
数据增强的原理及实现(超详细)
在深度学习中,数据增强是通过一定的方式改变输入数据,以生成更多的训练样本,从而提高模型的泛化能力和效果。数据增强可以减少模型对某些特征的过度依赖,从而避免过拟合。
一键AI生成摘要,助你高效阅读
问答
·
目录
一、什么是数据增强
在深度学习中,数据增强是通过一定的方式改变输入数据,以生成更多的训练样本,从而提高模型的泛化能力和效果。数据增强可以减少模型对某些特征的过度依赖,从而避免过拟合。
二、为什么要使用数据增强
在深度学习中,要求样本数量充足,样本数量越多,训练出来的模型效果越好,模型的泛化能力越强。但是实际中,样本数量不足或者样本质量不够好,这时就需要对样本做数据增强,来提高样本质量。
例如在图像分类任务中,对于输入的图像可以进行一些简单的平移、缩放、颜色变换等操作,这些操作不会改变图像的类别,但可以增加训练样本的数量。这些增强后的样本可以帮助模型更好地学习和理解图像的特征,提高模型的泛化能力和准确率。
三、数据增强的代码实现
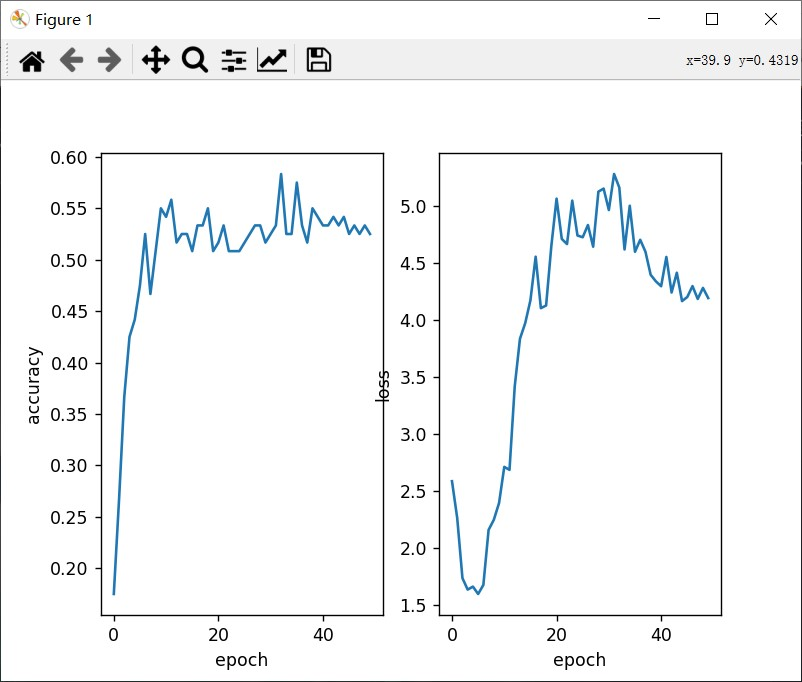
未使用数据增强的代码及结果展示:
import torch
from torch.utils.data import Dataset, DataLoader
import numpy as np
from PIL import Image
from torchvision import transforms
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
]),
'valid':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
]),
}
class food_dataset(Dataset):
def __init__(self, file_path, transform=None):
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
with open(self.file_path) as f:
samples = [x.strip().split(' ') for x in f.readlines()]
for img_path, label in samples:
self.imgs.append(img_path)
self.labels.append(label)
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
image = Image.open(self.imgs[idx])
if self.transform:
image = self.transform(image)
label = self.labels[idx]
label = torch.from_numpy(np.array(label, dtype=np.int64))
return image, label
training_data = food_dataset(file_path='.\\train.txt', transform=data_transforms['train'])
test_data = food_dataset(file_path='.\\test.txt', transform=data_transforms['valid'])
train_dataloader = DataLoader(training_data, batch_size=128, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=128, shuffle=True)
# from matplotlib import pyplot as plt
# image, label = iter(train_dataloader).__next__()
# sample = image[2]
# sample = sample.permute((1, 2, 0)).numpy()
# plt.imshow(sample)
# plt.show()
# print('Label is: {}'.format(label[2].numpy()))
import torch
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# print(device)
# import os
#
# os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
# os.environ["CUDA_VISIBLE_DEVICES"] = '1'
from torch import nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.conv3 = nn.Sequential(
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(),
)
self.out = nn.Linear(64 * 64 * 64, 20)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.size(0), -1)
output = self.out(x)
return output
model = CNN().to(device)
print(model)
def train(dataloader, model, loss_fn, optimizer):
model.train()
batch_size_num = 1
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model.forward(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss = loss.item()
if batch_size_num % 100 == 0:
print(f"loss: {loss:>7f} [number:{batch_size_num}]")
batch_size_num += 1
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval() #
test_loss, correct = 0, 0
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
pred = model.forward(x)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y)
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches
correct /= size
print(f"Test result: \n Accuracy: {(100 * correct)}%, Avg loss: {test_loss}")
acc_s.append(correct)
loss_s.append(test_loss)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# train(train_dataloader, model, loss_fn, optimizer)
# test(test_dataloader, model, loss_fn)
epochs = 50
acc_s = []
loss_s = []
for t in range(epochs):
print(f"Epoch {t + 1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
# print("Done!")
# test(test_dataloader, model, loss_fn)
from matplotlib import pyplot as plt
plt.subplot(1, 2, 1)
plt.plot(range(0, epochs), acc_s)
plt.xlabel("epoch")
plt.ylabel('accuracy')
plt.subplot(1, 2, 2)
plt.plot(range(0, epochs), loss_s)
plt.xlabel("epoch")
plt.ylabel('loss')
plt.show()其结果展示为:
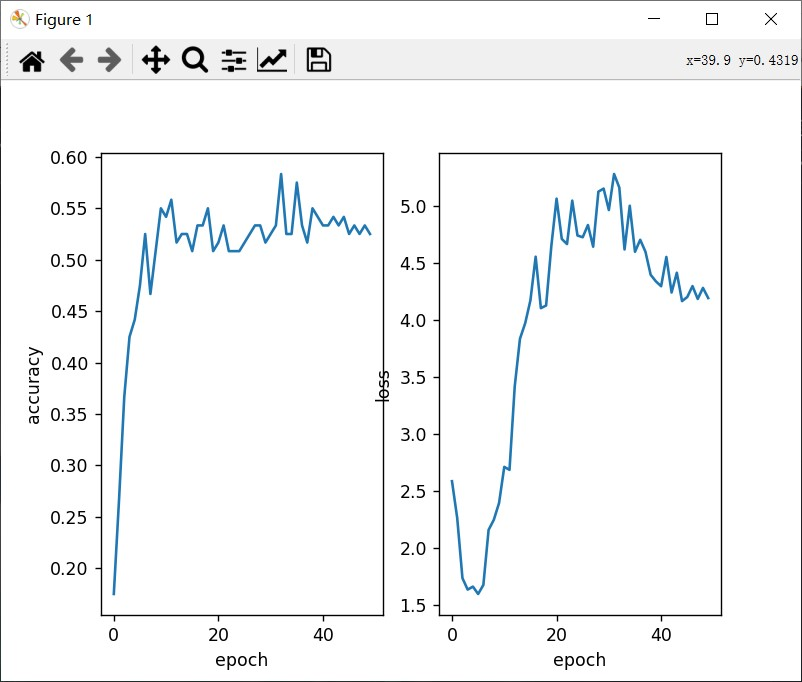
使用了数据增强即在这串代码里做出更改
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
]),
'valid':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
]),
}
将其更改为:
data_transforms = { # 也可以使用PIL库,smote 人工拟合出来数据
'train':
transforms.Compose([
transforms.Resize([300, 300]), # 是图像变换大小
transforms.RandomRotation(45), # 随机旋转,-45到45度之间随机选
transforms.CenterCrop(256), # 从中心开始裁剪[256,256]
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转
transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),
# 参数1为亮度,参数2为对比度,参数3为饱和度,参数4为色相
transforms.RandomGrayscale(p=0.1), # 概率转换成灰度率,3通道就是R=G=B
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 标准化,均值,标准差
]),
'valid':
transforms.Compose([
transforms.Resize([256, 256]),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}更改完成后,结果展示为:
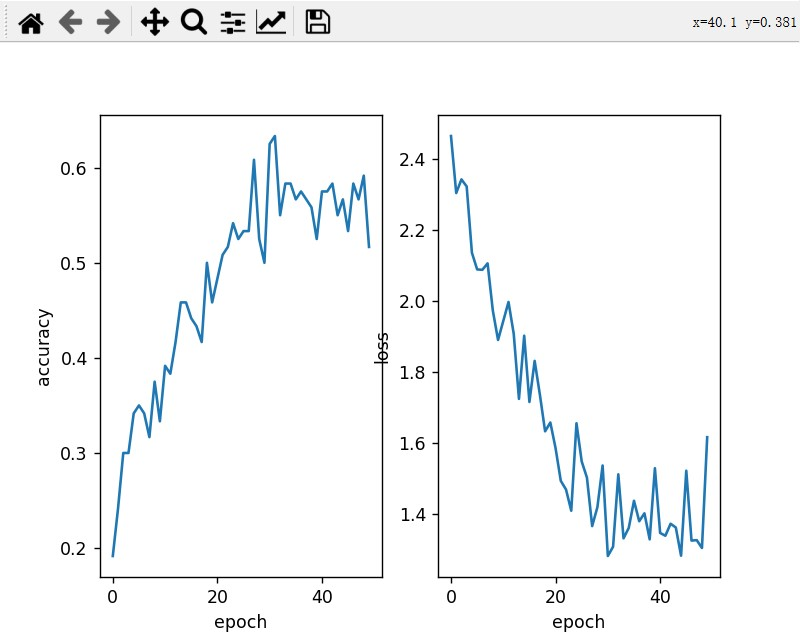
对比比较发现,不在产生梯度爆炸,且准确率更高。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 0
0 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)