
【stata】处理重复值之duplicates drop_all和duplicates drop_all, force区别(整行数据重复和单元格数据重复)
【stata】处理重复值之duplicates drop_all和duplicates drop_all, force区别(整行数据重复和单元格数据重复)
一键AI生成摘要,助你高效阅读
问答
·
关于stata重复值处理常用的duplicates函数,很疑惑为什么要加force,区别如下图所示。
一、duplicates常用语法
duplicates report [varlist] [if] [in] //报告某个变量出现的次数
duplicateslist [varlist] [if] [in] [,options] //列出重复的变量
duplicates tag [varlist] [if] [in] , generate(newvar) //生成一个新变量,当某一行数据为重复值时,生成的新变量值为1,否则为0
duplicates drop[if] [in] //删掉重复值,同时保留下每一组重复值中的第一行数据
二、duplicates drop_all和duplicates drop_all, force区别
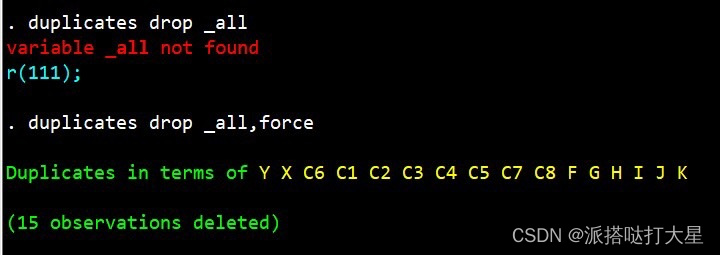
这是因为stata认为这样删除会让你丢失关于age的信息,所以它不允许。那如果某变量恰好是你不需要用的变量,可以加上force选项。
参考博客:

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)