

05_Flume之KafkaSource参数解析
Flume是一个开源的分布式日志收集系统,而Kafka是一个高吞吐量的分布式消息系统。KafkaSource是Flume中的Source类型之一,可以实现数据从Kafka到Flume的无缝传输。
一、介绍
Flume是一个开源的分布式日志收集系统,而Kafka是一个高吞吐量的分布式消息系统。
KafkaSource是Flume中的Source类型之一,可以实现数据从Kafka到Flume的无缝传输。
二、KafkaSource的特性:
- 可以通过配置选取特定的topic或者全部topic,并可以选择指定partition或全部partition。
- 可以支持多线程从Kafka中读取数据并发往Channel中。
- 可以配置是否自动提交offset,即保存消费位置的参数,来支持对数据消费的状态做精细的控制。
- 可以支持使用Kafka提供的Consumer Group机制,以及基于zookeeper的group机制,处理消息的负载均衡和failover机制。
- 可以自定义序列化和反序列化方式,可以配合不同的业务场景使用不同的序列化方案。
- 可以实现Kafka和Flume之间数据的格式转换。
三、KafkaSource的参数解析和用法:
| 序号 | 参数 | 默认值 | 描述 |
|---|---|---|---|
| 1 | type | 表示该Source的类型,需设置为org.apache.flume.source.kafka.KafkaSource | |
| 2 | kafka.bootstrap.servers | 无默认值 | 必填项,表示Kafka服务端的地址。 |
| 3 | kafka.topics | 无默认值 | 必填项,表示需要消费的topic名称列表,多个用“,”分隔。 |
| 4 | kafka.consumer.group.id | 空字符串 | 可选项,用于支持Kafka的消费者组机制,保证同一个组内的所有消费者共享partition。 |
| 5 | kafka.consumer.auto.offset.reset | latest | 可选项,用于设置当消费者刚启动时,处理哪些offset。有三种取值:smallest表示从最小的offset开始消费,largest表示从最大的offset开始消费,none表示在没有发现offset时抛出异常。 |
| 6 | batchSize | 100 | 该参数控制每次从Kafka获取的消息数量。默认情况下,该参数为100,即每次批量处理100条消息。如果需要一次获取更多的消息,则可以增加该值。但是请注意,过大的batchSize可能会导致一次性获取大量消息并在内存中缓存,从而导致系统性能下降。 |
| 7 | batchDurationMillis | 1000 | 该参数指定KafkaSource等待消息的时间间隔,以ms为单位。默认情况下,该参数值为1000,即每隔1s检查一次是否有新消息。如果需要更快地获取消息,则可以减小该值。请注意,过于频繁的检查新消息可能会增加网络和CPU负载,进而影响系统性能。 |
| 8 | kafka.consumer.auto.commit.enable | true | 可选项,若设置为true,表示是否自动提交offset;若设置为false,则需要通过Channel Processor手动提交offset,默认true。 |
| 9 | kafka.consumer.max.poll.records | 500 | 可选项,表示一次最多从Kafka中读取的记录数。 |
| 10 | kafka.key.deserializer | org.apache.kafka.common.serialization.StringDeserializer | 可选项,表示用于反序列化key的Deserializer类, |
| 11 | kafka.value.deserializer | org.apache.kafka.common.serialization.ByteArrayDeserializer。 | 可选项,表示用于反序列化value的Deserializer类 |
| 12 | parseAsFlumeEvent | false | 可选项,表示是否解析成Flume事件,默认为false,即将读取到的数据直接封装为KafkaEvent对象。 |
| 13 | selector.type | replicating | 事件选择器类型,可选参数,可选值为 和 multiplexing。默认值为 replicating,表示将事件复制到所有连接的 Channel;如果设置为 multiplexing,则将事件发送到通过拦截器链指定的单个 Channel。 |
| 14 | selector.optional | false | 当上述 selector.type 为 multiplexing 时,指示是否允许 Channel 缺失,可选参数,默认为 false。 |
| 15 | maxConcurrentPartitions | 1 | 最大并发分区数,可选参数,默认值为 1。该参数指定从多个分区中读取消息的并发度,可以设置为较高的值以提高吞吐量。 |
| 16 | pollTimeout | 5000 | 从 Kafka 中读取消息的轮询超时时间,另一个可选参数,单位为毫秒,默认值为 5000 毫秒。 |
| 17 | consumer.timeout.ms | 120000 | Kafka 消费者客户端等待 Broker 返回消息的响应超时时间,也是一个可选参数,默认值为 毫秒(即 2 分钟)。 |
| 18 | kafka.topic.whitelist | 用于白名单过滤,指定需要被消费的topic列表。 | |
| 19 | kafka.topic.blacklist | 用于黑名单过滤,指定不需要被消费的topic列表。 | |
| 20 | topicHeader | 将消息主题添加到 Flume 事件的头中,可选参数。 | |
| 21 | keyHeader | 将消息键添加到 Flume 事件的头中,可选参数。 |
除此之外,KafkaSource还有其他参数,例如
kafka.consumer.*系列参数,用于配置Kafka消费者相关参数,kafka.topic.*系列参数,用于配置Kafka topic参数,以及deserializer.*系列参数,用于配置数据序列化和反序列化方式等。这些参数的具体含义和用法可以通过查看Flume官方文档或Kafka官方文档进行了解。
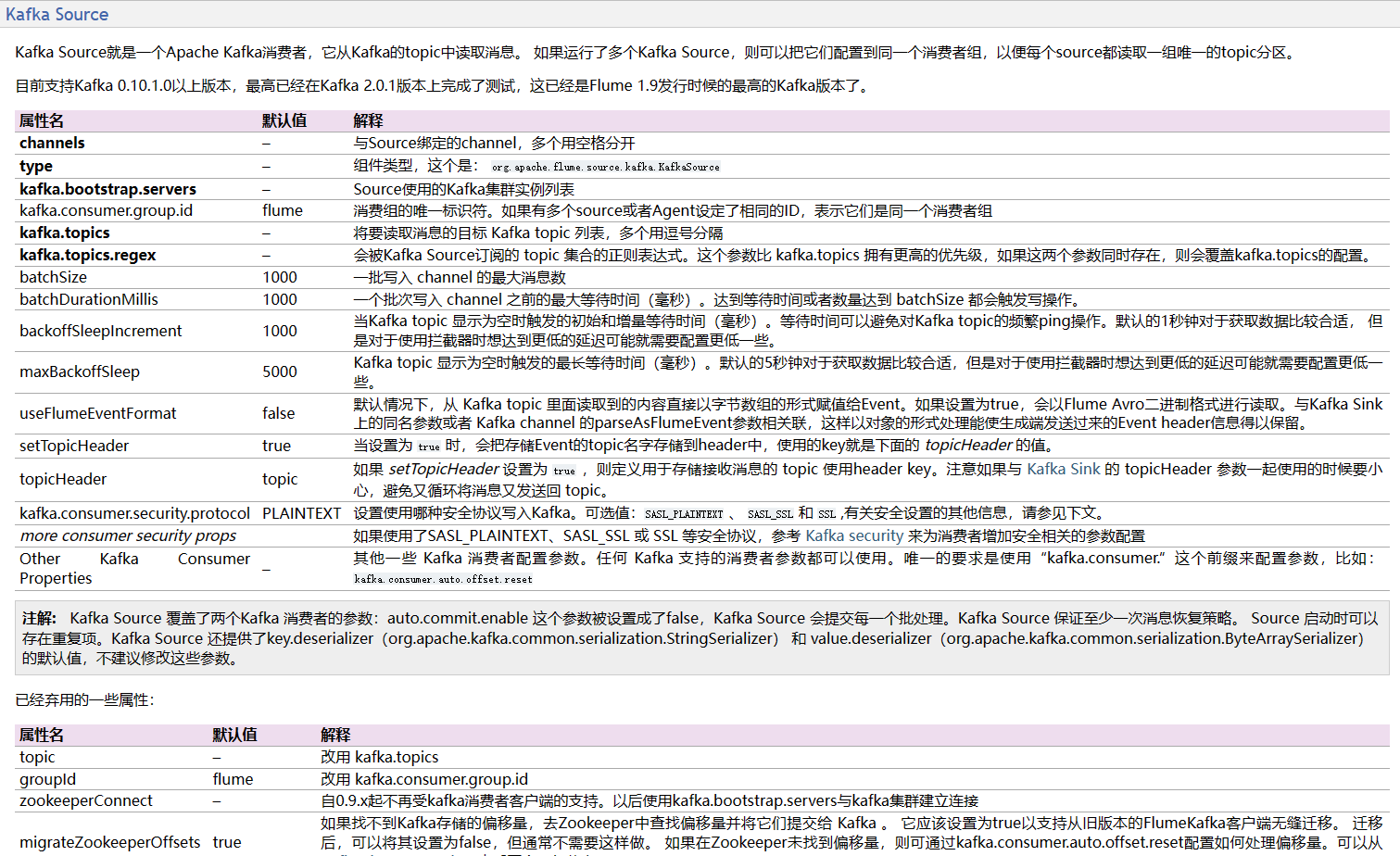
四、其它参数:
| 序号 | 参数名称 | 默认值 | 描述 |
|---|---|---|---|
| 1 | kafka.consumer.props | Kafka 消费者客户端属性值对,可选参数。该参数指定 Kafka 消费者客户端的属性值对,例如 auto.offset.reset=earliest, enable.auto.commit=false。 | |
| 2 | consumer.max.poll.records | 500 | 单次读取的最大消息数,可选参数,默认为 500。该参数指定 Kafka 消费者在一次轮询中最多读取的消息数量,建议不要将其设置过大。 |
| 3 | kafka.consumer.security.protocol | PLAINTEXT | Kafka 安全协议类型,可选参数,默认值为 PLAINTEXT。其他可选值包括 SASL_PLAINTEXT、SASL_SSL 等。 |
| 4 | kafka.ssl.truststore.location | SSL 客户端的信任库位置,可选参数。 | |
| 5 | kafka.ssl.truststore.password | SSL 客户端的信任库密码,可选参数。 | |
| 6 | kafka.ssl.keystore.location | SSL 客户端的密钥库位置,可选参数。 | |
| 7 | kafka.ssl.keystore.password | SSL 客户端的密钥库密码,可选参数。 | |
| 8 | kafka.ssl.key.password | SSL 密钥库中密钥的密码,可选参数。 | |
| 9 | kafka.consumer.headerFilterPattern | 需要保留的头信息的正则表达式,可选参数。如果设置了该参数,仅保留符合该正则表达式的头信息,不符合的头信息将被删除。 | |
| 10 | kafka.consumer.headersToLowerCase | false | 是否将头信息转换为小写字母,可选参数,默认为 false。如果设置为 true,则将所有头信息转换为小写字母。 |
| 11 | kafka.consumer.ssl.enabled.protocols | TLSv1.2, TLSv1.1, TLSv1 | SSL 支持的协议集合,用逗号分隔,可选参数,默认值为 TLSv1.2, TLSv1.1, TLSv1。 |
| 12 | kafka.consumer.ssl.truststore.type | JKS | Kafka Consumer SSL 客户端的信任库类型,可选参数,默认值为 JKS。 |
| 13 | kafka.consumer.ssl.keystore.type | JKS | Kafka Consumer SSL 客户端的密钥库类型,可选参数,默认值为 JKS。 |
| 14 | kafka.consumer.ssl.truststore.algorithm | SunX509 | Kafka Consumer SSL 客户端的信任库算法,可选参数,默认值为 SunX509。 |
| 15 | kafka.consumer.ssl.keystore.algorithm | SunX509 | Kafka Consumer SSL 客户端的密钥库算法,可选参数,默认值为 SunX509。 |
五、配置示例
# Name the source
agent1.sources.kafka-source.type = org.apache.flume.source.kafka.KafkaSource
# Set Kafka source properties
agent1.sources.kafka-source.kafka.bootstrap.servers = broker1:port,broker2:port,broker3:port
agent1.sources.kafka-source.kafka.topics = topic1,topic2,topic3
agent1.sources.kafka-source.batchSize = 5000
agent1.sources.kafka-source.batchDurationMillis = 2000
agent1.sources.kafka-source.kafka.consumer.group.id = flume_consumer_test
agent1.sources.kafka-source.kafka.consumer.auto.commit.enable = true
agent1.sources.kafka-source.kafka.consumer.auto.commit.interval.ms = 5000
agent1.sources.kafka-source.kafka.consumer.auto.offset.reset = earliest
agent1.sources.kafka-source.kafka.consumer.max.poll.records = 500
agent1.sources.kafka-source.kafka.consumer.fetch.max.wait.ms = 500
agent1.sources.kafka-source.interceptors = i1 i2
agent1.sources.kafka-source.interceptors.i1.type = timestamp
agent1.sources.kafka-source.interceptors.i2.type = static
agent1.sources.kafka-source.interceptors.i2.value = mytag
# 进一步调整优化
agent1.sources.kafka-source.rebalance.max.retries = 10
agent1.sources.kafka-source.rebalance.backoff.ms = 2000
agent1.sources.kafka-source.consumer.timeout.ms = 10000
agent1.sources.kafka-source.session.timeout.ms = 30000
agent1.sources.kafka-source.request.timeout.ms = 5000
agent1.sources.kafka-source.kafka.consumer.fetch.min.bytes = 1024
agent1.sources.kafka-source.kafka.consumer.fetch.max.bytes = 1048576
agent1.sources.kafka-source.kafka.consumer.fetch.max.wait.ms = 500
# Set channel and sink details
agent1.sources.kafka-source.channels = channel1
agent1.sinks.hdfs-sink.channel = channel1
上述配置中,我们设置了更多的Kafka和Flume参数,包括:
- 消费者超时时间
consumer.timeout.ms、会话超时时间session.timeout.ms和请求超时时间request.timeout.ms,分别控制消费者在不活动状态下被认为已经超时的时间、消费者与broker失去连接之前的时间、等待broker响应的最长时间。- 自动提交offset
auto.commit.enable和自动提交间隔时间auto.commit.interval.ms,用于控制消费者是否自动提交offset以及自动提交的时间间隔。fetch.max.wait.ms参数指定了poll()方法的最大等待时间,该值越小则会导致消费者的轮询速度变快但也可能会增加网络负载和服务器的负荷。rebalance.max.retries和rebalance.backoff.ms参数用于控制消费者组rebalance的次数和间隔时间,在发生故障时帮助恢复消费任务。consumer.fetch.min.bytes、consumer.fetch.max.bytes和consumer.fetch.max.wait.ms参数分别用于控制每次拉取的最小字节数、最大字节数以及最长等待时间。
六、其它要点
A:如果启动多套使用相同的KafkaSource的Flume,是不是保证kafka.consumer.group.id一样,获取的数据就不会出现重复了
B:是的,如果启动多个使用相同的KafkaSource的Flume,并且它们的kafka.consumer.group.id设置为相同的值,那么它们会组成一个Kafka Consumer Group,其中每个Flume实例只会从分配给其的partition中消费数据,而不会重复消费数据。此时,每个partition只会被一个消费者消费,保证了消费数据的唯一性。
需要注意的是,如果是多个Flume实例消费同一个topic的数据,即使它们使用不同的kafka.consumer.group.id,也存在数据重复消费的可能性。因为此时不同的Flume实例具有相同的消费权限,可能会订阅到相同的partition并同时消费同样的消息。所以,在这种情况下应该将partition按照一定规则均匀地分配给不同的Flume实例,避免数据重复消费的问题出现。
A:如果Kafka是5个partition,刚开始只启动一个Flume,是不是5个partition的数据都会发往这个Flume,还是只有一个partition发往Flume?
B:当只启动一个Flume实例消费一个包含5个partition的Kafka topic时,初始情况下这个Flume实例会分配到这个topic的所有分区,也就是说,5个分区都会发送数据到这个Flume实例中进行消费。
在Kafka中,每个partition只能被消费者组内的一个消费者消费,如果一个消费者组只有一个消费者,那么该消费者将会消费该topic的所有分区。因此,只有一个Flume实例消费一个包含多个分区的Kafka topic时,它将获取该topic的所有分区的消息,并对其执行相应的处理,避免了数据漏处理的可能性。
当然,随着Flume实例数量的增加,Kafka将会重新分配分区并将其分配给不同的Flume实例,以达到负载均衡和高可用的目的。
七、实操
agent1.sources.kafka_source.type = org.apache.flume.source.kafka.KafkaSource
agent1.sources.kafka_source.batchSize = 50000
agent1.sources.kafka_source.batchDurationMillis = 2000
agent1.sources.kafka_source.kafka.bootstrap.servers = ${kafkaCluster_acl}
agent1.sources.kafka_source.kafka.consumer.security.protocol=SASL_PLAINTEXT
agent1.sources.kafka_source.kafka.consumer.sasl.mechanism = PLAIN
agent1.sources.kafka_source.kafka.consumer.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="${kfk_user}" password="${kfk_pwd}" ;
agent1.sources.kafka_source.kafka.topics = event_full
agent1.sources.kafka_source.kafka.consumer.group.id = bigdata_flume
agent1.sources.kafka_source.kafka.setTopicHeader = true
agent1.sources.kafka_source.kafka.topicHeader = topic
agent1.sources.kafka_source.interceptors = i1
agent1.sources.kafka_source.interceptors.i1.type= com.yangvin.flume.TimestampInterceptor$Builder
3.3 配置优化
主要是在放入flume-channels 的批量数据加大
更改参数:
agent1.sources.kafka_source.batchSize = 50000
agent1.sources.kafka_source.batchDurationMillis = 2000
更改解释:即每2秒钟拉取 kafka 一批数据 批数据大小为50000 放入到flume-channels 中 。即flume该节点 flume-channels 输入端数据已放大
更改依据:
- 需要配置kafka单条数据 broker.conf 中配置
message.max.bytes- 当前flume channel sink 组件最大消费能力如何?

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)