

SQL中的聚合函数(AVG、COUNT、MAX、MIN、SUM)和数据分组
具体理解:WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。我们经常发现GROUP BY分组后的数据可能不是我们想要的,比如升序、降序,这个时候就需要再使用ORDER BY来针对分组后的数据进行排序。定义:使用WITH ROLLUP关键字,可以得到每个分组以及每个分组汇总级别(针对每个分组)的值。分别取出表table_name中行column_name去重的平均值,结果名为cn_a
目录
函数的分类
SQL 中常用 5 类的函数:字符串函数,日期函数,数学函数,系统函数,聚合函数;
本次主要讲解的是聚合函数
聚合函数
AVG()
定义:返回数值列的平均值
语法:
SELECT AVG(column_name) FROM table_name
需要关注点:
- AVG()只用于单个列,只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。
- 若为了获得多个列的平均值,必须使用多个AVG()函数。
- NULL值:AVG()函数忽略列值为NULL的行。
COUNT()
定义:返回匹配指定条件的行数
语法:
-- 查询所有记录的条数
select count(*) from access_log;
select count(1) from access_log;
-- 查询websites 表中 alexa列中不为空的记录的条数
select count(alexa) from websites;
-- 查询websites表中 country列中不重复的记录条数,如1,1,2,3,3 则返回1,2,3
select count(distinct country) from websites;
需要关注点:
- 如果指定列名,则指定列的值为空的行被COUNT()函数忽略,但如果COUNT()函数中用的是星号(*),则不忽略。
- count(*)和count(1)的区别
MAX()
定义:返回指定列的最大值
语法:
-- 从 "Websites" 表的 "alexa" 列获取最大值
SELECT MAX(alexa) AS max_alexa FROM Websites;
需要关注点:
- 对非数值数据使用MAX():虽然MAX()一般用来找出最大的数值或日期值,但MySQL允许将它用来返回任意列中的最大值,包括返回文本列中的最大值。在用于文本数据时,如果数据按相应的列排序,则MAX()返回最后一行。
- NULL值:MAX()函数忽略列值为NULL的行。
MIN()
定义:返回指定列的最小值。
语法:
-- 从 "Websites" 表的 "alexa" 列获取最小值
SELECT MIN(alexa) AS min_alexa FROM Websites;
需要关注点:
- 对非数值数据使用MIN() :MIN()函数与MAX()函数类似,MySQL允许将它用来返回任意列中的最小值,包括返回文本列中的最小值。在用于文本数据时,如果数据按相应的列排序,则MIN()返回最前面的行。
- NULL值:MIN()函数忽略列值为NULL的行。
SUM()
定义:返回数值列的总数。
语法:
-- 查找 "access_log" 表的 "count" 字段的总数
SELECT SUM(count) AS nums FROM access_log;
需要关注点:
- 在多个列上进行计算:利用标准的算术操作符,所有聚集函数都可用来执行多个列上的计算。如:
select SUM(column_name1*column_name2) from table_name得到列1和列2积的和 - NULL值:SUM()函数忽略列值为NULL的行。
DISTINCT 聚合不同值
以上5个聚合函数都可以如下使用:
- 对所有的行执行计算,默认ALL参数(不给参数即为默认ALL);
- 若需要指定只包含不同的值,则指定DISTINCT参数。
- ALL为默认:ALL参数不需要指定,因为它是默认行为。
DISTINCT:
定义:去除重复数据。
DISTINCT的语法:
SELECT AVG(DISTINCT column_name) FROM table_name
解析:
带上DISTINCT后,过滤column_name列重复数据后再计算平均值。
如果未带DISTINCT之前高于平均值的多,过滤后平均值下降;
如果未带DISTINCT之前低于平均值的多,过滤后平均值升高。
需要关注点:
- 如果指定列名,在使用COUNT()函数时,只能用于COUNT(),如COUNT(DISTINCT column_name)。DISTINCT不能用于COUNT(*),因此不允许使用COUNT(DISTINCT),否则会产生错误。类似地,DISTINCT必须使用列名,不能用于计算或表达式。
- 将DISTINCT用于MIN()和MAX() :虽然DISTINCT从技术上可用于MIN()和MAX(),但这样做实际上没有价值。一个列中的最小值和最大值不管是否包含不同值都是相同的。
组合聚合函数
顾名思义,就是将以上5个聚合函数组合在一起使用,如下:
SELECT AVG(DISTINCT column_name) AS cn_avg,
COUNT(*) AS cn_count,
MAX(column_name) AS cn_max,
MIN(column_name) AS cn_min,
SUM(column_name) AS cn_sum
FROM table_name
解析:
分别取出表table_name中行column_name去重的平均值,结果名为cn_avg;
取出表table_name一共有多少条数据,结果名为cn_count;
取出行column_name最大值,结果名为cn_max;
取出行column_name最小值,结果名为cn_min;
取出行column_name的合,结果名为cn_sum。
数据分组
主要介绍两部分内容:创建分组GROUP BY 、过滤分组HAVING
创建分组GROUP BY
定义:结合聚合函数,根据一个或多个列对结果集进行分组。
语法:
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;
数据表信息:
表Websites的数据

表access_log的数据
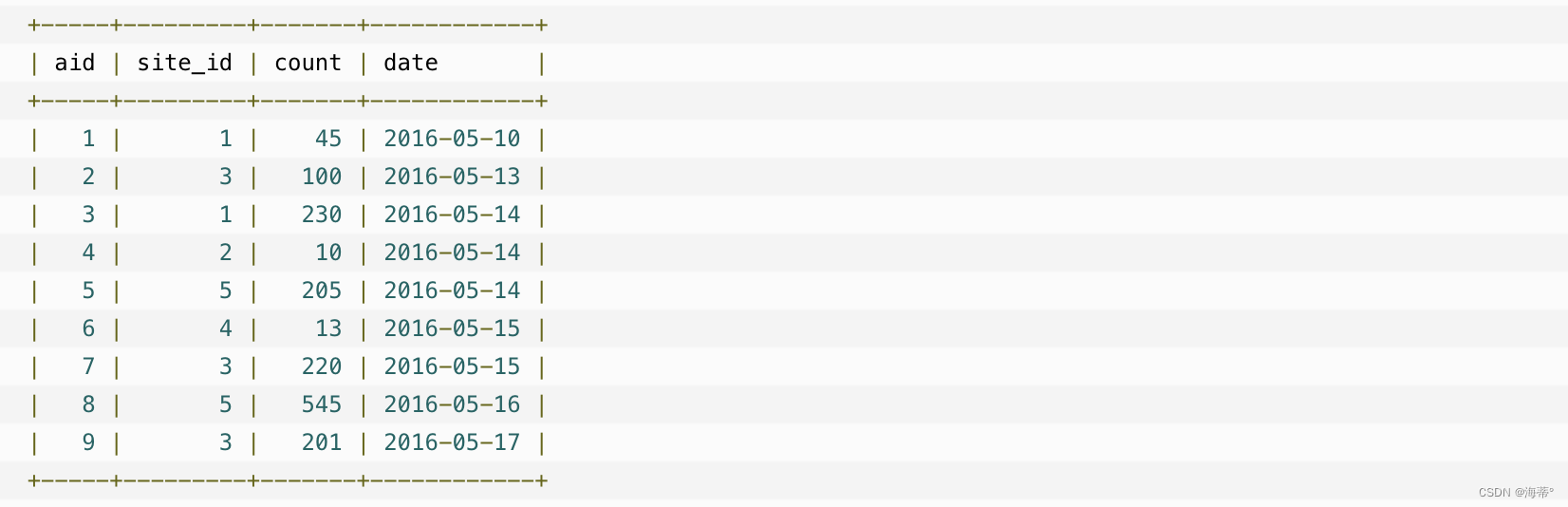
GROUP BY的使用:
--统计 access_log 各个 site_id 的访问量
SELECT site_id, SUM(access_log.count) AS nums
FROM access_log GROUP BY site_id;
结果为:

需要注意的:
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式(两个列相乘)。不能使用别名。
汇总分组数据ROLLUP
定义:使用WITH ROLLUP关键字,可以得到每个分组以及每个分组汇总级别(针对每个分组)的值。
语法实例:
--同上表统计 access_log 各个 site_id 的访问量 和总访问量
SELECT site_id, SUM(access_log.count) AS nums
FROM access_log GROUP BY site_id WITH ROLLUP;
结果为:

过滤分组HAVING
定义:SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
实例:
同上数据查询,现在我们想要查找总访问量大于 200 的网站:
SELECT Websites.name, Websites.url, SUM(access_log.count) AS nums FROM (access_log
INNER JOIN Websites
ON access_log.site_id=Websites.id)
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;
结果为:
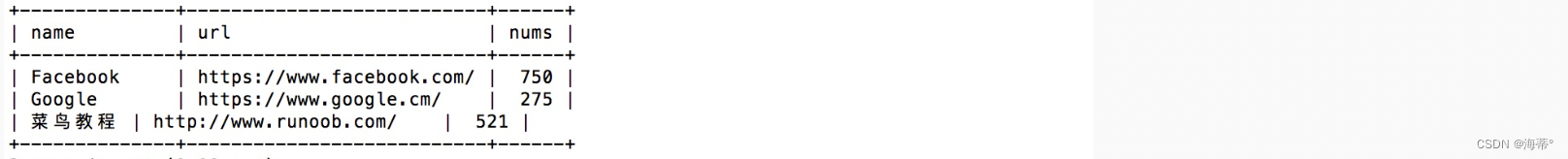
WHERE和HAVING的区别:WHERE过滤行,而HAVING过滤分组。
具体理解:WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
实例:
需求:现在我们想要查找总访问量大于 200 的网站,并且 alexa 排名小于 200
SELECT Websites.name, SUM(access_log.count) AS nums FROM Websites
INNER JOIN access_log
ON Websites.id=access_log.site_id
WHERE Websites.alexa < 200
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;
结果为:
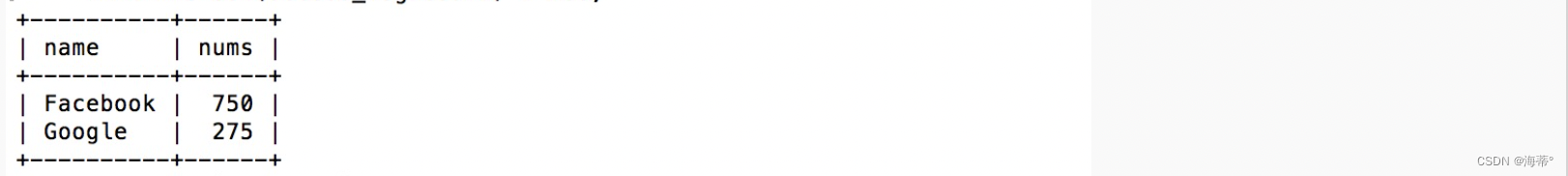
分组排序ORDER BY
我们经常发现GROUP BY分组后的数据可能不是我们想要的,比如升序、降序,这个时候就需要再使用ORDER BY来针对分组后的数据进行排序。
用以上SQL做实例:
SELECT Websites.name, SUM(access_log.count) AS nums FROM Websites
INNER JOIN access_log
ON Websites.id=access_log.site_id
WHERE Websites.alexa < 200
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200
ORDER BY nums DESC;
则执行结果同上:
需要注意:
- ORDER BY 是默认升序的,写成:
ORDER BY nums - 若指明降序,则写成:
ORDER BY nums DESC
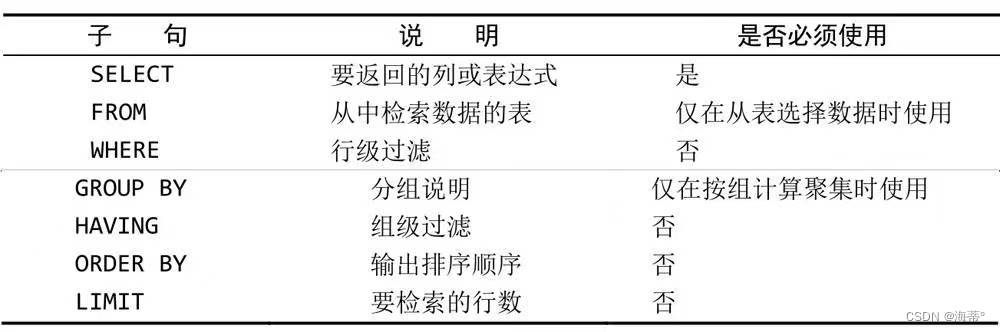
SELECT子句顺序

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)