

SSD训练自己的数据集(Pytorch),超详细版!!!!
近期开始学习SSD算法啦,从拿到代码的茫然到最后可以跑通自己的代码(本人基础薄弱),已经非常非常开心喽~这篇文章主要介绍一下我的修改过程,以及我训练过程中遇到的问题,可以给大家避避坑,也方便我以后自己使用。那接下来就开始吧~另,在训练中参考的文章标明出处,如有侵权,请联系我删除:【数据集制作】VOC2007格式数据集制作和处理教程(Faster-RCNN模型标准输入)_AI小杨的博客-CSDN博客
近期开始学习SSD算法啦,从拿到代码的茫然到最后可以跑通自己的代码(本人基础薄弱),已经非常非常开心喽~这篇文章主要介绍一下我的修改过程,以及我训练过程中遇到的问题,可以给大家避避坑,也方便我以后自己使用。那接下来就开始吧~
另,在训练中参考的文章标明出处,如有侵权,请联系我删除:
【数据集制作】VOC2007格式数据集制作和处理教程(Faster-RCNN模型标准输入)_AI小杨的博客-CSDN博客
SSD pytorch训练自己的数据集(windows+colab) | 码农家园
SSD的pytorch实现训练中遇到的问题总结_userwarning: volatile was removed and now has no e-CSDN博客
1.数据集制作
这里介绍的是数据集从0到1的过程,如果你已经准备好了数据集,那就跳过这一部分吧~
1.1创建文件夹
在这里我用的是VOC2007格式的数据集,在开始制作数据集之前,需要在SSD工作目录里创建如下几个文件夹:
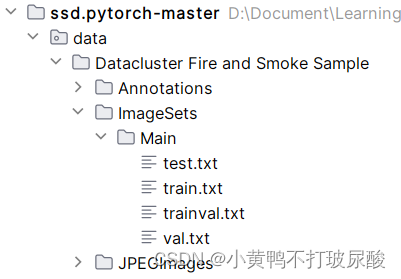
其中,Datacluster Fire and Smoke Sample是我所用的数据集名称(不用和我一致)
- Annotations:图片的标签文件,为xml文件
- JPEGImages:存放原图
- ImageSets:
- Main:
- test.txt:测试集
- train.txt:训练集
- trainval.txt:训练集和验证集
- val.txt:验证集
- Main:
1.2原图数据重命名
创建好相应的文件夹后,将原图放入JPEGImages文件夹中,由于获取的数据集名称杂乱,可以对原图数据进行重命名,脚本文件如下
import os
path = r"C:\Users\xxx\Desktop\VOC2007\JPEGImages"#JPEGImages文件夹所在路径
filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
count=0
for file in filelist:
print(file)
for file in filelist: #遍历所有文件
Olddir=os.path.join(path,file) #原来的文件路径
if os.path.isdir(Olddir): #如果是文件夹则跳过
continue
filename=os.path.splitext(file)[0] #文件名
filetype='.jpg' #文件扩展名
Newdir=os.path.join(path,str(count).zfill(6)+filetype) #用字符串函数zfill 以0补全所需位数
os.rename(Olddir,Newdir)#重命名
count+=1
1.3图像标注
数据集标注工具有很多,这里采用的与原文一致的标注工具:LabelImage,网站上有许多安装教程及使用方法,这里不再赘述,主要介绍几个可以简化操作的方法
- 默认保存地址:快捷键选择默认保存文件夹,使用快捷键Ctrl+r键,选择默认保存的文件夹为Annotation,这样就不用每次都选择文件夹保存了
- 设置默认标签值:如果标注的只有一个标签值,可以设置默认标签值,在标注工具的右上角

- 快捷键: w键选择标注,Ctrl+s键保存,a,d键可以快速切换上、下两张图片
1.4数据集划分
标注完之后,需要对Annotation中的文件进行数据集的划分,将其按照比例划分为训练集、测试集、验证集
import os
import random
trainval_percent = 0.9#验证集和训练集占的百分比
train_percent = 0.7#训练集占的百分比
xmlfilepath = r'C:\Users\xxx\Desktop\VOC2007\Annotations'#Annotation文件夹所在位置
txtsavepath = r'C:\Users\xxx\Desktop\VOC2007\ImageSets\Main'#ImageSets文件下的Main文件夹所在位置
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
#Main文件夹下所对应的四个txt文件夹路径
ftrainval = open(r'C:\Users\xxx\Desktop\VOC2007\ImageSets\Main\trainval.txt', 'w')
ftest = open(r'C:\Users\xxx\Desktop\VOC2007\ImageSets\Main\test.txt', 'w')
ftrain = open(r'C:\Users\xxx\Desktop\VOC2007\ImageSets\Main\train.txt', 'w')
fval = open(r'C:\Users\xxx\Desktop\VOC2007\ImageSets\Main\val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
此时,在ImageSets/Main文件夹下的.txt文件中就有相应图片的名称啦。到此数据集准备完毕~
2.开始训练
2.1环境配置
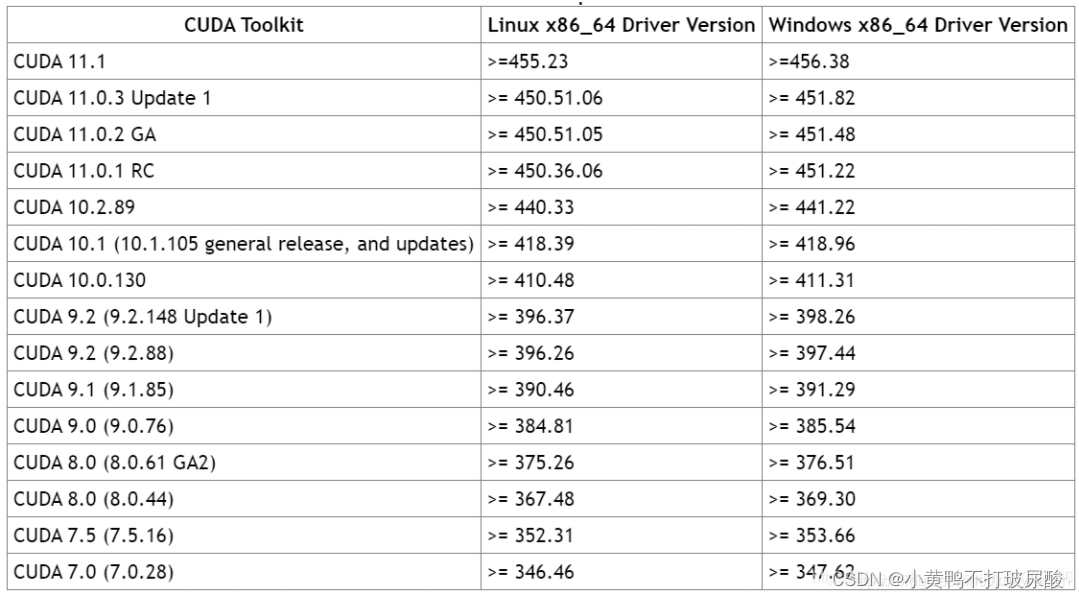
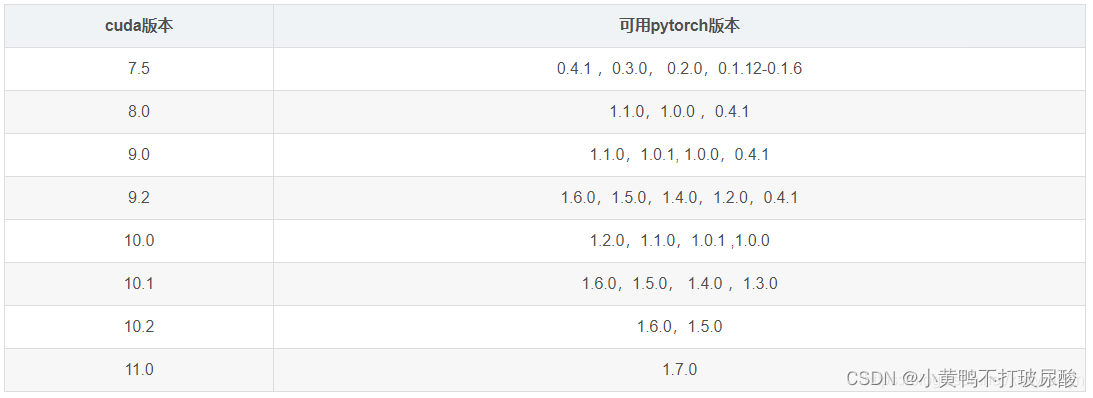
在这里主要就是安装好和你电脑匹配的torch版本以及cv库啦,这里放了两张torch与cuda版本匹配表,非原创!!图片来源于:torch与cuda版本,Driver Version版本,torchversion,torchaudio 对应关系_torch和cuda版本对应_菜鸟_noob的博客-CSDN博客
- CUDA驱动和CUDAToolkit对应版本
- CUDA及其可用PyTorch对应版本
2.2config.py修改
在下面按照VOC和coco数据集的格式复写自己的数据集,为了简单测试能否运行,迭代次数只采用了5次
fire = {
'num_classes': 2, #分类数+1,+1:背景
'lr_steps': (40000, 50000, 60000),#调整学习率的步数
'max_iter': 5,#迭代次数,可以先设小测试下能否运行
'feature_maps': [38, 19, 10, 5, 3, 1],
'min_dim': 300,
'steps': [8, 16, 32, 64, 100, 300],
'min_sizes': [30, 60, 111, 162, 213, 264],
'max_sizes': [60, 111, 162, 213, 264, 315],
'aspect_ratios': [[2], [2, 3], [2, 3], [2, 3], [2], [2]],
'variance': [0.1, 0.2],
'clip': True,
'name': 'FIRE',
}2.3在data中新建fire.py文件
因为我所采用的数据集是VOC的格式,所以可以在voc0712的基础上进行修改,修改处用#########进行标注:
from .config import HOME
import os.path as osp
import sys
import torch
import torch.utils.data as data
import cv2
import numpy as np
if sys.version_info[0] == 2:
import xml.etree.cElementTree as ET
else:
import xml.etree.ElementTree as ET
FIRE_CLASSES = ( 'fire')############
# note: if you used our download scripts, this should be right
FIRE_ROOT = osp.join('D:/Document/Learning/ObjectDetection/SSD/ssd.pytorch-master', "data/Datacluster Fire and Smoke Sample/") ################
class FIREAnnotationTransform(object):###############
"""Transforms a VOC annotation into a Tensor of bbox coords and label index
Initilized with a dictionary lookup of classnames to indexes
Arguments:
class_to_ind (dict, optional): dictionary lookup of classnames -> indexes
(default: alphabetic indexing of VOC's 20 classes)
keep_difficult (bool, optional): keep difficult instances or not
(default: False)
height (int): height
width (int): width
"""
def __init__(self, class_to_ind=None, keep_difficult=False):
# self.class_to_ind = class_to_ind or dict(
# zip(VOC_CLASSES, range(len(VOC_CLASSES))))
# self.keep_difficult = keep_difficult
self.class_to_ind = class_to_ind or dict(fire=0)########只有一个类别,直接创建了字典,否则按照原形式改写
self.keep_difficult = keep_difficult
def __call__(self, target, width, height):
"""
Arguments:
target (annotation) : the target annotation to be made usable
will be an ET.Element
Returns:
a list containing lists of bounding boxes [bbox coords, class name]
"""
res = []
for obj in target.iter('object'):
difficult = int(obj.find('difficult').text) == 1
if not self.keep_difficult and difficult:
continue
name = obj.find('name').text.lower().strip()
bbox = obj.find('bndbox')
pts = ['xmin', 'ymin', 'xmax', 'ymax']
bndbox = []
for i, pt in enumerate(pts):
cur_pt = int(bbox.find(pt).text) - 1
# scale height or width
cur_pt = cur_pt / width if i % 2 == 0 else cur_pt / height
bndbox.append(cur_pt)
label_idx = self.class_to_ind[name]
bndbox.append(label_idx)
res += [bndbox] # [xmin, ymin, xmax, ymax, label_ind]
# img_id = target.find('filename').text[:-4]
return res # [[xmin, ymin, xmax, ymax, label_ind], ... ]
class FIREDetection(data.Dataset):##############
"""VOC Detection Dataset Object
input is image, target is annotation
Arguments:
root (string): filepath to VOCdevkit folder.
image_set (string): imageset to use (eg. 'train', 'val', 'test')
transform (callable, optional): transformation to perform on the
input image
target_transform (callable, optional): transformation to perform on the
target `annotation`
(eg: take in caption string, return tensor of word indices)
dataset_name (string, optional): which dataset to load
(default: 'VOC2007')
"""
def __init__(self, root,
# image_sets=[('2007', 'trainval'), ('2012', 'trainval')],
image_sets='trainval',#################
transform=None, target_transform=FIREAnnotationTransform(),#############
dataset_name='FIRE'):################
self.root = root
self.image_set = image_sets
self.transform = transform
self.target_transform = target_transform
self.name = dataset_name
self._annopath = osp.join('%s', 'Annotations', '%s.xml')
self._imgpath = osp.join('%s', 'JPEGImages', '%s.jpg')
self.ids = list()
# for (year, name) in image_sets:
# rootpath = osp.join(self.root, 'VOC' + year)
# for line in open(osp.join(rootpath, 'ImageSets', 'Main', name + '.txt')):
# self.ids.append((rootpath, line.strip()))
for line in open(FIRE_ROOT+'/ImageSets/Main/'+self.image_set+'.txt'):
self.ids.append((FIRE_ROOT, line.strip()))###################
def __getitem__(self, index):
im, gt, h, w = self.pull_item(index)
return im, gt
def __len__(self):
return len(self.ids)
def pull_item(self, index):
img_id = self.ids[index]
target = ET.parse(self._annopath % img_id).getroot()
img = cv2.imread(self._imgpath % img_id)
height, width, channels = img.shape
if self.target_transform is not None:
target = self.target_transform(target, width, height)
if self.transform is not None:
target = np.array(target)
img, boxes, labels = self.transform(img, target[:, :4], target[:, 4])
# to rgb
img = img[:, :, (2, 1, 0)]
# img = img.transpose(2, 0, 1)
target = np.hstack((boxes, np.expand_dims(labels, axis=1)))
return torch.from_numpy(img).permute(2, 0, 1), target, height, width
# return torch.from_numpy(img), target, height, width
def pull_image(self, index):
'''Returns the original image object at index in PIL form
Note: not using self.__getitem__(), as any transformations passed in
could mess up this functionality.
Argument:
index (int): index of img to show
Return:
PIL img
'''
img_id = self.ids[index]
return cv2.imread(self._imgpath % img_id, cv2.IMREAD_COLOR)
def pull_anno(self, index):
'''Returns the original annotation of image at index
Note: not using self.__getitem__(), as any transformations passed in
could mess up this functionality.
Argument:
index (int): index of img to get annotation of
Return:
list: [img_id, [(label, bbox coords),...]]
eg: ('001718', [('dog', (96, 13, 438, 332))])
'''
img_id = self.ids[index]
anno = ET.parse(self._annopath % img_id).getroot()
gt = self.target_transform(anno, 1, 1)
return img_id[1], gt
def pull_tensor(self, index):
'''Returns the original image at an index in tensor form
Note: not using self.__getitem__(), as any transformations passed in
could mess up this functionality.
Argument:
index (int): index of img to show
Return:
tensorized version of img, squeezed
'''
return torch.Tensor(self.pull_image(index)).unsqueeze_(0)
2.4__init__文件
# from .voc0712 import VOCDetection, VOCAnnotationTransform, VOC_CLASSES, VOC_ROOT
from .fire import FIREDetection,FIREAnnotationTransform,FIRE_CLASSES,FIRE_ROOT
# from .coco import COCODetection, COCOAnnotationTransform, COCO_CLASSES, COCO_ROOT, get_label_map2.5 ssd.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from layers import *
from data import voc, coco, fire ############
import os def __init__(self, phase, size, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = (coco, voc, fire)[num_classes == 2] ###########
self.priorbox = PriorBox(self.cfg)
# self.priors = Variable(self.priorbox.forward(), volatile=True)
with torch.no_grad(): ############
self.priors = self.priorbox.forward() #############
self.size = size2.6 train.py
超参数中的batcsize等可以根据自己的实际情况修改
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
train_set = parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', default='FIRE', choices=['VOC', 'COCO','FIRE'],########
type=str, help='VOC or COCO')
parser.add_argument('--dataset_root', default=FIRE_ROOT, ########
help='Dataset root directory path')在train函数中,仿写加入自己的数据集
elif args.dataset == 'FIRE':
# if args.dataset_root == FIRE_ROOT:
# parser.error('Must specify dataset if specifying dataset_root')
cfg = fire
# print(cfg)
dataset = FIREDetection(root=args.dataset_root,
transform=SSDAugmentation(cfg['min_dim'],
MEANS))如果你像我一样采用的是cpu的话,记得修改文件里的所有.cuda和参数里的--GPU。
到这儿就修改完成啦,你可以尝试跑一下,如果顺利跑通,那就恭喜!(虽然概率不高)
遇到了问题的话,也不要犯愁,就接下来看第三部分吧~
####################### 补充 断点续训 #######################
**当我们受训练时间长影响,无法一次性训练完但又困得不行时,就可以使用断点续训功能啦!这样隔天我们还可以从断点处接着训练,不会让之前的努力付之东流,具体操作如下:
首先要将参数列表的resume参数设置为True:
parser.add_argument('--resume', default=True, type=str,
help='Checkpoint state_dict file to resume training from')然后将权重路径地址(该处为“weights/FIRE.pth")进行加载,修改如下
if args.resume:
print('Resuming training, loading {}...'.format(args.resume))
# ssd_net.load_weights(args.resume)
ssd_net.load_weights("weights/FIRE.pth")#############
else:
vgg_weights = torch.load(args.save_folder + args.basenet)
print('Loading base network...')
ssd_net.vgg.load_state_dict(vgg_weights)这样再次开始训练时,就可以从断点处开始续训啦!
3.问题总结
3.1 StopIteration
将train.py中的images, targets = next(batch_iterator)改成
try:
images, targets = next(batch_iterator)
except StopIteration:
batch_iterator = iter(data_loader)
images, targets = next(batch_iterator)3.2 IndexError: invalid index of a 0-dim tensor. Use tensor.item() to convert a 0-dim tensor to a Python number
将train.py中data[0]全改为data.item()
loc_loss += loss_l.data.item()#############
conf_loss += loss_c.data.item()###########
# if iteration % 10 == 0:
# print('timer: %.4f sec.' % (t1 - t0))
# print('iter ' + repr(iteration) + ' || Loss: %.4f ||' % (loss.data.item()), end=' ')
print('timer: %.4f sec.' % (t1 - t0)) #每次迭代打印一次
print('iter ' + repr(iteration) + ' || Loss: %.4f ||' % (loss.data.item()), end=' ')##############
if args.visdom:
update_vis_plot(iteration, loss_l.data.item(), loss_c.data.item(),##########
iter_plot, epoch_plot, 'append')
if iteration != 0 and iteration % 5000 == 0:
print('Saving state, iter:', iteration)
torch.save(ssd_net.state_dict(), 'weights/ssd300_FIRE_' +###########漏掉了一处,这里也要修改为自己的数据集名哦
repr(iteration) + '.pth')3.3 xavier_uniform已经被弃用
在train.py中将init.xavier_uniform(param)改为
def xavier(param):
init.xavier_uniform_(param)3.4 UserWarning: volatile was removed and now has no effect. Use with torch.no_grad(): instead.molded_images = Variable(molded_images, volatile=True)
在train.py中删除volatile=True
images = Variable(images)
targets = [Variable(ann) for ann in targets]3.5 UserWarning: size_average and reduce is now deprecated,please use reduction=‘sum’ instead
在multibox_loss.py中修改为
loss_l = F.smooth_l1_loss(loc_p, loc_t, reduction='sum')loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')3.6 UserWarning: torch.set_default_tensor_type() is deprecated as of PyTorch 2.1
train.py中将torch.set_default_tensor_type('torch.FloatTensor')修改为
torch.set_default_dtype(torch.float32)3.7 ValueError: setting an array element with a sequence.
在augmentations.py文件中修改
def __init__(self):
self.sample_options = np.array([
# using entire original input image
None,
# sample a patch s.t. MIN jaccard w/ obj in .1,.3,.4,.7,.9
(0.1, None),
(0.3, None),
(0.7, None),
(0.9, None),
# randomly sample a patch
(None, None),
],dtype=object) # 随机选择的数组维度不一致时,需加入dtype=object(numpy版本过高带来的问题)3.8 其他
文章SSD的pytorch实现训练中遇到的问题总结_userwarning: volatile was removed and now has no e-CSDN博客中给的建议,但我好像没有遇到,如果有报错的可以参考

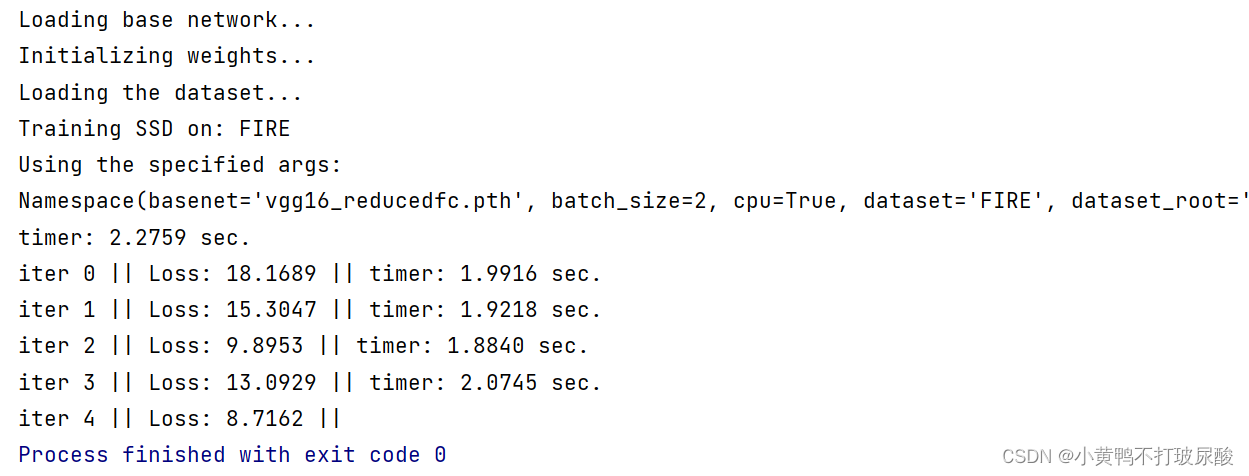
4.运行展示
经过一系列操作,终于运行成功啦!(这里修改了每一轮打印一次信息)~~~

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)