
MongoDB常见面试题总结(一)MongoDB面试题及答案
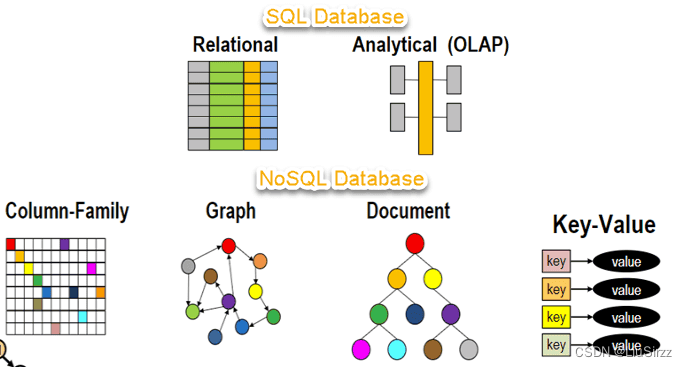
MongoDB是一个开源、面向文档的NoSQL数据库,它采用了BSON(Binary JSON)格式存储数据。数据模型:MongoDB是面向文档的数据库,数据以文档的形式存储,文档是一种类似于JSON的二进制表示形式(BSON)。文档可以包含嵌套的结构和数组。关系型数据库使用表格结构,数据被组织为行和列,遵循固定的表结构,需要事先定义表的结构。Schema(模式):MongoDB是schema-l

1. MongoDB的特点:
你能简要介绍一下MongoDB吗?它与关系型数据库的主要区别是什么?
MongoDB是一个开源、面向文档的NoSQL数据库,它采用了BSON(Binary JSON)格式存储数据。以下是MongoDB与关系型数据库的主要区别:
-
数据模型:
- MongoDB: MongoDB是面向文档的数据库,数据以文档的形式存储,文档是一种类似于JSON的二进制表示形式(BSON)。文档可以包含嵌套的结构和数组。
- 关系型数据库: 关系型数据库使用表格结构,数据被组织为行和列,遵循固定的表结构,需要事先定义表的结构。
-
Schema(模式):
- MongoDB: MongoDB是schema-less的,即不需要提前定义文档的结构,每个文档可以有不同的字段。这使得MongoDB更加灵活,适合处理半结构化或不确定结构的数据。
- 关系型数据库: 关系型数据库需要提前定义表的结构,包括列名、数据类型等,数据必须符合预定义的模式。
-
查询语言:
- MongoDB: MongoDB使用丰富的查询语言,支持丰富的查询表达式和嵌套文档的查询。
- 关系型数据库: SQL是关系型数据库的查询语言,使用表连接等方式进行查询。
-
扩展性:
- MongoDB: MongoDB具有良好的横向扩展性,支持分片(Sharding),可以轻松地扩展存储和处理能力。
- 关系型数据库: 通常采用垂直扩展,通过升级硬件来增加性能,这有一定的限制。
-
事务支持:
- MongoDB: MongoDB在某些版本中引入了事务支持,但在早期版本中是不支持原子事务的。事务支持主要用于处理多文档的操作。
- 关系型数据库: 关系型数据库通常具有原子性、一致性、隔离性和持久性(ACID)的事务支持。
-
复杂性:
- MongoDB: MongoDB相对较简单,尤其适合处理大量文档之间存在嵌套关系的场景,如JSON格式数据。
- 关系型数据库: 关系型数据库具有强大的关联性和复杂的查询功能,适合需要复杂关系和事务的应用。
MongoDB更适用于需要灵活性、快速迭代和半结构化数据的场景,而关系型数据库更适用于具有固定模式、需要严格事务和复杂查询的场景。
MongoDB的数据存储格式是什么?
MongoDB使用BSON(Binary JSON)作为数据的存储格式。BSON是一种类似于JSON的二进制表示形式,它支持一些额外的数据类型,如日期、二进制数据和特定于MongoDB的数据类型。BSON的二进制表示形式使得数据在传输和存储时更为紧凑和高效。
BSON的基本数据类型包括:
- Double: 64位双精度浮点数。
- String: UTF-8字符串。
- Object: 嵌套文档。
- Array: 数组。
- Binary Data: 二进制数据。
- Undefined: 未定义的数据类型(已弃用)。
- ObjectID: 文档的唯一标识。
- Boolean: 布尔类型。
- Date: 日期类型。
- Null: 空值。
- Regular Expression: 正则表达式。
- JavaScript Code: JavaScript代码。
- Symbol: 符号(已弃用)。
- JavaScript Code with Scope: 包含作用域的JavaScript代码。
- 32-bit Integer: 32位整数。
- Timestamp: 时间戳。
- 64-bit Integer: 64位整数。
- Decimal128: 128位十进制浮点数(从MongoDB 3.4版本开始支持)。
- Min Key: 最小键值。
- Max Key: 最大键值。
BSON的灵活性和二进制格式的特性使得MongoDB能够高效地存储和检索各种类型的数据。
2. 数据建模和Schema设计:
什么是文档(Document)?MongoDB的文档是如何组织的?
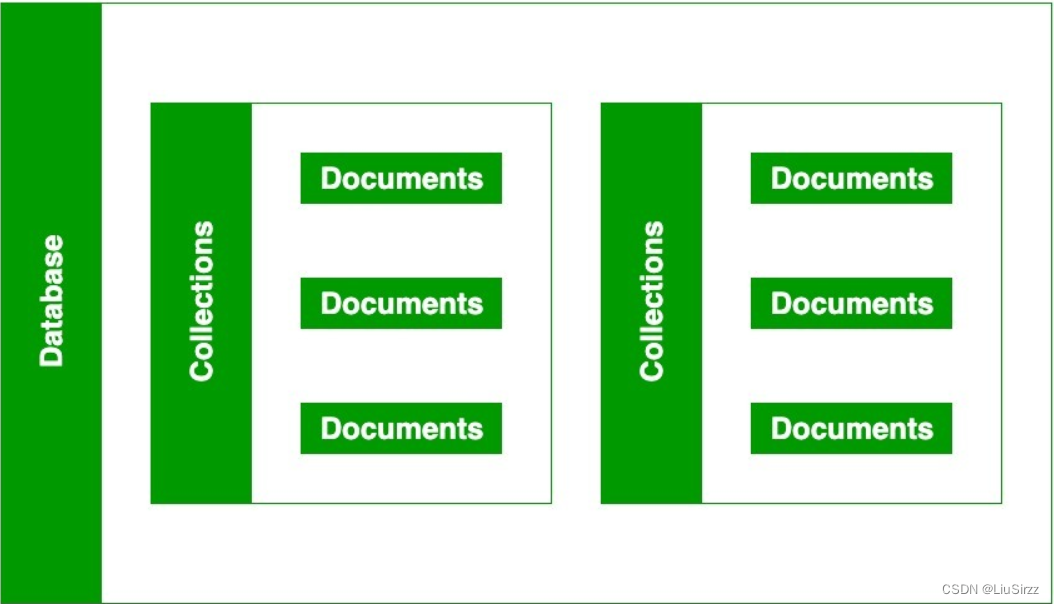
在MongoDB中,文档(Document)是数据的基本单元,它相当于关系数据库中的行。一个文档是一个由键值对组成的数据结构,它使用了 BSON(Binary JSON)格式进行存储。文档是MongoDB中数据的原子单位,可以包含多种类型的数据,包括嵌套文档和数组。
MongoDB的文档组织方式如下:
-
键值对结构: 文档由一个或多个键值对组成,每个键值对包含一个字段名和相应的值。字段名是字符串,而值可以是各种数据类型,包括其他文档、嵌套数组等。
-
嵌套结构: 文档可以包含嵌套的文档,形成层级结构。这使得MongoDB支持复杂的数据模型,可以更好地反映应用程序的数据关系。
-
动态模式: MongoDB是一个无模式(schema-less)的数据库,允许不同文档拥有不同的字段。这意味着同一集合中的文档可以有不同的结构,而不需要提前定义表结构。
示例MongoDB文档:
{
"_id": ObjectId("5f5f5e285f3d1a431f6f8b9b"),
"name": "John Doe",
"age": 30,
"address": {
"street": "123 Main St",
"city": "Cityville",
"zip": "12345"
},
"hobbies": ["reading", "traveling", "photography"]
}
在上面的示例中,_id是文档的唯一标识,name、age、address和hobbies都是文档中的字段,其中address是一个嵌套的文档,而hobbies是一个包含多个元素的数组。这种灵活的文档结构使得MongoDB适用于各种数据模型。
如何在MongoDB中设计Schema?有没有固定的Schema?
MongoDB是一个无模式(schema-less)的数据库,这意味着与传统的关系型数据库不同,MongoDB不要求在插入文档之前定义固定的模式(Schema)。文档在同一集合中可以有不同的字段,这使得MongoDB更加灵活,适应了不断变化的数据结构。
在MongoDB中,设计Schema通常涉及以下几个方面:
-
灵活性: MongoDB允许文档在同一集合中具有不同的字段,因此可以更灵活地适应不同数据模型和需求。
-
索引: 尽管MongoDB是一个无模式的数据库,但仍可以创建索引以提高查询性能。索引通常针对经常查询的字段,通过提供高效的查找和排序来加速查询。
-
嵌套文档和数组: 利用MongoDB的嵌套文档和数组功能,可以在一个文档中表示复杂的数据结构,避免使用多个表和外键的关系模型。
-
字段命名规范: 为了保持一致性和可读性,可以定义一些字段命名规范,使得字段在文档中有清晰的含义。
尽管MongoDB提供了灵活性,但在实际应用中,为了方便查询和维护,仍然建议在设计时考虑某种结构。合理的设计可以提高查询性能,减少冗余数据,并更好地支持应用程序的需求。例如,可以根据应用程序的查询模式和频率,选择将某些字段嵌套在文档中,或者创建索引以支持特定的查询。
MongoDB支持多少级嵌套文档?如何处理复杂的数据结构?
MongoDB支持多级嵌套文档,可以在文档中嵌套其他文档,形成复杂的数据结构。这样的嵌套文档可以包含字段、嵌套文档或数组。
在MongoDB中,处理复杂的数据结构有几个方面的考虑:
-
嵌套文档: 可以在文档中嵌套其他文档,形成层级结构。例如,一个文档可以包含一个字段,该字段的值是另一个文档。
{ "_id": 1, "name": "John Doe", "address": { "city": "New York", "zip": "10001" } } -
嵌套数组: 可以在文档中嵌套数组,允许表示一对多的关系。例如,一个文档可以包含一个字段,该字段的值是一个包含多个元素的数组。
{ "_id": 2, "name": "Jane Doe", "hobbies": ["reading", "traveling", "photography"] } -
多级嵌套: 可以将嵌套文档和数组结合使用,形成多级嵌套的数据结构。
{ "_id": 3, "title": "Book", "authors": [ { "name": "Author 1", "affiliation": { "organization": "University A", "department": "Computer Science" } }, { "name": "Author 2", "affiliation": { "organization": "University B", "department": "Physics" } } ] }
处理复杂的数据结构时,应根据应用程序的查询需求和数据访问模式选择适当的结构。嵌套结构的使用可以提高查询性能和降低数据冗余,但也需要根据具体情况权衡灵活性和维护成本。
3. 查询语言和操作:
如何在MongoDB中执行查询?可以提到一些基本的查询操作。
在MongoDB中,查询操作是通过使用find方法进行的,这是一个非常灵活且功能强大的查询工具。以下是一些基本的MongoDB查询操作:
-
查找所有文档: 使用
find方法,不带参数,将返回集合中的所有文档。db.collectionName.find() -
指定查询条件: 可以使用
find方法的参数指定查询条件,以筛选满足条件的文档。db.collectionName.find({ key: value }) -
投影: 使用
find方法的第二个参数指定投影,以选择要返回的字段。db.collectionName.find({}, { field1: 1, field2: 1, _id: 0 }) -
条件操作符: 使用条件操作符,如
$eq、$ne、$gt、$lt等,进行更复杂的条件查询。db.collectionName.find({ field: { $gt: value } }) -
逻辑操作符: 使用逻辑操作符,如
$and、$or、$not,结合多个条件进行查询。db.collectionName.find({ $or: [{ key1: value1 }, { key2: value2 }] }) -
正则表达式: 使用正则表达式进行模糊匹配。
db.collectionName.find({ field: /pattern/ }) -
排序: 使用
sort方法对结果进行排序。db.collectionName.find().sort({ field: 1 }) // 升序 -
限制返回结果数量: 使用
limit方法限制返回结果的数量。db.collectionName.find().limit(10)
这些是MongoDB中一些常见的基本查询操作,但还有更多高级功能,如索引的使用、聚合管道等,可根据具体需求选择合适的查询方式。
什么是索引,为什么在MongoDB中使用索引很重要?
在MongoDB中,查询操作是通过使用find方法进行的,这是一个非常灵活且功能强大的查询工具。以下是一些基本的MongoDB查询操作:
-
查找所有文档: 使用
find方法,不带参数,将返回集合中的所有文档。db.collectionName.find() -
指定查询条件: 可以使用
find方法的参数指定查询条件,以筛选满足条件的文档。db.collectionName.find({ key: value }) -
投影: 使用
find方法的第二个参数指定投影,以选择要返回的字段。db.collectionName.find({}, { field1: 1, field2: 1, _id: 0 }) -
条件操作符: 使用条件操作符,如
$eq、$ne、$gt、$lt等,进行更复杂的条件查询。db.collectionName.find({ field: { $gt: value } }) -
逻辑操作符: 使用逻辑操作符,如
$and、$or、$not,结合多个条件进行查询。db.collectionName.find({ $or: [{ key1: value1 }, { key2: value2 }] }) -
正则表达式: 使用正则表达式进行模糊匹配。
db.collectionName.find({ field: /pattern/ }) -
排序: 使用
sort方法对结果进行排序。db.collectionName.find().sort({ field: 1 }) // 升序 -
限制返回结果数量: 使用
limit方法限制返回结果的数量。db.collectionName.find().limit(10)
这些是MongoDB中一些常见的基本查询操作,但还有更多高级功能,如索引的使用、聚合管道等,可根据具体需求选择合适的查询方式。
MongoDB中的聚合框架是用来做什么的?
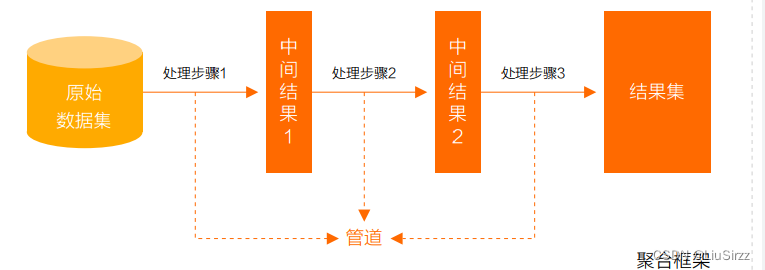
MongoDB中的聚合框架是用于进行数据聚合和转换的工具,通过构建管道操作链,可以对文档进行多个阶段的处理。聚合框架的主要目的是在数据库中执行复杂的数据处理操作,类似于关系型数据库中的SQL聚合函数。
聚合框架提供了一组强大的操作符和阶段,使用户能够以灵活的方式处理数据。一般而言,聚合框架用于以下一些常见的任务:
-
数据过滤和筛选: 可以使用
$match阶段来选择符合特定条件的文档。db.collection.aggregate([ { $match: { field: value } } ]) -
数据转换和投影: 使用
$project阶段对文档进行投影,选择要返回的字段,并可以进行计算和重命名。db.collection.aggregate([ { $project: { newField: "$existingField", _id: 0 } } ]) -
分组和统计: 使用
$group阶段进行分组,可以进行统计操作,如计数、求和、平均值等。db.collection.aggregate([ { $group: { _id: "$field", count: { $sum: 1 } } } ]) -
排序: 使用
$sort阶段对结果进行排序。db.collection.aggregate([ { $sort: { field: 1 } } ]) -
限制结果数量: 使用
$limit阶段限制返回结果的数量。db.collection.aggregate([ { $limit: 10 } ]) -
联接操作: 虽然MongoDB不支持传统的SQL联接操作,但通过聚合框架可以模拟一些联接操作,如
$lookup。db.orders.aggregate([ { $lookup: { from: "products", localField: "productId", foreignField: "_id", as: "product" } } ])
聚合框架允许将多个阶段组合在一起,形成一个处理管道。这种灵活性使得MongoDB可以应对各种复杂的数据处理需求。
4. 性能优化和查询优化:
如何优化MongoDB查询性能?可以考虑索引、合理的查询语句等。
优化MongoDB查询性能涉及多个方面,包括索引的使用、合理的查询语句设计、适当的配置等。以下是一些优化MongoDB查询性能的建议:
-
创建索引: 索引是MongoDB中提高查询性能的关键。根据查询的字段和排序需求创建合适的索引。使用
db.collection.createIndex()方法创建索引。常见的索引类型包括单字段索引、复合索引、文本索引等。db.collection.createIndex({ fieldName: 1 }) -
避免全表扫描: 尽量避免执行全表扫描,确保查询条件中的字段有索引。全表扫描对性能有较大影响,特别是在数据量较大时。
-
合理使用投影: 在查询时使用投影操作符
$project,只返回需要的字段,减少数据传输的开销。db.collection.find({ /* 查询条件 */ }, { fieldName: 1, _id: 0 }) -
使用合适的数据类型: 使用适当的数据类型能够减小数据存储的空间占用,并提高查询性能。例如,使用整数而不是字符串存储数字。
-
分页查询: 对于大数据集的查询,使用
limit()和skip()进行分页查询,而不是一次性返回所有结果。db.collection.find({ /* 查询条件 */ }).skip(10).limit(10) -
避免使用
$where: 避免使用$where,因为它会导致全表扫描,影响性能。db.collection.find({ $where: "this.fieldName > 100" }) -
使用合适的查询运算符: 根据具体查询条件选择合适的查询运算符,例如
$eq、$gt、$lt等。db.collection.find({ fieldName: { $gt: 100 } }) -
利用复制集和分片: 在大规模部署中,使用复制集提高可用性,使用分片实现水平扩展。
-
监控和调优: 使用MongoDB提供的工具和驱动程序的性能分析功能,如
explain()方法,定期监控查询性能并调整索引和查询语句。
以上建议是通用性的,具体优化策略还需根据应用的实际情况进行调整。在实施任何优化之前,最好先了解应用的查询模式、数据分布等信息。
什么是覆盖索引?为什么它对性能有影响?
覆盖索引是指索引本身包含了查询所需的所有字段,而不需要通过回表(即查询主键)来获取额外的数据。当一个查询可以仅通过索引就能满足所有需要的字段时,就称之为覆盖索引。覆盖索引对性能有积极的影响,原因如下:
-
减少IO操作: 覆盖索引能够减少IO操作,因为不需要去访问实际的数据行。索引通常存储在内存中,而实际的数据行可能需要从磁盘读取。通过只读取索引,可以减少对磁盘的IO操作,提高查询速度。
-
减少网络传输: 如果查询的数据可以完全由索引提供,那么在查询的过程中需要传输的数据量会减少。这对于分布式系统中的网络开销尤为重要。
-
减少CPU开销: 数据库系统在查询时需要进行解析和处理数据,覆盖索引减少了这些处理的工作量,从而减少了CPU的开销。
-
提高查询性能: 由于覆盖索引能够减少IO操作、网络传输和CPU开销,整体上提高了查询性能。特别是对于频繁执行的查询,性能的提升尤为显著。
覆盖索引的效果在于最大限度地减少了从存储引擎中检索数据所需的工作,将所需的数据都存储在索引中。这使得覆盖索引成为优化查询性能的一种重要手段。在设计数据库索引时,考虑覆盖索引对于提升查询性能的影响是一个常用的优化策略。
如何进行分页查询?
在进行分页查询时,可以使用MongoDB提供的limit和skip方法。下面是一个基本的分页查询的示例:
# 假设我们有一个集合名为 "exampleCollection"
# 分页参数,假设每页大小为pageSize,请求第pageNum页
pageSize = 10
pageNum = 1
# 计算跳过的文档数量
skip = (pageNum - 1) * pageSize
# 执行分页查询
result = db.exampleCollection.find().skip(skip).limit(pageSize)
# 遍历查询结果
for document in result:
print(document)
这里的skip用于跳过前面的文档,而limit用于限制返回的文档数量,从而实现分页查询的效果。需要注意的是,skip的性能在大数据集上可能会较低,因为它需要在跳过指定数量的文档后才能返回结果。
在实际应用中,还需要考虑使用合适的索引来优化分页查询的性能,以及处理分页总数等其他分页相关的信息。

关注公众号 洪都新府笑颜社,发送 “面试题” 即可免费领取一份超全的面试题PDF文件!!!!


瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)