论文阅读_音频表示_wav2vec_2.0
模型用于语音识别,模型结构结合了CNN和Transformer。文章言简意赅,结构非常舒服。
论文信息
name_en: wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
name_ch: wav2vec 2.0:语音表示自监督学习框架
paper_addr: http://arxiv.org/abs/2006.11477
date_read: 2023-04-27
date_publish: 2020-10-22
tags: [‘深度学习’,‘音频表示’]
author: Alexei Baevski,Facebook AI
code: https://github.com/pytorch/fairseq
1 读后感
模型用于语音识别,模型结构结合了CNN和Transformer。文章言简意赅,结构非常舒服。
2 摘要
先从未标注语音中学习音频的表示,然后通过少量标注数据精调,得到模型优于用大量标注数据训练的模型,且其原理非常简单。
仅使用十分钟的标记数据和 53k 小时的未标记数据的预训练,可达到 4.8/8.2 WER。这证明了使用有限数量的标记数据进行语音识别的可行性。
3 介绍
语音识别系统一般需要成千上万小时的转录语音(语音+对应文本)才能达到可接受的性能,而对于全球近7,000种语言中的大多数来说,并没有这么多标注数据。
神经网络受益于大量无标记训练数据。自监督学习的方法,可从未标注的数据示例中学习通用的数据表示,再在标注数据上微调模型。这在自然语言处理,和计算机视觉中都取得了重要进步。
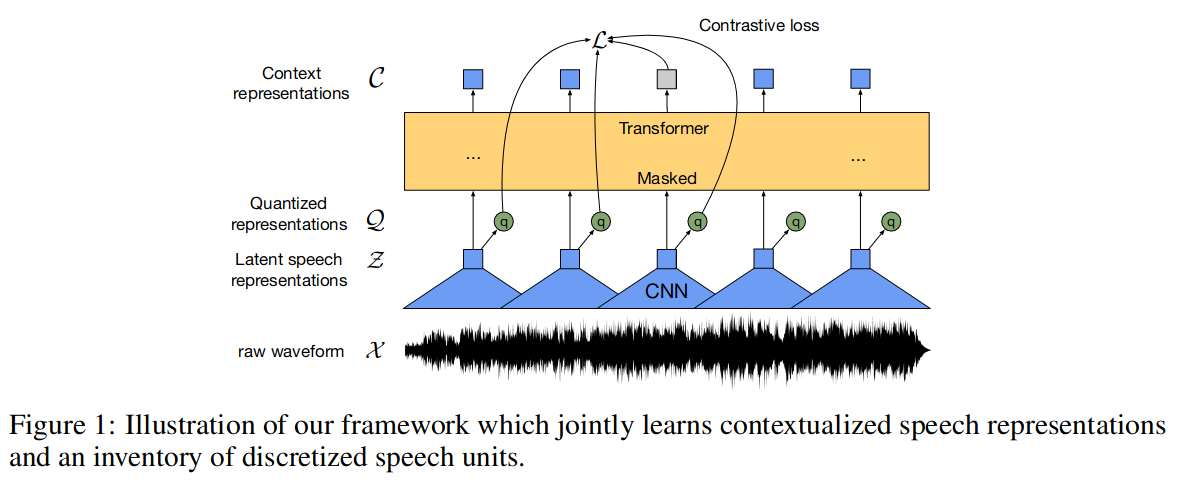
文中提出的一个自监督学习框架,旨在从原始音频数据中学习到通用的数据表示。该方法使用了多层卷积神经网络对语音音频进行编码,使用类似于NLP中mask的方法,通过Transformer网络来构建情境化的表示,并通过对比任务来训练模型。
4 模型
模型先使用卷积网络将输入音频X映射到隐空间Z,然后将Z送入Transformer网络构建表示C以便从上下文中提取相关信息;另外特征编码Z还被送入量化工具,以生成量化后的表示Q(离散)。从而学习了音频的表示。
4.1 特征编码器
编码器由多个块组成,其中包含时间卷积,然后是层归一化 和 GELU 激活函数。输入到编码器的原始波形被归一化为零均值和单位方差。编码器输出到 Transformer 。
4.2 通过Transformer结合上下文 表示
特征编码器的输出被送到Transformer 架构的上下文网络。使用卷积层作为相对位置嵌入。我们将卷积的输出和 GELU 添加到输入中,然后应用层归一化。
4.3 量化模型
在自监督训练阶段,通过乘法量化将特征编码器 z 的输出离散化为有限的语音表示集。乘积量化相当于从多个码本中选择量化表示并将它们连接起来。给定 G 个码本或组,从每个码本中选择一个条目并连接生成向量 e1, …, eG 并应用线性变换。Gumbel softmax 支持以完全可微分的方式选择离散码本条目。
5 训练&实验
5.1 Masking
类似BERT的Mask方法,Mask掉部分Encoder后的特征,随机无重复地选择一定比例的时间步作为起始点,并屏蔽每个起始点连续M个时间步,屏蔽区间可能会重叠。
5.2 目标
预训练时,通过对比学习优化损失函数Lm,同时使用损失Ld以鼓励模型使用codebook。
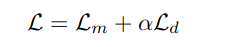
其中a为超参数。
5.2.1 对比学习的损失
上下文网络输出的c,q为量化隐空间的表示:
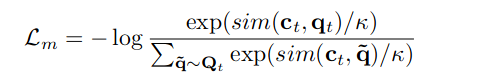
sim用于计算上下文表式与量化隐空间的距离。
5.2.2 多样性损失

5.3 精调
预训练模型针对语音识别进行了微调:使用Librispeech数据集,通过在上下文网络顶部添加一个线性投影,将音频表示映射到分类任务中,通过最小化 CTC 损失来优化模型。
LibriSpeech是一个包含大约1000小时16kHz英语读音的语料库,数据源自LibriVox项目的有声读物,并经过仔细的分段和对齐。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)