slurm集群执行作业出现RuntimeError: No CUDA GPUs are available、CUDA_LAUNCH_BLOCKING=1等问题。
解决了linux集群利用slurm工具在初期跑torch代码遇到的gpu不可用相关问题。
问题描述
当我写好脚本sh文件后用sbatch执行后发现,总是会报RuntimeError: No CUDA GPUs are available。
找了找办法,在main.py代码里加了两句:
print(torch.cuda.device_count())
print(torch.cuda.is_available())
结果:
0
False
用squeue -l查看当前进程状态,发现其已经在计算节点comput8上,难不成计算节点8没有GPU?
查了一下comput8节点的资源情况 sinfo -o "%all" -N -n comput8:
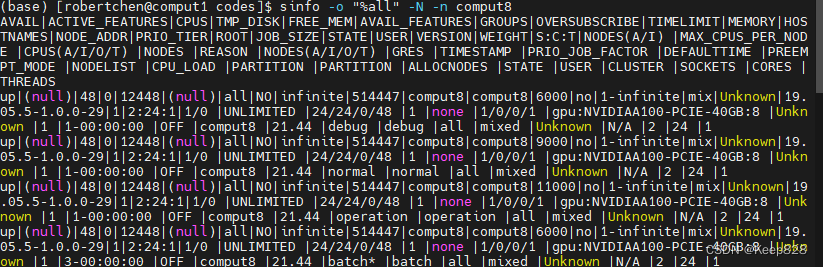
明明是有的。
最终,把脚本sh文件的内容改了一下重新保存,发现可能是之前脚本文件没有读进去导致的?因为改了之后至少python代码中.cuda()的部分不报错了。
把.sh文件改为如下:
#!/bin/bash
#SBATCH -J MICRO # 作业名
#SBATCH -N 1 # 申请节点数
#SBATCH --output=/public/home/robertchen/ylzhang20215227085/MICRO/codes/slurm/slurm.out # 输出slurm.out日志文件目录
#SBATCH --gres=gpu:1 # 指定我们需要使用 1 个 GPU 设备
#SBATCH --ntasks-per-node=8
source activate ylzhang20215227085-MICRO
nvidia-smi
python ./main.py
还有一种可能,是在代码中用了 os.environ[“CUDA_VISIBLE_DEVICES”] = str(args.gpu_id) 指定gpu id。这样也会报No GPU available!
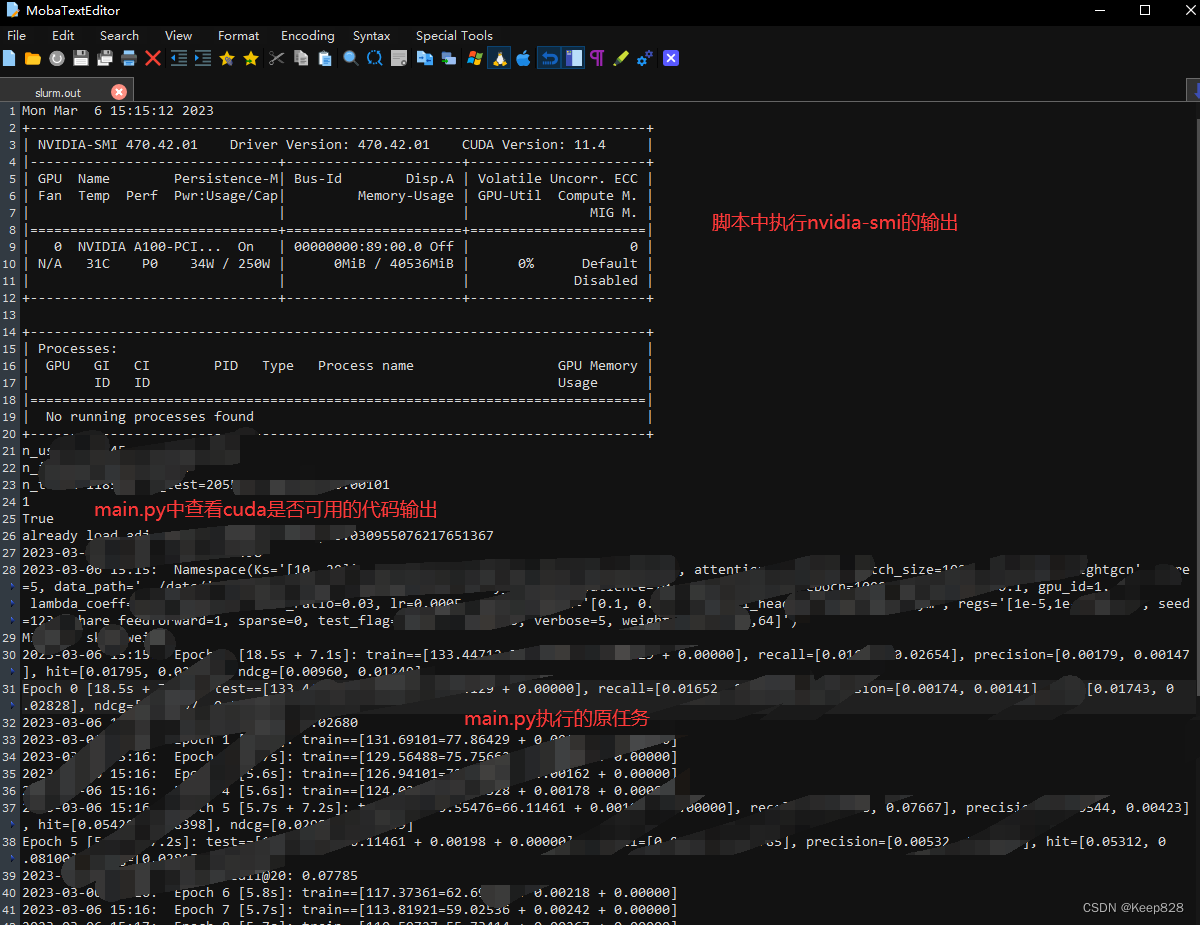
然后不报之前.cuda()的No GPU avaliable错误了,而且输出显示,torch打印cuda的代码输出GPU检测到了(结果中的1和True是之前在main.py函数中加的print函数打印出torch.cuda的信息):
Mon Mar 6 14:36:48 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.42.01 Driver Version: 470.42.01 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-PCI... On | 00000000:89:00.0 Off | 0 |
| N/A 31C P0 34W / 250W | 0MiB / 40536MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
/public/home/xxxxxx/anaconda3/envs/xxxxxxx-MICRO/lib/python3.6/site-packages/torch/cuda/__init__.py:143: UserWarning:
NVIDIA A100-PCIE-40GB with CUDA capability sm_80 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70.
If you want to use the NVIDIA A100-PCIE-40GB GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
warnings.warn(incompatible_device_warn.format(device_name, capability, " ".join(arch_list), device_name))
1
True
错误还是有,在forward内改报这个:
return F.linear(input, self.weight, self.bias)
File "/public/home/robertchen/anaconda3/envs/ylzhang20215227085-MICRO/lib/python3.6/site-packages/torch/nn/functional.py", line 1848, in linear
return torch._C._nn.linear(input, weight, bias)
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
查了一下说是要重装torch,用conda装,我之前确实用pip装的,所以进入自己的环境pip uninstall torch后,用conda的指令按照自己对torch版本的需要重新装了一下:
# CUDA 11.3
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
附:各个pytorch版本安装指令官网:torch各版本安装指令
安装完毕。
重新执行作业sbatch -N 1 -n 4 --nodelist=comput2 sleep.sh,
Submitted batch job 4168
用squeue查看作业情况:
(base) [robertchen@comput1 codes]$ squeue -l
Mon Mar 6 15:16:03 2023
JOBID PARTITION NAME USER STATE TIME TIME_LIMI NODES NODELIST(REASON)
4168 batch MICRO robertch RUNNING 0:35 3-00:00:00 1 comput2
顺利提交并执行作业。问题解决!
可在刚刚脚本文件中指定的output目录中查看作业实时的执行结果。
问题总结
对于一开始的RuntimeError: No CUDA GPUs are available
该问题报错在源代码.cuda()处,原因不清楚,推测可能是由于脚本文件.sh没有得到有效的读取(因为之前写的格式不对)导致。所以,在将.sh文件格式改为正确的后便没再报此错误了。
此外,还在执行slurm作业的命中中声明了其他的指定,我使用的指令如下:
sbatch -N 1 -n 4 --nodelist=comput2 sleep.sh
对于CUDA_LAUNCH_BLOCKING=1问题
用pip卸载原来pip安装的torch,并用conda安装指定的torch版本和对应的cuda版本(用conda安装),我用到的指令为:
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=11.3 -c pytorch -c conda-forge
至此,问题就解决了。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)