

在代码中使用训练好的YOLO各版本的模型
recursive=True&expand=False (Caused by NewConnectionError(': Failed to establish a new connection: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。是 OpenCV(一个开源的计算机视觉库)的一个函数,用于在图像上绘制矩形。
目录
目录
加载权重文件和图片,并进正向推导预测 (文件地址一定要对,最好不要出现中文)
注意: 这里一共会展示三种方式,推荐第三种方法
方法一、利用YOLO模块加载模型
下载模块
这里拿YOLOv5举例,同样你也可以下载YOLOv8等,如pip install yolov8 等等。
pip install yolov5
pip install opencv-python
加载权重文件和图片,并进正向推导预测 (文件地址一定要对,最好不要出现中文)
import cv2
import yolov5
model = yolov5.load('runs/train/exp/weights/best.pt')
imgPath = 'dataset/test/images/0db77f7288ba94280cfb8fb98d3f56cb.jpg'
results = model(imgPath, augment=True)
img=cv2.imread(imgPath)
#以下可以获取到标签label,以及检测框的左上右下角坐标,并为图画框
for *xyxy, conf, cls in results.xyxy[0]:
label = f'{model.model.names[int(cls)]} {conf:.2f}'
cv2.rectangle(img, (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])), (0, 0, 255), 2)
cv2.putText(img, label, (int(xyxy[0]), int(xyxy[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
print("label:"+str(label))
# 显示帧
cv2.imshow('YOLOv5 Real-time Object Detection', img)
cv2.waitKey(0)
#如果想保存
#cv2.imwrite('output.jpg', img)效果如下
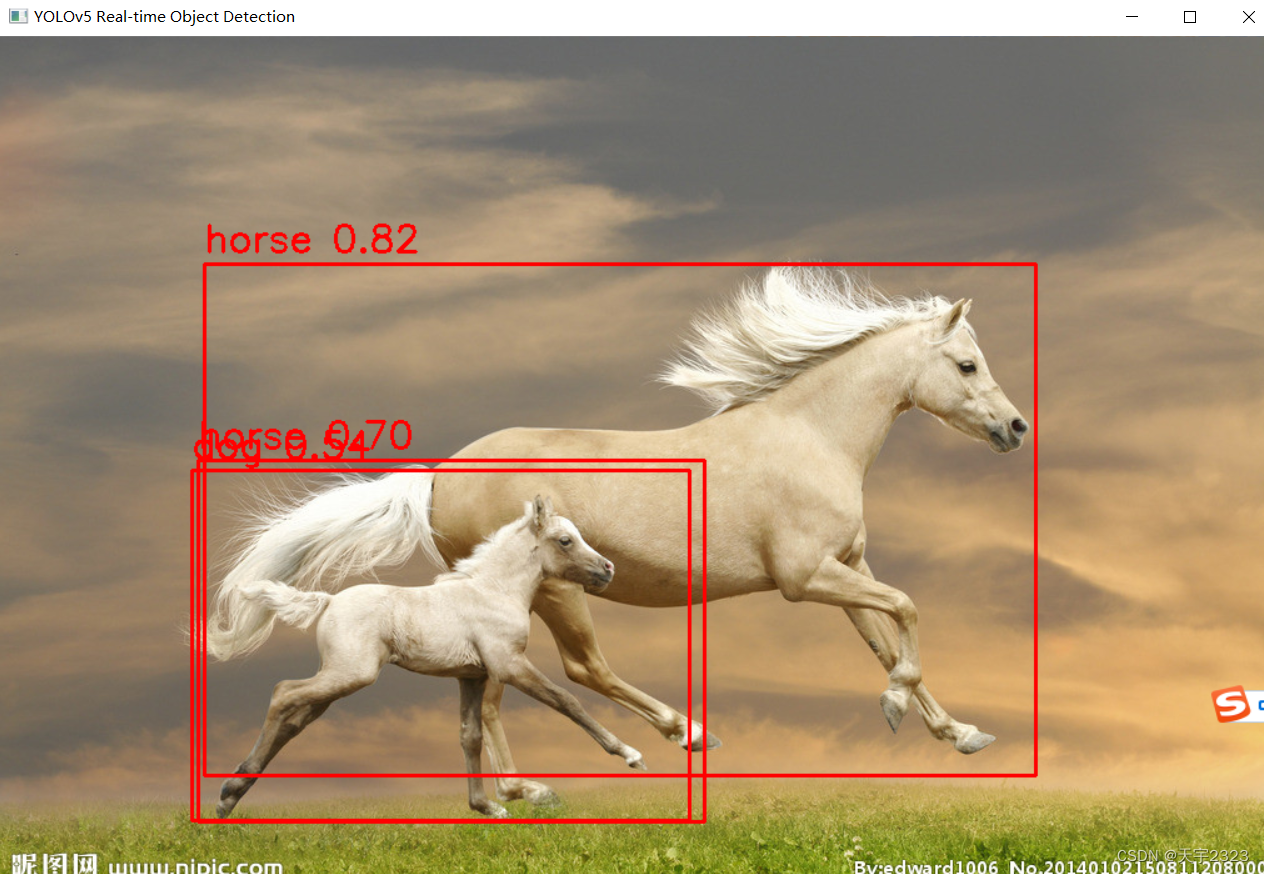
路径地址错误可能会出现如下问题(建议路径不要出现中文,再不想尝试用绝对地址而非相对地址)
requests.exceptions.ConnectionError: (MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/weights/yolov5s.pt/tree/main?recursive=True&expand=False (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x0000021B0220D580>: Failed to establish a new connection: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。'))"), '(Request ID: 5d71cb57-14f3-401f-81d1-0e13e48e6f91)')
预测摄像头当前拍摄的内容
import cv2
from yolov5 import YOLOv5
# 加载预训练的YOLOv5模型
model = YOLOv5("F:/File/AI/deepLearn/yolov5-master/weights/yolov5s.pt",device='cpu') # 选择模型
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
# 从摄像头读取帧
ret, frame = cap.read()
if not ret:
break
# 使用YOLOv5进行目标检测
results = model.predict(frame)
# 在帧上绘制检测结果
#xyxy得到左上右下角点坐标数组,conf代表置信度,cls代表类型名的下标
for *xyxy, conf, cls in results.xyxy[0]:
label = f'{model.model.names[int(cls)]} {conf:.2f}'
cv2.rectangle(frame, (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])), (0, 0, 255), 2)
cv2.putText(frame, label, (int(xyxy[0]), int(xyxy[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.0, color=(0, 0, 255), thickness=2)
# 显示帧
cv2.imshow('YOLOv5 Real-time Object Detection', frame)
# 按w键退出
if cv2.waitKey(1) & 0xFF == ord('W'):
break
# 释放资源并关闭窗口
cap.release()
cv2.destroyAllWindows()
效果
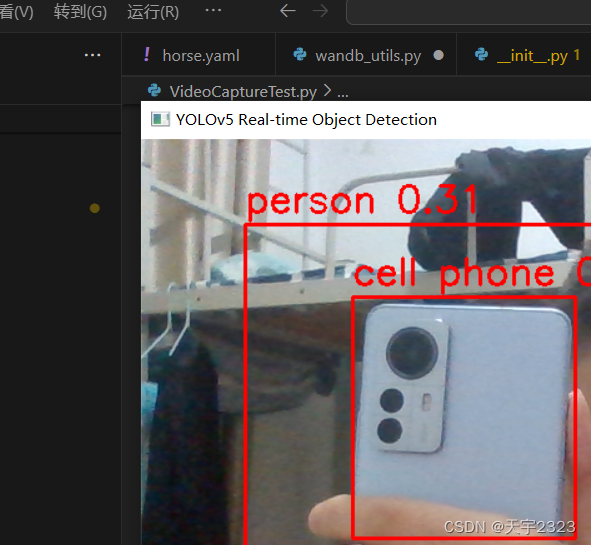
可能会遇到的问题
cv2.error: OpenCV(4.8.0) D:\a\opencv-python\opencv-python\opencv\modules\highgui\src\window.cpp:1272 error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support. If you are on Ubuntu or Debian, install libgtk2.0-dev and pkg-config, then re-run cmake or configure script in function 'cvShowImage'
我的用如下方法解决了问题。
pip uninstall opencv-python
pip install opencv-python函数部分的提示:
label = f'{model.model.names[int(cls)]} {conf:.2f}'f'{……}' #表示这是一个格式化字符串。model.model.names[int(cls)] #获取类型名。conf:.2f#表示置信值小数位为2
方法二、利用pytorch.hub.load加载模型
注意事项:这里的加载本地模型的代码文件要和YOLO项目的modes文件夹和hubconf.py同一目录,models文件夹存放了配置的yaml文件和Yolo的加载模型权重并进行正向传播的py文件。hubconf.py在联网情况下会自己加载。
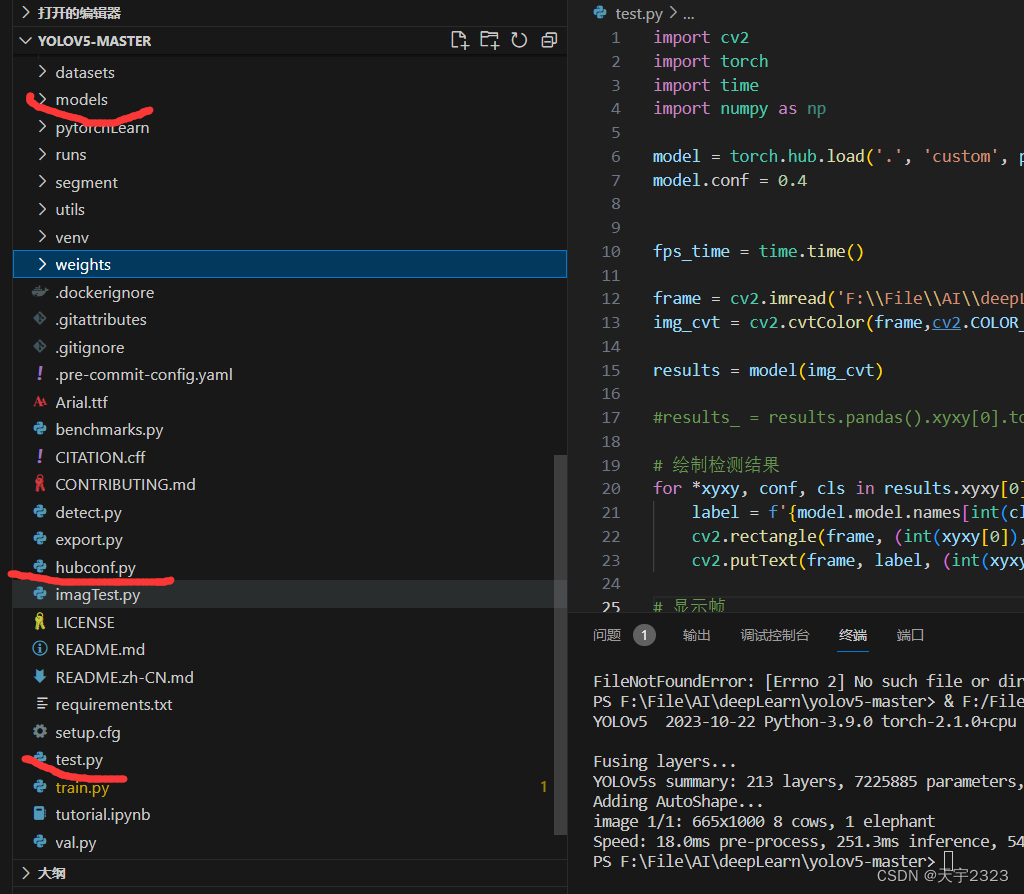
hubconf.py文件
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
"""
PyTorch Hub models https://pytorch.org/hub/ultralytics_yolov5
Usage:
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # official model
model = torch.hub.load('ultralytics/yolov5:master', 'yolov5s') # from branch
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt') # custom/local model
model = torch.hub.load('.', 'custom', 'yolov5s.pt', source='local') # local repo
"""
import torch
def _create(name, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
"""Creates or loads a YOLOv5 model
Arguments:
name (str): model name 'yolov5s' or path 'path/to/best.pt'
pretrained (bool): load pretrained weights into the model
channels (int): number of input channels
classes (int): number of model classes
autoshape (bool): apply YOLOv5 .autoshape() wrapper to model
verbose (bool): print all information to screen
device (str, torch.device, None): device to use for model parameters
Returns:
YOLOv5 model
"""
from pathlib import Path
from models.common import AutoShape, DetectMultiBackend
from models.experimental import attempt_load
from models.yolo import ClassificationModel, DetectionModel, SegmentationModel
from utils.downloads import attempt_download
from utils.general import LOGGER, ROOT, check_requirements, intersect_dicts, logging
from utils.torch_utils import select_device
if not verbose:
LOGGER.setLevel(logging.WARNING)
check_requirements(ROOT / 'requirements.txt', exclude=('opencv-python', 'tensorboard', 'thop'))
name = Path(name)
path = name.with_suffix('.pt') if name.suffix == '' and not name.is_dir() else name # checkpoint path
try:
device = select_device(device)
if pretrained and channels == 3 and classes == 80:
try:
model = DetectMultiBackend(path, device=device, fuse=autoshape) # detection model
if autoshape:
if model.pt and isinstance(model.model, ClassificationModel):
LOGGER.warning('WARNING ⚠️ YOLOv5 ClassificationModel is not yet AutoShape compatible. '
'You must pass torch tensors in BCHW to this model, i.e. shape(1,3,224,224).')
elif model.pt and isinstance(model.model, SegmentationModel):
LOGGER.warning('WARNING ⚠️ YOLOv5 SegmentationModel is not yet AutoShape compatible. '
'You will not be able to run inference with this model.')
else:
model = AutoShape(model) # for file/URI/PIL/cv2/np inputs and NMS
except Exception:
model = attempt_load(path, device=device, fuse=False) # arbitrary model
else:
cfg = list((Path(__file__).parent / 'models').rglob(f'{path.stem}.yaml'))[0] # model.yaml path
model = DetectionModel(cfg, channels, classes) # create model
if pretrained:
ckpt = torch.load(attempt_download(path), map_location=device) # load
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=['anchors']) # intersect
model.load_state_dict(csd, strict=False) # load
if len(ckpt['model'].names) == classes:
model.names = ckpt['model'].names # set class names attribute
if not verbose:
LOGGER.setLevel(logging.INFO) # reset to default
return model.to(device)
except Exception as e:
help_url = 'https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading'
s = f'{e}. Cache may be out of date, try `force_reload=True` or see {help_url} for help.'
raise Exception(s) from e
def custom(path='path/to/model.pt', autoshape=True, _verbose=True, device=None):
# YOLOv5 custom or local model
return _create(path, autoshape=autoshape, verbose=_verbose, device=device)
def yolov5n(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-nano model https://github.com/ultralytics/yolov5
return _create('yolov5n', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5s(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-small model https://github.com/ultralytics/yolov5
return _create('yolov5s', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5m(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-medium model https://github.com/ultralytics/yolov5
return _create('yolov5m', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5l(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-large model https://github.com/ultralytics/yolov5
return _create('yolov5l', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5x(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-xlarge model https://github.com/ultralytics/yolov5
return _create('yolov5x', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5n6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-nano-P6 model https://github.com/ultralytics/yolov5
return _create('yolov5n6', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5s6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-small-P6 model https://github.com/ultralytics/yolov5
return _create('yolov5s6', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5m6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-medium-P6 model https://github.com/ultralytics/yolov5
return _create('yolov5m6', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5l6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-large-P6 model https://github.com/ultralytics/yolov5
return _create('yolov5l6', pretrained, channels, classes, autoshape, _verbose, device)
def yolov5x6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
# YOLOv5-xlarge-P6 model https://github.com/ultralytics/yolov5
return _create('yolov5x6', pretrained, channels, classes, autoshape, _verbose, device)
if __name__ == '__main__':
import argparse
from pathlib import Path
import numpy as np
from PIL import Image
from utils.general import cv2, print_args
# Argparser
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, default='yolov5s', help='model name')
opt = parser.parse_args()
print_args(vars(opt))
# Model
model = _create(name=opt.model, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True)
# model = custom(path='path/to/model.pt') # custom
# Images
imgs = [
'data/images/zidane.jpg', # filename
Path('data/images/zidane.jpg'), # Path
'https://ultralytics.com/images/zidane.jpg', # URI
cv2.imread('data/images/bus.jpg')[:, :, ::-1], # OpenCV
Image.open('data/images/bus.jpg'), # PIL
np.zeros((320, 640, 3))] # numpy
# Inference
results = model(imgs, size=320) # batched inference
# Results
results.print()
results.save()
代码部分(这里加载本地模型,并进行前向传播)
这里还是拿YOLOv5模型举例
import cv2
import torch
import time
import numpy as np
model = torch.hub.load('.', 'custom', path="D:\\file\\test\\yolov5-master\\runs\\train\\exp5\\weights\\best.pt",source='local')
model.conf = 0.4
frame = cv2.imread('D:/file/files/labelsTest/54d8382de683ce00014a2899.jpg')
img_cvt = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
results = model(img_cvt)
#results_ = results.pandas().xyxy[0].to_numpy()
# 绘制检测结果
for *xyxy, conf, cls in results.xyxy[0]:
label = f'{model.model.names[int(cls)]} {conf:.2f}'
cv2.rectangle(frame, (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])), (0, 0, 255), 2)
cv2.putText(frame, label, (int(xyxy[0]), int(xyxy[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
# 显示帧
cv2.imshow('YOLOv5 Real-time Object Detection', frame)
cv2.waitKey()
展示效果
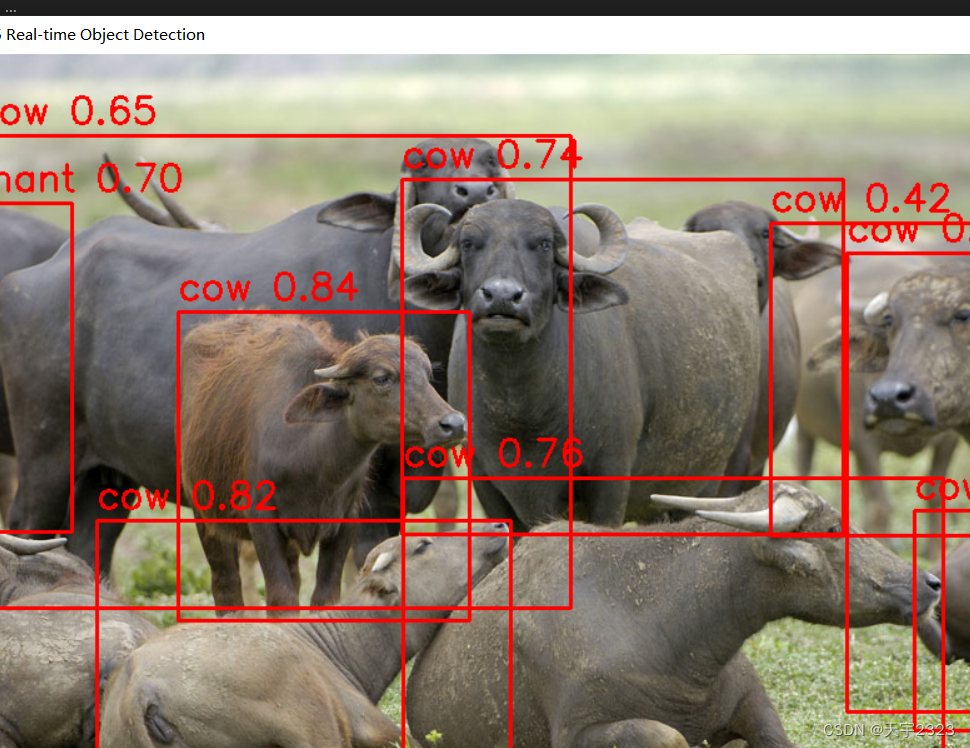
torch.hub.load()函数的使用
torch.hub.load是PyTorch中一个方便的API,用于从GitHub上的预训练模型仓库中加载模型。它允许用户在不离开Python环境的情况下,直接从GitHub中下载模型并加载它们。
例如yolov5项目主分支的官方地址https://github.com/ultralytics/yolov5/tree/master ,想加载yolov5模型并使用,可用如下代码。
import torch
# Model
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
# Images
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.第一个参数为可选标签/分支格式的 github 存储库,前面的“https://github.com/”不要加进去,它自己会加,你只要加分支tree前父目录"ultralytics/yolov5"。(目前看来,通过网络下载的情况,参数变动大,建议想联网下载模型时,去读这类项目的readme.md,一般有说明)
函数原型:
torch.hub.load(repo_or_dir, model, *args, source='github', force_reload=False, verbose=True, skip_validation=False, **kwargs)
参数说明:repo_or_dir ( string ) – 如果source是 ‘github’,这应该对应于repo_owner/repo_name[:tag_name] 方括号表示可选,该参数表示具有可选标签/分支格式的 github 存储库,例如 ‘pytorch/vision:0.10’。如果tag_name未指定,则假定默认分支为main存在,否则为master。如果source是“local”,则它应该是本地目录的路径。
model ( string ) – 在 repo/dir’s 中定义的可调用(入口点)的名称hubconf.py。
*args(可选)– callable 的相应参数model。
source ( string , optional ) – ‘github’ 或 ‘local’。指定如何 repo_or_dir解释。默认为“github”。
force_reload ( bool , optional ) – 是否无条件强制重新下载github repo。如果 没有任何影响 source = ‘local’。默认为False
verbose ( bool , optional ) – 如果False,静音有关命中本地缓存的消息。请注意,有关首次下载的消息无法静音。如果source = 'local’没有任何影响。默认为True。
skip_validation ( bool , optional ) – 如果False,torchhub 将检查github参数指定的分支或提交是否正确属于 repo 所有者。这将向 GitHub API 发出请求;您可以通过设置GITHUB_TOKEN环境变量来指定非默认 GitHub 令牌 。默认为False。
**kwargs (可选) – callable 的相应 kwargs model。
1、联网
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
2、加载本地模型
model = torch.hub.load('.', 'custom', path="D:\\file\\test\\yolov5-master\\runs\\train\\exp5\\weights\\best.pt",source='local')方法三(推荐)、利用ultralytics加载
ultralytics是YOLO官方的组件,它可以加载YOLOv3——YOLOv8版本模型,而且使用相当方便,这也为什么推荐使用这一个。注意:模型需要也是ultralytics工具训练的
下载模块
pip install ultralytics并建议确保下载
pip install opencv-python这里继续拿yolov5举例代码部分
from ultralytics import YOLO
import cv2
# 加载一个在COCO数据集上预训练的YOLOv5n模型
model = YOLO('yolov5n.pt')
# 显示模型信息(可选)
model.info()
cap = cv2.VideoCapture(0)
# 循环遍历视频帧
while cap.isOpened():
# 从视频读取一帧
success, frame = cap.read()
if success:
# 在帧上运行YOLO
results = model.track(frame, persist=True)
# 获取框
boxes = results[0].boxes.xywh.cpu()
track_ids = results[0].boxes.id.int().cpu().tolist()
# 在帧上展示结果
annotated_frame = results[0].plot()
# 展示带注释的帧
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# 如果按下'q'则退出循环
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# 如果视频结束则退出循环
break
# 释放视频捕获对象并关闭显示窗口
cap.release()
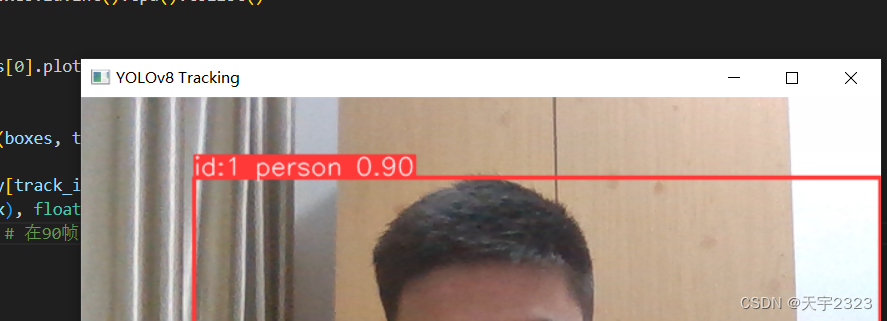
cv2.destroyAllWindows()展示效果

也可使用YOLOv8模型版本,这里使用方法差不多,如下
记得确保pip install lapx
from collections import defaultdict
import cv2
import numpy as np
from ultralytics import YOLO
# 加载YOLOv8模型
model = YOLO('yolov8n.pt')
# 打开视频文件
#video_path = "path/to/video.mp4"
cap = cv2.VideoCapture(0)
# 存储追踪历史
track_history = defaultdict(lambda: [])
# 循环遍历视频帧
while cap.isOpened():
# 从视频读取一帧
success, frame = cap.read()
if success:
# 在帧上运行YOLOv8追踪,持续追踪帧间的物体
results = model.track(frame, persist=True)
# 获取框和追踪ID
boxes = results[0].boxes.xywh.cpu()
track_ids = results[0].boxes.id.int().cpu().tolist()
# 在帧上展示结果
annotated_frame = results[0].plot()
# 绘制追踪路径
for box, track_id in zip(boxes, track_ids):
x, y, w, h = box
track = track_history[track_id]
track.append((float(x), float(y))) # x, y中心点
if len(track) > 30: # 在90帧中保留90个追踪点
track.pop(0)
# 绘制追踪线
points = np.hstack(track).astype(np.int32).reshape((-1, 1, 2))
cv2.polylines(annotated_frame, [points], isClosed=False, color=(230, 230, 230), thickness=10)
# 展示带注释的帧
cv2.imshow("YOLOv8 Tracking", annotated_frame)
# 如果按下'q'则退出循环
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# 如果视频结束则退出循环
break
# 释放视频捕获对象并关闭显示窗口
cap.release()
cv2.destroyAllWindows()展示效果
参考官方文档(想进一步了解,推荐参考官方文档)
参考博客

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)