

Pytorch--3.使用CNN和LSTM对数据进行预测
使用CNN+LSTM对数据进行预测
这个系列前面的文章我们学会了使用全连接层来做简单的回归任务,但是在现实情况里,我们不仅需要做回归,可能还需要做预测工作。同时,我们的数据可能在时空上有着联系,但是简单的全连接层并不能满足我们的需求,所以我们在这篇文章里使用CNN和LSTM来对时间上有联系的数据来进行学习,同时来实现预测的功能。
1.数据集:使用的是kaggle上一个公开的气象数据集(CSV)
有需要的可以去kaggle下载,也可以在评论区留下mail,题主发送过去
2.导入我们所需要的库和完成前置工作
2.1导入相关的库
torch为人工智能的库,pandas用于数据读取,numpy为张量处理的库,matplotlib为画图库
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import warnings
import torch.nn as nn
import torch.optim as optim
import random
2.2设置相关配置
我们设置随机种子(方便代码的复现)和警告的忽律(防止出现太多警告看不到代码运行的效果)
warnings.filterwarnings('ignore')
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.manual_seed(99)
np.random.seed(99)
random.seed(99)
print ("随机种子")
2.3数据的读入
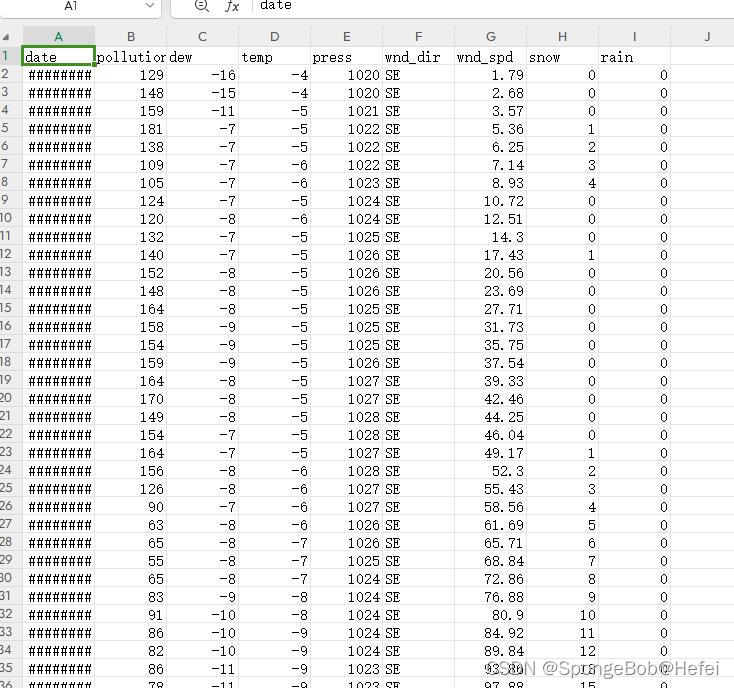
pd.read_csv里面的参数为相对位置,即代码和文件要在同一个文件夹下面。使用.head()函数来读一下数据的前几行,保证数据是存在的
train_data = pd.read_csv("LSTM-Multivariate_pollution.csv")
train_data.head()
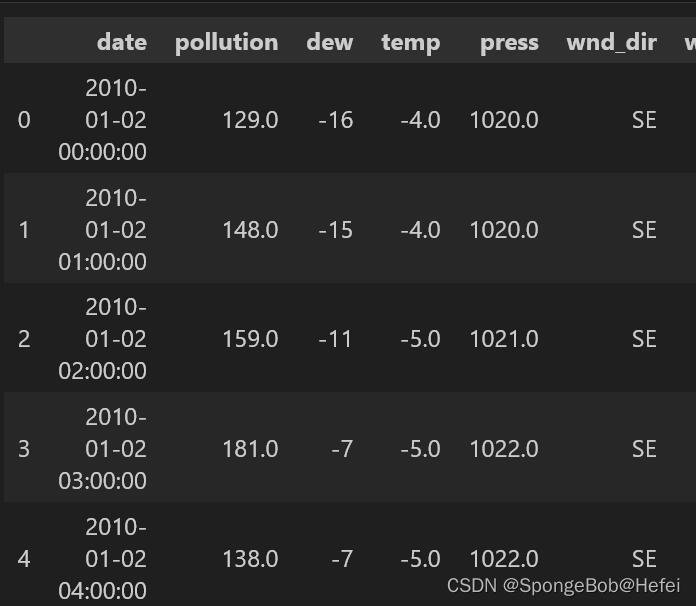
我们来看一下各个值的前2048个数据分布情况(方便挑选数据进行代码测试)
代码里面的pollution可以换成dew,temp等值(也就是上图里面的值),用于观看分布情况。
train_use = train_data["pollution"].values
plt.plot([i for i in range(2048)], pollution[:2048])
pollution:
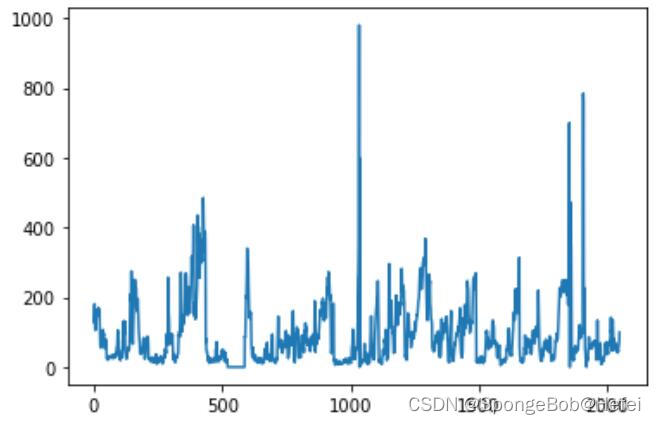
dew:
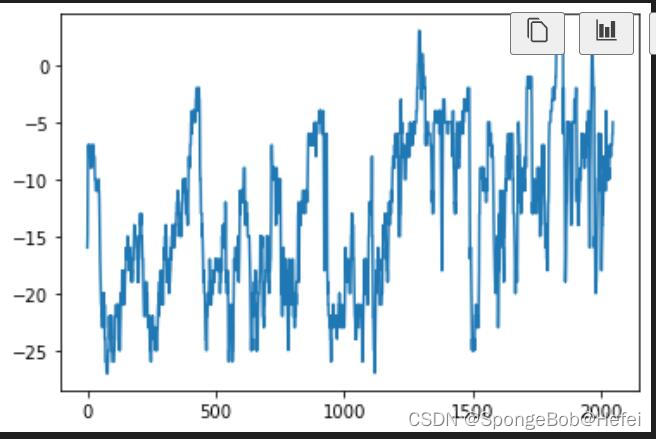
temp:
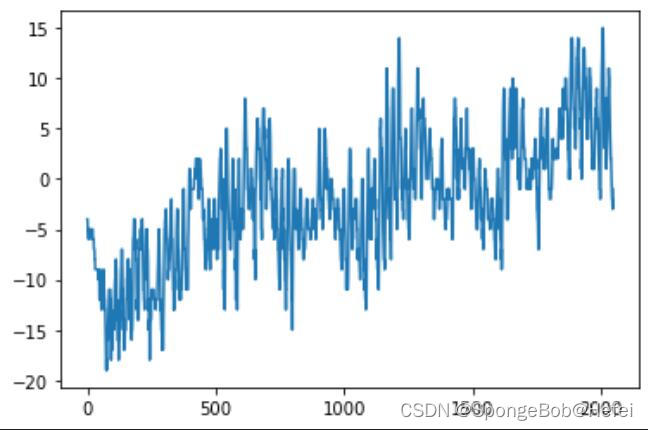
我们可以看到temp属性里面的数据整体呈现上升的趋势,所以我们使用属性为temp的值来进行学习和预测。
首先对数据进行归一化操作(因为值过大的话会导致神经网络损失不降低,同时神经网络难以达到收敛),我们使用minmax归一化后将其打印出来可以看到代码显示的效果
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
train_use = scaler.fit_transform(train_use.reshape(-1, 1))
print ((train_use))
print ("归一化处理")
可以看到归一化后的结果如下图所示:
我们将数据进行处理,默认使用前30个小时的数据对第31个小时的数据进行预测,同时将数据进行升维处理,使得输入的训练数据为3维度,分别为batchsize,每次所需要的数据(30个数据),和数据的输入维度(1维度)
def split_data(data, time_step = 30):
dataX = []
dataY = []
for i in range(len(data) - time_step):
dataX.append(data[i:i + time_step])
dataY.append(data[i + time_step])
dataX = np.array(dataX).reshape(len(dataX), time_step, -1)
dataY = np.array(dataY)
return dataX, dataY
进行数据处理后,获得了可以训练的数据和标签
datax,datay = split_data(train_use, 30)
print ((datay))
结果如下:
紧接着我们划分训练集和测试集,默认为80%的数据用于做训练集,20%的数据用于做测试集,shuffle表示是否要将数据进行打乱,以此来测试训练效果
def train_test_split(dataX,datay,shuffle = True,percentage = 0.8):
if shuffle:
random_num = [i for i in range(len(dataX))]
np.random.shuffle(random_num)
dataX = dataX[random_num]
datay = datay[random_num]
split_num = int(len(dataX)*percentage)
train_X = dataX[:split_num]
train_y = datay[:split_num]
testX = dataX[split_num:]
testy = datay[split_num:]
return train_X, train_y, testX, testy
获取我们的训练数据和测试数据,同时把源数据保存到X_train和y_train里面,方便以后对网络的性能进行评比。
train_X, train_y, testx,testy = train_test_split(datax,datay,False,0.8)
print (type(testx))
print("datax的形状为{},dataY的形状为{}".format(train_X.shape, train_y.shape))
X_train = train_X
y_train = train_y
定义我们的自定义网络
class CNN_LSTM(nn.Module):
def __init__(self, conv_input, input_size, hidden_size, num_layers, output_size):
super(CNN_LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.conv = nn.Conv1d(conv_input, conv_input, 1)
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first = True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.conv(x)
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
out, _= self.lstm(x,(h0,c0))
out = self.fc(out[:,-1,:])
return out
设置我们网络训练所需要的参数
test_X1 = torch.Tensor(testx)
test_y1 = torch.Tensor(testy)
input_size = 1
conv_input = 30
hidden_size = 64
num_layers = 2
output_size = 1
model = CNN_LSTM(conv_input, input_size, hidden_size, num_layers,output_size)
num_epoch = 1000
batch_size = 4
optimizer = optim.Adam(model.parameters(), lr = 0.0001, betas=(0.5, 0.999))
criterion = nn.MSELoss()
#print ((torch.Tensor(train_X[:batch_size])))
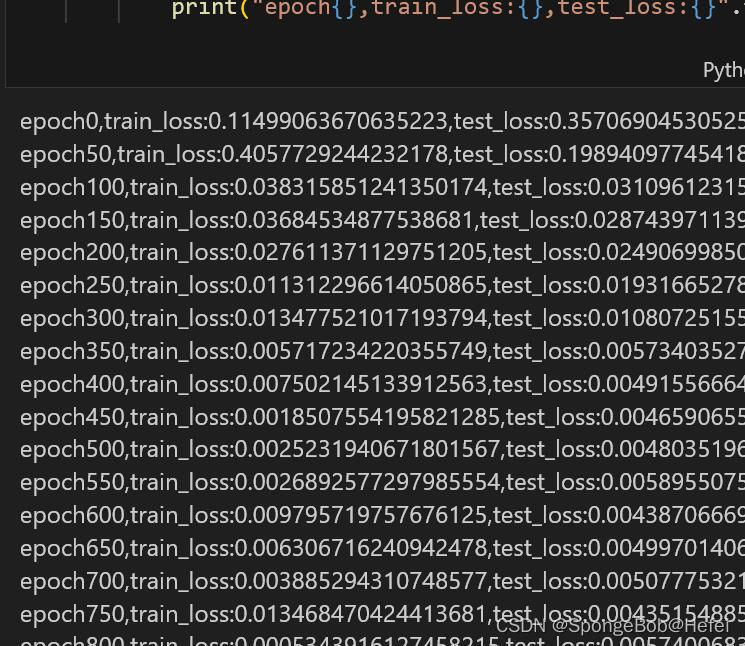
开始运行代码:
train_losses = []
test_losses = []
for epoch in range(num_epoch):
random_num = [i for i in range(len(train_X))]
np.random.shuffle(random_num)
train_X = train_X[random_num]
train_y = train_y[random_num]
train_x1 = torch.Tensor(train_X[:batch_size])
train_y1 = torch.Tensor(train_y[:batch_size])
model.train()
optimizer.zero_grad()
output = model(train_x1)
train_loss = criterion(output, train_y1)
train_loss.backward()
optimizer.step()
if epoch%50 == 0 :
model.eval()
with torch.no_grad():
output = model(test_X1)
test_loss = criterion(output, test_y1)
train_losses.append(train_loss)
test_losses.append(test_loss)
print("epoch{},train_loss:{},test_loss:{}".format(epoch, train_loss, test_loss))
自己手写一个mse计算函数(直接调库也可以),什么是mse?(均方误差,均方误差越小说明模型拟合的越好)
def mse(pred_y, true_y):
return np.mean((pred_y - true_y) **2)
然后我们对模型进行测试,观察mse的值
train_X1 = torch.Tensor(X_train)
train_pred = model(train_X1).detach().numpy()
test_pred = model(test_X1).detach().numpy()
pred_y = np.concatenate((train_pred, test_pred))
pred_y = scaler.inverse_transform(pred_y).T[0]
true_y = np.concatenate((y_train, testy))
#print (true_y)
true_y = scaler.inverse_transform(true_y).T[0]
#print (true_y)
print (f"mse(pred_y, true_y):{mse(pred_y, true_y)}")
##print (pred_y)
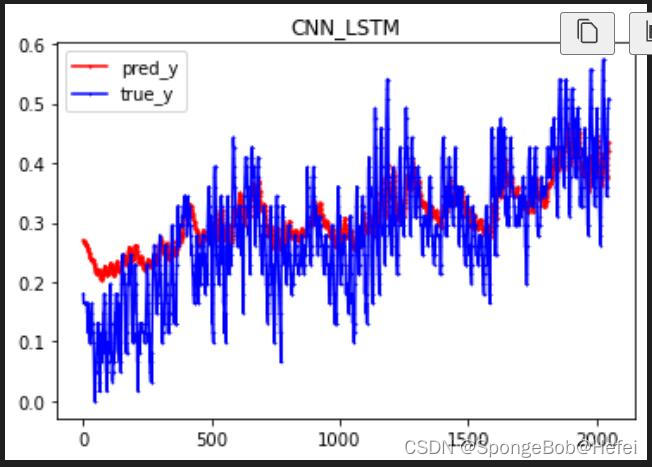
我们取前2048个值来看我们的预测的情况(因为数据有几万条,为了避免图形太过密集难以看出效果,所以我们只采用前2048个值来进行展示)
plt.title("CNN_LSTM")
x = [i for i in range(2048)]
plt.plot(x, pred_y[:2048], marker = "o", markersize =1, label="pred_y",color=(1, 0, 0))
plt.plot(x, true_y[:2048], marker = "x", markersize=1, label="true_y",color=(0, 0, 1))
plt.legend()
plt.show()
可以看出来,已经学习到了基本的上升趋势的
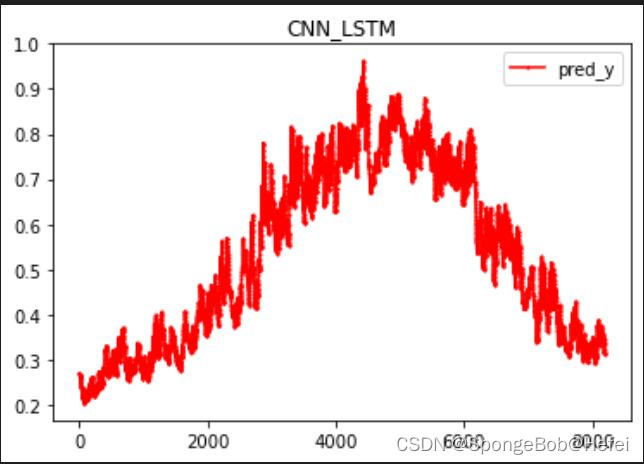
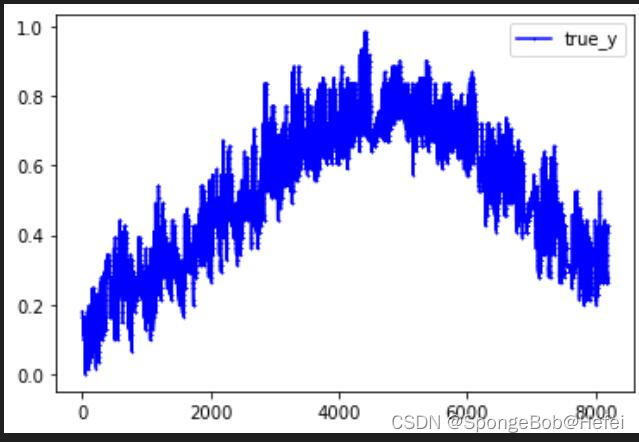
我们将两个图拆开来看,看到前8192个点的值,可以看到已经获得到了相对应的趋势。
码字不易,写代码不易,点个赞再走把

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 105
105 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)