
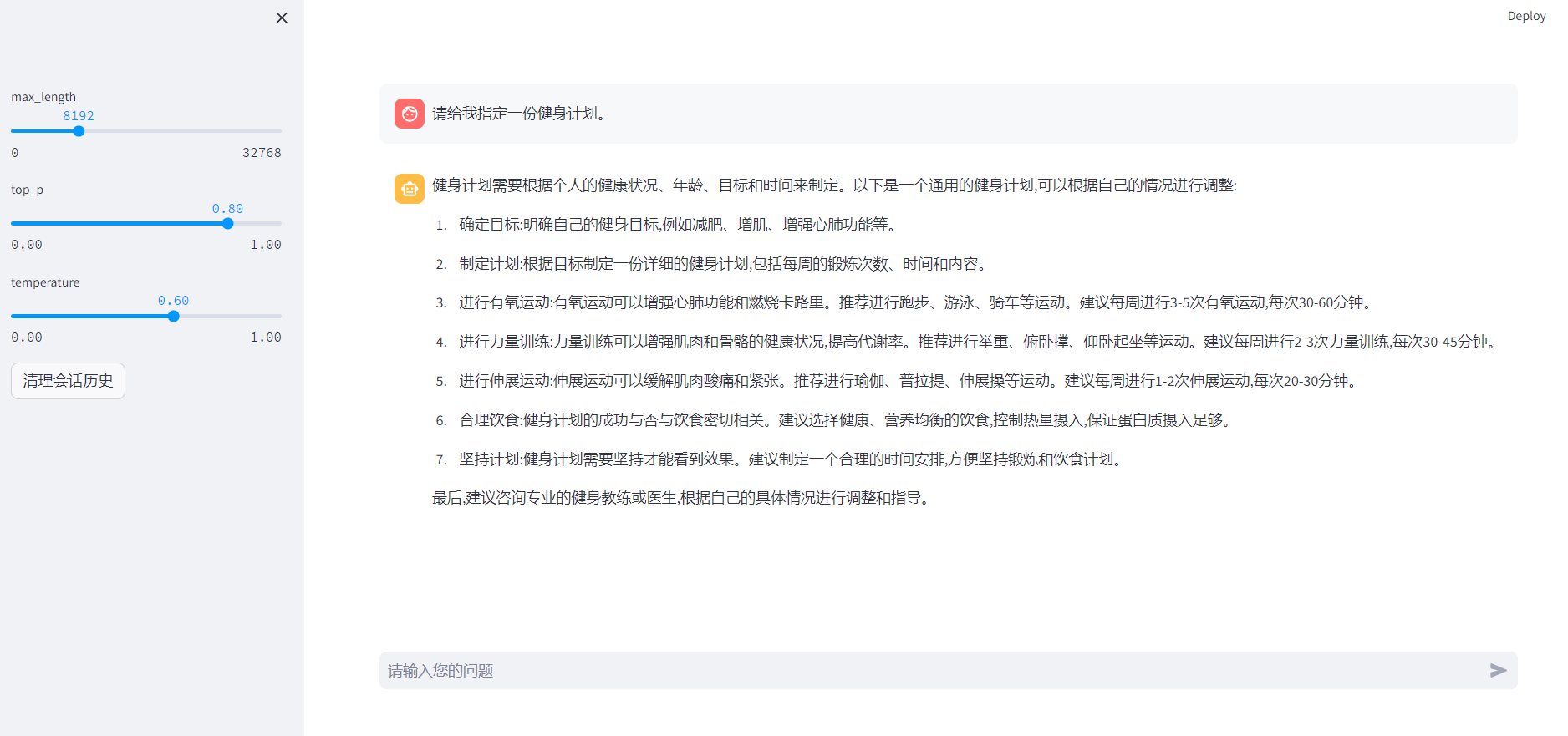
ChatGLM3-6B模型介绍及微调
对 ChatGLM3-6B-Base 的测试中,BBH 采用 3-shot 测试,需要推理的 GSM8K、MATH 采用 0-shot CoT 测试,MBPP 采用 0-shot 生成后运行测例计算 Pass@1 ,其他选择题类型数据集均采用 0-shot 测试。官方对 Base版提供的是基于Lora的微调。不同的部署方式,第一种只有Chat 对话模式,第二种将对话模式,工具模型和代码解释器模型进
文章目录
ChatGLM3-6B的强大特性
项目地址:https://github.com/THUDM/ChatGLM3
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代(第三代)对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型
- 更完整的功能支持
- 更全面的开源序列
更强大的基础模型
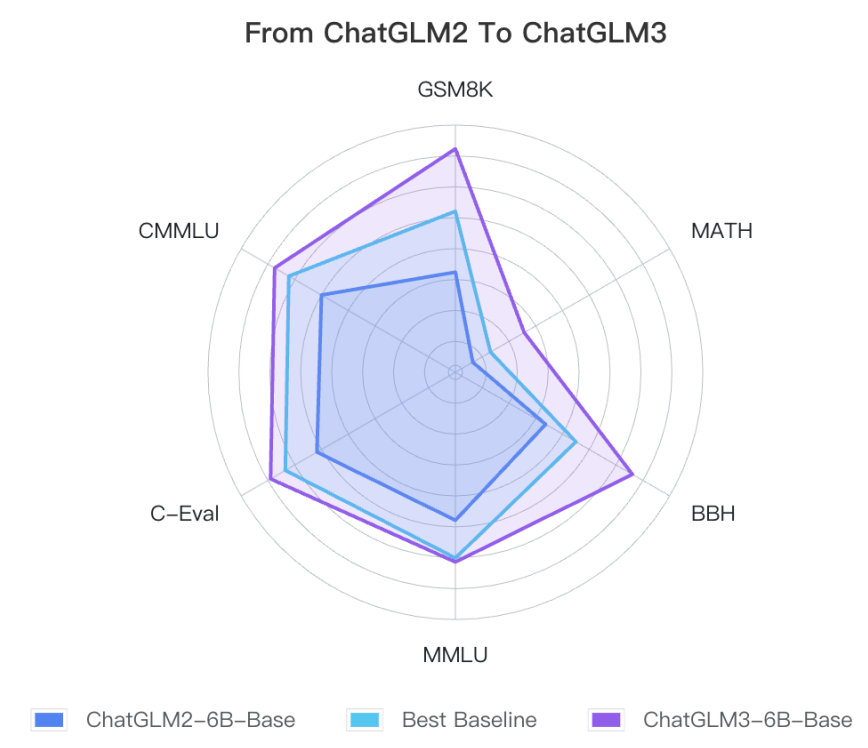
ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。其在44个中英文公开数据集测试国内第一。
ChatGLM3-6B-Base在不同数据集上的的性能展示图
ChatGLM3-6B-Base在不同数据上的具体效果
| Model | GSM8K | MATH | BBH | MMLU | C-Eval | CMMLU | MBPP | AGIEval |
|---|---|---|---|---|---|---|---|---|
| ChatGLM2-6B-Base | 32.4 | 6.5 | 33.7 | 47.9 | 51.7 | 50.0 | - | - |
| Best Baseline | 52.1 | 13.1 | 45.0 | 60.1 | 63.5 | 62.2 | 47.5 | 45.8 |
| ChatGLM3-6B-Base | 72.3 | 25.7 | 66.1 | 61.4 | 69.0 | 67.5 | 52.4 | 53.7 |
Best Baseline:
Best Baseline 指的是截止 2023年10月27日、模型参数在 10B 以下、在对应数据集上表现最好的预训练模型,不包括只针对某一项任务训练而未保持通用能力的模型。
对不同数据集采用的测试方式的区别:
对 ChatGLM3-6B-Base 的测试中,BBH 采用 3-shot 测试,需要推理的 GSM8K、MATH 采用 0-shot CoT 测试,MBPP 采用 0-shot 生成后运行测例计算 Pass@1 ,其他选择题类型数据集均采用 0-shot 测试。
更完整的功能支持
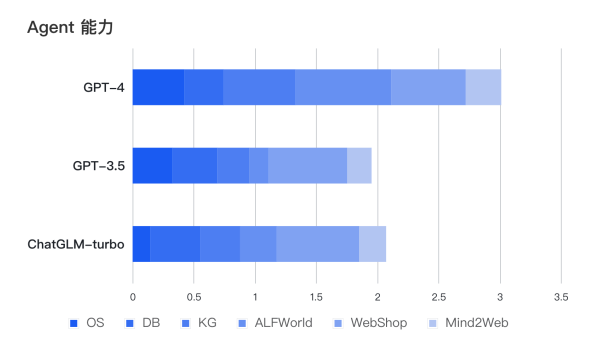
ChatGLM3-6B 采用了全新设计的 Prompt 格式,在不影响模型通用能力的情况下,全面增强ChatGLM3-6B的能力。此外,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
更全面的开源序列
除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
| Model | Seq Length | Download |
|---|---|---|
| ChatGLM3-6B | 8k | HuggingFace | ModelScope |
| ChatGLM3-6B-Base | 8k | HuggingFace | ModelScope |
| ChatGLM3-6B-32K | 32k | HuggingFace | ModelScope |
ChatGLM3-6B的部署
ChatGLM3-6B提供了两种不同的部署方式,第一种只有Chat 对话模式,第二种将对话模式,工具模型和代码解释器模型进行了集成。
- Chat: 对话模式,在此模式下可以与模型进行对话。
- Tool: 工具模式,模型除了对话外,还可以通过工具进行其他操作。
- Code Interpreter: 代码解释器模式,模型可以在一个 Jupyter 环境中执行代码并获取结果,以完成复杂任务。
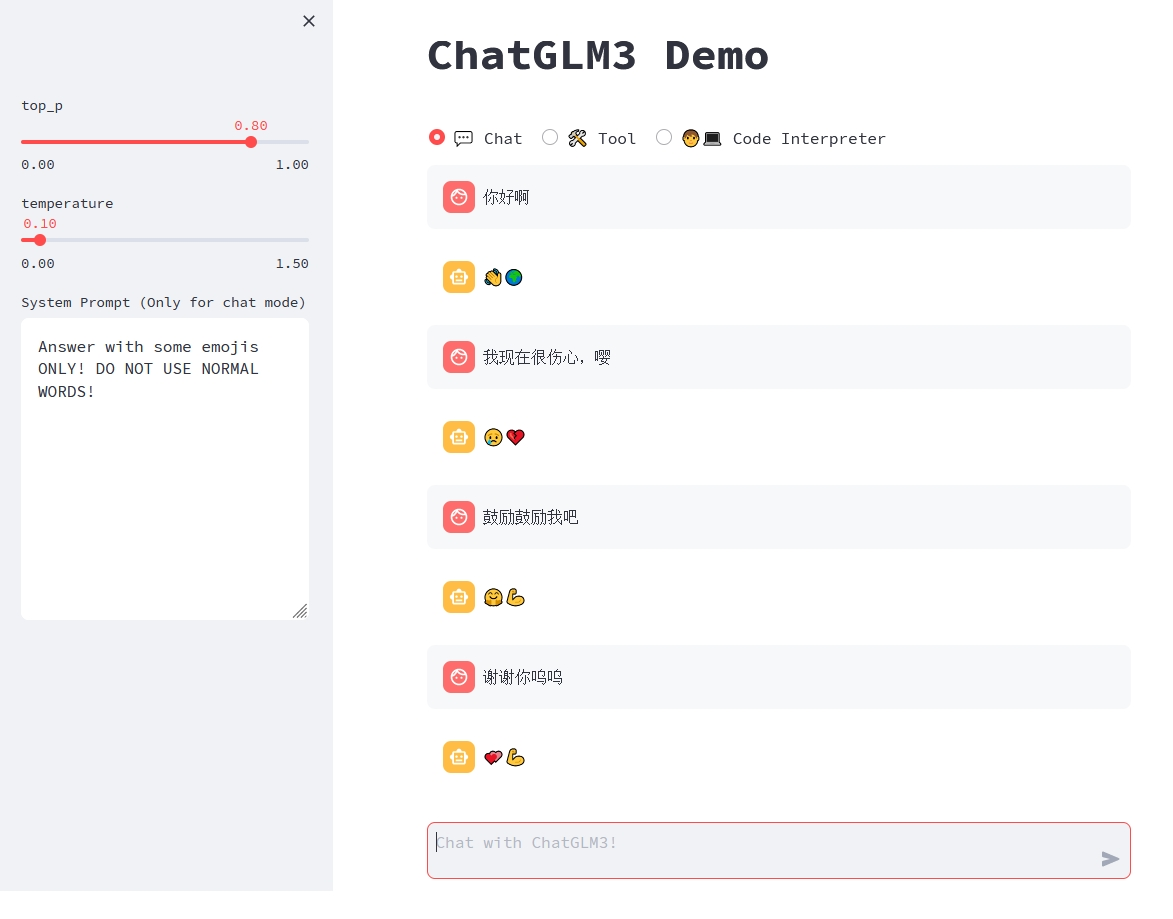
可以通过在 tool_registry.py 中注册新的工具来增强模型的能力。
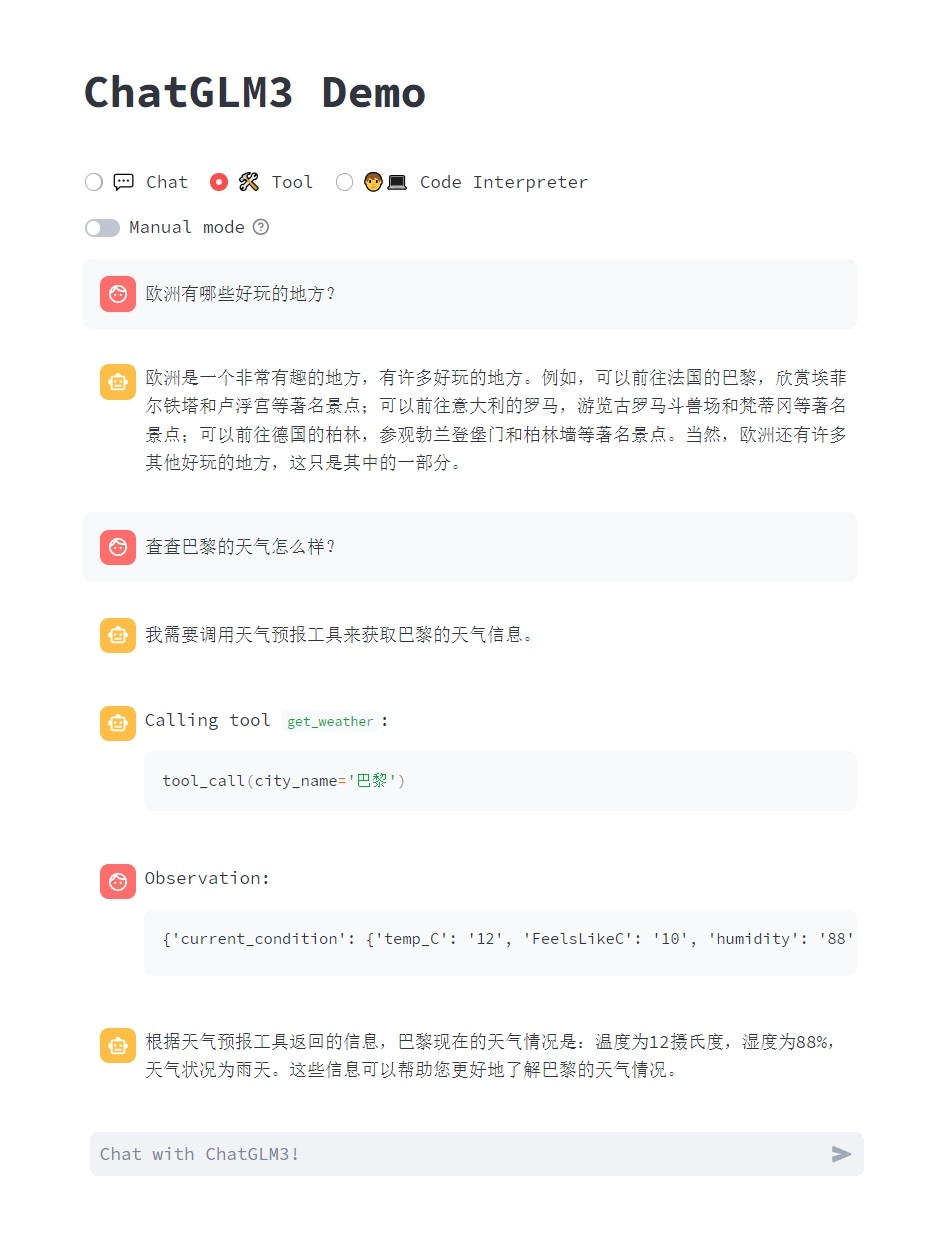
模型能够执行更为复杂的任务,例如绘制图表、执行符号运算等等。模型会根据对任务完成情况的理解自动地连续执行多个代码块,直到任务完成。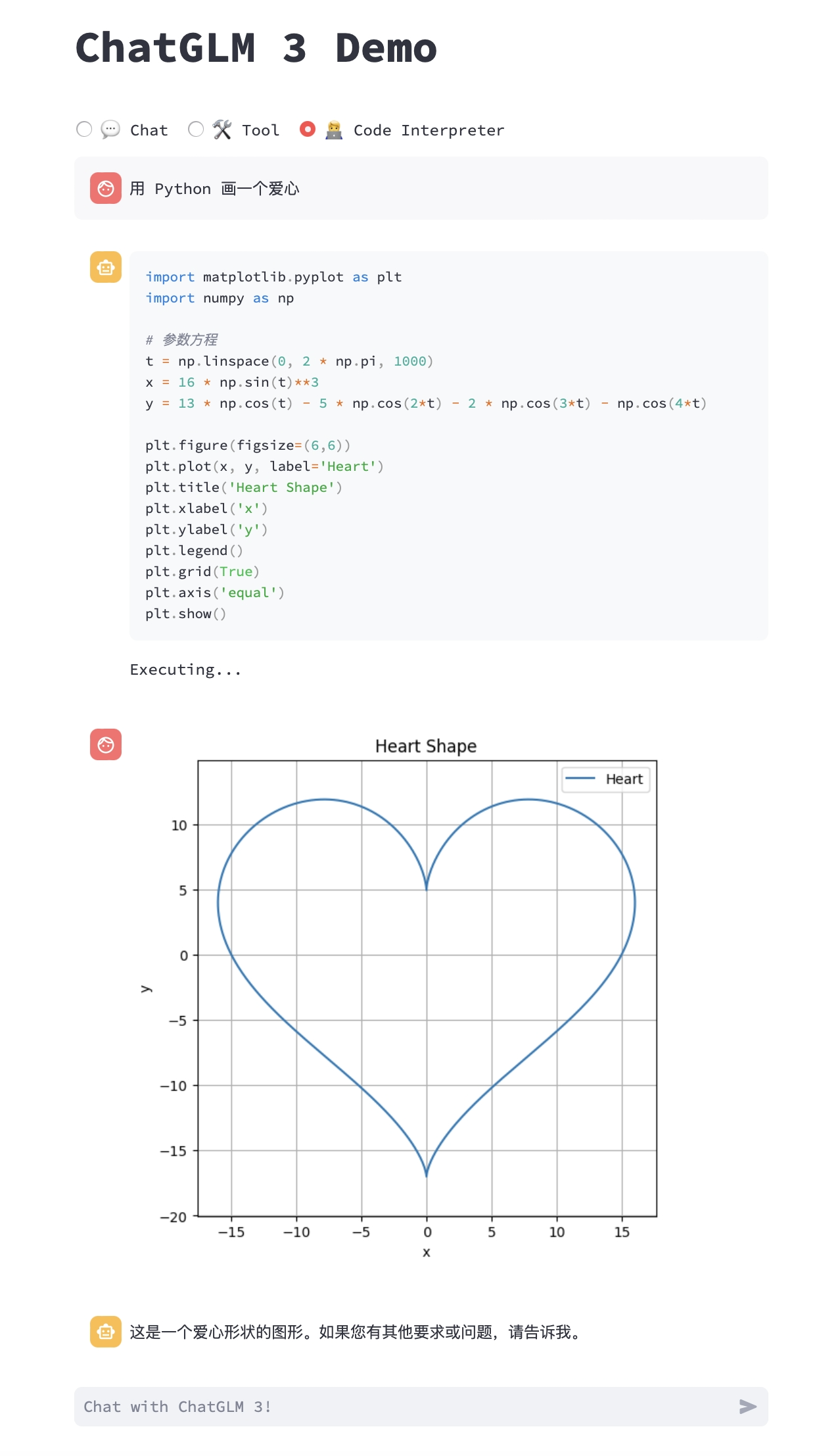
basic版部署
basic 版可以在七月GPU上进行部署,模型文件已下载,相关环境已配置。
模型文件路径:/data/sim_chatgpt
chatglm3-6b环境:
# 激活conda环境
source activate
# 进入对应的conda环境
conda activate chatglm3-6b
1、下载代码仓库
git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
如果遇到下载不下来的情况,有两种方法:
第一种是先仓库代码下载到本地解压后,传到服务器上;
第二种是在码云上搜索最新的ChatGLM3进行下载。
通过命令行方式下载下来,如:
git clone https://gitee.com/aqua/ChatGLM3
cd ChatGLM3
修改文件路径及设置
修改 basic_demo 下的web_demo.py和web_demo2.py
只需要将模型路径修改为 /data/sim_chatgpt 即可。
cd basic_demo
vi web_demo.py
vi web_demo2.py
MODEL_PATH = os.environ.get(‘MODEL_PATH’, ‘/data/sim_chatgpt/chatglm3-6b’)
注意:需要将web_demo.py中launch()函数中设置share=True,server_name=“0.0.0.0”,以便可以在浏览器打开。
部署推理
基于 Gradio 的网页版 demo:
python web_demo.py
基于 Streamlit 的网页版 demo:
streamlit run web_demo2.py
网页版 demo 会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。 经测试,基于 Streamlit 的网页版 Demo 会更流畅。
集成版部署
集成版由于会用到julyter内核,故可以在AutoDL平台上进行部署,建议选择显存32G的V100或4090进行操作,方便后面进行微调。
集成版的相关文件在 composite_demo 路径下。
下载仓库代码
git clone https://gitee.com/aqua/ChatGLM3
cd ChatGLM3
安装git-lfs
# 先安装git(如已安装可忽略)
sudo apt-get install git
# 安装apt-get源
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
# 安装git-lfs
sudo apt-get install git-lfs
# 初始化git-lfs
git lfs install
# 另外还可以# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
下载模型文件
可以从 modelscope(魔塔社区)上下载,下载前可以开启AutoDL上的[学术加速],下载模型速度会更快。(https://www.autodl.com/docs/network_turbo/)
# 开启学术加速
source /etc/network_turbo
# 下载chatglm3-6b模型文件
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
取消学术加速
如果不再需要建议关闭学术加速,因为该加速可能对正常网络造成一定影响
unset http_proxy && unset https_proxy
配置环境
# 激活conda环境
source activate
# 新建chatglm3-demo的conda环境
conda create -n chatglm3-demo python=3.11
# 进入chatglm3-demo的conda环境
conda activate chatglm3-demo
# 进入指定路径
cd composite_demo
# 安装相关依赖
pip install -r requirements.txt
安装jupyter内核
Code Interpreter模式需要jupyter内核
ipython kernel install --name chatglm3-demo --user
在运行代码前需要设置模型路径
export MODEL_PATH='/root/autodl-tmp/chatglm3-6b'
部署推理
streamlit run main.py --server.port=6006
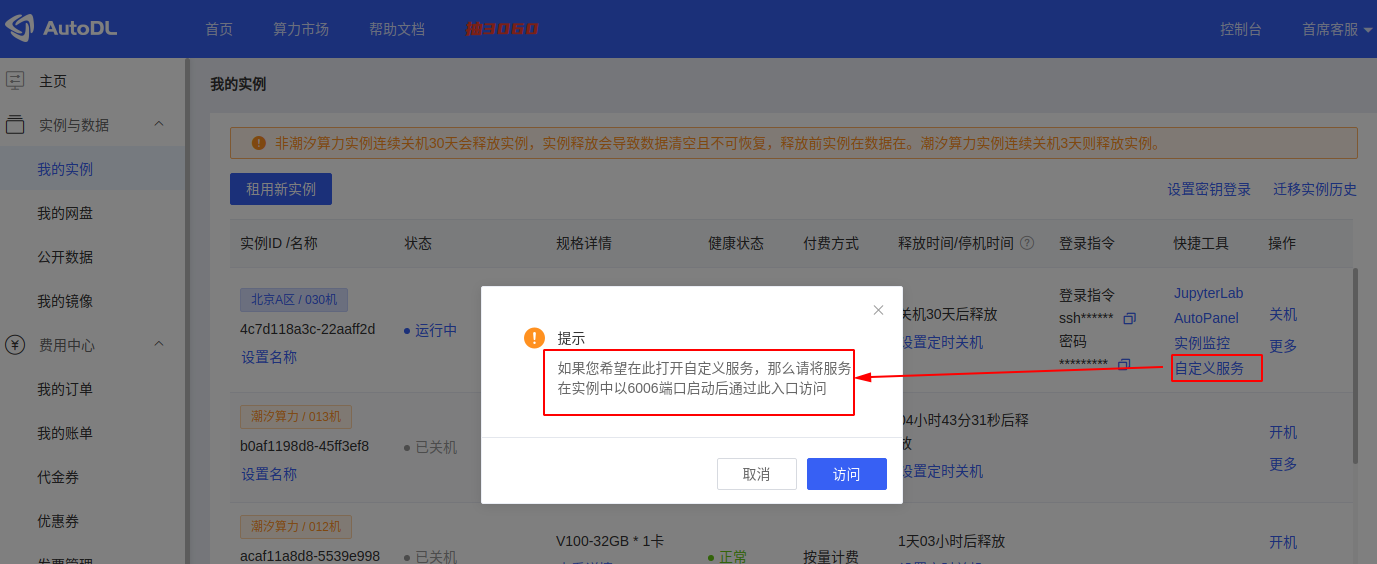
之后就可以从命令行中看到 demo 的地址,但从这里无法打开,需要在我的实例中点击自定义服务访问打开。(AutoDL为了安全只提供了6006端口,且需要实名认证后才会开放,没有实名认证的点击下图中的自定义服务即可完成实名认证)。
ChatGLM3-6B-base 微调
base模型不具备对话能力,仅能够生成单轮回复。如果你希望使用多轮对话模型,使用Chat模型进行微调。官方对 Base版提供的是基于Lora的微调。
下载 ChatGLM3-6B-base 模型
# 从modelscope下载chatglm3-6b-base模型
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b-base.git
由于Lora微调需要peft框架,故这里新建一个基于chatglm3-base的环境。
conda create -n chatglm3-base python=3.11
conda activate chatglm3-base
cd ChatGLM3
pip install -r requirements.txt
cd finetune_basemodel
pip install -r requirements.txt
数据下载
数据使用斯坦福的alpaca_data数据。
下载链接:https://github.com/tatsu-lab/stanford_alpaca/blob/main/alpaca_data.json
[
{
“instruction”: “Give three tips for staying healthy.”,
“input”: “”,
“output”: “1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule.”
},
…]
下载后对数据进行格式转换
python ./scripts/formate_alpaca2jsonl.py
转换后,context是对话的上文,也就是模型的输入,target是对话的下文,也就是模型的输出。
{“context”: “hello”, “target”: “hi,I am ChatGLM3”}
修改微调文件
# 修改文件
vi ./scripts/finetune_lora.sh
根据GPU情况修改GPU的数量,这里我们设置为1
NUM_GPUS=1
修改模型路径
BASE_MODEL_PATH=/root/autodl-tmp/chatglm3-6b-base
执行微调命令
# 修改文件
bash ./scripts/finetune_lora.sh
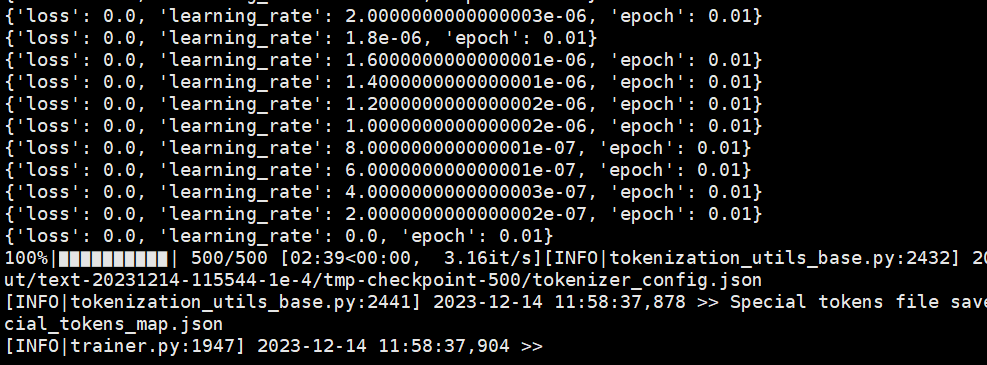
显存占用情况如下:约占22G显存。
微调结束后会生成下面的lora权重文件。

推理
python inference.py --model "/root/autodl-tmp/chatglm3-6b-base" ----lora-path output
ChatGLM3-6B-chat 微调
相关脚本在 finetune_basemodel_demo 下。
官方提供了针对多轮对话和单轮对话的微调过程,同时都包含全量微调和P-tuning V2 的微调方法。
多轮对话微调
多轮对话微调数据格式
[
{
"conversations": [
{
"role": "system",
"content": "<system prompt text>"
},
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
},
// ... Muti Turn
{
"role": "user",
"content": "<user prompt text>"
},
{
"role": "assistant",
"content": "<assistant response text>"
}
]
}
// ...
]
这里使用 ToolAlpaca 数据集
需要先将数据下载下来,运行下面代码对下载的数据集进行格式转换
python ./scripts/format_tool_alpaca.py --path "train_data.json"

修改微调脚本
vi ./scripts/finetune_pt_multiturn.sh
修改模型路径
BASE_MODEL_PATH=/root/autodl-tmp/chatglm3-6b
执行基于P-Tuning v2微调代码
bash ./scripts/finetune_pt_multiturn.sh
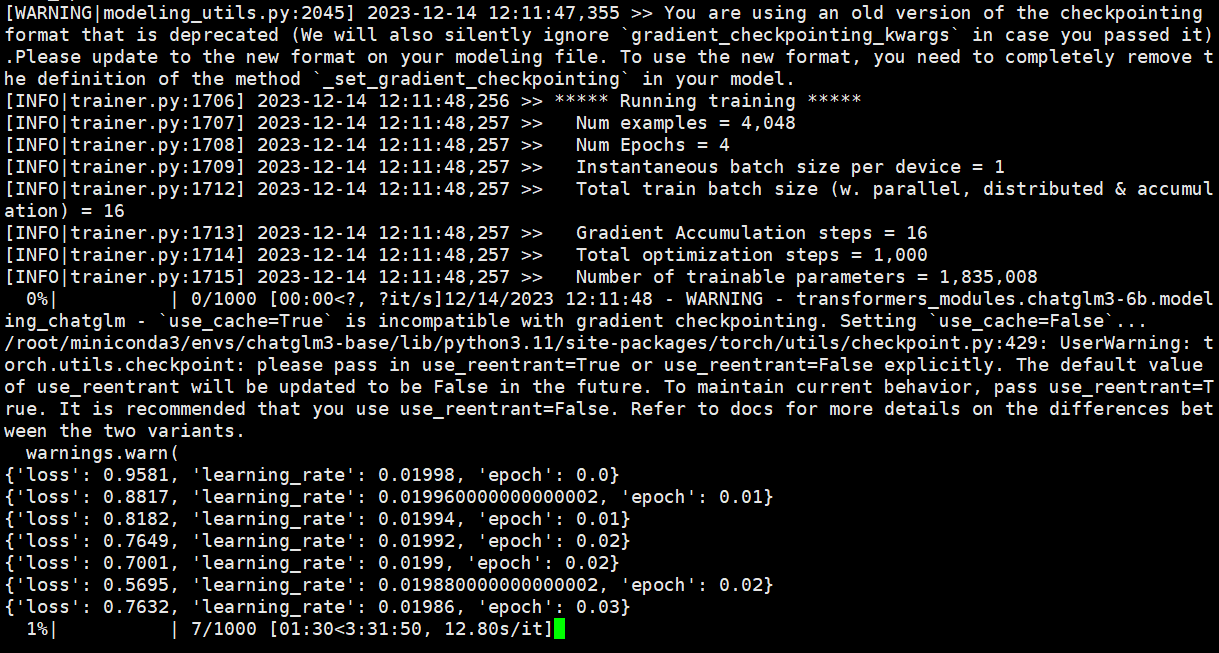
显存占用情况如下:约占16G显存。
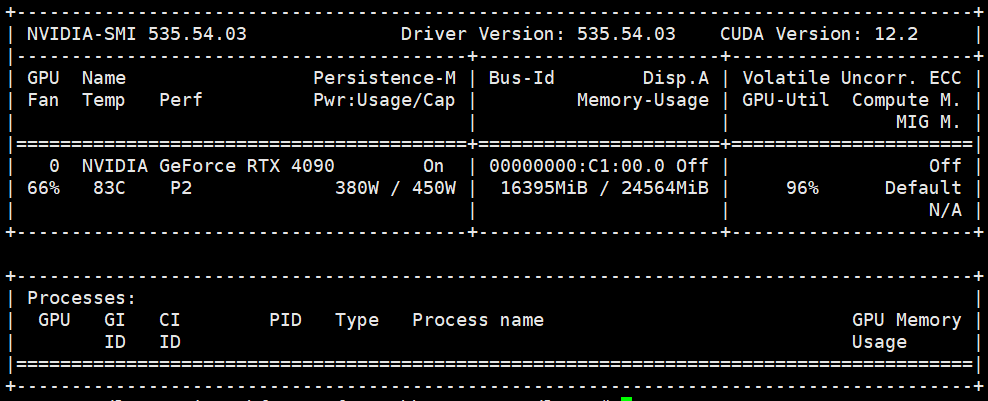
部署推理
对于 P-Tuning v2 微调,可以使用以下方式进行部署
cd ../composite_demo
MODEL_PATH="/root/autodl-tmp/chatglm3-6b" PT_PATH="path to p-tuning checkpoint" streamlit run main.py
单轮对话微调
相关脚本在 finetune_chatmodel_demo 下。
对于输入-输出格式,样例采用如下输入格式
[
{
"prompt": "<prompt text>",
"response": "<response text>"
}
// ...
]
使用 AdvertiseGen 数据集来进行微调,下载后将解压后的 AdvertiseGen 目录放到本目录下。
python ./scripts/format_advertise_gen.py --path "AdvertiseGen/train.json"
修改微调脚本
vi ./scripts/finetune_pt.sh
修改模型路径
BASE_MODEL_PATH=/root/autodl-tmp/chatglm3-6b
执行微调脚本
bash ./scripts/finetune_pt.sh
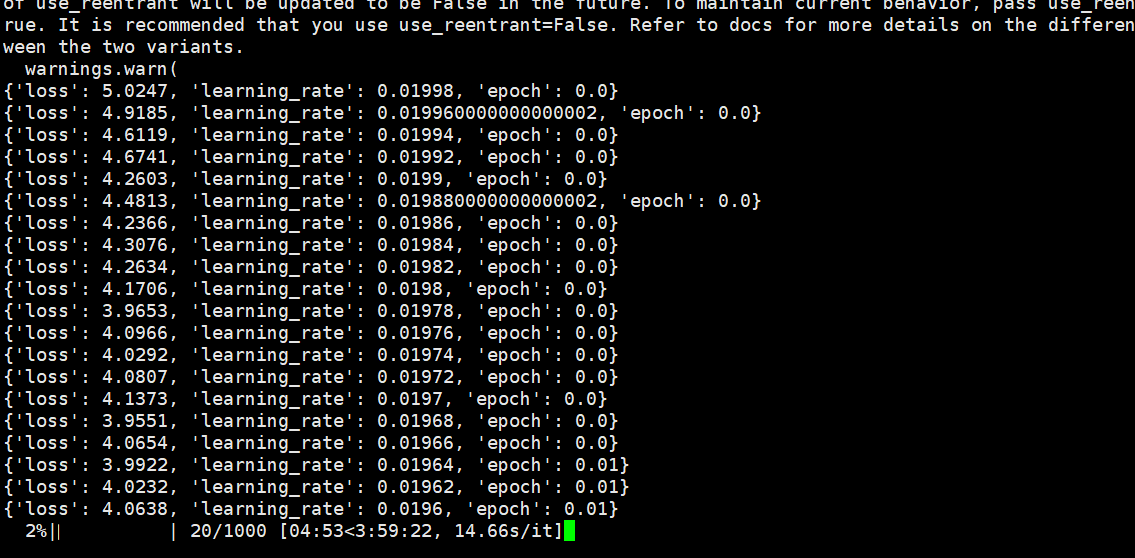
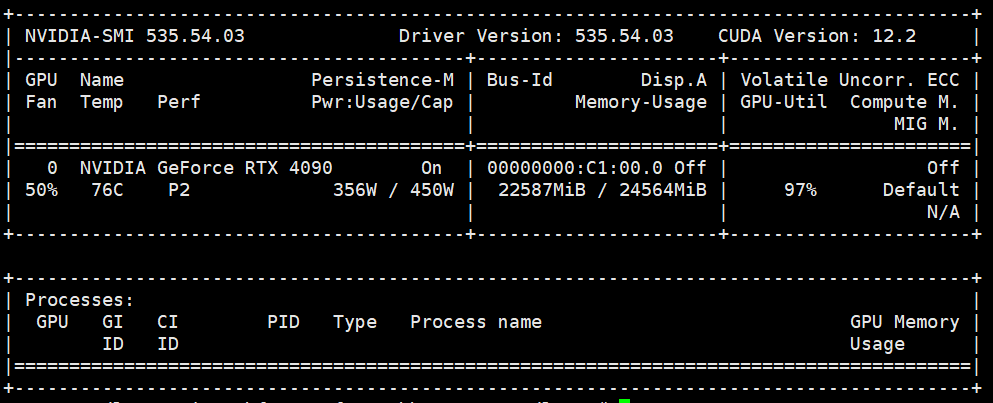
显存占用情况如下:约占22G显存。
推理
python inference.py \
--tokenizer /root/autodl-tmp/chatglm3-6b \
--model "path to finetuned model checkpoint"

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 32
32 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)