
【AI视野·今日Robot 机器人论文速览 第四十五期】Mon, 2 Oct 2023
AI视野·今日CS.Robotics 机器人学论文速览Mon, 2 Oct 2023Totally 42 papers👉上期速览✈更多精彩请移步主页Daily Robotics PapersLearning Decentralized Flocking Controllers with Spatio-Temporal Graph Neural NetworkAuthors Siji Chen,
·
AI视野·今日CS.Robotics 机器人学论文速览
Mon, 2 Oct 2023
Totally 42 papers
👉上期速览✈更多精彩请移步主页

Interesting:
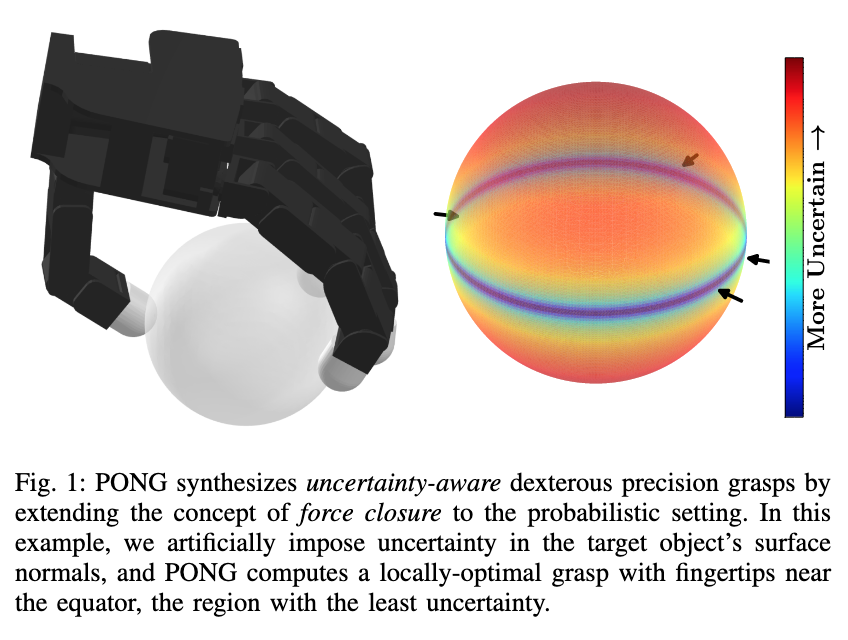
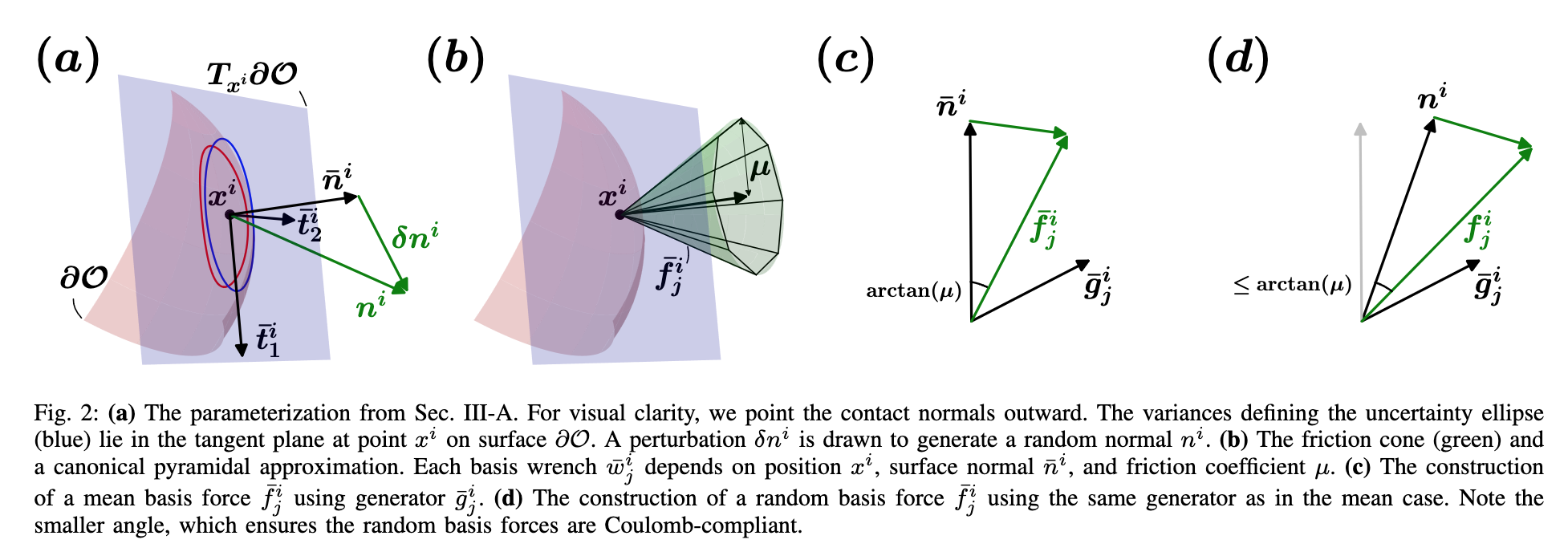
📚PONG, Probabilistic Object Normals for Grasping 用于抓取的概率目标归一化,根据目标表面法向量获取的不确定度,计算抓取力的闭合程度。(from 加州理工)
📚GPT-LAB, 基于GPT的大语言模型驱动的自动化机器人实验室。(from 之江实验室)
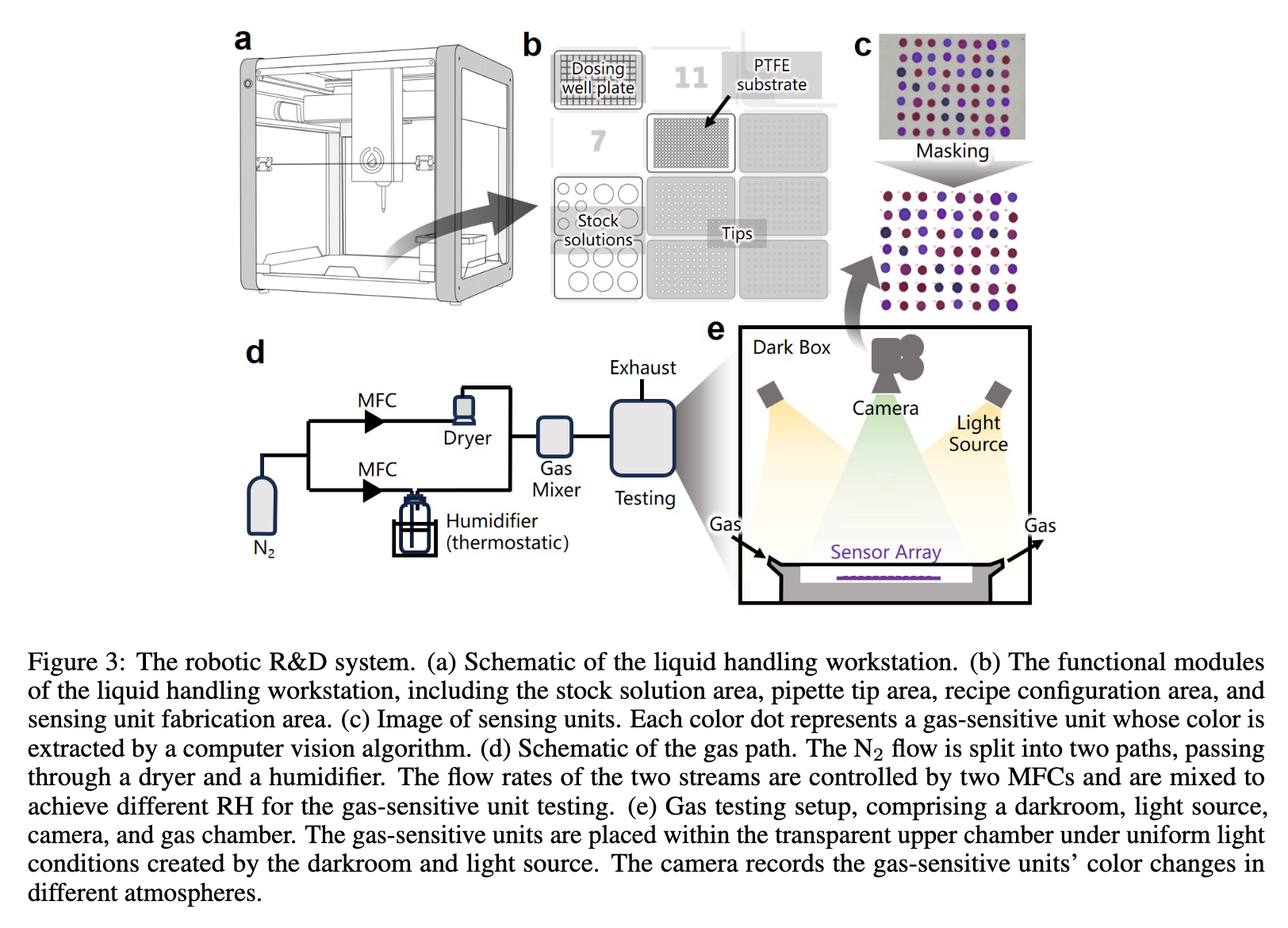
机器人化学实验流程:
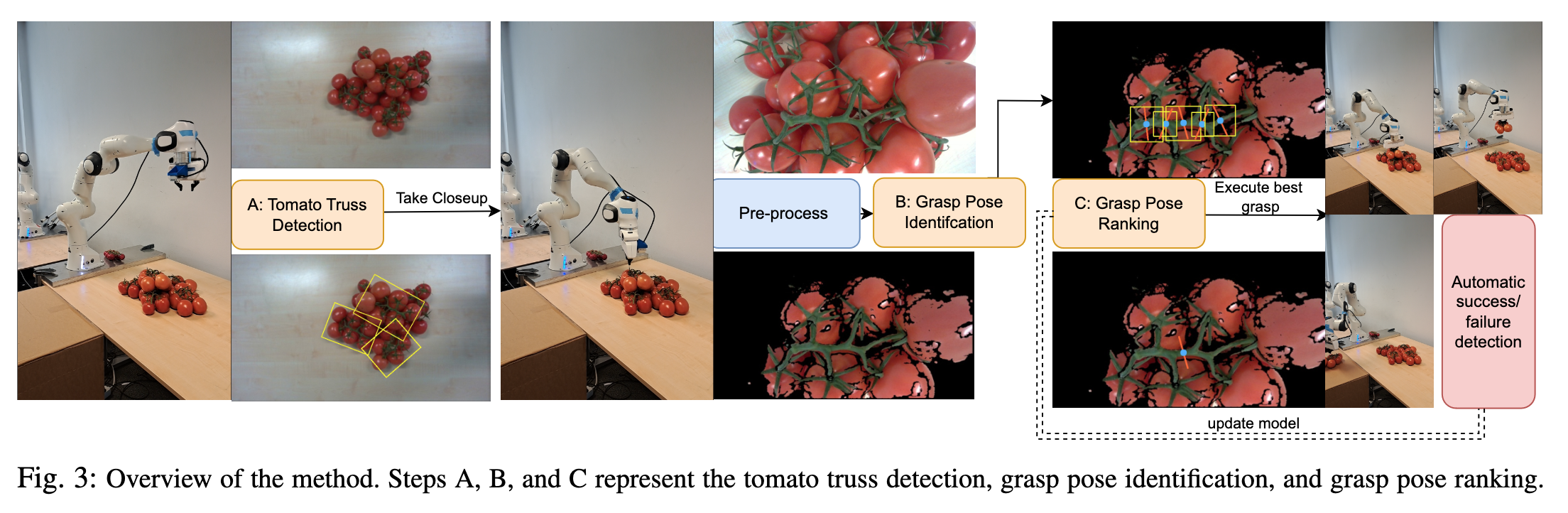
📚机器人抓番茄, 识别出番茄的叶柄,并一串的抓取。(from )
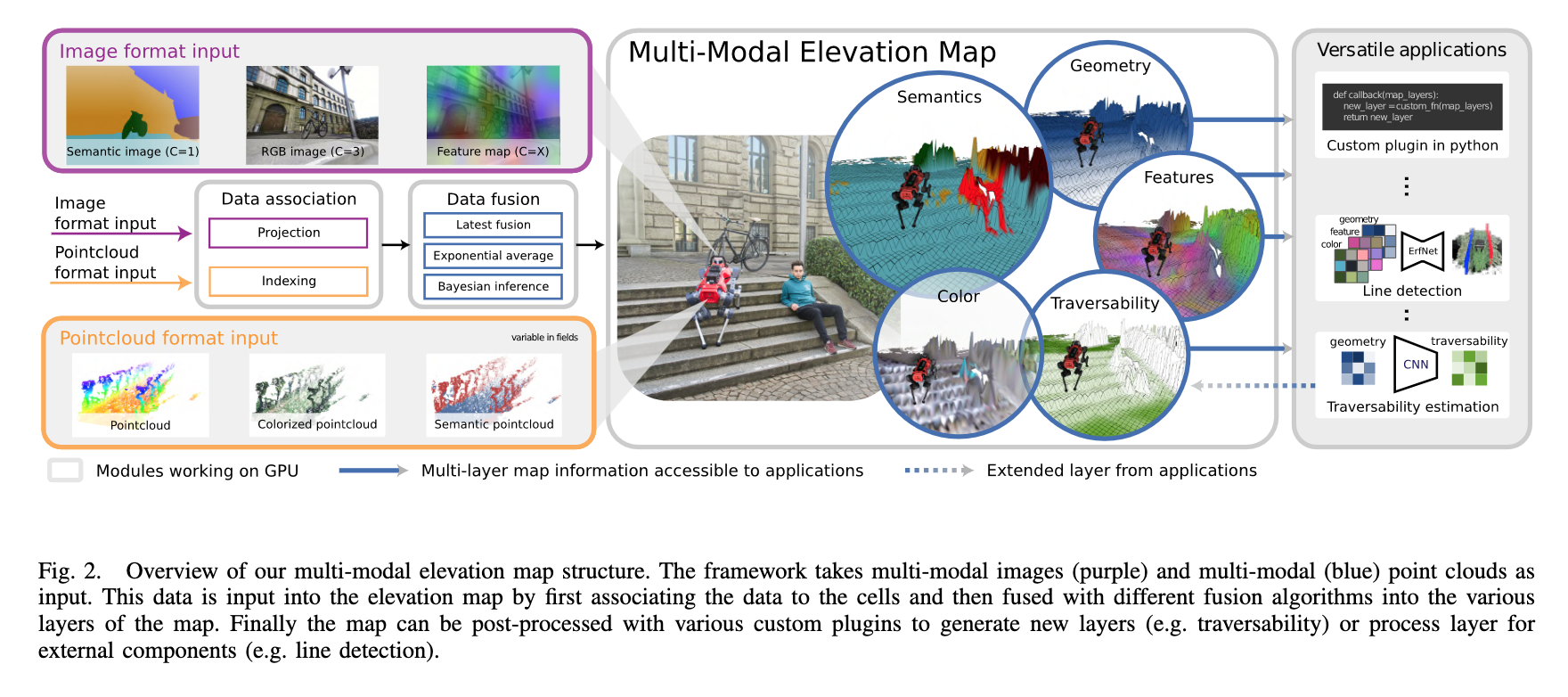
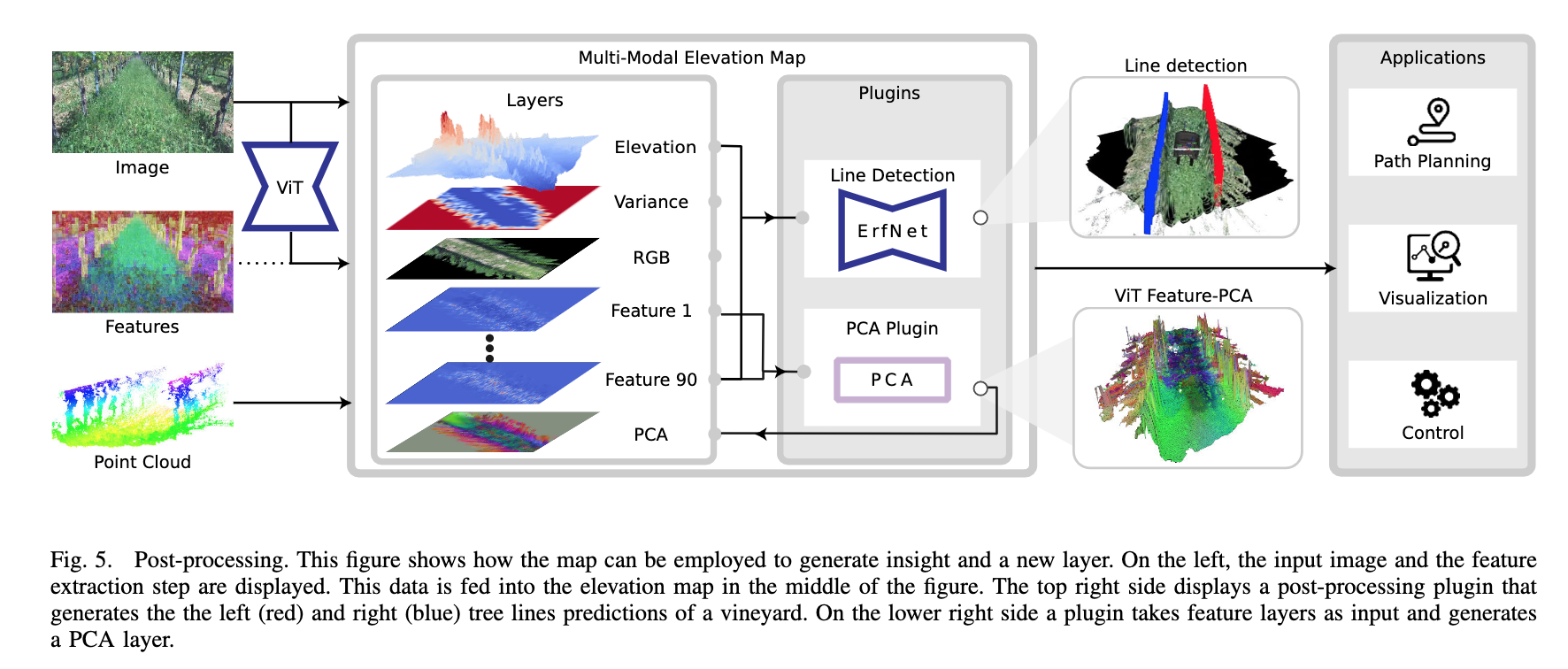
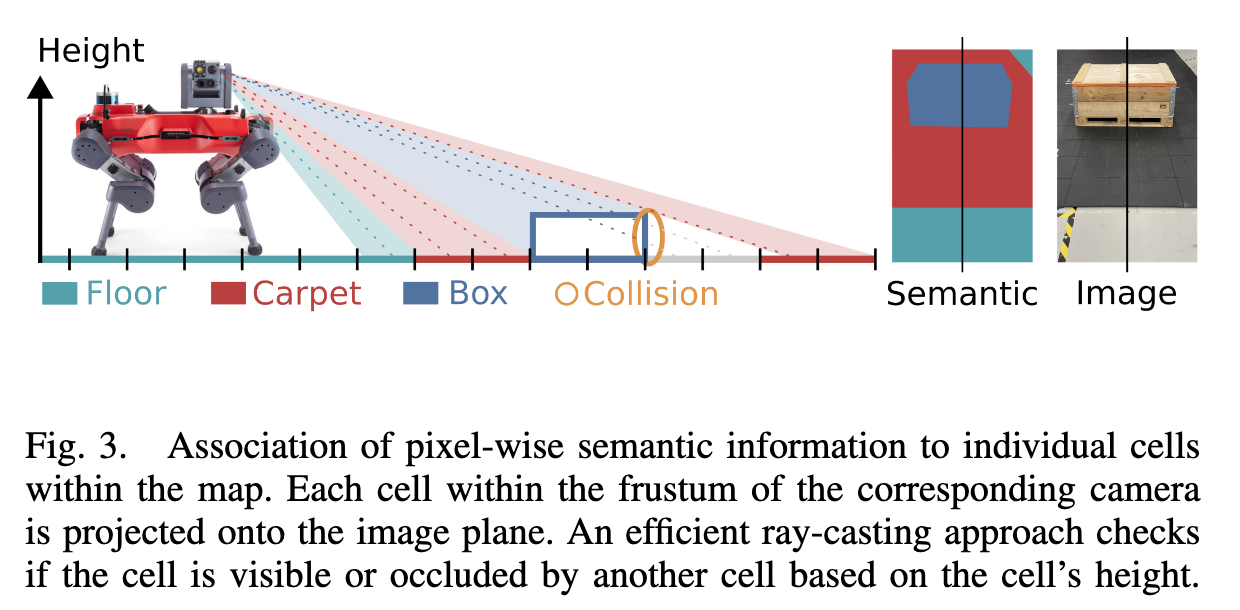
📚MEM, 用于机器人学习与训练的多模态高程图2.5D。(from 苏黎世理工 牛津机器人实验室)
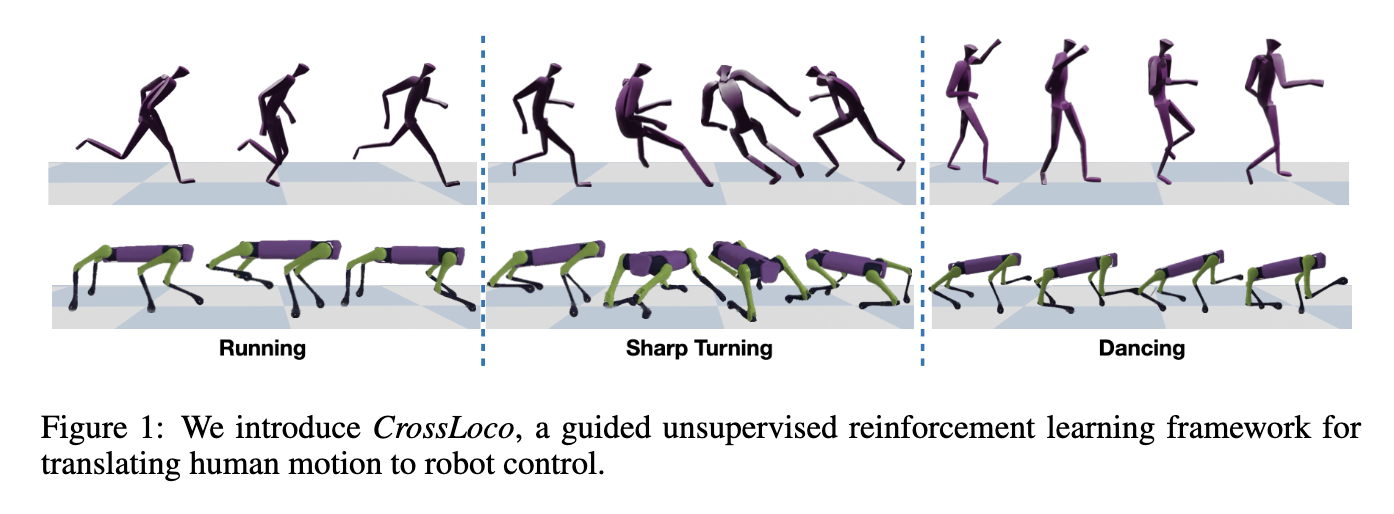
📚CROSSLOCO, 基于人类步态驱动的四足机器人学习框架. (from 佐治亚理工 )
Daily Robotics Papers
| Learning Decentralized Flocking Controllers with Spatio-Temporal Graph Neural Network Authors Siji Chen, Yanshen Sun, Peihan Li, Lifeng Zhou, Chang Tien Lu 最近一系列研究深入探讨了使用图神经网络 GNN 在群体机器人中进行分散控制。然而,据观察,仅依靠近邻国家不足以模仿集中控制政策。为了解决这个限制,先前的研究建议将 L 跳延迟状态纳入计算中。虽然这种方法显示出希望,但它可能导致遥远的群体成员之间缺乏共识并形成小集群,从而导致有凝聚力的群体行为失败。相反,我们的方法利用时空 GNN,名为 STGNN,包含空间和时间扩展。空间扩展收集来自遥远邻居的延迟状态,而时间扩展则合并来自直接邻居的先前状态。从两次扩展中收集到的更广泛、更全面的信息可以带来更有效、更准确的预测。我们开发了一种用于控制机器人群的专家算法,并采用模仿学习来训练基于专家算法的去中心化 STGNN 模型。我们在各种设置中模拟了所提出的 STGNN 方法,展示了其模拟全局专家算法的去中心化能力。此外,我们实施了我们的方法,通过一群 Crazyflie 无人机实现凝聚力聚集、领导者跟随和避障。 |
| DREAM: Decentralized Reinforcement Learning for Exploration and Efficient Energy Management in Multi-Robot Systems Authors Dipam Patel, Phu Pham, Kshitij Tiwari, Aniket Bera 资源受限的机器人通常会遇到能源效率低下、由于任务分配不足而导致计算能力未得到充分利用以及动态环境中缺乏鲁棒性等问题,所有这些都严重影响了它们的性能。本文介绍了用于多机器人系统中探索和高效能源管理的 DREAM 去中心化强化学习,这是一个优化资源分配以实现高效探索的综合框架。它超越了传统的基于启发式的任务规划。该框架结合了使用强化学习的操作范围估计,以在不熟悉的地形中执行探索和避障。 DREAM进一步引入了用于目标分配的能量消耗模型,从而利用图神经网络确保在资源有限的情况下完成任务。与随机分配目标的传统方法相比,这种方法还确保整个多机器人系统能够在更长的时间内生存以执行进一步的任务,这会损害一个或多个代理。我们的方法可以实时调整代理的优先级,展示出针对动态环境的卓越弹性。这一强大的解决方案在各种模拟环境中进行了评估,展示了跨不同场景的适应性和适用性。 |
| Improving Trajectory Prediction in Dynamic Multi-Agent Environment by Dropping Waypoints Authors Pranav Singh Chib, Pravendra Singh 轨迹固有的多样性和不确定性给精确建模带来了巨大的挑战。运动预测系统必须有效地学习过去的空间和时间信息,以预测智能体的未来轨迹。许多现有方法通过堆叠模型中的单独组件来学习时间运动以捕获时间特征。本文介绍了一种名为 Temporal Waypoint Dropping TWD 的新颖框架,该框架通过路点丢弃技术促进显式时间学习。通过路径点丢弃进行学习可以迫使模型提高对代理之间时间相关性的理解,从而显着增强轨迹预测。轨迹预测方法通常假设观测到的轨迹航路点序列是完整的,而忽略了可能出现缺失值的现实场景,这可能会影响其性能。此外,这些模型在进行预测时经常表现出对特定航路点序列的偏差。我们的TWD有能力有效解决这些问题。它结合了随机和固定过程,通过基于时间序列战略性地删除航路点来规范预测的过去轨迹。通过大量的实验,我们证明了 TWD 在迫使模型学习代理之间复杂的时间相关性方面的有效性。我们的方法可以补充现有的轨迹预测方法,以提高预测精度。 |
| PlaceNav: Topological Navigation through Place Recognition Authors Lauri Suomela, Jussi Kalliola, Atakan Dag, Harry Edelman, Joni Kristian K m r inen 最近的结果表明,将拓扑导航分为机器人独立组件和机器人特定组件,通过使机器人独立部分能够使用不同机器人类型收集的数据进行训练,可以提高导航性能。然而,导航方法仍然受到缺乏合适的训练数据的限制,并且计算规模较差。在这项工作中,我们提出了方法名称,将机器人独立部分细分为导航特定组件和通用计算机视觉组件。我们利用视觉位置识别来选择拓扑导航管道的子目标。这使得子目标选择更加高效,并能够利用非机器人来源的大规模数据集,从而提高训练数据的可用性。通过地点识别实现的贝叶斯过滤可通过提高子目标的时间一致性来进一步提高导航性能。 |
| MORPH: Design Co-optimization with Reinforcement Learning via a Differentiable Hardware Model Proxy Authors Zhanpeng He, Matei Ciocarlie 我们介绍 MORPH,一种使用强化学习在仿真中协同优化硬件设计参数和控制策略的方法。与大多数协同优化方法一样,MORPH 依赖于正在优化的硬件模型,通常基于物理定律进行模拟。然而,这样的模型通常很难集成到有效的优化例程中。为了解决这个问题,我们引入了代理硬件模型,该模型始终是可微分的,并且能够实现高效的协同优化以及使用 RL 的长范围控制策略。 MORPH 旨在确保优化的硬件代理尽可能接近其实际对应物,同时仍然能够完成任务。 |
| Differentiable Optimization Based Time-Varying Control Barrier Functions for Dynamic Obstacle Avoidance Authors Bolun Dai, Rooholla Khorrambakht, Prashanth Krishnamurthy, Farshad Khorrami 控制屏障函数 CBF 为安全控制合成提供了一种简单而有效的方法。最近,人们已经完成了使用基于可微优化的方法来系统地构建用于几何形状之间的静态避障任务的 CBF 的工作。在这项工作中,我们扩展了基于 CBF 的可微优化的应用来执行动态避障任务。我们证明,通过使用时变 CBF TVCBF 公式,我们可以对动态几何障碍物进行避障。此外,我们还展示了如何更改 TVCBF 约束以考虑测量噪声和驱动限制。为了证明我们提出的方法的有效性,我们首先在具有非椭圆体障碍物的模拟动态避障任务上将其性能与基于模型预测控制的方法进行比较。 |
| Robots That Can See: Leveraging Human Pose for Trajectory Prediction Authors Tim Salzmann, Lewis Chiang, Markus Ryll, Dorsa Sadigh, Carolina Parada, Alex Bewley 预测家庭和办公室等动态环境中所有人的运动对于实现安全有效的机器人导航至关重要。这些空间仍然具有挑战性,因为人类不遵循严格的运动规则,并且通常存在多个封闭的入口点,例如角落和门,为突然相遇创造了机会。在这项工作中,我们提出了一种基于 Transformer 的架构,可根据输入特征(包括来自船上野外感官信息的人体位置、头部方向和 3D 骨骼关键点)来预测以人为中心的环境中人类未来的轨迹。由此产生的模型捕获了未来人类轨迹预测的固有不确定性,并在通用预测基准和从适合预测任务的移动机器人捕获的人类跟踪数据集上实现了最先进的性能。 |
| A Vision-Guided Robotic System for Grasping Harvested Tomato Trusses in Cluttered Environments Authors Luuk van den Bent, Tom s Coleman, Robert Babuska 目前,桁架番茄称重和包装需要大量的手工工作。自动化的主要障碍在于难以为已经收获的桁架开发可靠的机器人抓取系统。我们提出了一种方法来抓取堆放在相当杂乱的板条箱中的桁架,这也是它们在收获后通常储存和运输的方式。该方法由基于深度学习的视觉系统组成,首先识别板条箱中的各个桁架,然后确定杆上合适的抓取位置。为此,我们引入了具有在线学习功能的抓取姿势排名算法。选择最有希望的抓取姿势后,机器人无需触摸传感器或几何模型即可执行捏握。使用配备有手眼 RGB D 相机的机器人操纵器进行的实验室实验显示,当任务从一堆桁架中拾取所有桁架时,清除率达到 100。 |
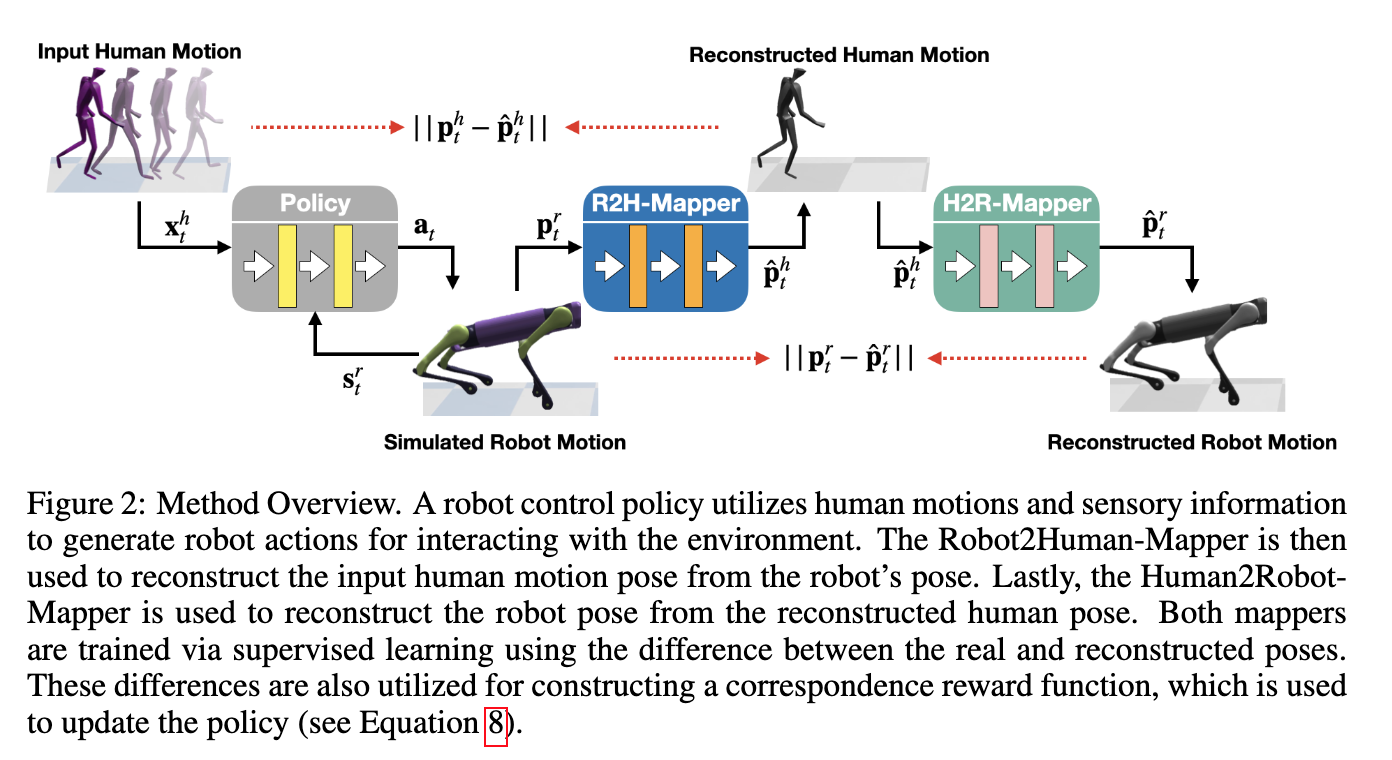
| CrossLoco: Human Motion Driven Control of Legged Robots via Guided Unsupervised Reinforcement Learning Authors Tianyu Li, Hyunyoung Jung, Matthew Gombolay, Yong Kwon Cho, Sehoon Ha 人体运动驱动控制 HMDC 是一种生成自然且引人注目的机器人运动,同时保留高级语义的有效方法。然而,由于运动学和动力学特性的不匹配,建立人类和具有不同身体结构的机器人之间的对应关系并不容易,这导致了问题的内在模糊性。许多以前的算法通过无监督学习来解决这个运动重定向问题,这需要先决条件。然而,在不理解给定的人体动作的情况下学习所有技能的成本将极其高昂,特别是对于高维机器人而言。在这项工作中,我们介绍了 CrossLoco,这是一种引导式无监督强化学习框架,可以同时学习机器人技能及其与人类动作的对应关系。我们的关键创新是引入基于循环一致性的奖励项,旨在最大化人类运动和机器人状态之间的相互信息。我们证明,所提出的框架可以通过转换不同的人类动作(例如跑步、跳跃和跳舞)来生成引人注目的机器人动作。我们将 CrossLoco 与手动设计和无监督的基线算法以及我们框架的消融版本进行定量比较,并证明我们的方法能够以更好的准确性、多样性和用户偏好来转换人体动作。 |
| UniQuadric: A SLAM Backend for Unknown Rigid Object 3D Tracking and Light-Weight Modeling Authors Linghao Yang, Yanmin Wu, Yu Deng, Rui Tian, Xinggang Hu, Tiefeng Ma 跟踪和建模环境中的未知刚性物体在自主无人系统和虚拟真实交互应用中发挥着至关重要的作用。然而,许多现有的同步定位、建图和移动物体跟踪SLAMMOT方法仅专注于估计特定物体姿态,缺乏对物体尺度的估计,无法有效跟踪未知物体。在本文中,我们提出了一种新颖的 SLAM 后端,它将自我运动跟踪、刚性物体运动跟踪和建模统一在联合优化框架内。在感知部分,我们基于Segment Anything Model SAM和DeAOT设计了像素级异步目标跟踪器AOT,使跟踪器能够在各种预定义任务和提示的引导下有效跟踪目标未知物体。在建模部分,我们提出了一种新颖的以对象为中心的二次参数化来统一静态和动态对象初始化和优化。随后,在物体状态估计部分,我们提出了一种用于物体位姿和尺度估计的紧耦合优化模型,将混合约束纳入一种新颖的双滑动窗口优化框架中以进行联合估计。据我们所知,我们是第一个将对象姿态跟踪与使用二次曲面的动态和静态对象的轻量级建模紧密结合在一起的。我们对模拟数据集和现实世界数据集进行定性和定量实验,展示了运动估计和建模方面最先进的鲁棒性和准确性。 |
| Simultaneous Synchronization and Calibration for Wide-baseline Stereo Event Cameras Authors Wanli Xing, Shijie Lin, Guangze Zheng, Yanjun Du, Jia Pan 基于事件的相机由于其高时间分辨率和低功耗而越来越多地应用于各种应用中。然而,当部署多个在独立时间系统上运行的此类相机时,就会出现一个根本性的挑战,导致时间错位。这种错位会显着降低下游应用程序的性能。传统的解决方案通常依赖于基于硬件的同步,面临兼容性的限制,并且对于长距离设置来说是不切实际的。为了解决这些挑战,我们提出了一种新颖的算法,该算法利用共享视场中物体的运动来实现多个基于事件的摄像机之间的毫秒级同步。我们的方法还同时估计外部参数。 |
| PONG: Probabilistic Object Normals for Grasping via Analytic Bounds on Force Closure Probability Authors Albert H. Li, Preston Culbertson, Aaron D. Ames 掌握规划的经典方法是确定性的,需要对物体的姿态和几何形状有完美的了解。作为回应,数据驱动的方法已经出现,计划完全从感官数据中掌握。虽然这些数据驱动方法在生成平行爪和动力抓取方面表现出色,但它们在使用灵巧手的指尖进行精确抓取(例如工具使用)方面的应用仍然有限。由于其对物体几何形状的敏感性,精确抓取提出了独特的挑战,这使得物体形状和姿势的微小不确定性导致原本稳健的抓取失败。为了应对这些挑战,我们引入了用于抓取 PONG 的概率对象法线,这是一种新颖的分析方法,用于在接触位置已知但表面法线不确定的情况下计算力闭合概率的保守估计。然后,我们提出一个实际应用,其中我们使用 PONG 作为抓取度量,以在模拟和现实世界的硬件实验中生成稳健的抓取。 |
| ASAP: Automated Sequence Planning for Complex Robotic Assembly with Physical Feasibility Authors Yunsheng Tian, Karl D.D. Willis, Bassel Al Omari, Jieliang Luo, Pingchuan Ma, Yichen Li, Farhad Javid, Edward Gu, Joshua Jacob, Shinjiro Sueda, Hui Li, Sachin Chitta, Wojciech Matusik 复杂产品的自动化组装需要一个能够自动规划物理上可行的动作序列以将许多零件组装在一起的系统。在本文中,我们提出了 ASAP,一种基于物理的规划方法,用于自动生成通用形状组件的此类序列。 ASAP 考虑重力来设计一个序列,其中每个子组件在物理上保持稳定,并固定有限数量的零件和支撑表面。我们应用高效的树搜索算法来降低确定此类组装序列的组合复杂度。搜索可以通过几何启发式或基于带有模拟标签的数据训练的图神经网络来指导。最后,我们展示了 ASAP 在针对数百个复杂产品装配的大型数据集生成物理上真实的装配顺序计划方面的卓越性能。我们进一步证明了 ASAP 在模拟和现实世界机器人设置上的适用性。 |
| A Sign Language Recognition System with Pepper, Lightweight-Transformer, and LLM Authors JongYoon Lim, Inkyu Sa, Bruce MacDonald, Ho Seok Ahn 这项研究探索使用轻量级深度神经网络架构,使人形机器人 Pepper 能够理解美国手语 ASL 并促进非语言人类机器人交互。首先,我们引入了一种针对嵌入式系统优化的轻量级且高效的 ASL 理解模型,确保快速符号识别,同时节省计算资源。在此基础上,我们采用大型语言模型法学硕士进行智能机器人交互。通过复杂的提示工程,我们定制交互,使 Pepper 机器人能够生成自然的语音手势响应,为更有机、更直观的人形机器人对话奠定基础。最后,我们提出了一个集成的软件管道,体现了社交意识人工智能交互模型的进步。利用 Pepper Robot 的功能,我们在现实场景中展示了我们的方法的实用性和有效性。 |
| Sandwich Approach for Motion Planning and Control Authors Mohamadreza Ramezani, Hossein Rastgoftar 本文受流体力学基础原理的启发,开发了一种在充满障碍物的环境中进行机器人运动规划和控制的新方法。对于运动规划,我们提出了运动空间(具有随机大小和形状的任意障碍物)与具有测地变化距离和约束过渡的无障碍规划空间之间的新颖变换。然后,我们通过对分布在规划空间上的均匀网格进行 A 搜索来获得机器人所需的轨迹。我们表明,与现有的运动空间 A 搜索相比,在规划空间上实施 A 搜索可以生成更短的路径。 |
| Predicting Object Interactions with Behavior Primitives: An Application in Stowing Tasks Authors Haonan Chen, Yilong Niu, Kaiwen Hong, Shuijing Liu, Yixuan Wang, Yunzhu, Katherine Driggs Campbell 装载是将物体放置在杂乱的货架或箱子中的任务,是仓库和制造操作中的常见任务。然而,这项任务仍然主要由人类工人执行,因为由于复杂的多对象交互和任务的长期性质,装载很难实现自动化。以前的工作通常涉及广泛的数据收集和跨不同对象类别的语义先验的昂贵的人工标记。本文提出了一种从对象交互的预测模型和行为原语的单个演示中学习通用机器人收起策略的方法。我们提出了一种新颖的框架,利用图神经网络来预测行为基元参数空间内的对象交互。我们进一步采用原语增强轨迹优化来搜索预定义的异构行为原语库的参数以实例化控制动作。我们的框架使机器人能够通过单个演示中的几个关键帧 3 4 熟练地执行长视野装载任务。尽管仅接受了模拟训练,但我们的框架表现出了卓越的泛化能力。 |
| Stochastic Implicit Neural Signed Distance Functions for Safe Motion Planning under Sensing Uncertainty Authors Carlos Quintero Pe a, Wil Thomason, Zachary Kingston, Anastasios Kyrillidis, Lydia E. Kavraki 感知不确定性下的运动规划对于非结构化环境中的机器人至关重要,以保证机器人和附近人类的安全。大多数在不确定性下进行规划的工作都无法扩展到高维机器人(例如机械手),假设机器人或环境的几何形状被简化,或者需要每个对象的噪声知识。相反,我们提出了一种方法,可以直接对传感器特定的任意不确定性进行建模,以找到复杂环境中高维系统的安全运动,而无需精确了解环境几何形状。我们将随机符号距离函数的新颖隐式神经模型与基于分层优化的运动规划器相结合,以在不牺牲路径质量的情况下规划低风险运动。我们的方法还明确限制了路径的风险,提供了可信度。 |
| Social Navigation in Crowded Environments with Model Predictive Control and Deep Learning-Based Human Trajectory Prediction Authors Viet Anh Le, Behdad Chalaki, Vaishnav Tadiparthi, Hossein Nourkhiz Mahjoub, Jovin D sa, Ehsan Moradi Pari 在过去的几十年里,人群导航越来越受到研究人员的关注,迄今为止,出现了许多旨在解决这一问题的方法。我们提出的方法将智能体运动预测和规划结合起来,以避免机器人冻结问题,同时利用最先进的轨迹预测模型(即社交长短期记忆模型 Social LSTM)捕获多智能体社交交互。在给定机器人可能动作的情况下,利用社交 LSTM 的输出来预测行人在每个时间步的未来轨迹,我们的框架使用模型预测控制 MPC 计算机器人在行人之间导航的最佳控制动作。 |
| Robust Safe Control with Multi-Modal Uncertainty Authors Tianhao Wei, Liqian Ma, Ravi Pandya, Changliu Liu 具有普遍不确定性的动态系统的安全性至关重要。当前的鲁棒安全控制器主要针对单模态不确定性而设计,在处理多模态不确定性时可能过于保守或不安全。 |
| An Attentional Recurrent Neural Network for Occlusion-Aware Proactive Anomaly Detection in Field Robot Navigation Authors Andre Schreiber, Tianchen Ji, D. Livingston McPherson, Katherine Driggs Campbell 移动机器人在农业领域等非结构化环境中的使用变得越来越普遍。因此,此类现场机器人主动识别和避免故障的能力对于确保效率和避免损坏至关重要。然而,杂乱的现场环境引入了各种噪声源,例如传感器遮挡,这使得主动异常检测变得困难。现有方法在传感器遮挡场景中表现不佳,因为它们通常不会显式地对遮挡进行建模,而仅利用当前的感官输入。在这项工作中,我们提出了一种基于注意力的循环神经网络架构,用于主动异常检测,它将当前的感官输入和计划的控制动作与先前机器人状态的潜在表示融合在一起。我们通过显式学习的传感器遮挡模型来增强我们的模型,该模型用于调节我们对先前机器人状态的潜在表示的使用。我们的方法显示出改进的异常检测性能,并使移动现场机器人能够在传感器遮挡期间(特别是在所有传感器短暂遮挡的情况下)显示出更高的弹性来预测有关导航故障的误报。 |
| MEM: Multi-Modal Elevation Mapping for Robotics and Learning Authors Gian Erni, Jonas Frey, Takahiro Miki, Matias Mattamala, Marco Hutter 高程图通常用于表示移动机器人的环境,对于运动和导航任务很有帮助。然而,纯几何信息对于许多需要外观或语义信息的现场应用来说是不够的,这限制了它们对其他平台或领域的适用性。在这项工作中,我们通过将多个来源的多模态信息融合到流行的地图表示中,扩展了以机器人为中心的 2.5D 高程测绘框架。该框架允许以统一的方式输入点云或图像中包含的数据。为了管理数据的不同性质,我们还提出了一组可以根据信息类型和用户需求进行选择的融合算法。我们的系统设计为在 GPU 上运行,使其能够实时执行各种机器人和学习任务。 |
| Cascaded Nonlinear Control Design for Highly Underactuated Balance Robots Authors Feng Han, Jingang Yi 本文提出了一种高度欠驱动平衡机器人的非线性控制设计,该机器人具有比驱动机器人更多的非驱动自由度 DOF。为了解决同时跟踪驱动坐标和平衡未驱动坐标的挑战,所提出的控制将机器人动力学转换为一系列级联子系统,并且每个子系统都被认为是虚拟驱动的。为了实现控制目标,我们依次设计和更新虚拟和实际控制输入以纳入平衡任务,从而使未驱动的坐标平衡到瞬时平衡。闭环动力学被证明是稳定的,并且跟踪误差以指数方式收敛到原点附近的邻域。 |
| Coupled Active Perception and Manipulation Planning for a Mobile Manipulator in Precision Agriculture Applications Authors Shuangyu Xie, Chengsong Hu, Di Wang, Joe Johnson, Muthukumar Bagavathiannan, Dezhen Song 移动操纵器经常发现自己处于需要在执行操纵任务之前进行近距离观察的应用程序中。将其命名为耦合主动感知和操作 CAPM 问题,我们对感知过程中的不确定性进行建模,并设计了一种关键状态任务规划方法,该方法将可达性条件视为移动平台感知和操作任务的任务约束。通过在满足任务约束的同时最小化身体关键状态规划中的预期能量使用,我们的算法实现了任务成功率和能量使用之间的最佳平衡。我们已经实现了该算法并在模拟和物理实验中对其进行了测试。 |
| Encountered-Type Haptic Display via Tracking Calibrated Robot Authors Chenxi Xiao, Yuan Tian 在过去的几十年里,各种触觉设备被开发出来,以促进虚拟现实 VR 中的高保真人机交互 HCI。特别是,被动触觉反馈可以基于真实物体与虚拟物体在空间上重叠而产生引人注目的感觉。然而,这些方法需要预先部署工作,阻碍了它们在实践中的民主化使用。我们提出了跟踪校准机器人 TCR,这是一种新颖且通用的触觉方法,可以将开发人员从部署工作中解放出来,可以在任何场景中部署。具体来说,我们使用协作机器人增强 VR,当用户触摸虚拟世界中的虚拟对象时,该机器人可以在现实世界中呈现触觉接触。用户手指和机器人末端执行器之间的距离随着时间的推移而受到控制。当用户想要触摸虚拟对象时,距离开始平滑地减小到零。 |
| Energy Efficient Foot-Shape Design for Bipedal Walkers on Granular Terrain Authors Xunjie Chen, Jingang Yi, Hao Wang 了解双足步行者如何在沙子和松散泥土等颗粒材料上有效平衡和行走非常重要。本文首先提出了一种计算方法来获得双足步行者在颗粒地形上的运动和能量分析,然后讨论了一种优化方法用于节能行走的机器人足部形状轮廓设计方法。我们首先使用提供综合力定律的阻力理论提出入侵过程的脚部地形相互作用特征。使用人类步态轮廓,我们计算并比较地面反作用力和在粒状地形上各种足部形状的步行步态的外部功。最终提出了考虑节能和行走效率的足部轮廓设计的多目标优化问题。有趣的是,非凸脚形状在坚硬的颗粒地形上提供了最佳的能量和运动效率性能。 |
| A Real-World Quadrupedal Locomotion Benchmark for Offline Reinforcement Learning Authors Hongyin Zhang, Shuyu Yang, Donglin Wang 在线强化学习 RL 方法通常数据效率低下或不可靠,这使得它们很难在真实的机器人硬件上进行训练,尤其是四足机器人。从预先收集的数据中学习机器人任务是一个有前途的方向。与此同时,敏捷而稳定的腿式机器人运动的一般形式仍然是一个悬而未决的问题。离线强化学习 ORL 有潜力在这个充满挑战的领域取得突破,但其目前的瓶颈在于缺乏多样化的数据集来应对具有挑战性的现实任务。为了促进 ORL 的开发,我们在真实的四足运动数据集中对 11 种 ORL 算法进行了基准测试。此类数据集是通过经典的模型预测控制 MPC 方法收集的,而不是以前基准测试中常用的无模型在线 RL 方法。大量的实验结果表明,与无模型强化学习相比,性能最好的 ORL 算法可以实现具有竞争力的性能,甚至在某些任务中超越它。然而,基于学习的方法与 MPC 之间仍然存在差距,特别是在稳定性和快速适应方面。 |
| Towards Safe Autonomy in Hybrid Traffic: Detecting Unpredictable Abnormal Behaviors of Human Drivers via Information Sharing Authors Jiangwei Wang, Lili Su, Songyang Han, Dongjin Song, Fei Miao 涉及自动驾驶和人类驾驶车辆的混合交通将在一段时间内成为自动驾驶汽车实践的常态。一方面,与自动驾驶汽车不同,人类驾驶的车辆可能会表现出突然的异常行为,例如不可预测地切换到危险的驾驶模式,使邻近的车辆面临风险,这种不期望的模式切换可能是由许多人类驾驶员因素引起的,包括疲劳、醉酒、另一方面,现代车对车通信技术使自动驾驶车辆能够高效、可靠地彼此共享稀缺的运行时间信息。在本文中,据我们所知,我们提出了第一个有效的算法,该算法可以 1 通过有效融合周围自动驾驶车辆共享的运行时信息来显着改善轨迹预测,并且可以 2 准确快速地检测异常的人类驾驶模式切换或具有正式保证的异常驾驶行为,且不会损害人类驾驶员的隐私。为了验证我们提出的算法,我们首先在 NGSIM 和 Argoverse 数据集上评估我们提出的轨迹预测器,并表明我们提出的预测器优于基线方法。然后通过在 SUMO 模拟器上进行大量实验,我们表明我们提出的算法在高速公路和城市交通中都具有良好的检测性能。 |
| Circular-Line Trajectory Tracking Controller for Mobile Robot using Multi-Pixy2 Sensors Authors Xuan Quang Ngo, Tri Duc Tran, Huy Hung Nguyen, Van Dong Nguyen, Van Tu Duong, Tan Tien Nguyen 这项研究提出了一种新颖的跟踪方法,该方法采用三个 Pixy2 传感器来识别所需的线轨迹,而不是传统的感知手段。首先,移动机器人的运动学模型是根据三个 Pixy2 传感器收集的信息得出的。其次,采用滑模控制器来调节跟踪误差。 |
| Autonomous Guidance Navigation and Control of the VISORS Formation-Flying Mission Authors Tommaso Guffanti, Toby Bell, Samuel Y. W. Low, Mason Murray Cooper, Simone D Amico 具有可重构群VISORS的虚拟超分辨率光学器件是一项分布式望远镜任务,使用两个在太阳同步近地轨道上编队飞行的6U立方体卫星对太阳进行高分辨率成像。光学航天器携带一个光子筛,充当极紫外光谱中的高分辨率透镜,而穿过筛子的图像则聚焦在探测器航天器上。本文介绍了机载制导、导航和控制 GNC 系统的新构想,该系统具有高度自主性、鲁棒性、被动安全性,并在实际任务模拟中得到了验证。 GNC系统的主要目标是在10秒持续时间的重复观测中,以40米间隔建立被动安全且高精度的编队对准,相对导航和位置控制精度达到亚厘米级。科学任务的成功率是通过蒙特卡罗分析在由于传感误差、机动误差、未建模的动力学和内部航天器组件的错误知识而产生的实际建模不确定性下进行评估的。通过整数模糊度分辨率的载波相位差分GPS实现精确的实时相对导航。通过基于闭环优化的随机模型预测控制,实现了对短基线的精确控制,精度达到厘米级。远距离和接近过程中的控制是通过具有米级精度的封闭式脉冲控制来实现的。在整个任务过程中强制实施被动安全,以减轻碰撞风险,即使在关键子系统发生故障的情况下也是如此。 |
| A New 1-mg Fast Unimorph SMA-Based Actuator for Microrobotics Authors Conor K. Trygstad, Xuan Truc Nguyen, Nestor O. Perez Arancibia 我们推出了一种用于微型机器人的新型单压电晶片执行器,它由细形状记忆合金 SMA 线驱动。利用被动毛细管对准技术和现有的 SMA 微系统制造方法,我们开发了一种长 7 mm、体积为 0.45 mm 3、重 0.96 mg 的执行器,可实现高达 40 Hz 的工作频率和 155 升的升力。乘以自身重量。为了演示所提出的执行器的功能,我们创建了一个 8 毫克爬行器(MiniBug)和一个仿生 56 毫克可控水表面张力爬行器(WaterStrider)。 MiniBug 长 8.5 毫米,移动速度高达每秒 0.76 BL 身体长度,是有史以来同类产品中最轻的全功能爬行微型机器人。 WaterStrider 长 22 毫米,能够以高达 0.28 BL s 的速度移动,并以 0.144 rad s 的角速率执行转弯机动。 |
| Controlling the Solo12 Quadruped Robot with Deep Reinforcement Learning Authors Michel Aractingi LAAS GEPETTO , Pierre Alexandre L ziart LAAS GEPETTO , Thomas Flayols LAAS GEPETTO , Julien Perez, Tomi Silander, Philippe Sou res LAAS GEPETTO 四足机器人需要强大且通用的运动技能,才能在复杂且具有挑战性的环境中发挥其移动潜力。在这项工作中,我们首次在 Solo12 四足动物上实现了基于端到端学习的稳健控制器。我们的方法基于关节阻抗参考的深度强化学习。由此产生的控制策略遵循命令的速度参考,同时具有高效的能源消耗、稳健且易于部署。我们详细介绍了在真实机器人上迁移的学习过程和方法。 |
| Powertrain Hybridization for Autonomous Vehicles Authors Shima Nazari, Norma Gowans, Mohammad Abtahi 当今混合动力电动汽车的动力系统是为人类驾驶员开发的,因此,考虑到自动驾驶汽车可以准确地操纵其速度曲线以避免不必要的能量损失,因此,它可能不是未来自动驾驶汽车的最佳选择。在这项工作中,我们通过部署现实世界的城市驾驶配置文件并在混合自动驾驶场景中生成等效的自动驾驶汽车驾驶周期,仔细研究了自动驾驶汽车与人类驾驶员相比所需的混合程度。我们解决了汽车市场上各种电机尺寸的混合动力汽车的最佳能源管理问题,并证明,虽然人类驾驶员通常需要 30 kW 左右的电机尺寸才能充分受益于混合动力,但 AV 仅需 12 kW 电机即可实现类似的增益。更小的电机尺寸带来的更大好处可以归因于更优化的扭矩请求,从而可以从再生制动中获得更高的收益,并实现更高效的发动机运行。此外,我们还研究了速度平滑对传统汽车和混合动力汽车的好处,并探讨了不同机制在降低燃料消耗方面的作用。 |
| See Beyond Seeing: Robust 3D Object Detection from Point Clouds via Cross-Modal Hallucination Authors Jianning Deng, Gabriel Chan, Hantao Zhong, Chris Xiaoxuan Lu 本文提出了一种通过跨模态幻觉从点云进行鲁棒 3D 物体检测的新颖框架。我们提出的方法与 LiDAR 和 4D 雷达之间的幻觉方向无关。我们在空间和特征层面上引入多重对齐,以实现同时骨干细化和幻觉生成。具体来说,提出了空间对齐来处理几何差异,以实现 LiDAR 和雷达之间更好的实例匹配。特征对齐步骤进一步弥合了传感模式之间的内在属性差距并稳定了训练。即使在推理阶段仅使用单模态数据作为输入,经过训练的目标检测模型也可以更好地处理困难的检测情况。 |
| ComSD: Balancing Behavioral Quality and Diversity in Unsupervised Skill Discovery Authors Xin Liu, Yaran Chen, Dongbin Zhao 在没有监督的情况下学习多样化且合格的行为以供利用和适应是智能生物的一项关键能力。理想的无监督技能发现方法能够在没有外在奖励的情况下产生多样化且合格的技能,而发现的技能集可以以各种方式有效地适应下游任务。理论上,最大化技能和访问状态之间的互信息MI可以实现理想的技能条件行为蒸馏。然而,最近的先进方法在实践中很难很好地平衡行为质量探索和多样性开发,这可能是由于其严格的内在奖励设计导致的 MI 估计不合理。在本文中,我们提出了对比多目标技能发现 ComSD,它试图通过更合理的 MI 估计和动态加权的内在奖励来减轻所发现行为的质量与多样性冲突。 ComSD 建议采用对比学习来更合理地估计 MI 分解中的技能条件熵。此外,还提出了一种新颖的加权机制,将 MI 分解估计中的不同熵动态平衡为新颖的多目标内在奖励,以提高技能多样性和质量。对于具有挑战性的机器人行为发现,ComSD 可以产生由不同活动级别的不同行为组成的合格技能集,这是最近的先进方法无法做到的。在数值评估中,ComSD 展示了最先进的适应性能,在所有技能组合任务和大多数技能微调任务中显着优于最新的高级技能发现方法。 |
| TBD Pedestrian Data Collection: Towards Rich, Portable, and Large-Scale Natural Pedestrian Data Authors Allan Wang, Daisuke Sato, Yasser Corzo, Sonya Simkin, Aaron Steinfeld 社交导航和行人行为研究已转向基于机器学习的方法,并集中在行人交互和行人机器人交互建模的主题上。为此,需要包含丰富信息的大规模数据集。我们描述了一个便携式数据收集系统,加上半自主标签管道。作为管道的一部分,我们设计了一个标签校正网络应用程序,有助于人工验证自动行人跟踪结果。我们的系统能够在不同的环境中进行大规模数据收集并快速生产轨迹标签。与现有的行人数据收集方法相比,我们的系统包含三个组件,即自上而下和以自我为中心的视图、在社交适当的机器人存在下的自然人类行为以及基于度量空间的人类验证标签的组合。据我们所知,现有的数据收集系统还没有同时具备这三个组件的组合。 |
| GAIA-1: A Generative World Model for Autonomous Driving Authors Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, Gianluca Corrado 自动驾驶有望对交通带来革命性的改进,但构建能够安全地应对现实世界场景的非结构化复杂性的系统仍然具有挑战性。 |
| Robust Asynchronous Collaborative 3D Detection via Bird's Eye View Flow Authors Sizhe Wei, Yuxi Wei, Yue Hu, Yifan Lu, Yiqi Zhong, Siheng Chen, Ya Zhang 通过促进多个智能体之间的通信,协作感知可以极大地提高每个智能体的感知能力。然而,由于通信延迟、中断和时钟错位,代理之间的时间异步在现实世界中是不可避免的。该问题导致多智能体融合时信息不匹配,严重动摇协作的基础。为了解决这个问题,我们提出了 CoBEVFlow,一种基于鸟瞰 BEV 流的异步鲁棒协作 3D 感知系统。 CoBEVFlow 的关键直觉是补偿运动以对齐多个代理发送的异步协作消息。为了对场景中的运动进行建模,我们提出了 BEV 流,它是与每个空间位置相对应的运动向量的集合。基于BEV流,可以将异步感知特征重新分配到适当的位置,减轻异步的影响。 CoBEVFlow有两个优点:iCoBEVFlow可以处理以不规则、连续时间戳发送的异步协作消息,无需离散化;ii对于BEV流,CoBEVFlow仅传输原始感知特征,而不是生成新的感知特征,避免了额外的噪声。为了验证 CoBEVFlow 的功效,我们创建了 IRregular V2V IRV2V,这是第一个具有各种时间异步性的合成协作感知数据集,可模拟不同的现实世界场景。对 IRV2V 和现实世界数据集 DAIR V2X 进行的大量实验表明,CoBEVFlow 始终优于其他基线,并且在极其异步的设置中具有鲁棒性。 |
| LEF: Late-to-Early Temporal Fusion for LiDAR 3D Object Detection Authors Tong He, Pei Sun, Zhaoqi Leng, Chenxi Liu, Dragomir Anguelov, Mingxing Tan 我们提出了一种使用时间 LiDAR 点云进行 3D 对象检测的晚期到早期循环特征融合方案。我们的主要动机是将对象感知的潜在嵌入融合到 3D 对象检测器的早期阶段。与直接从原始点学习相比,这种特征融合策略使模型能够更好地捕获具有挑战性的物体的形状和姿势。我们的方法以循环方式进行后期到早期的特征融合。这是通过在时间校准和对齐的稀疏柱标记上强制执行基于窗口的注意力块来实现的。利用鸟瞰图前景柱分割,我们将模型需要融合到当前帧中的稀疏历史特征的数量减少了 10 倍。我们还提出了一种随机长度 FrameDrop 训练技术,该技术将模型推广到推理时的可变帧长度,以提高性能而无需重新训练。 |
| Safe Non-Stochastic Control of Control-Affine Systems: An Online Convex Optimization Approach Authors Hongyu Zhou, Yichen Song, Vasileios Tzoumas 我们研究如何安全地控制被有界非随机噪声破坏的非线性控制仿射系统,即先验未知且不一定受随机模型控制的噪声。我们关注采用时变凸约束形式的安全约束,例如避免碰撞和控制努力约束。我们提供了一种具有有限动态遗憾的算法,即针对预先知道噪声实现的最优透视控制器的有限次优性。我们对自动化的未来充满动力,尽管现实世界存在阵风等不可预测的干扰,机器人仍将自主执行复杂的任务。为了开发算法,我们将问题捕获为控制器和对手之间的顺序游戏,其中控制器首先玩,选择控制输入,而对手其次玩,选择噪声的实现。尽管无法事先知道噪声的实现,但控制器的目标是最小化其累积跟踪误差。 |
| XVO: Generalized Visual Odometry via Cross-Modal Self-Training Authors Lei Lai, Zhongkai Shangguan, Jimuyang Zhang, Eshed Ohn Bar 我们提出了 XVO,一种半监督学习方法,用于训练广义单目视觉里程计 VO 模型,在不同的数据集和设置中具有鲁棒的自我操作能力。与通常研究单个数据集中的已知校准的标准单目 VO 方法相比,XVO 有效地学习从视觉场景语义中恢复与现实世界比例的相对姿势,即不依赖于任何已知的相机参数。我们通过 YouTube 上提供的大量无约束和异构行车记录仪视频进行自我训练来优化运动估计模型。我们的主要贡献是双重的。首先,我们凭经验证明半监督训练对于学习通用直接 VO 回归网络的好处。其次,我们演示了多模态监督,包括分割、流、深度和音频辅助预测任务,以促进 VO 任务的广义表示。具体来说,我们发现音频预测任务可以显着增强半监督学习过程,同时减轻噪声伪标签,特别是在高度动态和域外视频数据中。尽管没有多帧优化或不了解相机参数,我们提出的教师网络在常用的 KITTI 基准上实现了最先进的性能。 |
| GPT-Lab: Next Generation Of Optimal Chemistry Discovery By GPT Driven Robotic Lab Authors Xiaokai Qin, Mingda Song, Yangguan Chen, Zhehong Ai, Jing Jiang 机器人融入化学实验提高了实验效率,但由于缺乏人类智能来理解文献,因此很少为实验设计提供帮助。因此,在自驱动实验室 SDL 中实现从实验设计到验证的完整流程自主仍然是一个挑战。将生成式预训练 Transformers GPT(特别是 GPT 4)引入机器人实验中提供了一种解决方案。我们介绍 GPT Lab,这是一种利用 GPT 模型为机器人提供类人智能的范例。借助我们的机器人实验平台,GPT 实验室挖掘材料和方法的文献,并通过高通量合成验证研究结果。作为演示,GPT 实验室分析了 500 篇文章,鉴定了 18 种潜在试剂,并成功生产出精确的湿度比色传感器,均方根误差 RMSE 为 2.68。 |
| Chinese Abs From Machine Translation |

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)