教程|使用免费GPU 资源搭建专属知识库 ChatGLM2-6B + LangChain
“搭建私人定制化AI知识库!详解如何使用云计算资源,部署ChatGLM和LangChain模型,打造专属智能问答工具。”01—申请免费试用阿里云的免费产品申请地址:https://free.aliyun.com/因为免费产品太多太多!在“搜索试用产品”输入框内,输入“PAI”,快速找到我们要申请的机器学习平台API。跟着操作提示步骤一步一步申请即可,中间可能有一些阿里云必要的角色创建.
“ 搭建私人定制化AI知识库!详解如何使用云计算资源,部署ChatGLM和LangChain模型,打造专属智能问答工具。”

01
—
申请免费试用
阿里云的免费产品申请地址:
https://free.aliyun.com/
因为免费产品太多太多!在“搜索试用产品”输入框内,输入“PAI”,快速找到我们要申请的机器学习平台API。
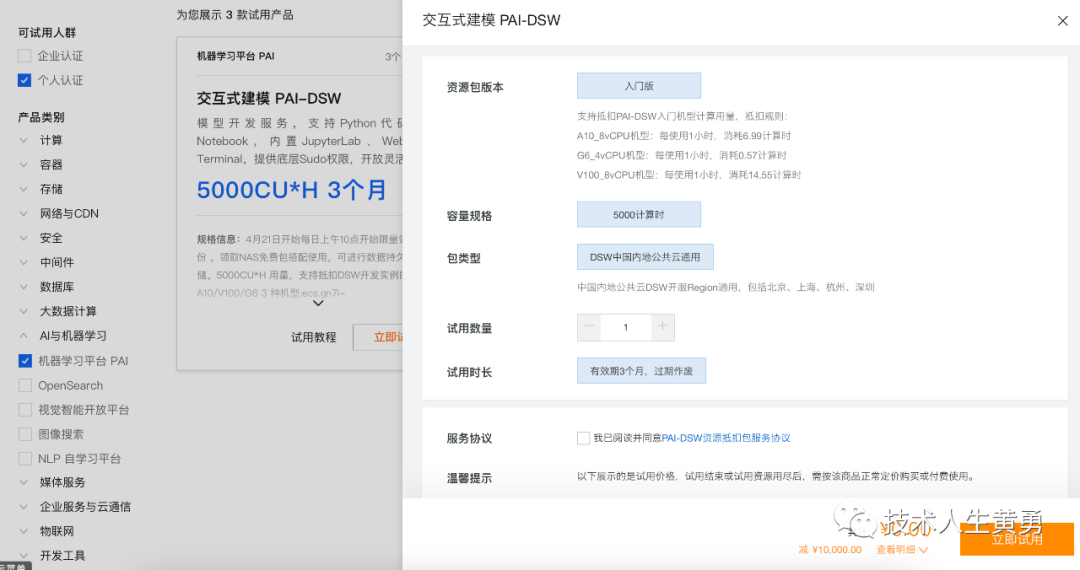
跟着操作提示步骤一步一步申请即可,中间可能有一些阿里云必要的角色创建,权限的赋予等等,都按照提示操作即可。
领取完成后,打开机器学习平台控制台
https://pai.console.aliyun.com/
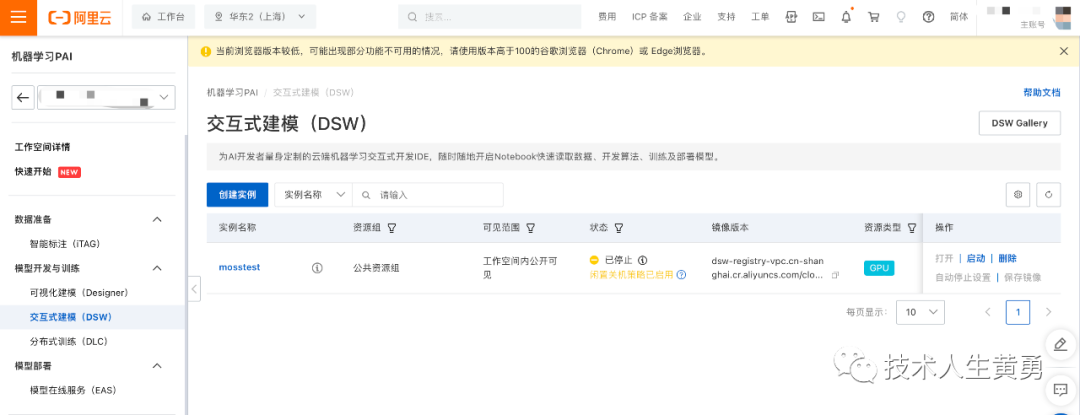
点击左边的“交互式建模(DSW)”,然后点击右边的按钮:“创建实例”,按提示操作步骤创建好实力,最后点击“操作”下面的“启动”,等待启动完成后,点击“打开”。
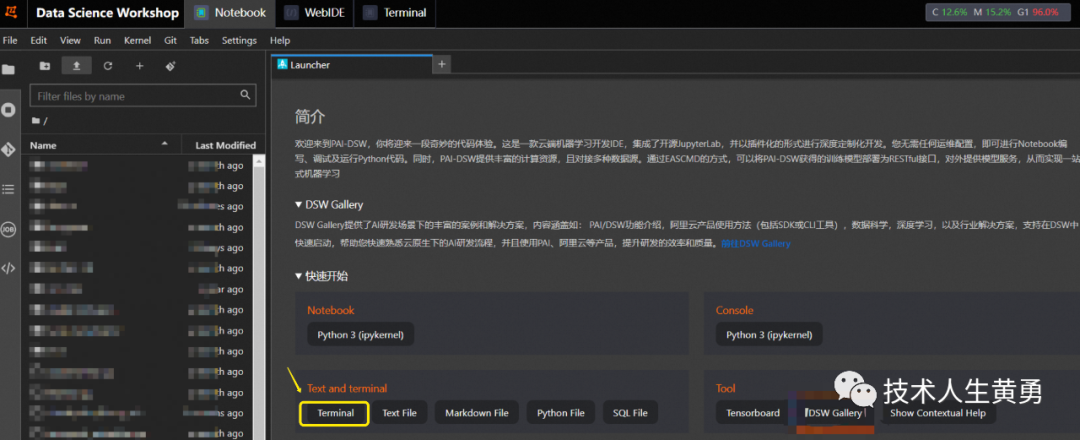
点击“terminal”,打开一个终端,后续主要操作都在这个终端界面进行。
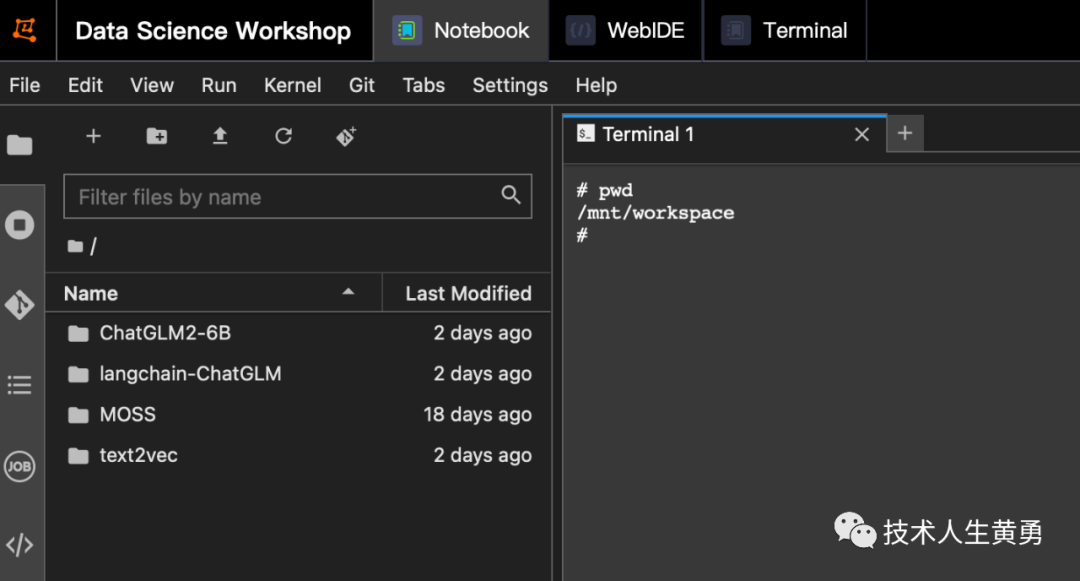
机器学习需要的一些基础框架和组建,这个环境的 Docker 镜像已经给我们准备好了,省去了我之前从云服务器开始部署吃的苦头。见:终于部署成功!GPU 云环境搭建 ChatGLM2-6B 坎坷路。
02
—
部署 ChatGLM2-6B
上面部分已经把环境准备好了,开始项目部署。
大模型项目因为是预训练模型,数据权重文件比较大,ChatGLM 就是代码和模型分开存放的。
下载源码
git clone https://github.com/THUDM/ChatGLM2-6B安装项目所需依赖
cd ChatGLM2-6B
# 官方推荐 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能
pip install -r requirements.txt下载模型
git clone https://huggingface.co/THUDM/chatglm2-6b这个下载命令会报错连不上 huggingface。这篇文章:工程落地实践|国产大模型 ChatGLM2-6B 阿里云上部署成功实现了解决方案,把文件传到 OSS 上(Object Storage Service,对象存储服务)。
模型下载问题解决后,我把模型文件放在了 ChatGLM2-6B/model 目录下,完整目录地址:/mnt/workspace/ChatGLM2-6B/model。
修改模型地址
打开 web_demo.py 文件,找到下面这两行,把引号里面模型地址改为下面这样刚刚放模型的目录名。不改的话,模型启动会去联网下载7个1G多的模型文件。
tokenizer = AutoTokenizer.from_pretrained("model", trust_remote_code=True)
model = AutoModel.from_pretrained("model", trust_remote_code=True).cuda()启用Web访问
还是 web_demo.py,找到这样,加上后面 server 部分。
demo.queue().launch(share=True, inbrowser=True, server_name='0.0.0.0', server_port=7860)启动Web UI
python web_demo.py出现下面界面表明模型部署成功
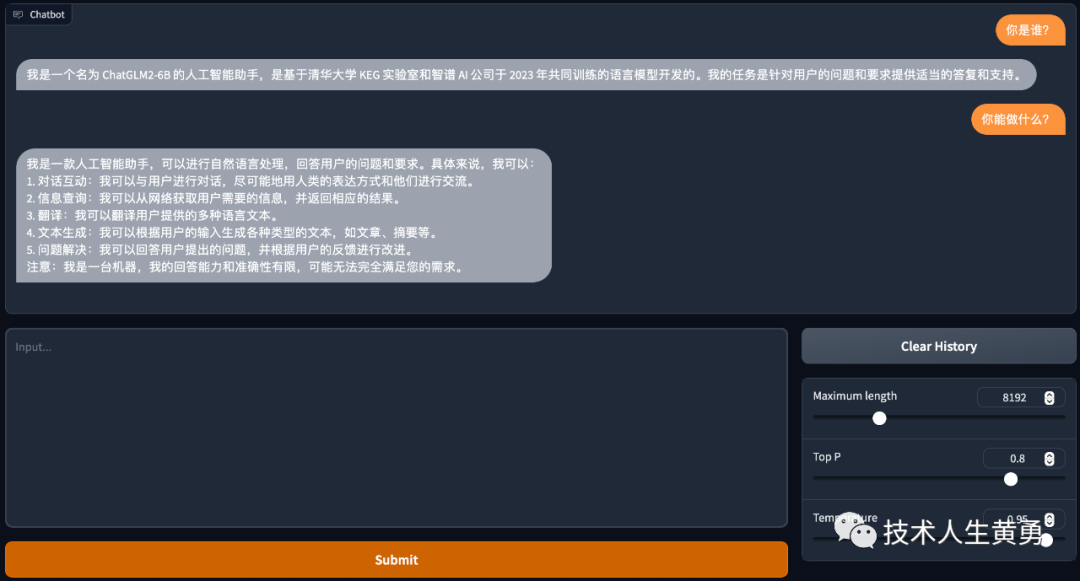
03
—
部署LangChain
模型部署安装完成后,可以将刚才启动的程序停止,开始部署 LangChain。
LangChain:是现在最流行围绕大语言模型构建的框架,可用于聊天机器人、生成式问答 (GQA)、摘要等。
如果要完成知识库的技术方案,需要一个文本向量化的模型,用户上传的知识和提问的问题,都会向量化,放在向量数据库中。搜索知识库时,大模型(这个项目采用就是ChatGLM)就会用它的推理能力将问题和知识进行向量计算匹配,最后会输出向量接近——也就是符合问题的结果。
下载源码
git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git安装依赖
cd langchain-ChatGLM
pip install -r requirements.txt下载模型
Embedding 模型
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese $PWD/text2vec照例按照上面的步骤,下载好模型,传到机器学习平台的服务器上,我放在了这个目录下:/mnt/workspace/text2vec。
修改模型地址
打开 configs/model_config.py 文件,找到参数 embedding_model_dict 修改 "text2vec" 的值为:/mnt/workspace/text2vec
找到参数 llm_model_dict 修改 "pretrained_model_name"值为: "/mnt/workspace/chatglm2-6b"。
embedding_model_dict = {
...
"text2vec-base": "shibing624/text2vec-base-chinese",
"text2vec": "/mnt/workspace/text2vec",
...
}
llm_model_dict = {
...
"chatglm2-6b": {
"name": "chatglm2-6b",
"pretrained_model_name": "/mnt/workspace/chatglm2-6b",
"local_model_path": None,
"provides": "ChatGLM"
},
...
}再确认一下模型名称
LLM_MODEL = "chatglm2-6b"确认 WebUI 界面可访问
(demo
.queue(concurrency_count=3)
.launch(server_name='0.0.0.0',
server_port=7860,
show_api=False,
share=True,
inbrowser=False))启动 WebUI
python webui.py出现这个界面就大功告成!
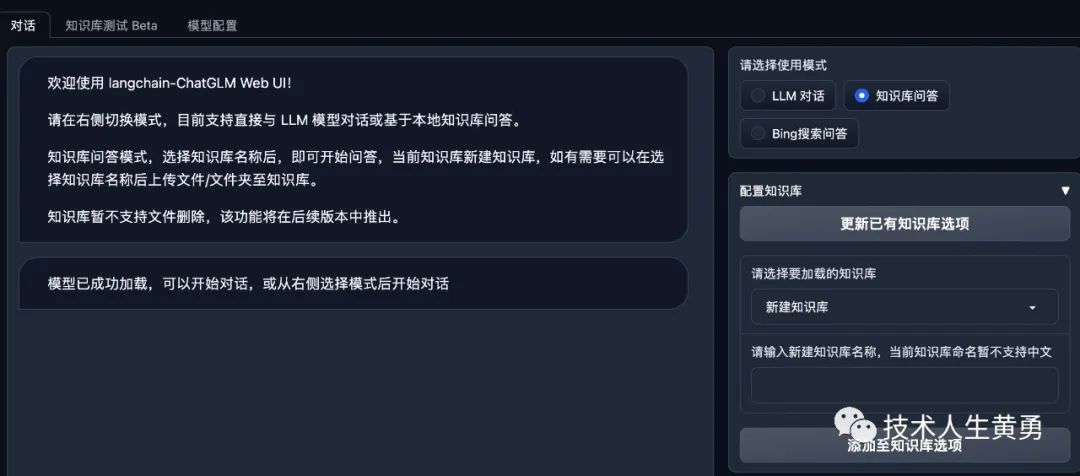
往期热门文章推荐:
工程落地实践|基于 ChatGLM2-6B + LangChain 搭建专属知识库初步完成
又一家顶级的大模型开源商用了!Meta(Facebook)的 Llama 2 搅动大模型混战的格局
Claude 2 解读 ChatGPT 4 的技术秘密:细节:参数数量、架构、基础设施、训练数据集、成本
AI人工智能大模型失守!ChatGPT、BARD、BING、Claude 相继被"提示攻击"攻陷!
拥抱未来,学习 AI 技能!关注我,免费领取 AI 学习资源。
不知不觉,已经输出 AI 技术方面的科普文章两个月了,很高兴看到有越来越多的朋友来关注我。你们的支持是我前进的动力,我会继续努力,为大家输出更多优质的内容。
让每个人都能了解 AI 技术,并将其应用到自己的工作和生活中,让AI技术变得更加普及和易用。我相信,AI技术有潜力改变世界,我希望能为这个目标贡献出自己的力量。
如果你喜欢我的文章,欢迎点击赞赏,你的支持将会激励我继续前进!

数据库是今天社会发展不可缺少的重要技术,它可以把大量的信息进行有序的存储和管理,为企业的数据处理提供了强大的保障。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)