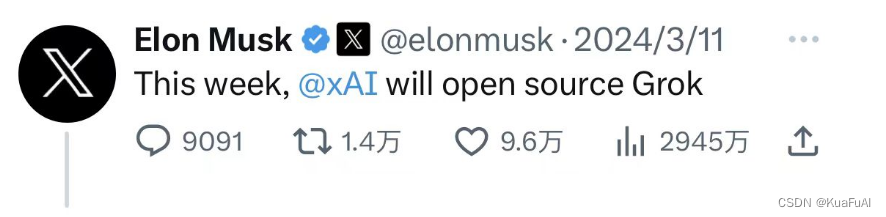
一周前,马斯克就在X上发布了一则消息,表示这周xAI会发布开源版本的Grok,然后今天就如期的实现了他的承诺。搞笑的事情来了,人家前脚刚发布了大模型,OpenAI就跑到马斯克地下凑热闹。
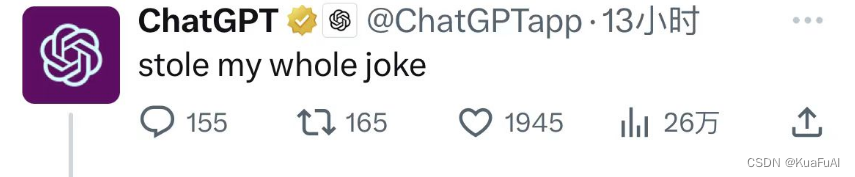
然后马斯克就直接阴阳OpenAI说:请你告诉我们关于OpenAI更多可以开放的信息。众所周知,马斯克一直热衷于开源,就连特斯拉的一些关键技术都被他公开了,可见这波马斯克是直接赢麻了。
由于Xai并没有公布任何关于Grok的机演示的视频。所以我们只能够简单的从其官网和GitHub上来了解到它的一些基本讯息。

斯坦福的研究员Andrew Kean Gao,分四个部分来梳理了Grok的架构信息:

Grok-1拥有314B的参数(GPT-3.5的参数为175B),包括8个混合专家的模型,其中有2个是活跃模型,拥有860亿激活参数(比Llama-2 70B还多)使用旋转嵌入,而不是固定位置嵌入。
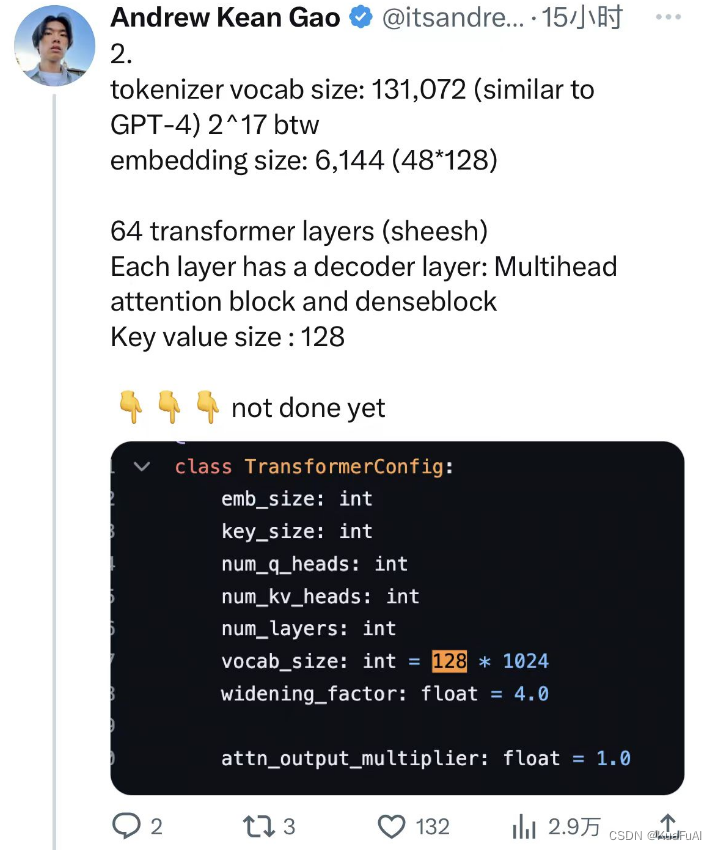
①分词器词汇大小:131,072(类似于 GPT-4)2^17
②嵌入尺寸:6,144(48*128)
③64层Transformer(Sheesh)每层都有一个解码器层:多头注意块和密集块
④键值大小:128
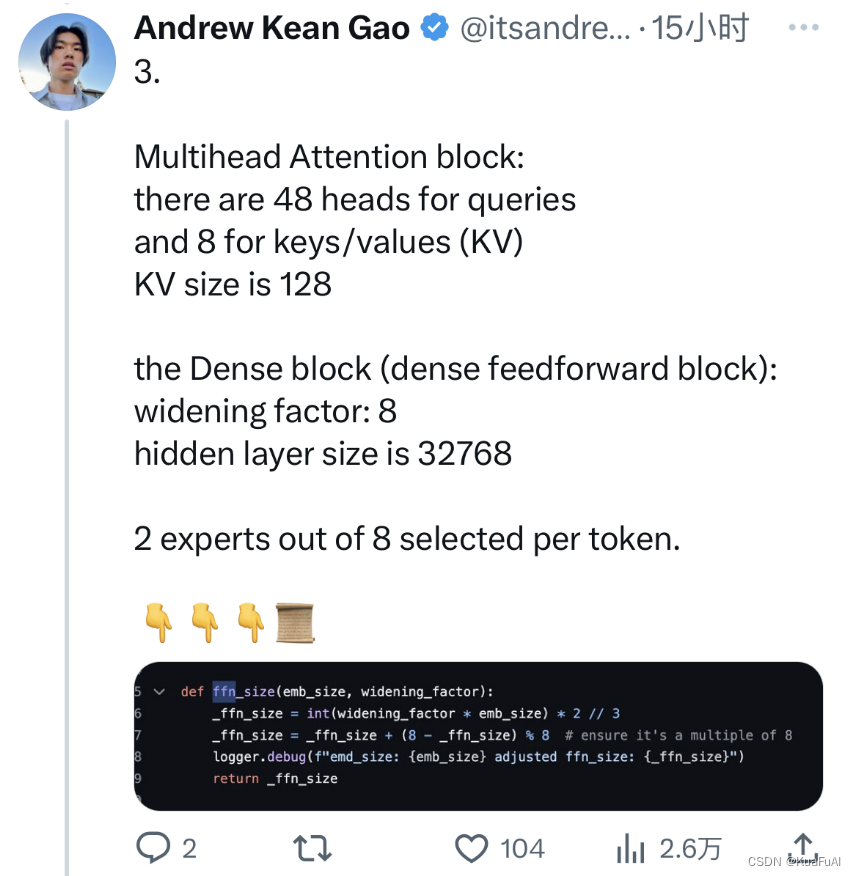
①多头注意力块:有48个可查询的头与8个 表示键值 (KV),KV大小为128
②Dense 模块(密集前馈模块):
加宽因子: 8
隐藏层大小为32768
③每个token从 8 名专家中选出 2 名。

①旋转位置嵌入大小 6144,它与模型的输入嵌入大小相同
②上下文长度:8,192 个token
③精度为:BF16
放上两张Andrew Kean Gao提供的图片

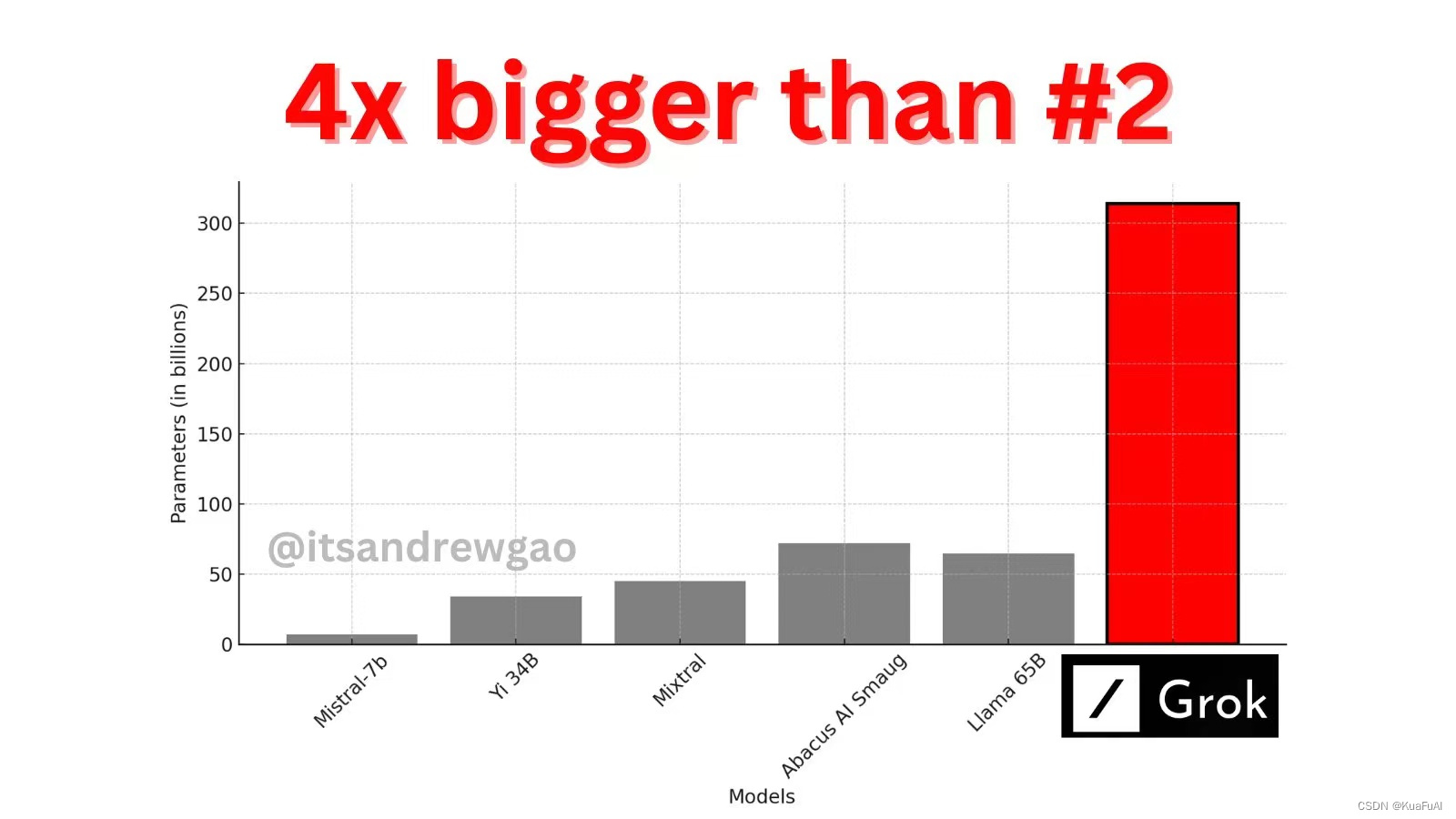
xAI 遵守 Apache 2.0 (可商用,允许用户自由地使用、修改和分发软件)许可证来开源 Grok-1 的权重和架构。
早在2023年11月,xAI就已经推出了Grok-0(当时的训练参数为330亿),其水平基本接近LLaMA 2(70B),经过了几个月的迭代之后,进行了基准测试
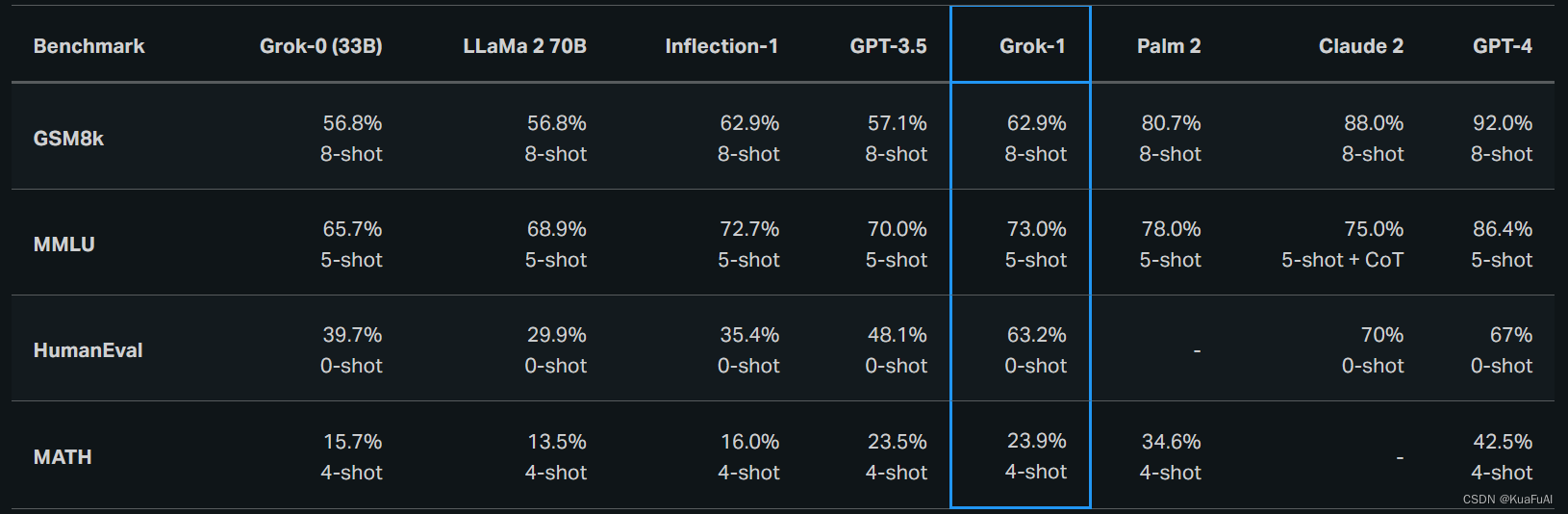
在这些基准测试中,Grok-1 表现出色,超过了其计算类中的所有其他模型,包括 ChatGPT-3.5 和 Inflection-1。只有使用 GPT-4 等大量训练数据和计算资源进行训练的模型才能超越它。

在2023年的时候Grok参加了 匈牙利全国高中数学决赛 ,Grok 以 C (59%) 的成绩通过了考试,而 Claude-2 获得了相同的成绩 (55%),GPT-4 以 68% 的成绩获得了 B。所有模型均在相同的提示下进行评估。并且Grok没有为这次评估进行针对性的调整。
具体Grok-1实测能够达到什么样的水平还尚不可知,因为如果我们自己想用的话,可能需要拥有一台搭载628G运存的GPU设备
最后附上一张,截止到文章发布前,Grok在GitHub上的互动数据


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)