
利用Sklearn中逻辑回归模型训练胸腺癌(breast_cancer)数据集
是基于基于NumPySciPy和Matplotlib的开源Python机器学习包,具有:1.简单高效的数据分析工具2.可在多种环境中重复使用3.建立在NumpyScipy以及matplotlib等数据科学库之上4.开源且可商用的基于BSD许可它封装了一系列数据预处理、机器学习算法、模型选择等工具,是数据分析师首选的机器学习工具包。自2007年发布以来,已经成为Python重要的机器学习库了,简称s
一键AI生成摘要,助你高效阅读
问答
·
一、前言
1.1 Scikit-learn概述
scikit-learn
是基于基于
NumPy
、
SciPy
和
Matplotlib
的开源
Python
机器学习包,具有:
1.
简单高效的数据分析工具
2.
可在多种环境中重复使用
3.
建立在
Numpy
,
Scipy
以及
matplotlib
等数据科学库之上
4.
开源且可商用的
-
基于
BSD
许可
它封装了一系列数据预处理、机器学习算法、模型选择等工具,是数据分析师首选的机器学习工具包。
自
2007
年发布以来,
Scikit-learn
已经成为
Python
重要的机器学习库了,
Scikit-learn
简称
sklearn
,支持包括分类、
回归、降维和聚类四大机器学习算法,还包括了特征提取、数据处理和模型评估三大模块。
sklearn
中文文档:
https://www.sklearncn.cn/ (https://www.sklearncn.cn/)
sklearn
中常用的模块有分类、回归、聚类、降维、模型选择、预处理。
分类:识别某个对象属于哪个类别,常用的算法有:
SVM
(支持向量机)、
nearest neighbors
(最近邻)、
random forest
(随机森林),常见的应用有:垃圾邮件识别、图像识别。
回归:预测与对象相关联的连续值属性,常见的算法有:
SVR
(支持向量机)、
ridge regression
(岭回归)、
Lasso
,常见的应用有:药物反应,预测股价。
聚类:将相似对象自动分组,常用的算法有:
k-Means
、
spectral clustering
、
mean-shift
,常见的应用有:客户细分,分组实验结果。
降维:减少要考虑的随机变量的数量,常见的算法有:
PCA
(主成分分析)、
feature selection
(特征选择)、non-negative matrix factorization(非负矩阵分解),常见的应用有:可视化,提高效率。
模型选择:比较,验证,选择参数和模型,常用的模块有:
grid search
(网格搜索)、
cross validation
(交叉验证)、 metrics
(度量)。它的目标是通过参数调整提高精度。
预处理:特征提取和归一化,常用的模块有:
preprocessing
,
feature extraction
,常见的应用有:把输入数据 (如文本)转换为机器学习算法可用的数据
1.2 使用sklearn建立一个机器学习框架
第一步:导入数据(loadData())
第二步:数据分割与预处理(train_test_split()、processing())
第三步:选择模型(somemodel())
第四步:模型的训练(model.fit(train_x,train_y))
第五步:模型的预测(model.predict(test_x))
第六步:模型的评测(score_function(test_y, predictions))
第七步:模型的保存(joblib.dump(model, 'filename.pkl'))
二、数据采集
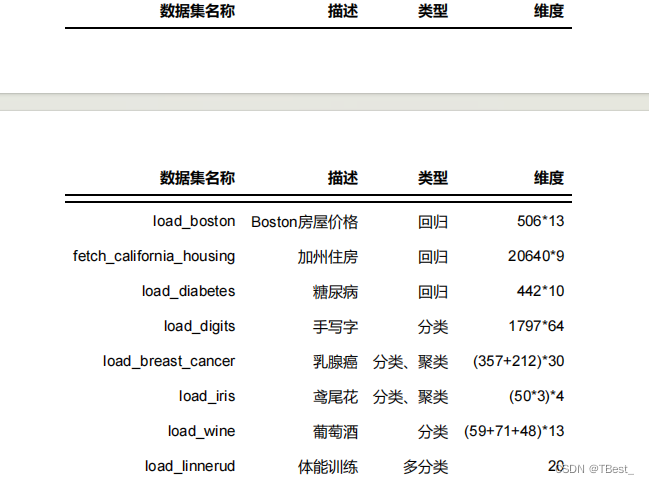
数据集:scikit-learn中自带数据集load_breast_cancer
三、数据处理
3.1 划分数据集
train_test_split
利用sklearn库中的train_test_split来进行划分数据集,其参数有:
# train_data:所要划分的样本特征集
# train_target:所要划分的样本结果
# test_size:样本占比,如果是整数的话就是样本的数量
# random_state:随机数的种子。
四、建模分析
4.1 LogisticRegression()主要参数:
penalty:指定正则化的参数可选为"l1", “l2” 默认为“l2”. 注意:l1正则化会将部分参数压缩到0,而l2正则化不会让 参数取到0只会无线接近
C : 大于0的浮点数。C越小对损失函数的惩罚越重
multi_class : 告知模型要处理的分类问题是二分类还是多分类。 默认为“ovr”(二分类) “multinational”:表示处理多分类问题,在solver="liblinear"时不可用 “auto” : 表示让模型自动判断分类类型
solver:指定求解方式
五、源代码
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import numpy as np
from matplotlib import pyplot as plt
# 加载乳腺癌数据集
breast_cancer = load_breast_cancer()
# 获取X特征向量数据以及y标签向量数据
cancer_x = breast_cancer.data
cancer_y = breast_cancer.target
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(cancer_x,
cancer_y,
test_size=0.3)
# 训练逻辑回归模型
log = LogisticRegression(solver='liblinear')
log.fit(x_train, y_train)
y_predict = log.predict(x_test)
print(f'预测结果:{y_predict}')
print(f"错误数据:{y_predict - y_test}")
print(len(x_train), '\n', len(y_train))
count = 0
L = len(y_test)
print(f'测试集长度:{L}')
for i in range(L):
if log.predict(x_test)[i] != y_test[i]:
count += 1
print(f"出错个数:{count}")
rate = (1 - count / L) * 100
print("错误率:%.2f%%" % rate)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)