
【全网最强文档智能】大模型 + RAG + PDF问答,居然比 PyPDF + langchain 还好用!
LLM主要依赖于公开的互联网来源作为训练数据,这些数据虽然丰富多样但在专业领域的应用中往往缺乏私有领域知识,限制了LLM在特定领域内的效能。这种全面的方法允许它在处理各种复杂PDF文档时,不仅能够提取文本,还能理解文档的深层结构和逻辑,从而为后续的信息检索和问答系统提供强大支持。:将PDF文档内容解析为结构化的形式,如段落、标题、表格和图像等,并进一步将这些内容分成更小的块(Chunks)。接下来
论文:https://arxiv.org/pdf/2401.12599.pdf
提出背景
LLM主要依赖于公开的互联网来源作为训练数据,这些数据虽然丰富多样但在专业领域的应用中往往缺乏私有领域知识,限制了LLM在特定领域内的效能。
采用检索增强生成(RAG)框架,通过从私有知识库中检索相关内容并结合用户查询作为上下文,进而让LLM生成答案。
但 PDF 格式设计用于保持文档的视觉布局和格式,而不是其语义结构。
- PDF 中的表格和复杂布局(例如跨页表格、多栏布局)对传统的基于规则的PDF解析工具(如PyPDF),这些工具无法有效地识别和保留这些结构的完整性。
RAG 能结合大型语言模型(LLM)的生成能力和基于检索的机制来提升回答的准确性和相关性
我用 langchian 实现了 PDF问答。
# 设置OpenAI API密钥,以便使用OpenAI的服务,比如GPT和其他API。
import os
os.environ['OPENAI_API_KEY'] = '自己的openai api key'
# 定义要处理的PDF文件名。
PDF_NAME = '某某法律.pdf'
# 使用PyMuPDFLoader从LangChain库加载PDF文档。这个步骤负责打开PDF文件并准备它以便后续处理。
from langchain.document_loaders import PyMuPDFLoader
docs = PyMuPDFLoader(PDF_NAME).load()
# 打印出加载的文档数量和第一页的字符数目,用于验证文档已正确加载。
print(f'There are {len(docs)} document(s) in {PDF_NAME}.')
print(f'There are {len(docs[0].page_content)} characters in the first page of your document.')
# 初始化文本分块器和嵌入模型。这里使用的是递归字符文本分块器(对文档进行分块以便向量化)和OpenAI的嵌入API。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
split_docs = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings()
# 创建向量存储(VectorStore),在这里使用的是Chroma,它基于分块的文档和嵌入来构建,用于后续的相似性搜索。
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(split_docs, embeddings, collection_name="serverless_guide")
# 初始化LLM(Large Language Model),这里使用的是OpenAI的模型,并加载一个问答链(QA Chain)。
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
llm = OpenAI(temperature=0)
chain = load_qa_chain(llm, chain_type="stuff")
# 定义查询,并执行相似性搜索来找到与查询最相似的文档块。然后使用问答链来根据找到的相似文档块回答查询。
query = "第一页第一行是什么?"
similar_doc = vectorstore.similarity_search(query, 3, include_metadata=True)
chain.run(input_documents=similar_docs, question=query)
能知道 pdf 内容是啥,但准确率不好,比如问某页第一行第一句是什么,回答不了。
这个精确定位、命中率底的问题 我也没有头绪 不知道怎么解决。
现在 chatdoc 已经给出了他的解法,我来学习一下。
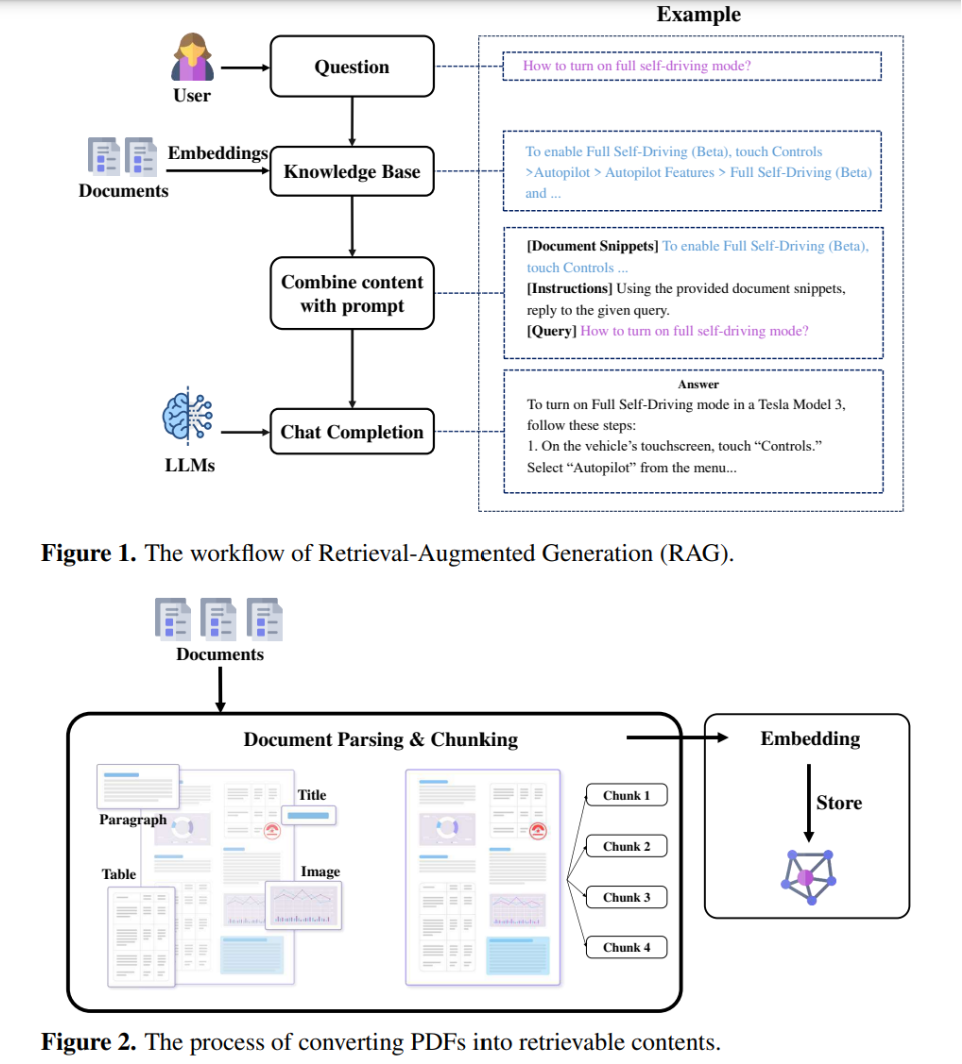
RAG 工作流程和将 PDF 文件转换为可检索内容的过程:
图1:检索增强生成(RAG)的工作流程
-
用户提问:用户向系统提出一个问题。
用户问:“怎样进行高血压的最新治疗?”
-
嵌入和知识库:系统利用先前生成的嵌入,从知识库中检索与问题相关的内容。
系统将这个问题转换为一个查询嵌入,然后在医学研究文献的知识库中搜索相关内容。
这个嵌入可能基于关键词如“高血压”、“治疗”来检索相关文档。
-
组合内容与提示:将检索到的内容与用户的问题结合,作为提示输入到大型语言模型(LLM)中。
系统找到了最新的高血压治疗指南,并将这些信息与用户问题结合成一个新的提示。
例如,它可能会提取一篇关于高血压治疗的最新临床试验结果的段落。
-
聊天完成:LLM处理结合后的内容,生成答案。例如,它给出了关于特斯拉Model 3如何开启全自动驾驶模式的详细步骤。
大型语言模型(LLM)接收这个结合了用户问题和相关医学信息的提示,生成一个详细的回答。
例如,它可能会概述最新的药物组合治疗方案。
图2:将PDF文件转换为可检索内容的过程
-
文档解析与分块:将PDF文档内容解析为结构化的形式,如段落、标题、表格和图像等,并进一步将这些内容分成更小的块(Chunks)。
每篇医学论文都被解析成结构化内容,其中段落、标题、表格和图像等被识别出来。
这些内容进一步被分块,例如,一篇论文中讨论高血压药物治疗的那个段落被标识为一个单独的块。
-
嵌入存储:接下来,将这些内容块转换为实值向量(即嵌入),然后将它们存储在一个数据库中,以便后续进行相似性搜索和检索。
接下来,这些内容块被转换成实值向量,也就是嵌入,这些嵌入反映了各自内容块的语义信息。
之后,它们被存储在一个可以进行快速相似性搜索的数据库中。
这两个图表一起说明了RAG系统如何通过将PDF文档内容转换为嵌入,并使用这些嵌入来检索和生成与用户查询相关的回答。
这个过程允许RAG系统访问大量专业知识,即使这些知识未包含在LLM的原始训练数据中。
传统规则提取逻辑:

文档被分割成多个文本块,但存在几个问题:
- 无法准确识别段落和表格的边界,导致表格被错误地分割,部分内容与后续段落合并。
- 无法识别表格内部结构,如合并单元格,结果在块中表现为连续的文本行,失去了表格的结构。
- 无法正确识别文档内容的阅读顺序,尤其是在面对复杂布局时,可能会导致混乱的结果。
chatdoc 提取逻辑:

- 解析结果以结构化的JSON或HTML格式呈现,清晰地表示了文档的逻辑和物理结构。
- 能够识别文档中的表格、段落和其他内容块,保留了表格内部结构,并且能够表示合并单元格的情况。
- 能够处理复杂的文档布局,并且能够正确地确定内容块的阅读顺序。
ChatDOC 对比传统方案 PyPDF:
- 传统的基于规则的PDF解析器难以准确识别复杂文档的结构。ChatDOC能够精确地区分文档的段落、表格和图表等不同类型的内容块。
- 多栏布局或者复杂的表格,传统解析器不行。ChatDOC在处理多栏页面、无边框表格和合并单元格的表格等复杂文档布局时有好的鲁棒性。
- 表格的结构对于理解文档内容至关重要,但传统方法经常会破坏表格的内部结构。ChatDOC能够识别并保留表格内部结构,包括合并单元格,并以结构化的格式表示这些信息。
- pdf默认按照字符的存储顺序解析文档,不符合实际的阅读顺序。ChatDOC能够识别并正确处理内容的阅读顺序,即使在面对复杂布局的文档时也能保持内容的连贯性。
- 解析结果需要以一种易于后续处理的格式输出,传统的输出更倾向于连续的文本流,缺少结构化信息。ChatDOC设计为能够输出JSON或HTML格式的解析结果 — ChatDOC输出结构化数据,使其类似于组织良好的Word文件,易于机器读取和后续处理。
ChatDOC、PyPDF + langchain 对比效果:


在这个例子中,ChatDOC明显优于PyPDF+LangChain的组合。
全流程分析
ChatDOC的设计依据一系列复杂的步骤,旨在解决PDF文档解析的挑战。以下是ChatDOC设计的全流程拆解:
数据准备与训练
- 收集大量文档:为了训练深度学习模型,ChatDOC可能首先收集了超过数百万页的文档页面,涵盖各种格式和布局。
- 预处理和标注:这些文档需要被预处理(例如,扫描文档的OCR处理)并手动或半自动地进行标注,以识别文档结构(如段落、表格、标题)。
模型开发与训练
- 选择深度学习架构:设计合适的深度学习模型架构,可能包括卷积神经网络(CNN)来处理视觉特征,递归神经网络(RNN)或Transformer来处理序列信息。
- 训练和调整:使用标注的数据集来训练模型,可能需要进行多次迭代和调整以优化性能。
文档解析
- 文本定位和识别(OCR):对文档进行OCR处理以识别和定位其中的文本。
- 物理文档对象检测:检测文档中的物理对象,如文字块、图表、表格等。
- 跨列和跨页修剪:处理文档中跨列和跨页的内容,确保信息的完整性。
- 阅读顺序确定:确定文档内容的正确阅读顺序。
- 表格结构识别:识别表格结构,包括单元格的边界和合并单元格。
- 文档逻辑结构识别:理解文档的层次结构,比如章节和标题。
输出生成
- 解析结果格式化:将解析的结果格式化为JSON或HTML,以便于机器处理和阅读。
- 结果验证和优化:可能需要手动检查解析结果,并根据反馈进行优化。
集成与部署
- 与RAG系统集成:将ChatDOC解析器集成到RAG系统中,以提高信息检索的准确性。
- 性能测试:在实际应用场景中进行性能测试,并根据结果进一步调整和优化。
用户体验和反馈
- 用户交互设计:设计用户界面,以便用户可以轻松地上传文档并接收解析结果。
- 收集用户反馈:根据用户如何使用ChatDOC和他们的反馈来进一步改进系统。
ChatDOC是一个复杂的系统,它结合了深度学习技术、OCR、文档结构理解和用户界面设计,提供了一个高度先进且用户友好的PDF解析解决方案。
这种全面的方法允许它在处理各种复杂PDF文档时,不仅能够提取文本,还能理解文档的深层结构和逻辑,从而为后续的信息检索和问答系统提供强大支持。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 39
39 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)