
automodel.from_pretrained 使用本地缓存模型(huggingface.co 链接报错时可用)
huggingface.co 链接报错时可用
一键AI生成摘要,助你高效阅读
问答
·
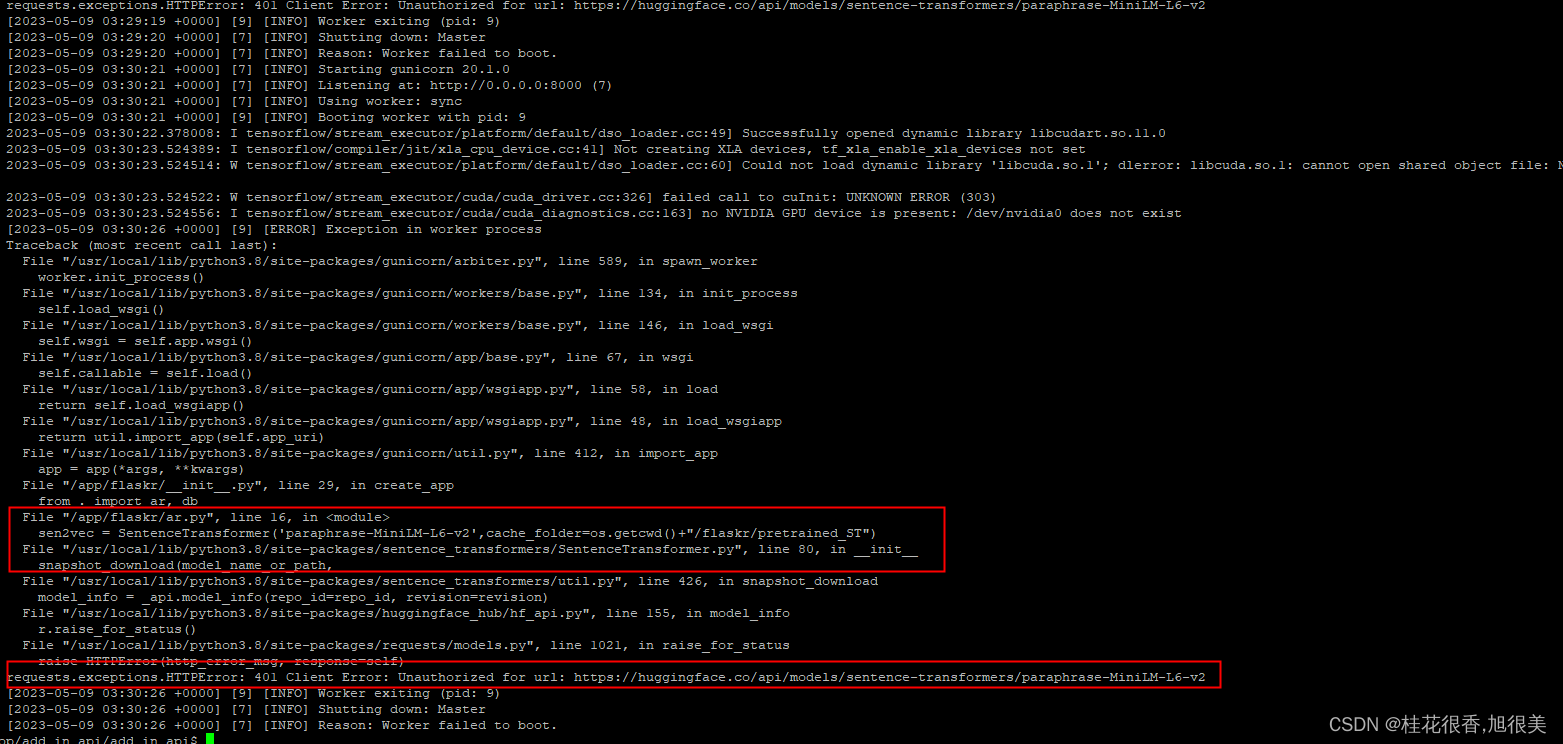
huggingface.co 链接报错
Automodel.from_pretrained()和AAutoTokenizer.from_pretrained()同理
第一次缓存模型到指定文件夹
from transformers import AutoTokenizer, AutoModel
sen_trans_pretrained_path = os.path.join(PWD, "pretrained_w", "sentence-transformers")
model_name = 'sentence-transformers/all-MiniLM-L6-v2'
tokenizer = AutoTokenizer.from_pretrained(
model_name,
cache_dir=os.path.join(sen_trans_pretrained_path, "tokenizer"))
model = AutoModel.from_pretrained(
model_name,
cache_dir=os.path.join(sen_trans_pretrained_path, "model"))
cache_dir 指定要保存的本地目录,方便后面使用
报错后使用本地缓存model和tokenizer
from transformers import AutoTokenizer, AutoModel
sen_trans_pretrained_path = os.path.join(PWD, "pretrained_w", "sentence-transformers")
tail = 'models--sentence-transformers--all-MiniLM-L6-v2/snapshots/7dbbc90392e2f80f3d3c277d6e90027e55de9125'
tokenizer = AutoTokenizer.from_pretrained(
pretrained_model_name_or_path = os.path.join(sen_trans_pretrained_path, "tokenizer",tail))
model = AutoModel.from_pretrained(
pretrained_model_name_or_path = os.path.join(sen_trans_pretrained_path, "model", tail))
pretrained_model_name_or_path 为之前缓存的模型和tokenizer的最里层目录
最里层目录指的是:
- 对于tokenizer 要到词表和config这一层:

- 对于model 要到bin这一层:

另一个例子
缓存
from sentence_transformers import SentenceTransformer
sen2vec = SentenceTransformer('paraphrase-MiniLM-L6-v2',cache_folder=os.getcwd()+"/flaskr/pretrained_ST")
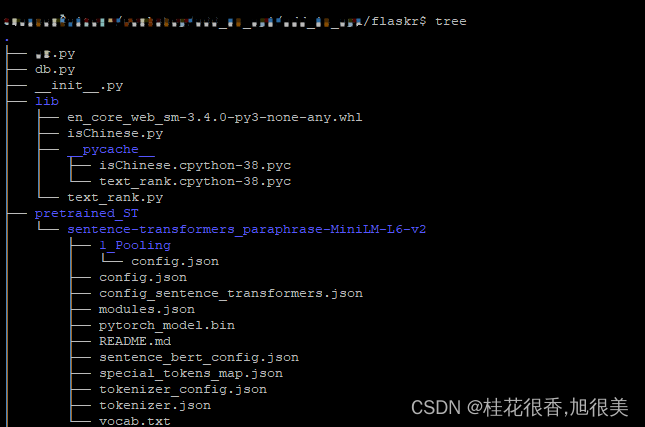
本地调用
from sentence_transformers import SentenceTransformer
sen2vec = SentenceTransformer(os.getcwd()+"/flaskr/pretrained_ST/sentence-transformers_paraphrase-MiniLM-L6-v2")
参考
AutoTokenizer
AutoModel
SSLError: HTTPSConnectionPool(host=‘huggingface.co’, port=443)
class AutoTokenizer: 源码
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs):
r""" Instantiate one of the tokenizer classes of the library
from a pre-trained model vocabulary.
The tokenizer class to instantiate is selected
based on the `model_type` property of the config object, or when it's missing,
falling back to using pattern matching on the `pretrained_model_name_or_path` string:
- `t5`: T5Tokenizer (T5 model)
- `distilbert`: DistilBertTokenizer (DistilBert model)
- `albert`: AlbertTokenizer (ALBERT model)
- `camembert`: CamembertTokenizer (CamemBERT model)
- `xlm-roberta`: XLMRobertaTokenizer (XLM-RoBERTa model)
- `longformer`: LongformerTokenizer (AllenAI Longformer model)
- `roberta`: RobertaTokenizer (RoBERTa model)
- `bert-base-japanese`: BertJapaneseTokenizer (Bert model)
- `bert`: BertTokenizer (Bert model)
- `openai-gpt`: OpenAIGPTTokenizer (OpenAI GPT model)
- `gpt2`: GPT2Tokenizer (OpenAI GPT-2 model)
- `transfo-xl`: TransfoXLTokenizer (Transformer-XL model)
- `xlnet`: XLNetTokenizer (XLNet model)
- `xlm`: XLMTokenizer (XLM model)
- `ctrl`: CTRLTokenizer (Salesforce CTRL model)
- `electra`: ElectraTokenizer (Google ELECTRA model)
Params:
pretrained_model_name_or_path: either:
- a string with the `shortcut name` of a predefined tokenizer to load from cache or download, e.g.: ``bert-base-uncased``.
- a string with the `identifier name` of a predefined tokenizer that was user-uploaded to our S3, e.g.: ``dbmdz/bert-base-german-cased``.
- a path to a `directory` containing vocabulary files required by the tokenizer, for instance saved using the :func:`~transformers.PreTrainedTokenizer.save_pretrained` method, e.g.: ``./my_model_directory/``.
- (not applicable to all derived classes) a path or url to a single saved vocabulary file if and only if the tokenizer only requires a single vocabulary file (e.g. Bert, XLNet), e.g.: ``./my_model_directory/vocab.txt``.
cache_dir: (`optional`) string:
Path to a directory in which a downloaded predefined tokenizer vocabulary files should be cached if the standard cache should not be used.
force_download: (`optional`) boolean, default False:
Force to (re-)download the vocabulary files and override the cached versions if they exists.
resume_download: (`optional`) boolean, default False:
Do not delete incompletely recieved file. Attempt to resume the download if such a file exists.
proxies: (`optional`) dict, default None:
A dictionary of proxy servers to use by protocol or endpoint, e.g.: {'http': 'foo.bar:3128', 'http://hostname': 'foo.bar:4012'}.
The proxies are used on each request.
use_fast: (`optional`) boolean, default False:
Indicate if transformers should try to load the fast version of the tokenizer (True) or use the Python one (False).
inputs: (`optional`) positional arguments: will be passed to the Tokenizer ``__init__`` method.
kwargs: (`optional`) keyword arguments: will be passed to the Tokenizer ``__init__`` method. Can be used to set special tokens like ``bos_token``, ``eos_token``, ``unk_token``, ``sep_token``, ``pad_token``, ``cls_token``, ``mask_token``, ``additional_special_tokens``. See parameters in the doc string of :class:`~transformers.PreTrainedTokenizer` for details.
Examples::
# Download vocabulary from S3 and cache.
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
# Download vocabulary from S3 (user-uploaded) and cache.
tokenizer = AutoTokenizer.from_pretrained('dbmdz/bert-base-german-cased')
# If vocabulary files are in a directory (e.g. tokenizer was saved using `save_pretrained('./test/saved_model/')`)
tokenizer = AutoTokenizer.from_pretrained('./test/bert_saved_model/')

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)