基于Redis的简单时序数据库实现
基于Redis的时序数据库简单实现,支持数据的时序动态加载、毫秒级甚至秒级的查询。
基于Redis的简单时序数据库实现
一、背景
在我负责的一个系统中,有一个数据的同步表,每天都会同步几万的数据,一定时间下来,表已经累积了几千万的数据,这些数据实际上是十万个站址的电量统计,平常没用到觉得没什么,后面来了一个实时性较强的需求,需要通过站址号、电表号、地址编码以及时间来查询一个范围的数据,即使加了索引查询效率依然没有达到实时的要求,后来发现系统的Redis内存申请的还算大,就打算用Redis来缓存这部分数据。主要考虑数据在Redis如何存储、如何高效的加载进Redis以及如何查询等问题,因此开发了cache_timing_db。
二、设计思路
数据特点 :数据有个特点,就是一个站址号下有很多条数据,这些数据是按照天来分布的,因此可以考虑一个站址的数据就放到一个Redis的数据结构里面。
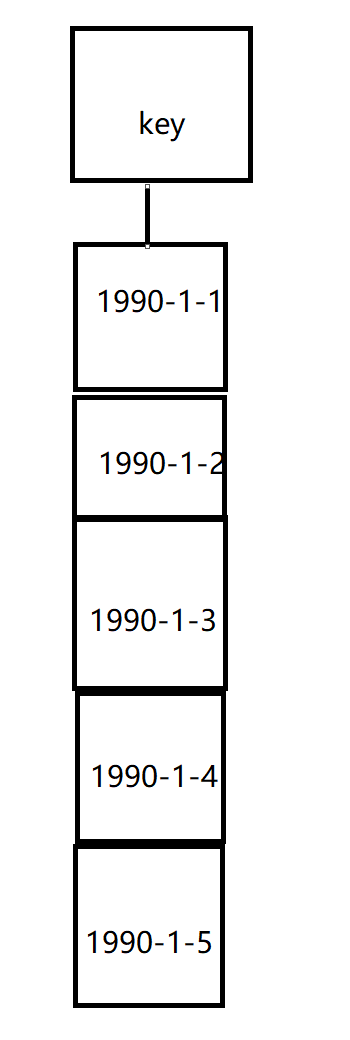
存储实现 :使用Redis的列表来实现,用户通过配置一个起始的日期时间以及一个单位偏移时间就能实现列表不同的下标存储不同时间的数据,查找时只需要知道起始时间和单位偏移就可以计算出要查找的数据的下标。当然有缺点,比如日期范围内有很多时间点没有数据就会造成存储的浪费,因为即使没有数据也需要Redis开辟一个空节点,空节点也会占用一定的内存,因此这种数据结构设计不能存储过长时间的数据。如下图:这就是一个站址号对应的每天同步的数据,我把这样的一个列表称之为一个“桶”。
序列化方式 :采用的是Protostuff作为序列化方式,相比JSON和JDK能够更加节省内存。
加载模块实现 :由于采用定时任务加载的方式,因此使用我的另一个框架AutoJob,支持错误重试,日志记录等。加载主要分为几个步骤:
首先就是初始化桶,Redis的lset命令必须要求下标在列表的长度范围内,所以必须先给桶初始化n个节点,都不放数据,初始化桶需要保证桶原来就不存在,因为通过管道的方式初始化,所以如果桶本来存在会让桶的长度变成几倍设置初始化长度。为了保证高效性,这里使用的是布隆过滤器来进行过滤,如果布隆过滤器说桶存在则可能存在,如果说不存在则一定不存在,这也会导致一个问题:在使用管道存数据时可能有的桶没有被创建,此时会出现异常,因此此时才去扫描Redis,查找不存在的桶然后创建,并且重新load这一批数据,这样布隆过滤器可以过滤出大部分(预估配置合理的情况下)key。
其次就是保存数据,保存数据主要就是利用配置的起始时间和单位偏移来计算下标,然后放入列表。
三、快速使用
1、配置
配置文件支持yml和properties,命名必须符合规范:timing-config-{configSuffix}.yml|properties。特别注意该框架依赖Spring的RedisTemplate,因此必须在application.yml等配置文件中配置Redis的相关内容。
# 应用名称,一个系统可以创建多个应用,一个应用一个名称,不得相同
applicationName: "demo"
# 数据加载器的相关配置
loader:
enable: true
cron: "20 39 16 * * ?"
# 重复次数:总执行次数=1+重复次数,-1为无限制
repeatCount: -1
# 在运行前是否清空桶,该选项主要用于出现不可逆的异常时清空桶,慎用
clearBeforeRun: false
# 如果数据加载发生异常是否进行随机测试,测试成功不会回滚
testAfterWhenError: true
# 目前使用的是Redis作为缓存,对Redis的单节点和集群的Scan实现方式不太一样,因此需要指定Redis部署类型
isCacheClustered: false
# 并发策略,建议关闭,测试多线程效率反而更低,可能是我的服务器配置低
concurrency:
enable: false
threadCount: 3
# 低耗配置,系统可能白天需要为业务保证更多的资源,提供动态资源池变化
lowPower:
# 变化cron
cron: "0 0 7 * * ?"
# 线程数
threadCount: 1
# 单批大小,加载是分页加载
batchSize: 5000
# 中断加载策略,有时我们只希望晚上运行加载,可以配置中断策略
interrupt:
# 单次最长运行时间:min,从cron指定的时间启动开始计算
maximumExecutionTime: 5000
# 单次最多加载条数
maximumExecutionSize: -1
# 本次加载默认起始ID
startID: 0
# 本次加载默认终止ID,-1表示直到最新的一条记录
endID: -1
# 布隆过滤器配置,用于过滤存在的桶
bloom:
# 预计桶的数目
expectedInsertions: 10000
# 误判率
misjudgmentRate: 0.0000001
# 桶的配置
bucket:
# 初始桶大小,如果过小会导致一些数据计算偏移超出这个值,无法存储
initialSize: 10000
# 暂时不用管
enableAlloc: true
# 桶过期时间:天
expiringTime: 10000
# 偏移配置
handler:
# 默认起始偏移,yyyy-MM-dd格式
defaultStartOffset: "1990-1-1"
# 默认单位偏移:毫秒
defaultUnitOffset: 86400000
2、定义存储实体
框架需要两个关键实体对象,一个是从DB查询出来的时序实体对象,必须实现TimeSeriesData接口,如下示列:
/**
* 测试数据实体,实现TimeSeriesData接口表名该类是一个时序数据
*
* @author JingGe(* ^ ▽ ^ *)
* @date 2023-07-17 15:11
* @email 1158055613@qq.com
*/
@Getter
@Setter
public class TimingDataEntity implements TimeSeriesData {
private Long id;
private String data1;
private Integer data2;
private String selectKey1;
private String selectKey2;
private Date createTime;
@Override
public long id() {
return id;
}
@Override
public long timestamp() {
if (createTime == null) {
return -1;
}
return createTime.getTime();
}
@Override
public String key() {
//返回该时序数据的查询key,该key会作为缓存的key
return selectKey1 + "_" + selectKey2;
}
@Override
public CacheData storeValue() {
//返回该实体要存到Redis中的数据
return new TimingDataEntityCacheData(data1, data2, createTime);
}
}
其次是加载进Redis的实例对象,必须实现CacheData接口,这个对象的定义直接决定序列化后的内存大小,因此字段类型要好好斟酌。
/**
* 要存入缓存的对象实体,实现CacheData接口
*
* @author JingGe(* ^ ▽ ^ *)
* @date 2023-07-17 15:26
* @email 1158055613@qq.com
*/
@Getter
@Setter
public class TimingDataEntityCacheData implements CacheData {
private String data1;
private String data2;
private String createTime;
public TimingDataEntityCacheData(String data1, Integer data2, Date createTime) {
this.data1 = data1;
this.data2 = data2 + "";
if (createTime != null) {
this.createTime = DateUtils.formatDateTime(createTime);
}
}
}
3、定义DB存储库
由于不知道客户端使用的是何种数据库,因此时序实体对象的查询需要用户自己定义,必须实现接口DBRepository的query方法,loader会自动调用查询数据加载到缓存
public class TimingDataEntityRepository implements DBRepository<TimingDataEntity> {
@Override
public List<TimingDataEntity> query(Map<String, Object> params, int batchNum, int batchSize, long startID, long endID) {
Optional<TimingDataEntityMapper> mapper = SpringUtil.getBeanOptional(TimingDataEntityMapper.class);
List<TimingDataEntity> res = new ArrayList<>();
mapper.ifPresent(mp -> res.addAll(mp.selectPaged(startID, endID, (batchNum - 1) * batchSize, batchSize)));
return res;
}
/**
* 保存方法暂时无需实现
*
* @param seriesData 要保存的数据
* @return int
* @author JingGe(* ^ ▽ ^ *)
* @date 2023/7/17 15:32
*/
@Override
public int save(List<TimingDataEntity> seriesData) {
return 0;
}
}
4、启动应用
在配置和定义好相关对象后可以通过对象TimingFinderBootstrap来构建和启动应用,如下是一个示列:
@Component
public class TimingDBRunner implements SpringStartProcessor {
@Override
public void onStart() {
TimingFinderApplication<TimingDataEntity> application = new TimingFinderBootstrap<>(new TimingDataEntityRepository(), new HandleType(TimingDataEntity.class, TimingDataEntityCacheData.class))
.setConfigSuffix("demo")
.build()
.run();
//可以从应用中获取Finder
TimeSeriesDataFinder<TimingDataEntity> finder = application.getTimeSeriesDataFinder();
//也可以通过配置文件新建Finder
TimeSeriesDataFinder<TimingDataEntity> finder2 = new TimeSeriesDataFinder<>("demo");
}
}
启动后应用会根据配置的cron表达式来定时启动,整个加载过程的日志可以在表aj_jog_logs找到,即AutoJob的调度日志里面。
5、查询
查询是通过TimeSeriesDataFinder来实现,TimeSeriesDataFinder对象的获取在第四点示列里有。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)