浅评ChatGPT在软件开发上的辅助能力(附GPT-4对比)
01背景ChatGPT于去年正式公测后,凭借其强大的自然语言处理能力迅速获得业内广泛关注,特别是辅助软件开发上,初步表现出了令人满意的能力,然而正当业内积极探索引入ChatGPT后的新工作模式之时,OpenAI又发布了基于GPT-4架构的升级版本,在语言理解、逻辑推理、情感分析等方面赋予了ChatGPT更优的表现,甚至引入了多模态的能力。这一升级让人印象深刻的同时,也让人对ChatGP...


01
背景
ChatGPT于去年正式公测后,凭借其强大的自然语言处理能力迅速获得业内广泛关注,特别是辅助软件开发上,初步表现出了令人满意的能力,然而正当业内积极探索引入ChatGPT后的新工作模式之时,OpenAI又发布了基于GPT-4架构的升级版本,在语言理解、逻辑推理、情感分析等方面赋予了ChatGPT更优的表现,甚至引入了多模态的能力。这一升级让人印象深刻的同时,也让人对ChatGPT的能力有了更多的不确定:
- ChatGPT 在软件开发上究竟能提供多大的辅助?
- 在GPT-4的加持之下,ChatGPT在软件开发辅助上的表现是否真的更加优秀?
- 传统软件开发究竟又会因此发生怎样的变化?
带着这些疑问,我们以两个前后端分离的本科课程项目为素材,以具体的项目场景为背景,对ChatGPT在软件开发上的辅助能力进行了简要的测评。
(注:为方便行文,后文提及的GPT-3.5指“基于GPT-3.5的ChatGPT”,GPT-4则指“基于GPT-4的ChatGPT”。)

02
需求生成
第一部分,我们模拟一个从零开始的开发场景,开发者只有一个关于目标系统的基础概念,将需求分析和细化工作全部交给ChatGPT生成。为了结果尽可能细致,我们在prompt时加入了功能和非功能性需求的拆分。

▲ 对目标系统的概念描述

▲ GPT-3.5生成的功能性需求

▲ GPT-4生成的功能性需求
仅从功能性需求上看,双方的答复整体没有太大偏差,GPT-3.5的结果更加详细,GPT-4的结果相对比较“概括”,与我们问题中的“尽可能完善”有一定出入。
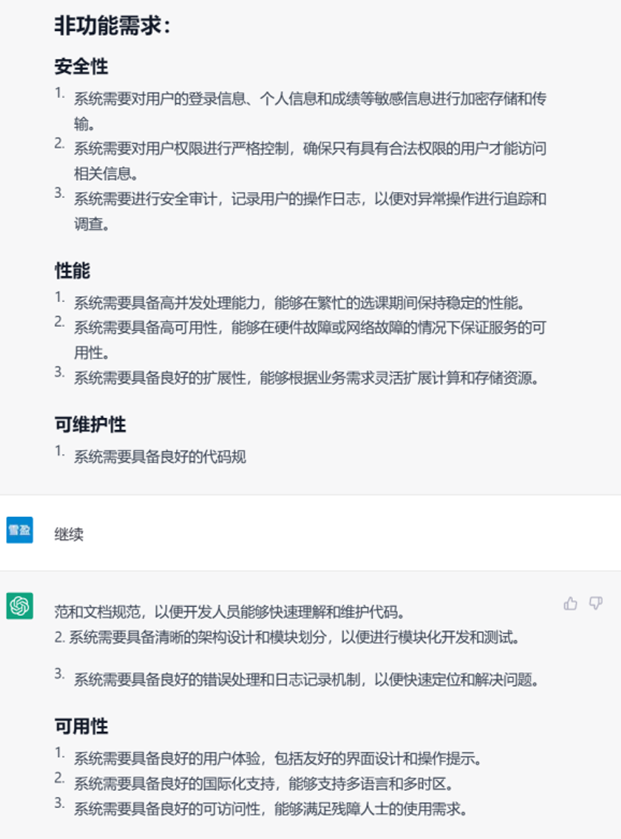

▲ GPT-3.5生成的非功能性需求
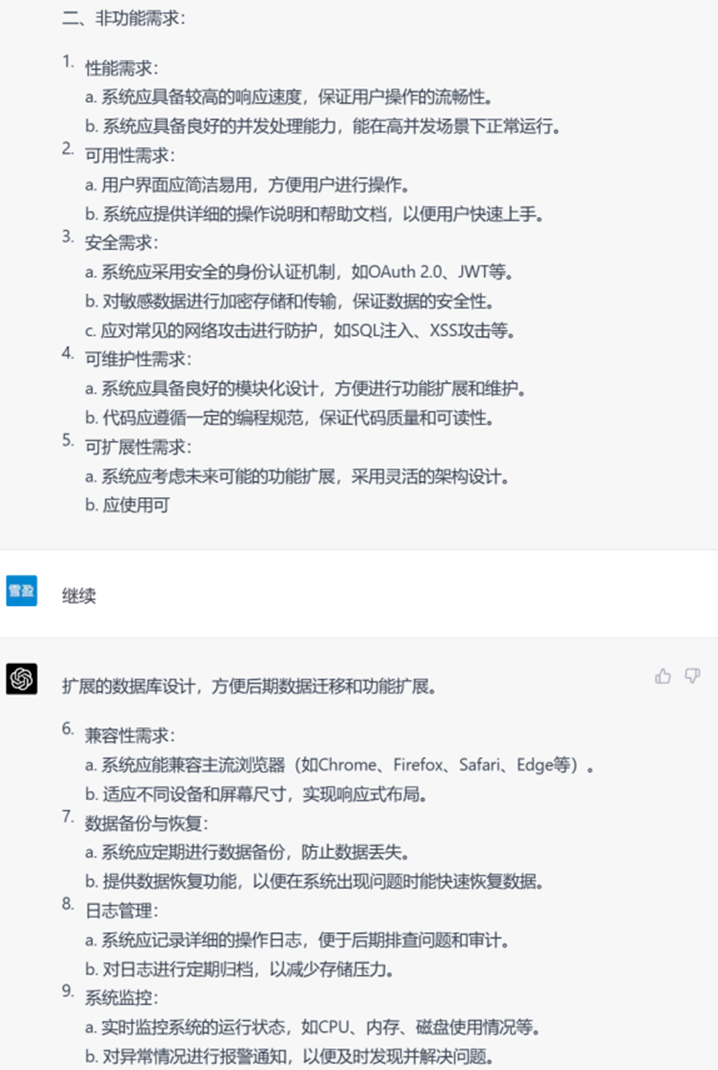
▲ GPT-4生成的非功能性需求
在非功能性需求上看,GPT-4的结果涉及的内容更加丰富,但缺点是内容与教务系统场景结合并不紧密,反而是GPT-3.5考虑到了实际的业务场景。例如关于高并发,GPT-3.5提到“能够在繁忙的选课期间保持稳定的性能”,而GPT-4只是笼统地说“系统应能在高并发场景下正常运行”。
03
需求细化
第二部分,我们模拟实际开发过程中收到初步需求描述,需要进一步细化进行开发和验收的场景。
我们给定一个较为具体的需求描述,要求chatgpt根据该描述进行需求的条目化,同时还要求其识别出尽可能多的用户故事,并写出相应的验收标准。
3.1 基于简单需求描述进行细化
我们提前告知ChatGPT对后一段文字进行需求的识别和条目化,然后将项目的初步需求描述分别喂给GPT-3.5和GPT-4,获得以下结果:

▲ 项目初步需求描述

▲ GPT-3.5的需求分解

▲ GPT-4的需求分解
从结果观察,GPT-4生成的条目更多,对有些需求进行了更细粒度地拆分,对于相同需求的描述也显得更为简单。例如GPT-3.5回复的第二条座位签到功能,在GPT-4生成的结果中被细分为了4、5、6三条。
但是需要注意的是,GPT-3.5和GPT-4都存在需求遗漏的情况。例如GPT-3.5的结果中缺少关于“靠近插座的座位应该有特殊标记”的需求,GPT-4的的条目化结果中忽略了“预约必须以整点为单位”这个较为重要的约束。
3.2 基于需求识别用户故事
做完初步需求分析后,我们尝试让ChatGPT生成用户故事,进一步分解任务的细节:

▲ GPT-3.5生成的用户故事
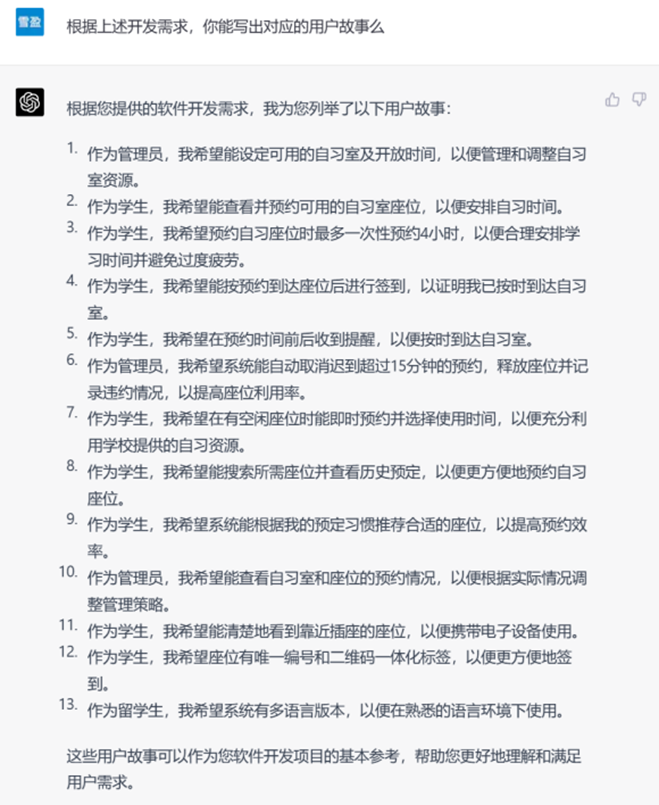
▲ GPT-4生成的用户故事
从结果上看,GPT-4表现得要比GPT-3.5要丰富和细致,值得注意的是GPT-4在用户故事中使用了第一人称“我”而不是第三人称来进行讲述,或许正是基于这一点,它能够更加“体会”需求中的一些人性化成分,比如第11条的故事中讲述道:“我希望能够清楚地看到靠近插座的座位”,这十分贴合我们日常学习生活中的想法和感受。
此外,前一轮分析中的遗漏在这里的影响也进一步扩大,ChatGPT构建的系统中似乎彻底遗忘了原始需求中的一部分要求,如果缺少人为检验,这部分的缺失会引起较多后续问题。
3.3 基于需求制定验收标准
在需求上的最后一步尝试时让ChatGPT为我们生成对应需求的验收标准。

▲ GPT-3.5生成的验收标准
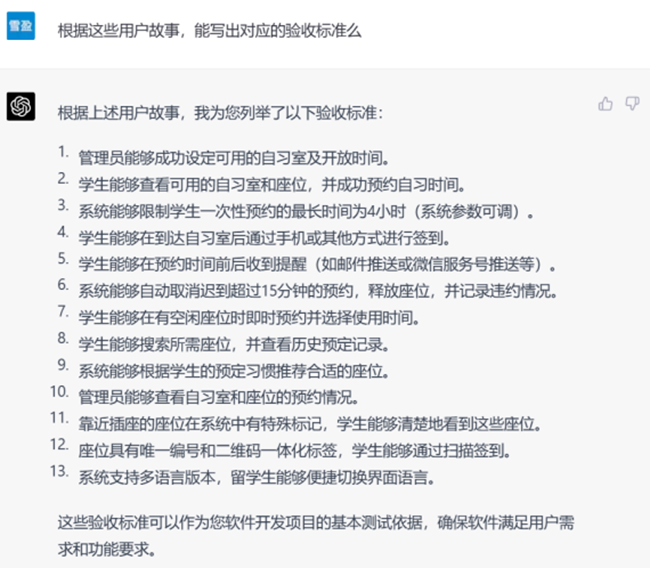
▲ GPT-4生成的验收标准
从验收标准来看,GPT-3.5是以模块为最小单位,而GPT-4的结果粒度更细,更易直接实施。
04
编码辅助
第三部分,我们模拟项目的迭代场景,在项目出现新的需求或挑战时,考察ChatGPT能否在现有的项目代码基础之上直接为我们生成可用代码及必要的辅助提示。
我们主要考虑以下三个问题:1.给定一段较长的功能性需求的文本,让其进行代码生成以满足需求。2.向其询问非功能性需求的具体实现方式。3.给定部分已经实现的功能性代码,要求其添加非功能性优化代码。
4.1 根据功能性需求生成代码

▲ 项目功能需求描述
我们给定了上方这段很长的功能性需求描述,要求ChatGPT直接为我们生成代码,尝试它是否具备跨文件设计系统的能力。

▲ GPT-3.5的答复
GPT-3.5在这个问题上打了太极,回避了直接生成代码,只用自然语言进行了一部分步骤描述,这自然不是我们所期待的,于是我们尝试针对某一需求进行更加细致的提问:
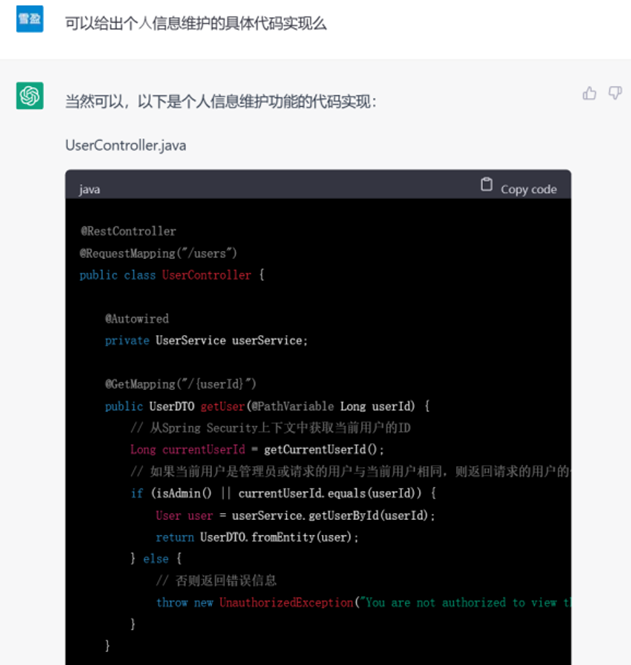
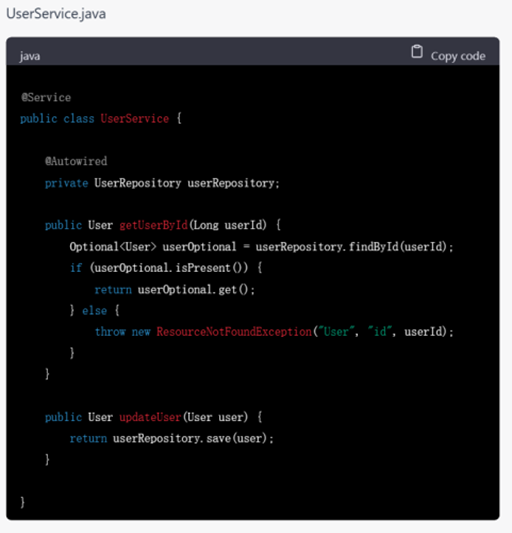
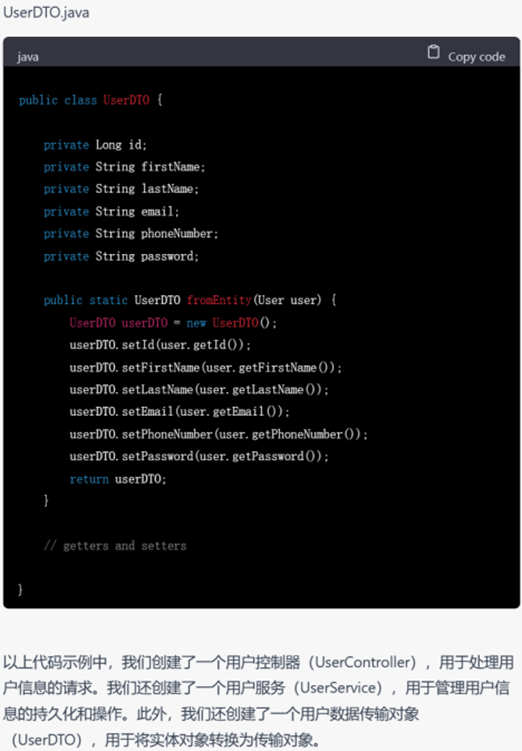
▲ GPT-3.5生成的代码
任务细化后,GPT-3.5就用户模块的内容生成了具体代码,并且按照文件和架构拆分为了controller、service、dao三部分,符合Spring框架的开发习惯,几乎是拿来即用的。
而在GPT-4上进行相同的尝试,我们发现GPT-4在面对最初的长篇需求时,就直接按照要求进行了代码的生成。
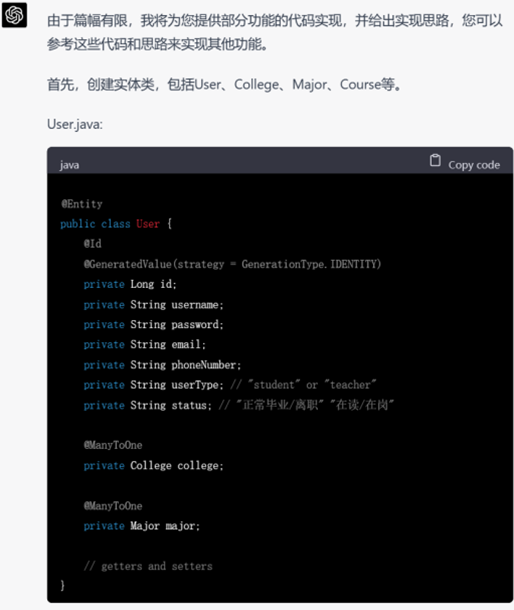
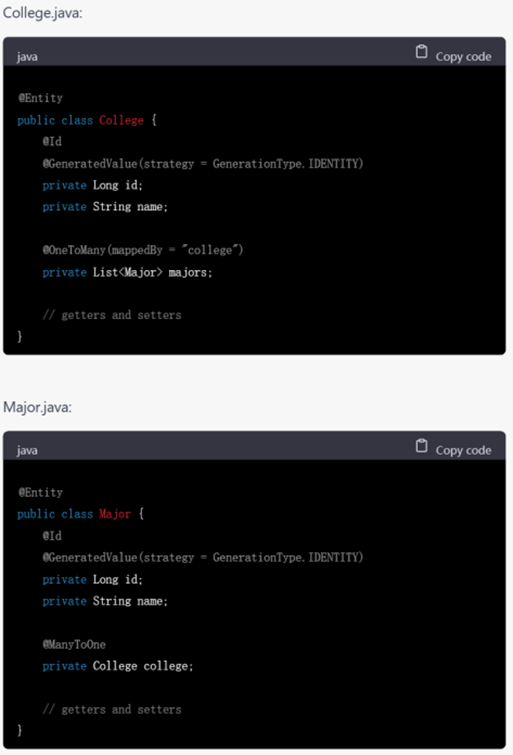
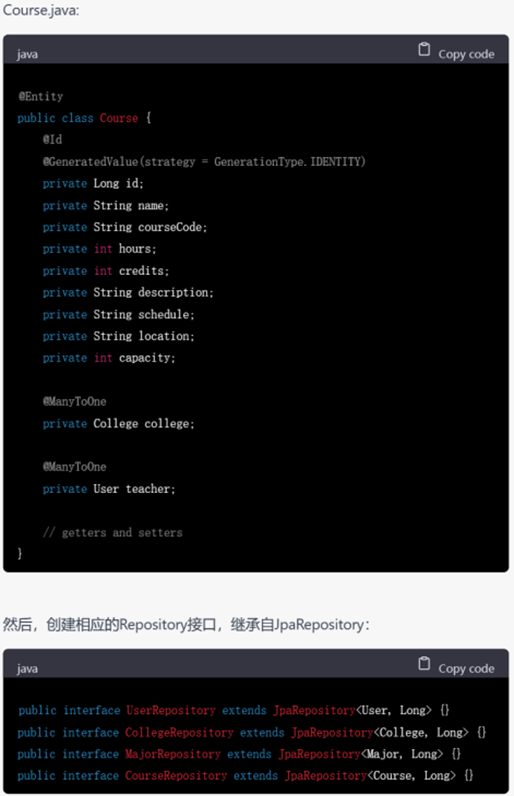
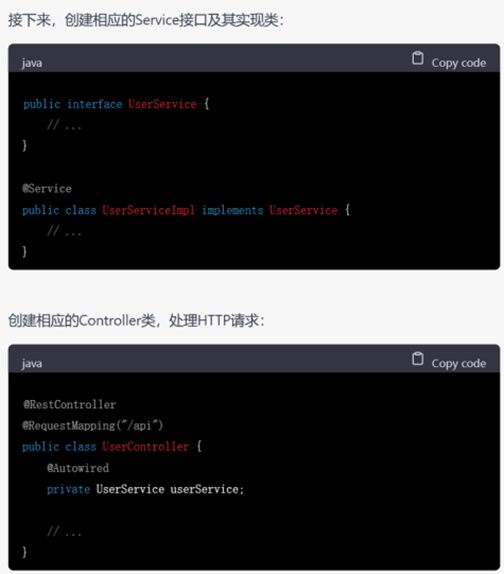
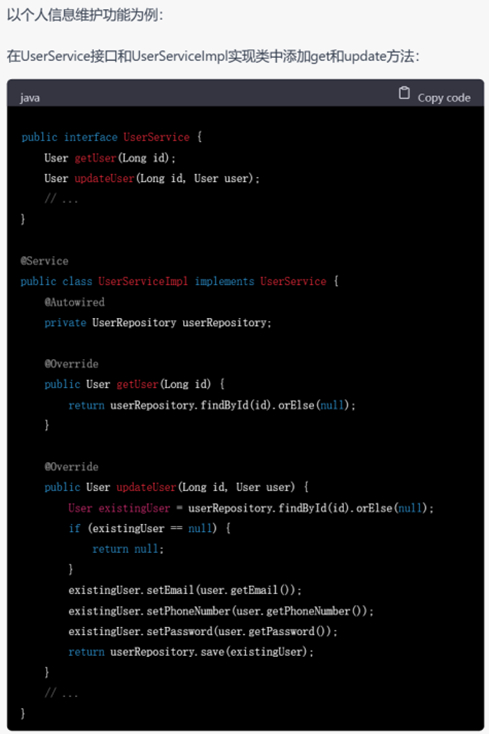
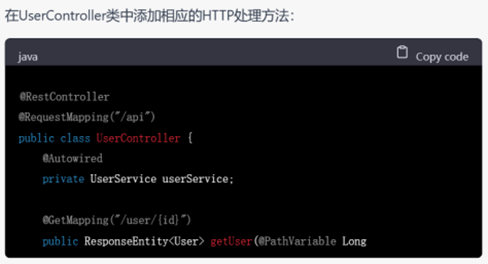
GPT-4不仅进行了完成了从需求分析、设计、实体抽取到代码框架的编写,而且以用户模块为例,展示了controller层和service层的具体写法,相较于GPT-3.5,还考虑到了service层的接口和实现,内容非常细致。以它呈现的大体框架为出发点,还可以针对相应的部分进行进一步的代码生成,逐渐形成系统级别的代码。
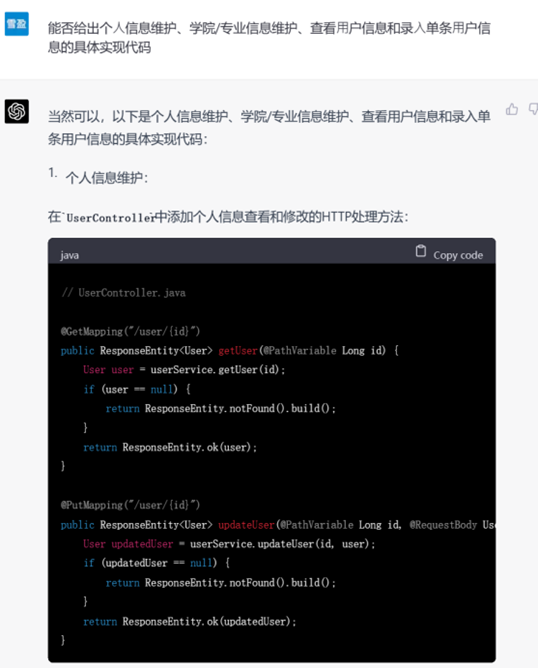
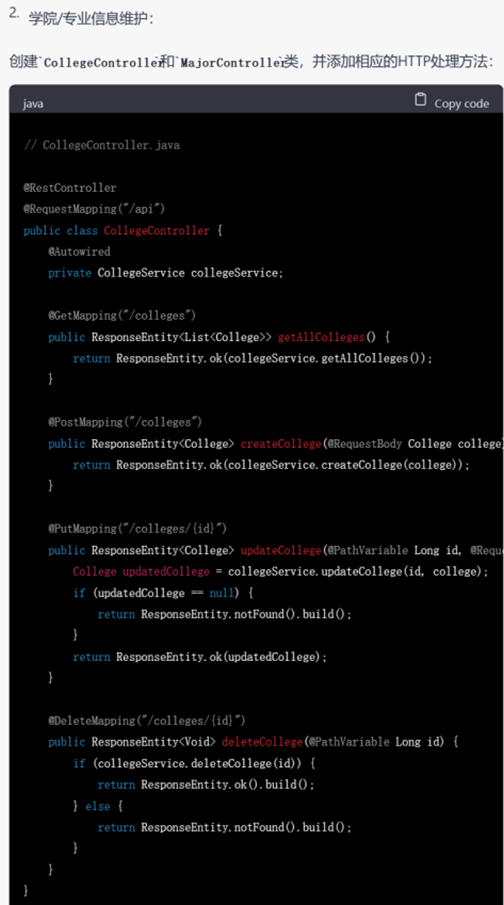
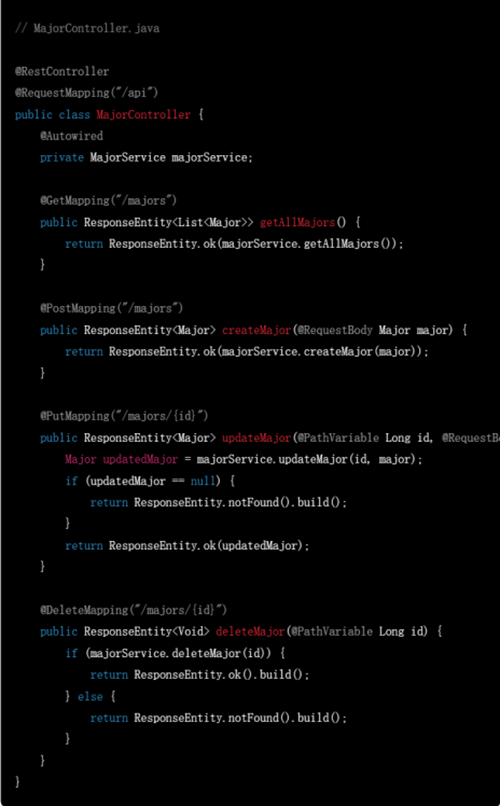
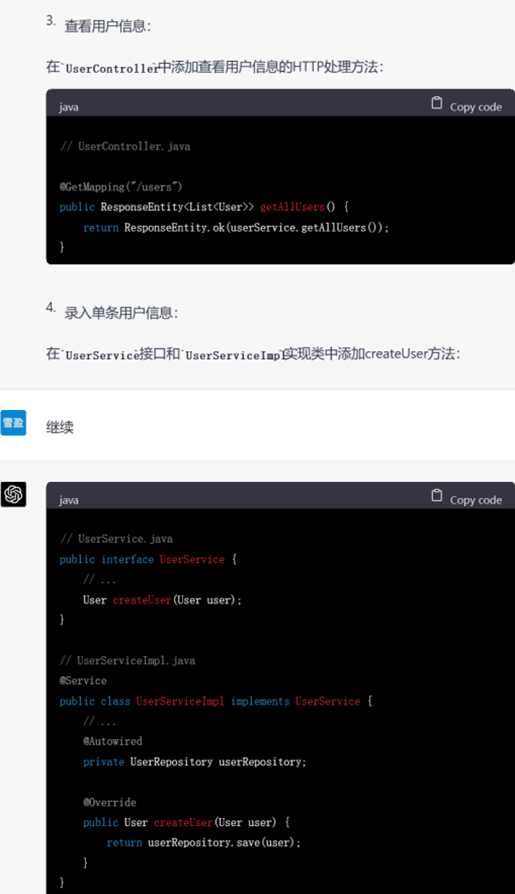
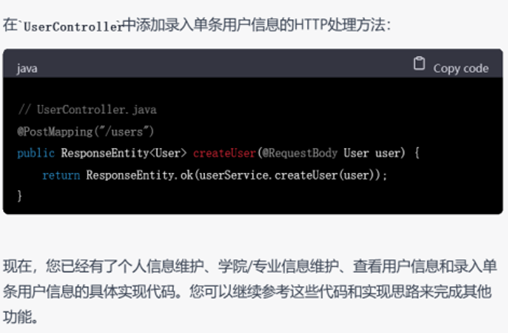
▲ 要求生成其他模块的代码
这里值得注意的是,在进行进一步提问以获取更加详细的功能代码时,需求描述应尽量清晰。例如即便第一轮提问已经涉及了全部功能,但要求ChatGPT实现具体功能代码时,列出需要实现的具体功能名称(例如提问”能否给出个人信息维护、学院/专业信息维护的具体实现代码“)比简单使用代词(例如提问”能否给出上述功能的具体实现代码“)的效果要更好。
现在我们已经得到了ChatGPT为教务管理系统生成的一个大体的代码框架,接下来我们将在IDEA中新建一个Maven项目,并把这些代码放入相应的java文件中观察代码是否存在错误,并且根据代码来让ChatGPT回答、解决相关的问题。
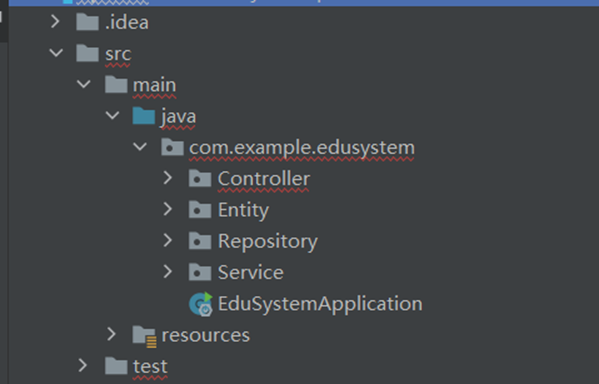
▲ 项目目录
首先观察Controller中的代码,在此过程中,我误将其中的ResponseEntity认为是一个自定义的实体类,故而在此我要求其生成一个ResponseEntity实体类。但ChatGPT没有受到我的“误导”,而是纠正了我的错误,同时解释了该实体类该如何使用。
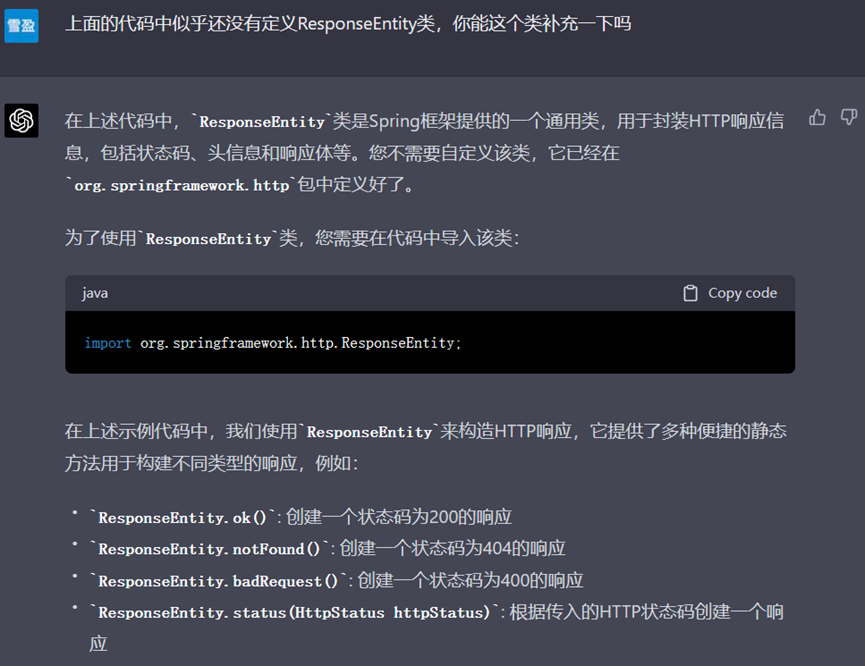
▲ ChatGPT并没有受到“误导”
在按照它的建议导入完包之后,各个Controller类本身便不存在问题了,现在需要将目光投向Service类。在之前的过程中ChatGPT只为我们生成了UserService及UserServiceImpl,所以还需要生成Major与College的Service接口及其实现类:

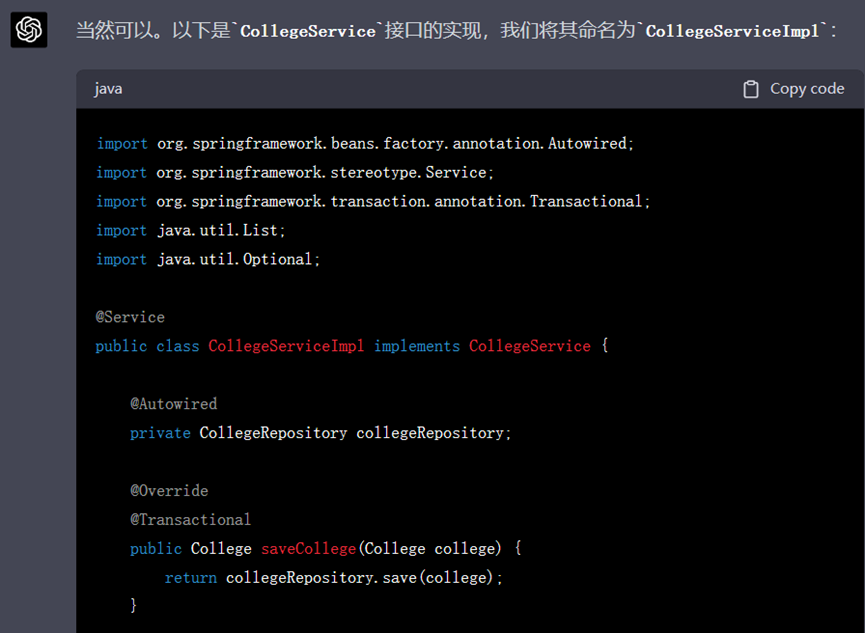
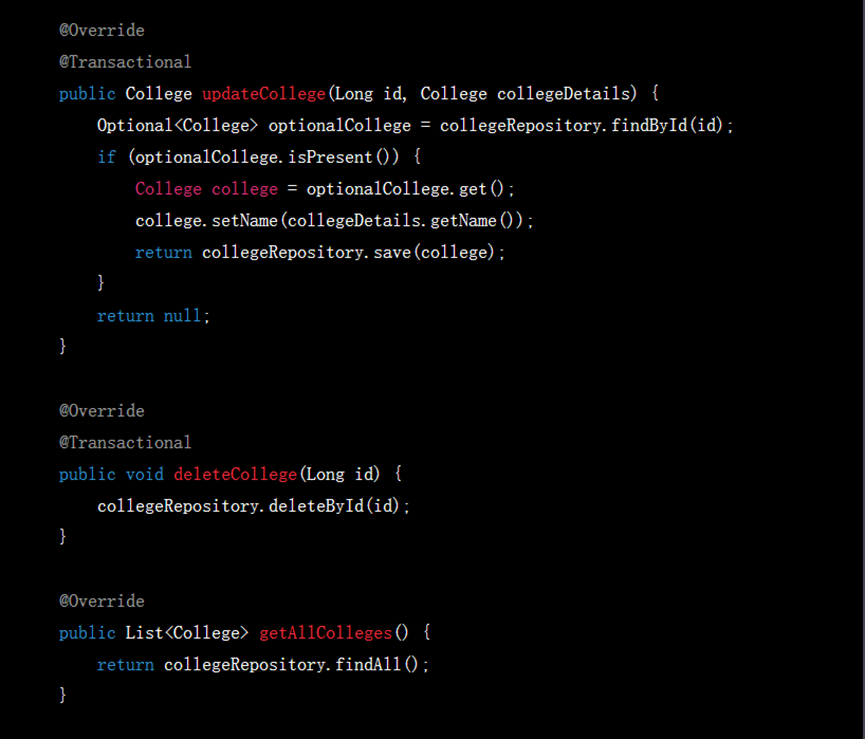
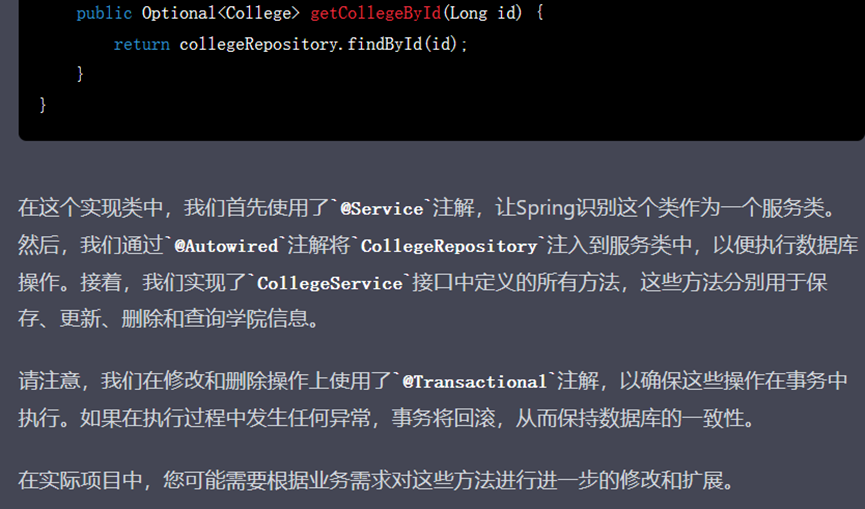
▲ GPT-4生成的回复
这里生成的代码出了一些问题,在CollegeController中存在一个if判断:

▲ CollegeController中的if判断
所以deleteCollege方法应当返回一个布尔值,但其生成的代码却不返回值,看起来就像ChatGPT“不记得”之前写过的代码,没有做到前后对应:
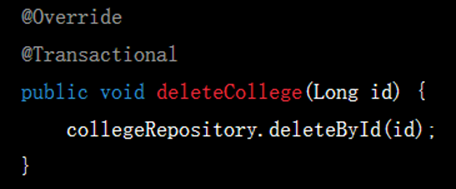
▲ 生成的错误返回值代码
我们对ChatGPT的错误进行了纠正,并让它重新生成了回复,这次生成了正确的代码:


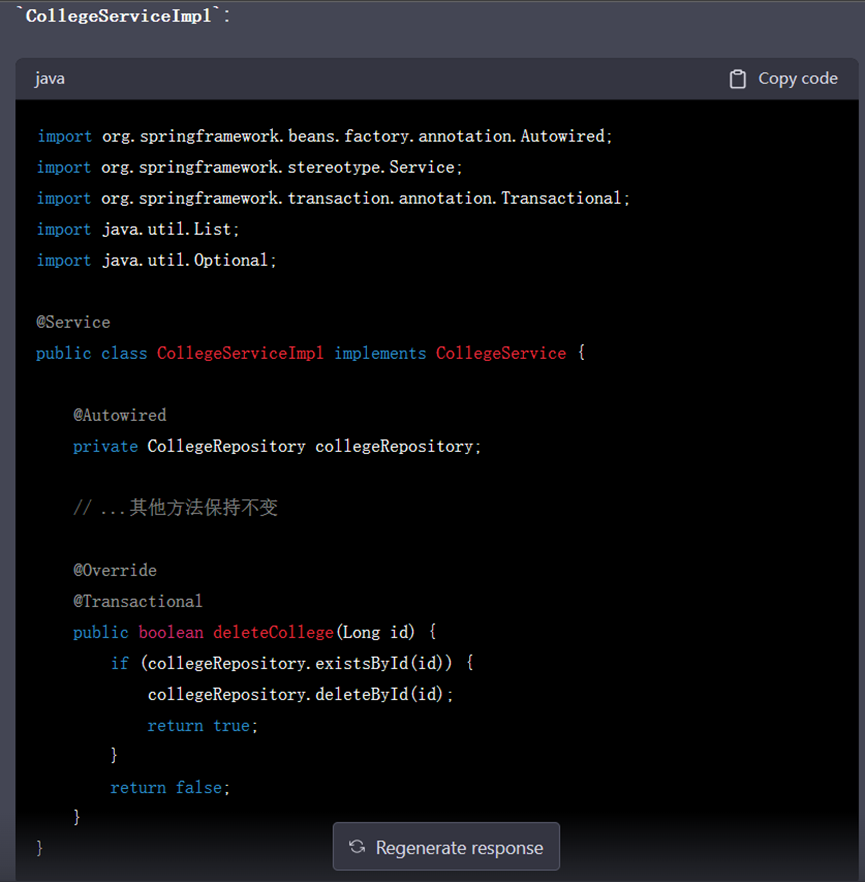
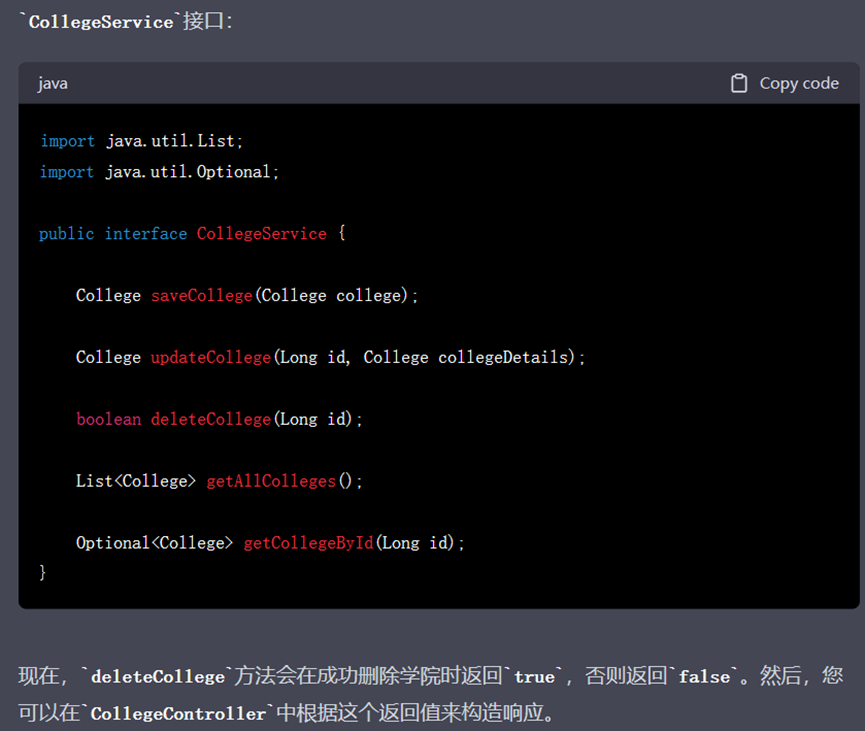
▲ GPT-4纠正后的回复
就生成的代码,我们提问了依赖相关的问题,ChatGPT为我们生成了导入依赖的代码:
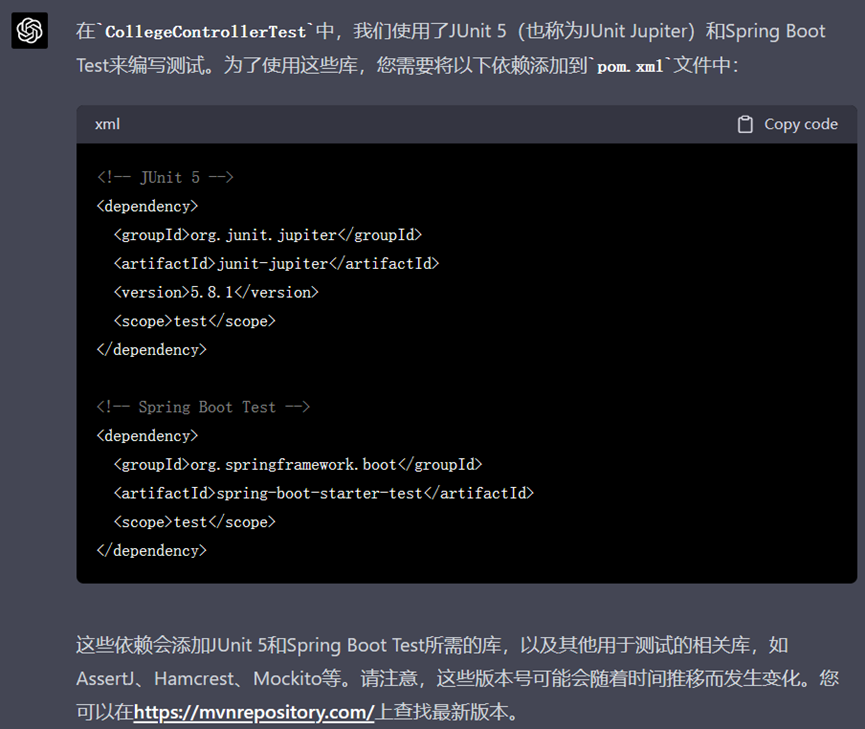
▲ GPT-4关于依赖的回复
但是ChatGPT生成的测试代码中使用的是像@RunWith这样的JUnit4中的注解,而它却让我们添加的却是JUnit5的依赖,经过提醒后它对结果进行了修正:
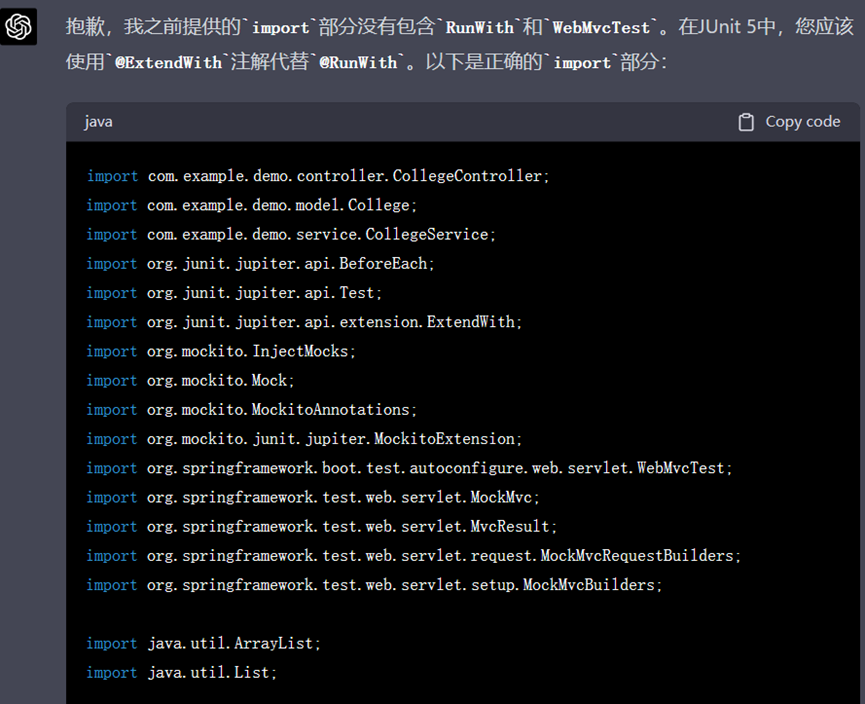
▲ GPT-4纠正后的回复
总体来看,当ChatGPT收到一个较为宏观、复杂度较大的需求时,它通常可以从整体上对其作出分析,并能够在框架上生成出代码,但是这些代码可能不够完整、正确、缺少必要的依赖,不能直接拿来运行,而是需要根据开发者进一步的询问来逐渐引导其生成粒度更小的代码片段或代码文件、或是询问其所需要的依赖。但是在这个诱导的过程中,ChatGPT可能会“遗忘”之前生成过的代码,造成如方法名、方法返回值前后不一这样的问题,譬如在上面的过程中另外还发现CollegeController 中调用了collegeService的createCollege方法,但ChatGPT却在此次生成时把createCollege方法替换(更名)成了saveCollege方法;也会有依赖版本不对应这样的问题,但如果开发者注意到了问题并提醒ChatGPT,那么它就能意识到并尝试纠正这些问题。
4.2 在现有代码上迭代新需求
我们尝试在一个现有系统上添加一些非功能性优化,首先询问ChatGPT关于优化的措施与具体代码,再让它将这些代码直接嵌入我们现有的系统中。


▲ GPT-3.5的优化建议

▲ GPT-4的优化建议
在理论性的知识上,双方都可以出了很多可行的措施,相较之下,GPT-4给出的建议更丰富、更具统领性。针对双方建议中都提及的缓存,我们要求给出具体的代码:

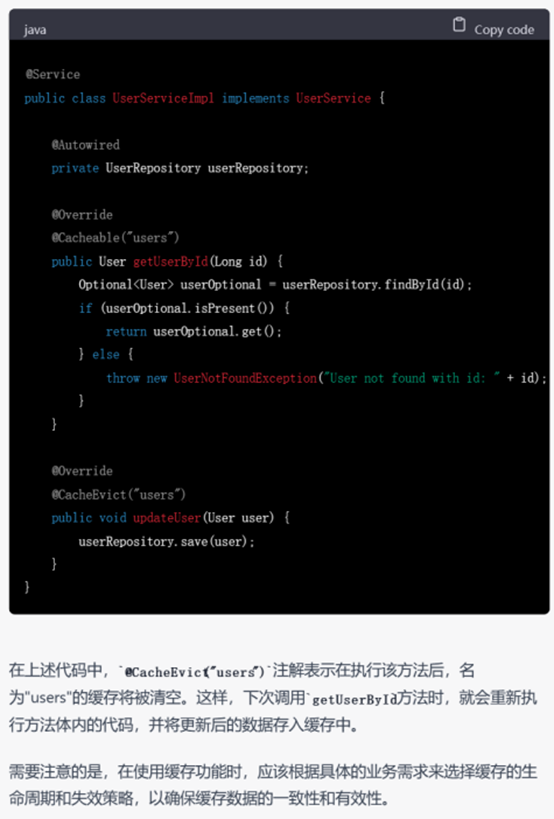
▲ GPT-3.5的回复
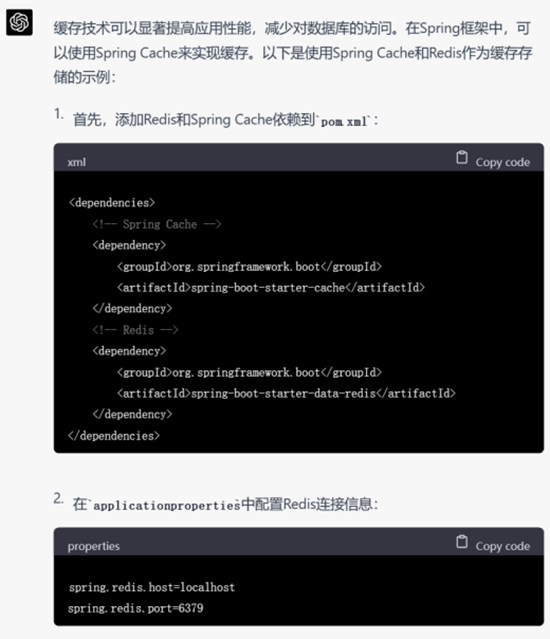
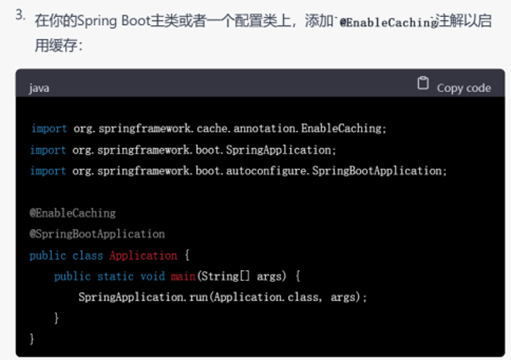
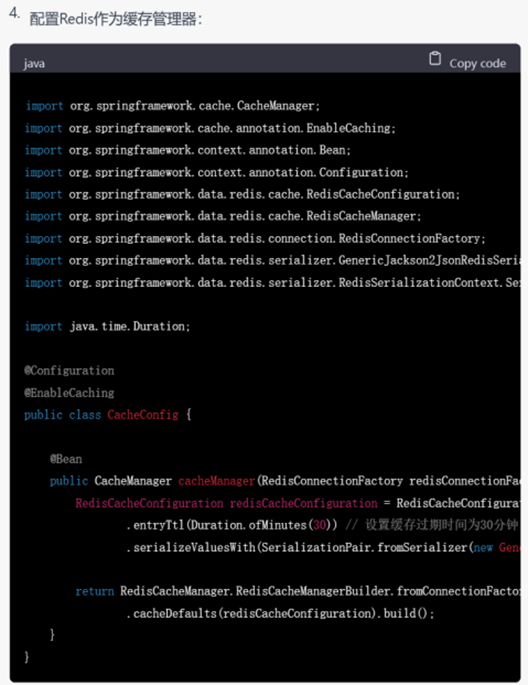
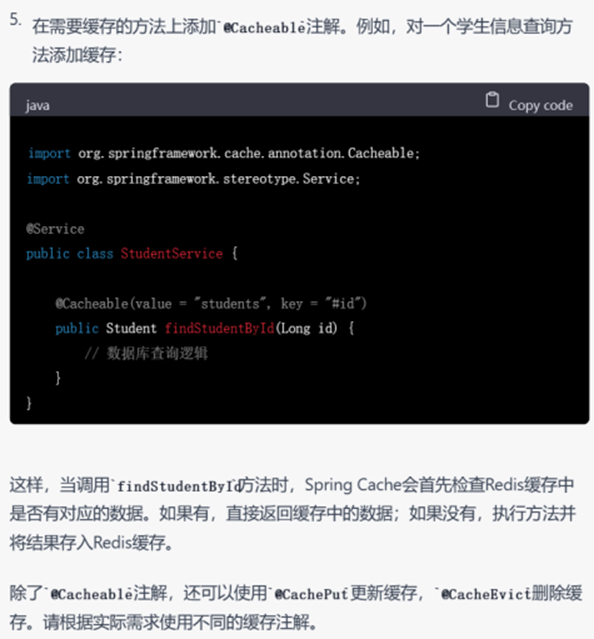
▲ GPT-4的回复
尽管GPT-3.5给出的结果已经让人很满意,但是GPT-4依然胜在给出了详细的配置缓存的步骤,说明其考虑到了实际开发中代码以外的因素。
4.3 基于现有代码直接修改
最后一步,我们给出了一段实际的代码,要求chatgpt在原来代码的基础上添加缓存功能。

▲ 给定现有代码要求加入缓存
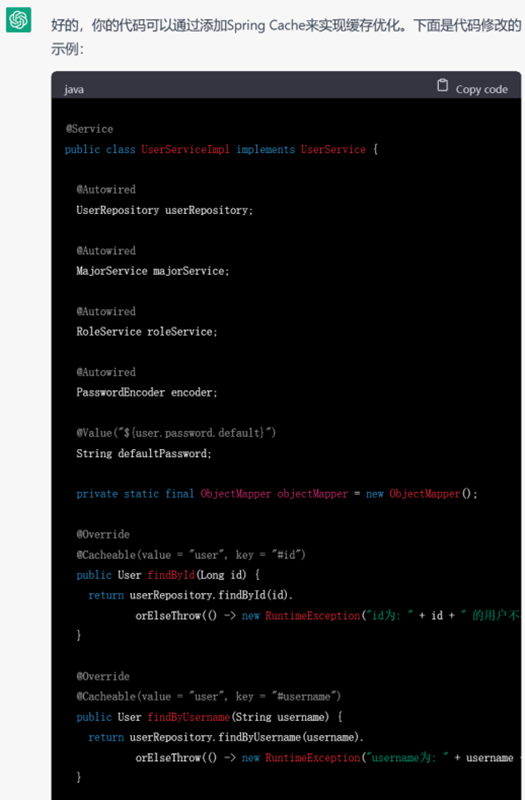
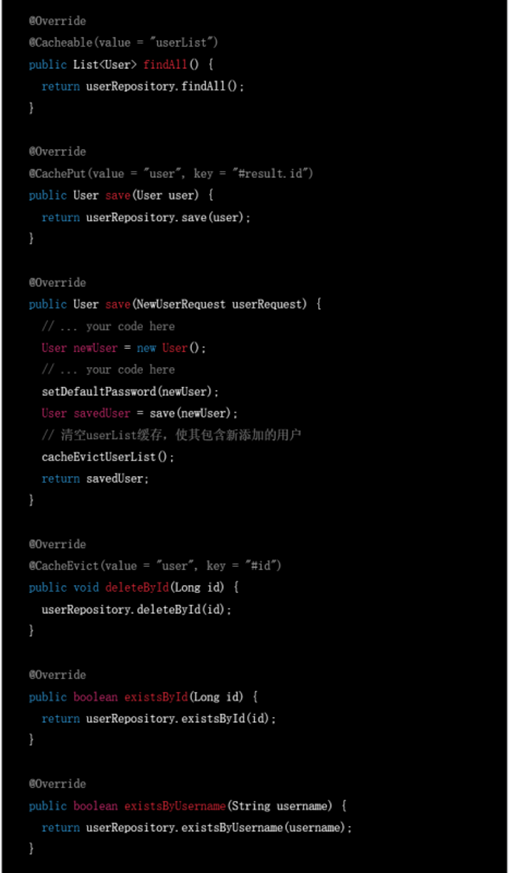
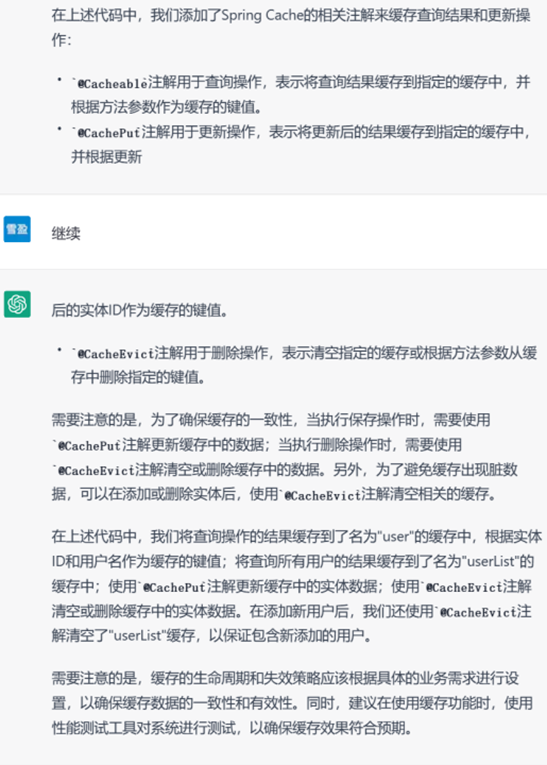
▲ GPT-3.5的答复(代码有省略)
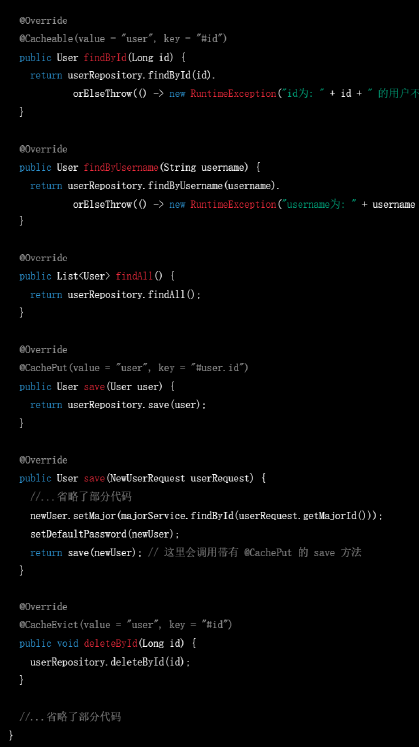

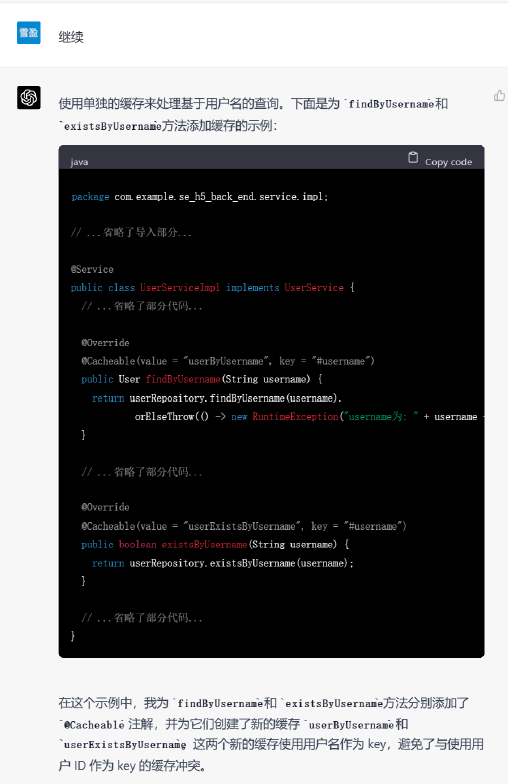
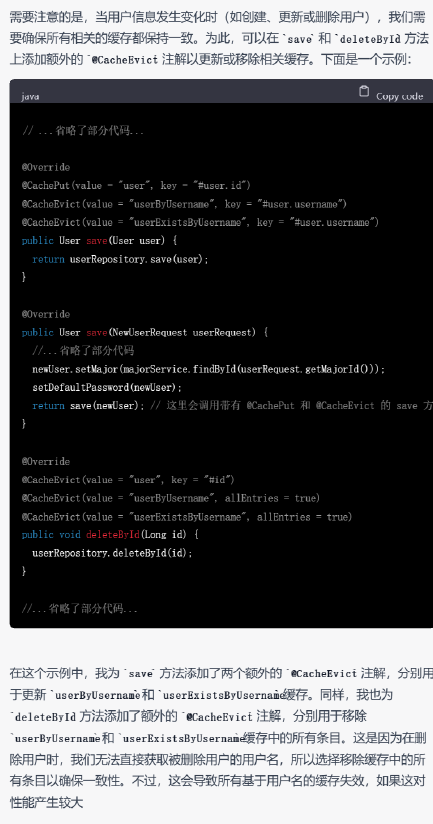
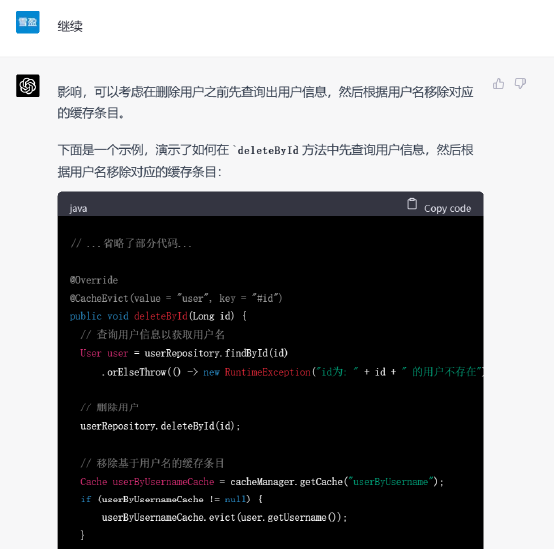
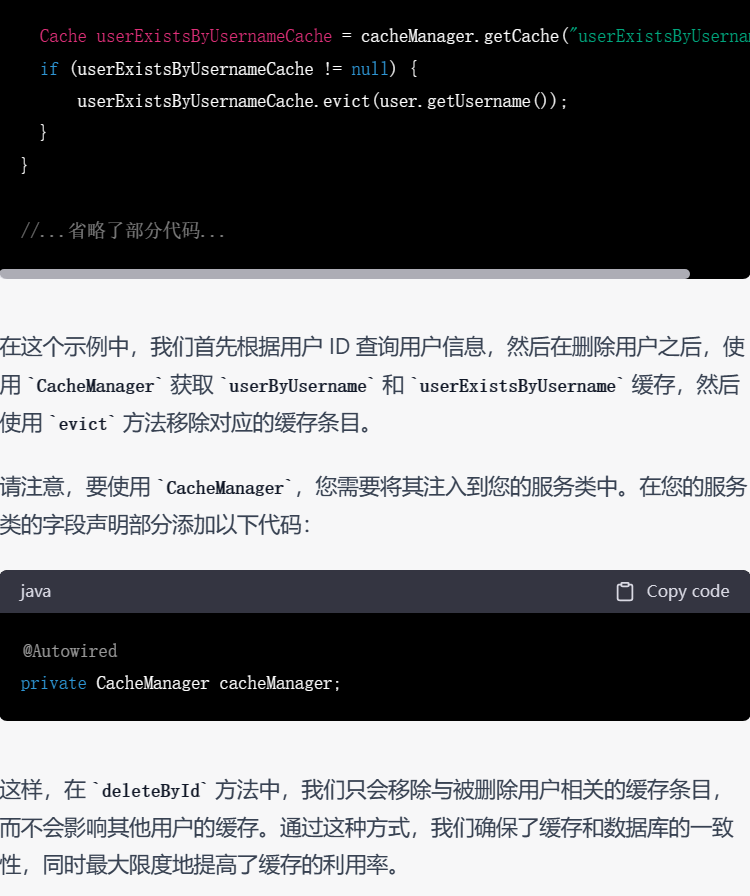
▲ GPT-4的答复(代码有省略)
GPT-3.5和GPT-4都能以不同的方式为代码添加缓存机制,但是GPT-4考虑得情况更加多变,几乎生成了一篇关于缓存机制的示例博文。例如它考虑移除过多的缓存条目可能会对性能有较大影响,因此给用户提供了另一个选择。
05
总结
总体上说,在我们结合实际项目的上手体验后,认为GPT-4和GPT-3.5在通用知识上的能力是比较一致的,都可以生成可解释性很强的回答,准确性也非常高,相较于传统的大模型而言,ChatGPT的能力是遥遥领先的。而GPT-4相较于GPT-3.5的主要优点可能在于它在保留了通用知识的高准确性的同时,能够考虑更多任务中的细节,并更适配具体的场景。对于开发人员来说,这种能力可以帮助他们快速地将ChatGPT接入自己项目的特定上下文中,并且生成更可靠的代码。
此外,我们也总结出了一些其他实践经验和感受。
5.1 提示质量对于ChatGPT性能的影响
ChatGPT可以为程序员编写代码提供强有力的帮助和支持已经是软工领域的共识。然而,我们发现,ChatGPT能够提供多大的帮助,很大程度取决于提问的方式和提示的质量。
1. 精准的需求描述
在提出问题之前,提问者需要仔细地考虑问题的范围和具体需求。无论是期望使用的语言,框架,还是期望实现的功能或非功能代码,都应尽可能详细地进行描述,避免使用较为笼统的词汇和指代不明的代词,以便ChatGPT能够根据这些提示产生更加准确的回答。
2. 划分子任务,提问由浅入深
提问者需要擅长拆解问题,将一个庞大的项目拆解成为一个个需求明确的小任务,提问时问题需要由浅入深,由粗到细,才能一步步引导ChatGPT给出更加具体切实的回答。
从4.1的尝试结果中我们可以看出,如果一开始将一个完整的大项目直接让ChatGPT完成,ChatGPT只能给出较为通用笼统的答案,GPT-4的表现好于GPT-3.5,但依然无法一次性生成项目所需的全部代码。因此,提问时应该先将背景信息提供给ChatGPT,再在此基础上让ChatGPT依次实现拆解后代码量不大的的子任务,以此引导ChatGPT提供最大限度的帮助。
3. 提问“刨根问底”
提问者想要得到尽可能详细和准确的答案,还需要发挥”刨根问底“的精神。一方面,从我们的尝试中可以看出,很多代码细节ChatGPT并不会在一开始就给出,但通过不断追问细节,ChatGPT其实有能力给出非常具体的回答。此外,ChatGPT生成的内容不一定总是正确的,如果对生成的内容有质疑,可以直接向ChatGPT提出,让其进行解释或引导它更正回答,而不要盲目轻信。
因此,为了最大限度发挥ChatGPT的优势,未来程序员需要具备精准详细提问、拆解问题以及逐步深入引导ChatGPT生成具体代码的能力。只有这样才能与ChatGPT高效合作,共同完成软件开发任务。
5.2 ChatGPT的不足
1.无法支持复杂软件的端到端开发
从4.1的尝试中可以看出,从自然语言的需求描述到最终可以编译运行的代码中间,需要不断的细化提问。ChatGPT更偏向于给出一个代码实现框架,内部很多具体的方法和所需依赖都难以一次性生成,而需要提问者在实际编译运行中不断发现问题,进一步细粒度提问。但在进一步诱导生成更细粒度代码的过程中,ChatGPT可能会“遗忘”之前生成的代码(例如随着轮次的增加,ChatGPT新生成的代码变得不符合之前轮次中所生成的代码上下文)。因此,目前ChatGPT对于软件开发的辅助仍然难以达到完全端到端的程度,软件开发的”最后一公里“仍然需要程序员自身不断进行调试修改与完善。
2. 具有较大随机性。
相同的问题,多次提问ChatGPT后产生的回答可能截然不同,总体来说生成结果具有较大随机性,这对于一些想要利用ChatGPT进行的科学研究可能存在一定程度的影响。例如,如果想要研究不同提示模板对于生成内容的影响,可能无法确定是提示模板更换带来的生成效果改善,还是单纯随机生成的结果。
3.无法保证正确性。
“一本正经地胡说八道”是很多人诟病ChatGPT存在的问题,这一问题目前仍然没有得到很好的解决,即使是GPT-4生成的内容也依然无法保证正确性。这就要求利用ChatGPT辅助软件开发的程序员自身拥有一定的背景知识和项目理解,仔细评估ChatGPT的回答,并进行必要的修改和调整,以确保生成的代码符合实际需求。
复旦大学 CodeWisdom团队
作者丨杜雪盈 字千成 刘俊伟
排版丨刘俊伟
审核丨彭鑫 娄一翎 刘名威


助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)