基于Flask+Vue的微博舆情分析系统
系统采集微博话题文章和评论数据,利用senta框架提供的预模型进行情感分析,对话题的关机键词、热度、地区进行分析,使用了tfidf、textrank等算法。
·
微博舆情分析系统
一、介绍
系统采集微博话题文章和评论数据,利用senta框架提供的预模型进行情感分析,对话题的关机键词、热度、地区进行分析,使用了tfidf、textrank等算法。
二、系统功能
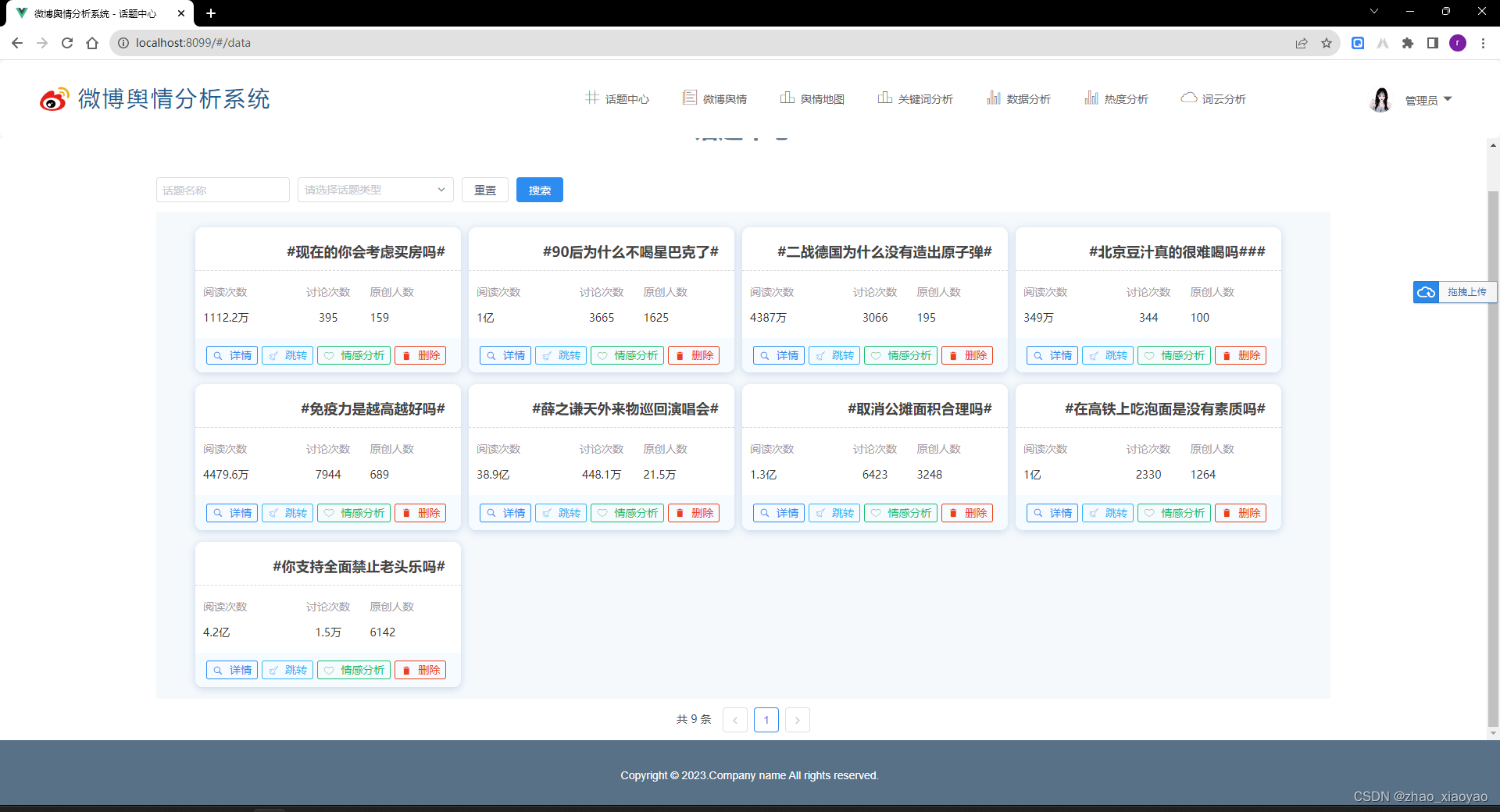
1、话题中心
展示我们系统中所爬取到的话题信息,包括阅读次数、讨论人数、原创人数等。
详情 展示话题的详情信息
跳转 跳转到微博该话题页面
情感分析 使用 百度情感分析senta模型,分析话题下评论内容的情感数据,点击按钮会展示当前话题下情感分析数据
删除 该功能是管理员功能,可删除当前话题


2、微博舆情
展示爬取到的文章信息及文章舆情分析信息(使用 百度情感分析senta模型分析舆情指数,舆情指数小于45分为绿色,45分-60分为橙色,大于60分为红色)。
点击地址可跳转到微博文章页面,点击详情按钮页面可查看该文章详情信息。


3、舆情地图
以地图的形式,直观的展示各个省份舆情信息,可以选择具体某个话题查看。

4、关键词分析
针对某一个话题 ,使用 textrank和tfidf分别提取话题关键词,以饼图和环形图的形式展示出来。

5、数据分析
以旭日图的形式展示各个话题正负面舆情占比。

6、热度分析
用时间热度图展示各个时期各个话题热度。

7、词云分析
使用jieba、wordcloud等库,对各个话题的文章和评论关键词进行分析,生成词云图

8、个人信息
用户查看、编辑个人信息

9、修改密码
用户登录后可修改密码

10、登录注册
用户登录注册


11、用户管理
管理员功能,管理用户信息

三、软件架构
后端
- python
- flask
前端
- vue
- iview
- echarts
所用python库
# 升级pip库,如果已升级可忽略
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
python -m pip install --upgrade pip
# flask库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple Flask
pip install fake_useragent
# pymysql
pip install pymysql
#requests
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
#xlwt
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlwt
#jieba
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
#wordcloud
pip --default-timeout=100 install wordcloud
#lxml
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple lxml
#BeautifulSoup4
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple BeautifulSoup4
# 情感分析 (https://aistudio.baidu.com/aistudio/projectdetail/4173079)
pip install paddlepaddle
pip install paddlehub
pip install --upgrade paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip3 install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip3 install paddlehub -i https://mirror.baidu.com/pypi/simple
pip install pyquery
# 日志打印
pip install coloredlogs
pip install textrank4zh
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple snownlp
pip install stopwords
pip install baidu-aip
四、安装教程
- 安装mysql5.7+,导入数据库脚本,修改项目中mysql配置(u_mysqlHelper.py)
- 安装python3.8(或附近版本均可)
- 安装上述所有python库
- 启动flask
# 启动flask命令
python app.py
- 安装node.js 14.x
- 安装cnpm
- 启动vue
# 安装vue库
cnpm i
# 启动vue
npm run serve
- 访问
http://localhost:8099/
五、工程目录结构
|micro-blog
|-- wb_server 后端目录
|-- app.py Flask主程序
|-- app_business.py 接口-业务相关
|-- app_user.py 接口-系统管理
|-- spider_comment.py 爬虫-评论
|-- spider_detail.py 爬虫-话题详情
|-- spider_run.py 爬虫执行文件(只执行该文件即可,其他爬虫都集成在此文件中,配置说明见下方爬虫说明部分)
|-- spider_sentiment.py 情感分析
|-- spider_wenzhagn.py 爬虫-文章信息
|-- stoplist.txt 关键词处理停词分拣
|-- u_cloud.py 工具类-生成词云
|-- u_data 数据处理工具类 (tfidf、textRank)
|-- u_mysqlHelper 数据库工具类
|-- u_timeHelper 时间工具
|-- wb_web
|-- node_modules node包
|-- public 结构文件
|-- src
|--api 接口
|--assets 静态文件
|--components 系统组件
|--router 路由
|--store 路由
|--utils 工具类
|--views 页面
|-- tests 测试类
|-- vue.config.js vue配置类
六、表结构
|p_jingdong_shouji
|-- talk_article 文章信息表
|-- talk_comment 评论信息表
|-- talk_detail 话题详情表
|-- tbl_user 用户表
七、特别说明
此系统爬虫脚本仅可用户学习交流,切勿爬取大量数据,对网站服务器施压!!!
爬虫说明:
- spider_run.py
爬虫执行文件,执行顺序:获取话题详情 -> 获取文章 -> 获取评论 -> 情感分析
# 参数设置
talk:话题名称
start_page:获取文章参数-开始页码
end_page:获取文章参数-结束页码
total:获取评论参数-一共获取多少条评论
num:获取评论参数-每个文章下最多获取多少评论
# 特别说明
爬取一条话题信息,只需要执行该文件即可。
如果需要分别爬取评论或者文章信息,可执行其他爬虫。
- spider_detail.py
该爬虫用户爬取 话题详情
# 目标地址
https://m.s.weibo.com/ajax_topic/detail?q=
# 防反爬设置
设置cookies,headers等信息,伪装成浏览器
# 参数设置
talk:话题名称
# 所用技术
requests、json处理
- spider_wenzhagn.py
该爬虫用户爬取 话题文章
# 目标地址
https://%s/api/container/getIndex?host
# 防反爬设置
设置headers等信息,伪装成浏览器
添加延时
# 参数设置
talk:话题名称
start: 开始页数吗
end: 结束页数
# 所用技术
requests、json处理
- spider_comment.py
该爬虫用户爬取 文章评论
# 目标地址
https://weibo.com/ajax/statuses/show?id={article_id}
# 防反爬设置
设置cookies,headers等信息,伪装成浏览器
# 参数设置
talk:话题名称
total:一共获取多少条评论
num:每个文章下获取多少评论
# 所用技术
requests、json处理
- spider_sentiment.py
该文件用户情感分析
# 所用技术
百度senta情感分析框架

前往低代码交流专区
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)