

Apache Kafka简介
Kafka是由Apache软件基金会开发的开源流处理平台。我们可以将其用作消息系统来解耦消息生产者和消费者,但与 ActiveMQ 等“经典”消息系统相比,它旨在处理实时数据流,并提供分布式、容错和高度可扩展的架构 用于处理和存储数据。
1. 概述
在本篇文章中,我将分享 Kafka 的基础知识——任何人都应该知道的用例和核心概念。然后我们就可以研磨关于Kafka更详细的知识。
2. 什么是Kafka
Kafka是由Apache软件基金会开发的开源流处理平台。 我们可以将其用作消息系统来解耦消息生产者和消费者,但与 ActiveMQ 等“经典”消息系统相比,它旨在处理实时数据流,并提供分布式、容错和高度可扩展的架构 用于处理和存储数据。
因此,我们可以在各种用例中使用它:
- 实时数据处理和分析
- 日志和事件数据聚合
- 监控和指标收集
- 点击流数据分析
- 欺诈识别
- 大数据管道中的流处理
3. 设置本地环境
如果我们是第一次接触 Kafka,我们可能希望本地安装来体验它的功能。 在 Docker 的帮助下我们可以快速实现这一点。
3.1 安装Kafka
下载现有镜像并使用以下命令运行容器实例:
docker run -p 9092:9092 -d bashj79/kafka-kraft
这将使所谓的 Kafka 代理在主机系统的端口 9092 上可用。现在,我们想使用 Kafka 客户端连接到代理。 我们可以使用多个客户端。
3.2 使用Kafka CLI
Kafka CLI 是安装的一部分,可在 Docker 容器中使用。 我们可以通过连接到容器的 bash 来使用它。
首先,我们需要使用以下命令找出容器的名称:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7653830053fa bashj79/kafka-kraft "/bin/start_kafka.sh" 8 weeks ago Up 2 hours 0.0.0.0:9092->9092/tcp awesome_aryabhata
在此示例中,名称为 Awesome_aryabhata。然后我们使用以下命令连接到 bash:
docker exec -it awesome_aryabhata /bin/bash
例如,现在我们可以创建一个主题(稍后我们将澄清这个术语)并使用以下命令列出所有现有主题:
cd /opt/kafka/bin
# create topic 'my-first-topic'
sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-first-topic --partitions 1 --replication-factor 1# list topics
sh kafka-topics.sh --bootstrap-server localhost:9092 --list# send messages to the topic
sh kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-first-topic
>Hello World
>The weather is fine
>I love Kafka
3.3 使用Kafka Java Client
我们必须将以下 Maven 依赖项添加到我们的项目中:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.5.1</version>
</dependency>
然后我们可以连接到 Kafka 并消费之前生成的消息:
// specify connection properties
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "MyFirstConsumer");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// receive messages that were sent before the consumer started
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// create the consumer using props.
try (final Consumer<Long, String> consumer = new KafkaConsumer<>(props)) {
// subscribe to the topic.
final String topic = "my-first-topic";
consumer.subscribe(Arrays.asList(topic));
// poll messages from the topic and print them to the console
consumer
.poll(Duration.ofMinutes(1))
.forEach(System.out::println);
}
当然,这是一种Kafka Client在Spring中的集成。
4. 基础概念
4.1 生产者&消费者
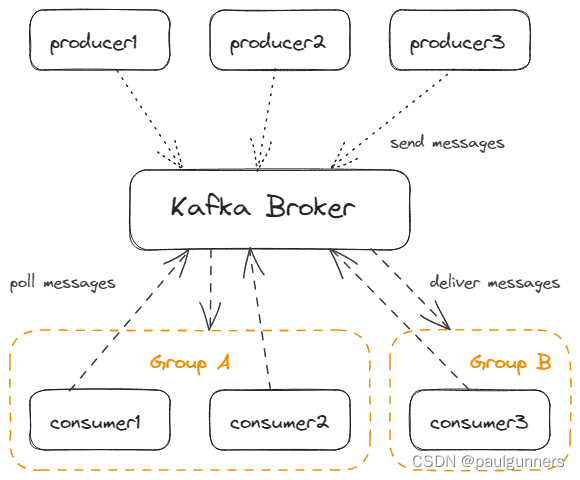
我们可以将 Kafka 客户端区分为消费者和生产者。 生产者向 Kafka 发送消息,而消费者则从 Kafka 接收消息。 他们仅通过主动从 Kafka 轮询来接收消息。 卡夫卡本身就是在以被动的方式行事。 这使得每个消费者都有自己的性能,而不会阻塞 Kafka。
当然,可以同时有多个生产者和多个消费者。当然,一个应用程序可以同时包含生产者和消费者。
消费者是消费者组的一部分,Kafka 通过一个简单的名称来识别消费者组。一个消费者组中只有一个消费者会收到该消息。这允许在保证仅一次消息传递的情况下扩展消费者。
下图是多个生产者和消费者与Kafka一起工作的情况:
4.2 消息
消息(我们也可以将其命名为“记录”或“事件”,具体取决于用例)是 Kafka 处理的数据的基本单位。 其有效负载可以是任何二进制格式以及纯文本、Avro、XML 或 JSON 等文本格式。
每个生产者都必须指定一个序列化器来将消息对象转换为二进制有效负载格式。 每个消费者必须指定相应的反序列化器来将有效负载格式转换回其 JVM 中的对象。 我们将这些组件简称为 SerDes。 有内置的 SerDes,但我们也可以实现自定义 SerDes。
下图展示了payload的序列化和反序列化过程:

此外,消息可以具有以下可选属性:
- 密钥也可以是任何二进制格式。 如果我们使用密钥,我们还需要 SerDes。 Kafka 使用键进行分区(我们将在下一章更详细地讨论这一点)。
- 时间戳指示消息的生成时间。 Kafka 使用时间戳来排序消息或实施保留策略。
- 我们可以应用标头将元数据与有效负载相关联。 例如。 Spring 默认添加用于序列化和反序列化的类型标头。
4.3 主题&分区
主题是生产者发布消息的逻辑通道或类别。消费者订阅一个主题以从其消费者组的上下文中接收消息。
默认情况下,主题的保留策略为 7 天,即 7 天后,Kafka 会自动删除消息,与是否发送给消费者无关。如果需要的话我们可以进行配置。
主题由分区(至少一个)组成。 确切地说,消息存储在主题的一个分区中。 在一个分区内,消息会获得一个顺序号(偏移量)。 这可以确保消息以与存储在分区中相同的顺序传递给消费者。 而且,通过存储消费者组已经收到的偏移量,Kafka 保证只传递一次。
通过处理多个分区,我们可以确定 Kafka 可以在消费者进程池上提供排序保证和负载平衡。
一个消费者在订阅该主题时将被分配到一个分区,例如 使用 Java Kafka 客户端 API,正如我们已经看到的:
String topic = "my-first-topic"; consumer.subscribe(Arrays.asList(topic));
However, for a consumer, it is possible to choose the partition(s) it wants to poll messages from:
TopicPartition myPartition = new TopicPartition(topic, 1); consumer.assign(Arrays.asList(myPartition));
此变体的缺点是所有组消费者都必须使用它,因此自动将分区分配给组消费者将无法与连接到特殊分区的单个消费者结合使用。 此外,如果架构发生变化(例如向组中添加更多消费者),则无法进行重新平衡。
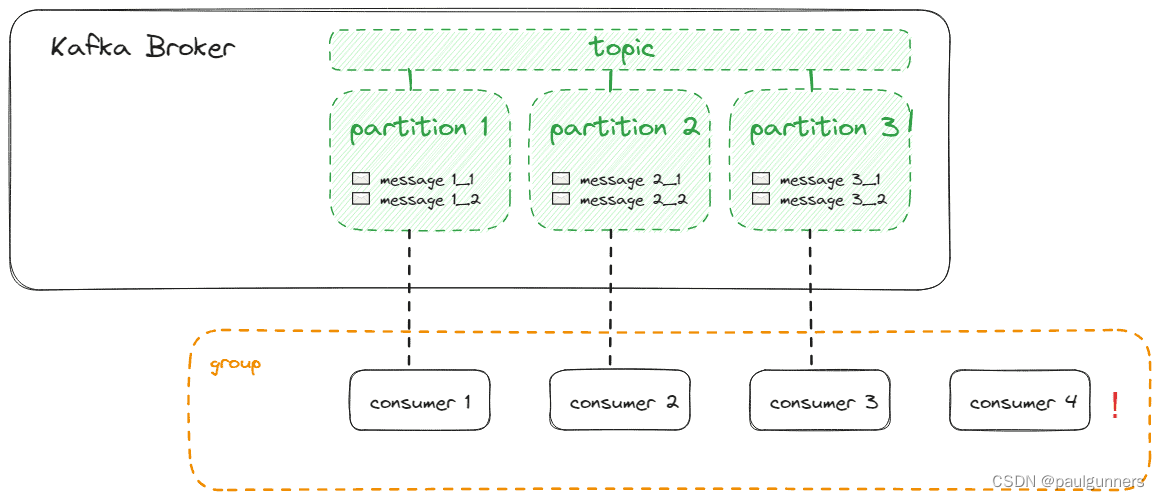
理想情况下,我们拥有与分区一样多的消费者,以便每个消费者都可以准确地分配给其中一个分区,如下所示:

如果我们的消费者多于分区,这些消费者将不会从任何分区接收消息:
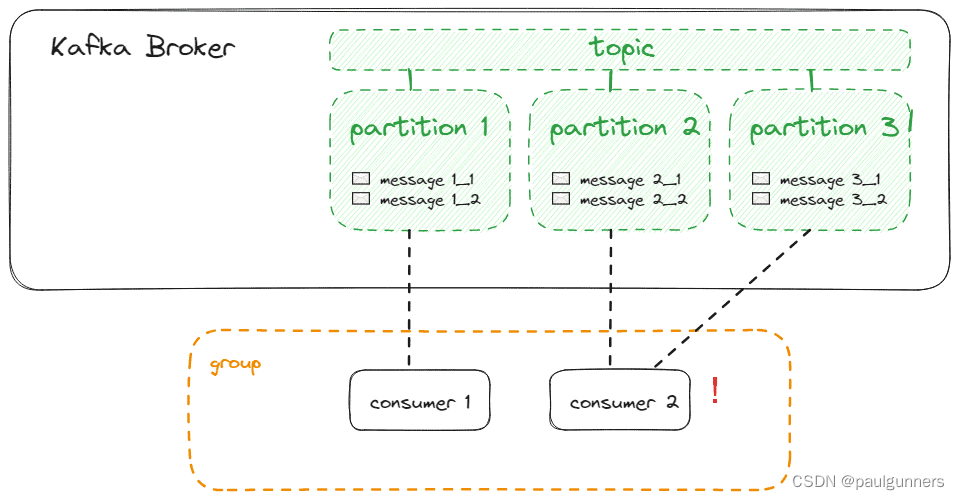
如果我们的消费者少于分区,消费者将从多个分区接收消息,这与最佳负载平衡相冲突:
生产者不一定只向一个分区发送消息。每条生成的消息都会自动分配到一个分区,遵循以下规则:
- 生产者可以指定分区作为消息的一部分。 如果这样做,这具有最高优先级
- 如果消息有密钥,则通过计算密钥的哈希值来完成分区。 具有相同哈希值的密钥将存储在同一分区中。 理想情况下,我们至少拥有与分区一样多的哈希值
- 否则,粘性分区器将消息分发到分区
同样,将消息存储到同一分区将保留消息顺序,而将消息存储到不同分区将导致无序但并行处理。
如果默认分区不符合我们的期望,我们可以简单地实现一个自定义分区器。 因此,我们实现Partitioner接口并在生产者初始化时注册它:
Properties producerProperties = new Properties();
// ...
producerProperties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyCustomPartitioner.class.getName());
KafkaProducer<String, String> producer = new KafkaProducer<>(producerProperties);
下图展示了生产者和消费者以及他们与分区的连接:
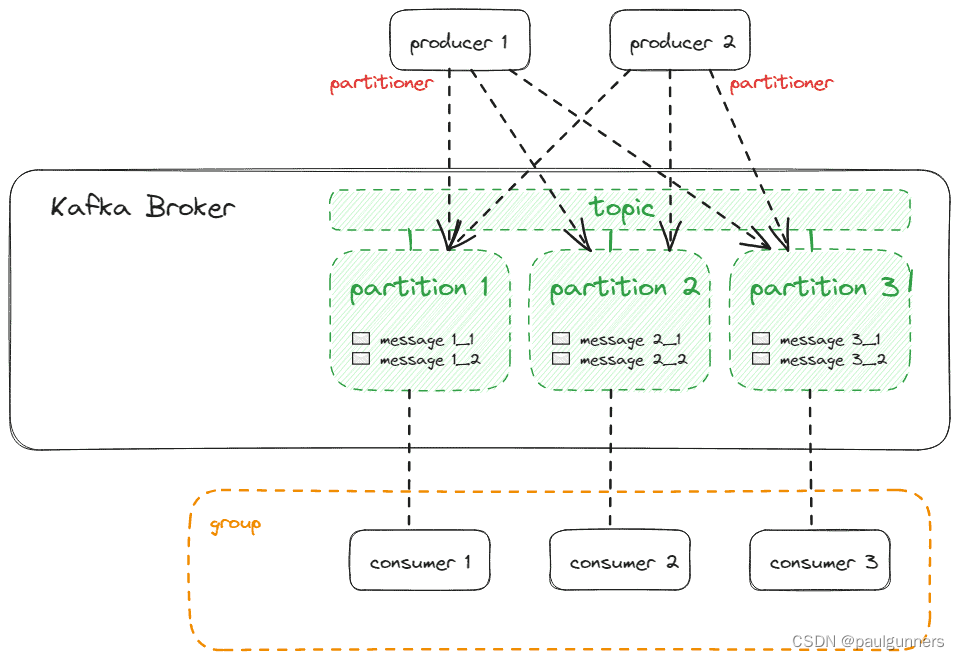
每个生产者都有自己的分区器,因此如果我们想确保消息在主题内一致地分区,我们必须确保所有生产者的分区器以相同的方式工作,或者我们应该只与单个生产者一起工作。
分区按照消息到达 Kafka 代理的顺序存储消息。 通常,生产者不会将每条消息作为单个请求发送,而是会在一批中发送多条消息。 如果我们需要确保消息的顺序以及在一个分区内只传递一次,我们需要事务感知的生产者和消费者。
4.4 集群和分区副本
正如我们所发现的,Kafka 使用主题分区来允许并行消息传递和消费者的负载平衡。 但 Kafka 本身必须具有可扩展性和容错性。 因此,我们通常不使用单个 Kafka Broker,而是使用多个 Broker 组成的集群。 这些代理的行为并不完全相同,但它们中的每一个都被分配了特殊的任务,如果一个代理发生故障,集群的其余部分可以承担这些任务。
为了理解这一点,我们需要扩大对主题的理解。 创建主题时,我们不仅指定分区的数量,还指定使用同步共同管理分区的代理的数量。 我们称之为复制因子。 例如,使用 Kafka CLI,我们可以创建一个具有 6 个分区的主题,每个分区在 3 个代理上同步:
sh kafka-topics.sh --bootstrap-server localhost:9092 --create --topic my-replicated-topic --partitions 6 --replication-factor 3
例如,复制因子为 3 意味着集群对于最多两次副本故障具有弹性(N-1 弹性)。 我们必须确保我们至少拥有与指定的复制因子一样多的代理。 否则,Kafka 不会创建主题,直到代理数量增加。
为了提高效率,分区的复制仅发生在一个方向。 Kafka 通过将其中一个代理声明为分区领导者来实现这一目标。 生产者仅向分区领导者发送消息,然后领导者与其他代理进行同步。 消费者还将向分区领导者进行轮询,因为不断增加的消费者组的偏移量也必须同步。
分区领先被分配给多个经纪人。 Kafka 尝试为不同的分区找到不同的代理。 让我们看一个具有四个代理和两个分区且复制因子为三的示例:
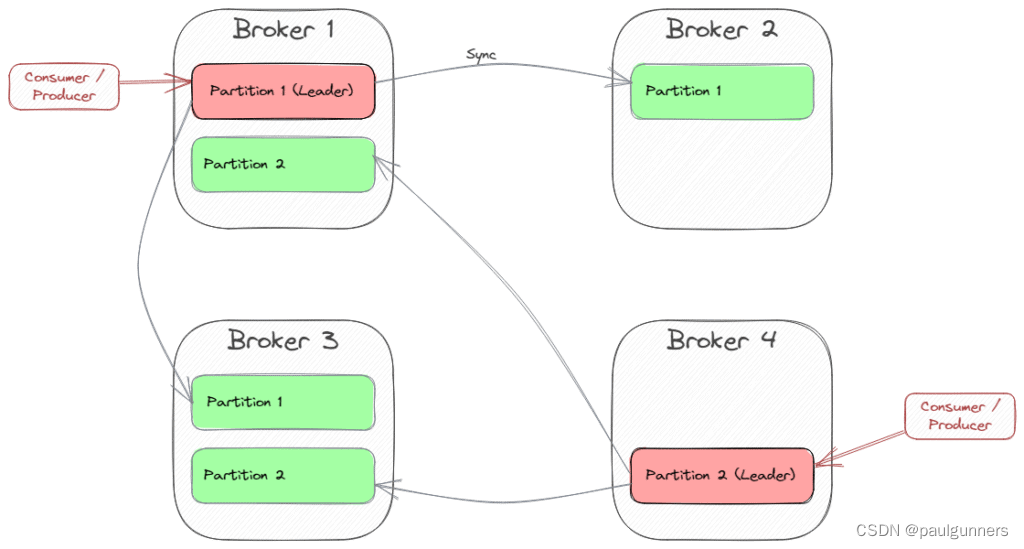 Broker 1 是分区 1 的领导者,代理 4 是分区 2 的领导者。因此,每个客户端在从这些分区发送或轮询消息时都会连接到这些代理。 为了获取有关分区领导者和其他可用代理(元数据)的信息,有一种特殊的引导机制。 总而言之,我们可以说每个代理都可以提供集群的元数据,因此客户端可以初始化与每个代理的连接,然后重定向到分区领导者。 这就是为什么我们可以指定多个代理作为引导服务器。
Broker 1 是分区 1 的领导者,代理 4 是分区 2 的领导者。因此,每个客户端在从这些分区发送或轮询消息时都会连接到这些代理。 为了获取有关分区领导者和其他可用代理(元数据)的信息,有一种特殊的引导机制。 总而言之,我们可以说每个代理都可以提供集群的元数据,因此客户端可以初始化与每个代理的连接,然后重定向到分区领导者。 这就是为什么我们可以指定多个代理作为引导服务器。
如果一个分区领导代理发生故障,Kafka 将声明仍在工作的代理之一作为新的分区领导者。 然后,所有客户端都必须连接到新的领导者。 在我们的示例中,如果 Broker 1 发生故障,Broker 2 将成为分区 1 的新领导者。然后,连接到 Broker 1 的客户端必须切换到 Broker 2。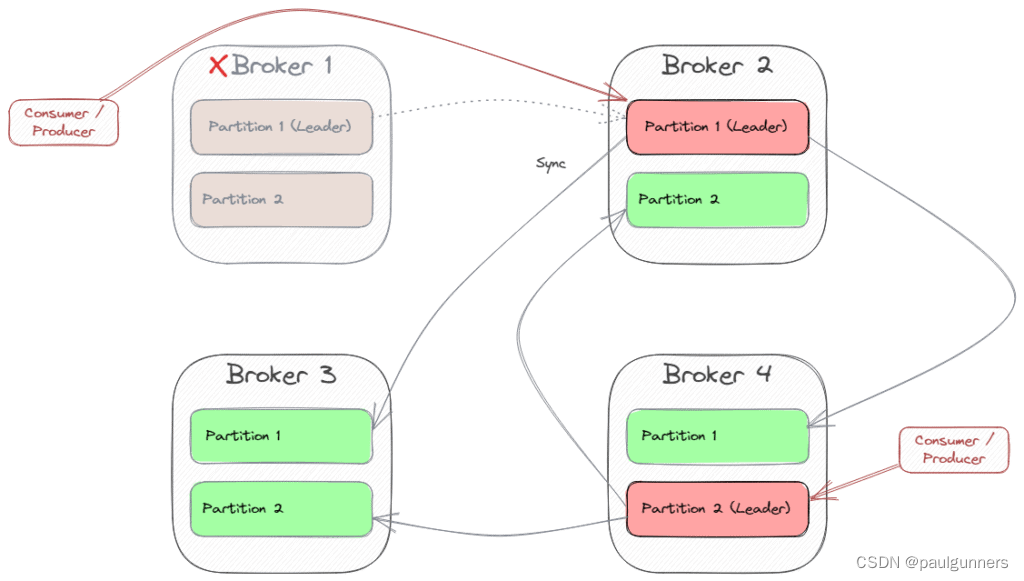
Kafka 使用 Kraft(早期版本中:Zookeeper)来编排集群内的所有代理。
4.4 将所有内容汇总
如果我们将生产者和消费者与三个代理组成的集群放在一起,这些代理管理具有三个分区和复制因子 3 的单个主题,我们将得到以下架构:
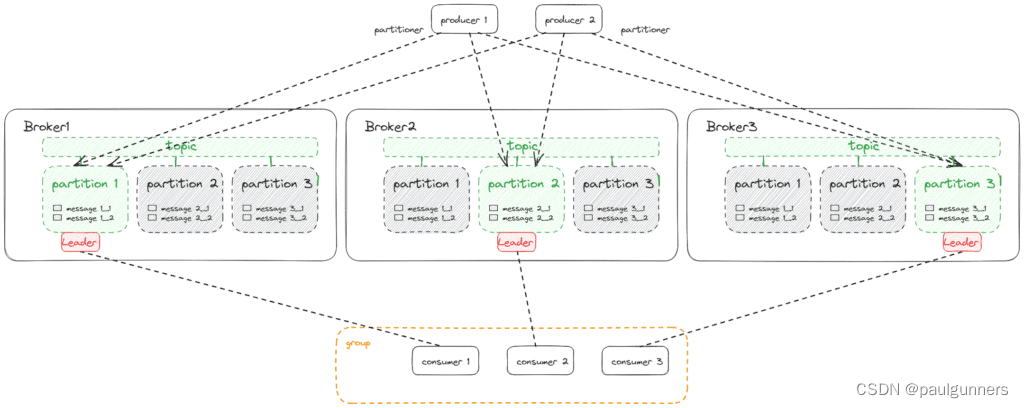
5. 生态系统
5.1 Kafka连接API
Kafka Connect是一个用于与第三方系统交换数据的API。有现有的连接器,例如用于 AWS S3、JDBC,甚至用于在不同 Kafka 集群之间交换数据。当然,我们也可以编写自定义连接器。
5.2 Kafka流API
KSQL 是一个构建在 Kafka Streams 之上的类似 SQL 的接口。 它不需要我们开发Java代码,但我们可以声明类似SQL的语法来定义与Kafka交换的消息的流处理。 为此,我们使用连接到 Kafka 集群的 ksqlDB。 我们可以使用 CLI 或 Java 客户端应用程序访问 ksqlDB。
5.3 KSQL
KSQL 是一个构建在 Kafka Streams 之上的类似 SQL 的接口。 它不需要我们开发Java代码,但我们可以声明类似SQL的语法来定义与Kafka交换的消息的流处理。 为此,我们使用连接到 Kafka 集群的 ksqlDB。 我们可以使用 CLI 或 Java 客户端应用程序访问 ksqlDB。
5.4 Kafka REST代理
Kafka REST 代理为 Kafka 集群提供 RESTful 接口。 这样,我们就不需要任何 Kafka 客户端,并避免使用原生 Kafka 协议。 它允许 Web 前端与 Kafka 连接,并可以使用 API 网关或防火墙等网络组件。
5.5 Kubernetes 的 Kafka 运算符 (Strimzi)
Strimzi 是一个开源项目,提供了一种在 Kubernetes 和 OpenShift 平台上运行 Kafka 的方法。 它引入了自定义 Kubernetes 资源,使您可以更轻松地以 Kubernetes 原生方式声明和管理 Kafka 相关资源。 它遵循操作员模式,即操作员自动执行 Kafka 集群的配置、扩展、滚动更新和监控等任务。
6. 总结
在本文中,我们了解到 Kafka 是为高可扩展性和容错能力而设计的。 生产者收集消息并批量发送,主题被划分为分区以允许并行消息传递和消费者的负载平衡,并且通过多个代理完成复制以确保容错。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)