
一文通透各种注意力:从多头注意力MHA到分组查询注意力GQA、多查询注意力MQA
因此,可以确认:在 MQA 中,除了 query 向量还保存着 8 个头,key 和 value 向量都只剩 1 个「公共头」了,这也正好印证了论文中所说的「所有 head 之间共享一份 key 和 value 的参数」然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA)模型中与 KV 缓存大小相关的内存成本显着增长。对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,
前言
通过本博客内之前的文章可知,自回归解码的标准做法是缓存序列中先前标记的键(K)和值(V) 对,从而加快注意力计算速度
- 然而,随着上下文窗口或批量大小的增加,多头注意力 (MHA)模型中与 KV 缓存大小相关的内存成本显着增长
- 对于较大的模型,KV 缓存大小成为瓶颈,键和值投影可以在多个头之间共享,而不会大幅降低性能,可以使用
具有单个 KV 投影的原始多查询格式(MQA),ChatGLM2-6B即用的这个
不过,多查询注意(Multi-query attention,简称MQA)只使用一个键值头
虽大大加快了解码器推断的速度,但MQA可能导致质量下降,而且仅仅为了更快的推理而训练一个单独的模型可能是不可取的 - 或具有多个 KV 投影的分组查询注意力(grouped-query attention,简称GQA),LLaMA2和Mistral均用的这个
这是一种多查询注意的泛化,它通过折中(多于一个且少于查询头的数量,比如4个)键值头的数量,使得经过强化训练的GQA以与MQA相当的速度达到接近多头注意力的质量,即速度快 质量高
经实验论证,GQA 变体在大多数评估任务上的表现与 MHA 基线相当,并且平均优于 MQA 变体
为方便一目了然,我用下表 帮大家再总结一下
| 多头注意力MHA | 分组查询注意力GQA | 多查询注意力MQA |
| LLaMA2 | ChatGLM2 | |
| Mistral | Google Gemini | |
| Google gemma2 |
第一部分 多头注意力
关于什么是多头注意力,可以参见此文《Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT》中的3.1.6 多头注意力机制“multi-headed” attention,我特地引用该节的内容,如下所示
为进一步完善自注意力层,下面增加一种叫做“多头”注意力(“multi-headed” attention)的机制,并在两方面提高了注意力层的性能:
- 它扩展了模型专注于不同位置的能力。编码“Thinking”的时候,虽然最后Z1或多或少包含了其他位置单词的信息,但是它实际编码中把过多的注意力放在“Thinking”单词本身(当然了,这也无可厚非,毕竟自己与自己最相似嘛)
且如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”和哪几个词都最有关联,这时模型的“多头”注意机制会起到作用 - 它给出了注意力层的多个“表示子空间”(representation subspaces)
July注:第一次看到这里的朋友,可能会有疑问,正如知乎上有人问(https://www.zhihu.com/question/341222779?sort=created):为什么Transformer 需要进行Multi-head Attention,即多头注意力机制?
- 叫TniL的答道:可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力有助于网络捕捉到更丰富的特征/信息
且论文中是这么说的:Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
关于different representation subspaces,举一个不一定妥帖的例子:
当你浏览网页的时候,你可能在颜色方面更加关注深色的文字,而在字体方面会去注意大的、粗体的文字。这里的颜色和字体就是两个不同的表示子空间。同时关注颜色和字体,可以有效定位到网页中强调的内容
使用多头注意力,也就是综合利用各方面的信息/特征(毕竟,不同的角度有着不同的关注点)- 叫LooperXX的则答道:在Transformer中使用的多头注意力出现前,基于各种层次的各种fancy的注意力计算方式,层出不穷。而Transformer的多头注意力借鉴了CNN中同一卷积层内使用多个卷积核的思想,原文中使用了 8 个 scaled dot-product attention ,在同一multi-head attention 层中,输入均为 KQV,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息,在此之前的 A Structured Self-attentive Sentence Embedding 也有着类似的思想
————
简而言之,就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立,其核心思想在于,抽取到更加丰富的特征信息
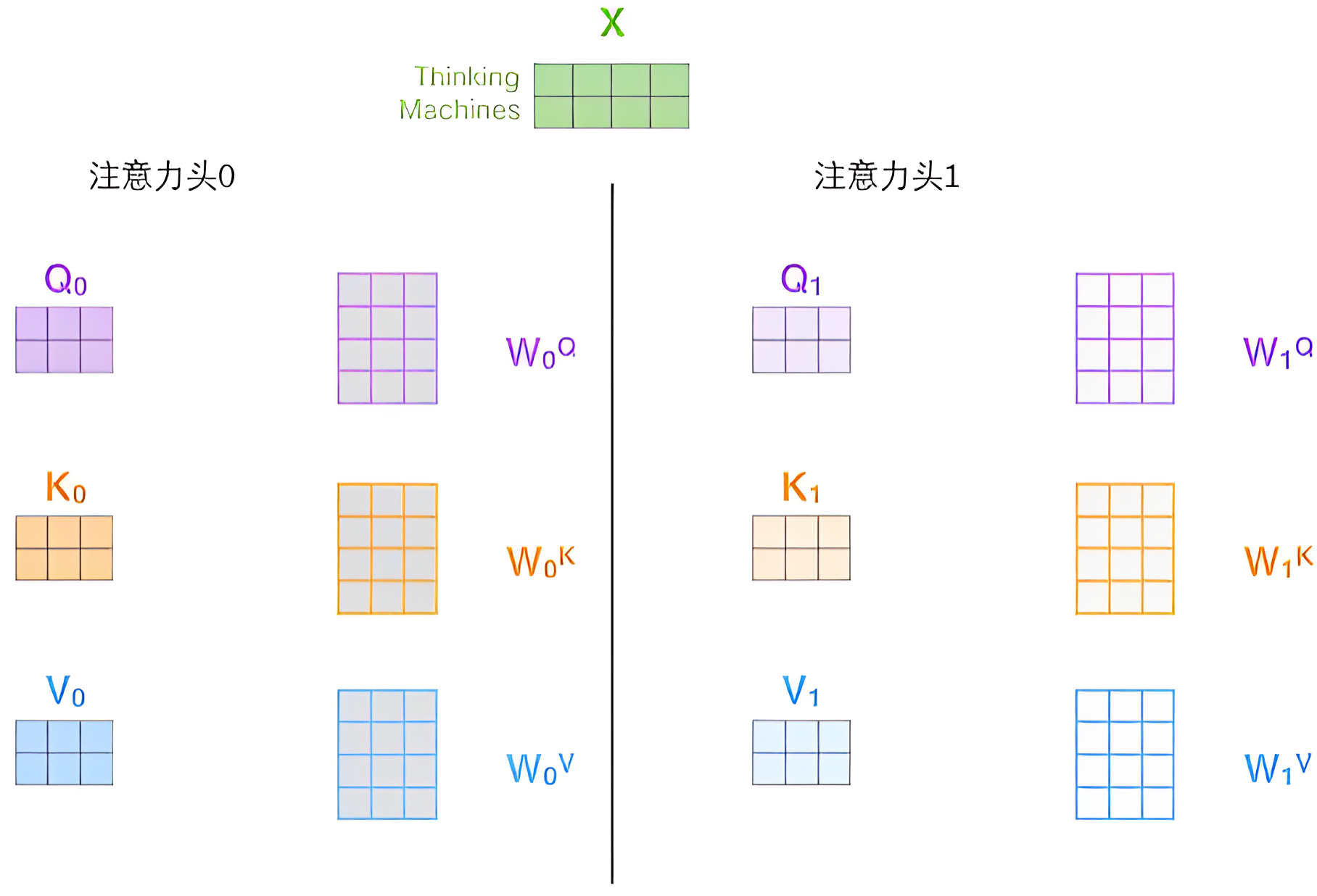
OK,接下来,我们将看到对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用8个注意力头,则对于每个编码器/解码器都有8个“
”的矩阵集合),每一组都是随机初始化,经过训练之后,输入向量可以被映射到不同的子表达空间中,具体而言
- 在“多头”注意机制下,我们为每个头保持独立的查询/键/值权重矩阵——头与头之间是没有交互计算的,从而产生不同的查询/键/值矩阵
和之前一样,我们拿乘以
/
/
矩阵来产生查询/键/值矩阵
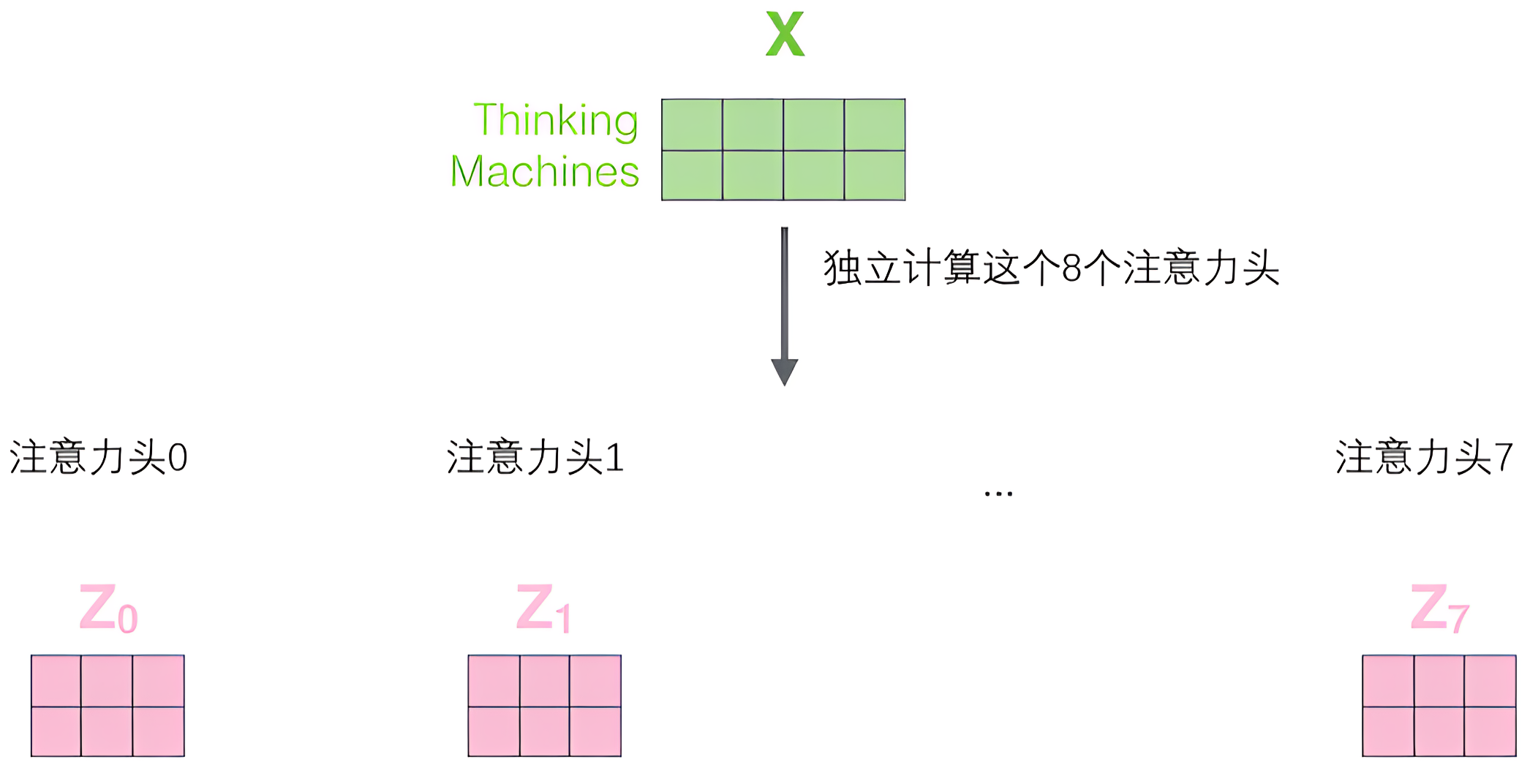
- 如果我们做与上述相同的自注意力计算,只需8次不同的权重矩阵运算,我们就会得到8个不同的Z矩阵
- 这给我们带来了一点挑战。前馈层没法一下子接收8个矩阵,它需要一个单一的矩阵(最终这个单一矩阵类似输入矩阵
所以我们需要一种方法把这8个矩阵合并成一个矩阵。那该怎么做?其实可以直接把这些矩阵拼接在一起,然后乘以一个附加的权重矩阵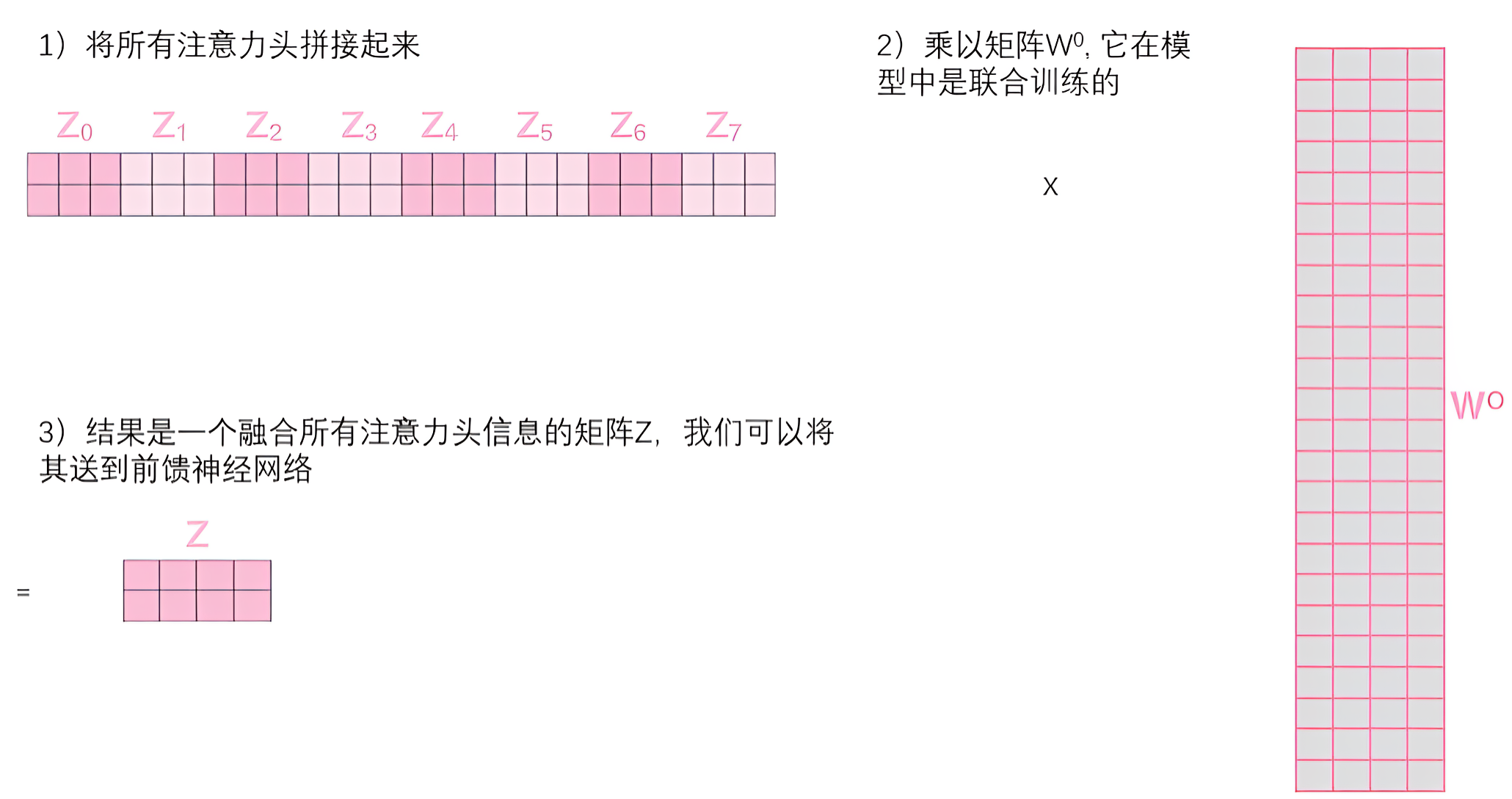
以上基本就是多头自注意力的全部了,接下来把所有矩阵集中展示下,如下图所示
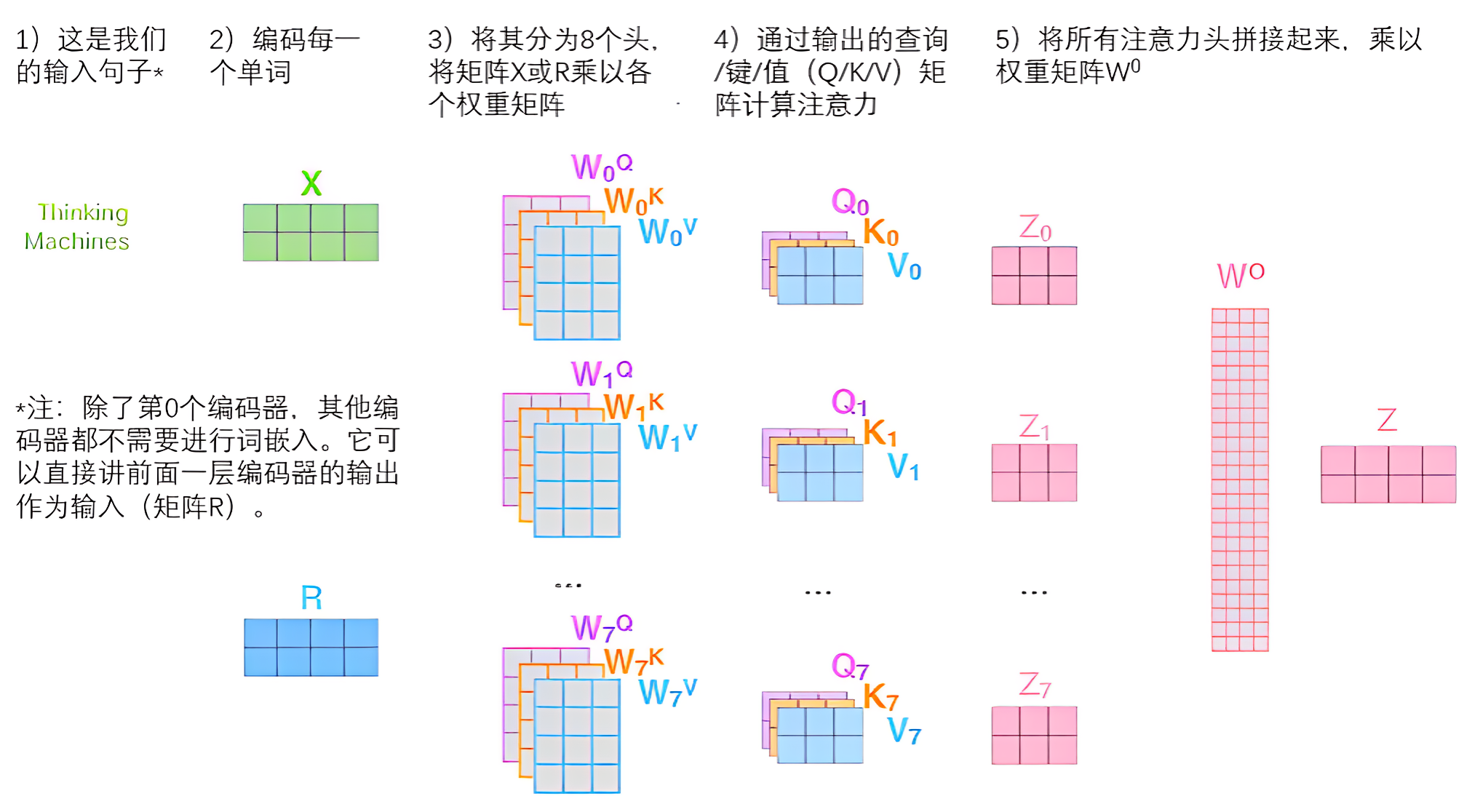
第二部分 ChatGLM2之多查询注意力(Muti Query Attention)
2.1 MQA的核心特征:各自Query矩阵,但共享Key 和 Value 矩阵
多查询注意力(Muti Query Attention)是 2019 年Google一研究者提出的一种新的 Attention 机制(对应论文为:Fast Transformer Decoding: One Write-Head is All You Need、这是其解读之一),其能够在保证模型效果的同时加快 decoder 生成 token 的速度
除了ChatGLM2用的MQA之外,23年12月Google最新推出的「多模态大模型Gemini」的注意力机制也使用的Multi-Query Attention
那其与17年 Google提出的transformer中多头注意力机制(简称MHA)有啥本质区别呢?有意思的是,区别在于:

- 我们知道MHA的每个头都各自有一份不同的Key、Query、Value矩阵
- 而MQA 让所有的头之间 共享 同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量
总之,MQA 实际上是将 head 中的 key 和 value 矩阵抽出来单独存为一份共享参数,而 query 则是依旧保留在原来的 head 中,每个 head 有一份自己独有的 query 参数
如下图图右所示
总之,MHA 和 MQA 之间的区别只在于建立 Wqkv Layer 上
2.2 MHA 和 MQA在编码实现上的细节对比
# Multi Head Attention
self.Wqkv = nn.Linear( # 【关键】Multi-Head Attention 的创建方法
self.d_model,
3 * self.d_model, # 有 query, key, value 3 个矩阵, 所以是 3 * d_model
device=device
)
query, key, value = qkv.chunk( # 【关键】每个 tensor 都是 (1, 512, 768)
3,
dim=2
)
# Multi Query Attention
self.Wqkv = nn.Linear( # 【关键】Multi-Query Attention 的创建方法
d_model,
d_model + 2 * self.head_dim, # 只创建 query 的 head 向量,所以只有 1 个 d_model
device=device, # 而 key 和 value 不再具备单独的头向量
)
query, key, value = qkv.split( # query -> (1, 512, 768)
[self.d_model, self.head_dim, self.head_dim], # key -> (1, 512, 96)
dim=2 # value -> (1, 512, 96)
)对比上面的代码,你可以发现
- 在 MHA 中,query, key, value 每个向量均有 768 维度
- 而在 MQA 中,只有 query 是 768 维,而 key 和 value 均只剩下 96 维了,恰好是 1 个 head_dim 的维度
因此,可以确认:在 MQA 中,除了 query 向量还保存着 8 个头,key 和 value 向量都只剩 1 个「公共头」了,这也正好印证了论文中所说的「所有 head 之间共享一份 key 和 value 的参数」
剩下的问题就是如何将这 1 份参数同时让 8 个头都使用,代码里使用矩阵乘法 matmul 来广播,使得每个头都乘以这同一个 tensor,以此来实现参数共享:
def scaled_multihead_dot_product_attention(
query,
key,
value,
n_heads,
multiquery=False,
):
q = rearrange(query, 'b s (h d) -> b h s d', h=n_heads) # (1, 512, 768) -> (1, 8, 512, 96)
kv_n_heads = 1 if multiquery else n_heads
k = rearrange(key, 'b s (h d) -> b h d s', h=kv_n_heads) # (1, 512, 768) -> (1, 8, 96, 512) if not multiquery
# (1, 512, 96) -> (1, 1, 96, 512) if multiquery
v = rearrange(value, 'b s (h d) -> b h s d', h=kv_n_heads) # (1, 512, 768) -> (1, 8, 512, 96) if not multiquery
# (1, 512, 96) -> (1, 1, 512, 96) if multiquery
attn_weight = q.matmul(k) * softmax_scale # (1, 8, 512, 512)
attn_weight = torch.softmax(attn_weight, dim=-1) # (1, 8, 512, 512)
out = attn_weight.matmul(v) # (1, 8, 512, 512) * (1, 1, 512, 96) = (1, 8, 512, 96)
out = rearrange(out, 'b h s d -> b s (h d)') # (1, 512, 768)
return out, attn_weight, past_key_value第三部分 LLaMA2之分组查询注意力——Grouped-Query Attention
23年,Google的研究者们提出了一种新的方法,即分组查询注意(GQA,论文地址为:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints)
GQA将查询头分为G组,每组共享一个键头和一个值头「Grouped-query attention divides query heads into G groups, each of which shares a single key headand value head」
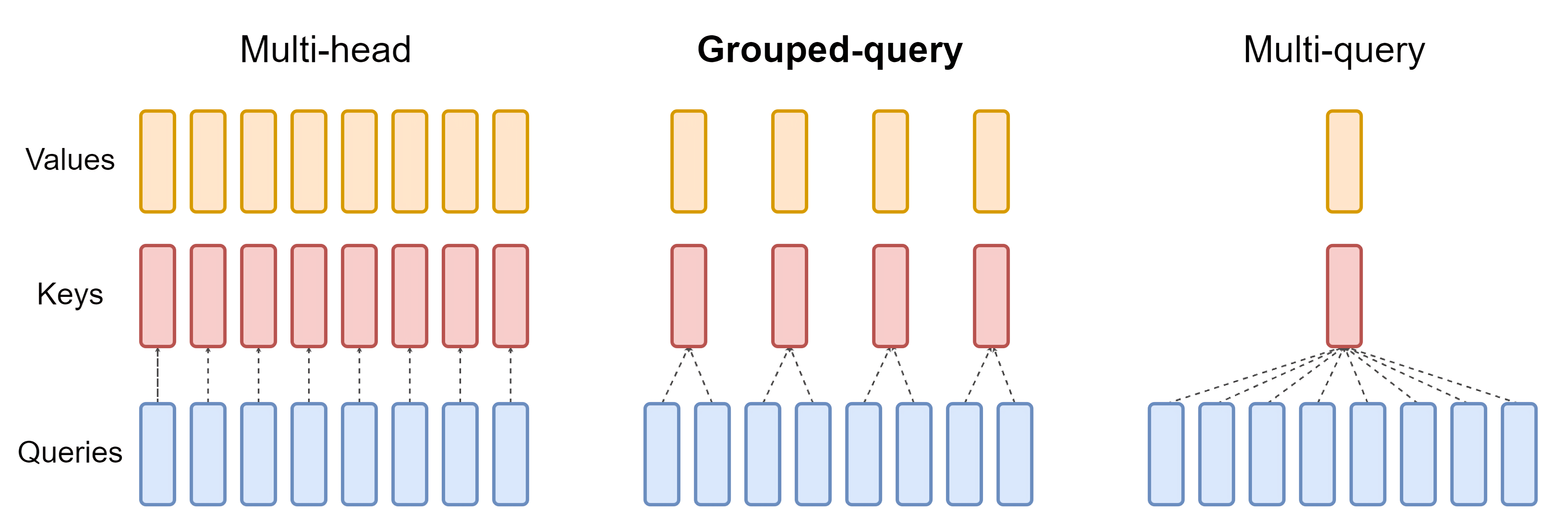
而G的具体大小,可以决定最终的结构具体长什么样:是类似下图左侧的MHA,还是下图右侧的MQA
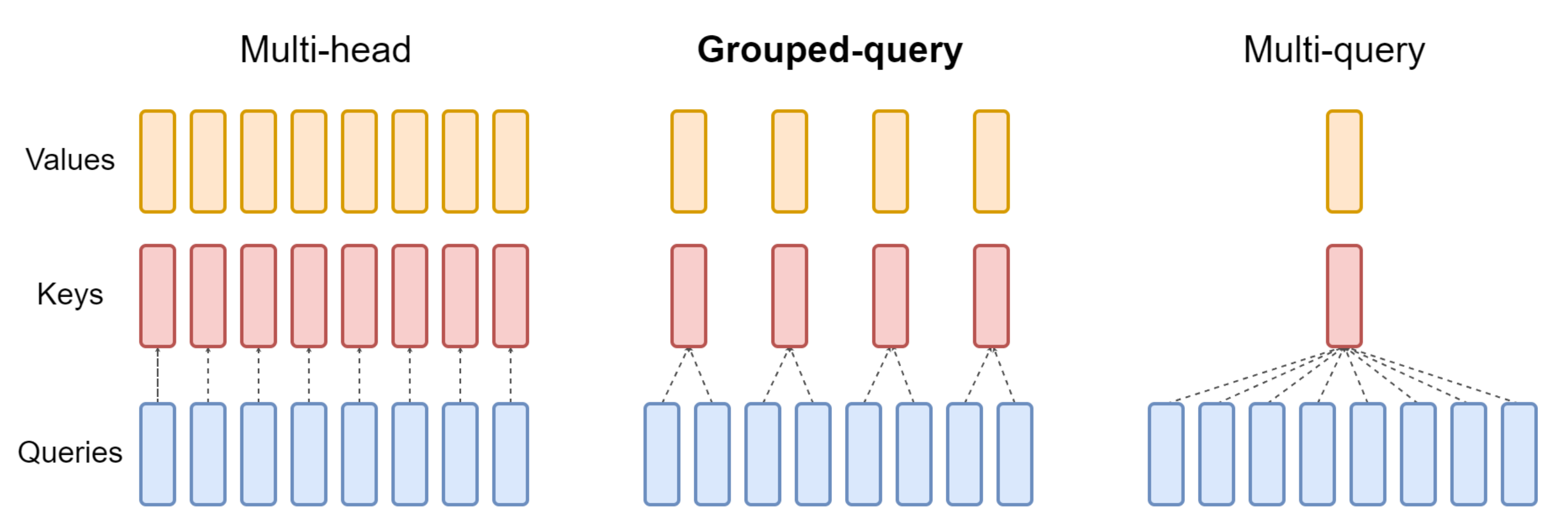
- GQA-G表示有G组的分组查询注意力,如上图中侧所示
GQA-G refers to grouped-querywith G groups. - GQA-1,即只有一个分组,因此只有一个键头和一个值头,这等同于MQA,如上图右侧所示
GQA-1, with a single group and therefore single key and value head, is equivalent toMQA - 而GQA-H,即分组数等于头数,则等同于MHA,如上图左侧所示
while GQA-H, with groups equal to numberof heads, is equivalent to MHA
更进一步,举个例子
- 一般模型中会有这么两个参数:n_heads、n_kv_heads,其中,n_heads的个数便是Q的个数(相当于多少个头 则多少个Q),n_kv_heads指的是K、V的个数
- 因为多个头会共享一个K或V,则头和Q的个数会大于K V的个数,比如可能8个头下:8个Q、4个K、4个V,即如下图图中所示
// 待更
更多推荐


 27
27 1
1- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)