DeepLabv3+复现以及训练自己代码
DeepLabv3+的Encoder的主体是带有空洞卷积的DCNN,可以采用常用的分类网络如ResNet,然后是带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP)),主要是为了引入多尺度信息;在训练voc数据集时,直接将数据集放置于VOCdevkit中即可,在训练自己数据时,需要运行voc_annotation.py文件,将数据按照训练-验
DeepLabv3+的Encoder的主体是带有空洞卷积的DCNN,可以采用常用的分类网络如ResNet,然后是带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling, ASPP)),主要是为了引入多尺度信息;相比DeepLabv3,v3+引入了Decoder模块,其将底层特征与高层特征进一步融合,提升分割边界准确度。
参考代码地址:GitHub - bubbliiiing/deeplabv3-plus-pytorch: 这是一个deeplabv3-plus-pytorch的源码,可以用于训练自己的模型。
本人是基于实验室服务器进行复现的,CUDA版本为11.4。
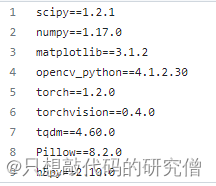
将代码Git下来之后,首先按照requirement将所需库配置完成。
在训练voc数据集时,直接将数据集放置于VOCdevkit中即可,在训练自己数据时,需要运行voc_annotation.py文件,将数据按照训练-验证-测试集分配并将标签另存。
在进行训练之前需要将参数设置好,其中较重的参数有backbone、num_classes、pretrained、model_path、downsample_factor,还有冻结训练以及非冻结训练过程中的bathsize和epoch。不同参数的意义如下:
#-----------------------------------------------------#
# num_classes 训练自己的数据集必须要修改的
# 自己需要的分类个数+1,如2+1
#-----------------------------------------------------#
num_classes = 21
#---------------------------------#
# 所使用的的主干网络:
# mobilenet
# xception
#---------------------------------#
backbone = "mobilenet"
#----------------------------------------------------------------------------------------------------------------------------#
# pretrained 是否使用主干网络的预训练权重,此处使用的是主干的权重,因此是在模型构建的时候进行加载的。
# 如果设置了model_path,则主干的权值无需加载,pretrained的值无意义。
# 如果不设置model_path,pretrained = True,此时仅加载主干开始训练。
# 如果不设置model_path,pretrained = False,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#----------------------------------------------------------------------------------------------------------------------------#
pretrained = False
#----------------------------------------------------------------------------------------------------------------------------#
# 权值文件的下载请看README,可以通过网盘下载。模型的 预训练权重 对不同数据集是通用的,因为特征是通用的。
# 模型的 预训练权重 比较重要的部分是 主干特征提取网络的权值部分,用于进行特征提取。
# 预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好
# 训练自己的数据集时提示维度不匹配正常,预测的东西都不一样了自然维度不匹配
#
# 如果训练过程中存在中断训练的操作,可以将model_path设置成logs文件夹下的权值文件,将已经训练了一部分的权值再次载入。
# 同时修改下方的 冻结阶段 或者 解冻阶段 的参数,来保证模型epoch的连续性。
#
# 当model_path = ''的时候不加载整个模型的权值。
#
# 此处使用的是整个模型的权重,因此是在train.py进行加载的,pretrain不影响此处的权值加载。
# 如果想要让模型从主干的预训练权值开始训练,则设置model_path = '',pretrain = True,此时仅加载主干。
# 如果想要让模型从0开始训练,则设置model_path = '',pretrain = Fasle,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#
# 一般来讲,网络从0开始的训练效果会很差,因为权值太过随机,特征提取效果不明显,因此非常、非常、非常不建议大家从0开始训练!
# 如果一定要从0开始,可以了解imagenet数据集,首先训练分类模型,获得网络的主干部分权值,分类模型的 主干部分 和该模型通用,基于此进行训练。
#----------------------------------------------------------------------------------------------------------------------------#
model_path = "model_data/deeplab_mobilenetv2.pth"
#---------------------------------------------------------#
# downsample_factor 下采样的倍数8、16
# 8下采样的倍数较小、理论上效果更好。
# 但也要求更大的显存
#---------------------------------------------------------#
downsample_factor = 16
#------------------------------#
# 输入图片的大小
#------------------------------#
input_shape = [512, 512]
#----------------------------------------------------------------------------------------------------------------------------#
# 训练分为两个阶段,分别是冻结阶段和解冻阶段。设置冻结阶段是为了满足机器性能不足的同学的训练需求。
# 冻结训练需要的显存较小,显卡非常差的情况下,可设置Freeze_Epoch等于UnFreeze_Epoch,此时仅仅进行冻结训练。
#
# 在此提供若干参数设置建议,各位训练者根据自己的需求进行灵活调整:
# (一)从整个模型的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 5e-4,weight_decay = 0。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 5e-4,weight_decay = 0。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 7e-3,weight_decay = 1e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 7e-3,weight_decay = 1e-4。(不冻结)
# 其中:UnFreeze_Epoch可以在100-300之间调整。
# (二)从主干网络的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 5e-4,weight_decay = 0。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 5e-4,weight_decay = 0。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 120,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 7e-3,weight_decay = 1e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 120,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 7e-3,weight_decay = 1e-4。(不冻结)
# 其中:由于从主干网络的预训练权重开始训练,主干的权值不一定适合语义分割,需要更多的训练跳出局部最优解。
# UnFreeze_Epoch可以在120-300之间调整。
# Adam相较于SGD收敛的快一些。因此UnFreeze_Epoch理论上可以小一点,但依然推荐更多的Epoch。
# (三)batch_size的设置:
# 在显卡能够接受的范围内,以大为好。显存不足与数据集大小无关,提示显存不足(OOM或者CUDA out of memory)请调小batch_size。
# 受到BatchNorm层影响,batch_size最小为2,不能为1。
# 正常情况下Freeze_batch_size建议为Unfreeze_batch_size的1-2倍。不建议设置的差距过大,因为关系到学习率的自动调整。
#----------------------------------------------------------------------------------------------------------------------------#
#------------------------------------------------------------------#
# 冻结阶段训练参数
# 此时模型的主干被冻结了,特征提取网络不发生改变
# 占用的显存较小,仅对网络进行微调
# Init_Epoch 模型当前开始的训练世代,其值可以大于Freeze_Epoch,如设置:
# Init_Epoch = 60、Freeze_Epoch = 50、UnFreeze_Epoch = 100
# 会跳过冻结阶段,直接从60代开始,并调整对应的学习率。
# (断点续练时使用)
# Freeze_Epoch 模型冻结训练的Freeze_Epoch
# (当Freeze_Train=False时失效)
# Freeze_batch_size 模型冻结训练的batch_size
# (当Freeze_Train=False时失效)
#------------------------------------------------------------------#
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 8
#------------------------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
# UnFreeze_Epoch 模型总共训练的epoch
# Unfreeze_batch_size 模型在解冻后的batch_size
#------------------------------------------------------------------#
UnFreeze_Epoch = 100
Unfreeze_batch_size = 4
#------------------------------------------------------------------#
# Freeze_Train 是否进行冻结训练
# 默认先冻结主干训练后解冻训练。
#------------------------------------------------------------------#
Freeze_Train = True

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)