stata u8笔记
u8notes@用Stata进行量化分析
第八章扩展命令集
8.1 Stata帮助文件
PDF Documentation(PDF文件)选项
包括:帮助文件,FAQs(常见问题),示例,与Stata相关论文。
(一)
①点击Stata主窗口上方的Help菜单按钮→PDF Documentation(PDF文件)选项。
②排序方式:按主题组织→按操作命令名称的字母顺序。
(二)
①Help→Contents
②eg.Statistics→Binary Outcome
(三)
①Help→Search→输入主题
(四)
命令help
Eg.help corr或help pearson
以命令corr为例:
①布局:
Title主题
Syntax语法
Options选项
简要:操作命令的一些限制Eg.是否可以使用前缀命令by
Eg.在本例中,可以看到两个命令都可以使用前缀命令by
varlist:可以输入的变量列表(newvar:新变量名,varname现有变量名,depvar因变量名)
=exp:例如命令gen:要求输入新的变量名后一个表达式。
#:数字。eg.命令level(#)
【】:可选项,非必须输入的内容(可参考命令corr)
·行:可以在command window输入的命令。
②字体:
粗体:命令名称及其选项
带下划线:最短缩写
·命令correlate:cor
·选项mean:m
斜体:必须“填写”(不是说将斜体字的内容直接复制到命令行,是必须输入内容的说明)
③颜色:
蓝色:可以点开
| 语言或代码language or code | 解释interpretation | 例子example |
| varname | 数据集中的变量名 | ·tab employst |
| varlist | 数据集中的变量列表 | ·corr workhrs totacts marrymin |
| newvar | 新的变量名 | ·gen agep16=agecats-16 |
| indepvars | 数据集中的解释变量 | ·reg workhrs totacts marrymin |
| depvar | 数据集中的被解释变量 | ·reg workhrs totacts marrymin |
④计算机必须联网,才能利用webuse命令打开对应的数据集。
⑤使用命令syuse打开的数据集,不用联网。
8.2高级的便捷命令
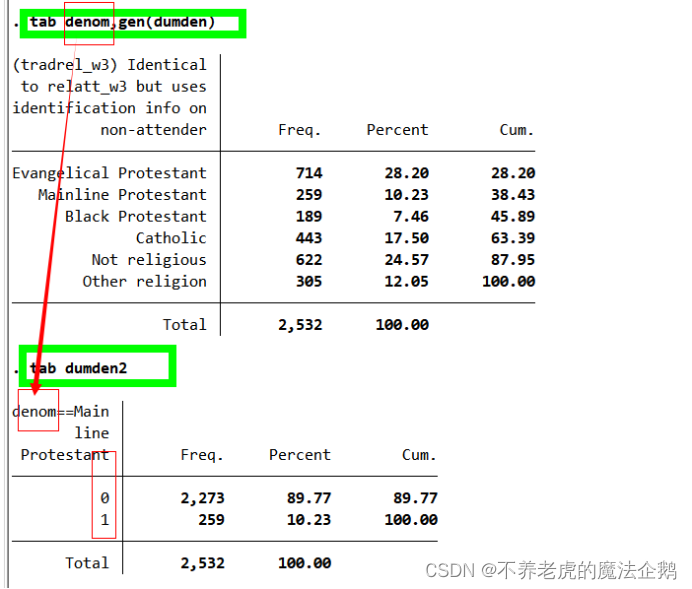
·tab,gen(newvar)
①命令tab产生频数分布和列联表
②选项gen(newvarstub)
③tab命令后使用选项gen(newvarstub):这个选项会自动地为tab命令后的变量生成取值为0和1的二元变量。
④数字表示该类变量在原始定性变量中的顺序。
Eg.在本例中那个要生成6个变量
·tab dumden1 dumden2 dumden3 dumden4 dumden5 dumden6
在command window输入(→[enter]):
tab denom,gen(dumden)
tab dumden2
⑤结果显示这是一个表示宗教信仰是否是主流新教Mainline Protestant的二元变量。有259个样本取值为1,其它取值为0。变量名是dumden2,因为Mainline Protestant是变量denom的第二类。
⑥列表左上角显示的变量标签,有助于明确该变量所代表的分类,以及它是从哪个变量派生出来的。
⑦这个快捷命令可以使用命令gen和命令replace组合生成6个二元变量。
通配符
①最常用:*。
Eg.在command window输入(→[enter]):
tab1 dumden*
Or·tab1 dumd*



②通配符*也可以在变量词根的前面或中间使用:
Eg.denonevar,dentwovar,denthreevar
在command window输入(→[enter]):
tab1 den*var
·egen
区别
①在命令gen中,用户需要再“=”后输入某种类型的表达式
②命令egen有一些内置函数
基本形式:egen newvar=fcn(arguments) [if] [,options]
①fcn:某个函数
②arguments:该函数的参数
在command window输入(→[enter]):
help egen
将定序-定比变量作为定序变量处理
Eg.变量bmi有太多分类,因此可以使用命令recode生成一个更为简洁的变量,但是egen中有一个专门的函数可以实现这个目的:
①函数cut可以在某个取值点处切割变量,也可以将变量的取值分成若干个组。
②选项at(#,#,#,…,#)+①:执行①第一个程序——切割
③选项group(#)+①:执行①第二个程序——分组
将变量bmi压缩成10类定序变量:
在command window输入(→[enter]):
egen ordbmi=cut(bmi),group(10)
tab ordbmi

这些分组基本上是等分的(约为10%)
当具有缺失值时,命令egen比命令gen更有效
①Eg.求(marrymin+marrymax)/2时,gen无法计算缺失值
②函数rowmean:生成均值变量的另一种快捷方法,以及大多数行函数,都会自动忽略缺失值:当某一样本的marrymax缺失时,stata会自动只使用变量marrymin计算这一样本的均值,即用marrymin除以1。
除非某样本的两个变量都缺失,则生成的新变量中该样本也是缺失的。
在command window输入(→[enter]):
egen idlmarry=rowmean(marrymin marrymax)
br
br marrymin marrymax idlmarry
【注】命令br有选择性
mark和markout
更有效地识别
①最初对变量workhrs使用命令sum的分析结果显示,2527格言各奔被用于计算集中趋势和度量波动性,有5个样本的值缺失。如果想限定值使用2455个有效样本执行命令sum,可以在命令窗口输入:
sum workhr if totacts<. &marrymin<. &currdate<.

②stata将缺失值视为最大值,因此if语句中的“<.”只是stata对有效响应的样本进行分析。
③基本结构:
mark newvar
markout markvar varlist
④第一个命令mark,生成了一个变量newvar,该变量用于识别样本,此时数据集中的每个样本都赋值为1。
第二个命令markout可以用来指定在最终分析中包括的变量,命令markout自动地对命令mark生成的新变量重新赋值,如果列出的变量中有任意一个有缺失,该样本就被重新赋值为0。
在command window输入(→[enter]):
mark nomiss
markout nomiss workhrs totacts marrymin currdate
tab nomiss

⑤使用命令④的原因:比命令①方便:现在可以将命令①荣昌的sum命令改写为:
在command window输入(→[enter]):
sum workhr if nomiss==1
此后如果在分析中改变条件/增加或删除有条件的变量
①删除当前momiss变量
②相应地生成新变量
③修改命令markout后的变量(即原来的“if<.”条件)
·alpha,gen(newvar)
①两个有用的函数:
第一个是计算分析中常用的一个统计量:Cronbach’s alpha。
第二个可以根据Cronbach’s alpha计算时使用的变量集创建一个指数变量。
help alpha //help cronbach不行
②Cronbach’s alpha(简称alpha)是一个统计量,用来评估一组变量“结合”得有多好。
③alpha该系数通常用于确定一组变量是否可以有效地综合为一个指数或者一种度量。其取值在0到1之间,越接近1,表明这些变量越相关,能综合成一个有效指数。
Eg.计算变量alpha值
NSYR数据集包括3根问题可以测量自我价值的基本概念:通常你多久有下述的几种感觉?(1)感觉到被关爱和被接受;(2)感觉孤独和被误解;(3)别人不在意你,而感觉被忽视。
每个问题有4个回答选项,从“完全没有”到“经常”,三个问题对应的变量名分别为accepted、alienate、invisible。
②Average interitem covariance:变量之间的平均协方差
Number of items in the scale: 量表中变量的个数
Scale reliability coefficient: 度量的信度系数,即alpha值。
③在command window输入(→[enter]):
alpha accepted alienate invisibl

④Alpha值=0.6252:表明三个变量是适度相关的。不是强相关,因为0.5<适度相关<0.75。
⑤在这个例子中,三个变量都是自我价值的度量,这三个变量均被“反向编码”,使得“经常”对应最低级别的值,而“完全没有”对应最高级别
【注】有快速修复此问题的方法,请参见本章末尾。
⑥变量accepted的最大值(即受访者“完全没有”感受到被接受)意味着低自我价值感。然而,对变量alienate和invisibl而言,最大值意味着高自我价值感(即受访者没有感觉被疏远和忽视)。
因此,要么对变量accepted反向调整,要么对变量alienate和invisibl反向调整。使得这些变量的度量方向一致。
当使用gen(newvar)选项时,这种自动进行的反向调整特别有用。
(承上例)
①Stata在计算平均值之前会自动地反向调整必要的变量值,确保生成正确的指数变量(index variable)。
②新的指数的值越高,说明自我价值感越高。
③在command window输入(→[enter]):
alpha accepted alienate invisibl,gen(worth)

④显示的结果与上面相同,但在变量窗口会出现一个新的指数变量worth。
【注】如果有疑问,可以把它和原始变量一起进行相关分析:
在command window输入(→[enter]):
corr accepted alienate invisibl worth

根据指数变量和原始变量相关系数的方向(正或负),就能看出指数变量较大的值意味着什么。
缺失值的两种结果处理:
①alpha,gen(newvar)中生成新变量:对于每个样本,如果它至少在一个变量上有有效的响应,那么生成新变量时这个样本就会被赋值。
即平均值是基于每个样本有效响应变量的个数来计算的。
Eg.如果某个样本在变量alienate上的值是缺失的,那么该样本对应的变量worth的值是将变量accepted和invisibl值相加并除以2得到的,而不是除以3。
②选项casewise:如果你希望在新生成的变量中,只要有缺失值的样本,都将其新变量的值设置为缺失,那么可以调用选项casewise来实现。
8.3扩展stata功能
虽然stata并不是一个开源代码软件,但是stata允许开源代码增加并增强它的功能。Stata用户可以自己编写程序发布给其他用户,并提供程序下载。
pearson相关系数:
①是定距-定比变量相关性最常见的一种度量。
②不能完全准确地测量两个定序变量之间,或者有有限分类的定距-定比变量之间的相关性。
在command window输入(→[enter]):
corr accepted numfrien
③结果表明,两个变量呈弱负相关关系(-0.1161),表明年轻人的朋友越多,“自我感觉被接受程度”越高。
④这种解释感觉和相关系数给出的方向不一致,因为变量accepted的取值方向是反向的,即值越小表明“自我感觉被接受程度”越高(从频率分布表可知)。
⑤因此根据④这一编码顺序,负相关表明有更多的朋友,意味着更高的自我认同。
多分隔相关polychoric correlation系数:
另一种相关系数,用于度量游戏按分类的变量之间的相关性。(vs pearson系数)
polychoric 安装方法:
①在command window输入(→[enter]):
help polychoric
②单击“polychoric from…”
③这个程序包有六个不同的文件:
前4个是程序文件,扩展名是.ado。
.ado和.do扩展名是相似的,但是“ado”文件可以直接添加到stata中,作为程序或者命令来运行。
最后2个文件是帮助文件,扩展名是.hlp。
④点击链接“click here to install”
⑤安装在特定的位置
相关系数对比corr VS polychoric
①如果只计算2个变量的相关系数,命令polychoric和命令corr的输出结果会略有不同。
②如果计算3个或更多变量的相关系数,两者的输出结果非常接近。
③Rho值与相关系数相似,表明相关系数polychoric比相关系数corr更强一些(分别为-0.1587和-0.1106)。
添加资源的方法:
①波士顿学院统计软件组件档案:Boston College Statistics Software Components Archive
Statistical Software Components, Boston College Department of Economics | IDEAS/RePEc
这里储存了很多用户编写的程序。
网站简写:ssc
②Stata网站的Statalist讨论区:
www.stata.com
用户可以在Statalist上发布问题、回答问题、发布编写的程序
(一)Stata网站的搜索窗口→跳转到Statalist
(二)Support→点击Statalist
u8notes@用Stata进行量化分析

为开发者提供自动驾驶技术分享交流、实践成长、工具资源等,帮助开发者快速掌握自动驾驶技术。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)