多头自注意力机制脑电情绪识别:论文精读
文章题目:EEG-Based Emotion Recognition Using Convolutional Recurrent Neural Network with Multi-Head Self-AttentionAbstract: In recent years, deep learning has been widely used in emotion recognition, but
文章题目:EEG-Based Emotion Recognition Using Convolutional Recurrent Neural Network with Multi-Head Self-Attention
Abstract: In recent years, deep learning has been widely used in emotion recognition, but the models and algorithms in practical applications still have much room for improvement. With the development of graph convolutional neural networks, new ideas for emotional recognition based on EEG have arisen. In this paper, we propose a novel deep learning model-based emotion recognition method. First, the EEG signal is spatially filtered by using the common spatial pattern (CSP), and the filtered signal is converted into a time–frequency map by continuous wavelet transform (CWT).This is used as the input data of the network; then the feature extraction and classification are performed by the deep learning model. We called this model CNN-BiLSTM-MHSA, which consists of a convolutional neural network (CNN), bi-directional long and short-term memory network (BiLSTM), and multi-head self-attention (MHSA). This network is capable of learning the time series and spatial information of EEG emotion signals in depth, smoothing EEG signals and extracting deep features with CNN, learning emotion information of future and past time series with BiLSTM, and improving recognition accuracy with MHSA by reassigning weights to emotion features. Finally , we conducted experiments on the DEAP dataset for sentiment classification, and the experimental results showed that the method has better results than the existing classification. The accuracy of high and low valence, arousal, dominance, and liking state recognition is 98.10%, and the accuracy of four classifications of high and low valence-arousal recognition is 89.33%.
摘要:近年来,深度学习在情绪识别中得到了广泛的应用,但实际应用中的模型和算法仍有很大的改进空间。随着图卷积神经网络的发展,基于脑电图的情绪识别出现了新的思路。在本文中,我们提出了一种新的基于深度学习模型的情感识别方法。首先,利用共空间模式(CSP)对脑电信号进行空间滤波,并通过连续小波变换(CWT)将滤波后的信号转换成时频图;这被用作网络的输入数据;然后利用深度学习模型进行特征提取和分类。我们将该模型命名为CNN-BiLSTM-MHSA,该模型由卷积神经网络(CNN)、双向长短期记忆网络(BiLSTM)和多头自注意(MHSA)组成。该网络能够深度学习脑电情绪信号的时间序列和空间信息,利用CNN对脑电信号进行平滑处理并提取深度特征,利用BiLSTM学习未来和过去时间序列的情绪信息,利用MHSA对情绪特征重新分配权重来提高识别精度。最后,我们在情感分类的DEAP数据集上进行了实验,实验结果表明该方法比现有的分类有更好的效果。高低效价、唤醒度、优势度、喜欢度状态识别的正确率为98.10 %,高低效价-唤醒度四分类的正确率为89.33 %。
 https://blog.csdn.net/sxn0121/article/details/130901448?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22130901448%22%2C%22source%22%3A%22sxn0121%22%7D
https://blog.csdn.net/sxn0121/article/details/130901448?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22130901448%22%2C%22source%22%3A%22sxn0121%22%7D连续小波变换(Continuous Wavelet Transform,CWT)是一种用于信号分析的数学工具,它可以同时提供时间和频率信息。CWT是通过将信号与一组连续的小波函数进行卷积来实现的。
CWT的主要思想是将小波函数(也称为母小波)通过不同的尺度参数进行伸缩和平移,以适应信号在时间和频率上的变化。这意味着小波函数可以根据信号的不同频率成分在时间上自适应地进行拉伸或压缩。
以下是CWT的一般步骤:
选择小波函数:选择适当的小波函数作为CWT的基础函数。常用的小波函数包括Morlet小波、Mexican Hat小波(也称为Ricker小波)、Haar小波等。
连续尺度变换:对于给定的小波函数,通过在不同的尺度参数上应用平移和伸缩,将其与原始信号进行卷积。尺度参数控制了小波函数的频率范围。
计算系数图:对于每个尺度参数,计算卷积结果的幅度或复数值,得到CWT的系数图。系数图显示了信号在不同时间和频率上的能量或幅度。
重构信号:如果需要,可以通过将系数图与小波函数的逆变换(反卷积)相结合,对CWT的结果进行逆变换,从而重构原始信号。
CWT的优点在于它能提供在时间和频率上的局部信息,因此对于分析非平稳信号和瞬态事件非常有用。CWT广泛应用于信号处理、图像处理、模式识别和时间频率分析等领域。它可用于检测信号中的频率变化、分析信号的时频特性以及提取信号中的重要特征。
1.介绍
Emotion plays an important role in daily human life and influences all aspects. Emotion is an indispensable and important role for humans that affects people all the time, including human decision-making, speech, sleep, health, communication, and various other characteristics. Emotion recognition is often implemented based on facial expressions, speech, and physiological signals, while physiological signals more accurately reflect fluctuations in human emotional states [1] and are often used in the field of human-computer interaction. In recent years, emotion recognition based on electroencephalography (EEG) [2] in physiological signals has had widespread applications because of its non-invasive, easyto-use, and inexpensive characteristics.
情感在人类日常生活中扮演着重要的角色,影响着方方面面。情绪是人类不可或缺的重要角色,无时无刻不在影响着人们,包括人类的决策、言语、睡眠、健康、交流等各种特征。情感识别常基于面部表情、语音和生理信号实现,而生理信号更准确地反映了人类情感状态的波动[ 1 ],常被应用于人机交互领域。近年来,基于生理信号中基于脑电描记法( EEG ) [ 2 ]的情感识别因其非侵入性、易用性、廉价性等特点得到了广泛的应用。
EEG is an electrical signal of the human brain epidermis, which has nonlinear and non-smooth characteristics, while feature extraction and classification of such signals have been a challenge for researchers. Many researchers have proposed their feature extraction algorithms based on traditional methods [3–6] emotion recognition methods, and deep learning emotion recognition methods based on convolutional neural networks [7],deep learning networks [6,8], long and short-term memory networks [9–12], graph convolutional networks [9,12,13], attention mechanisms [14], etc. In recent years, graph convolutional neural networks (GCNN), long short-term memory neural networks (LSTM), and attention mechanisms have begun to be applied increasingly in the field. However, we are facing the problem of how to improve the integration of these different functional networks and apply them to EEG-based emotion recognition.
----
脑电信号( Electroencephalogram,EEG )是人脑表皮的电信号,具有非线性和非平滑特性,而对这类信号的特征提取和分类一直是研究人员面临的挑战。许多研究者在传统方法[ 3-6 ]情感识别方法的基础上提出了特征提取算法,以及基于卷积神经网络的深度学习情感识别方法[ 7 ],深度学习网络[ 6、8]、长短期记忆网络[ 9-12 ]、图卷积网络[ 9、12、13]、注意力机制[ 14 ]等。近年来,图卷积神经网络( GCNN )、长短时记忆神经网络( LSTM )和注意力机制开始在该领域得到越来越多的应用。然而,我们面临的问题是如何提高这些不同功能网络的集成,并将其应用于基于EEG的情感识别。
To address the above problems, we propose a deep learning model-based emotion recognition method. The method first uses common spatial pattern to process the EEG signal to get better spatial information, and then continuous wavelet transform transforms the filtered signal into a time–frequency map as the input of the deep model, which incorporates convolutional aspects. The model integrates convolutional neural networks and bidirectional long- and short-term memory networks and adds a multi-headed selfattentive mechanism on top of that. In the hybrid model, feature information is extracted using multiple CNNs, future, and past time series information is learned, and temporal features are extracted using BiLSTM, while better feature information is given by assigning weights to sentiment feature information using a multi-headed self-attentive mechanism. Finally, we conducted extensive experiments on DEAP dataset and the experimental results showed that the method has better classificatio
----
针对上述问题,本文提出了一种基于深度学习模型的情感识别方法。该方法首先使用共同空间模式(CSP)对脑电信号进行处理,以获得更好的空间信息,然后连续小波变换将滤波后的信号转化为时频图作为深度模型的输入,该模型包含了卷积方面。该模型集成了卷积神经网络和双向长短期记忆网络,并在此基础上增加了多头自注意力机制。在混合模型中,使用多个卷积神经网络提取特征信息,学习未来和过去的时间序列信息,使用Bi LSTM提取时间特征,并使用多头自注意力机制为情感特征信息分配权重以提供更好的特征信息。最后,我们在DEAP数据集上进行了广泛的实验,实验结果表明该方法具有较好的分类效果。
The main contributions of this paper are as follows: We propose a deep learning emotion recognition method for EEG signals, which is a deep learning framework consisting of a hybrid model of CNN, BiLSTM, and MHSA. The CNN is used to smooth and down-sample the data, then the BiLSTM extracts the future and past emotion features from the data for learning, and finally, the multi-headed attention mechanism is implemented to improve the emotion recognition accuracy by weighing the key information of the EEG emotion features.
----
本文的主要贡献如下:提出了一种脑电信号的深度学习情感识别方法,该方法是由CNN、Bi LSTM和MHSA混合模型组成的深度学习框架。利用CNN对数据进行平滑和降采样,然后BiLSTM从数据中提取未来和过去的情感特征进行学习,最后通过加权脑电情感特征的关键信息实现多头注意力机制来提高情感识别准确率。
• We propose a method for converting EEG signals into time–frequency maps as model data input. The method uses CSP filtering to extract the spatial information of EEG signals, and then CWT is used to convert the filtered information into time–frequency maps as model input data, which makes the CNN-BiLSTM-MHSA better for extracting feature information.
• We conducted extensive experiments on the DEAP dataset and achieved higher accuracy contrasted to other deep learning models and traditional methods for both binary classification tasks of valence, arousal, dominance, and liking, as well as quadruple classification tasks of valence-arousal states.
----
我们提出了一种将EEG信号转换为时频图作为模型数据输入的方法。该方法使用CSP滤波提取EEG信号的空间信息,然后使用CWT将滤波后的信息转换为时频图作为模型输入数据,这使得CNN - BiLSTM - MHSA更好地用于提取特征信息。
我们在DEAP数据集上进行了广泛的实验,并在效价、唤醒度、优势度和喜好度的二分类任务以及效价-唤醒度的四分类任务上取得了比其他深度学习模型和传统方法更高的准确率。
The content of the remainder of this paper is arranged as follows: The first part introduces some related studies on EEG sentiment recognition, and the second part describes the proposed sentiment recognition method and its key components, including CNN, BiLSTM, and multi-headed self-attentive mechanism fusion models and their architectures and evaluation metrics, the third part presents the DEAP dataset used in the experiments and analyzes the experimental results of CSP-CWT time–frequency maps and CNN-BiLSTM-MHSA on DEAP in detail, and the fourth part is the summary.
----
本文余下部分内容安排如下:第一部分介绍脑电情感识别的相关研究;第二部分介绍本文提出的情感识别方法及其关键组成部分,包括CNN、Bi LSTM和多头自注意力机制融合模型及其架构和评价指标;第三部分给出实验所用的DEAP数据集,并详细分析CSP - CWT时频图和CNN - Bi LSTM - MHSA在DEAP上的实验结果;第四部分为总结。
2.相关工作
Deep learning is a key element in the research of EEG emotion recognition, and more and more excellent models are being applied to EEG emotion recognition with more in depth research in the field of deep learning. The ability of convolutional neural networks to learn local smooth structures and evolve them into multi-scale hierarchical patterns has led to great breakthroughs in processing tasks such as images, speech, and video [15]. Tabar [8] used a one-dimensional CNN to process temporal, frequency, and location information for EEG extraction. Ozdemir [9] converted EEG signals into multispectral topological image sequences and used a two-dimensional convolutional network for feature extraction. Tripathi [16] undertook experiments on the DEAP dataset using CNN with good results. Li et al. [17] used a hierarchical convolutional neural network (HCNN) to verify the feasibility of this approach on the SEED dataset compared with traditional methods. Cui et al. [12] deeply integrated the complexity of the EEG signal, the spatial structure of the brain, and the temporal context of emotion formation to obtain a 4D feature tensor fed into CNN to extract features and obtained better results. Li et al. [18] used CNN to handle a four-category emotion task. Convolutional neural networks have a great role in the feature extraction of EEG signals. One-dimensional convolutional networks are suitable for the direct processing of EEG signals [8,17], but in the processing of information about images [9,12,16,18], two-dimensional convolution is more effective.
----
深度学习是脑电情感识别研究中的关键要素,随着深度学习领域研究的更加深入,越来越多的优秀模型被应用到脑电情感识别中。卷积神经网络学习局部平滑结构并演化为多尺度分层模式的能力使其在图像、语音、视频等处理任务中取得了重大突破[ 15 ]。Tabar [ 8 ]使用一维CNN处理时间、频率和位置信息进行EEG提取。Ozdemir [ 9 ]将脑电信号转换为多光谱拓扑图像序列,并使用二维卷积网络进行特征提取。特里帕蒂[ 16 ]使用CNN在DEAP数据集上进行了实验,取得了较好的效果。Li等[ 17 ]使用了分层卷积神经网络( HCNN ) 去验证该方法在SEED数据集上相对于传统方法的可行性。Cui等[ 12 ]将脑电信号的复杂性、大脑的空间结构以及情感形成的时间上下文进行深度融合,得到4D特征张量馈入CNN进行特征提取,取得了较好的效果。Li等[ 18 ]使用CNN来处理四分类情感任务。卷积神经网络在脑电信号的特征提取方面有很大的作用。一维卷积网络适用于脑电信号[ 8、17]的直接处理,但在处理图像[ 9、12、16、18]的信息时,二维卷积更加有效。
Recurrent neural networks (RNN) with good addressing capability for time series data are commonly used in natural language processing. In the development of deep learning, LSTM, which can better handle long-term dependencies, has become an effective scalable model for recurrent neural networks to solve the learning problem of sequence data. Ozdemir et al. [9] used LSTM to process the features extracted from CNN and achieved better results on the DEAP dataset. The accuracy was 90.62% in the high and low valence test, 86.13% in the high and low arousal test, and 86.23% in the liking test. Li et al. [18] used LSTM to fuse the spatial, frequency domain, and temporal features of the original EEG signal to make progress in a four-classification task.Many researchers currently are starting to use BiLSTM networks more and more, due to their ability to learn past and future information in time series and get better results than LSTM. Fares et al. [10] proposed a bidirectional neural network for EEG-based image recognition. They used bi-directional long short-term memory (BiLSTM) as a feature encoder and then used independent component analysis (ICA) and support vector machine (SVM) to classify the features which achieved advanced results. Xie et al. [11] proposed an end-to-end BiLSTM model with a neural attention mechanism for EEG-based target recognition tasks. Cui et al. [12] used BiLSTM to serialize feature-specific information processed by CNN and then learn the relationship between past and future in the information, achieving significant improvement with an average accuracy of 94% in the DEAP dataset.Sharma et al. [19] used the BiLSTM model for experimental validation on both dichotomous and quadruple classification, with significant room for improvement on the quadruple classification task. In terms of model selection for dealing with EEG emotion recognition. The use of ConvLSTM in the literature [20] has a good performance in processing time series, and advanced results were obtained on all three datasets. BiLSTM has more obvious advantages over LSTM for learning emotional information. The model proposed in this paper also utilizes the features of BiLSTM to achieve good results in EEG emotion recognition.
----
对时间序列数据具有良好寻址能力的循环神经网络( RNN )常用于自然语言处理。在深度学习的发展过程中,能够较好处理长期依赖关系的LSTM成为循环神经网络解决序列数据学习问题的有效可扩展模型。Ozdemir等[ 9 ]使用LSTM对CNN提取的特征进行处理,在DEAP数据集上取得了较好的效果。高、低效价测试的正确率为90.62 %,高、低唤醒度测试的正确率为86.13 %,喜欢度测试的正确率为86.23 %。Li等[ 18 ]使用LSTM融合原始EEG信号的空间、频域和时间特征,在四分类任务中取得进展。 由于Bi LSTM网络能够学习时间序列中过去和未来的信息,并且能够得到比LSTM更好的结果,目前很多研究者开始越来越多地使用Bi LSTM网络。Fares等[ 10 ]提出了一种双向神经网络用于基于EEG的图像识别。他们使用双向长短期记忆网络( BiLSTM )作为特征编码器,然后使用独立成分分析( ICA )和支持向量机( SVM )对特征进行分类,取得了较好的效果。Xie等[ 11 ]针对基于EEG的目标识别任务,提出了一种具有神经注意力机制的端到端Bi LSTM模型。Cui等[ 12 ]利用Bi LSTM将CNN处理后的特征特异性信息序列化,进而学习信息中过去与未来的关系,在DEAP数据集中取得了显著提升,平均准确率达到94 %。Sharma等[ 19 ]使用Bi LSTM模型在二分类和四分类上进行实验验证,在四分类任务上有显著的提升空间。在处理EEG情感识别的模型选择方面。文献[ 20 ]中卷积长短时记忆网络的使用在处理时间序列上有很好的表现,在3个数据集上都取得了先进的结果。Bi LSTM比LSTM学习情感信息的优势更加明显。本文提出的模型也利用了Bi LSTM的特性,在脑电情感识别中取得了较好的效果。
Attention mechanisms are often used to process natural language [21], where the relationship between the input and the word to be predicted is attended to in the sentence where the encoder output is obtained, and attention weights are calculated to determine the part of the input data that has the greatest impact on the output data, and then this part is given a higher weight, while this part of the input can have a greater value in the network. With the use of deep learning in the field of EEG emotion recognition, the attention mechanism has improved the ability to recognize emotional information. Kim et al. [14] used the attention mechanism to assign weights based on peaks to the emotional states that occur at a particular moment in a three-level emotion classification study up to 91.8%.Nowadays, self-attention mechanisms are less frequently used in EEG emotion recognition to improve classification accuracy, while multi-headed self-attention mechanisms have a greater advantage in this task of emotion recognition. In this study, the addition of multi-headed self-attention mechanism to the fusion model used in this paper significantly improved the accuracy of emotion recognition.
----
注意力机制常用于处理自然语言[ 21 ],在得到编码器输出的句子中关注输入与待预测词之间的关系,计算注意力权重,确定输入数据中对输出数据影响最大的部分,然后赋予这部分较高的权重,而这部分输入在网络中可以有较大的价值。随着深度学习在脑电情感识别领域的运用,注意力机制提高了对情感信息的识别能力。Kim等[ 14 ]在一项高达91.8 %的三级情感分类研究中,使用注意力机制为特定时刻发生的情感状态分配基于峰值的权重。如今,自注意力机制在脑电情感识别中的使用频率较低,以提高分类准确率,而多头自注意力机制在这种情感识别任务中具有更大的优势。本研究在本文使用的融合模型中加入多头自注意力机制,显著提高了情感识别的准确率。
The mixture of traditional methods and machine learning in EEG emotion recognition also has good results. Pandey et al. [6] used wavelet transform as a feature extraction method to form EEG signals of different frequency bands and used DNN for binary classification of emotional states; however, the results were not good. In the literature [22–24], wavelet transform was used to decompose time–frequency features and smoothen the feature information into SVM for classification, which shows much improvement in the accuracy of EEG emotional state recognition in the field of machine learning. Xu et al. [25] used discrete wavelet transform to process the EEG signal and then used the model of mRMR-KELM to achieve 80.83% accuracy in quadruple classification emotion classification recognition. Sharma et al. [19] used discrete wavelet transform to decompose the EEG signal into sub-bands and particle swarm optimization to remove irrelevant information. Galvão et al. [13] used wavelet transform to extract EEG features with KNN, and RF was determined as the best machine learning method for regression to achieve 84.4% accuracy in four classifications. The above-mentioned wavelet-transformed features are more conducive to the understanding of the model. In this paper, we also use the continuous wavelet transform to obtain the time–frequency features as the model input, which has better results compared with the direct input of the EEG signal.
----
传统方法与机器学习的混合在EEG情感识别中也有不错的效果。Pandey等人[ 6 ]使用小波变换作为特征提取方法,形成不同频段的脑电信号并使用DNN进行情感状态的二分类;但是,效果不佳。文献[ 22-24 ]采用小波变换分解时频特征,将特征信息平滑到SVM中进行分类,脑电情感状态识别在机器学习领域的准确性取得了较好的效果。Xu等[ 25 ]使用离散小波变换对脑电信号进行处理,然后使用mRMR - KELM的模型在四分类情感分类识别中取得了80.83 %的准确率。Sharma等人[ 19 ]利用离散小波变换将EEG信号分解为子带和粒子群优化去除无关信息。Galv ã o等[ 13 ]利用小波变换结合KNN提取EEG特征,确定RF为回归的最佳机器学习方法,在四种分类中达到84.4 %的准确率。上述的小波变换特征更有利于模型的理解。本文还利用连续小波变换得到的时频特征作为模型输入,与直接输入脑电信号相比具有更好的效果。
Although the above recognition methods have made some progress in EEG emotion recognition, the accuracy of many classifications is relatively low. The successful applications of convolutional neural networks, bidirectional long- and short-term memory networks, and attention mechanisms have provided new ideas for EEG-based emotion recognition. Therefore, we tried a new deep-learning model of emotion recognition to improve its accuracy of emotion recognition.
----
尽管上述识别方法在脑电情感识别方面取得了一定的进展,但是很多分类的准确率比较低。卷积神经网络、双向长短期记忆网络和注意力机制的成功应用为基于EEG的情绪识别提供了新的思路。因此,我们尝试了一种新的情感识别深度学习模型来提高其情感识别的准确率。
3.方法
3.1.常见的空间模式过滤
When acquiring EEG signals from the scalp, different channel acquisitions can make the spatial resolution of the signal poor. Therefore, spatial filters are needed to increase spatial resolution and improve the spatial information contained in the signal [26]. In this paper, the CSP algorithm is used as a spatial filter to convert the original time series into a new time series with variance discriminative information and maximize the variance according to the labels to achieve spatial discrimination of two and four class time series. The spatially filtered signal Ztr for trial tr with dimension N × ch, where N is the number of samples and ch is the number of channels, is determined by: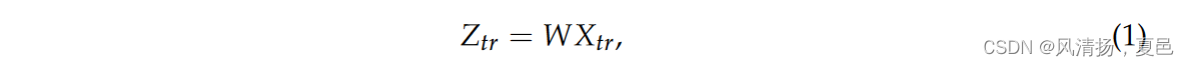
----
在从头皮采集EEG信号时,不同的通道采集会使信号的空间分辨率变差。因此需要空间滤波器来提高空间分辨率,改善信号中包含的空间信息[ 26 ]。本文采用CSP算法作为空间滤波器,将原始时间序列转换为具有方差判别信息的新时间序列,并根据标签最大化方差,实现二、四类时间序列的空间判别。维数为N × ch的试验tr的空间滤波信号Ztr,其中N为样本个数,ch为通道数,由确定:
where Xtr is the original EEG signal and W is the projection matrix. The columns of the spatial filter W−1 are the spatial patterns, which are the EEG source distribution vectors. The first and last columns are the significant spatial patterns that explain the maximum variance of one class of sentiment and the minimum variance of the other class. The EEG features with the greatest correlation between the two classes of emotions in the EEG are extracted by common-space pattern transformation, in preparation for the next step of the continuous wavelet transformation.
----
其中Xtr为原始EEG信号,W为投影矩阵。空间滤波器W - 1的列是空间模式,即EEG源分布向量。第一列和最后一列是解释一类情感最大方差和另一类最小方差的显著空间模式。通过共空间模式变换提取EEG中两类情感相关性最大的EEG特征,为下一步的连续小波变换做准备。
3 . 2 .连续小波变换的生成
The continuous wavelet transform is used to generate a function scale map of frequency and time for better frequency localization of low-frequency and long-term events. In the context of image classification, the images obtained from the scale map are used as input to the network model [27]. In this paper, CWT is used because it produces good time–frequency analysis and helps in the localization of frequency information, which is determined by: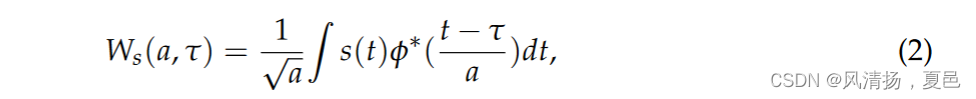
where s(t) is the input signal, a is the wavelet transform scale, φ is the wavelet basis function, and τ is the time shift. The wavelets were compressed according to the resolution by translating along time t, with s as the scale. In the spectrogram analysis of EEG signals, the classification of emotional states with a fixed window size is generally effective. In contrast, the multi-resolution analysis based on the scale map can capture short and abrupt changes in EEG signal frequency.
----
利用连续小波变换生成频率和时间的函数尺度图,更好地对低频和长期事件进行频率局部化。在图像分类的背景下,从比例尺地图中获取的图像作为网络模型的输入[ 27 ]。在本文中使用CWT是因为它产生了良好的时频分析并且有助于频率信息的定位,这是由:
其中s ( t )为输入信号,a为小波变换尺度,φ为小波基函数,τ为时移。将小波按分辨率沿时间t平移进行压缩,尺度为s。在脑电信号的频谱分析中,固定窗口大小的情绪状态分类一般是有效的。相比之下,基于尺度图的多分辨率分析可以捕捉EEG信号频率的短暂和突变。
3.3. 数据表示时间频率图
We used the “pywt” library of Python with 14 wavelet families, according to the experimental comparison of “cmor4-4”, “gaus8”, “cgau8”, “mexh”, “morl” wavelet families generated by the time–frequency map. “cgau8”, “mexh” and “morl” wavelet families. According to the effect of feeding into CNN, we applied the continuous wavelet transform of the “cgau8” wavelet family. The scalar map was plotted as a function of frequency and time to allow better temporal localization of short and high-frequency events and better frequency localization of low frequencies. The frequencies were sampled from 0 to 64 (128 Hz/2 = 64 Hz) for all possible frequencies, and half of the sampling rates we analyzed are given according to Nyquist theory.By segmenting the filtered signal in 6 s, it can be divided into 10 segments, and the CNN input image size of 32 channels of EEG data is 20 × 65 × 3, which is stored according to different label categories. This is the size we confirmed by repeated experiments, too high or too low will make the CNN processing of features worse, while the generated partial images are shown in Figure 1. 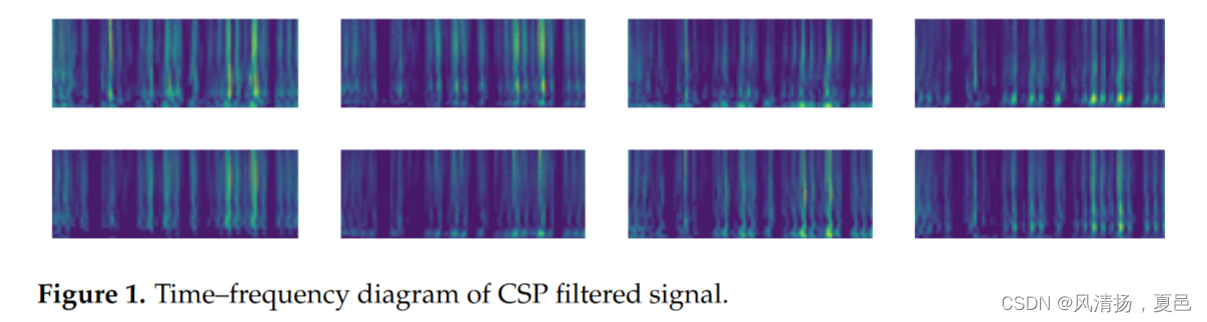
----
使用Python的' pywt '库中的14个小波族,根据时频图生成的' cmor4-4 '、' gaus8 '、' cgau8 '、' mexh '、' morl '小波族进行实验对比。根据馈入CNN的效果,我们应用了' cgau8 '小波族的连续小波变换。标量图被绘制成频率和时间的函数,以允许短和高频事件更好的时间定位和低频更好的频率定位。对所有可能的频率从0 ~ 64 ( 128 Hz / 2 = 64 Hz)进行采样,根据奈奎斯特理论给出我们分析的采样率的一半。通过对滤波后的信号在6s内进行分段,可以分为10段,32通道EEG数据的CNN输入图像大小为20 × 65 × 3,按照不同的标签类别进行存储。这是我们通过反复实验确认的尺寸,过高或过低都会使CNN对特征的处理效果变差,而生成的部分图像如图1所示。
3 . 4 .多头自注意力的CNN - BiLSTM方法
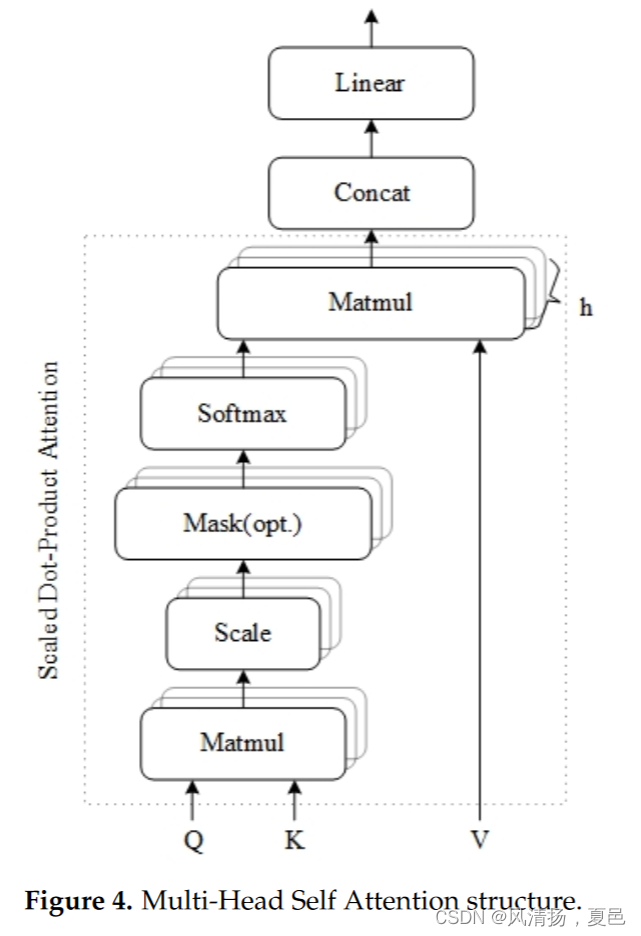
The training model studied in this paper is a bidirectional two-layer LSTM with a multi-headed self-attentive mechanism coupled with a single-layer convolutional neural network structure, referred to as a CNN-BiLSTM-MHSA network. The input data is passed through a one-dimensional convolutional network with a convolutional kernel of 128. Then after batch normalization (BN) and ReLu activation function and then one-dimensional pooling of the data with the kernel of 3, the obtained data sequence is fed to the BiLSTM deep network with 256 hidden units per layer of the LSTM network. The output structure is spliced with fully connected layers, and the 512 data sequences obtained are cloned to the multi-headed self-attentive Q, K, and V , respectively , and then weights are assigned by scaling dot product attention. Finally , the classification results are derived using the Softmax activation function, while the network classification framework diagram is shown in Figure 2.
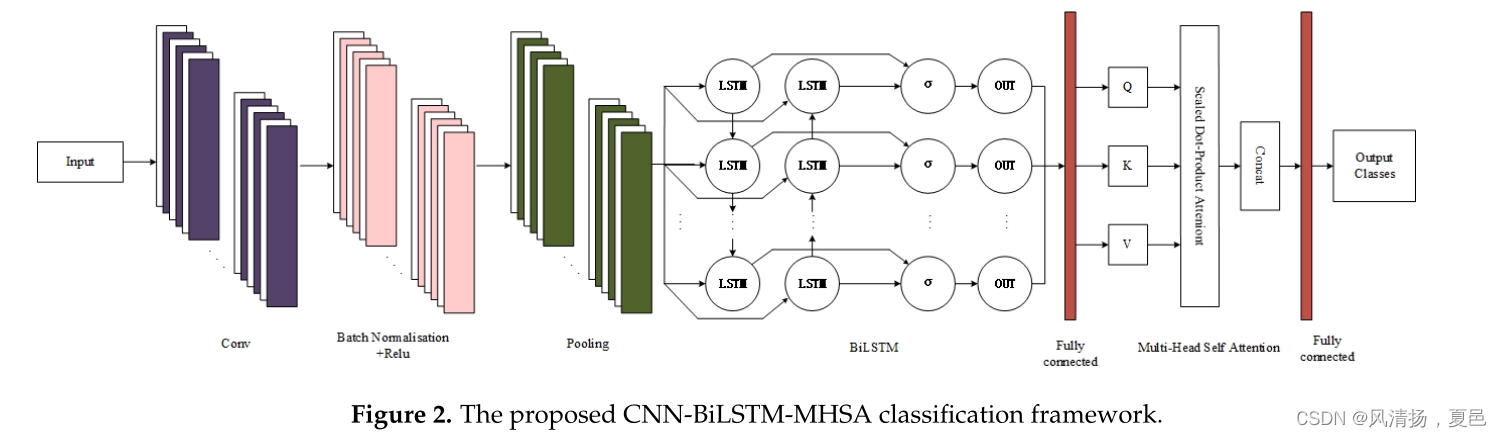
本文研究的训练模型是一个具有多头自注意力机制的双向双层LSTM与单层卷积神经网络结构相结合,称为CNN-BiLSTM-MHSA网络。输入数据通过卷积核为128的一维卷积网络传递。然后经过批处理归一化(batch normalization, BN)和ReLu激活函数,再对核数为3的数据进行一维池化,将得到的数据序列馈送到LSTM网络每层256个隐藏单元的BiLSTM深度网络。将得到的512个数据序列分别克隆到多头自注意的Q、K和V上,然后通过缩放点积关注分配权重。最后利用Softmax激活函数导出分类结果,网络分类框架图如图2所示。
3.4 . 1卷积神经网络
CNN is a very effective image processing and classification model. the architecture uses convolutional operations to extract various features of the data and then pass the features to the next layer. The convolutional smoothed signal after CNN processing has a significant improvement on the LSTM network.
----
CNN是一种非常有效的图像处理和分类模型,该架构使用卷积操作提取数据的各种特征,然后将特征传递给下一层。经过CNN处理后的卷积平滑信号在LSTM网络上有明显的提升。
3 . 4 . 2 .双向Lstm网络
LSTM occupies a place in the field of sequential signal analysis by sharing weights, and the weights between its hidden layer and output layer can be recycled at any time [28]. It is a chain model for processing time series and can effectively compensate for the vanishing gradient problem. Compared with the classical unidirectional EEG signal extraction method, the bidirectional EEG signal extraction method can extract dynamic information from both earlier and later segments of the EEG signal sequence [29]. An LSTM unit consists of three gate control units of the forget gate and input gate and the calculation formulas are defined by Equations (3)–(8):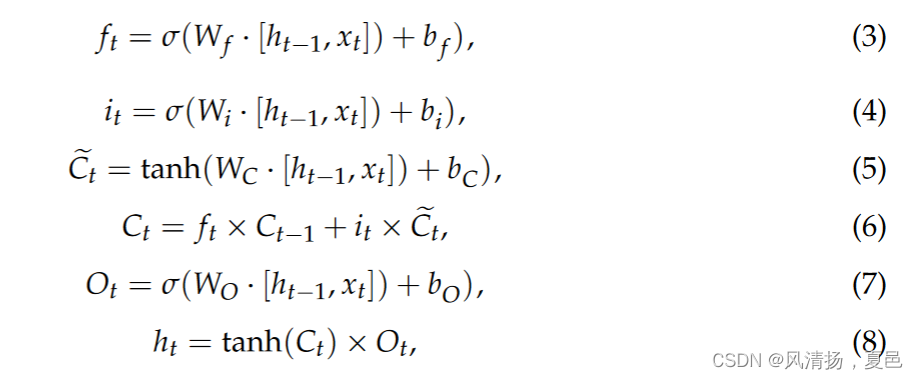
where, xt is the time series at time t, Ct is the cell state, ̃ Ct is the temporary cell state, σ is the sigmoid function, W is the weight matrix, b is the bias vector of the corresponding weight, ht is the hidden state, ft is the forget gate, it is the memory gate, and Ot is the output gate. The forget gate selects the retained features and inputs both the information of the previous state and the current state information into the Sigmoid function. The memory gate is responsible for updating the state of the LSTM cell, after which the input gate controls the output value to the next LSTM cell. Unlike the above single LSTM, the output formulas of the bidirectional LSTM are defined by Equation (9):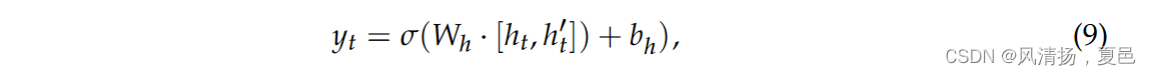
----
LSTM通过共享权重在序列信号分析领域占有一席之地,其隐藏层和输出层之间的权重可以随时回收[ 28 ]。它是一种处理时间序列的链式模型,可以有效地弥补梯度消失问题。与经典的单向EEG信号提取方法相比,双向EEG信号提取方法可以同时从EEG信号序列的前段和后段中提取动态信息[ 29 ]。LSTM单元由遗忘门和输入门的三个门控单元组成,计算公式由式( 3 ) - ( 8 )定义:
其中,xt是t时刻的时间序列,Ct是细胞状态,' Ct是临时细胞状态,σ是sigmoid函数,W是权重矩阵,b是相应权重的偏置向量,ht是隐藏状态,ft是遗忘门,it是记忆门,Ot是输出门。遗忘门选择保留的特征,将上一状态的信息和当前状态信息同时输入Sigmoid函数。记忆门负责更新LSTM单元的状态,之后输入门控制输出值到下一个LSTM单元。与上述单一LSTM不同,双向LSTM的输出公式由式( 9 )定义:
The BiLSTM network adds a backward layer to learn the future sentiment information, which is an extension of the past sentiment information. The BiLSTM merges the gating architecture and bidirectional characteristics perfectly so that more information can be remembered and processed by the two LSTM units [30]. The network structure of BiLSTM is shown in Figure 3. The time series is input to the model, the forward layer connects the feature information in the past series with the present information, the backward layer connects the future, and finally, the predicted value is output by Equation (9).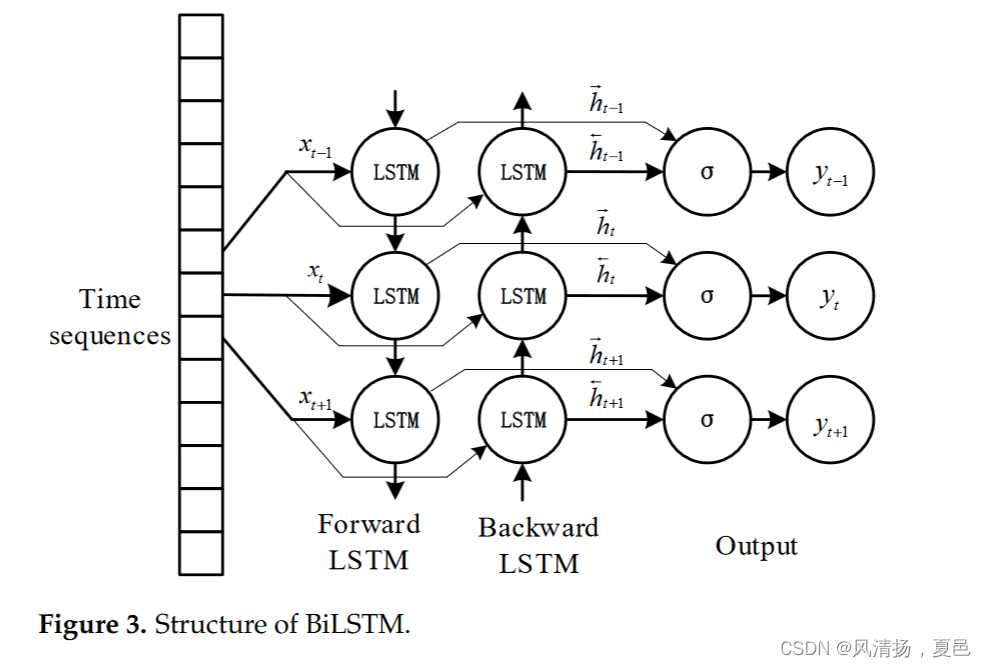
----
BiLSTM网络增加了后向层来学习未来的情感信息,是对过去情感信息的扩展。Bi LSTM完美地融合了门控结构和双向特性,使得两个LSTM单元可以记忆和处理更多的信息[ 30 ]。BiLSTM的网络结构如图3所示。将时间序列输入模型,前向层将过去序列中的特征信息与现在信息联系起来,后向层将未来联系起来,最后通过式( 9 )输出预测值。
3 . 4 . 3 .Transformer中的多头自注意力
The Transformer model [21] is an autoregressive generative model that uses mainly self-attentive mechanisms and sinusoidal location information. Each layer includes a timeself-noticing sublayer, a pre-feedback network sublayer, a residual network sublayer, and a dropout layer.
Attention essentially assigns a weighting factor to each element in the EEG sequence, and if each element is stored, attention can be calculated as the similarity between Q and K. The similarity calculated from Q and K reflects the importance of the extracted V values, the weights, which are then weighted and summed to obtain the attention values. The special point of the self-attention mechanism in the K, Q, V model is that Q = K = V. The scaled dot product attention formula is defined as Equation (10):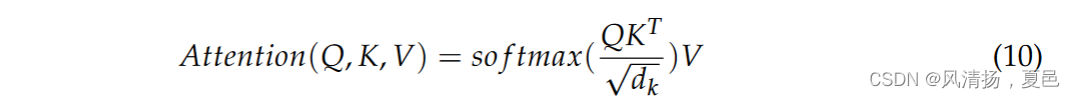
The multi-headed self-attention mechanism obtains different representations of h (i.e., each head) of (Q, K, V), calculates the self-attention of each representation, and connects the results. This can be expressed in the same notation as in Equations (11) and (12):
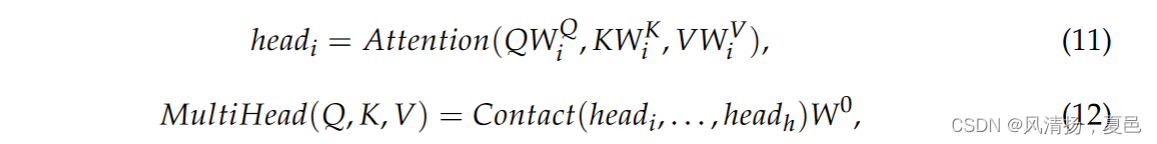
where Wi and W0 make the parameter matrix; the structure of the multi-headed self-attentive mechanism is shown in Figure 4.
----
Transformer模型[ 21 ]是一种自回归生成模型,主要利用自注意机制和正弦位置信息。每层包括时间自通知子层、预反馈网络子层、残差网络子层和dropout层。
Attention本质上是为EEG序列中的每个元素分配一个权重因子,如果每个元素都被存储,那么注意力可以计算为Q和K之间的相似度。由Q和K计算的相似度反映了提取的V值的重要性,权重,然后加权求和得到注意力值。自注意力机制在K,Q,V模型中的特殊之处在于Q = K = V:
多头自注意力机制获取( Q , K , V)的h (即,每个头)的不同表示,计算每个表示的自注意力,并将结果进行连接。这可以用与式( 11 )和式( 12 )相同的符号表示:
式中:Wi和W0为参数矩阵;多头自注意机制的结构如图4所示。
The BiLSTM contains two outputs, the output O = [O1, O2, O3, . . . , OD] for all time steps and the hidden state HD for the last time step D. Since O = [O1, O2, O3, . . . , OD] denotes the EEG sentiment feature and HD denotes the hidden temporal feature, to identify the importance of time on sentiment, we need to establish the self-attention relationship between HD and Ot. That is, to establish the weight of each time step output Ot for HD.
----
Bi LSTM包含两个输出,所有时间步的输出O = [ O1 , O2 , O3 , ... , OD],最后一个时间步D的隐藏状态HD。由于O = [ O1 , O2 , O3 , ... , OD]表示EEG情感特征,HD表示隐藏的时间特征,为了识别时间对情感的重要性,需要在HD和Ot之间建立自注意力关系。即为HD建立每个时间步输出Ot的权重。
Since BiLSTM itself considers the location information, there is no need to set up additional location encoding. The implementation method of the self-attention mechanism in BiLSTM we use is scaled dot product attention [21], which is the self-attention implementation method proposed by the transformer.
----
由于BiLSTM本身考虑了位置信息,因此不需要设置额外的位置编码。我们使用的Bi LSTM中自注意力机制的实现方法是尺度化点积注意力[ 21 ],这是Transformer提出的自注意力实现方法。
The output Ot of each time step is linearly transformed as Keyt and Valuet, while the output HD of the final time step is multiplied by the matrix WQ as Query. at time step t, Keyt, Valuet, Query, score e and weight a have the following equations:
----
每个时间步的输出Ot线性变换为Keyt和Valuet,而最后一个时间步的输出HD乘以矩阵WQ为Query: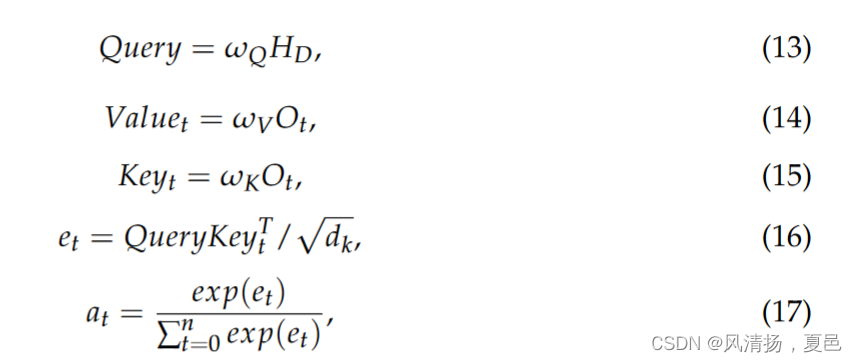
where Query does not change with time step and ωQ, ωK, ωV are parameters of the neural network that are modified with backpropagation. The weights at and Valuet of each time step are weighted and summed to obtain the emotional feature vector with self-attentiveness:
----
式中Query不随时间步长变化,ω Q、ω K、ω V为经反向传播修正后的神经网络参数。对每个时间步的权重at和Valuet进行加权求和,得到具有自注意力的情感特征向量: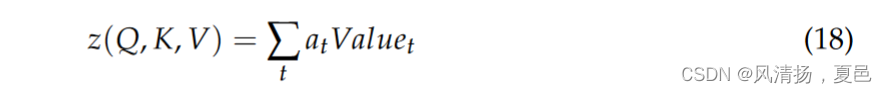
To obtain the multi-headed self-attention, the above equation is performed h times to obtain the multi-headed self-attention feature z1, . . . , zh, which is spliced and linearly transformed once as the final output:
----
为获得多头自注意力,对上式进行h次运算,得到多头自注意力特征z1,..,zh,将其进行一次拼接和线性变换,作为最终输出: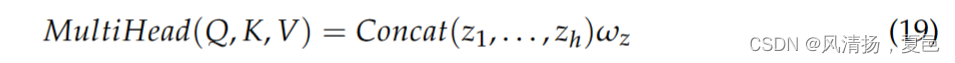
3.5 .训练CNN - BiLSTM - MHSA
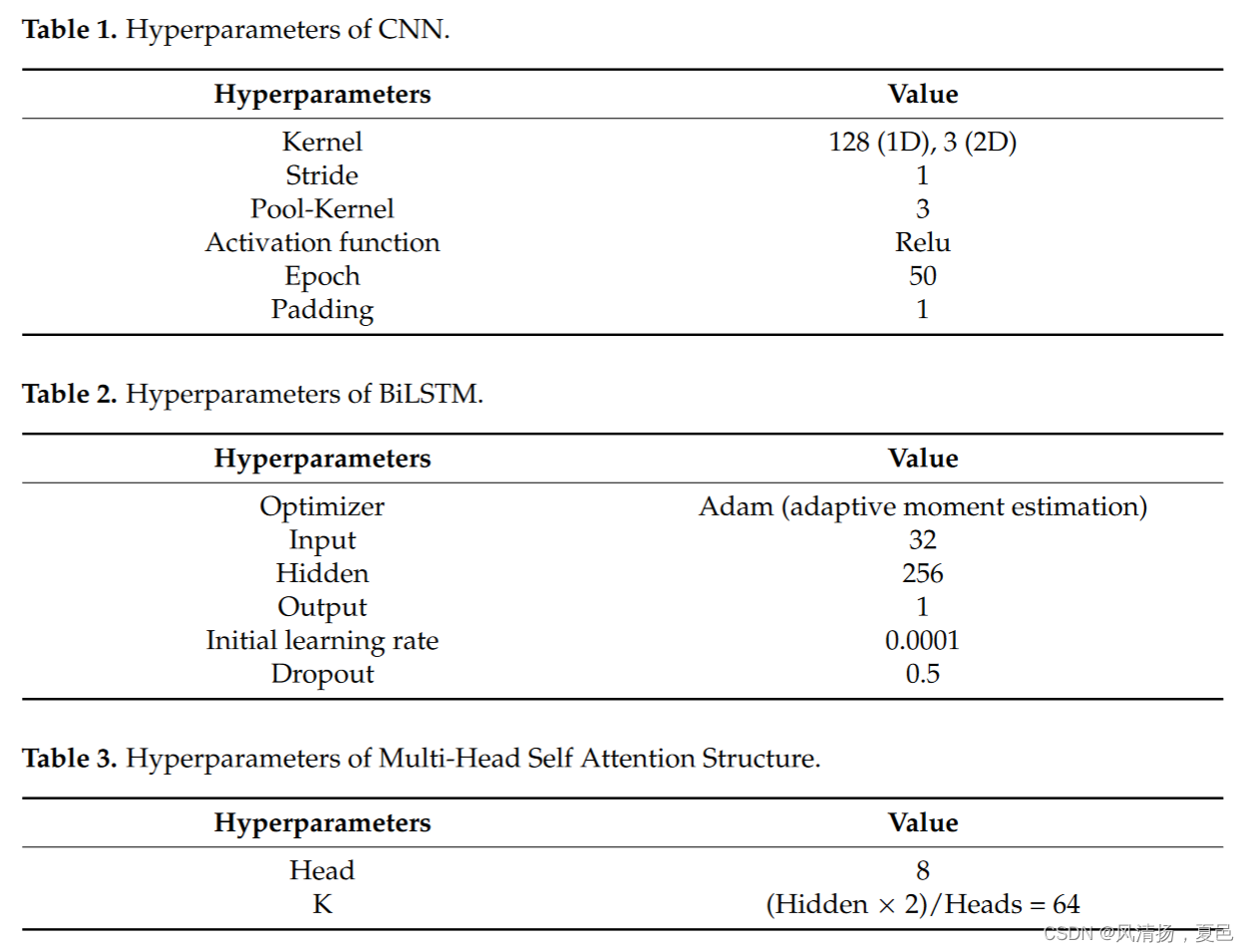
In this paper, the network training is based on cross-entropy function optimization and stochastic gradient descent for backpropagation. The optimizer used for the network is the optimizer responsible for the backpropagation process. The commonly used optimizers are SGD and Adam, both of which are interchangeable. Here, we will use Adam. For backpropagation, we will define a loss function using cross-entropy loss, which is a common loss function used for multi-class purposes. Weight sharing in CNN usually results in varying the gradients across layers, for this reason, single-layer convolutional neural networks are used for binary classification and use a smaller learning rate. Since the twolayer bidirectional LSTM has a larger depth, a smaller number of iterations (epoch = 50) is sufficient to converge, while dropout = 0.5 is adopted in the training network to eliminate the influence of the overfitting problem. The convolutional layer uses a single-layer CNN with a kernel of 128. The convolutional network is used to extract the frequency domain features of the EEG information sequence, and then the LSTM unit analyzes the time domain features. Finally , the multi-head self-attention mechanism is used to improve classification accuracy . In this method, the bidirectional LSTM layer has 256 units (512 in total), and the hidden layer with 128 vs. 512 units is also investigated to select the 256 units with the best results. The multi-head self-attentive mechanism of the head selects the 8 heads with the best effect from 2/4/8/12/16. The following table lists the hyperparameters of the training network. The hyperparameters of the training network are shown in Tables 1–3.
在本文中,网络训练是基于交叉熵函数优化和随机梯度下降的反向传播。用于网络的优化器是负责反向传播过程的优化器。常用的优化器是SGD和Adam,它们都是可互换的。在这里,我们将使用Adam。对于反向传播,我们将使用交叉熵损失定义损失函数,这是用于多类目的的常见损失函数。CNN中的权值共享通常会导致各层间梯度的变化,因此,单层卷积神经网络被用于二值分类,并且使用较小的学习率。由于两层双向LSTM具有较大的深度,因此较少的迭代次数(epoch = 50)就足以收敛,而在训练网络中采用dropout = 0.5来消除过拟合问题的影响。卷积层使用核数为128的单层CNN。利用卷积网络提取脑电信息序列的频域特征,LSTM单元对其时域特征进行分析。最后,利用多头自注意机制提高分类精度。在该方法中,双向LSTM层有256个单元(共512个),并且还研究了128和512个单元的隐藏层,以选择效果最好的256个单元。头部的多头自注意机制从2/4/8/12/16中选择效果最好的8个头部。下表列出了训练网络的超参数。训练网络的超参数如表1-3所示。
3 . 6 .不同参数的影响
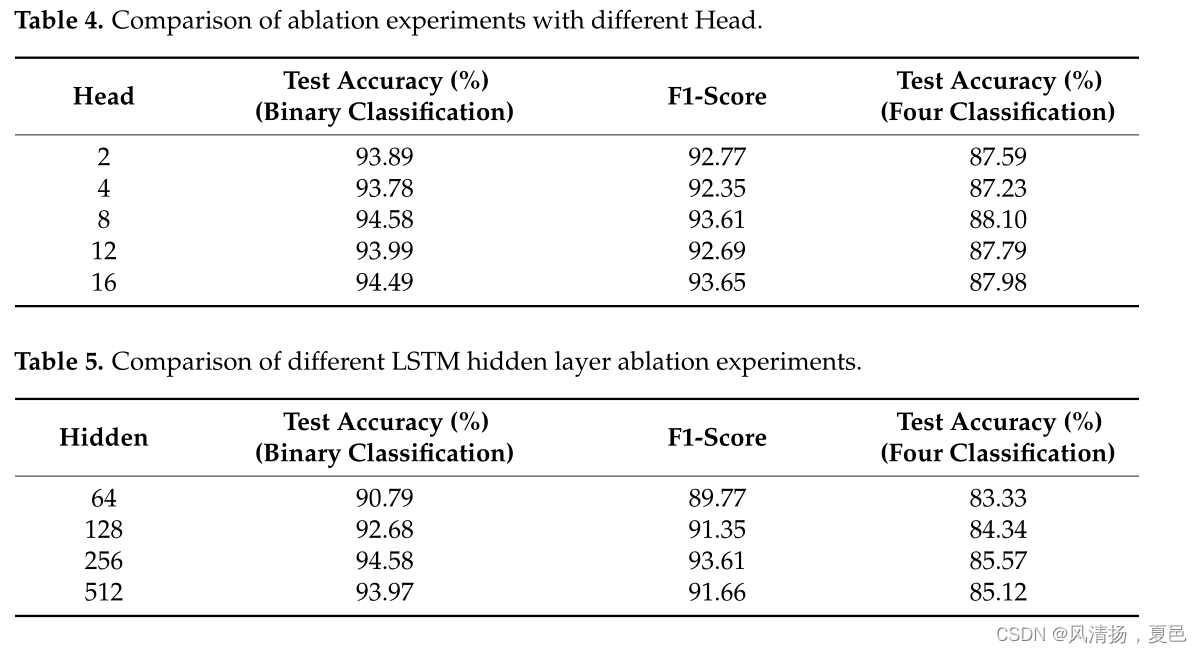
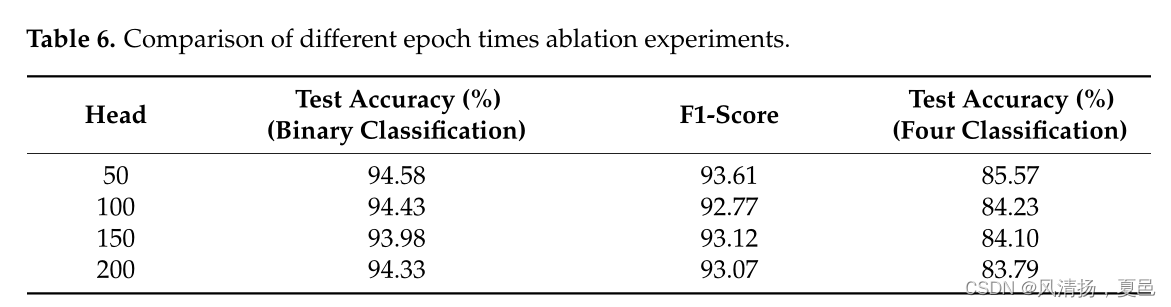
In this section, we analyze the impact of the parameter Head on the performance, which is the number of self-attention heads in the attention-based encoder. Table 4 reports the performance of the proposed CNN-BiLSTM-MHSA on the DEAP dataset for different values of Head. This illustrates that the CNN-BiLSTM-MHSA performance does not fluctuate significantly due to the change of the parameter Head, which indicates that the method has relatively good robustness. In addition, when Head is set to 8, the model obtains more competitive recognition results than any other setting. Therefore, to obtain better performance, we set the CNN-BiLSTM-MHSA model to Head = 8. We also compare the hidden layer of the LSTM with the epoch count as in Tables 5 and 6. Different parameter configurations will have an impact, so the most suitable parameters are selected after several experiments.
----
在本节中,我们分析了参数Head对性能的影响,即注意力编码器中自注意力头的数量。表4报告了本文提出的CNN - BiLSTM - MHSA在DEAP数据集上针对不同Head值的表现。这说明CNN - BiLSTM - MHSA的性能并没有因为参数Head的变化而产生明显的波动,说明该方法具有较好的鲁棒性。此外,当Head设置为8时,模型获得了比其他任何设置都更具竞争力的识别结果。因此,为了获得更好的性能,我们将CNN - BiLSTM - MHSA模型设置为Head = 8。我们还将LSTM的隐藏层与epoch 数进行了比较,如表5和表6所示。不同的参数配置会产生影响,因此经过多次实验选取最合适的参数。
3 . 7 .评价指标
Classification accuracy Acc and F-score are used to evaluate the CNN-BiLSTM-MHSA model. Acc is denoted as:
----
分类准确率Acc和F值用来评估CNN - BiLSTM - MHSA模型。Acc记为:
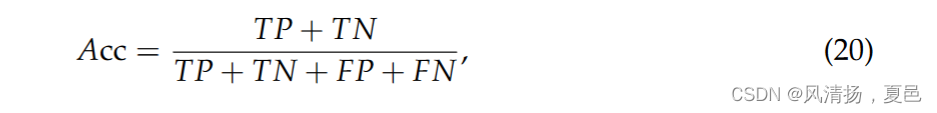
where TP is the number of low-state samples for which the classification model can accurately identify arousal, potency, dominance, and preference; TN is the number of high-state samples for which the classification model can accurately identify arousal, potency, dominance, and preference; FP is the number of low-state misclassifications, and FN is the number of high-state misclassifications. The precision Pre is defined as:
----
其中TP为分类模型能够准确识别唤醒度、效价、优势度和偏好度的低状态样本数;TN是分类模型能够准确识别唤醒度、效价、优势度和偏好度的高状态样本数量;FP为低状态误分类数,FN为高状态误分类数。精度Pre定义为:
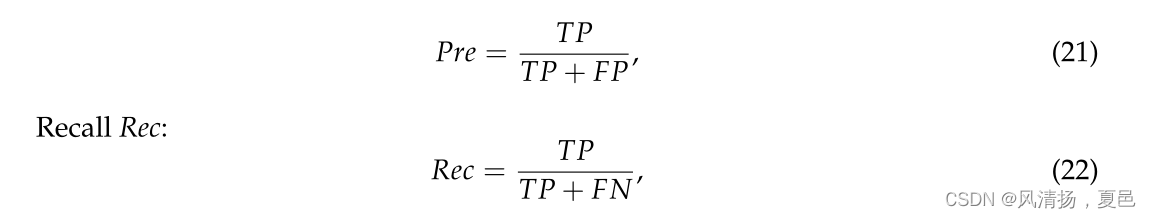
The F-score is an extension of classification accuracy, combining accuracy and recall, and is calculated as defined by:
----
F值是分类准确率的扩展,结合了准确率和召回率,计算公式为: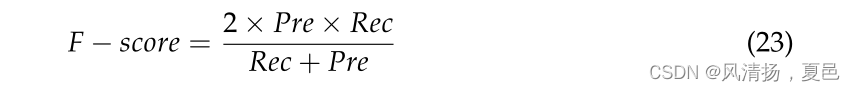
4 .材料与实验
4 . 1 .数据集
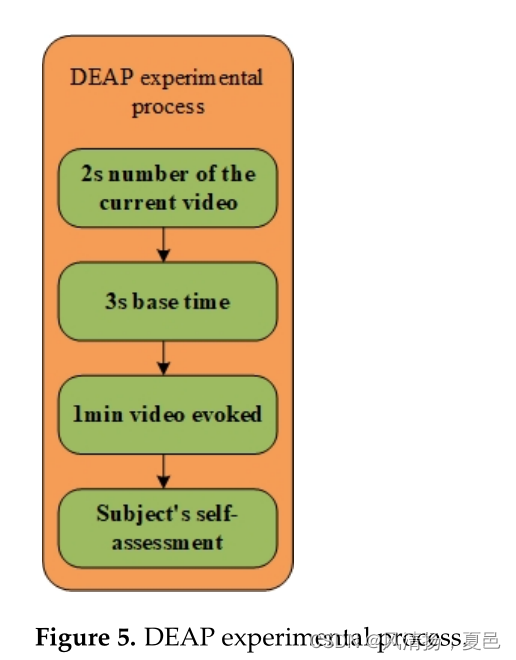
The current experiment is a DEAP dataset consisting of two parts of emotion recognition and physiological signals [31], while the acquisition process is shown in Figure 5. The DEAP dataset collected physical signals and emotional assessments from 32 subjects. Subjects autonomously rated videos from 1 to 9 on 4 dimensions based on arousal, valence, dominance, and liking [32]. The official provides two data forms, one is the original signal including various interferences, such as EMG, EOG, and other interference; the other is preprocessed data, including down-sampling data to 128 Hz, removing EMG artifacts, 4.0–45 Hz band-pass frequency filter filtering, etc. Preprocessing removes the non-emotional information from the previous 2 s to avoid affecting the training of the subsequent models.
----
目前的实验是由情感识别和生理信号两部分组成的DEAP数据集[ 31 ],采集流程如图5所示。DEAP数据集收集了32名被试的身体信号和情绪评估。被试基于唤醒度、效价、优势度和喜好度4个维度对1到9的视频进行自主评分[ 32 ]。官方提供了两种数据形式,一种是包含各种干扰的原始信号,如EMG、EOG等干扰;另一种是数据预处理,包括将数据降采样至128Hz,去除肌电伪迹,4.0 ~ 45Hz带通滤波等。预处理去除前2 s的非情绪信息,避免影响后续模型的训练。
The states of valence, arousal, dominance, and liking in the DEAP dataset can be classified according to a given threshold. Emotion states were studied in a quadratic dichotomy of high and low valence, high and low arousal, high and low dominance, and high and low liking with a threshold of 5. The two-dimensional model with four categories consists of a combination of four different affective states: high arousal and low valence (HALV), high arousal and high valence (HAHV), low arousal and low valence (LALV), low arousal and high valence (LAHV) [33].
----
DEAP数据集中的效价、唤醒度、优势度和喜欢度状态可以根据给定的阈值进行分类。情绪状态采用高、低效价,高、低唤醒度,高、低优势度,高、低喜欢度的二次二分法进行研究,阈值为5。四分类的二维模型由四种不同情绪状态的组合构成:高唤醒低效价( HALV )、高唤醒高效价( HAHV )、低唤醒低效价( LALV )、低唤醒高效价( LAHV ) [ 33 ]。
4.2. 脑电情绪分类实验
For Experiment 1, which did not use continuous wavelet transform, the process is shown in Figure 6. We tried to improve the input long-short time memory network before part of the BiLSTM by adding CNN before the BiLSTM, because CNN can help us smooth the signal and will make the sequence length of the EEG signal smaller, so it can greatly the CNN processed the EEG signal after the data as if it was sampled again, instead of using the original data directly , and feed the processed data into BiLSTM to obtain higher accuracy of sentiment classification. In the CNN network, we also add a down sampling, or pooling, layer, which reduces the parameters and speeds up the computation. The data length will not change. Then we can use BiLSTM to learn the temporal features passed by CNN in a more in depth way . LSTM can only consider the sentiment information in a shorter period of time, while BiLSTM can capture the influence of the future and past on the present moment, learn the future and past information of the time series, and be able to concatenate the sentiment features extracted before and after as the final sentiment features. However, BiLSTM may not take advantage of the association of given labels, such as whether high valence has an effect on low valence, or the association between other criteria given in more classifications. The multi-headed attention mechanism incorporated in the experiments of this paper solves this problem well. The features of all time steps and hidden states of the BiLSTM can be weighted and reassigned using the multi-headed self-attentive mechanism by back-propagating the parameters of Value and Key over time to modify the parameters and obtain the emotional feature vector of attention based on the weighted sum of the calculated time steps and Value to obtain the multi-headed state.Attention reassignment achieves weighting the key information of EEG emotion features and improves the emotion recognition accuracy
实验1没有使用连续小波变换,实验过程如图6所示。我们试图改善之前输入的多空时间记忆网络的一部分通过添加CNN BiLSTM BiLSTM之前,因为CNN可以帮助我们光滑信号,会使EEG信号的序列长度小,所以它可以加大CNN加工后的脑电图信号数据,如果是再次取样,而不是直接使用原始数据,并将处理后的数据输入到BiLSTM中,以获得更高的情感分类精度。在CNN网络中,我们还添加了下采样或池化层,这减少了参数并加快了计算速度。数据长度不会改变。然后我们可以使用BiLSTM更深入地学习CNN传递的时间特征。LSTM只能考虑较短时间内的情绪信息,而BiLSTM可以捕捉未来和过去对当前时刻的影响,学习时间序列的未来和过去信息,并能够将前后提取的情绪特征连接起来作为最终的情绪特征。然而,BiLSTM可能不会利用给定标签之间的关联,例如高价是否对低价有影响,或者在更多分类中给出的其他标准之间的关联。本文实验中引入的多头注意机制很好地解决了这一问题。利用多头自关注机制对BiLSTM的所有时间步长和隐藏状态的特征进行加权和重新分配,通过对Value和Key的参数随时间反向传播来修改参数,并根据计算出的时间步长和Value的加权和得到注意力的情感特征向量,从而得到多头状态。注意重分配实现了对脑电情绪特征关键信息的加权,提高了情绪识别的准确率
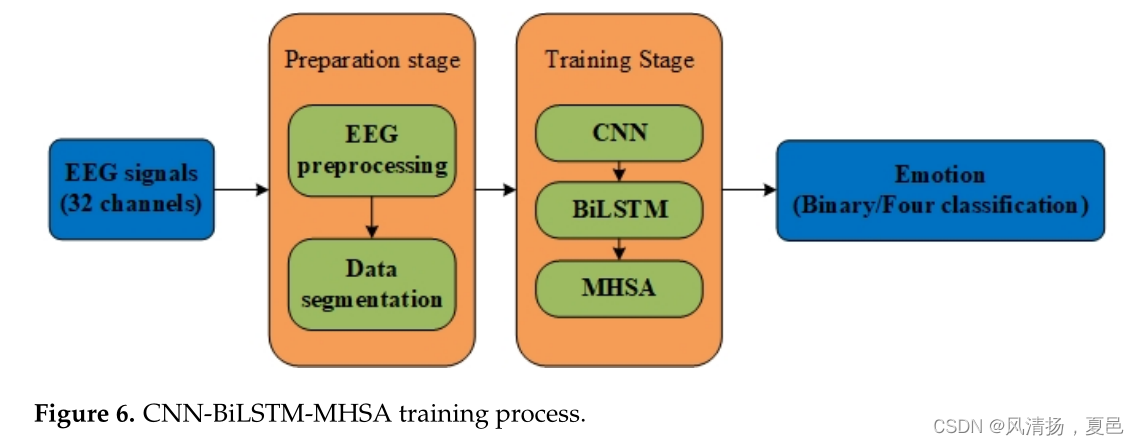
The proposed CNN-BiLSTM-MHSA model is used for the identification of high and low potency , arousal, control, and preference in the DEAP dataset. The dataset python pre-processed version was selected for this experiment. The first 32 EEG channels were extracted and the data were downsampled to 128 Hz. Thus, one second includes 128 samples, and one minute or 60 s about 7680 samples, but the 8064 samples in the data should be 128 × 63 samples, with 3 s of benchmark time for each test. Data segmentation is used to create more data. In this paper, a 1-min video is divided into 12 five-second segments, which greatly increases the number of samples and thus increases the chance of prediction.The original data format is 1280 × 32 × 8064. After dividing into 12 segments, the data format is 1280 × 32 × 672 × 12, and then the data is replaced with 15,360 × 32 × 672.The data are fed into a CNN-BiLSTM-MHSA network, where the batch size is 16. The leave-one-subject-out cross-validation method is used, and the high and low states are distinguished by a threshold value of 5 afterwards, with the high label set to 1 for those greater than 5 and the low label 0 for the rest. Training and validation accuracies of 99.07% and 95.12% were obtained on the DEAP dataset for the potency state, respectively . The training and validation accuracies in the arousal state were 99.12% and 94.62%. The training and validation accuracies were 99.25% and 94.32% for the dominance state, and 99.02% and 94.25% for the preference state, respectively .
提出的CNN-BiLSTM-MHSA模型用于识别DEAP数据集中的高效价和低效价、唤醒、优势度和喜好度。本实验选择数据集python预处理版本。提取前32个脑电信号通道,下采样至128 Hz。因此,1秒包含128个样本,1分钟或60秒大约包含7680个样本,但数据中的8064个样本应该是128 × 63个样本,每个测试的基准测试时间为3秒。数据分割用于创建更多的数据。在本文中,一个1分钟的视频被分成12个5秒的片段,这大大增加了样本的数量,从而增加了预测的机会。原始数据格式为1280 × 32 × 8064。将数据分成12段后,数据格式为1280 × 32 × 672 × 12,再将数据替换为15360 × 32 × 672。数据被送入CNN-BiLSTM-MHSA网络,其中批处理大小为16。采用留一个被试的交叉验证方法,然后以5为阈值区分高低状态,大于5的设置高标签为1,其余设置低标签为0。在DEAP数据集上获得的效价状态训练和验证准确率分别为99.07%和95.12%。唤醒状态下的训练和验证准确率分别为99.12%和94.62%。优势态的训练和验证准确率分别为99.25%和94.32%,偏好态的训练和验证准确率分别为99.02%和94.25%。
In the validating split process, this paper defines the training and validation ratio as 7:2, and the remaining data is used as a test model. The training steps are repeated for each emotional state (valence, arousal, dominance, and liking), and the classification training result graph is shown in Figure 7. All training and testing procedures proposed in this study were performed on a server with 4 Nvidia GeForce RTX2080Ti GPUs and 256 GB RAM by using Cuda 11. Pytorch version 1.11.
在验证分割过程中,本文将训练与验证的比例定义为7:2,剩余数据作为测试模型。对每种情绪状态(效价、唤醒、优势和偏好)重复训练步骤,分类训练结果图如图7所示。本研究中提出的所有训练和测试过程均在使用Cuda 11的4块Nvidia GeForce RTX2080Ti gpu和256 GB RAM的服务器上进行。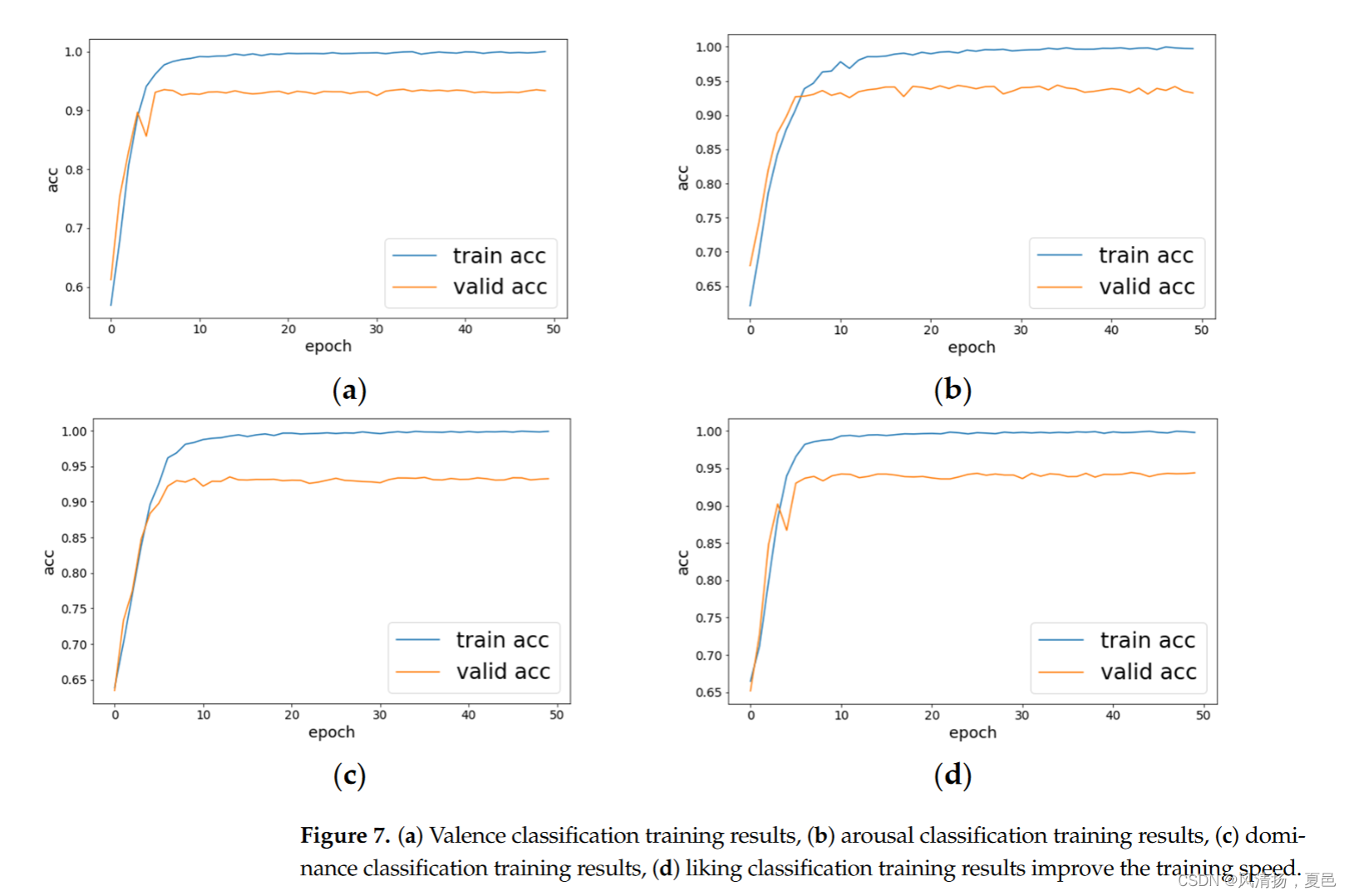
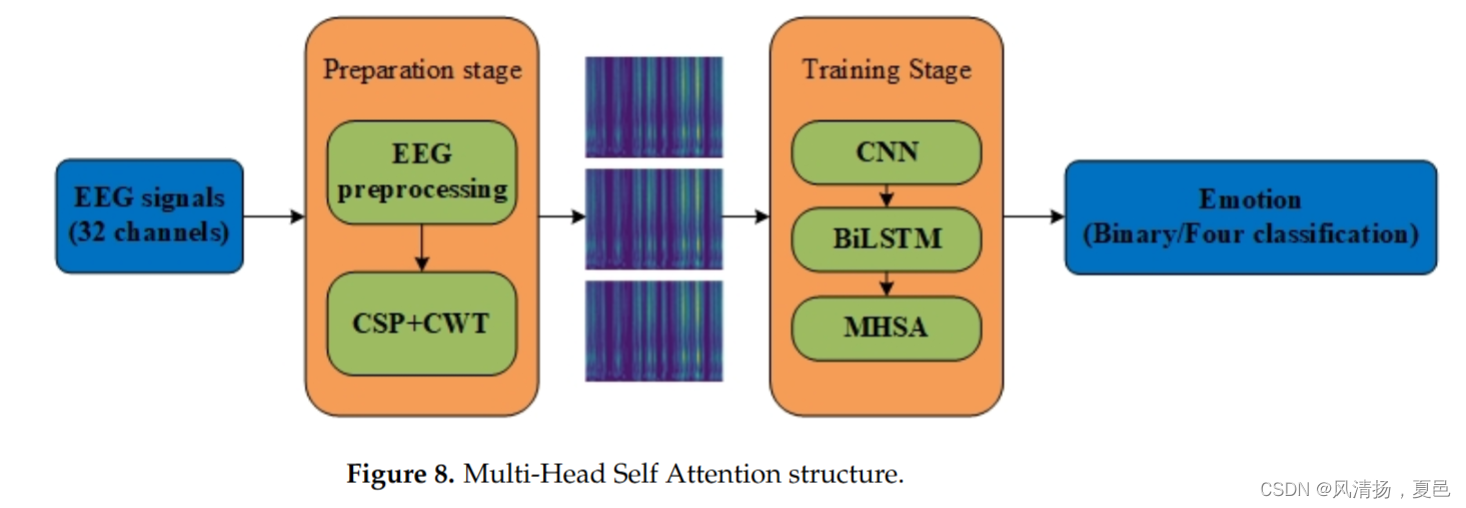
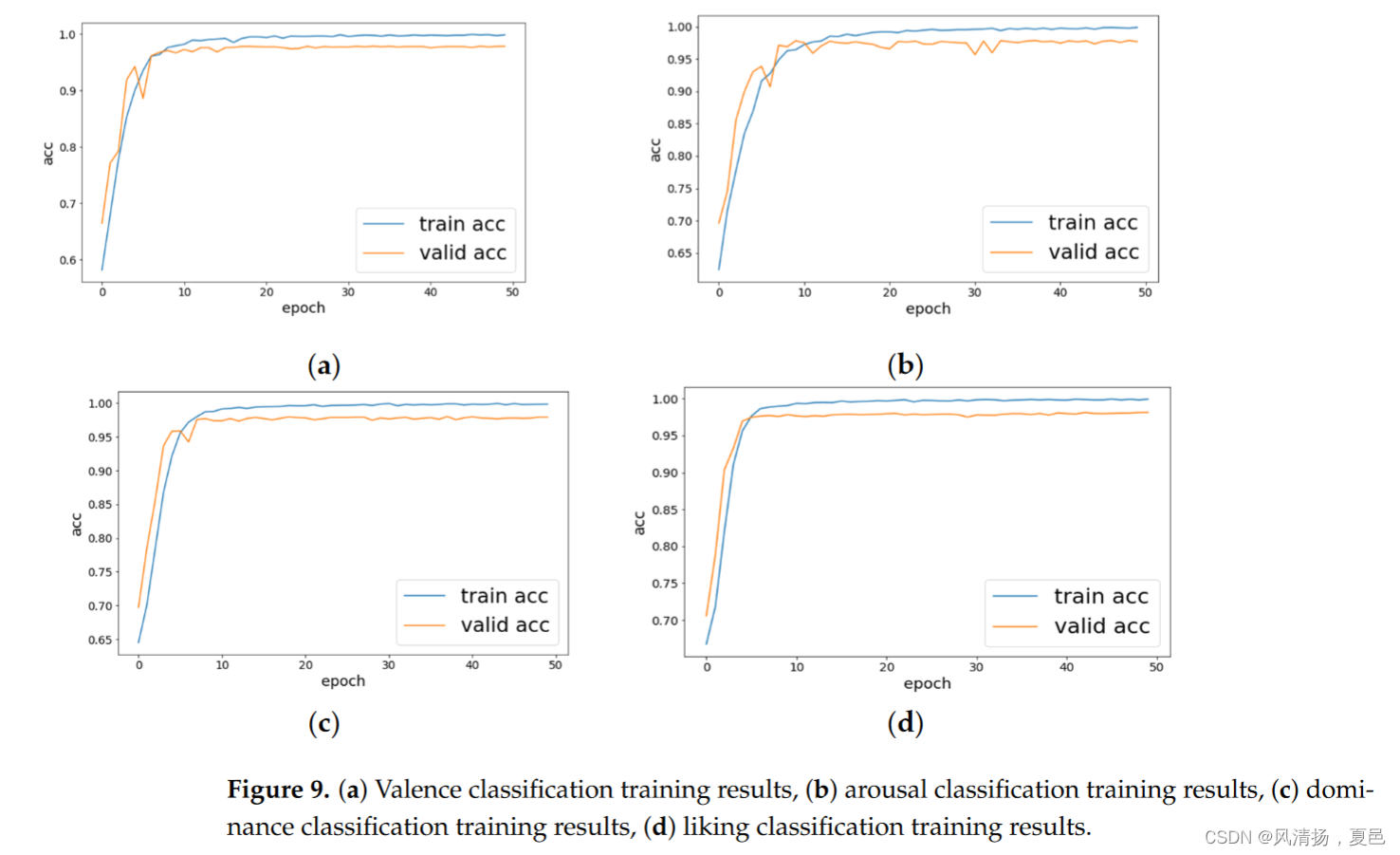
Experiment 2 using the time–frequency diagrams of CSP and CWT as input data is shown in Figure 8, and the method used is referred to as CP-CNN-BiLSTM-MHSA.The images are used as data input to CNN-BiLSTM-MHSA, and the input to CNN is a 20 × 65 × 3 time–frequency map. To perform better feature extraction of the image, the CNN in this paper is designed as a two-dimensional convolution of two layers, the original data 1280 × 32 × 8064 is transformed into 7680 × 32 × 20 × 65 and then sent into the CNN in the form of padding after the convolution operation to obtain the dimension 7680 × 64 × 20 × 65, and then after pooling down sampling it becomes 7680 × 64 × 10 × 32 and when sent into the next CNN layer and pooling layer becomes 7680 × 128 × 5 × 16. The whole training process has 102,977 training parameters. The training is based on cross-entropy function optimization and back-propagation of stochastic gradient descent for network training, and the optimizer continues to use Adam with a learning rate of 0.0001 and 50 iterations. The average accuracy of training and testing in high and low valence, arousal, dominance, and liking states was 99.98 and 98.10% respectively . Their other performance index F1 score values were 98.22%, 98.02%, 98.17%, and 98.11% respectively . The training accuracy is improved by about 4% compared to the experiments with the time series of input EEG, and the training accuracy and test accuracy shown in Figure 9.
以CSP和CWT的时频图作为输入数据的实验2如图8所示,使用的方法称为CP-CNN-BiLSTM-MHSA。将图像作为CNN- bilstm - mhsa的数据输入,CNN的输入是一张20 × 65 × 3的时频图。为了更好地对图像进行特征提取,本文将CNN设计为两层二维卷积,将原始数据1280 × 32 × 8064变换为7680 × 32 × 20 × 65,经过卷积运算后以填充的形式送入CNN,得到维度为7680 × 64 × 20 × 65,然后经过池化降采样变为7680 × 64 × 10 × 32,送入下一个CNN层和池化层变为7680 × 128 × 5 × 16。整个训练过程共有102 977个训练参数。训练基于交叉熵函数优化和随机梯度下降反向传播进行网络训练,优化器继续使用学习率为0.0001的Adam,迭代50次。高、低效价、唤醒度、优势度和偏好度状态下训练和测试的平均正确率分别为99.98 %和98.10 %。其他性能指标F1得分值分别为98.22 %、98.02 %、98.17 %、98.11 %。与输入EEG时间序列的实验相比,训练精度提高了约4 %,训练精度和测试精度如图9所示。
4 . 3 .脑电情绪四分类实验
In this paper, four classes of high and low valence-arousal (HALV, HAHV, LALV, LAHV) were studied. The first 32 channels of data were selected, and the total duration of the data experiment was 40 min, all of which yielded 1280 labels, classified using HALV, HAHV, LALV, and LAHV labels. Based on the positive and negative deviations of potency and arousal, we mapped each trial into four quadrants to form an effective classification label. It was possible to classify HALV = 352, HAHV = 348, LALV = 282, and LAHV = 298. The segmented data and labels are fed into the CNN-BiLSTM-MHSA network with a training and validation ratio of 7:2, using the cross-validation method. The scored data and labels were fed into the CNN-BiLSTM-MHSA network with a training to validation ratio of 7:2, using a cross-validation method, and the average validation and testing accuracy of the four classifications for high and low validity and arousal was 89.58 and 85.57%; the training results are shown in Figure 10a.
----
本文以4类高、低效价-唤醒度( HALV、HAHV、LALV、LAHV)为研究对象。选取前32通道数据,数据实验总时长为40 min,共产生1280个标签,使用HALV、HAHV、LALV和LAHV标签进行分类。基于效价和唤醒度的正负偏差,我们将每个试次映射到四个象限,形成有效的分类标签。可以分类出HALV = 352,HAHV = 348,LALV = 282,LAHV = 298。将分割后的数据和标签输入训练和验证比例为7:2的CNN - BiLSTM - MHSA网络,采用交叉验证的方法。将打分后的数据和标签输入训练与验证比例为7:2的CNN - BiLSTM - MHSA网络中,采用交叉验证的方法,对高、低效率和唤醒度的四种分类的平均验证和测试准确率分别为89.58 %和85.57 %;训练结果如图10a所示。
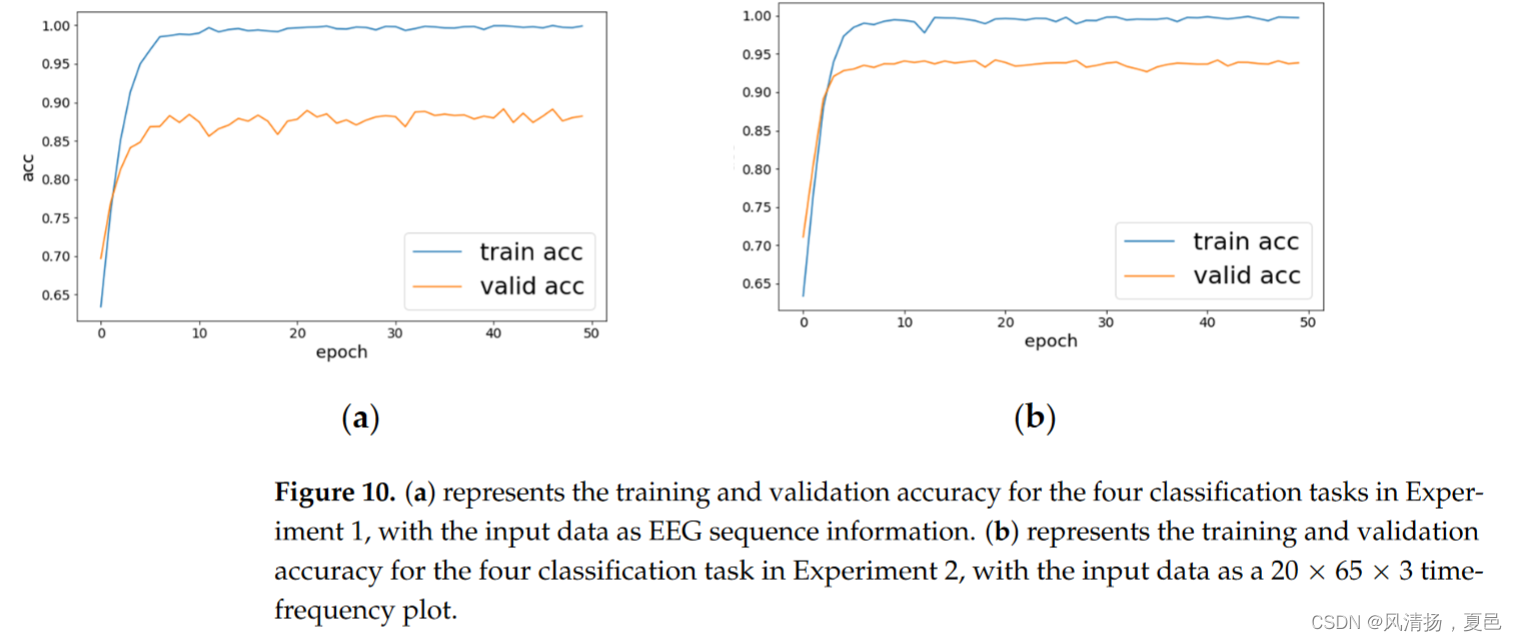
在高唤醒和低唤醒四分类中,第二种方法研究了使用CWT从CSP空间滤波信号的时频图中提取特征进行分类,输入20 × 65 × 3个时频图。该网络基于交叉熵函数优化和反向传播随机梯度下降进行训练,优化器使用Adam,学习率为0.0001,经过多次50次迭代。高效唤醒态和低效唤醒态验证和测试的平均正确率分别为92.89和89.33%。与训练a相比,训练精度提高了4%。
4 . 4 .实验对比
In this paper, the proposed CNN-BiLSTM-MASH fusion model is compared in ablation experiments on DEAP dataset by fusing convolutional neural network, long and short-term memory network, and attention mechanism with each other. The compared models are LSTM, BiLSTM, CNN-LSTM, CNN-BiLSTM, CNN-BiLSTM-Attention, and CNN-BiLSTMMASH. all models are used on the DEAP dataset to compare the models on datasets for testing accuracy and time complexity of training and testing. The datasets in all experiments were divided into 7:2:1 patterns and tested on the server. The architecture has a training time of 88.57 s for one epoch on the dataset and a testing time of 11.41 s for the same cycle, and all the results are shown in Table 7.
本文通过将卷积神经网络、长短期记忆网络和注意机制相互融合,在DEAP数据集上对所提出的CNN-BiLSTM-MASH融合模型进行消融实验比较。比较的模型是LSTM、BiLSTM、CNN-LSTM、CNN-BiLSTM、CNN-BiLSTM- attention和CNN-BiLSTMMASH。在DEAP数据集上使用所有模型,比较数据集上的模型对训练和测试的测试精度和时间复杂度。所有实验中的数据集被分成7:2:1的模式,在服务器上进行测试。该架构在数据集上一个epoch的训练时间为88.57 s,同一周期的测试时间为11.41 s,所有结果如表7所示。
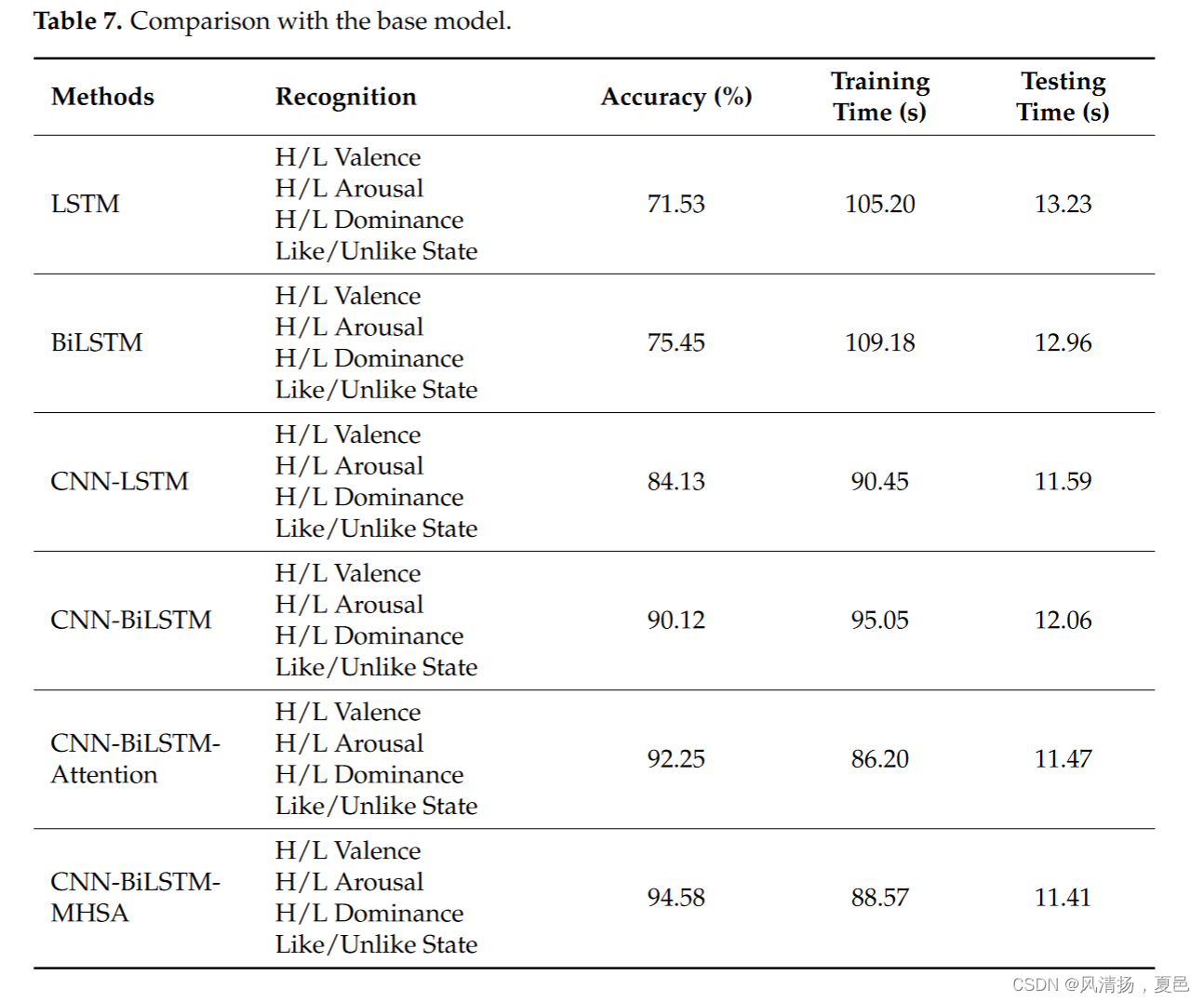
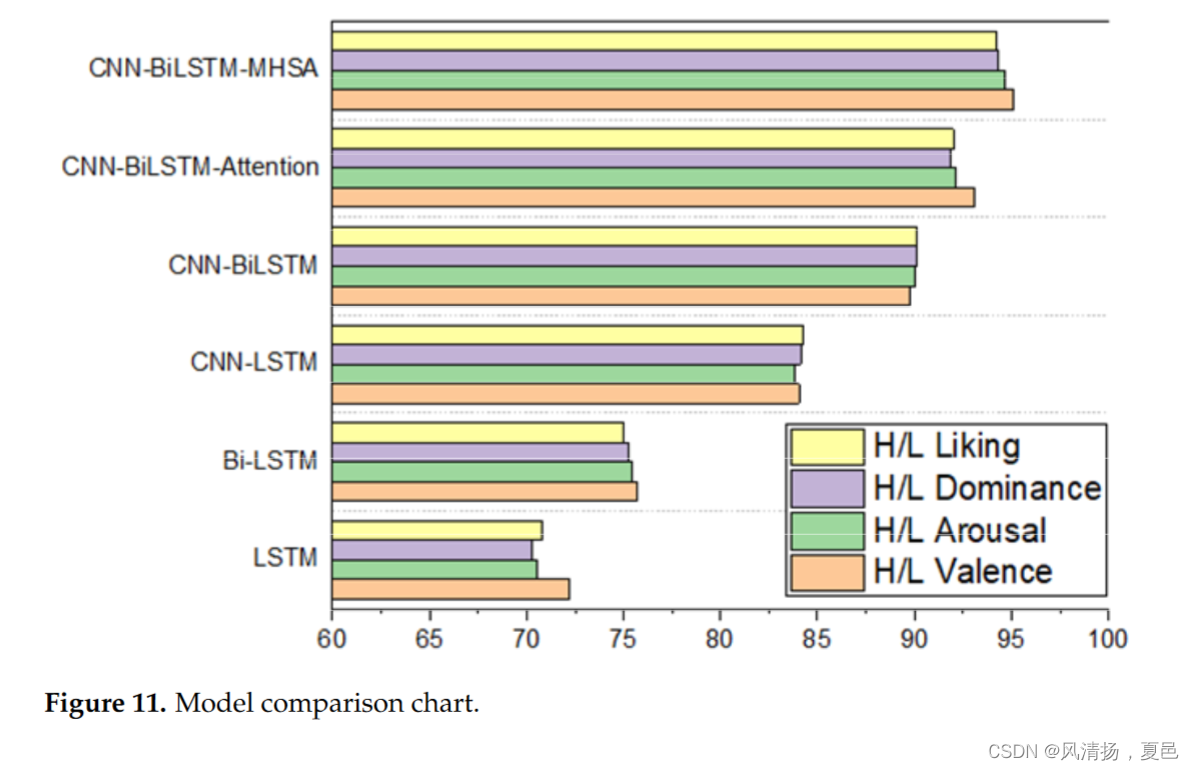
It can be seen that only one layer of the LSTM network works poorly because a single sample point is only a single data point at the time of input. Since most of the EEG signals are long, the DEAP dataset used in this paper, for example, has a signal length of 40 min and 8064 sampling points. Therefore, the single-layer LSTM cannot understand the relationship between the 1st second (sample point 1) and 60 s (sample point 8064) after the input sequence. The subsequent addition of the CNN network combined with LSTM brings a huge improvement, which means that the smoothing and convolutional signals of the 1D convolutional network have better performance for the training of LSTM, thus solving the problem of long-time sequence training of LSTM. While the addition of a bidirectional two-layer LSTM structure allows the before-and-after time series to be understood, improving the accuracy by about 6%, the addition of an attention mechanism on top of it brings a slight improvement, increasing the accuracy by about 2%. In this paper, we propose a fusion model combining one-dimensional convolution, a bi-directional two-layer LSTM, and a multi-headed self-attentive mechanism. Among them, BiLSTM can utilize both earlier and later sequence information, which helps to explore deep cognition from EEG sequence signals, while the addition of a multi-headed self-attention mechanism is superior to single-headed attention. The CNN-BiLSTM-MHSA model studied in this paper achieves an average accuracy of 94.58% for quadratic binary classification, and the comparison graph is shown in Figure 11.
可以看出,LSTM网络中只有一层效果很差,因为在输入时单个样本点只是单个数据点。由于大多数EEG信号都很长,因此本文使用的DEAP数据集的信号长度为40 min,采样点为8064个。因此,单层LSTM无法理解输入序列后的第1秒(采样点1)和第60秒(采样点8064)之间的关系。随后加入的CNN网络结合LSTM带来了巨大的改进,这意味着1D卷积网络的平滑和卷积信号对LSTM的训练有更好的性能,从而解决了LSTM长时间序列训练的问题。增加双向两层LSTM结构可以理解前后时间序列,提高准确率约6%,而在其上增加注意机制则略有提高,提高准确率约2%。本文提出了一种结合一维卷积、双向两层LSTM和多头自关注机制的融合模型。其中,BiLSTM可以同时利用较早和较晚的序列信息,有助于从脑电序列信号中挖掘深层认知,同时增加多头自注意机制优于单多头注意机制。本文研究的CNN-BiLSTM-MHSA模型对二次二元分类的平均准确率达到94.58%,对比图如图11所示。
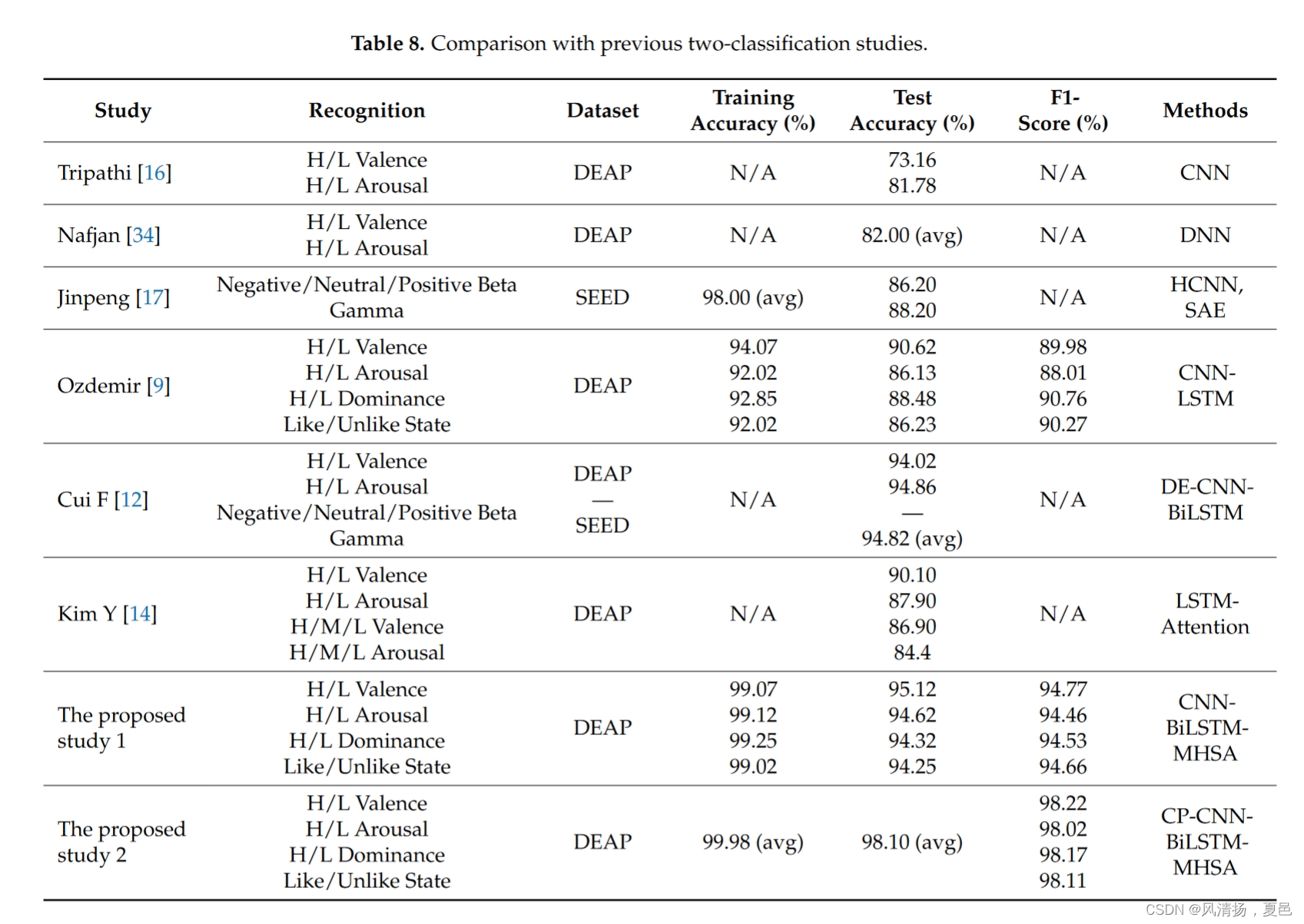
The results of the dichotomous classification experiments were compared with other dichotomous classification studies using DEAP databases or CNN and DNN types, and the corresponding results are given in Table 8. Compared with single CNN and DNN [16,34], the method in this paper shows a great improvement, which demonstrates that dynamic temporal features have a great impact on the accuracy of sentiment recognition, and single spatial or temporal features are poorly recognized. The key information of past and future in temporal dynamic features is also important. The CNN-LSTM [17] has no learning of future emotional states in EEG time series signals, accuracy is still low. The DE-CNNBiLSTM [12] fully considers the complexity and spatial structure of the brain and considers the temporal properties of dynamic EEG signals. However, there is no learning of time– frequency features, and no self-attention mechanism is used to redistribute the weights of EEG emotional key information. There is no convolutional smoothing signal processed by CNN in LSTM-Attention [14], no resolution of spatial structure, just resolution of a single time series with attention. In contrast to these studies, the CP-CNN-BiLSTM-MHSA method proposed in this paper improves the spatial information in the EEG signal, and the features in the time–frequency domain are analyzed and then input to the network as a time–frequency map. This feature information was re-extracted using CNN, for the dynamic temporal features present in the EEG, and then the future and past key sentiment information in it was fully learned using BiLSTM. Finally , the weight of this information is redistributed using a self-attentive mechanism, making the network more capable of recognizing this information. In the comparison of binary classification in the DEAP dataset, the proposed method in this paper is significant in sentiment recognition research enhancement.
将二分类实验结果与使用DEAP数据库或CNN和DNN类型的其他二分类研究结果进行比较,结果如表8所示。与单一的CNN和DNN[16,34]相比,本文的方法有了很大的改进,这表明动态时间特征对情感识别的准确性影响很大,而单一的空间或时间特征识别效果较差。时间动态特征中过去和未来的关键信息也很重要。CNN-LSTM[17]没有学习在脑电图时间序列信号中预测未来情绪状态,准确率仍然较低。DE-CNNBiLSTM[12]充分考虑了大脑的复杂性和空间结构,并考虑了动态脑电信号的时间特性。然而,该方法没有学习时频特征,也没有使用自注意机制来重新分配脑电情绪关键信息的权重。LSTM-Attention[14]中没有经过CNN处理的卷积平滑信号,没有对空间结构的分辨率,只是对单个时间序列的具有注意力的分辨率。与这些研究相比,本文提出的CP-CNN-BiLSTM-MHSA方法改进了脑电信号中的空间信息,对其时频域特征进行分析,然后以时频图的形式输入到网络中。利用CNN重新提取EEG中存在的动态时间特征,然后利用BiLSTM充分学习EEG中未来和过去的关键情感信息。最后,使用自关注机制重新分配这些信息的权重,使网络更有能力识别这些信息。在DEAP数据集的二值分类对比中,本文提出的方法在情感识别研究中具有重要的增强作用。
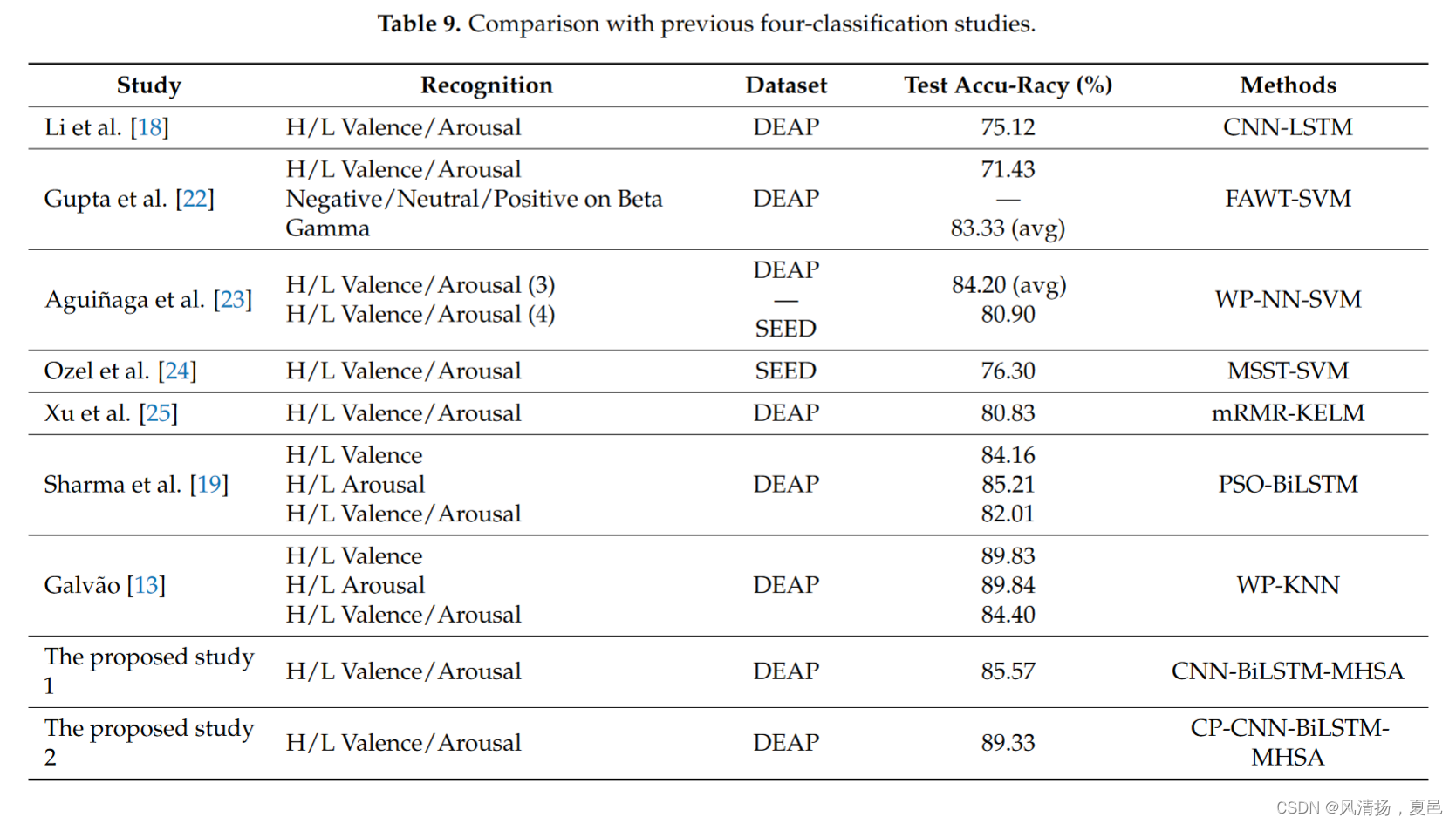
The results of the four-classification experiment were compared with the previous two-dimensional potency-arousal four-classification studies of HALV, HAHV, LALV, and LAHV using the DEAP dataset, and the results are shown in Table 9. The CNN-LSTM [18] fuses the spatial, frequency domain, and temporal features of the original EEG signal, but the recognition accuracy is still low for the four-classification tasks. The SVM [22–24] used wavelets to decompose and extract the time–frequency features and smoothed the features into the SVM but did not improve the spatial information and dynamic time features of the EEG. The PSO-BiLSTM [19] deep learning techniques based on long and short-term memory are used to retrieve emotional changes from optimized data corresponding to labeled EEG signals and to remove repetitive information, but this also lacks learning of spatial and time–frequency features. The WP-KNN [13], on the other hand, does not analyze the dynamic time features. In summary , the method proposed in this paper fully analyzes the dynamic temporal features and spatial information present in EEG and is effective in four-category sentiment recognition.
利用DEAP数据集将四分类实验结果与之前HALV、HAHV、LALV、LAHV的二维效价-唤醒度四分类研究进行对比,结果如表9所示。CNN-LSTM [ 18 ]融合了原始EEG信号的空间、频域和时间特征,但对于四分类任务,识别精度仍然较低。SVM [ 22-24 ]使用小波分解提取时频特征并将特征平滑到SVM中,但没有改善EEG的空间信息和动态时间特征。基于长短期记忆的PSO - Bi LSTM [ 19 ]深度学习技术用于从标记EEG信号对应的优化数据中检索情感变化,去除重复信息,但也缺乏对空间和时频特征的学习。另一方面,WP-KNN [ 13 ]没有分析动态时间特征。综上所述,本文提出的方法充分分析了EEG中存在的动态时间特征和空间信息,在四分类情感识别中效果良好。
5.结果
In this paper, we classify EEG emotions in four dimensions, namely potency , arousal, dominance, and preference. A deep learning approach is proposed to analyze emotional states using deep learning. We proposed a CNN-BiLSTM-MASH model for EEG emotion classification and also extracted emotion features by scale maps. Experiments were conducted on the DEAP dataset, and it was concluded that the proposed framework achieves better results in experiments with dichotomous and quadruple classifications. The analysis of one-dimensional EEG signals is performed using data segmentation to increase the training number, and after CNN smoothing of the signal as well as pooled down sampling, BiLSTM is used to obtain the future and past correlation features of the sentiment time series. The weighted redistribution of hidden features using multi-headed self-attentiveness improves the EEG sentiment recognition accuracy , and the proposed CP-CNN-BiLSTMMASH model is used to extract the sentiment features by CSP filtered scale maps to extract emotion features, which has a good effect on the four classification results.
In recent years, with the development of deep learning technology , the models applied to EEG emotion recognition have become more and more diverse. In this paper, we propose a new fusion deep learning model with new enhancements on the DEAP dataset, but there is still much room for improvement in four-category recognition. In the future, we plan to conduct improved deep training in this area.
在本文中,我们将EEG情绪分为四个维度,即效能、觉醒、支配和偏好。提出了一种利用深度学习分析情绪状态的深度学习方法。提出了一种基于CNN-BiLSTM-MASH的脑电情感分类模型,并利用比例图提取情感特征。在DEAP数据集上进行了实验,结果表明该框架在二分类和四分类实验中取得了较好的效果。对一维脑电信号进行数据分割,增加训练次数,对信号进行CNN平滑和池化下采样后,利用BiLSTM得到情绪时间序列的未来和过去相关特征。利用多头自注意对隐藏特征进行加权再分配,提高了脑电情感识别的准确性,并采用所提出的CP-CNN-BiLSTMMASH模型,通过CSP滤波的尺度图提取情感特征提取情感特征,对四种分类结果均有较好的效果。
近年来,随着深度学习技术的发展,应用于脑电情感识别的模型也越来越多样化。在本文中,我们提出了一种新的融合深度学习模型,并在DEAP数据集上进行了新的增强,但在四分类识别方面仍有很大的改进空间。未来,我们计划在这方面进行更完善的深度训练。

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)