
马斯克旗下xAI开源Grok-1:3140亿参数迄今最大,权重架构全开放,附磁力下载
之后,他们对模型的推理和编码能力进行了重大改进,最终开发出了 Grok-1,这是一款功能更为强大的 SOTA 语言模型,在 HumanEval 编码任务中达到了 63.2% 的成绩,在 MMLU 中达到了 73%。相对的,在 X(原 Twitter)上可用的 Grok 大模型是微调过的版本,其行为和原始权重版本并不相同。研究人员可以利用Grok-1进行自然语言理解和生成的实验,开发者可以构建能够处
马斯克说一不二,今天凌晨,旗下 xAI 将大模型 Grok 开源!

xAI 是埃隆・马斯克成立的人工智能公司,于2023年7月12日宣布成立。该公司的目标是专注于回答更深层次的科学问题,希望未来可以利用人工智能帮助人们解决复杂的科学和数学问题,并且 “理解” 宇宙。
该公司团队成员曾在 DeepMind、OpenAI、谷歌研究院、微软研究院、特斯拉及多伦多大学供职,由埃隆・马斯克领导。
Grok-1项目的代码和模型权重已上线GitHub。官方信息显示,此次开源的Grok-1是一个3140亿参数的混合专家模型,这是当前开源模型中参数量**(违反广告法)的一个!
项目地址:https://github.com/xai-org/grok-1.git

xAI 遵守 Apache 2.0 许可证来开源 Grok-1 的权重和架构。Apache 2.0 许可证允许用户自由地使用、修改和分发软件,无论是个人还是商业用途。项目发布短短八个小时,已经揽获 6.9k 星标,热度还在持续增加。
当然,老马开源后,不忘反手嘲讽一下 OpenAI

强者如是。
Grok-1 从头开始训练,并且没有针对任何特定应用(如对话)进行微调。相对的,在 X(原 Twitter)上可用的 Grok 大模型是微调过的版本,其行为和原始权重版本并不相同。
Grok-1 的模型细节包括如下:
基础模型基于大量文本数据进行训练,没有针对任何具体任务进行微调;
3140 亿参数的 MoE 模型,在给定 token 上的激活权重为 25%;
2023 年 10 月,xAI 使用 JAX 库和 Rust 语言组成的自定义训练堆栈从头开始训练。
这个模型的意义和影响如何?
研究人员可以利用Grok-1进行自然语言理解和生成的实验,开发者可以构建能够处理复杂对话的智能系统,企业可以使用Grok- 1 作为基础模型,进一步开发行业特定的AI应用。
Grok- 1 包括提供未经特定任务微调的大型语言模型,包含 3140 亿参数,其中25%的权重在给定标记上活跃,使用基于JAX和Rust的自定义训练堆栈进行训练。访问官网获取更多信息。
此外,根据网站流量数据显示,Grok- 1 的访问量主要来自美国、英国、印度、德国和巴西,展现出其在全球范围内的受欢迎程度和用户基础。
该存储库包含用于加载和运行 Grok-1 开放权重模型的 JAX 示例代码。使用之前,用户需要确保先下载 checkpoint ,并将 ckpt-0 目录放置在 checkpoint 中, 然后,运行下面代码进行测试:

项目说明中明确强调,由于 Grok-1 是一个规模较大(314B 参数)的模型,因此需要有足够 GPU 内存的机器才能使用示例代码测试模型。此外,该存储库中 MoE 层的实现效率并不高,之所以选择该实现是为了避免需要自定义内核来验证模型的正确性。
用户可以使用 Torrent 客户端和这个磁力链接来下载权重文件:
1 magnet:?xt=urn:btih:5f96d43576e3d386c9ba65b883210a393b68210e&tr=https%3A%2F%2Facademictorrents.com%2Fannounce.php&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce
看到这,有网友开始好奇 314B 参数的 Grok-1 到底需要怎样的配置才能运行。对此有人给出答案:可能需要一台拥有 628 GB GPU 内存的机器(每个参数 2 字节)。这么算下来,8xH100(每个 80GB)就可以了。

知名机器学习研究者、《Python 机器学习》畅销书作者 Sebastian Raschka 评价道:「Grok-1 比其他通常带有使用限制的开放权重模型更加开源,但是它的开源程度不如 Pythia、Bloom 和 OLMo,后者附带训练代码和可复现的数据集。」
DeepMind 研究工程师 Aleksa Gordié 则预测,Grok-1 的能力应该比 LLaMA-2 要强,但目前尚不清楚有多少数据受到了污染。另外,二者的参数量也不是一个量级。
Grok-1 是个什么模型?能力如何?
Grok 是马斯克 xAI 团队去年 11 月推出的一款大型语言模型。在去年 11 月的官宣博客中(参见《马斯克 xAI 公布大模型详细进展,Grok 只训练了 2 个月》), xAI 写道:
Grok 是一款仿照《银河系漫游指南》设计的 AI,可以回答几乎任何问题,更难能可贵的是,它甚至可以建议你问什么问题!
Grok 在回答问题时略带诙谐和叛逆,因此如果你讨厌幽默,请不要使用它!
Grok 的一个独特而基本的优势是,它可以通过 X 平台实时了解世界。它还能回答被大多数其他 AI 系统拒绝的辛辣问题。
Grok 仍然是一个非常早期的测试版产品 —— 这是我们通过两个月的训练能够达到的最佳效果 —— 因此,希望在您的帮助下,它能在测试中迅速改进。
xAI 表示,Grok-1 的研发经历了四个月。在此期间,Grok-1 经历了多次迭代。
在公布了 xAI 创立的消息之后,他们训练了一个 330 亿参数的 LLM 原型 ——Grok-0。这个早期模型在标准 LM 测试基准上接近 LLaMA 2 (70B) 的能力,但只使用了一半的训练资源。之后,他们对模型的推理和编码能力进行了重大改进,最终开发出了 Grok-1,这是一款功能更为强大的 SOTA 语言模型,在 HumanEval 编码任务中达到了 63.2% 的成绩,在 MMLU 中达到了 73%。
xAI 使用了一些旨在衡量数学和推理能力的标准机器学习基准对 Grok-1 进行了一系列评估:

在这些基准测试中,Grok-1 显示出了强劲的性能,超过了其计算类中的所有其他模型,包括 ChatGPT-3.5 和 Inflection-1。只有像 GPT-4 这样使用大量训练数据和计算资源训练的模型才能超越它。xAI 表示,这展示了他们在高效训练 LLM 方面取得的快速进展。
不过,xAI 也表示,由于这些基准可以在网上找到,他们不能排除模型无意中在这些数据上进行了训练。因此,他们在收集完数据集之后,根据去年 5 月底(数据截止日期之后)公布的 2023 年匈牙利全国高中数学期末考试题,对他们的模型(以及 Claude-2 和 GPT-4 模型)进行了人工评分。结果,Grok 以 C 级(59%)通过考试,Claude-2 也取得了类似的成绩(55%),而 GPT-4 则以 68% 的成绩获得了 B 级。xAI 表示,他们没有为应对这个考试而特别准备或调整模型。

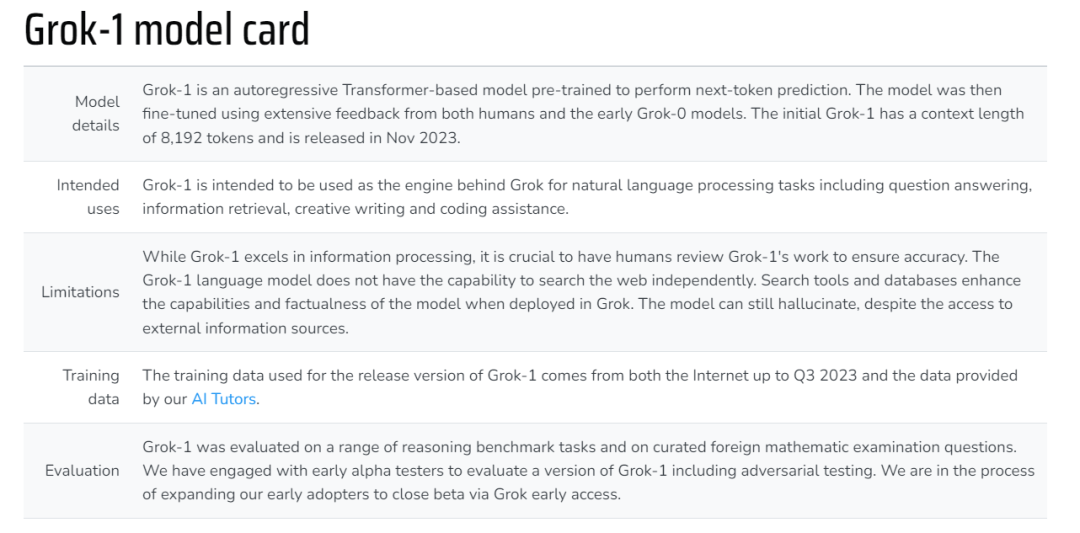
下面这个表格展示了 Grok-1 的更多信息(来自 2023 年 11 月的博客,部分信息可能存在更新):
模型细节:Grok-1 是一个基于 Transformer 的自回归模型。xAI 利用来自人类和早期 Grok-0 模型的大量反馈对模型进行了微调。初始的 Grok-1 能够处理 8192 个 token 的上下文长度。模型于 2023 年 11 月发布。
预期用途:Grok-1 将作为 Grok 背后的引擎,用于自然语言处理任务,包括问答、信息检索、创意写作和编码辅助。
局限性:虽然 Grok-1 在信息处理方面表现出色,但让人类检查 Grok-1 的工作以确保准确性至关重要。Grok-1 语言模型不具备独立搜索网络的能力。在 Grok 中部署搜索工具和数据库可以增强模型的能力和真实性。尽管可以访问外部信息源,但模型仍会产生幻觉。
训练数据:Grok-1 发布版本所使用的训练数据来自截至 2023 年第三季度的互联网数据和 xAI 的 AI 训练师提供的数据。
评估:xAI 在一系列推理基准任务和国外数学考试试题中对 Grok-1 进行了评估。他们与早期 alpha 测试者合作,以评估 Grok-1 的一个版本,包括对抗性测试。目前,Grok 已经对一部分早期用户开启了封闭测试访问权限,进一步扩大测试人群。
在博客中,xAI 还公布了 Grok 的构建工程工作和 xAI 大致的研究方向。其中,长上下文的理解与检索、多模态能力都是未来将会探索的方向之一。
xAI 表示,他们打造 Grok 的愿景是,希望创造一些 AI 工具,帮助人类寻求理解和知识。
具体来说,他们希望达到以下目标:
收集反馈,确保他们打造的 AI 工具能够最大限度地造福全人类。他们认为,设计出对有各种背景和政治观点的人都有用的 AI 工具非常重要。他们还希望在遵守法律的前提下,通过他们的 AI 工具增强用户的能力。Grok 的目标是探索并公开展示这种方法;
增强研究和创新能力:他们希望 Grok 成为所有人的强大研究助手,帮助他们快速获取相关信息、处理数据并提出新想法。
他们的最终目标是让他们的 AI 工具帮助人们寻求理解。
在 X 平台上,Grok-1 的开源已经引发了不少讨论。值得注意的是,技术社区指出,该模型在前馈层中使用了 GeGLU,并采用了有趣的 sandwich norm 技术进行归一化。甚至 OpenAI 的员工也发帖表示对该模型很感兴趣。
最后,大胆猜想,国产完全自主知识产权的sora很快就要喷涌了 :)

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)