
Open Metadata数据治理框架基本使用(v1.3.0 Release)
最近工作中要用到数据治理中元数据管理的部分,所以调研了下Open Metadata框架,由于相关中文文档较少,所以翻看了官网的主要功能介绍并做了实践,在此记录并分享给有需要的人。
目录
授权规则(Rules)、策略(Policies)和角色(Roles)... 38
示例1:我们希望我们的团队能够创建服务并提取元数据... 52
示例4:如果数据资产标记名为PII.Sensitive的标签,则拒绝所有访问,只允许所有者访问 54
如何使用基本认证(Basic Auth)从CLI运行摄入管道... 54
通过Open Metadata本机文档Swagger进行API调用测试... 61
【说明】:最近工作中要用到数据治理中元数据管理的部分,所以调研了下Open Metadata框架,由于相关中文文档较少,所以翻看了官网的主要功能介绍并做了实践,在此记录并分享给有需要的人。
OpenMetadata 包括内容
元数据模式 - 定义元数据的核心抽象和词汇表,其中包含类型、实体、实体之间的关系的模式。这是开放元数据标准的基础。
元数据存储 - 存储连接数据资产、用户和工具生成的元数据的元数据图。
元数据 API - 用于生成和使用基于用户界面和工具、系统和服务集成模式构建的元数据。
摄取框架 - 用于集成工具并将元数据摄取到元数据存储的可插拔框架。摄取框架已经支持众所周知的数据仓库 - Google BigQuery、Snowflake、Amazon Redshift 和 Apache Hive,以及数据库 - MySQL、Postgres、Oracle 和 MSSQL。
OpenMetadata 用户界面 - 一个供用户发现和协作处理所有数据的地方。
OpenMetadata如何帮助数据团队?
OpenMetadata是一个完整的包,用于数据团队分解团队竖井,安全地共享来自多个来源的数据资产,围绕数据进行协作,并在组织中建立文档至上的数据文化。
-所有元数据为集中式、单一可信的来源。
-及时发现合适的资产并减少依赖关系。
-通过实时对话、任务、公告和警报促进团队协作。
-通过数据质量测试建立对数据的信任,以确保数据的完整性和准确性。
-使用端到端数据系列跟踪您的数据演变。
-通过定义角色和策略来确保对敏感数据的安全访问。
-加强组织数据文化,以获得推动创新的关键见解。
-定义术语表,以便在组织内建立对术语的共同理解。
-实施数据治理以维护数据的完整性、安全性和合规性。
Open Metadata安装
-参考文档:OpenMetadata Documentation: Get Help Instantly
-Open Metadata版本:1.3.0 Release
-安装环境要求:
Docker (version 20.10.0 or greater)
Docker Compose (version v2.1.1 or greater)
MySQL5.7+
必须为Docker分配至少6 GiB的内存和4个vCPU才能运行OpenMetadata。
-安装步骤:
1.为Open Metadata创建一个目录:
cd /home
mkdir openmetadata-docker && cd openmetadata-docker
2.获取Docker Compose File文件:
curl -sL -o docker-compose.yml https://github.com/open-metadata/OpenMetadata/releases/download/1.3.1-release/docker-compose.yml
(其实也可直接用我下载好的docker-compose.yml文件)
3.启动Docker Compose服务:
cd /home/openmetadata-docker
docker compose -f docker-compose.yml up --detach
Open Metadata启动及访问
启动命令和上一节提到的启动Docker Compose服务一样:
cd /home/openmetadata-docker
docker compose -f docker-compose.yml up --detach
注意:
a.启动时不能关闭Linux防火墙哦,要不执行上面命令会报错的。
b.虚拟机内存最少分配个6G,CPU分配4核才能够用。
c.上面的命令启动后,正常是应该启动成功4个容器来的,如果个别容器没有启动成功,则可用下面的命令手动启动:
(8080端口)
docker start openmetadata_ingestion
(8585端口)
docker start openmetadata_server
(9200端口)
docker start openmetadata_elasticsearch
(3306端口)
docker start openmetadata_mysql
PS:其实不用挨个执行上面的命令,如果发现有未启动起来的容器,则直接再执行一次docker compose -f docker-compose.yml up –detach命令即可。
d.MySQL连接问题:
默认用户名:root
默认密码:password
在默认安装的情况下,该MySQL容器虽然对外提供了3306端口,但root用户通过navcat并不能远程连接上,需要做以下设置:
use mysql;
select host,user from user;
update user set host='%' where user='root';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
flush privileges;
-【停止docker compose服务和清理命名卷】:
docker compose down --volumes
-【访问地址】:
-----------------------------(访问OpenMetadata)
-访问地址:
http://192.168.70.128:8585
-管理员用户:
admin
admin
-普通用户:(部署启动后,可以在OpenMetadata中手动添加用户的^_^)
-默认角色:
Data Consumer:数据使用者
Data Steward:数据管理者
Application bot role:应用程序机器人角色
Data quality Bot role:数据质量Bot角色
lngestion bot role:管理机器人角色
Profiler bot role:探查器机器人角色
Quality bot role:质量机器人角色
-团队类型:
BusinessUnit:业务部门
Division:部门
Department:子部门
Group:组
-----------------------------(访问Open Metadata Api 文档)
-访问地址:
http://192.168.70.128:8585/swagger.html
(PS:上面地址是我本机虚拟机部署时的IP和端口,大家可以替换为自己的部署的IP和端口)
-----------------------------(访问Airflow)
-访问地址:
http://192.168.70.128:8080
(PS:上面地址是我本机虚拟机部署时的IP和端口,大家可以替换为自己的部署的IP和端口)
-管理员用户:
Username: admin
Password: admin
Open Metadata首页介绍
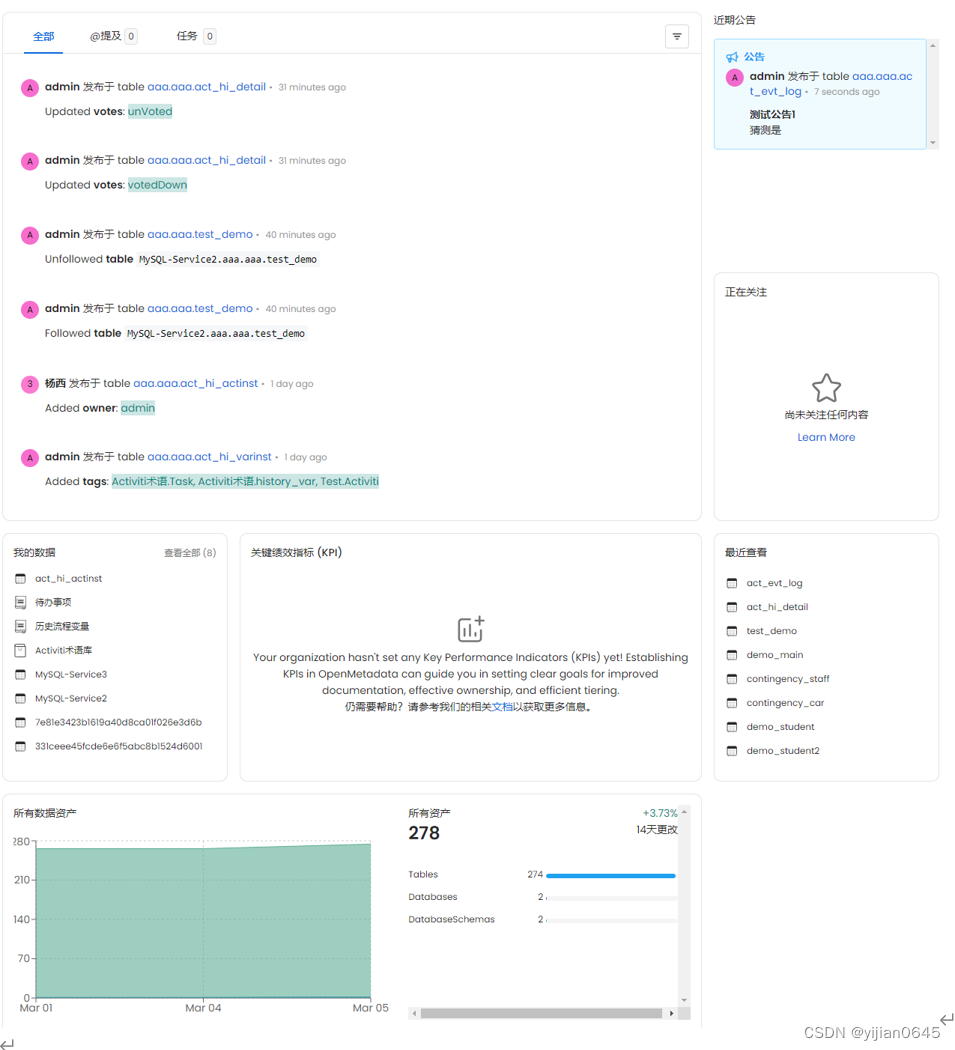
-全部:与您拥有、关注或提及您的数据资产相关的所有活动。
-@提及:提及您的提要。
-任务:显示由您创建或分配给您的任务。此处仅显示“Open”状态的任务。
-我的数据:将显示您拥有的所有数据资产。如果您或您的团队没有任何数据资产,您可以从“探索”页面开始申请这些资产。
-关键绩效指标(KPI):提供了有关数据资产所有权覆盖范围、描述覆盖范围和分层的信息。
-所有数据资产&所有资产:显示过去14天内总数据资产的趋势。它显示统计表、仪表板、数据库、数据库架构、管道、主题、MLModels、图表等。
-近期公告:查看有关您拥有或关注的数据资产的所有最新公告。此公告将在计划的时间内显示在OpenMetadata中。它将显示给拥有或关注该特定数据资产的所有用户。
-正在关注:查看您正在关注的所有数据资产。
-最近查看:显示最近查看的所有数据资产。
Open Metadata基本使用
OpenMetadata为您提供了使用CLI或UI从第三方来源引入数据的灵活性。让我们从通过UI从各种来源获取元数据开始。
-参考文档:OpenMetadata Documentation: Get Help Instantly
添加一个连接器(指定从哪里抽取元数据)
-进入“设置”-》“服务”:
可以看到Open Metadata有很多支持的连接器类型。
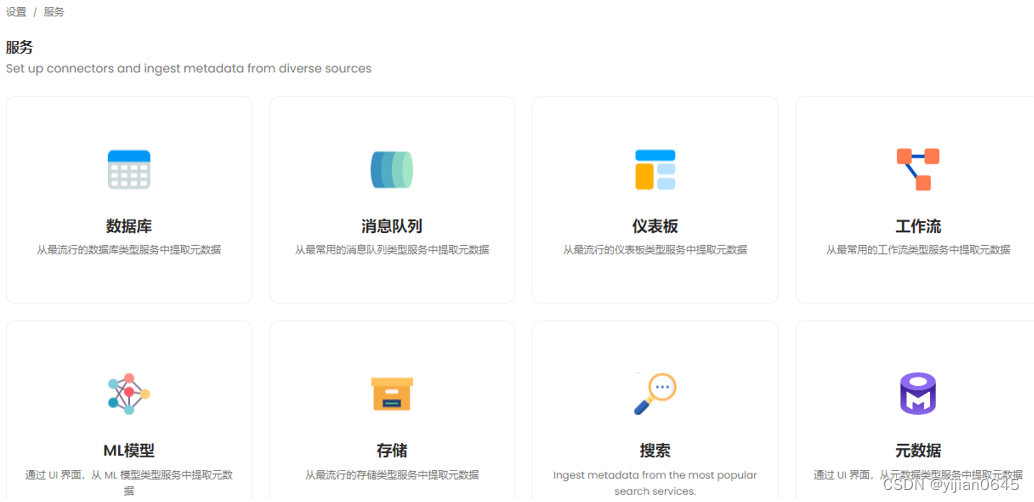
-以数据库连接为例,选择“数据库”,并添加连接器:

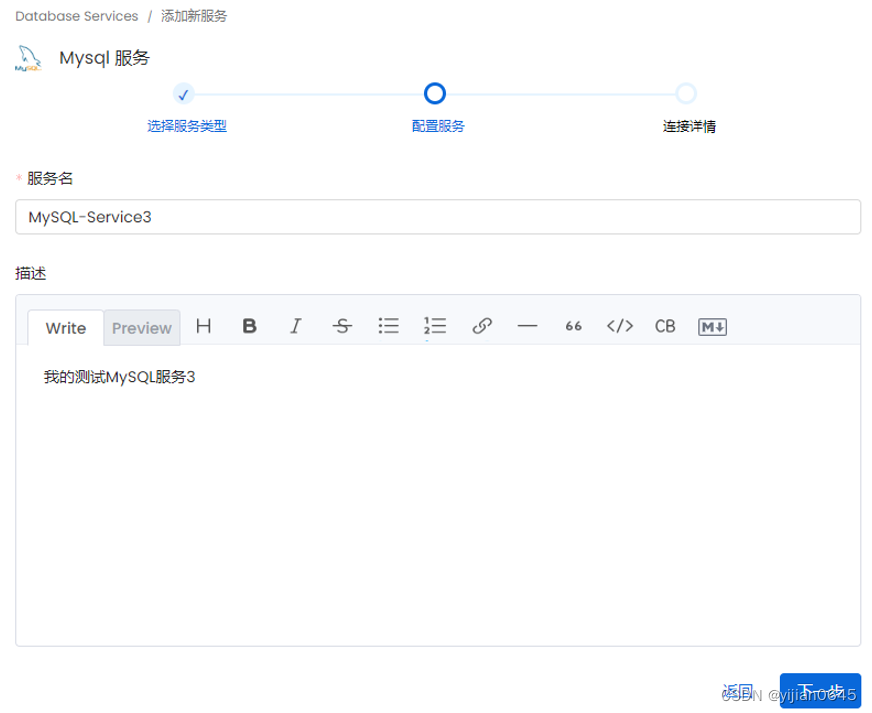
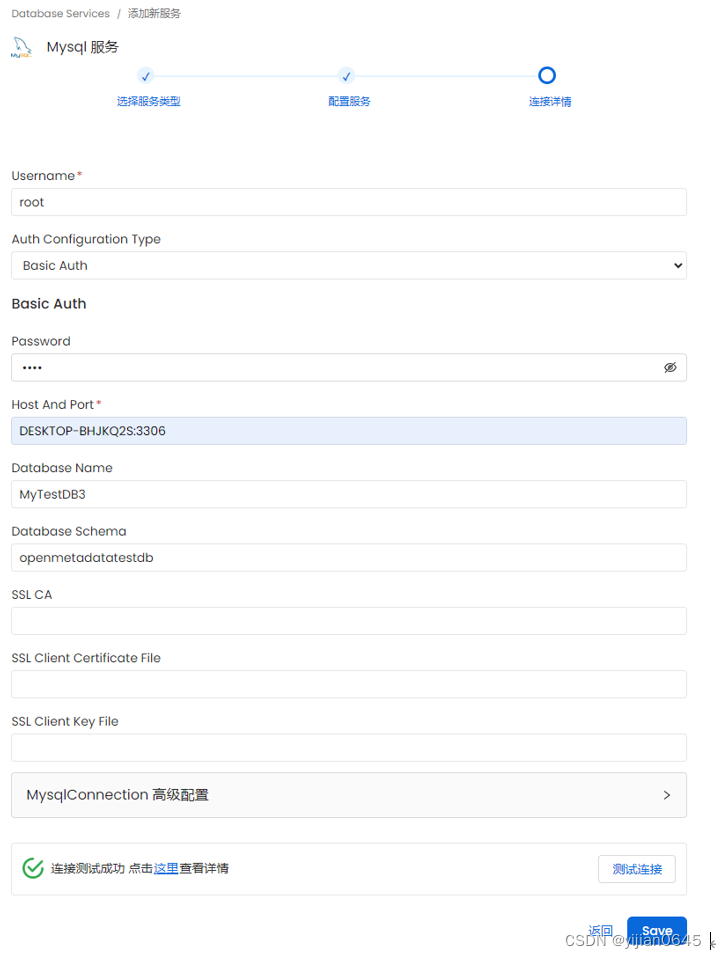
完成后,可点击“查看服务”或直接“添加提取”。
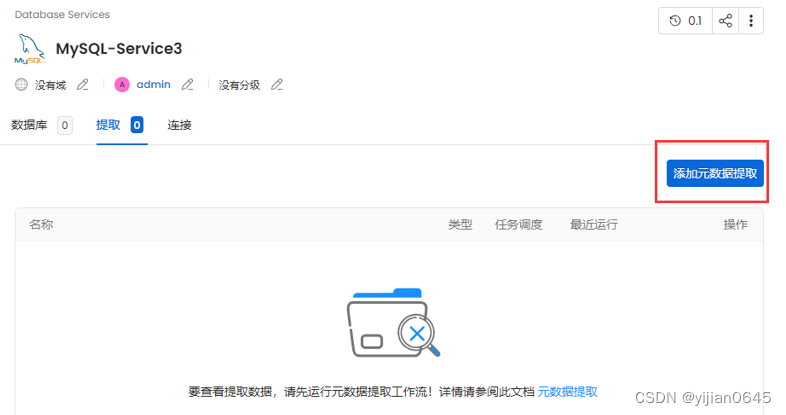
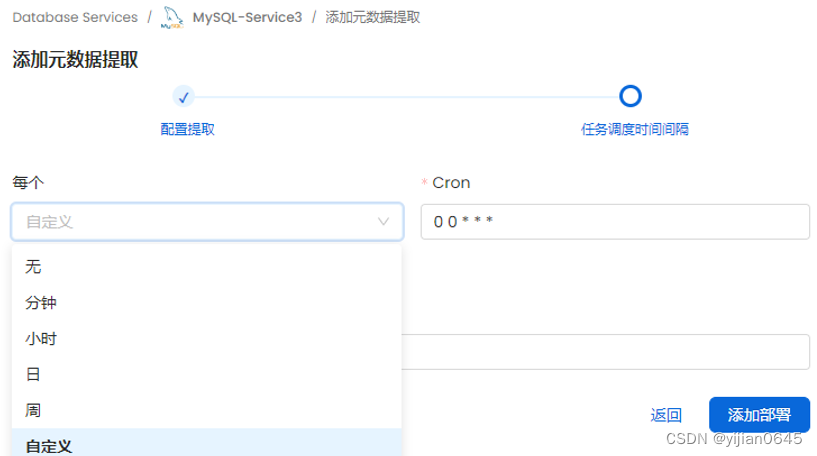
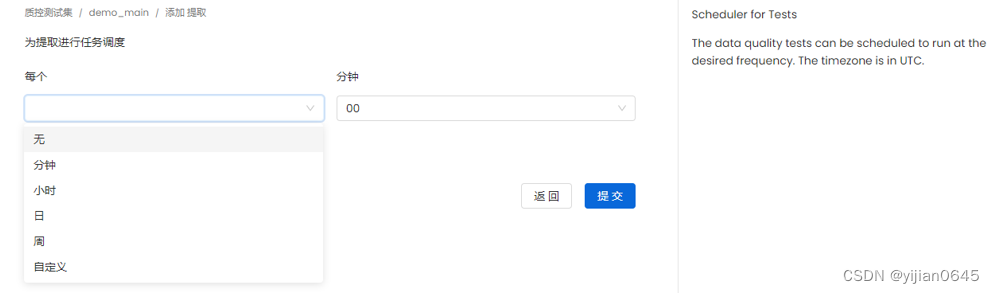
添加元数据提取(以所需的频率定期获取元数据)
添加元数据提取
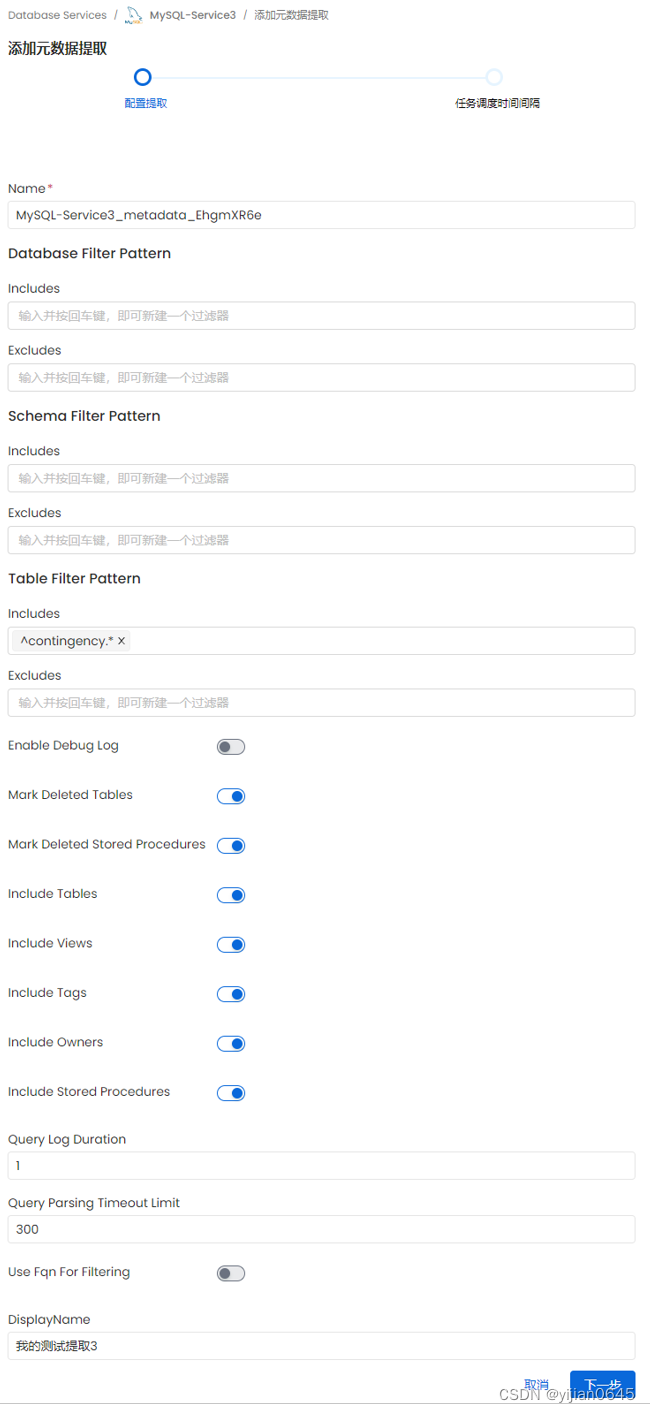
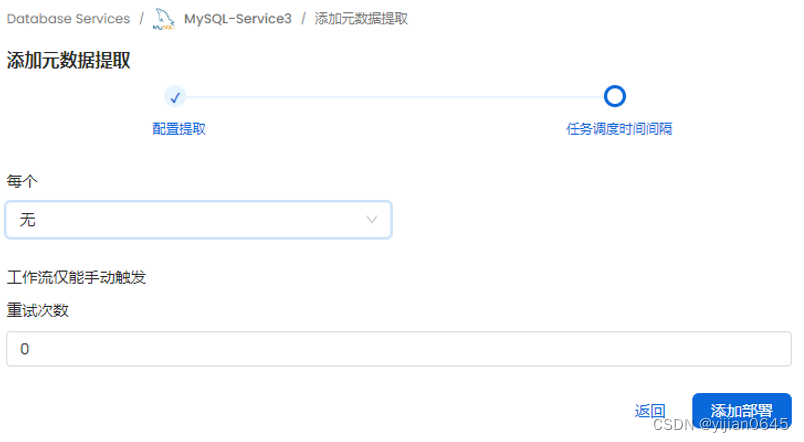
下面这步可以按需求自定义抽取元数据的频率,选“无”表示只能手动触发:
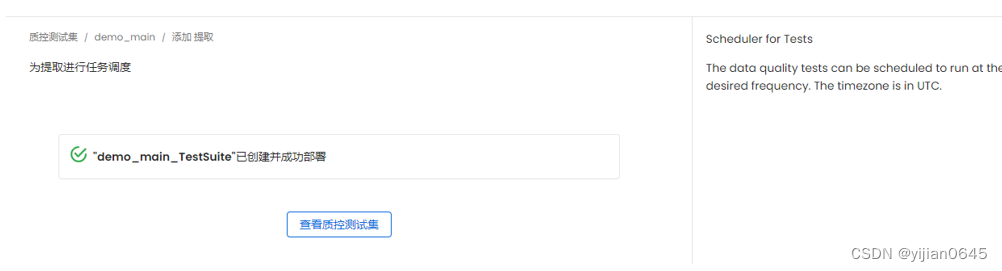
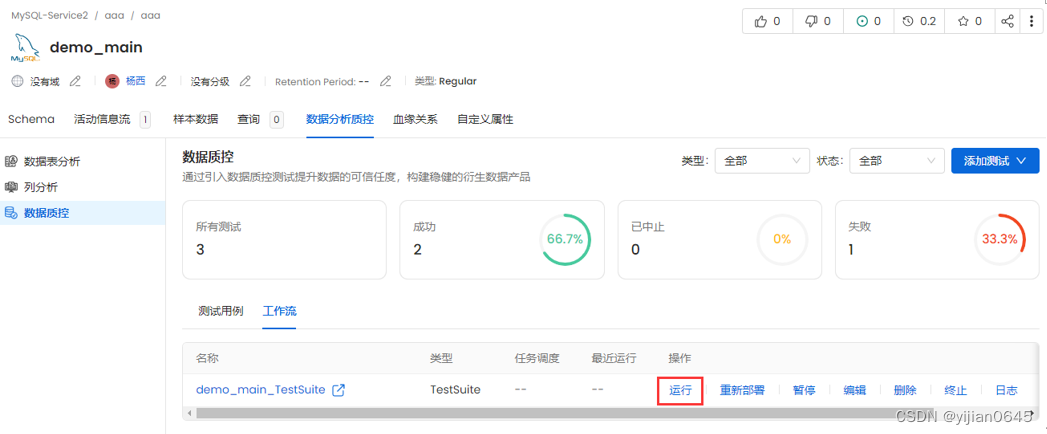
执行元数据提取
点击右侧的“运行”按钮,可手动进行元数据的提取:

抽取结果如下:
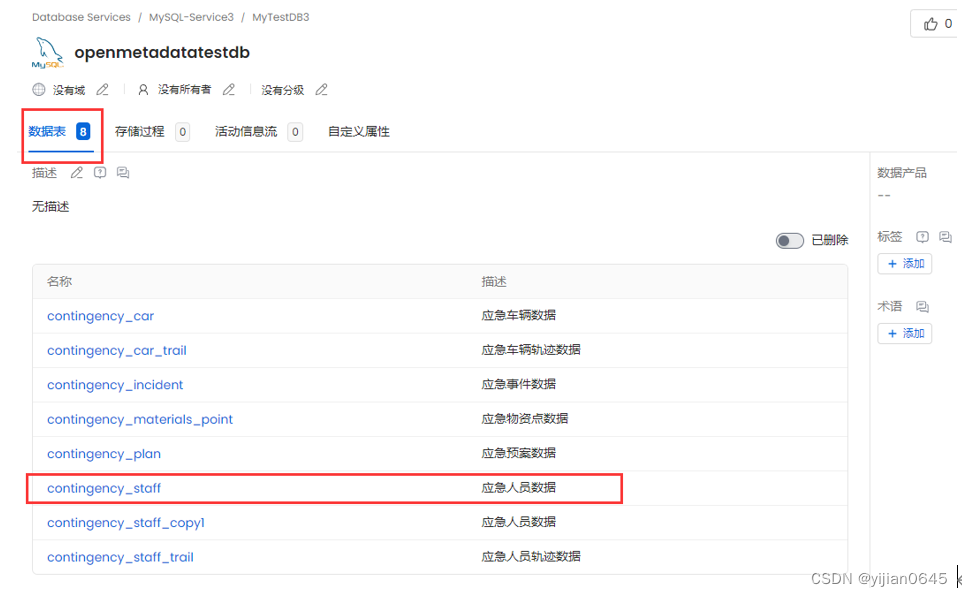
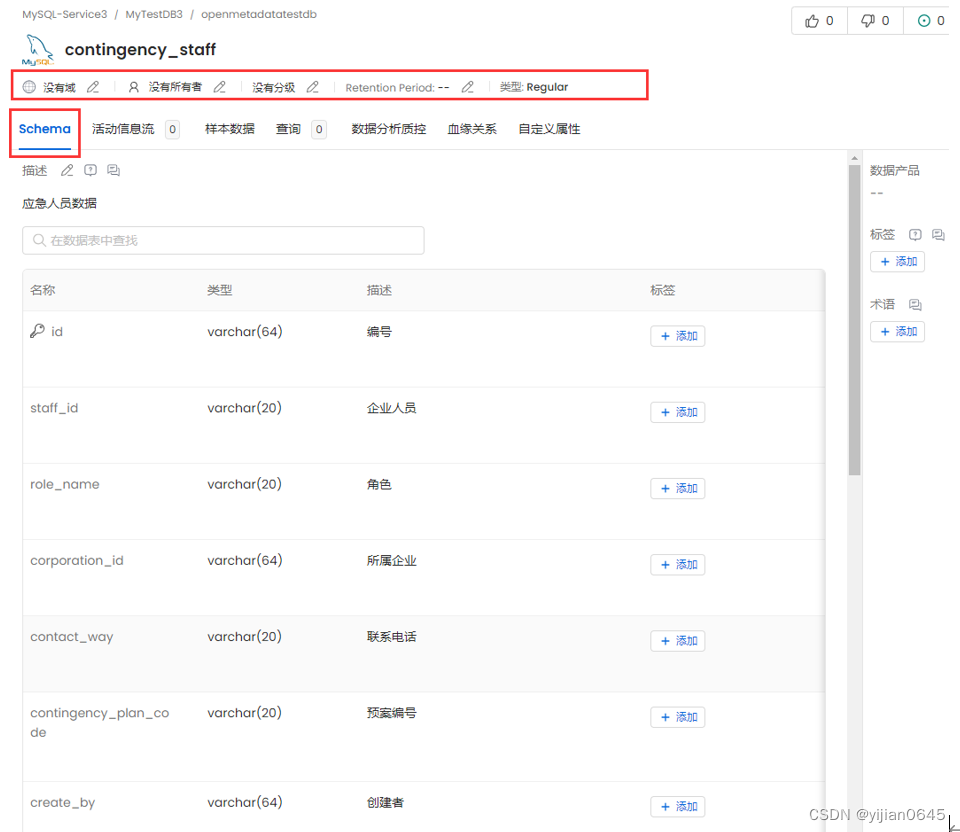
血缘分析
在元数据详情页面,可点击“血缘关系”页签,来维护血缘之间的关系:
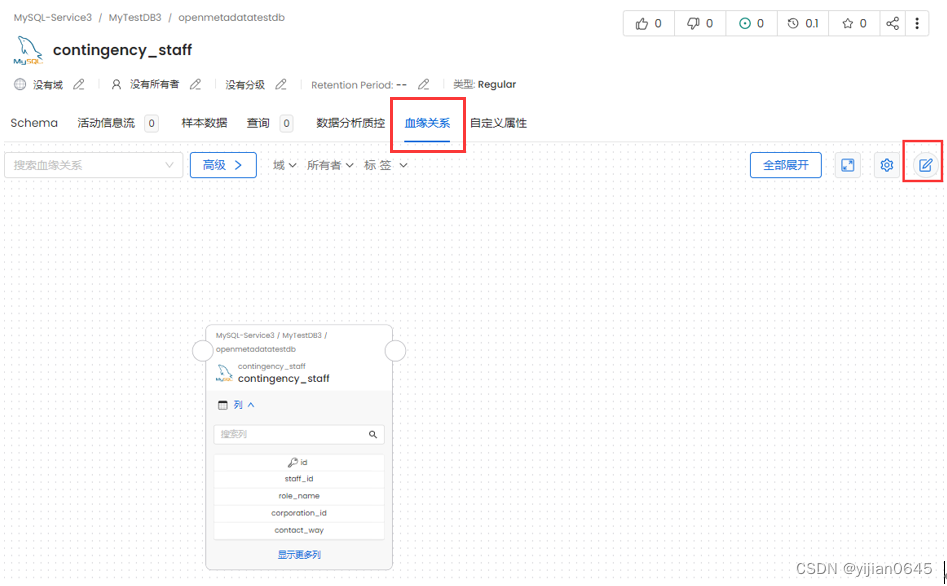
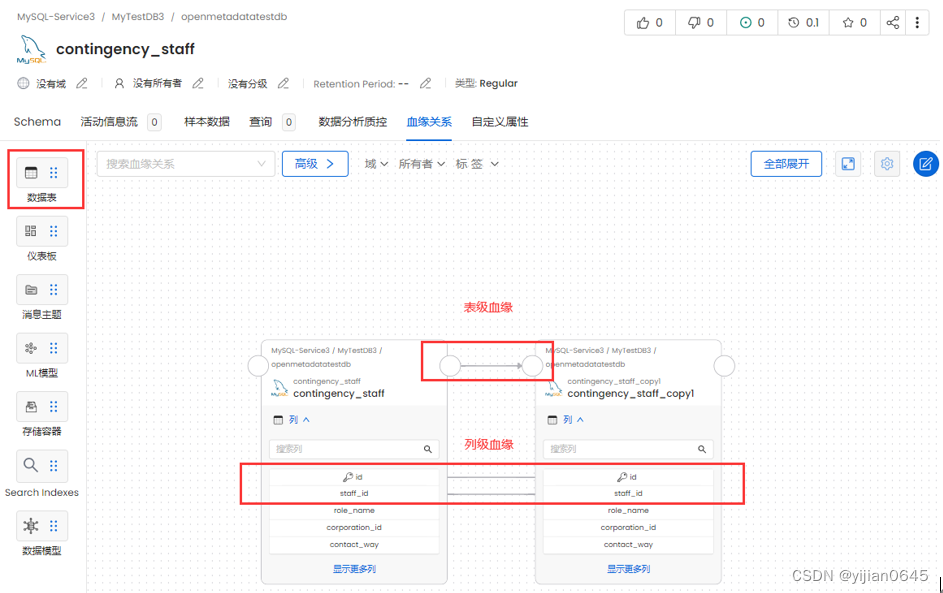
数据质量控制
参考:
OpenMetadata Documentation: Get Help Instantly
https://docs.open-metadata.org/v1.3.x/connectors/ingestion/workflows/profiler
添加分析器提取
数据探查器有助于捕获一段时间内的表使用情况统计信息。
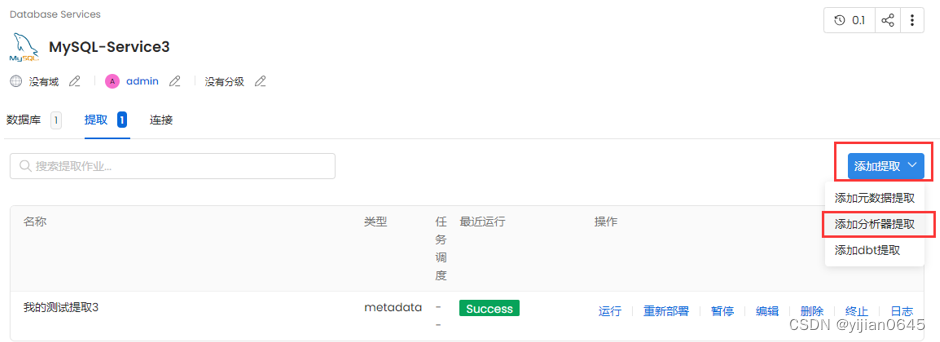
下图的添加分析器提取页面中,可设置根据Database、Schema、Table过滤模式,比如下面的按照Table明过滤(包含以contingency开头的表):
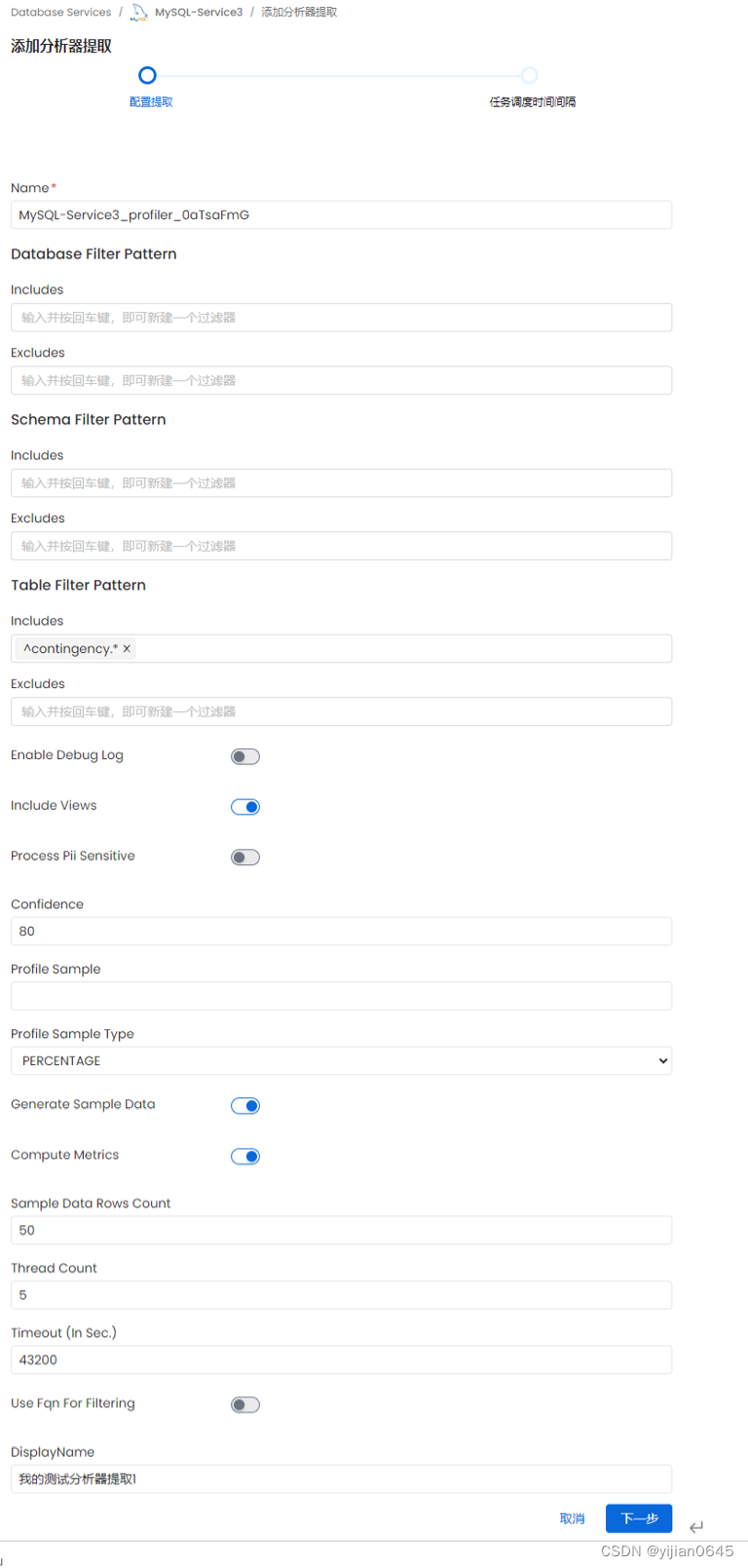
设置任务调度时间间隔,设置“无”表示手动执行:
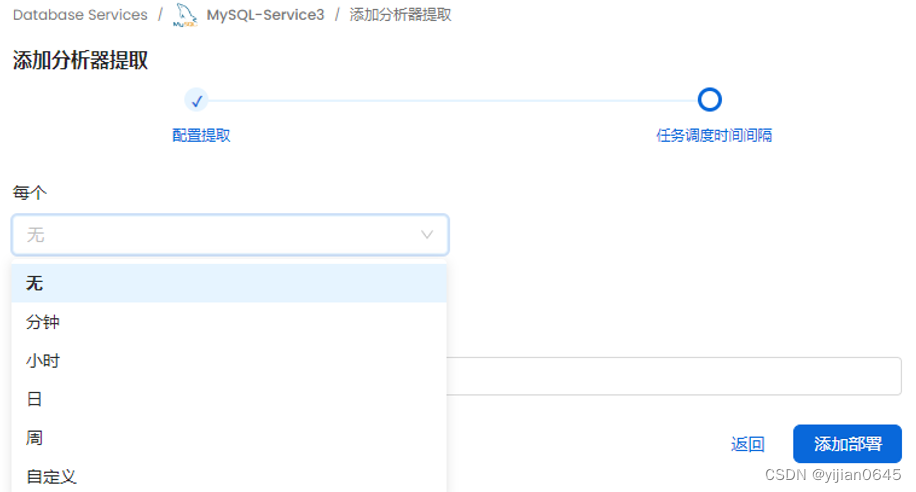
执行分析器提取
点击右侧的“运行”按钮,可手动进行分析器的提取:
注意:分析器的运行会执行了WITH … AS … 语法的SQL,如果用了MySQL5.7,则导致会报以下语法错误的异常:
Skipping metrics for contingency_car_trail.update_by due to (pymysql.err.ProgrammingError) (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'contingency_car_trail_rnd AS \n(SELECT openmetadatatestdb.contingency_car_trail.u' at line 2")
用MySQL8就支持WITH…AS…语法了。
添加测试用例
可添加对数据表和列的测试用例。
数据表测试
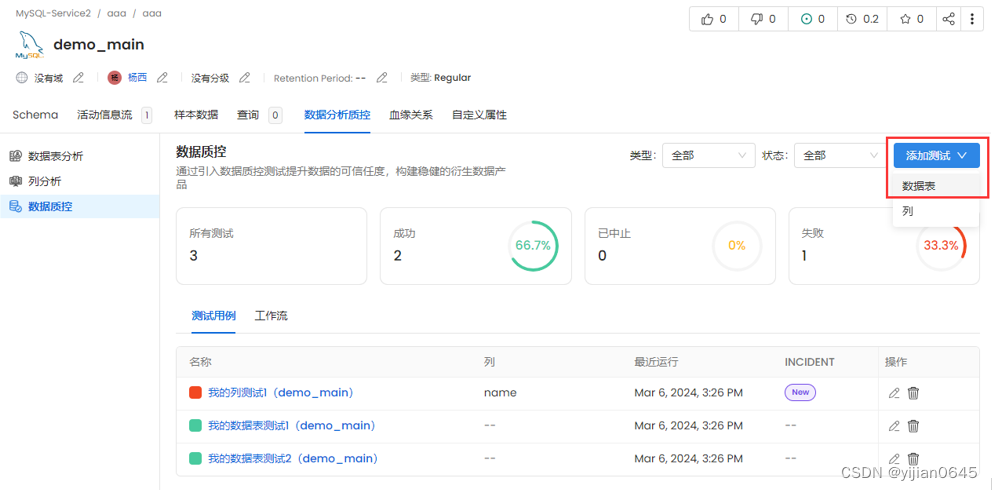
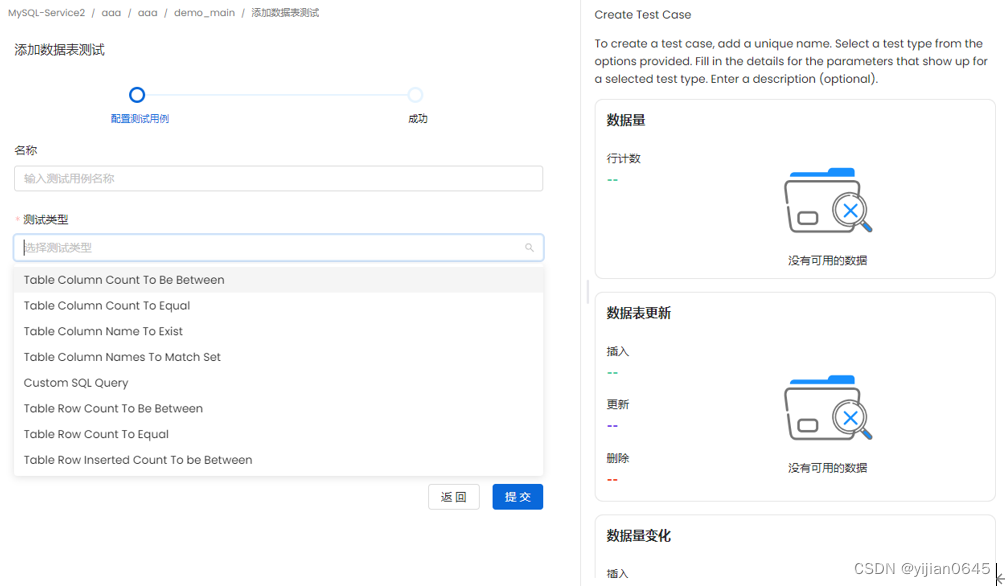
-要创建表级测试,请输入以下详细信息:
名称:添加一个最能定义测试用例的名称。
测试类型:根据测试类型,您将有更多的字段来定义测试。
描述:描述测试用例。单击“提交”以设置测试。
-OpenMetadata当前支持以下表级测试类型:
1-表列计数介于之间(Table Column Count to be Between):定义最小值和最大值。
2-表列计数等于(Table Column Count to Equal):定义一个数字。
3-要存在的表列名(Table Column Name to Exist):定义列名。
4-要匹配的表列名集(Table Column Names to Match Set):添加要匹配的逗号分隔的列名。还可以验证列名是否有序。
5-自定义SQL查询(Custom SQL Query):定义SQL表达式。如果策略应适用于“行”或“计数”,请选择该策略。定义一个阈值来确定测试是通过还是失败。
6-表行计数介于之间(Table Row Count to be Between):定义最小值和最大值。
7-表行计数等于(Table Row Count to Equal):定义一个数字。
8-表中插入的行数介于(Table Row Inserted Count to be Between):定义最小和最大行数。此测试将适用于值为“时间戳”、“日期”和“日期-时间”字段类型的列。按小时、天、月或年指定范围类型。根据所选范围类型定义间隔。
列测试
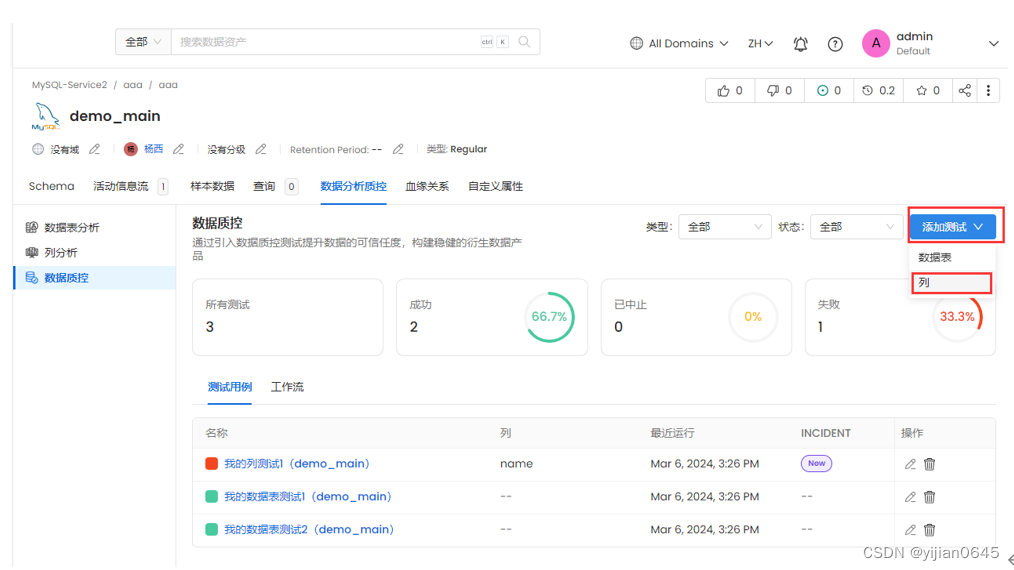
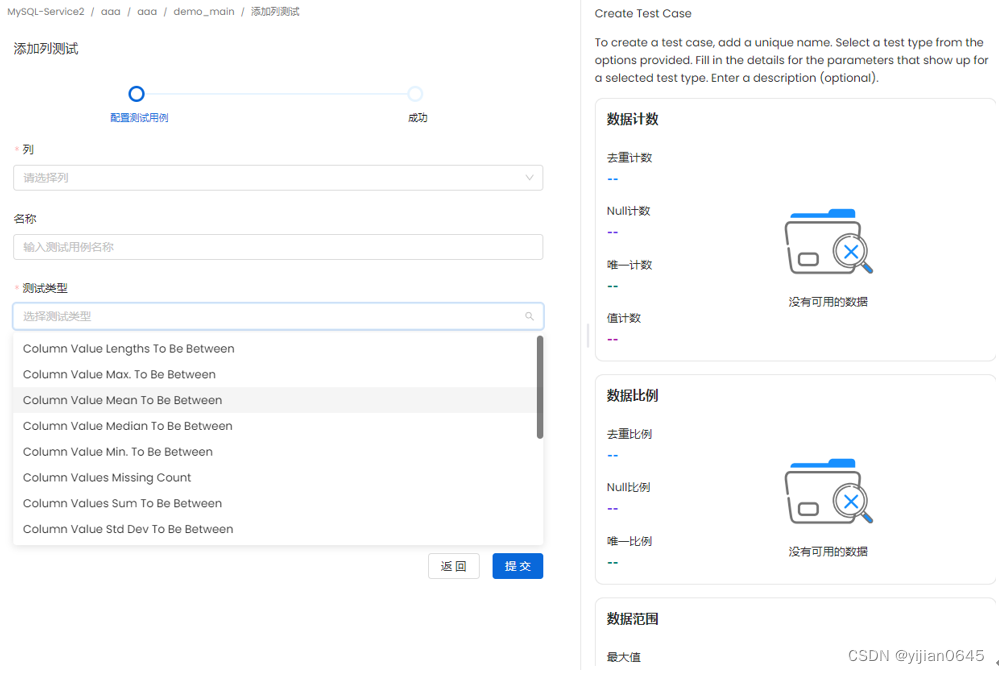
-要创建列级测试,请输入以下详细信息:
列:选择一列。在右侧,您可以查看有关该列的一些上下文。
名称:添加一个最能定义测试用例的名称。
测试类型:根据测试类型,您将有更多的字段来定义测试。
描述:描述测试用例。单击“提交”以设置测试。
-OpenMetadata当前支持以下列级测试类型:
1-列值长度介于之间(Column Value Lengths to be Between):定义最小值和最大值。
2-列值最大值介于之间(Column Value Max. to be Between):定义最小值和最大值。
3-列值平均值介于之间(Column Value Mean to be Between):定义最小值和最大值。
4-要介于之间的列值中间值(Column Value Median to be Between):定义最小值和最大值。
5-列值最小值介于之间(Column Value Min. to be Between):定义最小值和最大值。
6-列值丢失计数(Column Values Missing Count):定义丢失值的数量。您还可以将所有null值和空值匹配为缺失值。您还可以配置其他丢失的字符串,如N/A。
7-列值总和介于之间(Column Values Sum to be Between):定义最小值和最大值。
8-列值标准偏差介于之间(Column Value Std Dev to be Between):定义最小值和最大值。
9-要介于之间的列值(Column Values to be Between):定义最小值和最大值。
10-要在集合中的列值(Column Values to be in Set):您可以添加一个允许值的数组。
11-不在集合中的列值(Column Values to be Not in Set):您可以添加一个禁止值的数组。
12-列值不能为Null(Column Values to be Not Null)
13-列值必须唯一(Column Values to be Unique)
14-要匹配Regex模式的列值(Column Values to Match Regex Pattern):定义列条目应匹配的正则表达式。
15-列值不匹配Regex(Column Values to Not Match Regex):定义列条目不应匹配的正则表达式。
执行测试用例
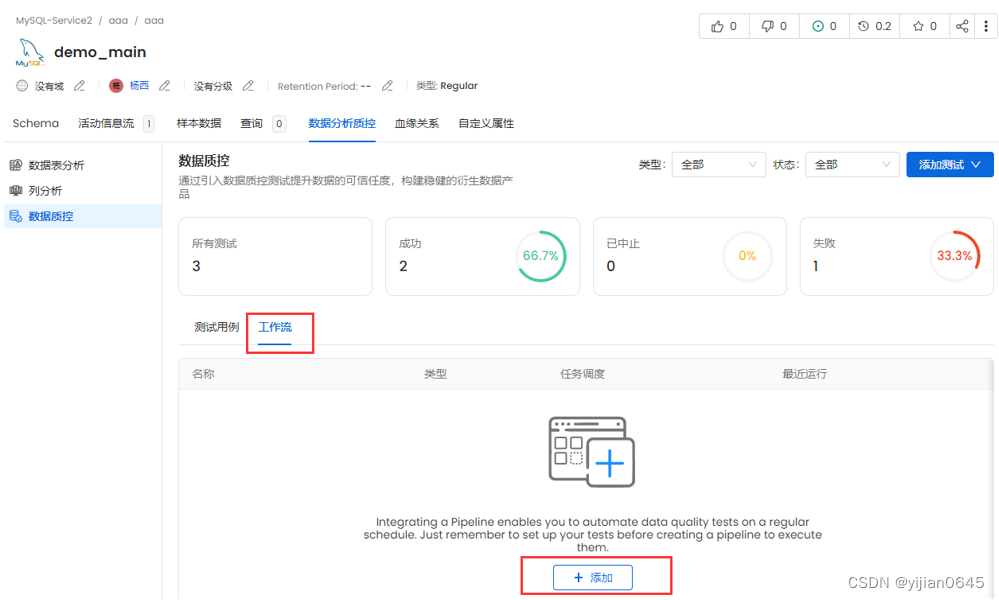
运行结果将在“数据质量”选项卡中更新。
用户还可以设置警报,以便在测试失败时收到通知。
测试失败警告设置
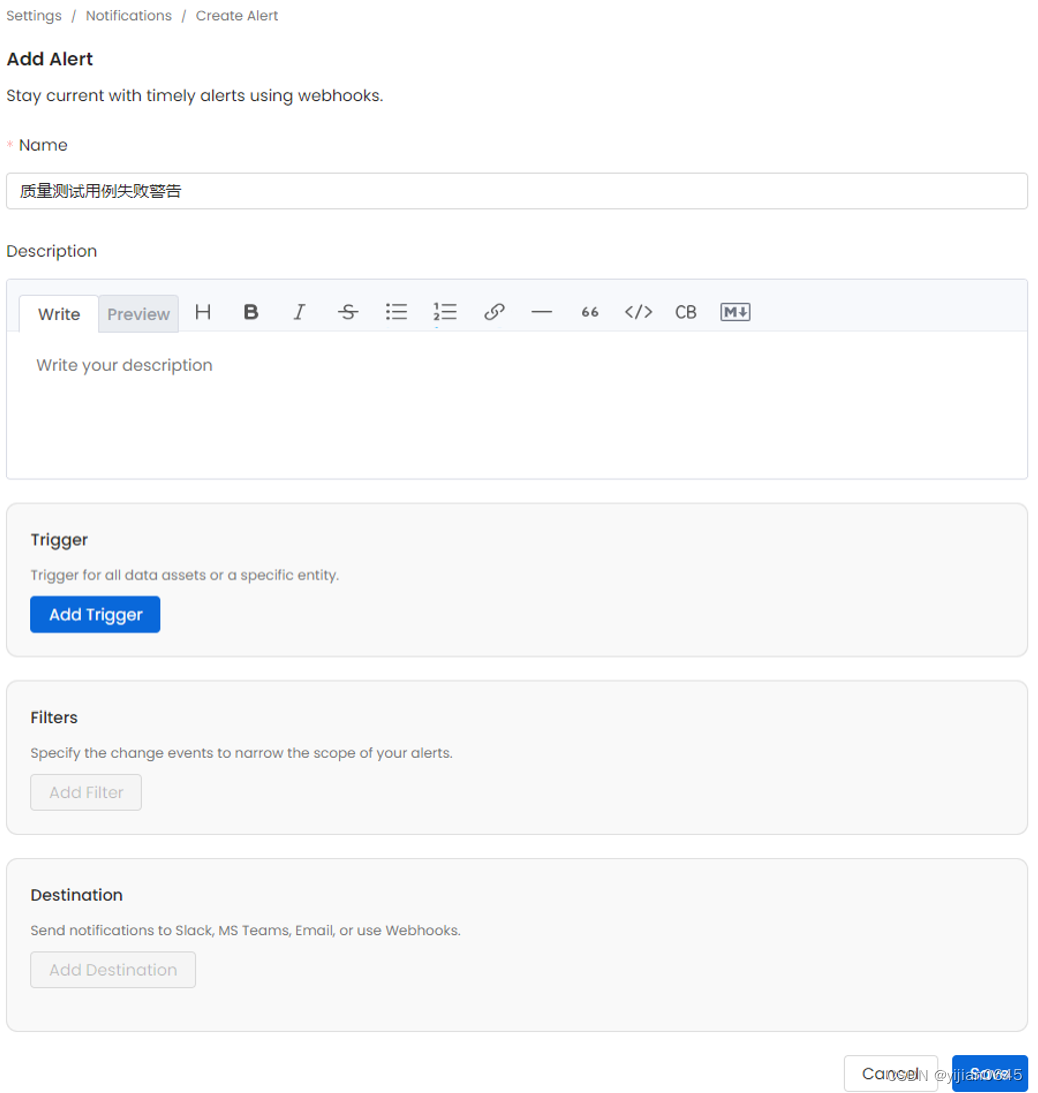
-输入以下详细信息:
-名称:添加警报的名称。
-描述:描述laert的用途。
-触发器:取消选中All的触发器,并为Test Case添加一个触发器
-过滤器:添加过滤器以缩小到失败的测试结果。您也可以添加另一个筛选器来指定FQN,使其仅包括要考虑的表。
-目标:指定必须发送测试失败通知的目标。警报可以发送到电子邮件、Slack、MS Teams、谷歌聊天和其他Webhook。通知也只能发送给数据资产的管理员、所有者和追随者。
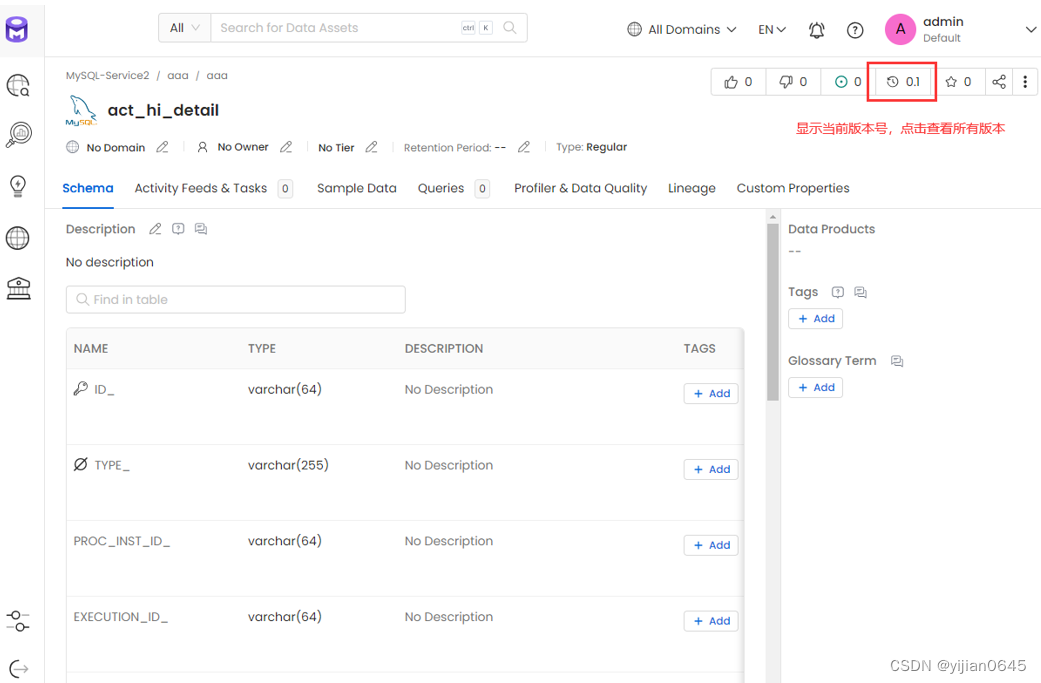
数据资产版本控制
元数据版本控制有助于简化调试过程。查看版本历史记录,查看最近的更改是否导致数据问题。数据所有者和管理员可以查看更改并在必要时进行恢复。
OpenMetadata对元数据的所有更改进行版本化,以捕捉版本历史中数据随时间的演变。这将针对所有数据资产进行跟踪。
OpenMetadata还捕获源位置的元数据更改。
OpenMetadata使用一个格式为major.minor的数字来维护所有数据资产的版本历史记录,该数字以0.1作为实体的初始版本。
以下元数据的更改会导致版本的更改:
-向后兼容的更改会导致轻微的版本更改。
描述、标签或所有权的更改将使数据资产元数据的版本增加0.1(例如,从0.1增加到0.2)。
-向后不兼容的更改会导致主版本更改。
例如,删除表中的列时,版本会增加1.0(例如,从0.2增加到1.2)。
-单击版本图标以查看数据的版本历史记录。
管理团队和用户
OpenMetadata的多功能分层团队结构有助于与组织的设置保持一致。管理员可以通过创建各种团队类型来反映其组织层次结构。您可以将新用户加入相关团队。一个组织可以有多个管理员,这样不同的团队和部门就可以由不同的管理员进行有效地管理。
OpenMetadata中的团队结构
OpenMetadata引入了一种通用的分层团队结构,与组织的设置保持一致。管理员可以通过创建各种团队类型来反映其组织层次结构。
OpenMetadata支持使用teamType的分层团队结构,teamType可以是组织、业务部门、部门、部门和组(默认团队类型)。组织是代表整个公司的团队层次结构的基础。组织下的其他团队类型是业务部门、部门、部门和组。
-组织(Organization):是层次结构中的根团队。它不能有父级。它可以拥有业务单位、部门、部门、集团类型的子级以及直接作为子级的用户(没有团队)。
-业务单位(BusinessUnit):是层次结构中团队的下一个级别。它可以拥有业务单位、部门、子部门和组作为子级。它只能有一个父级,可以是组织或业务单位。
-部门(Division):是业务单位以下层次结构中团队的下一个级别。它可以拥有部门、小组和组作为子级。它只能有一个组织、业务单位或部门的父级。
-子部门(Department):是团队在组织结构中的下一个级别,低于事业部。它可以拥有部门和组作为子级。它可以拥有组织、业务单位、部门或子部门作为父级。它可以拥有多个父级。
-组(Group):是层次结构中团队的最后一个级别。它只能有用户作为子级,而不能有任何其他团队。它可以拥有所有团队类型的父级。它可以拥有多个父级。组代表此层次结构的最后一层。它包含一组用户,这些用户反映了组织内的有限团队。
注意:创建后,组的teamType不能在以后更改。且只有 Group 类型的团队可以拥有数据资产。
添加团队
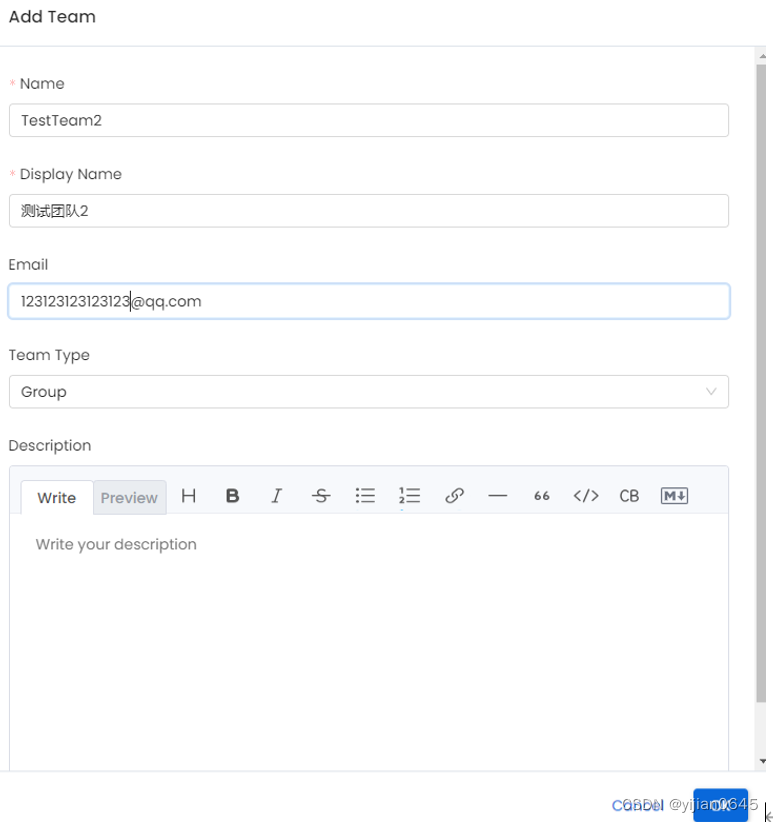
注意:添加团队时,团队之间的上下级关系是不能直接添加的,需要在团队列表中手动拖动团队到另一团队中即可:
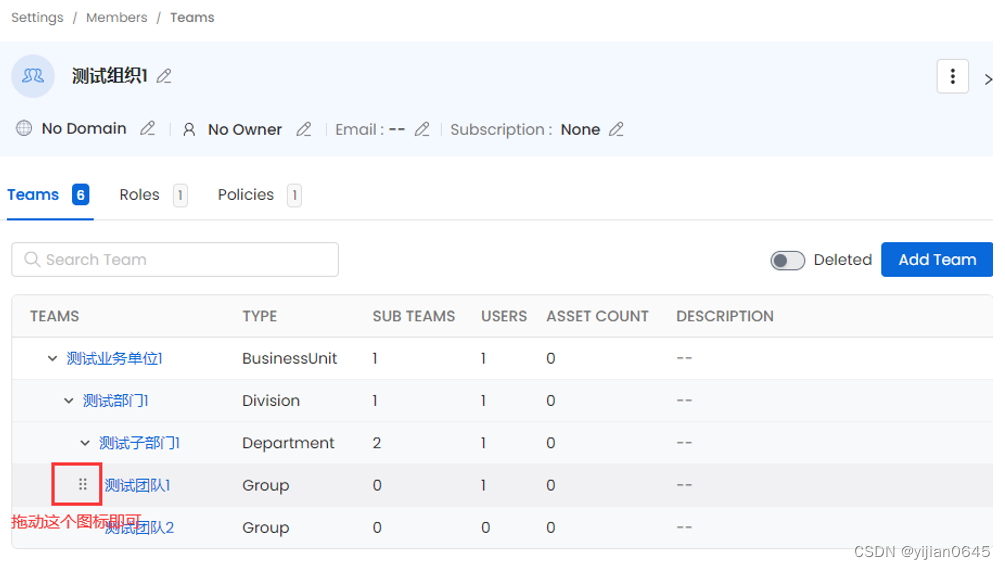
用户可以在某个团队详情页手动加入该团队:
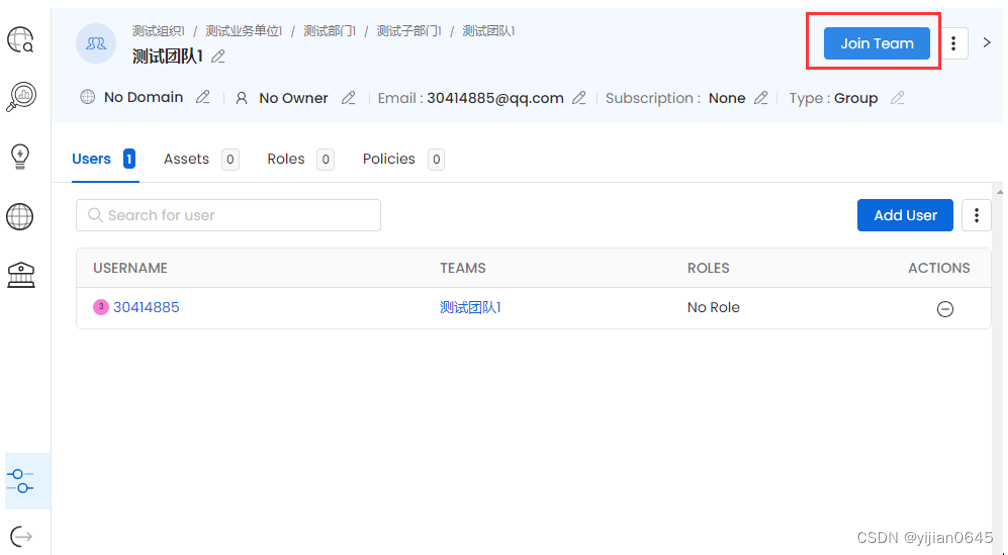
添加用户
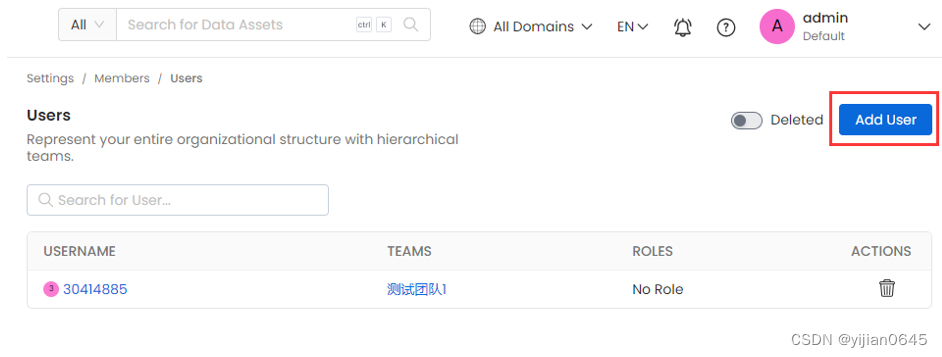
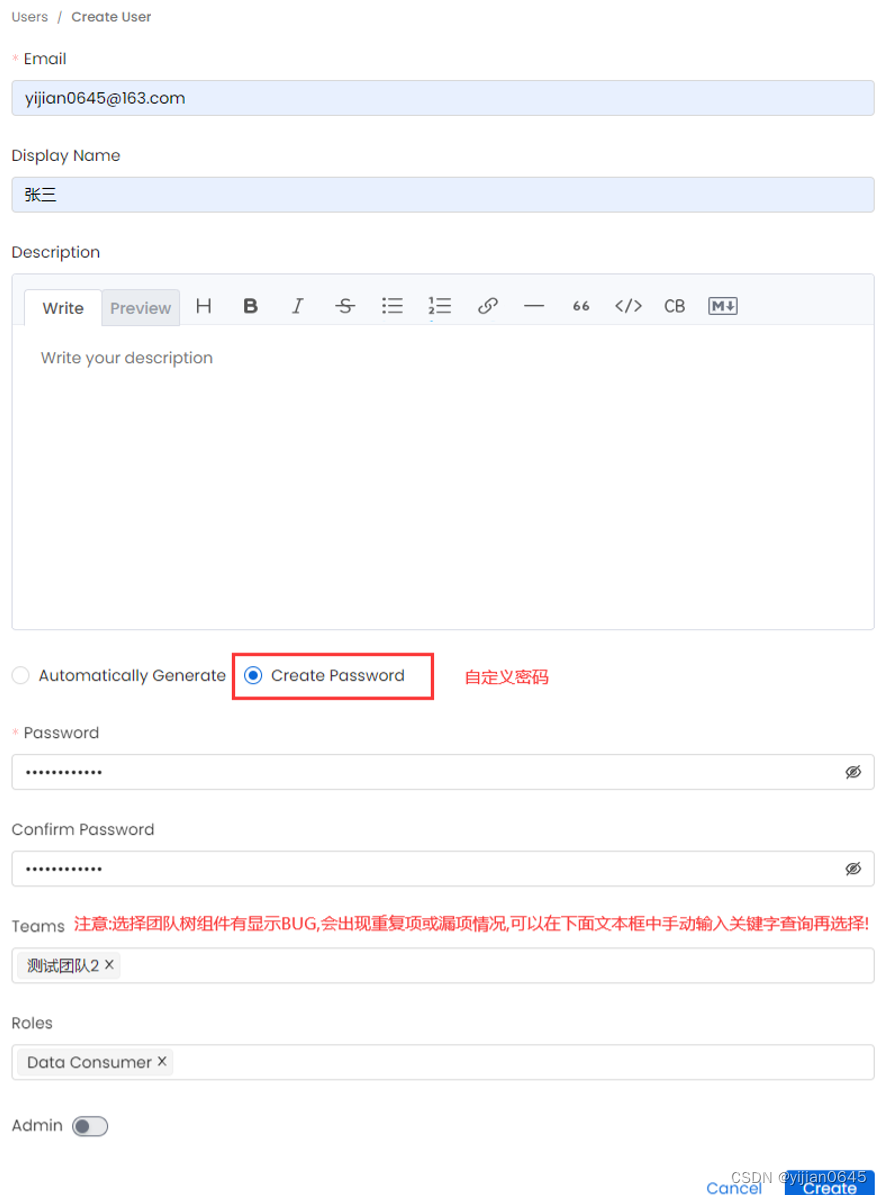
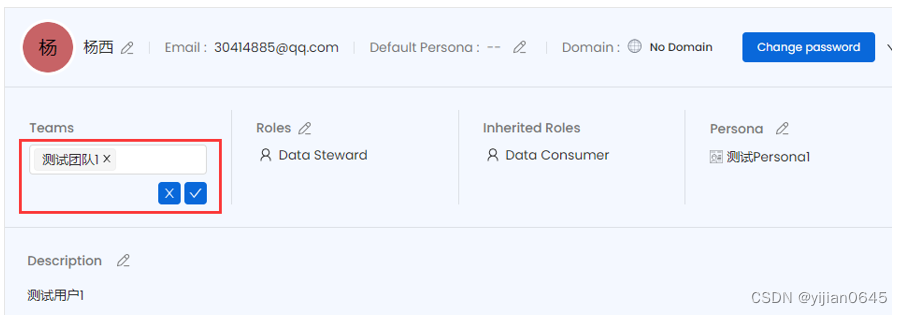
注意:一个用户可以属于多个Teams和多个Roles。
将已有用户添加到团队
方法1:
在类型为Group的团队详情页右侧点击“Add User”按钮可以选择要加入的已有用户:
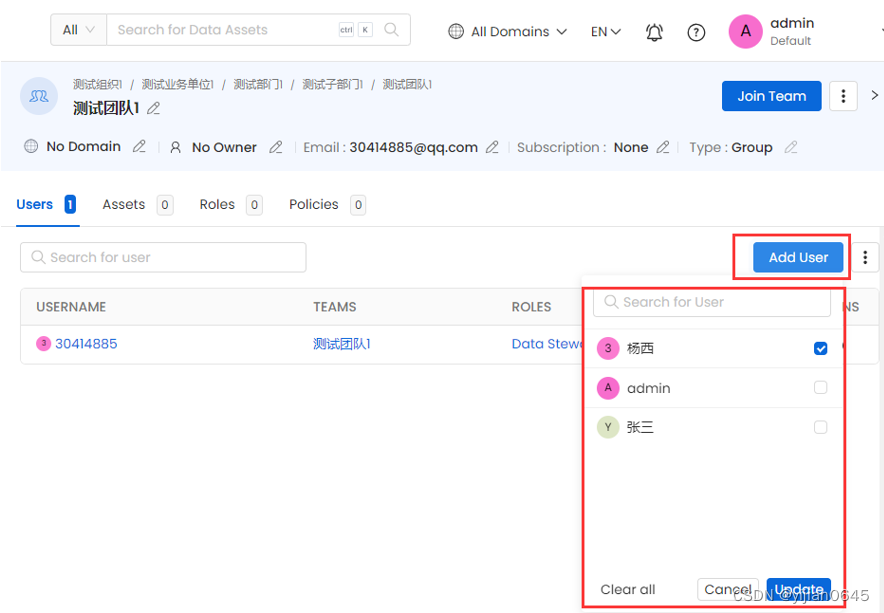
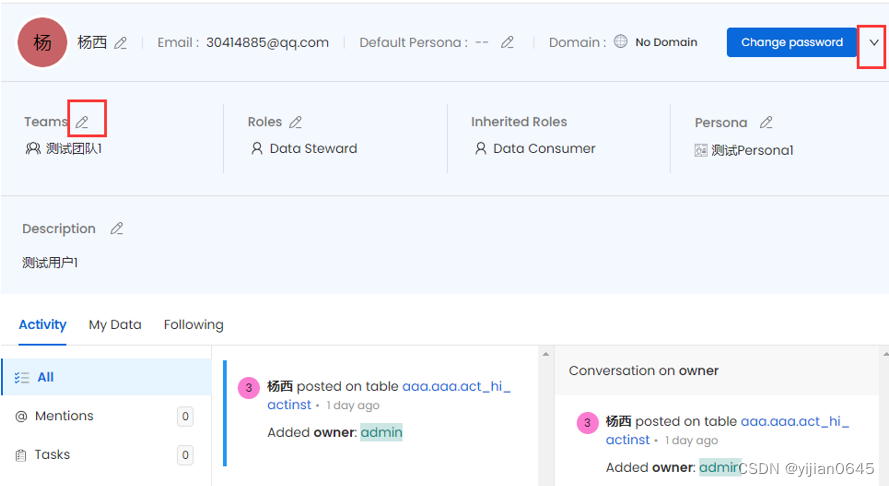
方法二:
在用户详情页上方编辑用户所属的团队:
访问控制设计:角色和策略
OpenMetadata 包含一个强大的访问控制框架,该框架将基于角色的访问控制 (RBAC) 与基于属性的访问控制 (ABAC) 合并到一个强大的混合模型中。
这种安全设计通过以下方式得到加强:
-SSO集成身份验证:OpenMetadata与各种单点登录(SSO)提供商无缝集成,包括Azure AD、Google、Okta、Auth0、OneLogin等。这确保了用户统一安全的身份验证体验。
-团队层次结构:OpenMetadata提供了一个结构化的团队层次结构,反映了组织的结构,增强了访问控制的可管理性和粒度。
-角色和策略:政策和角色在决定谁可以访问哪些资源以及执行哪些操作方面起着关键作用。这些政策基于用户属性、角色和资源属性的组合。
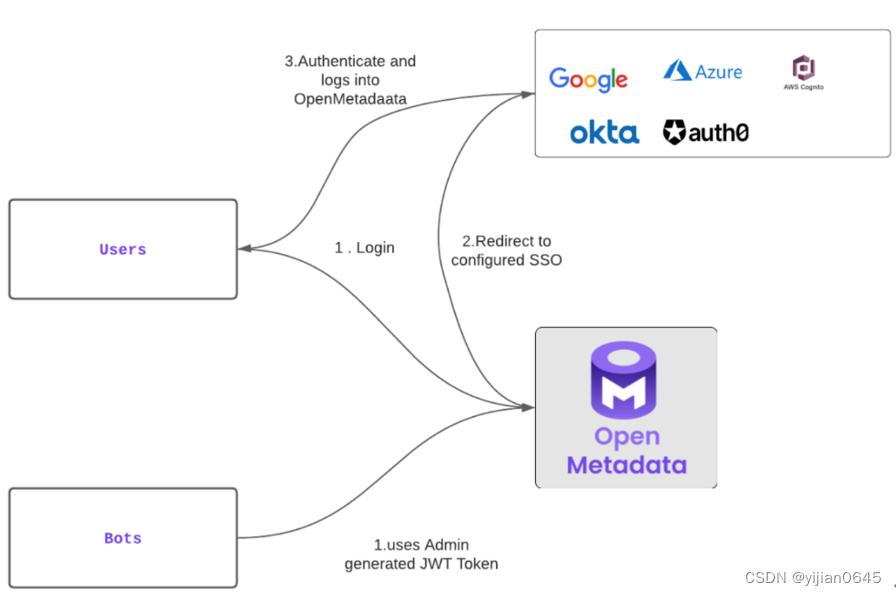
-用户和机器人验证:OpenMetadata可容纳人类用户和自动化应用程序(机器人)。对于人类用户,登录OpenMetadata UI需要SSO验证。验证成功后,会颁发JWT令牌。另一方面,机器人配备有基于SSL证书生成的JWT令牌。在与OpenMetadata服务器API交互时,该令牌用作其身份和授权机制。
用户身份验证:当用户访问OpenMetadata UI时,他们需要使用SSO提供程序进行身份验证。身份验证成功后,将生成JWT令牌。此令牌验证用户的会话,并允许他们验证对OpenMetadata服务器的请求。
机器人身份验证:像摄取连接器这样的自动化应用程序配备了一个预先生成的JWT令牌。OpenMetadata及其配置的SSL证书对JWT令牌进行身份验证,建立机器人的身份。该令牌授权机器人与OpenMetadata服务器API进行交互。
认证流程
授权框架介绍
OpenMetadata的授权是评估以下三个关键因素的结果:

Who is the User(Authentication ,身份验证):
这一方面由身份验证过程决定——无论是用户还是机器人——确保只有授权实体才能访问系统。
What Resource(Resource Attributes ,资源属性):
根据正在进行的API调用,OpenMetadata识别目标资源及其相关属性。
下面是与实体(如表、主题、管道等)相对应的资源列表:

What Opration(API Call ,API调用):
每个API调用都链接到一个特定的操作,如编辑描述、删除标记、更改所有权等。
有适用于所有资源的常见操作,如创建、删除和查看所有。每个资源也可以有其特定的操作,如查看测试、查看表的查询。
每个资源都有自己的一组细粒度操作:

通过综合应用这些组件,OpenMetadata动态地确定用户或机器人是否可以对特定资源执行特定操作。
混合模型中RBAC和ABAC的融合有助于实现强大而灵活的访问控制机制,增强OpenMetadata环境的安全性和控制性。
授权规则(Rules)、策略(Policies)和角色(Roles)
规则、策略和角色的维护均包含在“设置” -》 “Access Control”里:
规则(Rules)
规则简介
规则是被包含在 策略 中的。
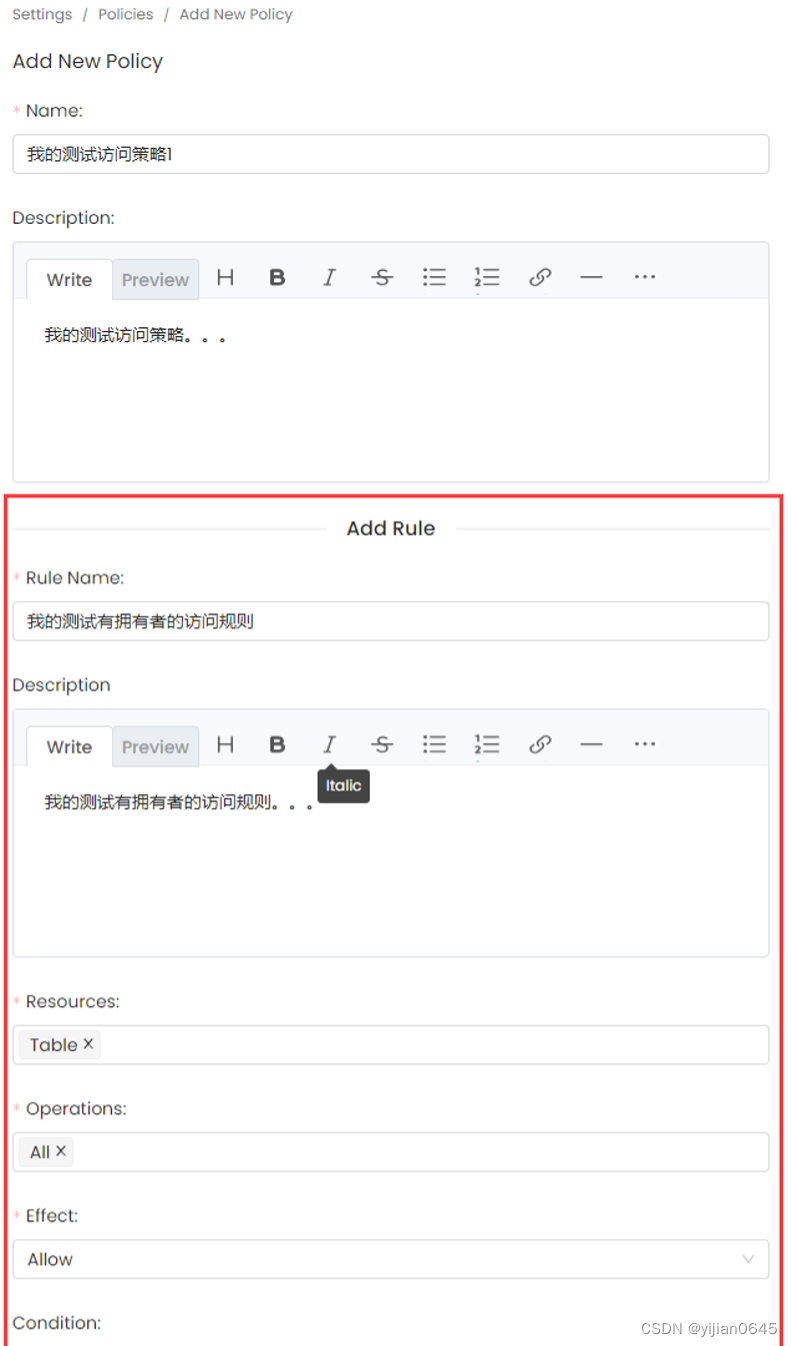
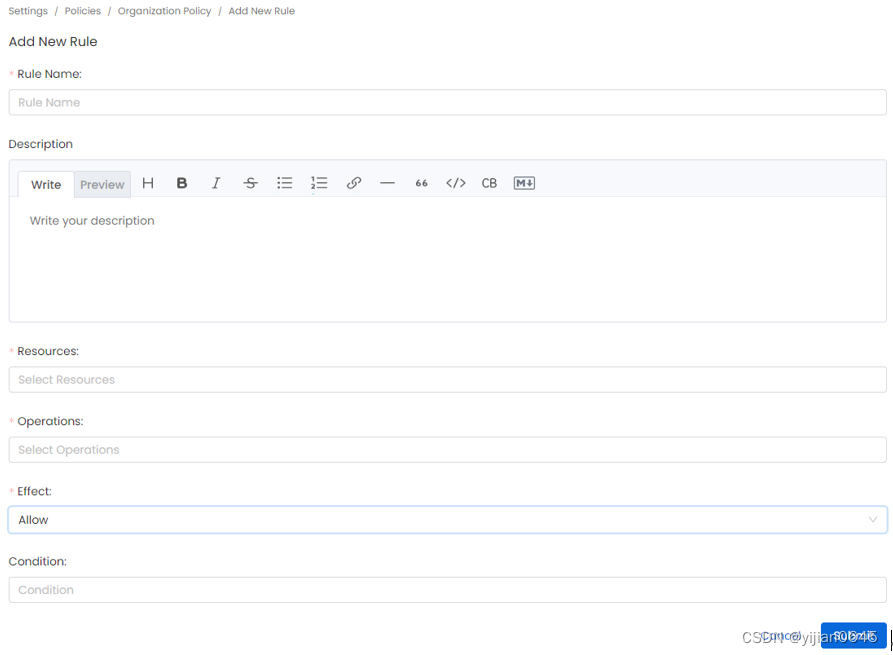
策略中的规则是授权的组成部分, 它包含以下内容:
1.名称(Name):定义规则的唯一名称。
2.描述(Description):规则的描述。
3.资源(Resources):此规则适用的资源列表。管理员可以选择特定资源(如表或所有)以应用于所有资源。
4.操作(Operations):此规则适用的操作列表。管理员可以选择特定操作,如“编辑所有者”或“全部”,以应用于所有操作。
5.条件(Condition):使用评估真假的策略函数编写的表达式。
6.效果(Effect):拒绝或允许操作。
规则的创建
-方式1:在创建策略(Policy)的页面进行规则的添加:
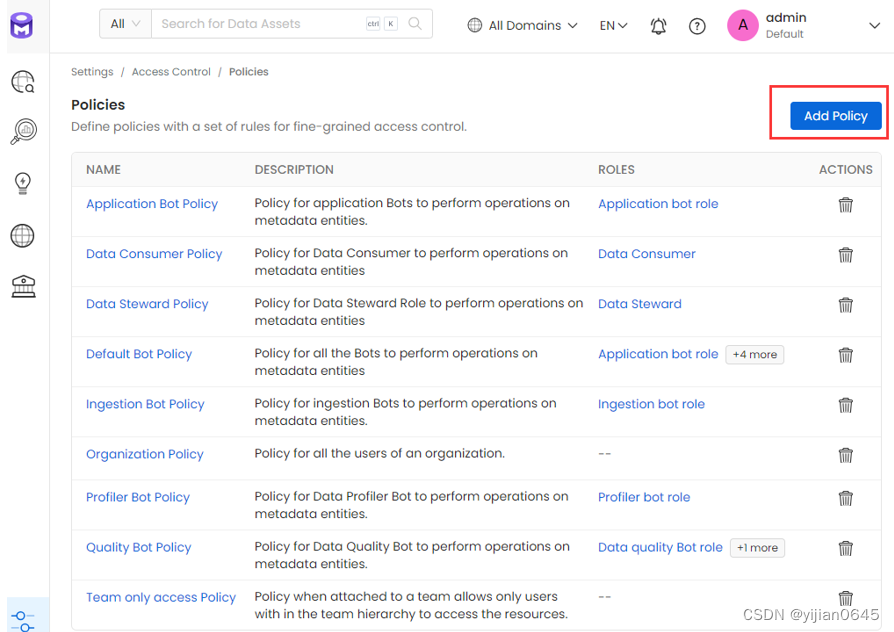
1.策略列表中点击右侧“Add Policy”按钮创建策略:
2.在策略添加表单下方添加规则:
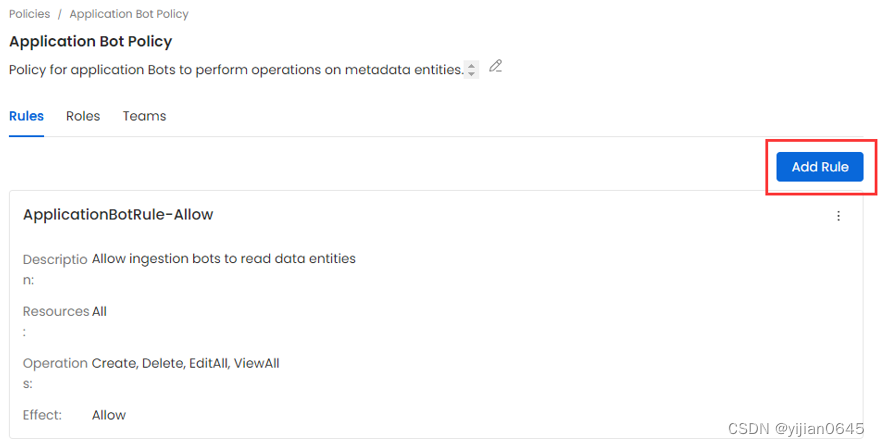
-方式2:在已有策略(Policy)的详情页右侧点击“Add Rule”按钮给当前策略添加规则:
条件(Condition)说明
条件用于评估特定属性的数据资产,如表/主题/仪表板等。
OpenMetadata 为管理员在创建规则时提供了基于 SpEL 的条件选择。
以下是一些条件的例子:
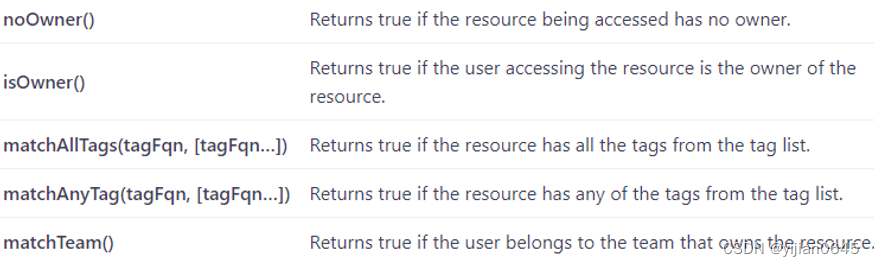
示例1:
考虑应用于事实表fact_orders的noOwner()条件。如果此表缺少分配的所有者,则该条件返回true。但是,如果存在所有者,则返回false。
示例2:
当应用于带有PII.Sensitive标签的dim_address表时,matchAnyTag(PII.Sensitive)条件将产生true。但是,如果没有这个特定标签,结果将是false。
示例3:
您还可以使用逻辑运算符(如AND(&&)或OR(||))组合条件。
例如,如果数据资产(无论是表、主题等)没有分配所有者并且同时匹配所有指定的标签,则组合条件:noOwner() && matchAllTags('PersonalData.Personal', 'Tier.Tier1', 'Business Glossary.Clothing')将产生一个true结果。
这些动态条件使管理员能够制定规则,在规定访问控制时全面考虑数据资产及其属性。
默认的策略与规则
当导航到 “设置”-》“Access Control”-》“策略”-》“Organization Policy”时,您将发现组织级设置的默认规则。
以下是这些规则的说明:
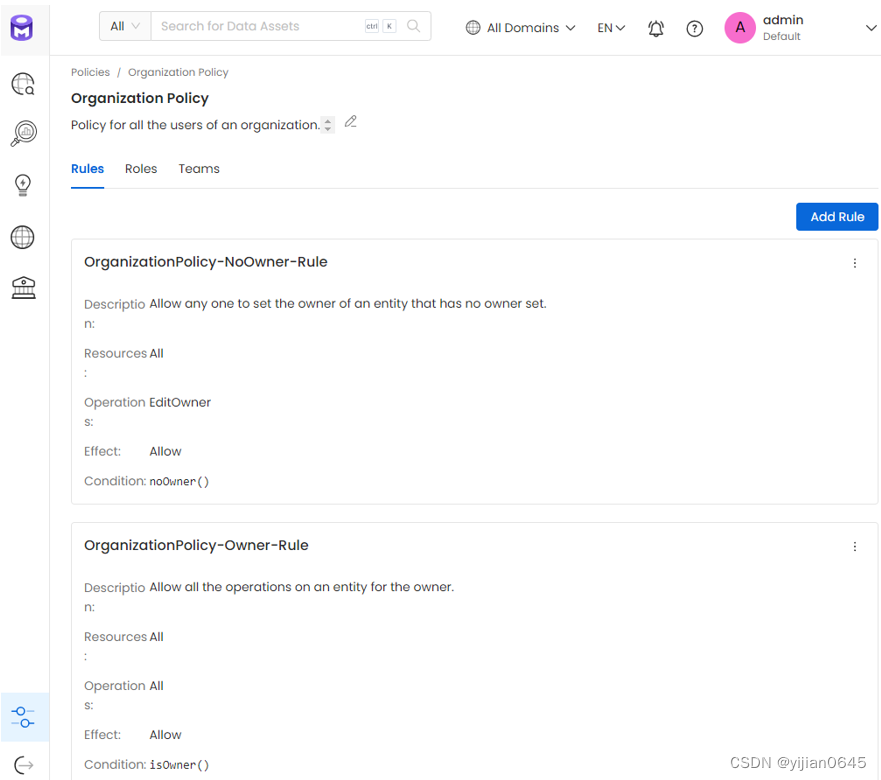
-OrganizationPolicy-NoOwner-Rule规则:

目的:此规则允许用户在没有所有者的情况下为资源分配所有权。
示例:如果用户访问事实表并发现它没有所有者,那么他们可以修改所有权字段以建立新的所有者。但是,对于已经分配了所有者的表(如dim_address),任何更改所有权的尝试都将受到限制。
-OrganizationPolicy-Owner-Rule规则:

目的:此规则根据数据资产的所有权授予权限。
说明:当个人拥有一个表或属于拥有该表的团队的用户登录时,他们被授予广泛的权限。他们可以修改该数据资产的所有属性并访问有关它的完整信息。
通过设置此类默认规则,组织可以确保基于所有权状态和用户角色的访问控制清晰明了。
策略(Policy)
策略简介
策略可以被分配给 团队。
如前一小节所述,策略包含多个规则。
当用户访问资源时,策略会在该用户当前会话的上下文中评估其所有相关规则。
在 OpenMetadata 中,策略是一组规则的集合,基于某些条件定义访问权限。
我们支持基于 SpEL(Spring Expression Language)的丰富条件规则,已发布支持实体的所有操作。
使用这些细粒度操作权限为每个策略定义条件规则。
基于条件规则创建明确定义的策略,以构建丰富的访问控制角色。
策略的创建
策略列表中点击右侧“Add Policy”按钮创建策略:
PS:添加策略时,可同时添加与之关联的规则(Rules),具体的规则信息参考前一小节内容。
策略的分配
策略可以与组织层次结构中的特定团队相关联,但它们不能直接链接到单个用户。
-在团队详情页面,可添加该团队的策略:
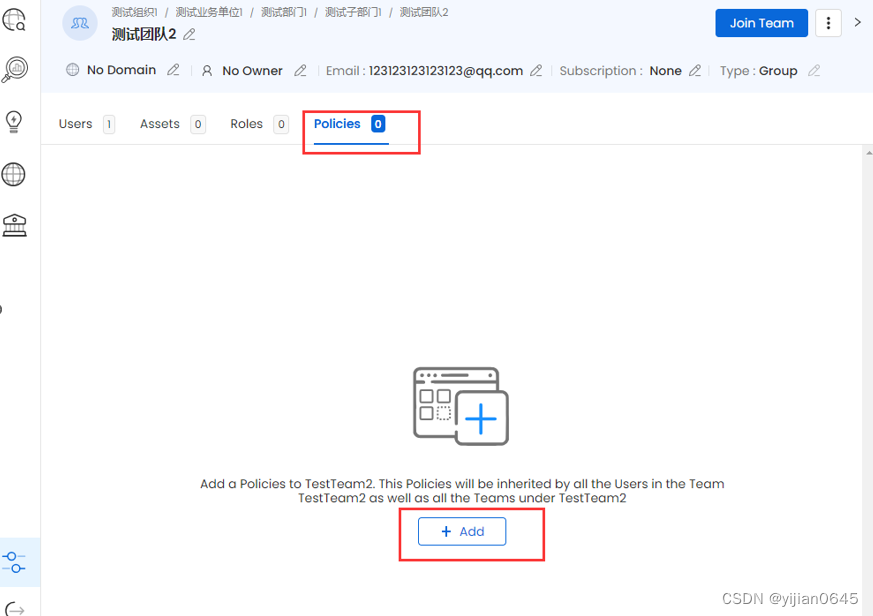
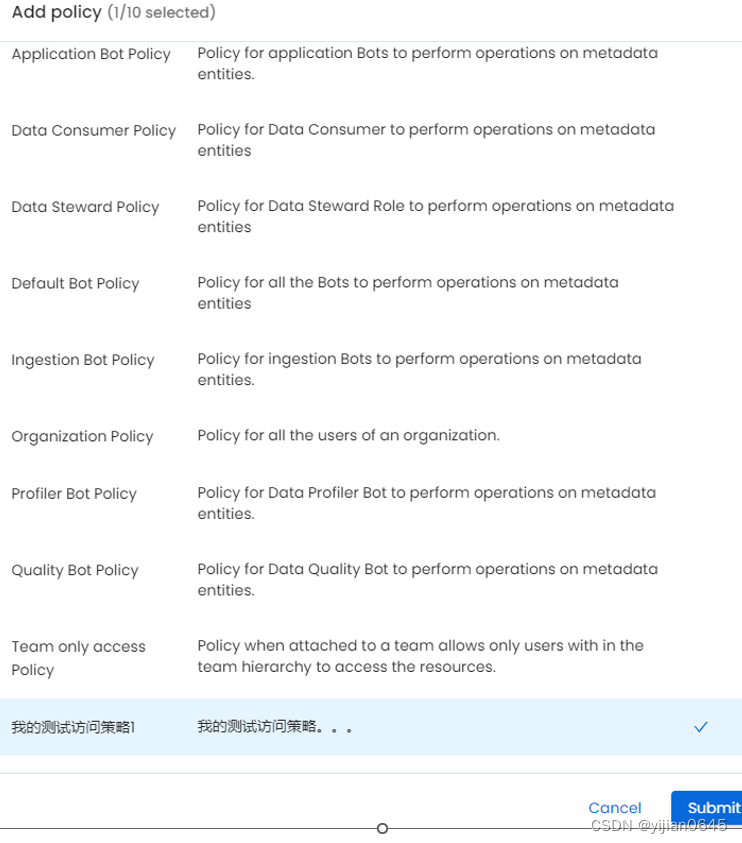
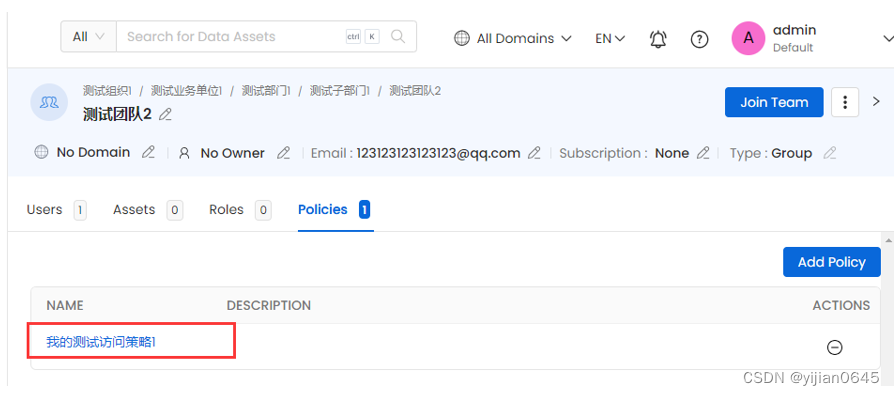
策略的继承和应用
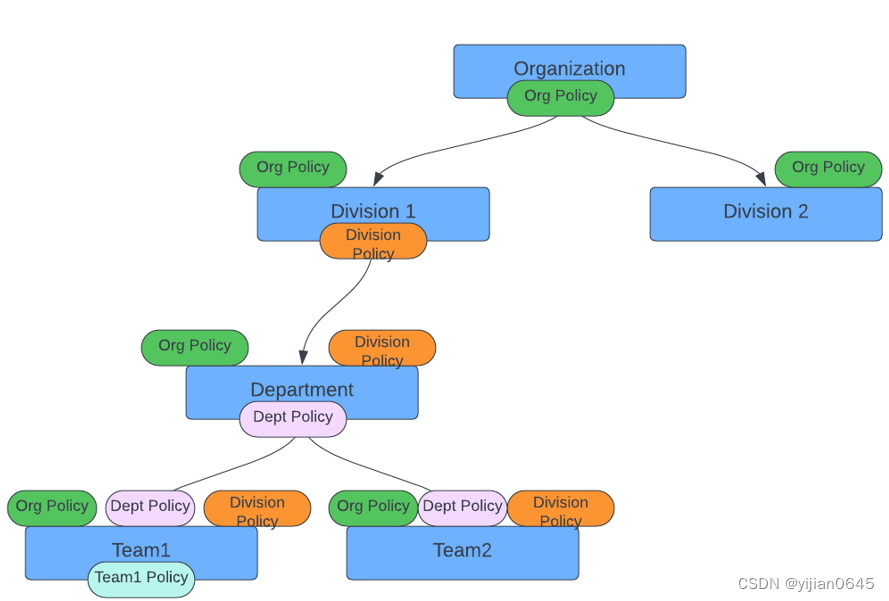
位于团队结构内的任何用户都固有地采用其策略。
例如,如果在组织的顶层制定了“组织-无所有者-策略”,则其所有内部成员都将受此策略及其规则的约束。
同样,如果将某项政策指定为“部门1”,如“部门政策”,则每个成员,无论是“部门”、“团队1”、“团队2”还是这些组中的个人用户,都将属于其职权范围。
但是,如果您为“Team1”明确制定政策,则只有“Team1”的成员会受到影响。
设计背后的哲学
这种架构旨在在组织层面建立广泛的总体规则,在本质上可能更加松散。随着你向下移动层级,团队可以制定更严格、更定制化的政策。
例如,一项政策可能规定,“拒绝团队1以外的所有人访问。”这确保了顶层的灵活性和基层的精确性。
解决策略冲突
在策略具有相互矛盾的规则的情况下,例如,一条规则允许对所有资源执行“EditDescription”,而另一条规则则拒绝执行该操作,则“拒绝”操作优先。
角色(Roles)
角色简介
角色可以分配给组织层次结构中的 团队或用户。
当角色分配给团队时,该团队的每个成员都会继承该角色的特权。这种设计是有意的,旨在简化管理员的角色分配过程。
策略是执行授权的机制,而角色则提供了用于相同目的的结构化层次结构。
一个角色可以绑定多个策略(Policy),这些策略涵盖了用户的特定功能或工作。
例如,“数据消费者”角色将包括“数据消费者政策”。
任何分配此角色的个人或团队都将自动遵守相关政策中规定的内容。
每个角色都与用户的职能或职位描述紧密相关。
例如,在组织中,您可能拥有:
数据工程师:负责生产数据资产。
数据科学家:负责创建仪表板并利用数据工程师开发的资产。
数据管理员:所有数据相关事务的专家,负责监督组织内的治理职责。
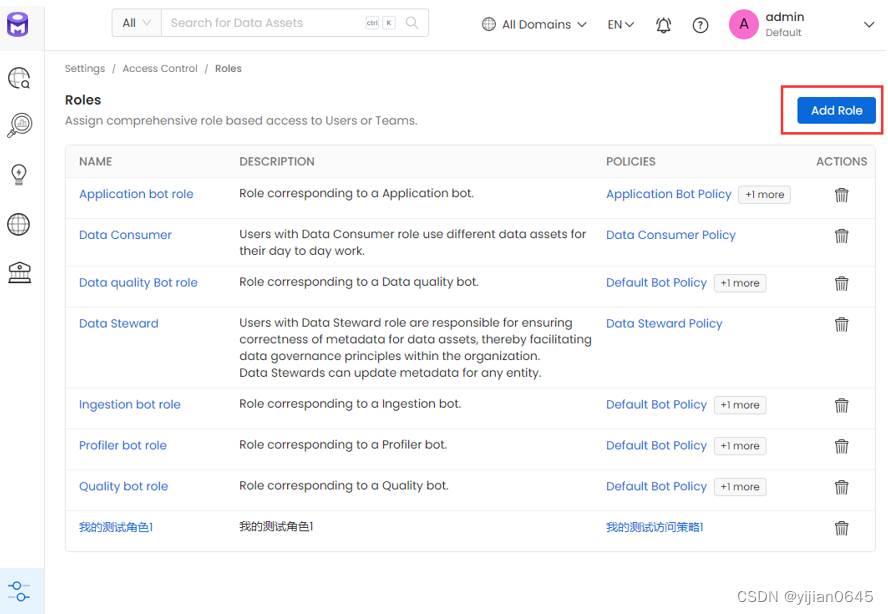
角色的创建
角色列表中点击右侧“Add Role”按钮创建角色:
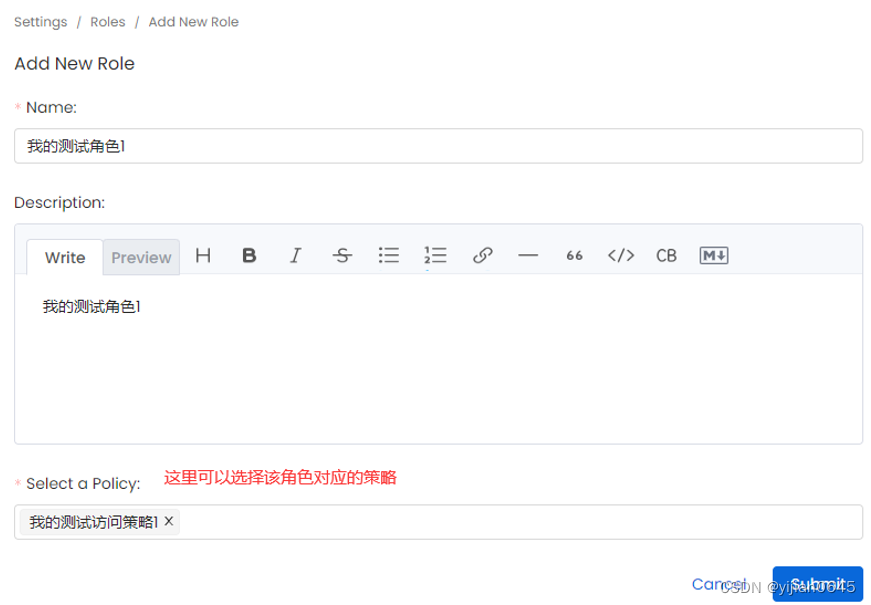
官网示例
官网示例网址:
https://docs.open-metadata.org/v1.3.x/how-to-guides/admin-guide/roles-policies/use-cases
示例1:我们希望我们的团队能够创建服务并提取元数据
您可以使用“所有操作”设置为允许的DatabaseService、Ingesiton Pipeline和Workflow资源创建策略。
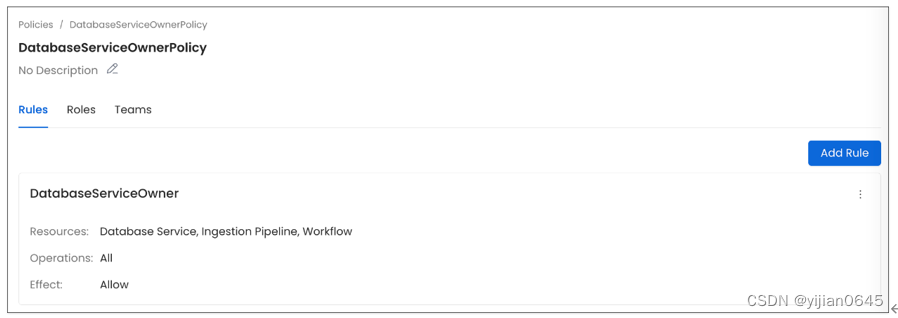
您可以创建一个角色,例如ServiceOwner角色,并分配上述策略。
创建角色后,您可以将其分配给用户,以便在不需要管理员的情况下自行创建服务。
示例2:数据管理员的角色
OpenMetadata中的数据管理员应该能够创建术语表和术语表术语,并能够查看所有数据并出于治理目的对其进行管理。
以下示例中使用一个包含了两个规则的策略,并将该策略应用到数据管理者(Data Stewards)角色上。
允许术语表操作:启用策略以允许进行所有与术语表相关的操作。
编辑规则: 授予数据管家编辑描述、编辑所有实体上的标签的权限;使得用户能够管理数据。
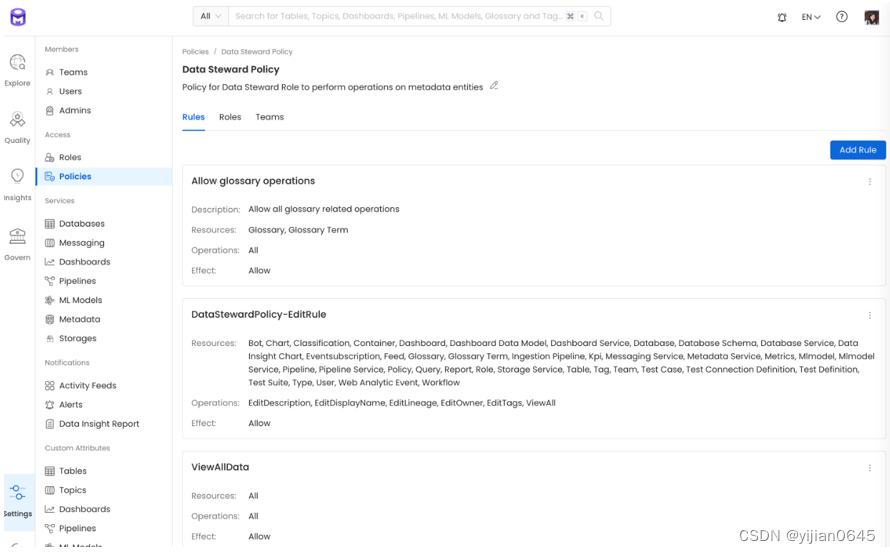
您可以对这些权限进行微调,以满足您的组织需求。
示例3:只有拥有数据资产的团队才能访问它
为了保护特定团队拥有的数据,可以防止外部访问。
如果登录用户不是所有者,或者登录用户的团队不是资产的所有者,则上述规则指定拒绝所有操作。
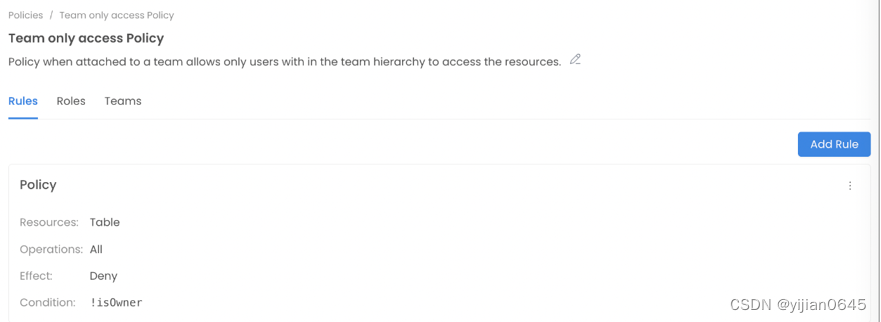
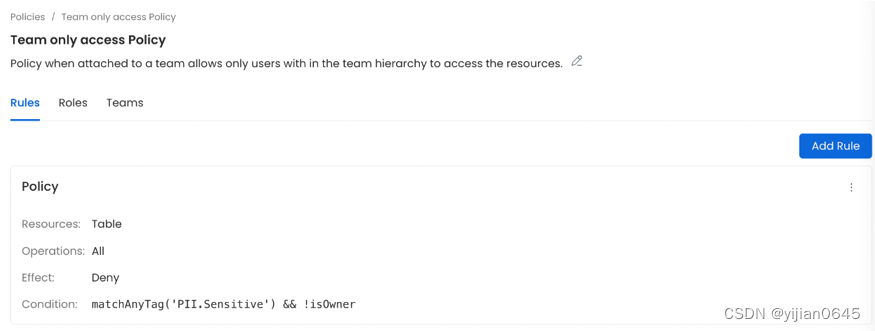
示例4:如果数据资产标记名为PII.Sensitive的标签,则拒绝所有访问,只允许所有者访问
在这个规则中,如果表(Table)标记了名为PII.Sensitive的标签,且登录的用户不是表的所有者,或者他们的团队不是表的所有权人,则拒绝操作。
如何使用基本认证(Basic Auth)从CLI运行摄入管道
从0.12.1开始,OpenMetadata已将默认的无身份验证更改为基本身份验证,因此,要从CLI运行任何摄取管道,您必须在securityConfig中传递jwtToken和authProvider。
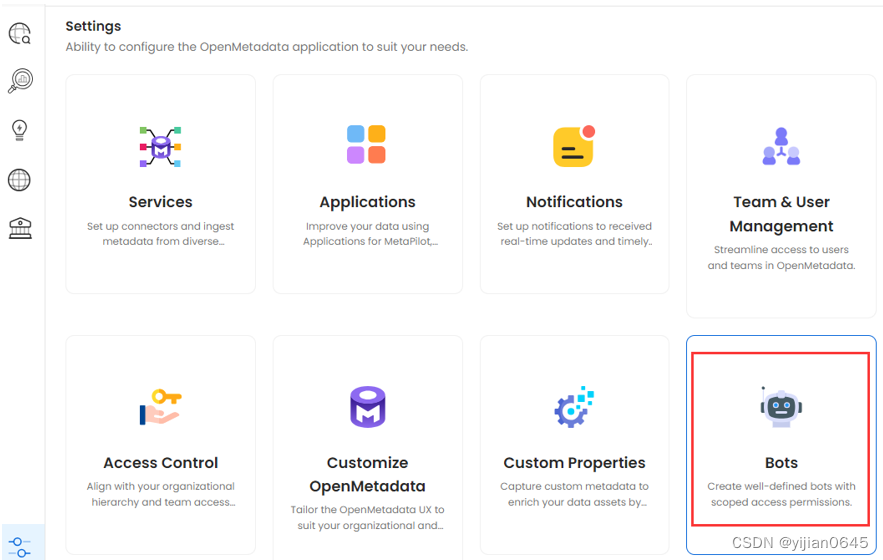
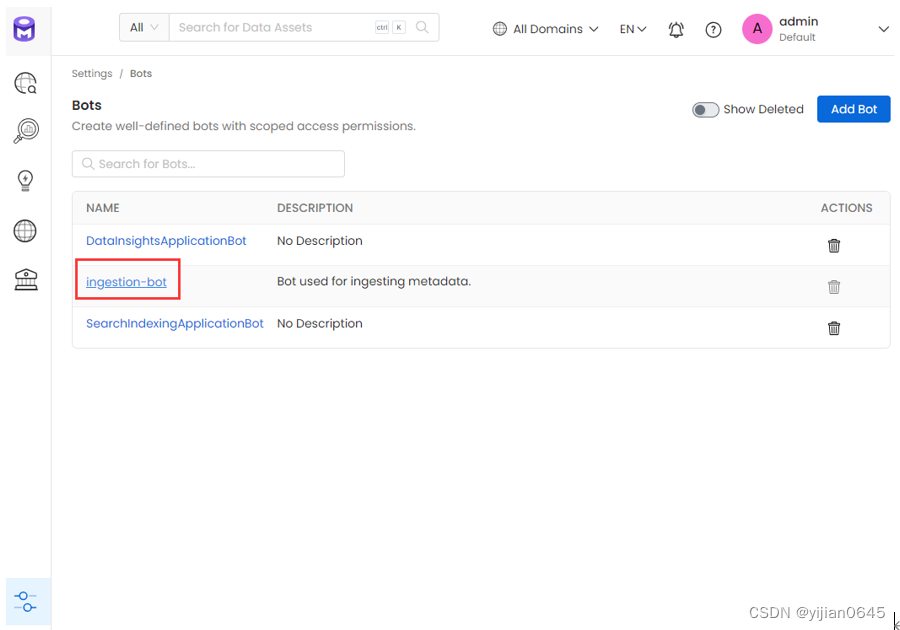
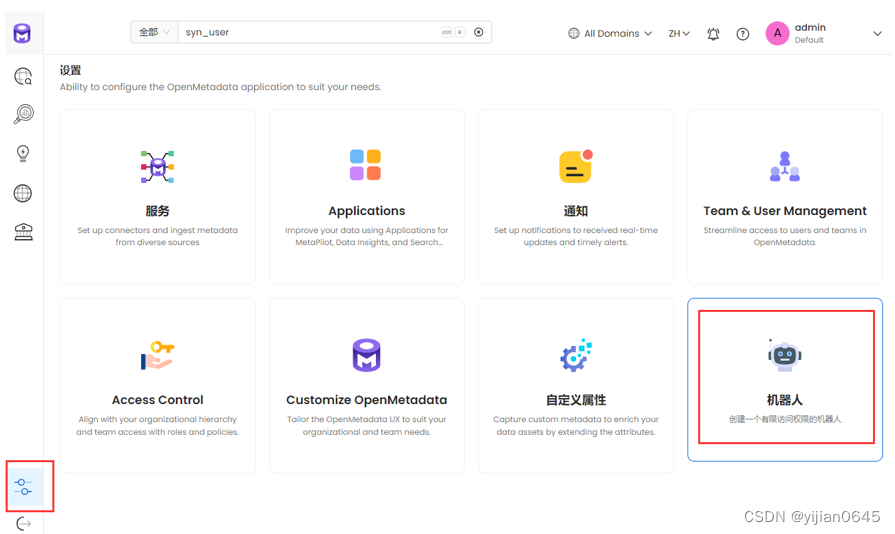
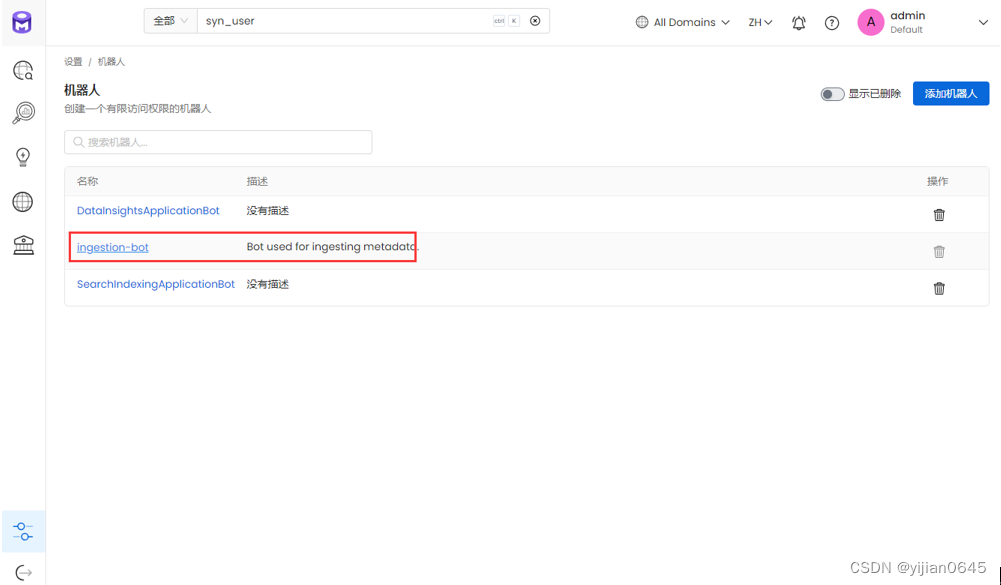
如何获取JWT token
找到设置中的摄取机器人:
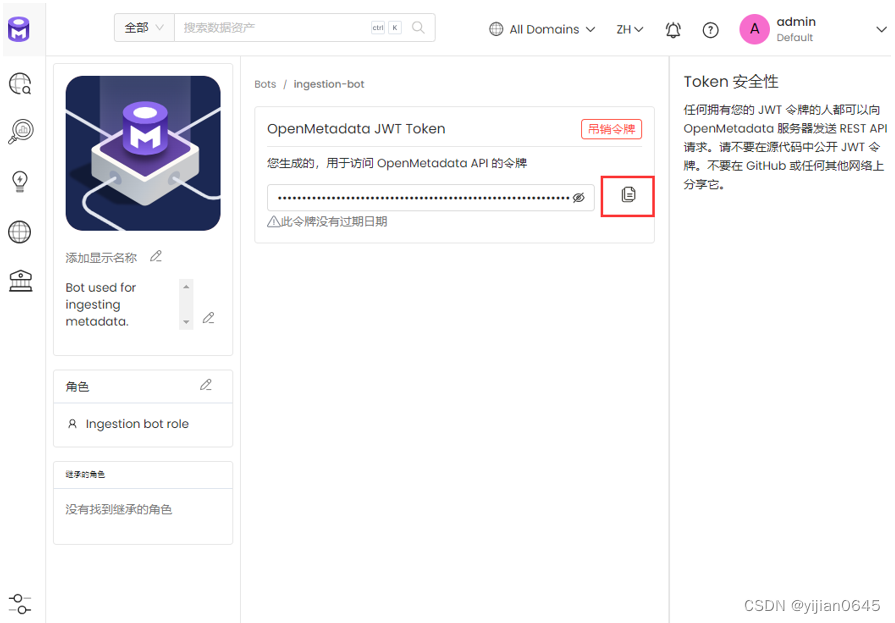
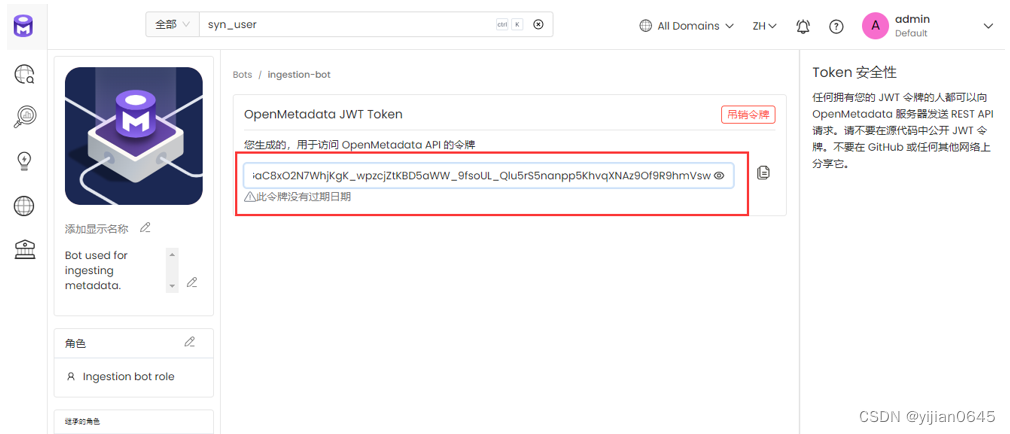
好了,现在有了JWT令牌,让我们看看如何将其添加到工作流配置中。
如何将JWT令牌添加到工作流配置中
现在将复制的JWT令牌传递到您的管道安全配置(pipeline securityConfig)中,因此您的最终工作流配置将如下所示。
AuthProvider应为openmetadata,即authProvider:openmetadata
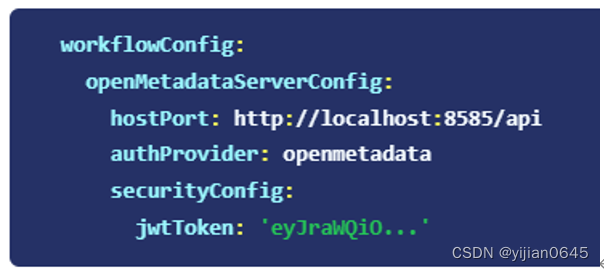
现在,您可以通过命令行(running)来运行管道了:
metadata ingest -c ./pipeline_name.yaml
更改登录页、导航栏图标和收藏夹图标
导航到“Settings”-》“Customize OpenMetadata”-》“Custom Logo”
API的调用
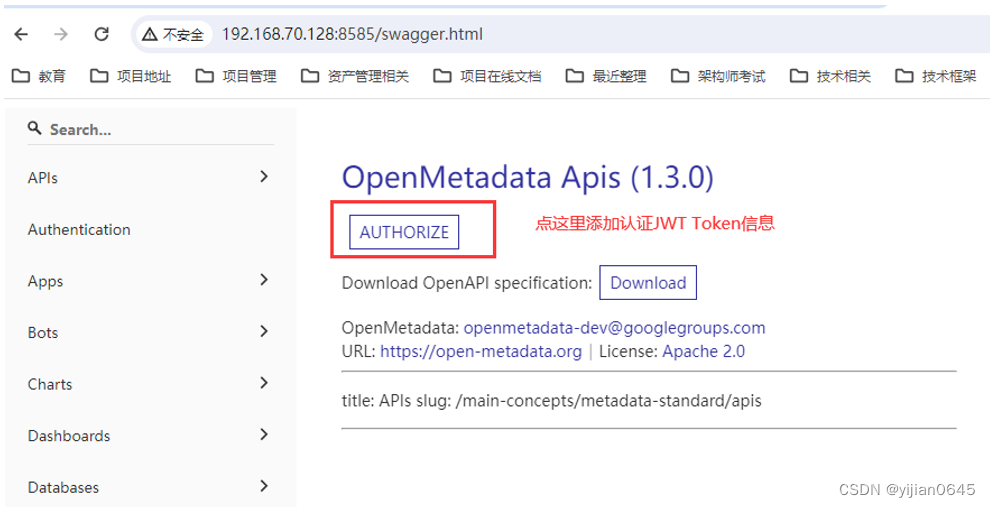
本机文档:http://192.168.70.128:8585/swagger.html
OpenMetadata支持RESTAPI,用于获取数据以及进出元数据服务。
API是使用REST API设计的一般最佳实践构建的。
我们采用模式优先的方法,在JSON模式中定义类型和实体。我们基于这些模式实现API。
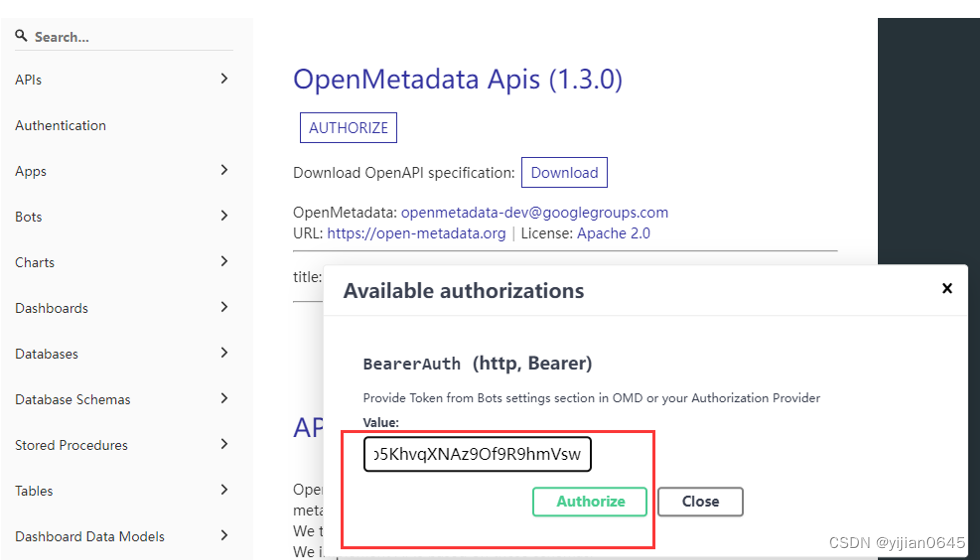
获取Bot JWT Token
通过Open Metadata本机文档Swagger进行API调用测试
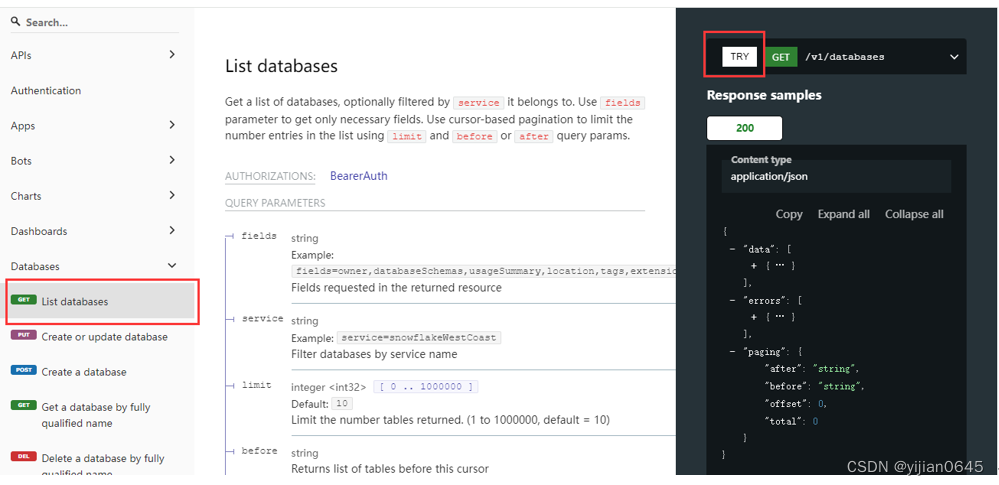
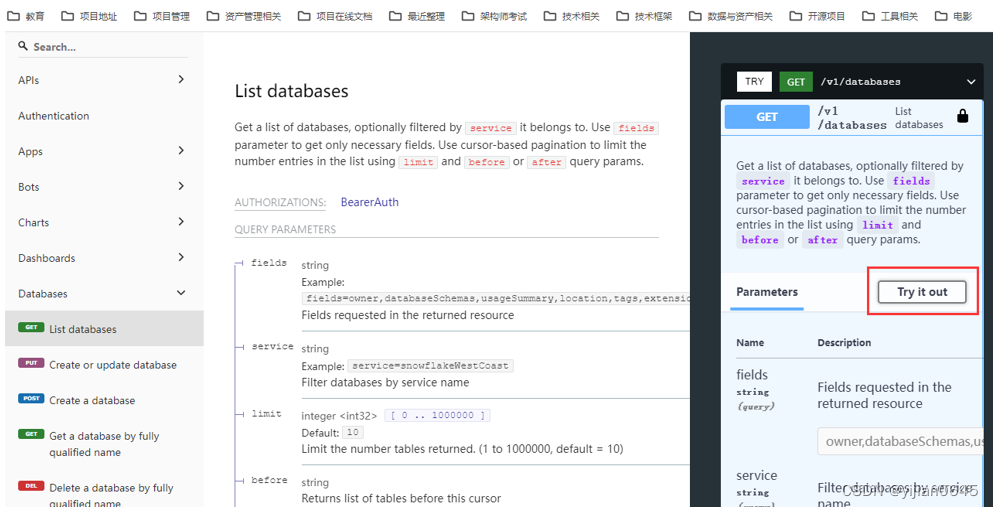
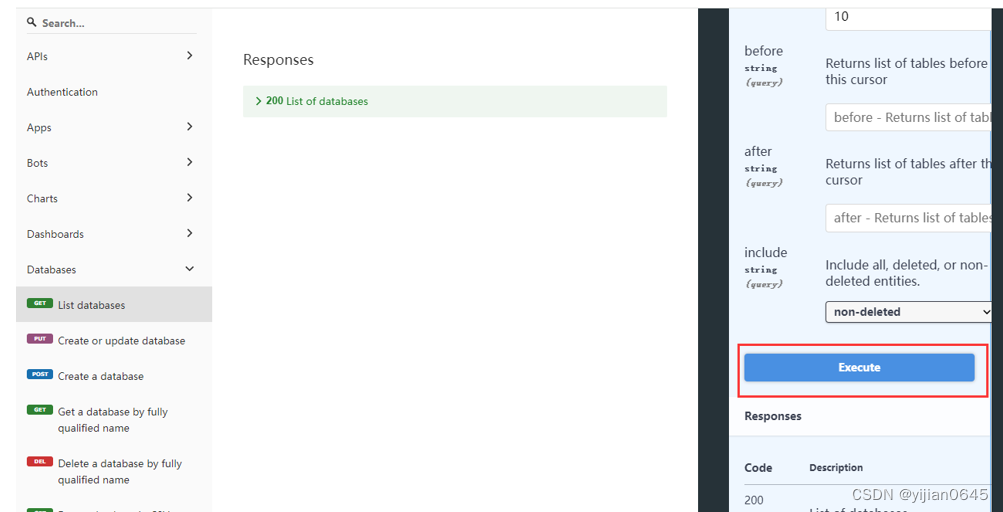
通过Soap UI进行API调用测试
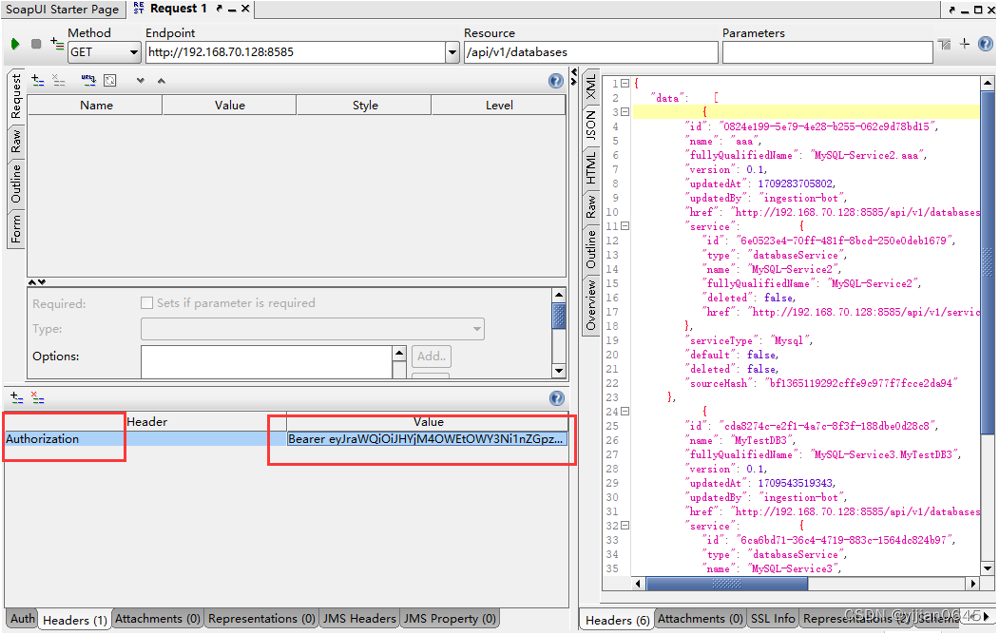
注意:API调用需要传入名为Authorization的头信息,值为Bearer Your Bot JWT Token。
Bearer和Bot JWT Token间要有空格哦!

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)