
保姆级NHANES数据库使用教程
National Health and Nutrition Examination Survey (NHANES数据库,网址:https://www.cdc.gov/nchs/nhanes/index.htm),收集了有关美国家庭人口健康和营养信息,是一项基于人群的横断面调查。该数据库开始于80年代,生物样本包含了参与者的血清,血浆,尿液等,涉及多种测量指标。此外,还包含了大量的调查问卷数据,调查
National Health and Nutrition Examination Survey (NHANES数据库,网址:https://www.cdc.gov/nchs/nhanes/index.htm),收集了有关美国家庭人口健康和营养信息,是一项基于人群的横断面调查。
该数据库开始于80年代,生物样本包含了参与者的血清,血浆,尿液等,涉及多种测量指标。此外,还包含了大量的调查问卷数据,调查问卷涉及广泛,包括人口统计学、社会经济学、饮食和健康相关问题,体检部分包括生理测量、实验室检查等内容。
该数据库自20世纪末开始,每两年一个周期,更新数据,而且是免费对外开放的,研究者可以根据需要直接下载数据。
该数据库所涉及的参与者的死亡状况存在另一个数据库:NDI数据库。网址为https://www.cdc.gov/nchs/ndi/index.htm,如下图:


那,如何从NHANES数据库下载研究所需要的数据呢?
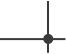
Step 1. 点击1处或2处直接进入数据下载页面(如下图)
Step 2. 可以从下图中的1、2、3处下载数据。
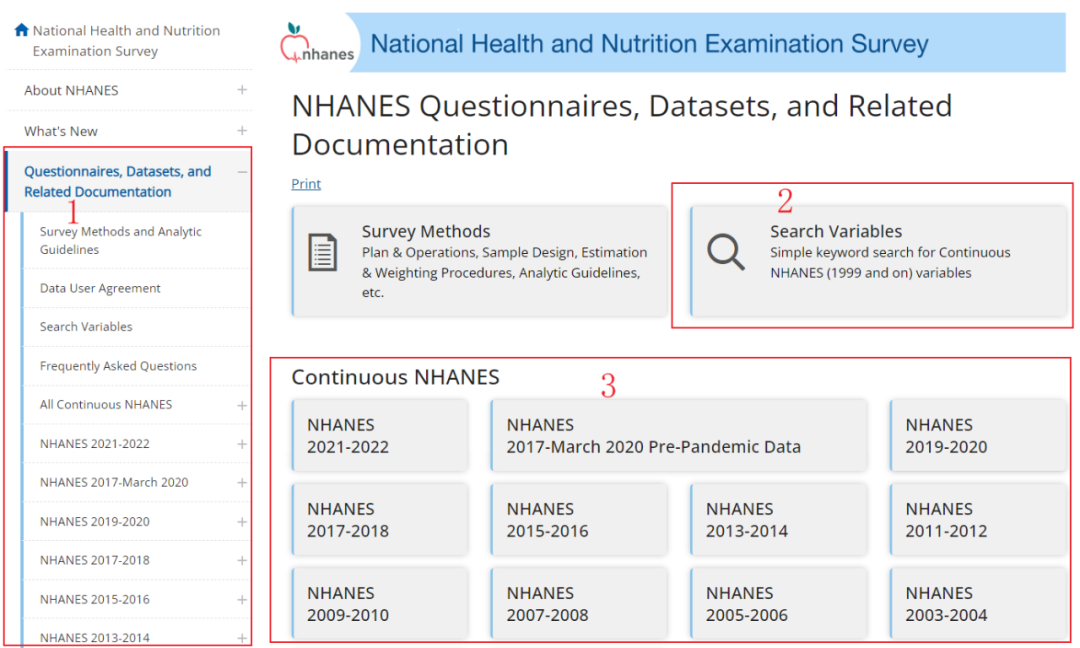
从1或3处可以按年份下载,每个年份包含Demographics Data”(人口数据)、“Dietary Data”(饮食数据)、“Examination Data”(检查数据)、“Laboratory Data”(化验数据)、“Questionnaire Data”(问卷数据)、“Limited Access Data”(限制访问数据)。
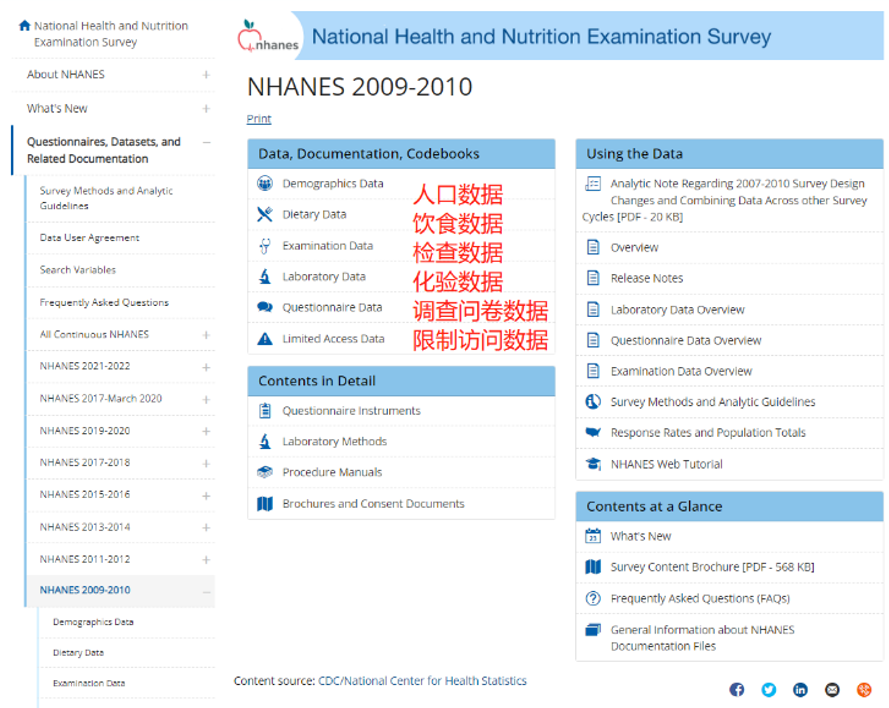
点击相应的图标即可进入下载页面,本文以下载2009-2010年份的人口数据为例。注意2020-2022年的数据目前还不能下载。
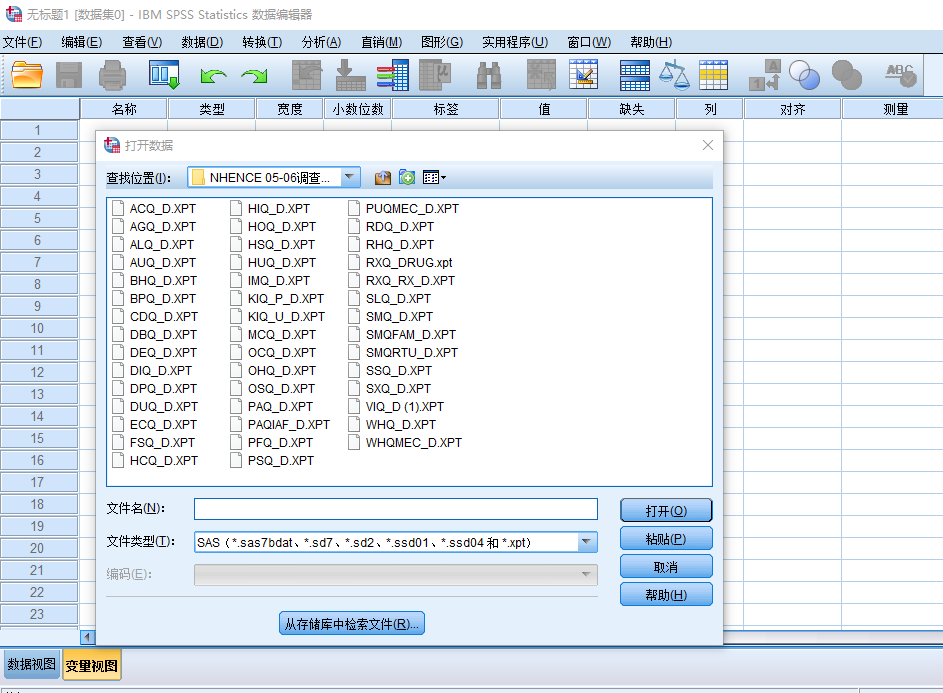
Step 3. 点击数据文件即可下载数据XPT文件,该格式数据可以用SPSS软件打开,也可以用R软件打开。
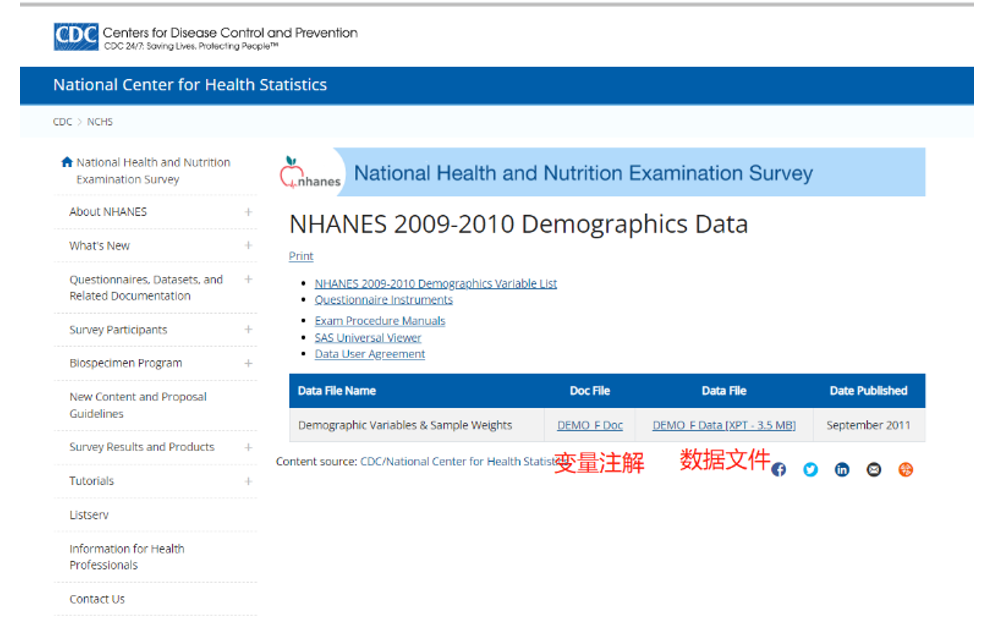
点击变量注解,进入变量解释页面,主要关注右边的codebook栏,是对变量的具体解释,非常重要(尤其是在调查问卷文件中)。
左边栏的codebook和Frequencies 中是对字段值的解释,比如:gender中的1 代表male,2 代表female,点代表缺失。

Step 4. 数据处理,可采用SPSSR软件、R软件或Excel 处理。
数据处理方法(1):SPSS数据导入及处理。
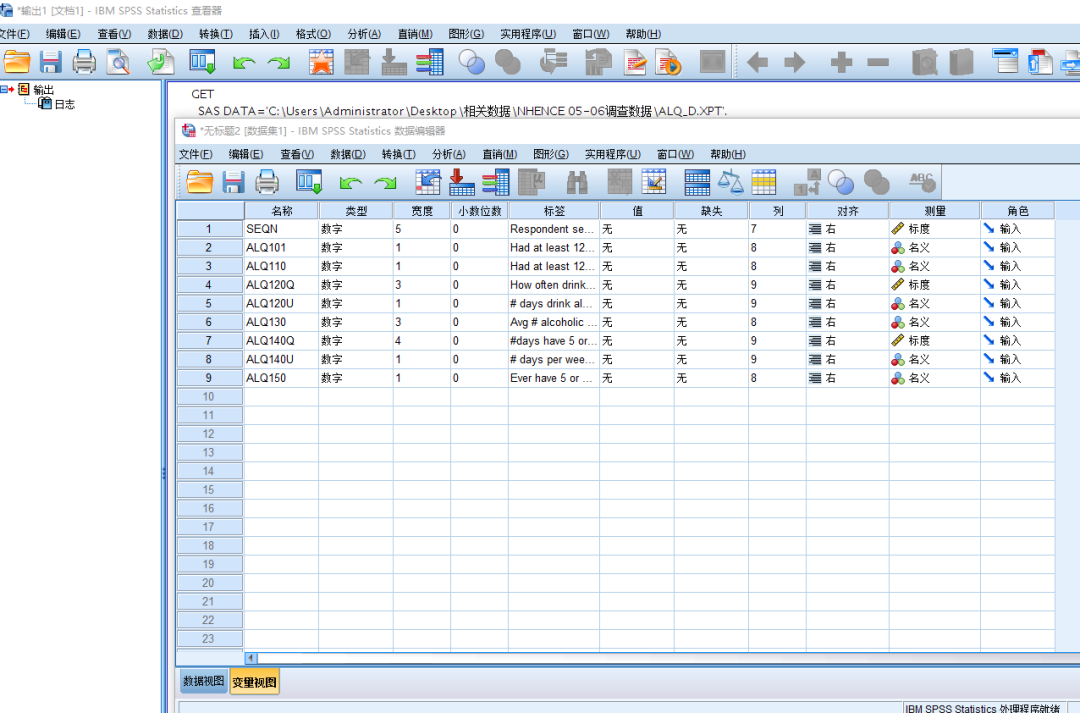
a. 格式转换XPT文件格式转化为另存为sav文件或者xlsx文件,以方便处理。
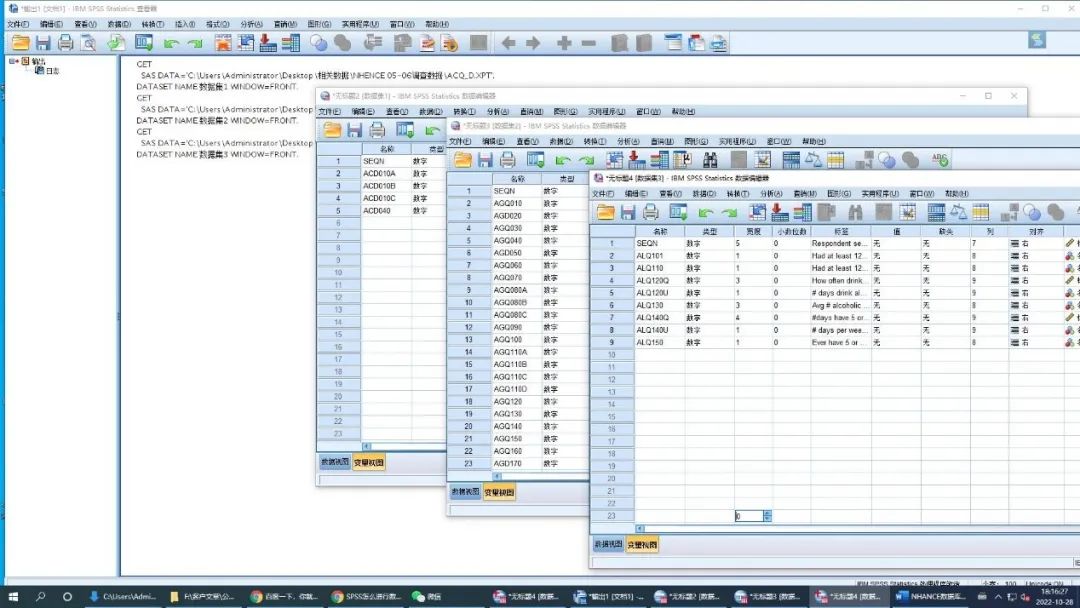
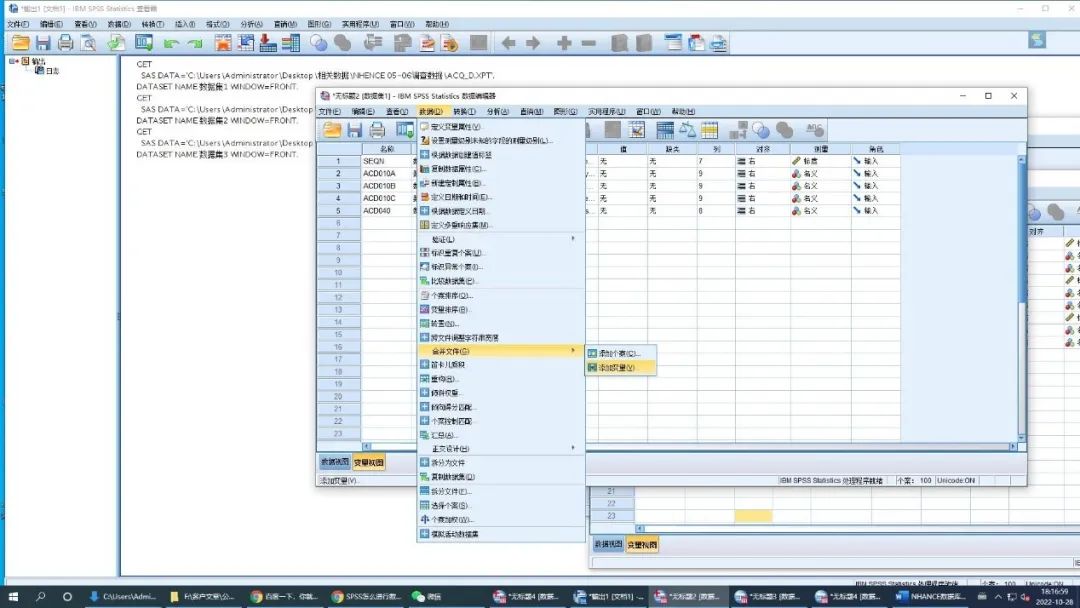
b. 数据合并。
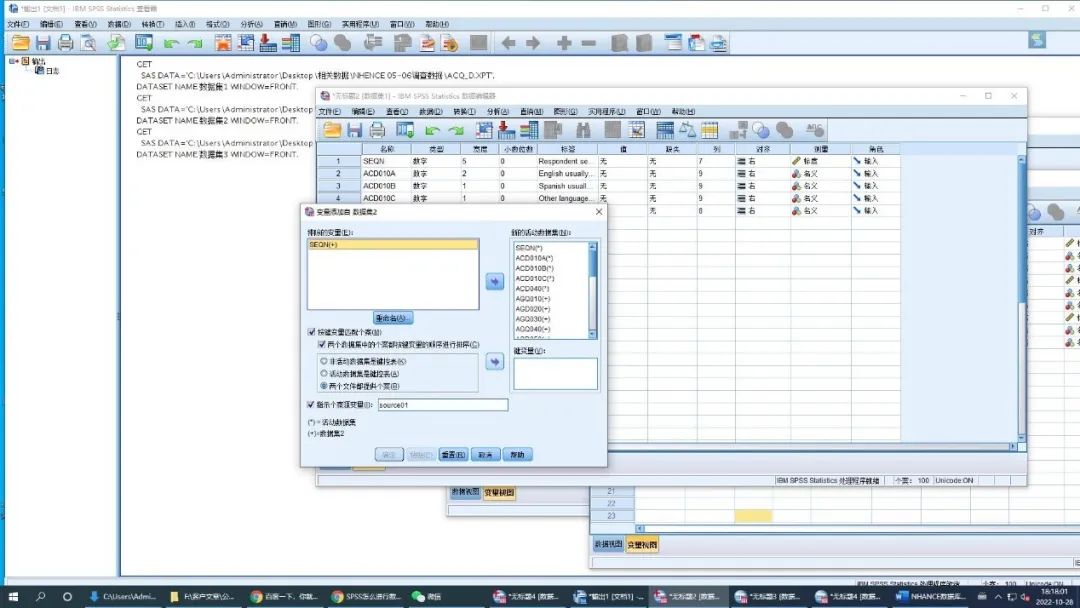
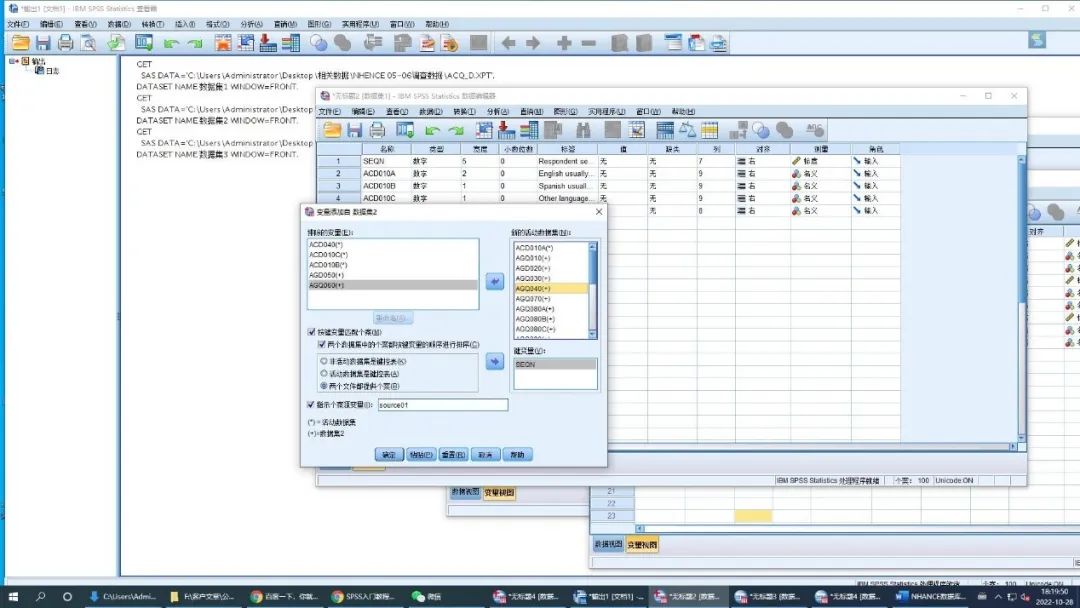
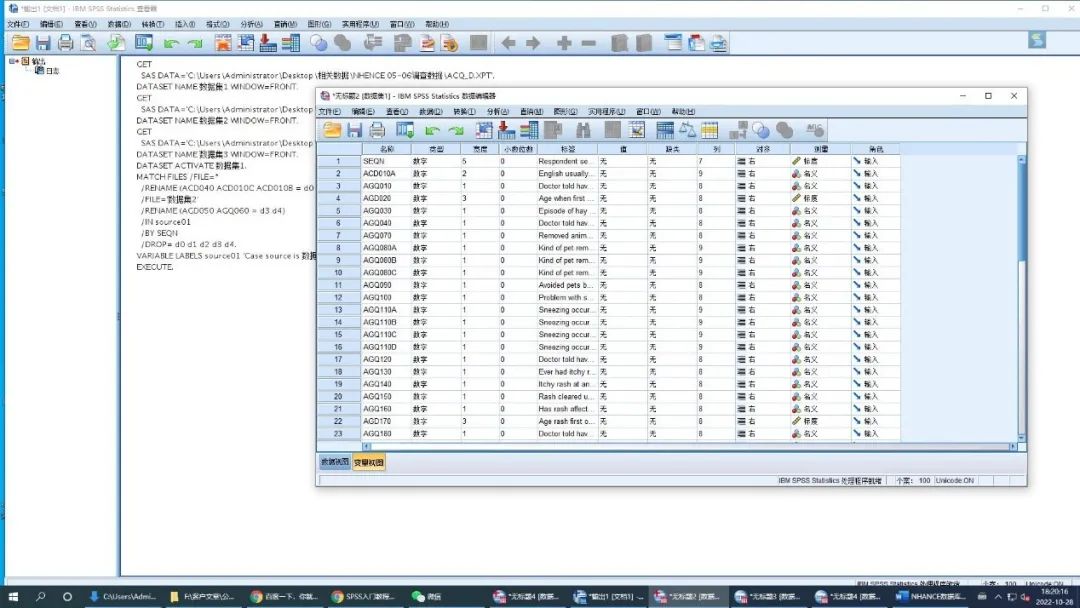
打开先要合并的数据,选中需添加的表格,这里以在数据集1上添加数据集2中的变量,并剔除不需要的变量为例,操作演示如下图的五个步骤,注意的是两个数据集的相同变量为键变量,即患者序列号(SEQN)。

数据处理方法(2): 用R-Studio软件导入及初步处理数据
a. 在R-Studio 安装"foreign"包。
采用镜像安装比较快(这里采用的是阿里镜像)
具体代码如下:
options(repos=structure(c(CRAN="http://mirrors.aliyun.com/CRAN/")))
install. packages("foreign")
b. 把XPT文件放入R软件下的文件夹
备注:如果不清楚该文件路径,可以运行getwd() 语句获取相应的文件路径
c. 导入XPT文件(如下例子读取了四个XPT文件)
library(“foreign”)
mydata1<-read.xport("ACQ_D.XPT")
mydata2<-read.xport("AGQ_D.XPT")
mydata3<-read.xport("ALQ_D.XPT")
mydata4<-read.xport("AUQ_D.XPT")
d. 文件合并(根据每个文件的“SEQN”的进行合并,“SEQN”表示受访者ID号)
merge_data<-merge.data.frame(mydata1,mydata2,by.x="SEQN",by.y="SEQN",all=TRUE)
若有多个数据集可以分步两两合并,也可采用其它的函数进行合并(下次介绍)
e. 合并文件导出Excel,需要先安装”xlsx”包(这里采用阿里镜像安装)
options(repos=structure(c(CRAN="http://mirrors.aliyun.com/CRAN/")))
install. packages("xlsx")
library(“xlsx”)
write.xlsx(merge_data3,file=”D:/merge_data3.xlsx”)
数据处理方法(3):Excel数据匹配
如果数据很少的话,也可用SPSS或R软件把XPT文件转化为xlsx文件之后,也可采用Excel匹配数据,操作如下:
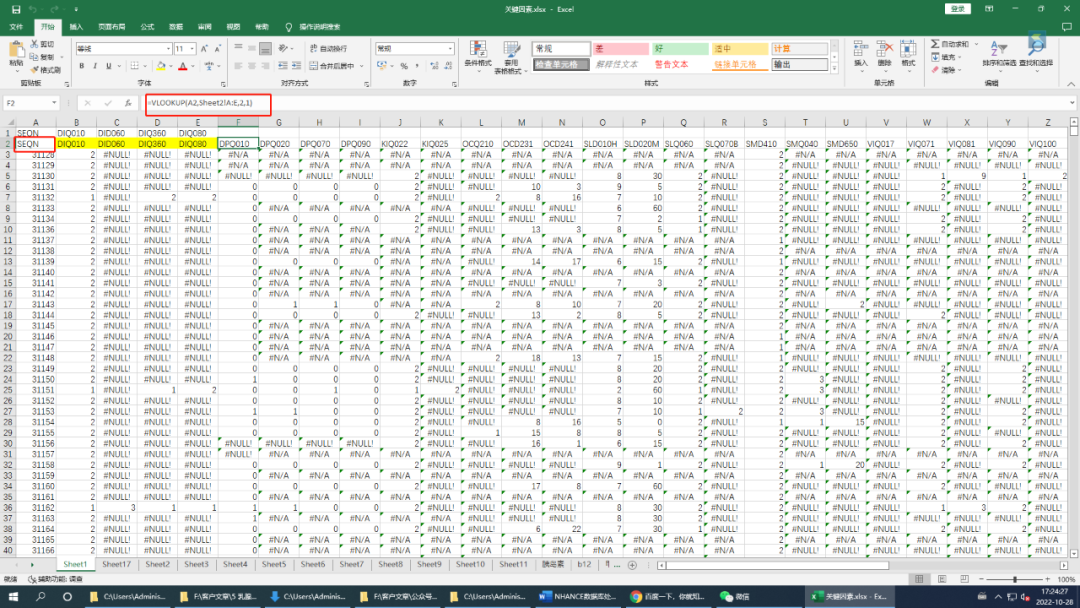
用Excel打开,根据每个文件中的相同字段患者序列号(SEQN),利用VLOOKUP函数进行数据匹配。函数如下图所示。Vlookup(A2,sheet2!A:E,2 1),该函数中A2是查询值,这里是SEQN;Sheet2!A:E表示匹配范围;2代表匹配的数据所在列;1 代表精准匹配。
![]()
现在有很多国际认可的临床数据库,这些平台的数据都是鼓励科研人员去挖掘数据、做科学研究的。
大家可以好好探索一下这些数据库。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 41
41 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)