
TypeScript 实现的轻量级内存数据库 warehouse
本文是 `warehouse` 源代码结构分析的笔记,介绍了整个系统的各个实体的抽象,解释了其核心原理,并介绍了基本的用法。最后,还介绍了逐步具体化组装代码的设计模式。展示了泛型和面向对象技术怎么共同作用,用在系统软件架构设计中的方法。希望对大家有帮助!
因为要实现 HexoPress,我不得不去研究 hexo 的源代码,只有这样,才能更好地以两边都兼容的方式去操作 hexo 内的对象。本文将介绍 hexo 引用的一个库 warehouse,这个库实现了一个内存级数据库,还支持持久化到本地磁盘。这个组件在 hexo 系统中,充当着缓存的角色。

一、简介
Hexo 是一个静态站点生成器,支持将各种格式的源码文件(常用的是 html 和 markdown 格式)静态化成网页,在生成器运转的过程中,为了处理网页上的一些关系型数据,不得不将一些数据缓存到内存中进行操作,比如分类、标签、上一篇、下一篇链接等等。
于是,作者开发了这个内存级数据库 warehouse ,作为 Hexo 的内部组件使用。也开源在了 GitHub 上了。这个数据库成为我能够开发 HexoPress 的重要设施基础。因为HexoPress 的立意,就是让创作者去“有机地”去处理自己的整个博客的数据,但是 Markdown 文件在磁盘上是线性存储的,一个一个的文件。分类、标签这种高度共享的元数据信息,就不能有效地去管理了。
所以,在开发过程中,我持续去阅读 Hexo 的源码,并且了解它的 API,学习到了不少 js 和 typescript 开发的知识和技巧。也学习到了不少 js 软件代码组织的技巧。这里就分享一下 warehouse 的代码构造,希望给大家一点启发。
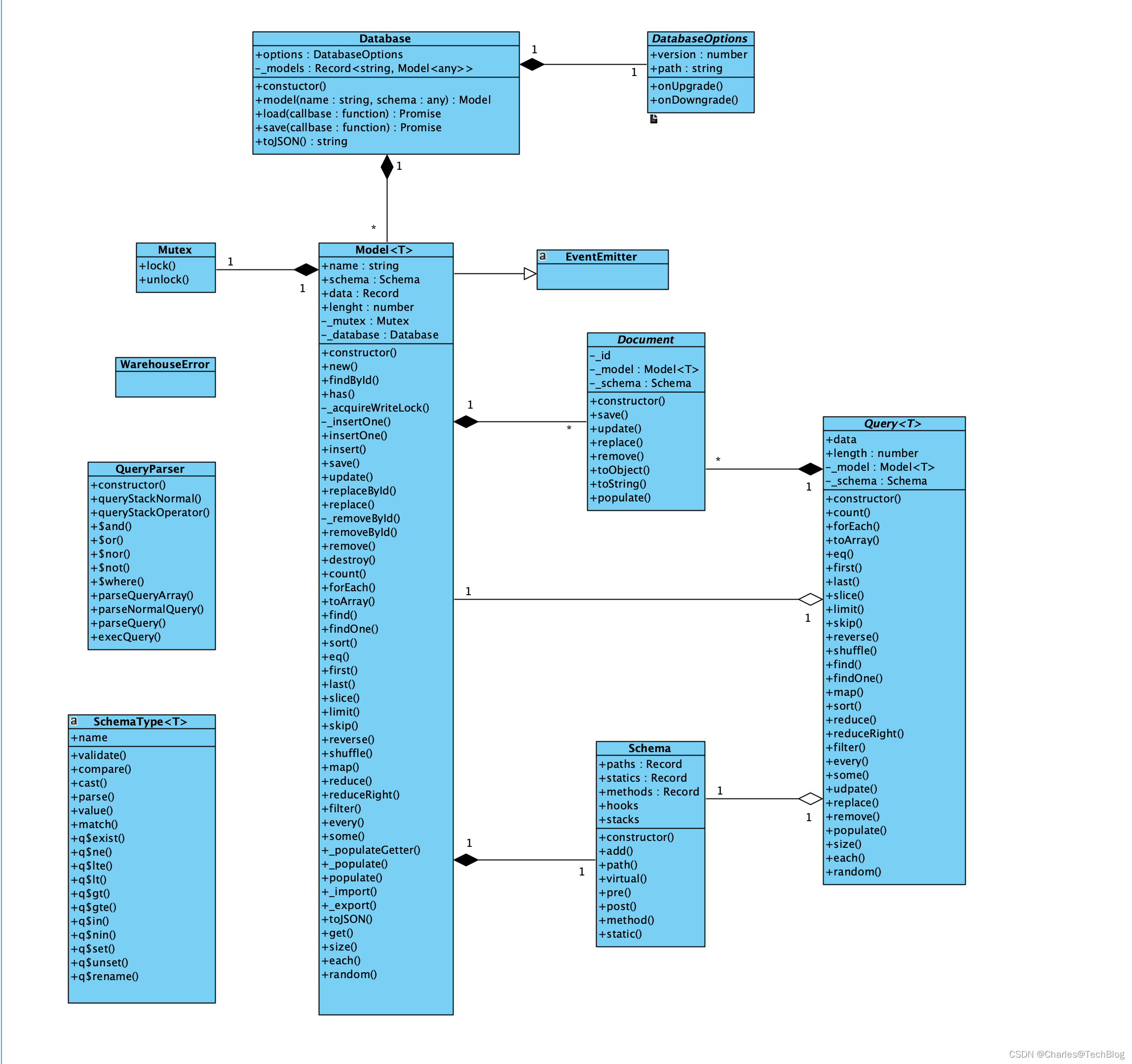
二、数据库抽象
不知道是作者的情怀使然,还是格局使然,整个软件的命名,或者说定义的各种抽象,概念都大得不得了。如果你按照自己的常识去理解,反倒会增加困难。比如项目叫 warehouse,这是数据仓库的意思,不过这个东西远远不能充当数据仓库,哈哈哈。
1. SchemaType
这个是整个系统的最基本的抽象,是对基本数据类型的封装,并抽象了所有数据类型的基本操作,比如比较之类的东西。充分利用了 TypeScript 的泛型特性。
class SchemaType<T> {
options: { required: boolean; default?: (() => T) | T; };
default: () => T;
/**
* SchemaType constructor.
*
* @param {String} name
* @param {Object} [options]
* @param {Boolean} [options.required=false]
* @param {*} [options.default]
*/
constructor(public name: string = '', options?: { required?: boolean; default?: (() => T) | T; }) {
this.options = Object.assign({
required: false
}, options);
const default_ = this.options.default;
if (typeof default_ === 'function') {
this.default = default_ as () => T;
} else {
this.default = () => default_;
}
}
//....
}
节选一点点,可以看到主要是扩展了一些属性,比如 required,表示这个字段的必选,和 default 表示缺省值等等,看着还挺像那么回事。
2. Schema
顾名思义,就好象数据库有表结构一样,这个抽象,定义了一种数据的格式,简单理解就是表结构也行。不过建议还是理解得更抽象一点,就是抽象数据结构。
这个 Schema 的特点是,除了一些具体类型,还支持虚拟或者说动态的类型,可以看到图里,有一个 virtual 方法,可以将一个方法也即 Getter 当成一个属性注册到一份 Schema 里面。
export = (ctx: Hexo) => {
const Asset = new warehouse.Schema({
_id: {type: String, required: true},
path: {type: String, required: true},
modified: {type: Boolean, default: true},
renderable: {type: Boolean, default: true}
});
Asset.virtual('source').get(function() {
return join(ctx.base_dir, this._id);
});
return Asset;
};
这是在 Hexo 的源代码里,定义了一个数据 Asset 的代码,可见用 5 个字段来描述一份附件,从调用的代码可以看出,定义了字段的名字,类型,以及一些属性,比如 required,和 default 值。也展示了 virtual 字段的用法。
3. Model
你会发现,这虽然是一个 Database,但是没有 Table,在这个系统里,抽象叫做 Model,也就是模型。如果用语言去解释的话,就是很多行相同结构的数据,确实有点像数据库的 Table,一个 Model 要且仅要包含一个 Schema,毕竟所有的数据,都需要满足相同的格式,才能存储在这里。
在 Model 里,有一个 data 字段,保存了所有的数据的一个哈希表。这些数据都要符合 Schema 的定义。length 字段描述了数据的行数。
重点看看 Model 的方法,如果你把这个 Model 理解成一个哈希表的封装,那么就可以很容易把握住这些方法的用途。主要解决增、删、改、查等功能。
4. Document
细看代码的话,就会知道 Model 里的 data 字段,key 是 _id,而 value 是 Document 类型。就是对单行数据的抽象。一行数据被称为是一个 Document,本质上的话,其实就是一个 js 的 Plain Object 的一个封装。增加了一些基本操作,toObject 还原成 Plain Object,而 populate 将数据填充到 Document。
5. Query
最后一个抽象就是查询了。其实 Query 和 Model 是一回事,但是 Model 里封装了整张“表”的数据,而 Query,是本次要提取的数据,这个所谓的数据库,当然是不支持 SQL 这种语言的,但是可以支持查询。
主要是靠 Query,利用 js 的函数式变成的一些特点,一层一层叠加过滤器上去,最后实现对数据的查询、排序。
6. Database
这个也很好理解,单行数据是一个 Plain Object,封装成 Document,很多个相同的 Document 封装成 Model,很多个 Model,就封装成 Database 了。主要处理整个数据库的持久化,和恢复加载。
三、使用
看了这个抽象的介绍,你不难想象它的用法,在数据处理的过程中,逐条插入,在内存中管理所有的数据。系统退出之前,持久化到磁盘上,下次可以载入,相当于有了一个将所有数据库载入到内存中的数据结构,而且还支持查询等功能。
整个系统采用 CommonJS 的模块标准组织的。如果你的系统里,正巧需要这么一个东西,可以考虑使用这个库。就是缺乏 一些文档,不过代码规模本身很小的,也就没多少行,在本文的辅助下,一两个小时也就看懂了。
四、设计模式
阅读这个代码的过程,我还是学到了不少东西的,比如工厂模式。当然,我早就知道设计模式,也知道工厂模式怎么写,只是没想到可以像他这样去写。
abstract class Document<T> {
abstract _model: Model<T>;
_id!: string | number | undefined;
abstract _schema: Schema;
[key : string]: any;
/**
* Document constructor.
*
* @param {object} data
*/
constructor(data?: T) {
if (data) {
Object.assign(this, data);
}
}
//....
//....
}
上面展示了一个 Document 的定义,我们可以看到,它不但是一个抽象类,还是一个泛型类。
class Model<T> extends EventEmitter {
_mutex = new Mutex();
data: Record<PropertyKey, T> = {};
schema: Schema;
length = 0;
Document;
Query;
_database: Database;
/**
* Model constructor.
*
* @param {string} name Model name
* @param {Schema|object} [schema_] Schema
*/
constructor(public name: string, schema_: Schema | Record<string, AddSchemaTypeOptions>) {
super();
let schema: Schema;
// Define schema
if (schema_ instanceof Schema) {
schema = schema_;
} else if (typeof schema_ === 'object') {
schema = new Schema(schema_);
} else {
schema = new Schema();
}
// Set `_id` path for schema
if (!schema.path('_id')) {
schema.path('_id', {type: Types.CUID, required: true});
}
this.schema = schema;
class _Document<T> extends Document<T> {
_model!: Model<T>;
_schema!: Schema;
constructor(data: T) {
super(data);
// Apply getters
schema._applyGetters(this);
}
}
this.Document = _Document;
_Document.prototype._model = this;
_Document.prototype._schema = schema;
class _Query<T> extends Query<T> {
_model!: Model<T>;
_schema!: Schema;
}
this.Query = _Query;
_Query.prototype._model = this;
_Query.prototype._schema = schema;
// Apply static methods
Object.assign(this, schema.statics);
// Apply instance methods
Object.assign(_Document.prototype, schema.methods);
}
//....
//...
}
这里展示了 Model 的定义,可以看到在 Model 的构造器里,将 Document 这个类进行了具体化,但是还保留了泛型,具体化的类,是 Model 的私有成员,也就是只有通过 Model 可以构造一个 Document 实例。这其实就是说,Model 是 Document 的工厂。
不过到这个时候,Model 的泛型还没被确定,直到到了 Database 里,会固定 Model 的泛型。也就是 Database 是 Model 的工厂。
用这种方式,将非常抽象的 Document,逐步具体化,最后成功组装在了一起,到底是怎么想到要这么写的呢?这是一种将代码保持高度抽象,在使用时候在具体化并组装的技术。对于不熟悉 js 和 TypeScript 的我来说,是很有启发的。
我认为这也是一种 TypeScript 的设计模式。只是没有人专门去提取和总结这些东西而已,只能从人家的优秀代码里去学习了。
总结
本文是 warehouse 源代码结构分析的笔记,介绍了整个系统的各个实体的抽象,解释了其核心原理,并介绍了基本的用法。最后,还介绍了逐步具体化组装代码的设计模式。展示了泛型和面向对象技术怎么共同作用,用在系统软件架构设计中的方法。希望对大家有帮助!

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)