

Streamlit 讲解专栏(三):两种方案构建多页面
Streamlit是一款流行的Python库,用于快速构建数据科学和机器学习应用。本文介绍了Streamlit的两种多页面应用实现方式。第一种方法是使用侧边栏组件,您可以在其中添加导航链接或按钮,每个页面可以定制其内容和布局。第二种方法是使用选项卡组件,创建多个选项卡以显示不同的内容。无论选择哪种方式,Streamlit提供了简单而强大的功能来构建令人印象深刻的交互式应用程序。无论是简单的页面导航
文章目录

1 前言
首先,感谢各位读者阅读之前的一篇博文Streamlit 讲解专栏(二):搭建第一个应用,该博文详细介绍了如何使用Streamlit框架来搭建数据应用程序。🎉 在那篇博文中,我们强调了Streamlit的简单易用性和强大功能,以及如何通过编写Python代码快速创建交互式应用。
在这篇博文中,我们将进一步扩展之前的内容,并专注于Streamlit多页面应用的构建。多页面是一种重要且常见的应用程序设计方案,它允许我们在一个应用程序中使用多个页面来组织和呈现不同的内容或功能。通过多页面,我们可以更好地组织和管理复杂的应用,使用户能够轻松地与不同的功能模块进行交互。
但是,多页面是什么呢?在简单的术语中,多页面是指将一个大型应用程序拆分为多个独立的页面,每个页面专注于不同的任务或功能。这种设计模式的好处是明显的:它提高了应用的可维护性、可扩展性和用户体验。
在本博文中,我们将介绍两种不同的方案来构建Streamlit多页面应用。每种方案都有其独特的特点和用途;通过掌握这些方案,您将能够根据自己的需求选择最适合的方法。
无论您是数据科学家、开发人员还是对数据应用程序感兴趣的读者,希望这篇博文能为您学习和掌握Streamlit多页面应用的设计和实现提供指导和启发。
在进入具体方案之前,让我们先回顾一下Streamlit的基础知识,确保我们对Streamlit的核心概念和用法有一个清晰的理解。然后,我们将深入研究两个不同的多页面方案,并比较它们的优缺点。
请继续阅读,探索Streamlit多页面应用的令人兴奋和灵活的可能性!
2 第一种方案:使用Session State实现多页面交互
2.1 Session State简介
在介绍具体的设计方案之前,让我们先回顾一下Streamlit的Session State功能。Session State是Streamlit中用于在不同页面之间传递和保存状态数据的一种机制。通过Session State,我们可以在应用程序的整个生命周期中维护和访问特定于会话的变量。这意味着我们可以在不同页面之间共享和使用相同的变量值,从而实现多页面之间的交互和数据传递。
2.2 多页面应用的基本结构
在使用Session State构建多页面应用之前,让我们先了解一下多页面应用的基本结构。一个典型的多页面应用通常包括以下几个组成部分:
导航栏:用于切换页面的导航栏,可以是按钮、链接或下拉菜单等形式。
页面内容:不同页面的具体内容和功能模块,可以通过导航栏进行切换。
状态管理:保持和管理不同页面之间的状态数据,确保用户在切换页面时数据不会丢失。
2.3 实现多页面交互的代码示例
下面是一个使用Session State实现多页面交互的简单代码示例:
import streamlit as st
# 设置初始页面为Home
session_state = st.session_state
session_state['page'] = 'Home'
# 导航栏
page = st.sidebar.radio('Navigate', ['Home', 'About'])
if page == 'Home':
st.title('Home Page')
# 在Home页面中显示数据和功能组件
elif page == 'About':
st.title('About Page')
# 在About页面中显示数据和功能组件

通过以上代码,我们创建了一个导航栏,其中包含了两个页面选项:Home和About。根据用户选择的页面,在相应的代码块中显示内容和功能组件。
如果页面内容构建的太过复杂,单纯的 if-else 语句已经无法满足应用的构建需求,这时候可以使用函数来构建。
import streamlit as st
def page_home():
st.title('Home Page')
# 在Home页面中显示数据和功能组件
def page_about():
st.title('About Page')
# 在About页面中显示数据和功能组件
def main():
# 设置初始页面为Home
session_state = st.session_state
if 'page' not in session_state:
session_state['page'] = 'Home'
# 导航栏
page = st.sidebar.radio('Navigate', ['Home', 'About'])
if page == 'Home':
page_home()
elif page == 'About':
page_about()
if __name__ == '__main__':
main()
ps:请记住运行项目需要在终端执行以下代码:
streamlit run 你的代码文件.py
通过使用函数来构建多页面应用,我们可以更好地组织和管理不同页面的代码逻辑,并提高代码的可重用性。在上述示例代码中,我们定义了三个函数:
- page_home():用于显示Home页面的内容和功能。
- page_about():用于显示About页面的内容和功能。
- main():作为应用程序的主函数,根据用户导航栏的选择调用对应的页面函数。
在main()函数中,我们首先检查Session State中是否存在page键,如果不存在则将其初始化为Home。接着根据导航栏的选择,调用相应的页面函数进行内容显示。
2.4 Session State机制的优缺点
优点:
简单易用:Streamlit的Session State机制使得在不同页面之间传递和保存状态数据变得非常简单。只需使用字典来存储和访问状态数据,无需复杂的配置或额外的库。
跨页面数据共享:通过Session State,我们可以在应用程序的整个生命周期中保存和访问特定于会话的变量。这使得在多个页面之间共享数据变得轻松,可以传递复杂的数据结构,如字典、列表等。
可扩展性:使用Session State,我们可以轻松地在应用程序中添加新的页面,并在不同页面之间保持数据的一致性。这使得应用程序更易于管理和维护,可以随着需求的增长进行扩展和修改。
状态持久化:通过Streamlit的Session State机制,我们可以在刷新应用程序或重新运行应用程序时保留状态数据。这对于用户来说非常方便,他们可以在应用程序的不同会话之间保持他们的工作状态。
缺点:
内存消耗:由于Session State数据存储在内存中,当应用程序的状态数据变得庞大时,内存消耗可能会较大。这可能会限制应用程序的可伸缩性和性能。
无持久化方案:Session State数据存储在应用程序的内存中,并且仅在应用程序运行期间存在。因此,当应用程序停止运行或重新启动时,Session State数据将丢失。如果需要长期存储数据,需要使用其他机制,如数据库或文件系统。
难以调试:由于Session State是在应用程序的多个页面之间传递和共享数据,当出现问题时,追踪和调试可能会比较困难。特别是在复杂的多页面应用程序中,正确地处理和管理Session State变量可能会变得复杂。
3 第二种方案:Streamlit内置多页面方案(更为推荐)
随着应用程序逐渐庞大,将其组织成多个页面变得非常有用。这样一来,开发者可以更轻松地管理应用程序,用户也能更方便地浏览。Streamlit 提供了一种无障碍的方式来创建多页面应用程序。页面会自动显示在漂亮的导航小部件中,放置在应用程序的侧边栏,用户点击页面时,无需重新加载前端,使应用程序浏览速度极快!
在 Streamlit的第一个应用(二)中,我们创建了一个“单页面应用程序”,用于探索纽约市的 Uber 公共数据集,分析乘客上车和下车的情况。在本文中,让我们学习如何创建多页面应用程序。一旦我们掌握了创建多页面应用程序的基础知识,接下来的部分就会开始亲自动手,将其应用到我们自己的应用程序中!
3.1 如何运行多页面应用程序
运行多页面应用程序与运行单页面应用程序完全相同。运行多页面应用程序的命令如下:
streamlit run [入口文件]
📂 “入口文件” 是应用程序向用户展示的第一个页面。一旦你向应用程序添加了多个页面,入口文件将出现在侧边栏的顶部。你可以将入口文件视为应用程序的 “主页面”。举个例子,假设你的入口文件是 Home.py。那么,要运行你的应用程序,你可以执行以下命令:
streamlit run Home.py
这将启动你的应用程序,并执行 Home.py 文件中的代码。然后你会看到你的应用程序在本地服务器上运行起来,准备好通过浏览器进行访问。
请注意,你可以根据自己的需求和具体情况来制定入口文件和其他页面文件的命名方式。确保多页面应用程序的每个页面都有其独特的名称,以便在应用程序中进行正确的导航和路由。现在你已经掌握了运行多页面应用程序的技巧,是时候让你的应用程序在互联网上展现它的魅力了!快来展示你的创意吧!
3.2 添加页面
创建好入口文件后,你可以通过在入口文件所在目录的相对位置上创建文件来添加更多页面。比如说,如果你的入口文件是 Home.py,那么你可以创建一个文件来定义 “关于” 页面。下面是一个多页面应用程序的有效目录结构示例:
Home.py # 这是你用 "streamlit run" 命令来运行的文件
└─── pages/ # 这是存放其他页面文件的目录
└─── About.py # 这是一个页面
└─── 2_Page_two.py # 这是另一个页面
└─── 3_😎_three.py # 这也是一个页面

⭐小贴士: 当在文件名中添加表情符号时,最佳实践是在文件名前面添加编号前缀,这样可以更方便在终端中使用自动补全功能。因为终端的自动补全功能有时可能对 Unicode(即表情符号的表示方式)感到困惑。
页面是通过创建目录中的文件来定义的。基于下面的规则,页面文件的文件名将会在侧边栏中转换为页面名称。例如,文件名 About.py 会在侧边栏中显示为 “About”,2_Page_two.py 会显示为 “Page two”,3_😎_three.py 则会显示为 “😎 three”。
目录结构只有目录中的文件会作为页面加载。Streamlit会忽略目录和子目录中的所有其他文件。
请注意,确保为应用程序中的每个页面选择独一无二的文件名,并根据实际需求对文件和目录进行适当命名。这样可以确保你的多页面应用程序正确导航和定位到每个页面。现在你已经掌握了添加页面的方法,是时候为你的应用程序添加更多精彩内容了!快来展示你的创意吧!🎉💡
3.3 页面在用户界面中的标签和排序方式
页面在侧边栏用户界面中的标签是根据文件名生成的。现在我们来学习一下构成页面有效文件名的要素,页面如何显示在侧边栏中,以及页面如何排序。
下表展示了文件名示例及其在侧边栏中的标签,按照它们在侧边栏中出现的顺序进行排序。
| 文件名 | 显示标签 |
|---|---|
| 1 - first page.py | first page |
| 12 monkeys.py | monkeys |
| 123.py | 123 |
| 123_hello_dear_world.py | hello dear world |
| _12 monkeys.py | 12 monkeys |
⭐小贴士: 你可以使用表情符号使页面名称更有趣!例如,名为 🏠_Home.py 的文件将在侧边栏中创建一个名为 “🏠 Home” 的页面。
3.4 现在我们来实现一个多页面应用
- 在与入口文件(Hello.py)相同的目录中创建一个新的文件夹,命名为 pages。
- 将我们的入口文件重命名为 Hello.py,这样在侧边栏中的标题将被大写。
- 在刚创建的 pages 文件夹中,创建三个新的文件:
pages/1_📈_Plotting_Demo.py
pages/2_🌍_Mapping_Demo.py
pages/3_📊_DataFrame_Demo.py - 运行以下命令,以查看您新转换的多页应用程序:
streamlit run Hello.py
Hello.py
import streamlit as st
st.set_page_config(
page_title="你好",
page_icon="👋",
)
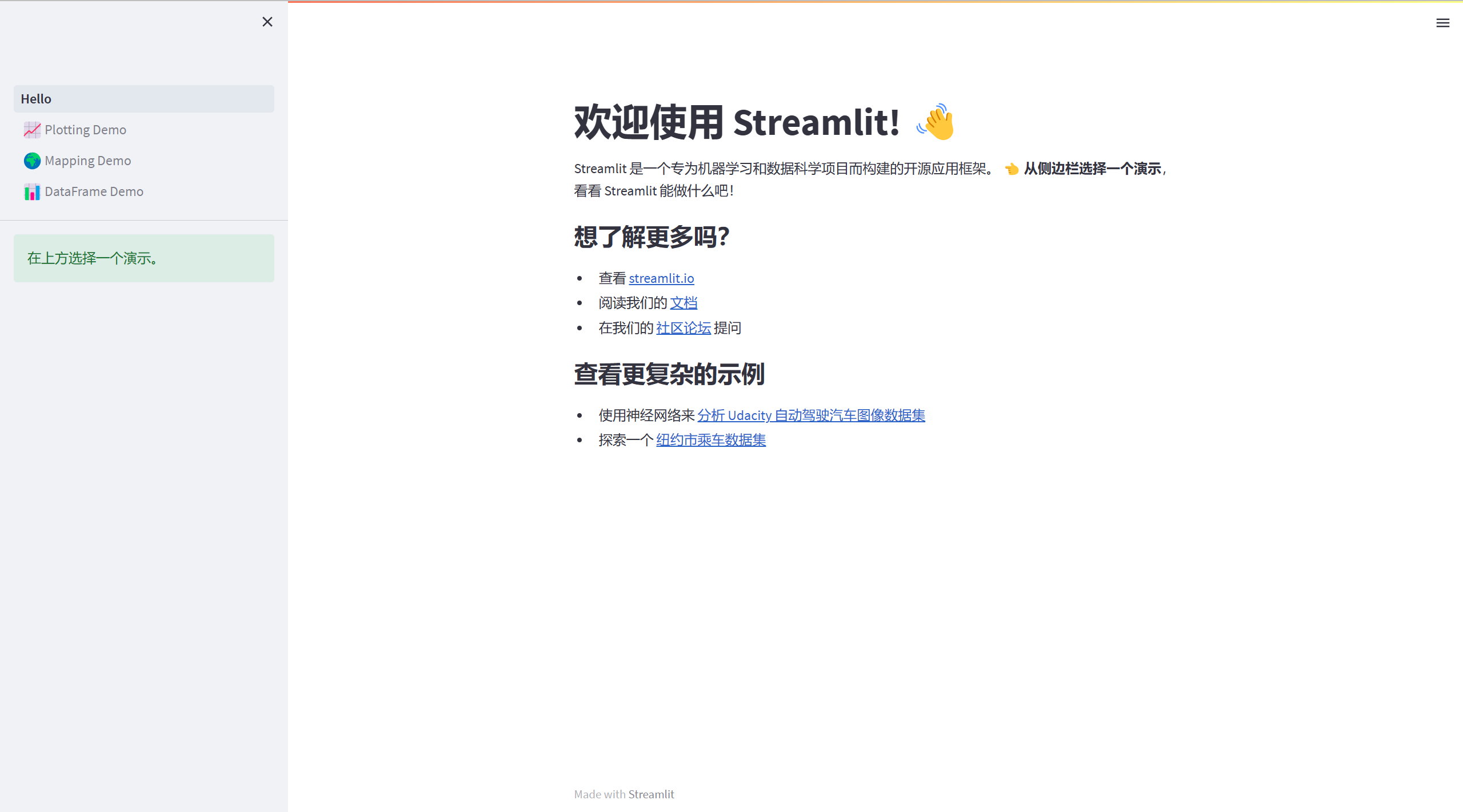
st.write("# 欢迎使用 Streamlit! 👋")
st.sidebar.success("在上方选择一个演示。")
st.markdown(
"""
Streamlit 是一个专为机器学习和数据科学项目而构建的开源应用框架。
**👈 从侧边栏选择一个演示**,看看 Streamlit 能做什么吧!
### 想了解更多吗?
- 查看 [streamlit.io](https://streamlit.io)
- 阅读我们的 [文档](https://docs.streamlit.io)
- 在我们的 [社区论坛](https://discuss.streamlit.io) 提问
### 查看更复杂的示例
- 使用神经网络来 [分析 Udacity 自动驾驶汽车图像数据集](https://github.com/streamlit/demo-self-driving)
- 探索一个 [纽约市乘车数据集](https://github.com/streamlit/demo-uber-nyc-pickups)
"""
)
pages/1_📈_Plotting_Demo.py
import streamlit as st
import time
import numpy as np
st.set_page_config(page_title="绘图演示", page_icon="📈")
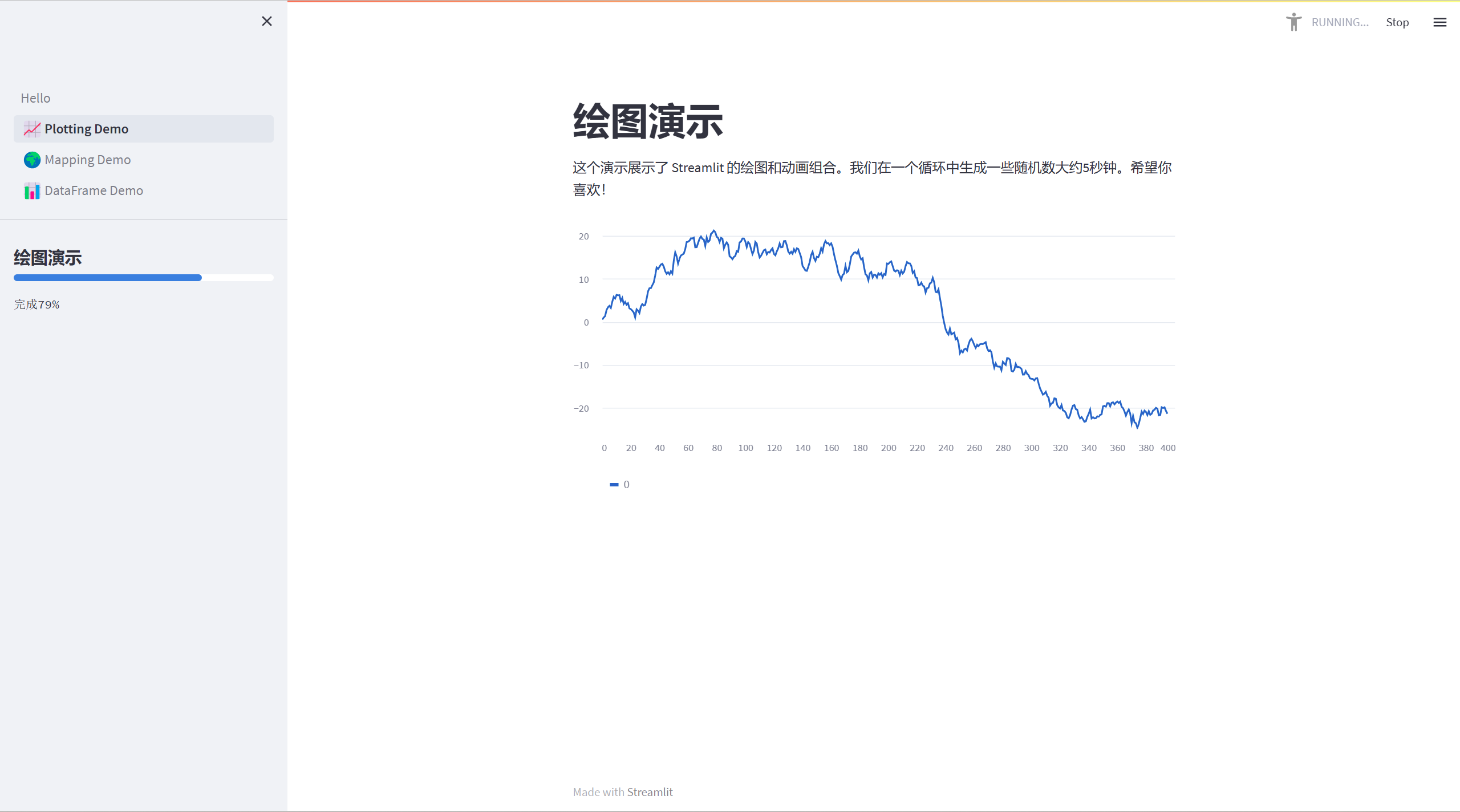
st.markdown("# 绘图演示")
st.sidebar.header("绘图演示")
st.write(
"""这个演示展示了 Streamlit 的绘图和动画组合。我们在一个循环中生成一些随机数大约5秒钟。希望你喜欢!"""
)
progress_bar = st.sidebar.progress(0)
status_text = st.sidebar.empty()
last_rows = np.random.randn(1, 1)
chart = st.line_chart(last_rows)
for i in range(1, 101):
new_rows = last_rows[-1, :] + np.random.randn(5, 1).cumsum(axis=0)
status_text.text("完成%i%%" % i)
chart.add_rows(new_rows)
progress_bar.progress(i)
last_rows = new_rows
time.sleep(0.05)
progress_bar.empty()
# Streamlit 的部件会自动按顺序运行脚本。由于此按钮与任何其他逻辑都没有连接,因此它只会引起简单的重新运行。
st.button("重新运行")
pages/2_🌍_Mapping_Demo.py
import streamlit as st
import pandas as pd
import pydeck as pdk
from urllib.error import URLError
st.set_page_config(page_title="Mapping Demo", page_icon="🌍")
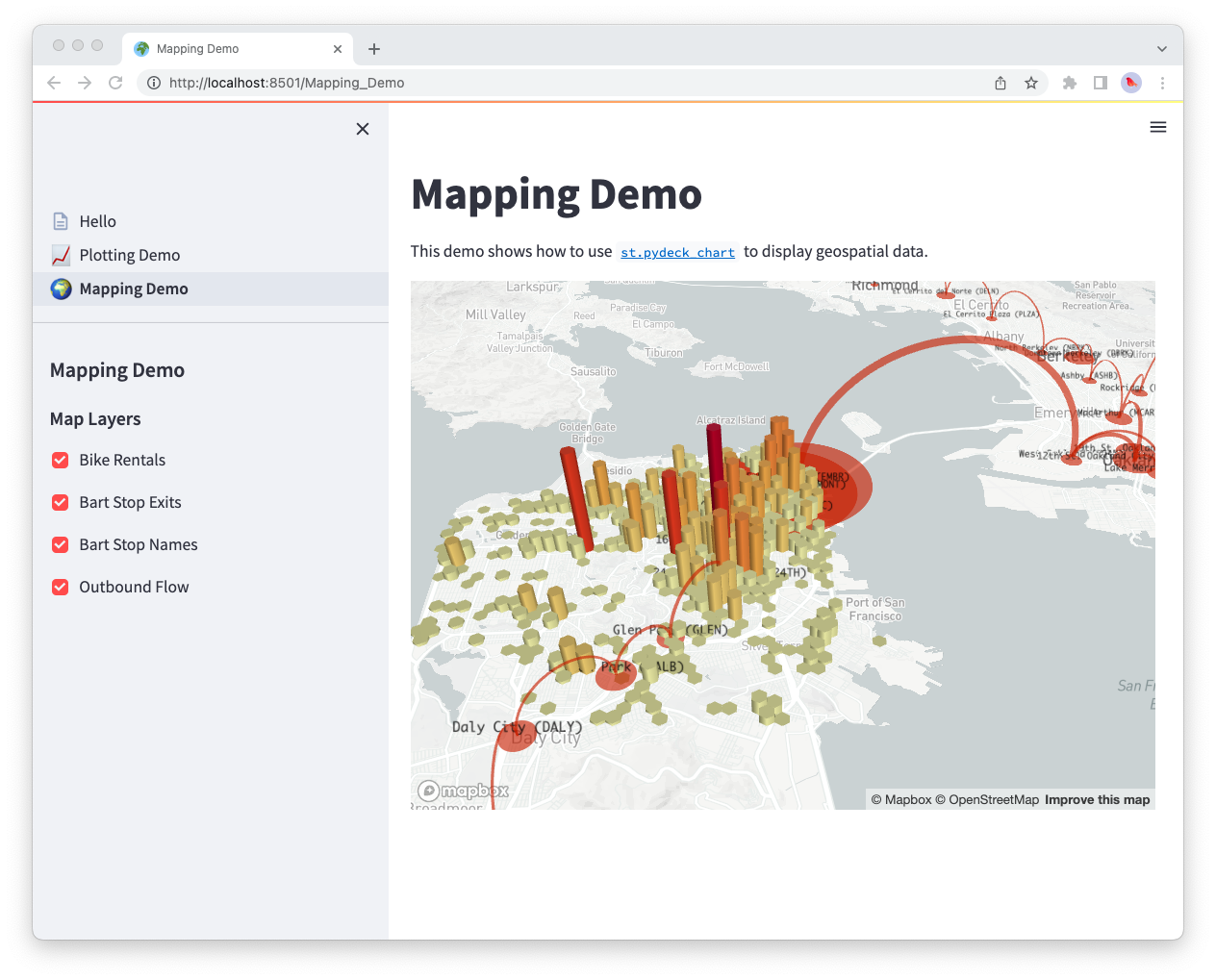
st.markdown("# Mapping Demo")
st.sidebar.header("Mapping Demo")
st.write(
"""This demo shows how to use
[`st.pydeck_chart`](https://docs.streamlit.io/library/api-reference/charts/st.pydeck_chart)
to display geospatial data."""
)
@st.cache_data
def from_data_file(filename):
url = (
"http://raw.githubusercontent.com/streamlit/"
"example-data/master/hello/v1/%s" % filename
)
return pd.read_json(url)
try:
ALL_LAYERS = {
"Bike Rentals": pdk.Layer(
"HexagonLayer",
data=from_data_file("bike_rental_stats.json"),
get_position=["lon", "lat"],
radius=200,
elevation_scale=4,
elevation_range=[0, 1000],
extruded=True,
),
"Bart Stop Exits": pdk.Layer(
"ScatterplotLayer",
data=from_data_file("bart_stop_stats.json"),
get_position=["lon", "lat"],
get_color=[200, 30, 0, 160],
get_radius="[exits]",
radius_scale=0.05,
),
"Bart Stop Names": pdk.Layer(
"TextLayer",
data=from_data_file("bart_stop_stats.json"),
get_position=["lon", "lat"],
get_text="name",
get_color=[0, 0, 0, 200],
get_size=15,
get_alignment_baseline="'bottom'",
),
"Outbound Flow": pdk.Layer(
"ArcLayer",
data=from_data_file("bart_path_stats.json"),
get_source_position=["lon", "lat"],
get_target_position=["lon2", "lat2"],
get_source_color=[200, 30, 0, 160],
get_target_color=[200, 30, 0, 160],
auto_highlight=True,
width_scale=0.0001,
get_width="outbound",
width_min_pixels=3,
width_max_pixels=30,
),
}
st.sidebar.markdown("### Map Layers")
selected_layers = [
layer
for layer_name, layer in ALL_LAYERS.items()
if st.sidebar.checkbox(layer_name, True)
]
if selected_layers:
st.pydeck_chart(
pdk.Deck(
map_style="mapbox://styles/mapbox/light-v9",
initial_view_state={
"latitude": 37.76,
"longitude": -122.4,
"zoom": 11,
"pitch": 50,
},
layers=selected_layers,
)
)
else:
st.error("Please choose at least one layer above.")
except URLError as e:
st.error(
"""
**This demo requires internet access.**
Connection error: %s
"""
% e.reason
)
pages/3_📊_DataFrame_Demo.py
import streamlit as st
import pandas as pd
import altair as alt
from urllib.error import URLError
st.set_page_config(page_title="DataFrame Demo", page_icon="📊")
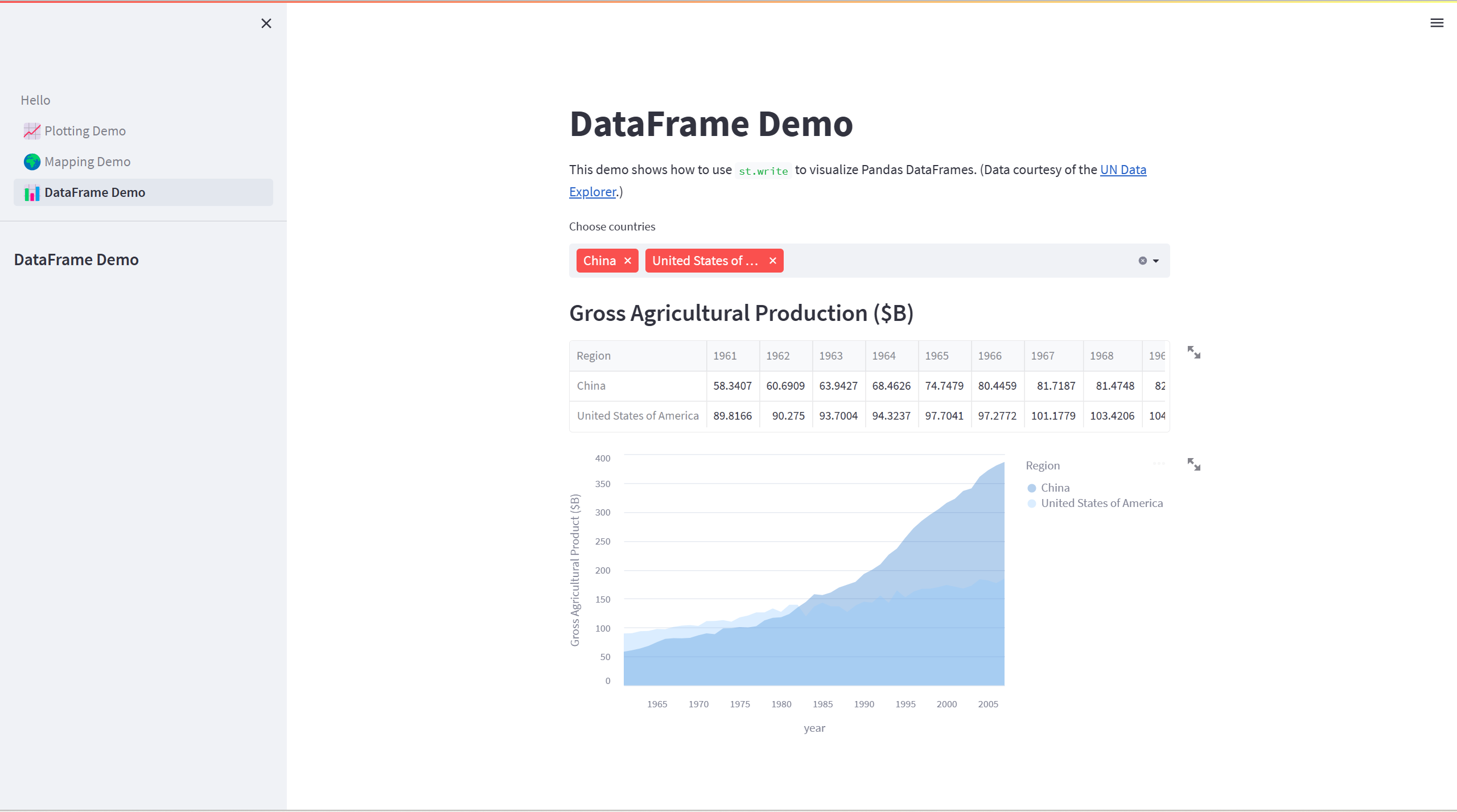
st.markdown("# DataFrame Demo")
st.sidebar.header("DataFrame Demo")
st.write(
"""This demo shows how to use `st.write` to visualize Pandas DataFrames.
(Data courtesy of the [UN Data Explorer](http://data.un.org/Explorer.aspx).)"""
)
@st.cache_data
def get_UN_data():
AWS_BUCKET_URL = "http://streamlit-demo-data.s3-us-west-2.amazonaws.com"
df = pd.read_csv(AWS_BUCKET_URL + "/agri.csv.gz")
return df.set_index("Region")
try:
df = get_UN_data()
countries = st.multiselect(
"Choose countries", list(df.index), ["China", "United States of America"]
)
if not countries:
st.error("Please select at least one country.")
else:
data = df.loc[countries]
data /= 1000000.0
st.write("### Gross Agricultural Production ($B)", data.sort_index())
data = data.T.reset_index()
data = pd.melt(data, id_vars=["index"]).rename(
columns={"index": "year", "value": "Gross Agricultural Product ($B)"}
)
chart = (
alt.Chart(data)
.mark_area(opacity=0.3)
.encode(
x="year:T",
y=alt.Y("Gross Agricultural Product ($B):Q", stack=None),
color="Region:N",
)
)
st.altair_chart(chart, use_container_width=True)
except URLError as e:
st.error(
"""
**This demo requires internet access.**
Connection error: %s
"""
% e.reason
)
4 结语
至此,两种streamlit的多页面的方案介绍完毕,感谢您阅读本篇博文!如果您对数据可视化和交互式应用程序感兴趣,我们邀请您关注我们的博客,以获取更多关于 Streamlit 和数据科学的有趣内容。您可以在我们的网站上了解更多细节,并发现更多有趣的示例和应用。
让我们一起探索数据世界的魅力,让数据在 Streamlit 的引领下展现出令人惊叹的效果!📈🚀
感谢您的阅读和关注!


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 25
25 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)