
ChatGPT Plugin发布,这东西到底是干嘛的?里面的逻辑是什么?
这个逻辑和LangChain的agent模块基本一致。目前只有一个核心区别,就是这个插件看起来是只作用于ChatGPT,也就是说我们需要登录到chatGPT的网站上通过对话才能使用这个插件。而LangChain不同,他是一个工具,可以开发一个独立与ChatGPT的网站或者工具。如果我是LangChain,就直接着手开发对接plugin的Agent或者tool咯。
前言
chatGPT目前的明显问题是不能够获取新知识,也没有办法和外界交互,而plugin就是来解决这个问题的。
chatgpt-retrieval-plugin
插件的基本信息
这是最新开源的一个plugin,里面有几个核心点
第一个是插件的定义

我不逐句翻译了,大概意思就是可以扩展chatGPT,这样就可以试用外部的资料和调用外部的服务了。
然后又说明了一个插件需要的三个部分
- 需要一个API
- 需要一个API的定义
- 需要一个描述这个插件的json文件
插件和chatGPT之间的核心逻辑
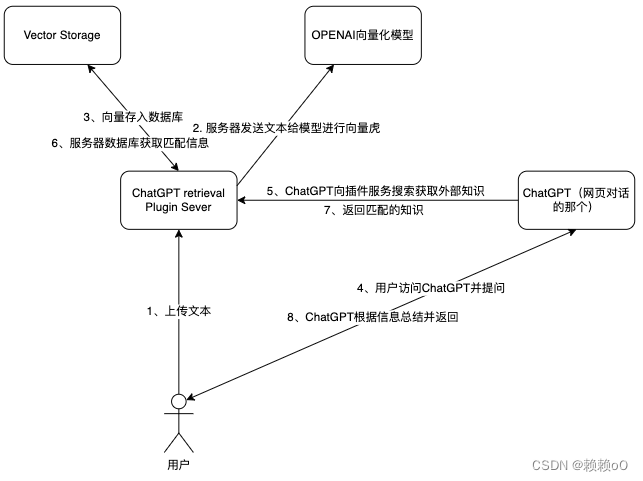
这个图其实就是插件与chatGPT的一个核心交互模式。
解释下里面的的核心点:chatGPT是如何和工具进行交互的。
这里就涉及到刚才插件要求的三个要素,Api、Api文档、插件描述。
我们核心看插件描述和API文档
api-plugin.json
{
"schema_version": "v1",
"name_for_model": "retrieval",
"name_for_human": "Retrieval Plugin",
"description_for_model": "Plugin for searching through the user's documents (such as files, emails, and more) to find answers to questions and retrieve relevant information. Use it whenever a user asks something that might be found in their personal information.",
"description_for_human": "Search through your documents.",
"auth": {
"type": "user_http",
"authorization_type": "bearer"
},
"api": {
"type": "openapi",
"url": "https://your-app-url.com/.well-known/openapi.yaml",
"has_user_authentication": false
},
"logo_url": "https://your-app-url.com/.well-known/logo.png",
"contact_email": "hello@contact.com",
"legal_info_url": "hello@legal.com"
}
openapi.yaml
openapi: 3.0.2
info:
title: Retrieval Plugin API
description: A retrieval API for querying and filtering documents based on natural language queries and metadata
version: 1.0.0
servers:
- url: https://your-app-url.com
paths:
/query:
post:
summary: Query
description: Accepts search query objects array each with query and optional filter. Break down complex questions into sub-questions. Refine results by criteria, e.g. time / source, don't do this often. Split queries if ResponseTooLargeError occurs.
operationId: query_query_post
requestBody:
content:
application/json:
schema:
$ref: "#/components/schemas/QueryRequest"
required: true
responses:
"200":
description: Successful Response
content:
application/json:
schema:
$ref: "#/components/schemas/QueryResponse"
"422":
description: Validation Error
content:
application/json:
schema:
$ref: "#/components/schemas/HTTPValidationError"
security:
- HTTPBearer: []
components:
schemas:
DocumentChunkMetadata:
title: DocumentChunkMetadata
type: object
properties:
source:
$ref: "#/components/schemas/Source"
source_id:
title: Source Id
type: string
url:
title: Url
type: string
created_at:
title: Created At
type: string
author:
title: Author
type: string
document_id:
title: Document Id
type: string
DocumentChunkWithScore:
title: DocumentChunkWithScore
required:
- text
- metadata
- score
type: object
properties:
id:
title: Id
type: string
text:
title: Text
type: string
metadata:
$ref: "#/components/schemas/DocumentChunkMetadata"
embedding:
title: Embedding
type: array
items:
type: number
score:
title: Score
type: number
DocumentMetadataFilter:
title: DocumentMetadataFilter
type: object
properties:
document_id:
title: Document Id
type: string
source:
$ref: "#/components/schemas/Source"
source_id:
title: Source Id
type: string
author:
title: Author
type: string
start_date:
title: Start Date
type: string
end_date:
title: End Date
type: string
HTTPValidationError:
title: HTTPValidationError
type: object
properties:
detail:
title: Detail
type: array
items:
$ref: "#/components/schemas/ValidationError"
Query:
title: Query
required:
- query
type: object
properties:
query:
title: Query
type: string
filter:
$ref: "#/components/schemas/DocumentMetadataFilter"
top_k:
title: Top K
type: integer
default: 3
QueryRequest:
title: QueryRequest
required:
- queries
type: object
properties:
queries:
title: Queries
type: array
items:
$ref: "#/components/schemas/Query"
QueryResponse:
title: QueryResponse
required:
- results
type: object
properties:
results:
title: Results
type: array
items:
$ref: "#/components/schemas/QueryResult"
QueryResult:
title: QueryResult
required:
- query
- results
type: object
properties:
query:
title: Query
type: string
results:
title: Results
type: array
items:
$ref: "#/components/schemas/DocumentChunkWithScore"
Source:
title: Source
enum:
- email
- file
- chat
type: string
description: An enumeration.
ValidationError:
title: ValidationError
required:
- loc
- msg
- type
type: object
properties:
loc:
title: Location
type: array
items:
anyOf:
- type: string
- type: integer
msg:
title: Message
type: string
type:
title: Error Type
type: string
securitySchemes:
HTTPBearer:
type: http
scheme: bearer
这两个部分有点长,我摘出重点
在插件描述中:
"name_for_model": "retrieval",
"description_for_model": "Plugin for searching through the user's documents (such as files, emails, and more) to find answers to questions and retrieve relevant information. Use it whenever a user asks something that might be found in their personal information.",
api定义中
/query:
post:
summary: Query
description: Accepts search query objects array each with query and optional filter. Break down complex questions into sub-questions. Refine results by criteria, e.g. time / source, don't do this often. Split queries if ResponseTooLargeError occurs.
operationId: query_query_post
这两段逻辑就是ChatGPT可以判断是否要调用这个接口的依据,也就是说这两段会传如到prompt中去。
而具体怎么调用就是通过openapi.yaml 来获取的接口知识,这个对gpt来说实在是太简单。
总结
这个逻辑和LangChain的agent模块基本一致。目前只有一个核心区别,就是这个插件看起来是只作用于ChatGPT,也就是说我们需要登录到chatGPT的网站上通过对话才能使用这个插件。而LangChain不同,他是一个工具,可以开发一个独立与ChatGPT的网站或者工具。
如果我是LangChain,就直接着手开发对接plugin的Agent或者tool咯

助力广东及东莞地区开发者,代码托管、在线学习与竞赛、技术交流与分享、资源共享、职业发展,成为松山湖开发者首选的工作与学习平台
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)