
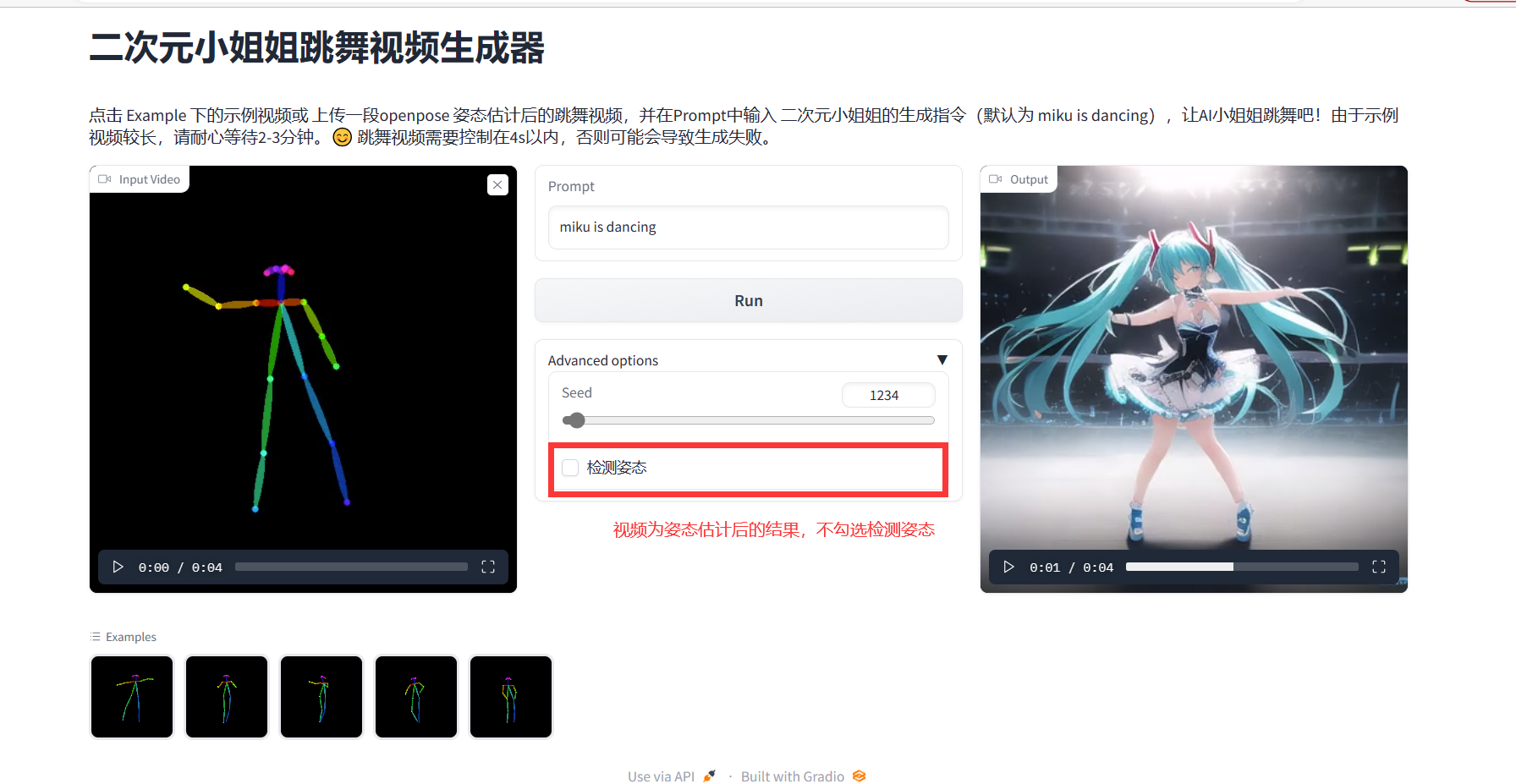
【AI视频】二次元小姐姐跳舞视频生成器
点击 Example 下的示例视频或 上传一段openpose 姿态估计后的跳舞视频,并在Prompt中输入 二次元小姐姐的生成指令(默认为 miku is dancing),让AI小姐姐跳舞吧!
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、项目介绍
输入 一段 跳舞视频,并在Prompt中输入 二次元小姐姐的生成指令,生成AI小姐姐跳舞视频
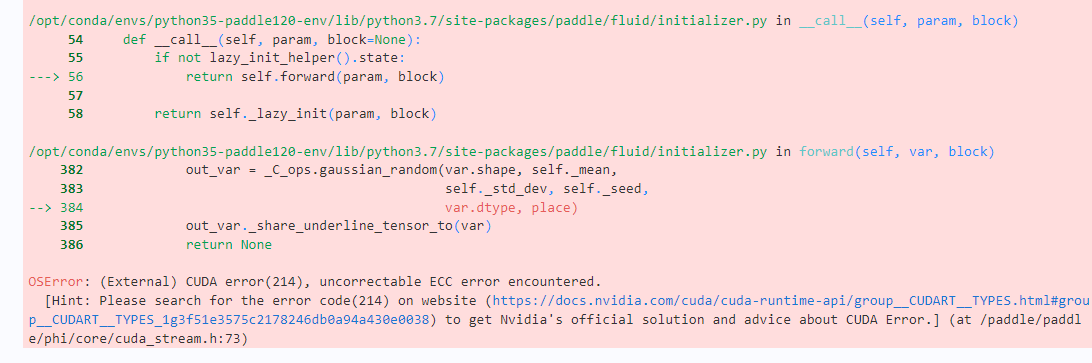
AI Studio 有部分GPU 会出现上述问题。如果刚好被分配到这种 GPU,建议关闭项目后,等待一段时间,重新启动GPU,最好选择V100 32G 显存,16G显存出现该问题的可能性较大
二、详细说明
2.1 环境配置
由于该项目需要调用 PaddleNLP 的 文本-图像生成模型,因此需要安装 ppdiffusers 等相关库。此外,由于模型文件过大,两个模型加在一起约 6 G 左右,每次启动项目都要下载十分耗时,因此,这里将 sd-controlnet-openpose 、 MoososCap/NOVEL-MODEL 权重文件 保存在 AI studio 数据集中,第一次运行项目,需要将上述权重文件解压到 AI Studio 本地路径,之后,可以直接从本地加载 sd-controlnet-openpose 和 MoososCap/NOVEL-MODEL 文本-图像生成模型。
!pip install --user ftfy regex
# 由于pddiffuser更新后与项目不兼容,这里指定 ppdiffusers==0.14.0 版本安装
!pip install --user ppdiffusers==0.14.0
!pip install --user scikit-image
# 安装decode,以便进行视频读取
!pip install --user decord
# 安装 omegaconf,以便读取配置文件
!pip install --user omegaconf
# 安装moviepy用于将 MP4 文件转化为 gif 文件显示
!pip install moviepy
# 解压文本-图像编辑模型 sd-controlnet-openpose,该过程耗时2-3分钟左右,由于文本-图像类模型文件过大,这里使用AI Studio本地目录加载模型
# 该过程只需解压一次即可
%cd /home/aistudio/
!unzip /home/aistudio/data/data224144/lllyasviel.zip
# 解压文本-图像编辑模型 MoososCap/NOVEL-MODEL,该过程耗时2-3分钟左右,由于文本-图像类模型文件过大,这里使用AI Studio本地目录加载模型
# 该过程只需解压一次即可
%cd /home/aistudio/
!unzip /home/aistudio/data/data224144/novel.zip
由于新安装的依赖库不会同步更新到 notebook 中,此处需要先重启内核,再运行 2.2 之后的代码,否则会报错“找不到 ppdiffusers 环境”,其他找不到环境问题一般可以通过加入 --user 重新安装或者重启内核解决
2.2 利用 openpose 检测后的姿态估计视频生成跳舞视频
# 切换到Text2Video-Zero_paddle目录下
%cd /home/aistudio/work/Text2Video-Zero_paddle/
# 导入相关包
from model import Model
import paddle
import warnings
warnings.filterwarnings("ignore")
import logging
import os
import argparse
# 屏蔽ppdiffusers运行过程中所产生的日志
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = '0'
/home/aistudio/work/Text2Video-Zero_paddle
W0625 17:48:24.235563 30580 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.7
W0625 17:48:24.240814 30580 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
W0625 17:48:24.240860 30580 gpu_resources.cc:117] WARNING: device: 0. The installed Paddle is compiled with CUDA 11.7, but CUDA runtime version in your machine is 11.2, which may cause serious incompatible bug. Please recompile or reinstall Paddle with compatible CUDA version.
load pretrained checkpoint success
load pretrained checkpoint success
# 进行模型初始化
model = Model(device = "cuda", dtype = paddle.float16)
# 设置随机种子
seed = 1234
# 设置文本提示词
prompt = "miku is dancing"
# 姿态引导视频路径
motion_video_path = '__assets__/dance1_corr.mp4'
# 设置生成视频输出目录
output_dir = "/home/aistudio/work/Text2Video-Zero_paddle/output"
# 设置视频的保存格式,包含:gif 和 mp4 两种
save_format = "gif"
out_path = '{}/{}.{}'.format(output_dir,'test',save_format)
# 设置 MoososCap/NOVEL-MODEL和 controlNet 在AI Studio中的本地路径
stable_diffision_path="/home/aistudio/novel_model/MoososCap/NOVEL-MODEL"
controlnet_path="/home/aistudio/lllyasviel/sd-controlnet-openpose"
# 使用 controlnet_pose 模型生成姿态引导的文本视频, 需要显存 13.4G,耗时2-3分钟
model.process_controlnet_pose( motion_video_path, prompt=prompt, save_path=out_path,save_format=save_format,\
is_detect_pose = False,chunk_size= 12, resolution=384,seed=seed,model_path_list=[stable_diffision_path,controlnet_path])
Module Pose
/home/aistudio/novel_model/MoososCap/NOVEL-MODEL id
Processing chunk 1 / 2
W0625 17:48:51.271497 30580 gpu_resources.cc:217] WARNING: device: . The installed Paddle is compiled with CUDNN 8.4, but CUDNN version in your machine is 8.2, which may cause serious incompatible bug. Please recompile or reinstall Paddle with compatible CUDNN version.
0%| | 0/20 [00:00<?, ?it/s]
Processing chunk 2 / 2
0%| | 0/20 [00:00<?, ?it/s]
from IPython.display import Image
# 文本-视频生成结果可视化
Image(filename=out_path)
<IPython.core.display.Image object>
由于notebook 不会自动释放显存,如果显存不足,需要重启内核,再运行2.3 代码块
2.3 利用原视频生成跳舞视频
# 切换到Text2Video-Zero_paddle目录下
%cd /home/aistudio/work/Text2Video-Zero_paddle/
# 导入相关包
from model import Model
import paddle
import warnings
warnings.filterwarnings("ignore")
import logging
import os
import argparse
# 屏蔽ppdiffusers运行过程中所产生的日志
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = '0'
/home/aistudio/work/Text2Video-Zero_paddle
W0625 17:49:37.593441 31009 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.7
W0625 17:49:37.598455 31009 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
W0625 17:49:37.598502 31009 gpu_resources.cc:117] WARNING: device: 0. The installed Paddle is compiled with CUDA 11.7, but CUDA runtime version in your machine is 11.2, which may cause serious incompatible bug. Please recompile or reinstall Paddle with compatible CUDA version.
load pretrained checkpoint success
load pretrained checkpoint success
# 进行模型初始化
model = Model(device = "cuda", dtype = paddle.float16)
# 设置随机种子
seed = 1234
# 设置文本提示词
prompt = "Hanfu (traditional Chinese woman is dancing and looking at the viewer"
# 姿态引导视频路径
motion_video_path = '__assets__/dance.mp4'
# 设置生成视频输出目录
output_dir = "/home/aistudio/work/Text2Video-Zero_paddle/output"
# 设置视频的保存格式,包含:gif 和 mp4 两种
save_format = "gif"
out_path = '{}/{}.{}'.format(output_dir,'test',save_format)
# 设置 MoososCap/NOVEL-MODEL 和 controlNet 在AI Studio中的本地路径
stable_diffision_path="/home/aistudio/novel_model/MoososCap/NOVEL-MODEL"
controlnet_path="/home/aistudio/lllyasviel/sd-controlnet-openpose"
# 使用 controlnet_pose 模型生成姿态引导的文本视频, 需要显存 13.4G,耗时2-3分钟
model.process_controlnet_pose( motion_video_path, prompt=prompt, save_path=out_path,save_format=save_format,\
is_detect_pose = True,chunk_size= 12, resolution=384,seed=seed,model_path_list=[stable_diffision_path,controlnet_path])
Module Pose
/home/aistudio/novel_model/MoososCap/NOVEL-MODEL id
W0625 17:50:24.019990 31009 gpu_resources.cc:217] WARNING: device: . The installed Paddle is compiled with CUDNN 8.4, but CUDNN version in your machine is 8.2, which may cause serious incompatible bug. Please recompile or reinstall Paddle with compatible CUDNN version.
Processing chunk 1 / 2
0%| | 0/20 [00:00<?, ?it/s]
Processing chunk 2 / 2
rocessing chunk 2 / 2
0%| | 0/20 [00:00<?, ?it/s]
from IPython.display import Image
# 文本-视频生成结果可视化
Image(filename=out_path)
<IPython.core.display.Image object>
由于notebook 不会自动释放显存,如果显存不足,需要重启内核,再启动 Gradio 页面,否则会导致启动失败
三、Gradio 界面
Gradio 页面位于/home/aistudio/gradio_ui 目录下,部署文件位于 /home/aistudio/gradio_package 目录下,Gradio页面启动前,需要确保 2.1-2.3 运行正常。具体操作过程如下:
点击 miki_dance_local.gradio.py ,如果项目没有正常启动,点击运行,待页面加载完毕,点击在浏览器打开,之后,便可以开始生成跳舞视频了。 近期由于大模型比赛的原因,部署应用的人比较多,gradio预览时好时坏,如果加载不出来,建议等一段时间再启动


四、总结
该项目基于 Text2Video-Zero 中姿态引导的文本-视频生成模块实现了二次元小姐姐跳舞视频生成,并提供了notebook命令行和 gradio 页面两种运行方式。由于部署环境限制,在线体验存在时长限制,感兴趣的小伙伴可以把项目 fork 到本地运行。项目后期可能还会更新,可以点击 ❤ ,以便实时关注项目动态。
参考项目:
【1】 Text2Video-Zero
【2】 Tune-A-Video
【3】 PPDiffusers: Diffusers toolbox implemented based on PaddlePaddle
【5】 【大模型专区】Text2Video-Zero—零样本文本到视频生成(下)
【6】 PPdiffusers从DreamBooth(+Lora)训练到应用发布全套流程
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 0
0 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)