
JVM coredump分析系列(6):使用AttachCurrentThread出现Crash分析
问题现象近期笔者收到用户反映在大数据场景下遇到一个奇怪的问题,用户的 ClickHouse 服务使用 hadoop-hdfs-native-client(libhdfs)操作 HDFS 文件一直失败。libhdfs 是一个基于 JNI 的 C API,它为部分 HDFS API 提供 C 的 API 以供 C/C++ 程序操作 HDFS 文件和文件系统,简单说就是用户的 C++ 服务需要使用 li
问题现象
近期笔者收到用户反映在大数据场景下遇到一个奇怪的问题,用户的 ClickHouse 服务使用 hadoop-hdfs-native-client(libhdfs)操作 HDFS 文件一直失败。libhdfs 是一个基于 JNI 的 C API,它为部分 HDFS API 提供 C 的 API 以供 C/C++ 程序操作 HDFS 文件和文件系统,简单说就是用户的 C++ 服务需要使用 libhdfs 这种 JNI 的方式与 HDFS(Java服务)进行交互,出现问题的代码为 jni_helper.c 中的 getGlobalJNIEnv[1]:
static JNIEnv* getGlobalJNIEnv(void)
{
......
// 获取当前进程已经创建的JVM
rv = JNI_GetCreatedJavaVMs(&(vmBuf[0]), VM_BUF_LENGTH, &noVMs);
if (rv != 0) {
fprintf(stderr, "JNI_GetCreatedJavaVMs failed with error: %d\n", rv);
return NULL;
}
if (noVMs == 0) {
......
//Create the VM
rv = JNI_CreateJavaVM(&vm, (void*)&env, &vm_args);
......
} else {
//Attach this thread to the VM
vm = vmBuf[0];
rv = (*vm)->AttachCurrentThread(vm, (void*)&env, 0);
if (rv != 0) {
fprintf(stderr, "Call to AttachCurrentThread "
"failed with error: %d\n", rv);
return NULL;
}
}
return env;
}这块逻辑比较简单,先尝试去获取当前进程已经创建的 JVM,如果获取不到就去创建一个新的 JVM,如果能获取到就将当前线程 attach 到已经创建好的 JVM 上以获取 JNIEnv,供后续交互使用。其中在 rv = (*vm)->AttachCurrentThread(vm, (void*)&env, 0); 这一步时一直失败,rv 返回 -1 导致报错 Call to AttachCurrentThread failed。
问题分析
1. AttachCurrentThread
让我们来简单梳理下 AttachCurrentThread 的逻辑(以下代码皆只说明 Hotspot 在 Linux 中的具体实现),用户的 C++ 进程想要反调 Java 层的代码,但是 Java 层对自己的线程做了一个包装(即Java thread),C++ 进程创建的线程对 JVM 来说是不相关的,C++ 线程需要通过 AttachCurrentThread 将自己 wrap 成一个 Java 层面的线程(Java thread),JVM 才能感知到这个线程并进行后续的调用操作。
查看 AttachCurrentThread 的代码逻辑:
jint JNICALL jni_AttachCurrentThread(JavaVM *vm, void **penv, void *_args) {
......
JNIWrapper("AttachCurrentThread");
jint ret = attach_current_thread(vm, penv, _args, false);
......
return ret;
}
static jint attach_current_thread(JavaVM *vm, void **penv, void *_args, bool daemon) {
......
Thread* t = ThreadLocalStorage::get_thread_slow();
if (t != NULL) {
// If the thread has been attached this operation is a no-op
*(JNIEnv**)penv = ((JavaThread*) t)->jni_environment();
return JNI_OK;
}
// Create a thread and mark it as attaching so it will be skipped by the
// ThreadsListEnumerator - see CR 6404306
JavaThread* thread = new JavaThread(true);
......
thread->set_thread_state(_thread_in_vm);
// Must do this before initialize_thread_local_storage
thread->record_stack_base_and_size();
thread->initialize_thread_local_storage();
if (!os::create_attached_thread(thread)) {
delete thread;
return JNI_ERR;
}
// Enable stack overflow checks
thread->create_stack_guard_pages();
thread->initialize_tlab();
thread->cache_global_variables();
......
// Create Java level thread object and attach it to this thread
bool attach_failed = false;
{
EXCEPTION_MARK;
HandleMark hm(THREAD);
Handle thread_group(THREAD, group);
thread->allocate_threadObj(thread_group, thread_name, daemon, THREAD);
if (HAS_PENDING_EXCEPTION) {
CLEAR_PENDING_EXCEPTION;
// cleanup outside the handle mark.
attach_failed = true;
}
}
if (attach_failed) {
// Added missing cleanup
thread->cleanup_failed_attach_current_thread();
return JNI_ERR;
}
......
return JNI_OK;
}我们可以看到在 attach_current_thread 中返回 JNI_ERR 的地方有两处,第一处在 os::create_attached_thread(thread) 创建失败时报错,查看 create_attached_thread 逻辑:
// Allocate the OSThread object
OSThread* osthread = new OSThread(NULL, NULL);
if (osthread == NULL) {
return false;
}此处的 new OSThread 只是创建了一个空的 OSThread 对象(用来描述 OS 对应的线程的信息,如 Linux 上对应 pthread),此处在内存空间充足的情况下基本不会失败。
主要怀疑方向还是在第二处逻辑,thread->allocate_threadObj 的过程中可能抛出了异常,导致判断 HAS_PENDING_EXCEPTION 状态为 true,最后 attach 失败。allocate_threadObj 方法主要是用于创建一个 Java 级别的线程对象(java.lang.Thread对象):
void JavaThread::allocate_threadObj(Handle thread_group, char* thread_name, bool daemon, TRAPS) {
......
Klass* k = SystemDictionary::resolve_or_fail(vmSymbols::java_lang_Thread(), true, CHECK);
instanceKlassHandle klass (THREAD, k);
instanceHandle thread_oop = klass->allocate_instance_handle(CHECK);
java_lang_Thread::set_thread(thread_oop(), this);
java_lang_Thread::set_priority(thread_oop(), NormPriority);
set_threadObj(thread_oop());
JavaValue result(T_VOID);
if (thread_name != NULL) {
Handle name = java_lang_String::create_from_str(thread_name, CHECK);
// Thread gets assigned specified name and null target
JavaCalls::call_special(&result,
thread_oop,
klass,
vmSymbols::object_initializer_name(),
vmSymbols::threadgroup_string_void_signature(),
thread_group, // Argument 1
name, // Argument 2
THREAD);
} else {
// Thread gets assigned name "Thread-nnn" and null target
// (java.lang.Thread doesn't have a constructor taking only a ThreadGroup argument)
JavaCalls::call_special(&result,
thread_oop,
klass,
vmSymbols::object_initializer_name(),
vmSymbols::threadgroup_runnable_void_signature(),
thread_group, // Argument 1
Handle(), // Argument 2
THREAD);
}通过调试发现,果然在 thread->allocate_threadObj 的 JavaCalls 这一步时抛出了异常(简单提一下,Java 层可以通过 JNICall 进入 JVM 层调用 native 方法,而 JVM 层也可以通用 JavaCall 进入 Java 层调用 Java 方法):

异常出现的位置为:
void JavaCalls::call_helper(JavaValue* result, methodHandle* m, JavaCallArguments* args, TRAPS) {
......
// Check that there are shadow pages available before changing thread state
// to Java
if (!os::stack_shadow_pages_available(THREAD, method)) {
// Throw stack overflow exception with preinitialized exception.
Exceptions::throw_stack_overflow_exception(THREAD, __FILE__, __LINE__, method);
return;
} else {
// Touch pages checked if the OS needs them to be touched to be mapped.
os::bang_stack_shadow_pages();
}
......
}问题出现在 stack_shadow_pages_available 的校验逻辑之中,该逻辑为判断线程的 shadow page 是否可用,如果不可用就会抛出堆栈溢出的异常:
// Returns true if the current stack pointer is above the stack shadow
// pages, false otherwise.
bool os::stack_shadow_pages_available(Thread *thread, methodHandle method) {
assert(StackRedPages > 0 && StackYellowPages > 0,"Sanity check");
address sp = current_stack_pointer();
// Check if we have StackShadowPages above the yellow zone. This parameter
// is dependent on the depth of the maximum VM call stack possible from
// the handler for stack overflow. 'instanceof' in the stack overflow
// handler or a println uses at least 8k stack of VM and native code
// respectively.
const int framesize_in_bytes =
Interpreter::size_top_interpreter_activation(method()) * wordSize;
int reserved_area = ((StackShadowPages + StackRedPages + StackYellowPages)
* vm_page_size()) + framesize_in_bytes;
// The very lower end of the stack
address stack_limit = thread->stack_base() - thread->stack_size();
return (sp > (stack_limit + reserved_area));
}2. Java thread
查看 shadow page 是否可用就要去梳理下 Java Thread 的相关知识,在 HotSpot 的 Linux 实现中,Java thread 模型如下所示:
// Java thread:
//
// Low memory addresses
// +------------------------+
// | |\ JavaThread created by VM does not have glibc
// | glibc guard page | - guard, attached Java thread usually has
// | |/ 1 page glibc guard.
// P1 +------------------------+ Thread::stack_base() - Thread::stack_size()
// | |\
// | HotSpot Guard Pages | - red, yellow and (reserved) pages
// | |/
// +------------------------+ JavaThread::stack_yellow_zone_base()
// | |\
// | Normal Stack | -
// | |/
// P2 +------------------------+ Thread::stack_base()
//其中 HotSpot 会为 Java thread 分配一些保护页(相关知识可以查阅 Stack Overflow handling in HotSpot JVM[2]),展开来看即:

(1)Reserved pages:JDK 9 及以后版本添加,通过预留部分内存,解决在关键部分(如执行 ReentrantLock.lock()、unlock() 时)发生 StackOverflowError 导致的死锁问题,详见 JEP270[3]。
(2)Yellow pages:线程堆栈如果一直上涨触碰到 Yellow pages 的区域,就会发生 StackOverflowError 的异常。
(3)Redpages:线程堆栈如果一直上涨触碰到 Red pages 的区域,就会发生 Crash 导致虚拟机崩溃。
(4)Shadow pages:通过预留部分内存,防止调到 Native 方法时发生堆栈溢出。
需要注意的是 Stack 通常是从高地址往低地址增长的,与普通 Mapping 映射内存、申请 Heap 内存时的从低地址往高地址增长不同,此处不再赘述。
简单来说就是 HotSpot 需要为线程预留一些空间作为保护页,预留的大小即 stack_shadow_pages_available 逻辑中的 int reserved_area = ((StackShadowPages + StackRedPages + StackYellowPages) * vm_page_size()) + framesize_in_bytes;(JDK8 未引入 Reserved pages),我们此时的 sp(或者说 stack_pointer,即堆栈当前的深度)的地址是要大于 Stack limit + reserved_area 才是能保证线程堆栈不会发生溢出等异常的,如果此时的 stack_pointer 地址已经小于 Stack limit + reserved_area 的地址,说明我们已经触碰或者越过了 Hotspot 的保护页区域,此时可能已经溢出或者发生错位了。
至于我们的为何会溢出,我们目前只能猜测在 stack_shadow_pages_available 的校验逻辑之前就已经发生了错误,甚至可能在 C++ 线程 attach JVM 之前就已经发生了溢出。
3. Crash
为了输出更多的信息,我们使用了 debug 级别的 JDK 进行调试,结果程序运行到 AttachCurrentThread 的时候直接发生了如下 Crash:
#
# A fatal error has been detected by the Java Runtime Environment:
#
# Internal Error (/jdk8u/hotspot/src/os_cpu/linux_x86/vm/os_linux_x86.cpp:743), pid=4101053, tid=0x00007ff4b2bf4700
# assert(os::current_stack_pointer() >= *bottom && os::current_stack_pointer() < *bottom + *size) failed: just checking
......调试 coredump:
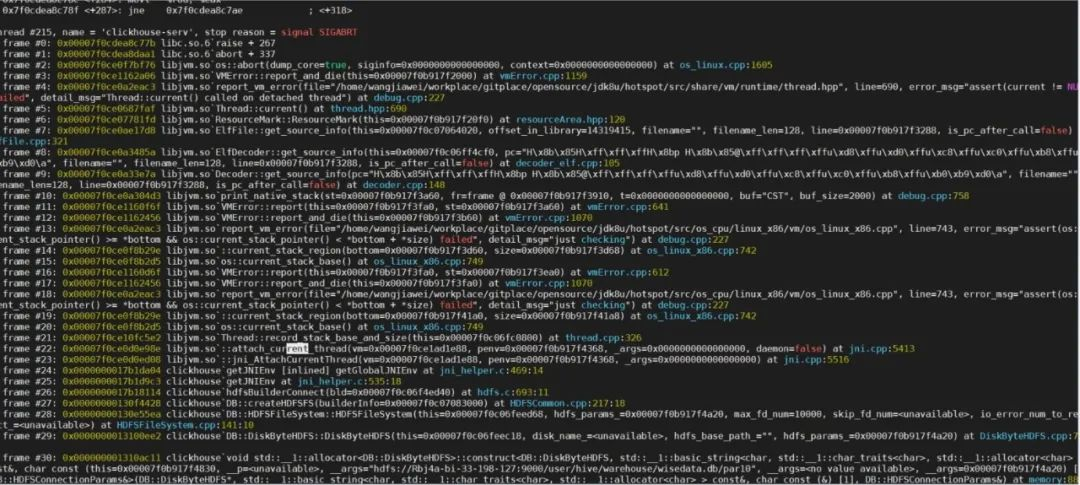
可以发现 Crash 发生在 thread->allocate_threadObj 之前的 thread->record_stack_base_and_size() 逻辑之中,record_stack_base_and_size 是做什么的呢?简单说就是我们需要将 C++ 创建的线程 wrap 成一个 Java thread,就需要将 C++ 线程或者说操作系统标准的 pthread 线程的一些信息如:栈顶地址、栈大小、操作系统线程id等等保存到 Java thread 之中,这样 Java Thread 就可以去代表这个 C++ 线程/系统线程,record_stack_base_and_size 正是用来设置栈顶地址和栈大小的方法。
按照 coredump 堆栈一路追踪:
void Thread::record_stack_base_and_size() {
set_stack_base(os::current_stack_base());
set_stack_size(os::current_stack_size());
......
}
address os::current_stack_base() {
address bottom;
size_t size;
current_stack_region(&bottom, &size);
return (bottom + size);
}
size_t os::current_stack_size() {
// stack size includes normal stack and HotSpot guard pages
address bottom;
size_t size;
current_stack_region(&bottom, &size);
return size;
}current_stack_base 和 current_stack_size 都会走到 current_stack_region 逻辑之中:
static void current_stack_region(address * bottom, size_t * size) {
if (os::is_primordial_thread()) {
// primordial thread needs special handling because pthread_getattr_np()
// may return bogus value.
*bottom = os::Linux::initial_thread_stack_bottom();
*size = os::Linux::initial_thread_stack_size();
} else {
pthread_attr_t attr;
int rslt = pthread_getattr_np(pthread_self(), &attr);
// JVM needs to know exact stack location, abort if it fails
if (rslt != 0) {
if (rslt == ENOMEM) {
vm_exit_out_of_memory(0, OOM_MMAP_ERROR, "pthread_getattr_np");
} else {
fatal(err_msg("pthread_getattr_np failed with errno = %d", rslt));
}
}
if (pthread_attr_getstack(&attr, (void **)bottom, size) != 0) {
fatal("Can not locate current stack attributes!");
}
pthread_attr_destroy(&attr);
}
assert(os::current_stack_pointer() >= *bottom &&
os::current_stack_pointer() < *bottom + *size, "just checking");
}
address os::current_stack_pointer() {
#ifdef SPARC_WORKS
void *esp;
__asm__("mov %%"SPELL_REG_SP", %0":"=r"(esp));
return (address) ((char*)esp + sizeof(long)*2);
#elif defined(__clang__)
void* esp;
__asm__ __volatile__ ("mov %%"SPELL_REG_SP", %0":"=r"(esp):);
return (address) esp;
#else
register void *esp __asm__ (SPELL_REG_SP);
return (address) esp;
#endif
}让我们来梳理一下 current_stack_region 的逻辑,首先 primordial thread 是进程的初始线程(详情可以参见R大的回答[4]),HotSpot 无法对它做额外的控制(例如说设定栈大小),所以它的 bottom、size 获取方式是另外一套逻辑。 很明显我们此时的线程并不是初始线程,我们会走到下面的逻辑当中。下面的逻辑也相当简单,使用 pthread 库提供的标准API:pthread_attr_getstack[5] 去获取当前这个进行 attach 的线程的堆栈起始地址 bottom、堆栈大小 size,然后通过读取 sp 寄存器(取决于不同的机器与架构,可能叫 esp/rsp/csp 等等)获取线程当前的堆栈深度 Stack pointer,理论上讲一个正常的 pthread 线程,此时的 Stack pointer 一定是在 bottom 与 bottom + size 之间的,即:

但是我们在断言 assert(os::current_stack_pointer() >= *bottom && os::current_stack_pointer() < *bottom + *size, "just checking"); 处直接失败导致发生了 Crash,说明此时 sp 寄存器的值早已不在 pthread 的堆栈范围之内了,该线程在进行 attach JVM 之前就已经出现了问题。
我们在 jni_helper.c 调用 AttachCurrentThread 方法之前加入如下代码来打印 pthread 的相关信息:
size_t size;
char* bottom;
pthread_attr_t attr;
int rslt = pthread_getattr_np(pthread_self(), &attr);
pthread_attr_getstack(&attr, (void**)&bottom, &size);
fprintf(stderr, "size = %d, bottom = %p\n", size, bottom);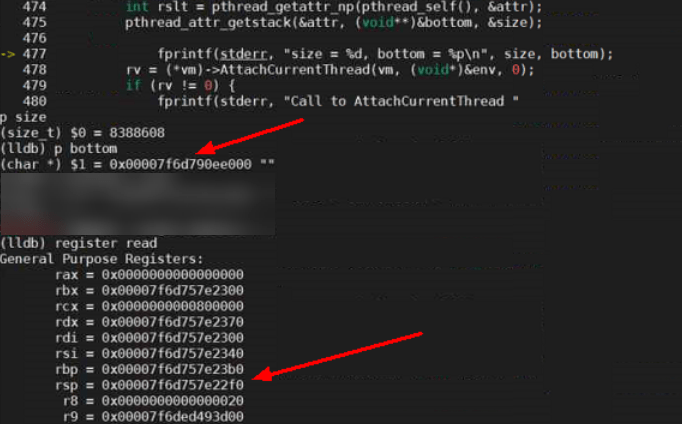
果然,此时线程堆栈的低位地址 bottom 为 0x00007f6d790ee000,size 为 8388608,通过计算我们可以得出该线程堆栈的地址范围在 0x00007f6d790ee000-0x00007f6d798ee000(bottom+size)之间,而此时 sp 寄存器中储存的地址值是 0x00007f6d757e22f0,sp 寄存器中的地址已不在 pthread 的线程堆栈范围之间,且是个低于线程堆栈 bottom 数十兆的地址。
在 Linux 上 HotSpot 对于完全受控的 Java 线程(JVM 自己创建的线程)可以通过调用 pthread_create() 传入栈大小,然后让 libpthread 自己去分配空间,而不是自行申请了栈空间然后通知 pthread 直接使用那块空间。对于已经创建好的线程要 attach 到 JVM 上的情况,那个线程之前是如何创建、其中的栈是如何分配的,HotSpot 是管不到的,即进行 attach 的线程是不受控的线程。
现在 JVM 已经撇清了关系,但是问题还没有解决,我们需要去查看那个神奇的 C++ 线程当前的现象是如何造成的(sp 在一个比较离谱的位置且未触发到 Glibc 设置的保护页)。继续追踪堆栈信息,我们发现用户的 ClickHouse 进程中使用了一个开源 rpc 库 brpc,而 brpc 库会去创建自己实现的用户级线程/协程 bthread:
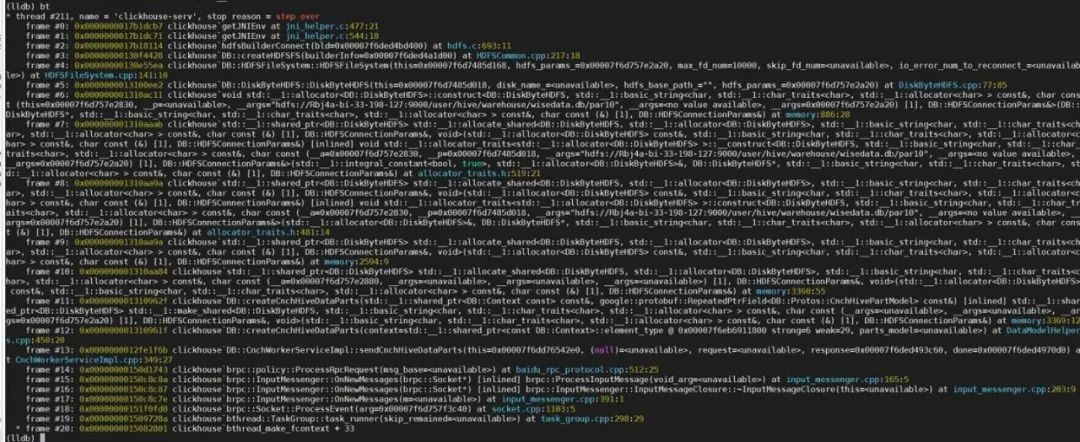
4. bthread
目前最大的嫌疑就落在了 bthread 上,笔者研究了一下 bthread 源码[6](文章如有不正确之处敬请指正),发现该线程库存在两种线程概念分别是 worker_thread(或者说 worker pthread)和 bthread。 首先是 worker_thread:
int TaskControl::init(int concurrency) {
......
for (int i = 0; i < _concurrency; ++i) {
const int rc = pthread_create(&_workers[i], NULL, worker_thread, this);
if (rc) {
LOG(ERROR) << "Fail to create _workers[" << i << "], " << berror(rc);
return -1;
}
}
......
}
void* TaskControl::worker_thread(void* arg) {
......
TaskControl* c = static_cast<TaskControl*>(arg);
TaskGroup* g = c->create_group();
......
}我们可以看到 worker_thread 其实是使用 pthread_create 创建的标准的 Linux 线程,同时 worker_thread 也是从操作系统角度用来调度的线程,是用户自己设计的线程 bthread 运行的底座。 然后 worker_thread 会去创建一个 TaskGroup,这个 TaskGroup 对应着的就是一组 bthread,在创建并运行 bthread 的时候(不论是 start_foreground 还是 start_background)都会将创建好的 bthread 通过 ready_to_run/ready_to_run_remote 加入到 TaskGroup 的队列之中:
int TaskGroup::start_foreground(TaskGroup** pg, bthread_t* __restrict th, const bthread_attr_t* __restrict attr, void * (*fn)(void*), void* __restrict arg) {
......
if (g->is_current_pthread_task()) {
// never create foreground task in pthread.
g->ready_to_run(m->tid, (using_attr.flags & BTHREAD_NOSIGNAL));
}
......
}
template <bool REMOTE>
int TaskGroup::start_background(bthread_t* __restrict th, const bthread_attr_t* __restrict attr, void * (*fn)(void*), void* __restrict arg) {
......
if (REMOTE) {
ready_to_run_remote(m->tid, (using_attr.flags & BTHREAD_NOSIGNAL));
} else {
ready_to_run(m->tid, (using_attr.flags & BTHREAD_NOSIGNAL));
}
return 0;
}从操作系统的角度来说,进程调度运行的依然是 worker_thread(即一个标准的 pthread,或者说系统级线程),但是worker_thread作为底座,上面跑的其实是用户自定义的 bthread。
这里简单地补充下相关的知识,我们可以将线程看作是一个执行指令序列的实体,指令的执行依赖指令指针寄存器和栈指针寄存器等,通常它们放到一起被称为线程上下文(context),正常的系统级线程上下文切换需要把用户态堆栈、寄存器等信息保存到内核态,而为了节省用户态内核态之间的切换开销,可以将上下文的信息保存到用户态的空间之中,协程/用户级线程的原理就是通过自己实现寄存器、栈信息等的保存与恢复在用户态中完成上下文切换。到 bthread 这里就是,一个 worker_thread(系统级线程 pthread)上跑的是一个 bthread(用户级线程),bthread 因 bthread API 而阻塞后会通过自己实现的上下文切换将 worker_thread 让给另一个 bthread 运行,当然 worker_thread 也可能因为 pthread API 或者系统调度之类的原因而发生阻塞,此时其他空闲的 worker_thread 便会将该 bthread 窃取过去继续运行:
bool TaskControl::steal_task(bthread_t* tid, size_t* seed, size_t offset) {
......
if (g) {
if (g->_rq.steal(tid)) {
stolen = true;
break;
}
if (g->_remote_rq.pop(tid)) {
stolen = true;
break;
}
......
}至于这个上下文的切换是如何自己实现的呢?笔者发现 bthread 使用了业界著名的协程库 Boost.Context[7],首先我们来看下 bthread 自身的创建逻辑:
template <typename StackClass> struct StackFactory {
struct Wrapper : public ContextualStack {
explicit Wrapper(void (*entry)(intptr_t)) {
if (allocate_stack_storage(&storage, *StackClass::stack_size_flag,
FLAGS_guard_page_size) != 0) {
storage.zeroize();
context = NULL;
return;
}
context = bthread_make_fcontext(storage.bottom, storage.stacksize, entry);
stacktype = (StackType)StackClass::stacktype;
}
......
};
int allocate_stack_storage(StackStorage* s, int stacksize_in, int guardsize_in) {
......
if (guardsize_in <= 0) {
void* mem = malloc(stacksize);
if (NULL == mem) {
PLOG_EVERY_SECOND(ERROR) << "Fail to malloc (size="
<< stacksize << ")";
return -1;
}
s_stack_count.fetch_add(1, butil::memory_order_relaxed);
s->bottom = (char*)mem + stacksize;
s->stacksize = stacksize;
......
} else {
// Align guardsize
const int guardsize =
(std::max(guardsize_in, MIN_GUARDSIZE) + PAGESIZE_M1) &
~PAGESIZE_M1;
const int memsize = stacksize + guardsize;
void* const mem = mmap(NULL, memsize, (PROT_READ | PROT_WRITE),
(MAP_PRIVATE | MAP_ANONYMOUS), -1, 0);
if (MAP_FAILED == mem) {
PLOG_EVERY_SECOND(ERROR)
<< "Fail to mmap size=" << memsize << " stack_count="
<< s_stack_count.load(butil::memory_order_relaxed)
<< ", possibly limited by /proc/sys/vm/max_map_count";
// may fail due to limit of max_map_count (65536 in default)
return -1;
}
......
s->bottom = (char*)mem + memsize;
s->stacksize = stacksize;
s->guardsize = guardsize;
......
}
}我们可以发现 bthread 使用 allocate_stack_storage 申请了自身的堆栈空间,而 allocate_stack_storage 则是通过 malloc/mmap 的方式在进程的 Heap/Mapping Memory 中分配了内存。申请完堆栈空间后,就会进入到 bthread_make_fcontext 的逻辑(即 Boost.Context 的 make fcontext)为该线程设置上下文信息:
#if defined(BTHREAD_CONTEXT_PLATFORM_linux_x86_64) && defined(BTHREAD_CONTEXT_COMPILER_gcc)
__asm (
".text\n"
".globl bthread_make_fcontext\n"
".type bthread_make_fcontext,@function\n"
".align 16\n"
"bthread_make_fcontext:\n"
" movq %rdi, %rax\n"
" andq $-16, %rax\n"
" leaq -0x48(%rax), %rax\n"
" movq %rdx, 0x38(%rax)\n"
" stmxcsr (%rax)\n"
" fnstcw 0x4(%rax)\n"
" leaq finish(%rip), %rcx\n"
" movq %rcx, 0x40(%rax)\n"
" ret \n"
"finish:\n"
" xorq %rdi, %rdi\n"
" call _exit@PLT\n"
" hlt\n"
".size bthread_make_fcontext,.-bthread_make_fcontext\n"
".section .note.GNU-stack,\"\",%progbits\n"
".previous\n"
);同样的,当我们需要切换 bthread 的时候,比如 TaskGroup::sched_to 调度的时候,我们也会切换 bthread 的上下文:
void TaskGroup::sched(TaskGroup** pg) {
......
if (cur_meta->stack != NULL) {
if (next_meta->stack != cur_meta->stack) {
jump_stack(cur_meta->stack, next_meta->stack);
......
}
......
}
......
}
inline void jump_stack(ContextualStack* from, ContextualStack* to) {
bthread_jump_fcontext(&from->context, to->context, 0/*not skip remained*/);
}
#if defined(BTHREAD_CONTEXT_PLATFORM_linux_x86_64) && defined(BTHREAD_CONTEXT_COMPILER_gcc)
__asm (
".text\n"
".globl bthread_jump_fcontext\n"
".type bthread_jump_fcontext,@function\n"
".align 16\n"
"bthread_jump_fcontext:\n"
" pushq %rbp \n"
" pushq %rbx \n"
" pushq %r15 \n"
" pushq %r14 \n"
" pushq %r13 \n"
" pushq %r12 \n"
" leaq -0x8(%rsp), %rsp\n"
" cmp $0, %rcx\n"
" je 1f\n"
" stmxcsr (%rsp)\n"
" fnstcw 0x4(%rsp)\n"
"1:\n"
" movq %rsp, (%rdi)\n"
" movq %rsi, %rsp\n"
" cmp $0, %rcx\n"
" je 2f\n"
" ldmxcsr (%rsp)\n"
" fldcw 0x4(%rsp)\n"
"2:\n"
" leaq 0x8(%rsp), %rsp\n"
" popq %r12 \n"
" popq %r13 \n"
" popq %r14 \n"
" popq %r15 \n"
" popq %rbx \n"
" popq %rbp \n"
" popq %r8\n"
" movq %rdx, %rax\n"
" movq %rdx, %rdi\n"
" jmp *%r8\n"
".size bthread_jump_fcontext,.-bthread_jump_fcontext\n"
".section .note.GNU-stack,\"\",%progbits\n"
".previous\n"
);我们观察汇编的具体实现可以发现存在 movq %rsi, %rsp,此时将 rsi 寄存器的值(即 next_meta->stack,是将要切换到的 bthread 的上下文)传给了 rsp,即此时的栈顶指针 rsp 指向了新的协程栈。此处不再展开来讲,详情可以参考 brpc 官方资料[8]。
按照我们看到的 bthread 的逻辑,基本上是可以和我们 Crash 的现场对应上的,sp 指向的地址为 bthread 通过 mmap 申请的内存空间之中,是一个比 pthread 堆栈所在 Stack 区域低的多的地址:
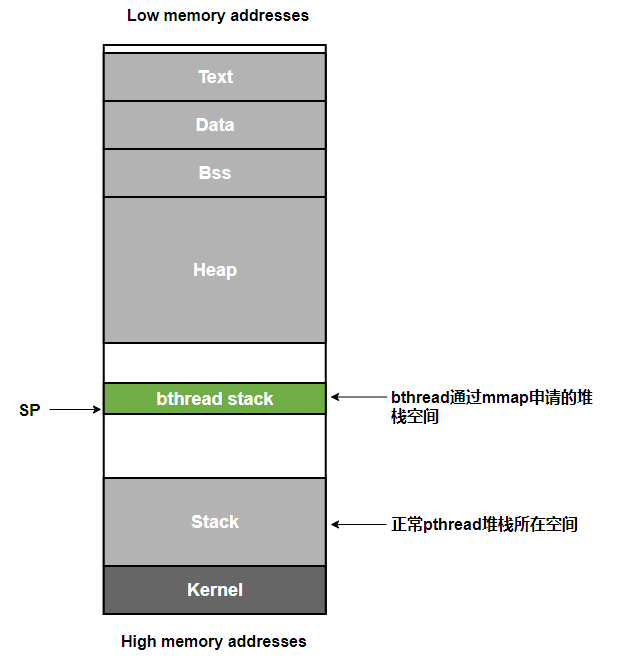
验证
用户场景较为复杂,我们可以抽取核心逻辑自己写一个简单的 Demo 来复现问题。 brpc 库的编译使用可以参考 brpc 官网教程[9],JDK 则可以使用毕昇 JDK(下载地址[10]),为了方便大家调试与排查问题,毕昇 JDK 贴心地提供了对应的debuginfo,按照使用指导[11]挂载 debuginfo 信息后即可愉快地调试 JVM/CoreDump。如果你想自行编译 debug 版本的 JDK,同样可以下载毕昇 JDK8源码[12],然后通过如下命令编译即可:
bash configure --with-debug-level=fastdebug --with-native-debug-symbols=internal --disable-zip-debug-info
make images从 jni_helper.c 改写代码有两点需要注意:
(1)rv = JNI_CreateJavaVM(&vm, (void*)&env, &vm_args); 中 env 的 (void*) 在 C++ 中需要改写成 (void**);
(2)rv = (*vm)->AttachCurrentThread(vm, (void*)&env, 0); 在 C++ 中需要改写为 rv = vm->AttachCurrentThread( (void**)&env, 0);;
Demo 代码如下:
#include <bthread/bthread.h>
#include <jni.h>
#include <stdio.h>
#define VM_BUF_LENGTH 1
void *PrintHellobRPC(void *arg) {
printf("I Love bRPC");
jint rv = 0;
JNIEnv *env;
JavaVM *vm;
rv = vm->AttachCurrentThread( (void**)&env, 0);
if (rv != 0) {
fprintf(stderr, "Call to AttachCurrentThread "
"failed with error: %s,rv = %d\n", rv);
return nullptr;
} else {
printf("AttachCurrentThread successful.\n");
}
return nullptr;
}
int main(int argc, char **argv) {
JavaVM* vmBuf[VM_BUF_LENGTH];
JNIEnv *env;
jint rv = 0;
jint noVMs = 0;
int noArgs = 1;
JavaVMInitArgs vm_args;
JavaVM *vm;
//JavaVMOption *options;
rv = JNI_GetCreatedJavaVMs(&(vmBuf[0]), VM_BUF_LENGTH, &noVMs);
if (rv != 0) {
fprintf(stderr, "JNI_GetCreatedJavaVMs failed with error: %s,rv = %d\n", rv);
return 0;
} else {
printf("No JVM available.\n");
}
JavaVMOption joptions[1];
joptions[0].optionString = "-verbose:jni";
//Create the VM
vm_args.version = JNI_VERSION_1_2;
vm_args.options = joptions;
vm_args.nOptions = noArgs;
vm_args.ignoreUnrecognized = 1;
rv = JNI_CreateJavaVM(&vm, (void**)&env, &vm_args);
if (rv != 0) {
fprintf(stderr, "Call to JNI_CreateJavaVM failed "
"with error: %s,rv = %d\n", rv);
return 0;
} else {
printf("Create JVM successful.\n");
}
int a = 0;
scanf("%d", &a);
bthread_t th_1;
bthread_start_background(&th_1, nullptr, PrintHellobRPC, nullptr);
bthread_join(th_1, nullptr);
return 0;
}编译的时候需要注意的是,我们不仅要把 bthread 的库 include 进来,还需要 include JNI 相关的库:-I $JAVA_HOME/include -I $JAVA_HOME/include/linux -L $JAVA_HOME/bin -L $JAVA_HOME/jre/lib/amd64/server -ljvm。
使用 debug 版本 JDK 运行 Demo 后发生了同样的 Crash:
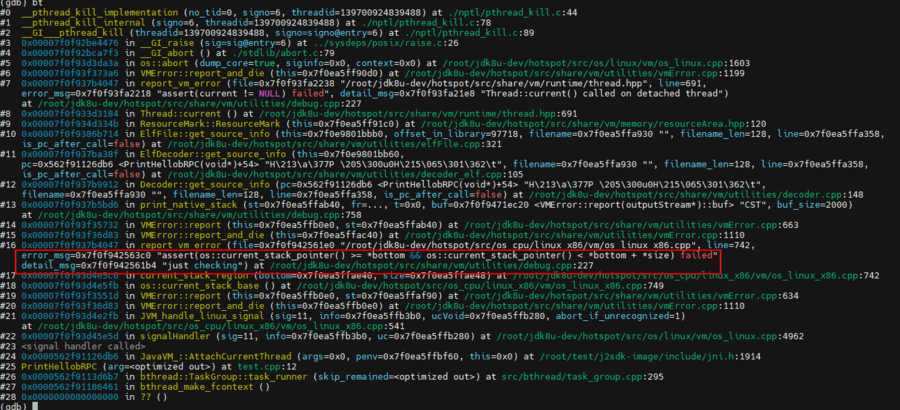
我们查看出问题时的 sp 寄存器信息:

sp 寄存器中的地址为 0x7fff60482f80,而此时 pthread 的信息为:

pthread 的地址范围为 0x7fff60607000-7fff60e07000,sp 的 0x7fff60482f80 是个远远低于 pthread 地址范围的值,我们再查看 bthread 在 allocate_stack_storage 时分配的自身线程堆栈地址范围:


bthread 堆栈的地址范围为 0x7fff60382000-0x7fff60483000,sp 的 0x7fff60482f80 正好处于其中,此时已经可以完美实锤问题出现的根因。
总结及解决方案
JVM 内部会对 Java thread 做一系列的校验与设置保护页等操作,以防止出现线程堆栈相关的问题。而 JVM 获取线程相关信息(如 bottom、size 等)是通过 Linux Libc 提供的标准线程库 pthread 的 API 来操作的,如果你用来进行 attach 的线程不是一个标准意义上的 pthread,那么在 JVM 将其 wrap 成一个 Java thread 的过程中就会出现异常造成功能不可使用。对于已经创建好的线程要 attach 到 JVM 上的情况,那个线程之前是如何创建、其中的栈是如何分配的,JVM 是管不到的,所以我们只能从进行 attach 的线程入手看是否存在解决方案,如果不存在我们只能放弃这种使用方式。
幸运的是,bthread 本身确实考虑到与标准 pthread 差异造成的功能受限问题,提供了 pthread 模式供大家使用,详情可见 brpc pthread 模式说明[13]:
用户代码(客户端的done,服务器端的CallMethod)默认在栈为1MB的bthread中运行。但有些用户代码无法在bthread中运行,对于这些情况,brpc提供了pthread模式,开启 -usercode_in_pthread 后,用户代码均会在pthread中运行,原先阻塞bthread的函数转而阻塞pthread。
我们在开启 -usercode_in_pthread 使用 pthread 模式之后,问题得到成功解决。
参考
1. libhdfs/jni_helper.c#getGlobalJNIEnv:https://github.com/apache/hadoop/blob/trunk/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfs/jni_helper.c#L656
2. Stack Overflow handling in HotSpot JVM:https://pangin.pro/posts/stack-overflow-handling
3. JEP270:https://openjdk.java.net/jeps/270
4. R大:Unable to create new native thread 的本质是什么?https://www.zhihu.com/question/64685291/answer/223734268
5. pthread_attr_getstack:https://linux.die.net/man/3/pthread_attr_getstack
6. bthread源码:https://github.com/apache/brpc/
7. Boost.Context:https://github.com/boostorg/context
8. brpc官方资料:https://brpc.apache.org/zh/docs/blogs/sourcecodes/bthread/
9. brpc官网教程:https://brpc.apache.org/zh/docs/getting_started/
10. 毕昇JDK下载地址:https://www.hikunpeng.com/zh/developer/devkit/compiler/jdk
11. debuginfo使用指导:https://gitee.com/openeuler/bishengjdk-8/wikis/%E4%B8%AD%E6%96%87%E6%96%87%E6%A1%A3/debuginfo%E7%9A%84%E4%BD%BF%E7%94%A8%E6%8C%87%E5%AF%BC
12. 毕昇JDK8源码:https://gitee.com/openeuler/bishengjdk-8
13. brpc pthread模式说明:https://gitee.com/baidu/BRPC/blob/master/docs/cn/server.md#pthread%E6%A8%A1%E5%BC%8F

鲲鹏展翅 立根铸魂 深耕行业数字化
更多推荐
 1
1 0
0- 0



 已为社区贡献315条内容
已为社区贡献315条内容

所有评论(0)